自顶向下分析概述
引言
在第一章绪论中曾介绍过语法分析的基本任务就是根据给定的文法,识别输入句子中的各类短语,并构造它的分析树
如果输入串的各个单词恰好自左至右的在分析树的各个叶结点上,那么这个子串就是该语言的一个句子,否则就不是。
按照分析树的构造方向,我们可以把语法分析分为两类。
- 第一类是从分析树顶部的根节点向底部的叶节点方向构造分析树,这种方法称为自顶向下的分析方法。
- 第二类是从分析树底部的叶节点向顶部的根节点方向构造分析树,这种方法称为自底向上的分析方法。
自顶向下分析
从分析树的顶部(根节点)向底部(叶节点)方向构造分析树
由于分析树的根节点对应文法的开始符号,分析树的叶节点对应输入串的各个单词,因此自顶向下分析可以看成是从文法开始符号 S 推导出词串w的过程。
【例】最左推导和最右推导
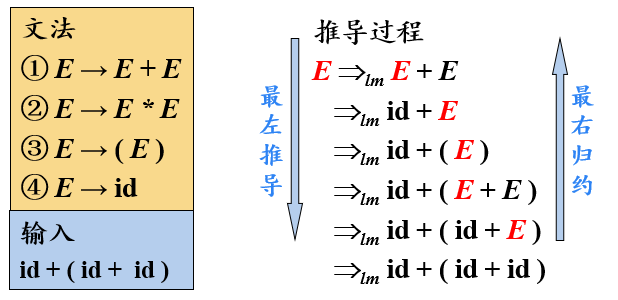
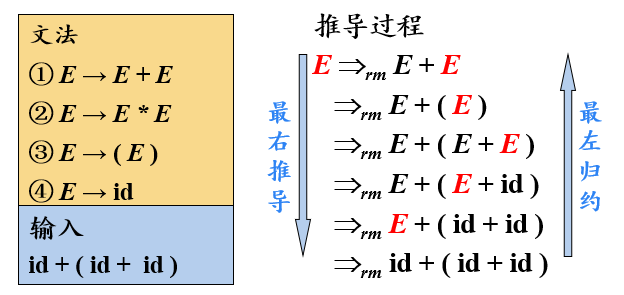
- 每一步推导中,都需要做两个选择
- 替换当前句型中的哪个非终结符
- 用该非终结符的哪个候选式进行替换
- 在最左(右)推导中,总是选择每个句型的最左(右)非终结符进行替换
- 在自底向上的分析中,总是采用最左归约的方式,因此把最左归约称为规范归约,而最右推导相应地称为规范推导
最左推导和最右推导具有唯一性
自顶向下的语法分析采用最左推导方式
- 总是选择每个句型的最左非终结符进行替换
- 替换时根据输入流中的下一个终结符,选择最左非终结符的一个候选式
【例】自顶向下分析(最左推导)
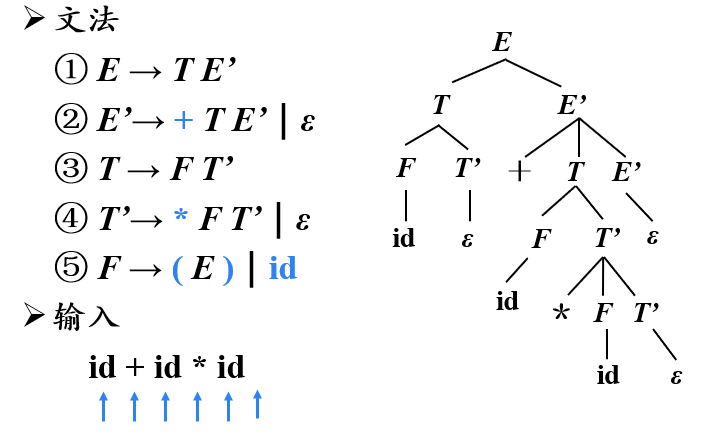
递归下降分析
计算机如何实现自顶向下的语法分析:递归下降分析
- 递归下降分析 (Recursive-Descent Parsing)
- 由一组过程组成,每个过程对应一个非终结符
- 也就是说文法中有多少个非终结符,就有多少个过程
- 从文法开始符号S对应的过程开始,其中递归调用文法中其它非终结符对应的过程。如果S对应的过程体恰好扫描了整个输入串,则成功完成语法分析
- 由一组过程组成,每个过程对应一个非终结符
对应于非终结符A的过程:
|
|
在A的工作过程中,虽然我们是根据输入符号来选择产生式,但是我们仍然会遇到一些不确定的情况。
- 比如说:对于当前的输入符号a,存在多个以终结符a打头的候选式时我们就不能确定选择哪一个。
- 解决方法:我们按照某一顺序逐个尝试,如果尝试失败,则退回上一步,然后看是否还有其他候选式。这个退回上一步再重新尝试的步骤就叫做回溯。
回溯会导致分析器的效率降低。需要回溯的分析器叫做不确定的分析器。
如果在分析的过程中,我们能预测出正确的产生式,那么就不需要回溯,这种分析叫做预测分析。
预测分析是递归下降分析技术的一个特例,通过在输入中向前看固定个数(通常是一个)符号来选择正确的A-产生式。
- 可以对某些文法构造出向前看k个输入符号的预测分析器,该类文法有时也称为LL(k)文法类
预测分析不需要回溯,是一种确定的自顶向下分析方法
文法转换
事实上,并不是所有的文法都适合自顶向下的分析。但可以通过改造文法使其适合自顶向下的分析,这就叫做文法转换。
【问题1】文法中的某个符号存在多个公共前缀导致回溯

提取左公因子

算法

【问题二】左递归导致无限循环
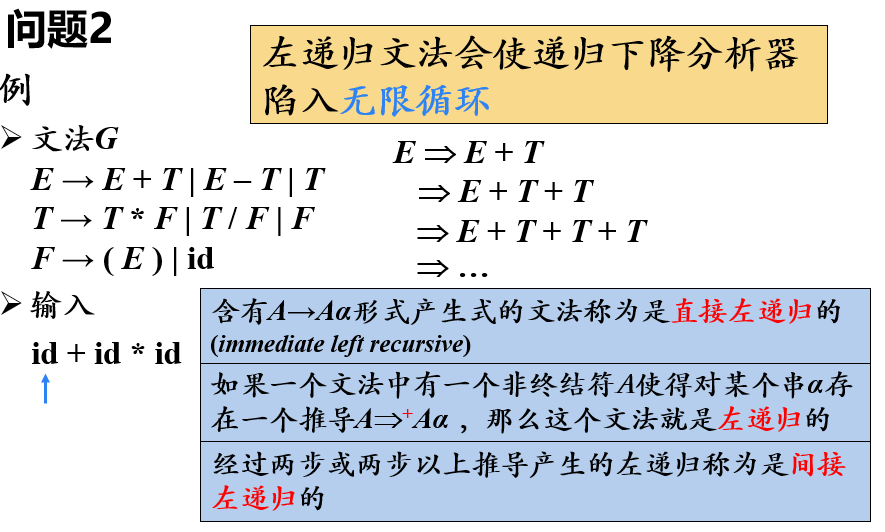
消除左递归
消除直接左递归
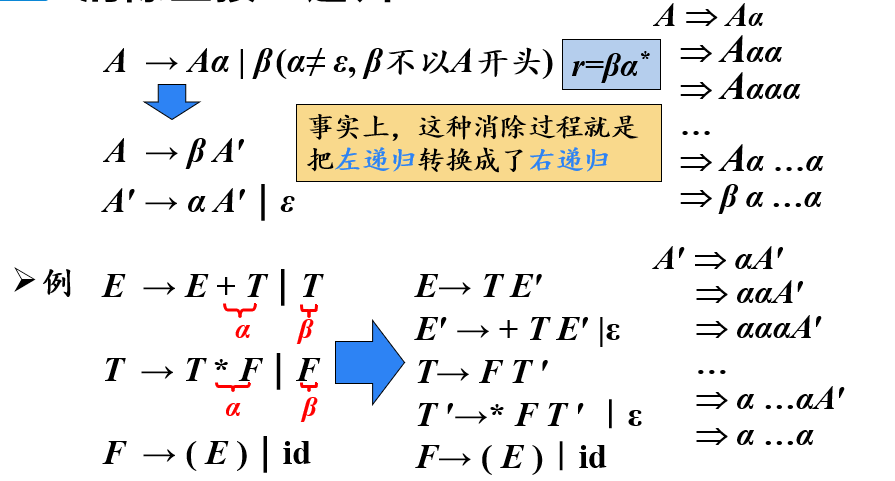
将上述方法进行推广,可得到消除直接左递归的一般形式:
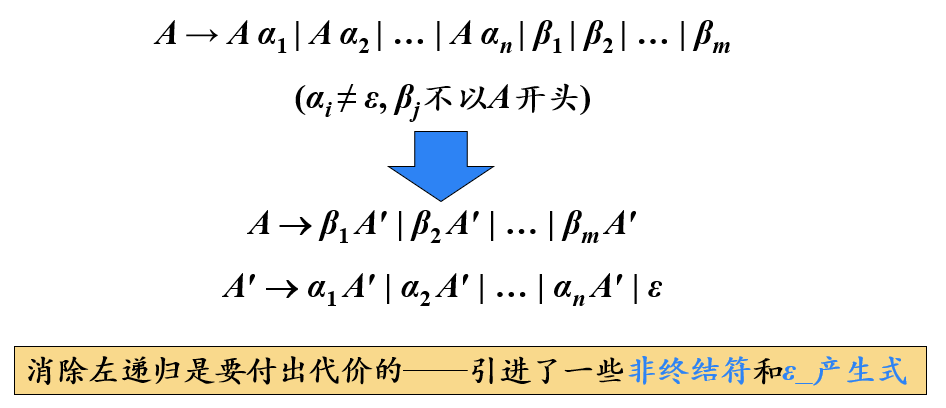
消除间接左递归

算法

LL(1)文法
递归下降分析可能会遇到回溯,回溯会影响分析器的效率。如果在分析的每一步我们都能预测到正确的选择的话,我们就不需要回溯。这样的分析叫做预测分析。下面介绍的LL(1)文法就可以使用预测分析技术。
S_文法

【例】
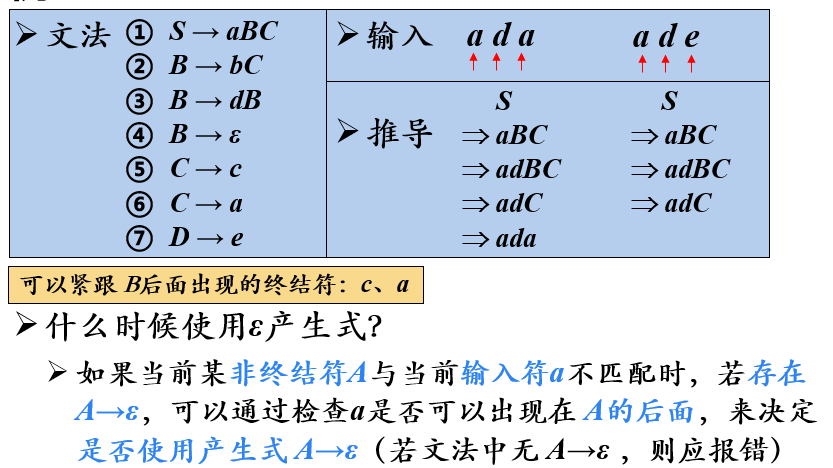
- 由文法中的156式可以看出,B后面可以出现的终结符:c、a
非终结符的后继符号集
由上例可以引出非终结符的后继符号集FOLLOW这一概念

产生式的可选集
为了叙述上的方便,引入产生式的可选集SELECT这一概念

- 也就是说当输入符号在可选集中时,就可以使用该产生式进行推导
- 对于拥有相同左部的各个产生式,它们的SELECT集互不相交的话,我们就可以做出确定的分析。因此,我们给出q_文法的定义。
q_文法相比s_文法更加强大,因为q_文法的右部可以是空串。
串首终结符
q_文法对产生式的右部限制依然非常严格,它不允许产生式的右部以非终结符打头,这限制了q_文法的应用范围。因此我们引入功能更加强大的LL(1)文法。
在LL(1)文法中,允许产生式的右部以非终结符打头,这就增加了计算可选集SELECT的复杂性。由此,我们引入串首终结符集FIRST这一概念。

LL(1)文法

LL(1)文法
- 第一个“L”表示从左向右扫描输入
- 第二个“ L”表示产生最左推导
- “1”表示在每一步中只需要向前看一个输入符号来决定语法分析动作
FIRST集和FOLLOW集的计算
FIRST集的计算

- 计算顺序:245→3→1
算法

串

FOLLOW集的计算
要先求出FIRST集

- E → TE'
- E可以是某个句型的最右符号,所以将
$加入FOLLOW(E); - E’的FIRST集中所有终结符可以跟在T后面,所以将FIRST(E')中的
+加入FOLLOW(T); - 由于E’的FIRST集中存在空串,也就是说E’可以是空串,那么E和T等价,能跟在E后面的终结符就能跟在T后面,所以将FOLLOW(E)中
$符号加入FOLLOW(T)中; - E’是产生式右边最后一个符号,也就是说能跟在E后面的终结符就能跟在E‘后面,因此将FOLLOW(E)中
$符号加入FOLLOW(E')中; - 此时FOLLOW(E) = {
$},FOLLOW(T) = {+$},FOLLOW(E') = {$}
- E可以是某个句型的最右符号,所以将
- E' → +TE' | ε
- TE’所处位置与第一个产生式类似,所以分析结果与第一个产生式相同
- T → FT'
- T’的FIRST集中所有终结符可以跟在F后面,所以将FIRST(T')中的
*加入FOLLOW(F); - 由于T’的FIRST集中存在空串,也就是说T’可以是空串,那么T和F等价,能跟在T后面的终结符就能跟在F后面,所以将FOLLOW(T)中
+和$符号加入FOLLOW(F)中; - T’是产生式右边最后一个符号,也就是说能跟在T后面的终结符就能跟在T’后面,因此将FOLLOW(T)中
+和$符号加入FOLLOW(T')中; - 此时FOLLOW(E) = {
$},FOLLOW(T) = {+$},FOLLOW(E') = {$},FOLLOW(F) = {*+$},FOLLOW(T') = {+$}
- T’的FIRST集中所有终结符可以跟在F后面,所以将FIRST(T')中的
- T' → *FT' | ε
- FT’所处位置与第三个产生式类似,所以分析结果与第一个产生式相同
- F → (E) | id
- E后面跟着终结符
),所以将)加入FOLLOW(E)中 - 由于FOLLOW(E')、FOLLOW(T)依赖于FOLLOW(E),所以将
)加入FOLLOW(E')、FOLLOW(T)中 - 由于FOLLOW(T')、FOLLOW(F)依赖于FOLLOW(T),所以将
)加入FOLLOW(T')、FOLLOW(F)中 - 此时FOLLOW(E) = {
$)},FOLLOW(T) = {+$)},FOLLOW(E') = {$)},FOLLOW(F) = {*+$)},FOLLOW(T') = {+$)}
- E后面跟着终结符
算法

SELECT集的计算
要先求出FIRST集和FOLLOW集

- 第一个产生式的开头是一个非终结符,所以它的SELECT集应该是产生式右部第一个非终结符T的FIRST集中的终结符
- 第二个产生式开头是
+,所以第二个产生式的SELECT集就是终结符+ - 第三个产生式是一个空产生式,所以它的SELECT集就是E’的FOLLOW中的终结符
- ……
- 第二个产生式和第三个产生式具有相同的左部,且它们的SELECT集互不相交;第五个产生式和第六个产生式具有相同的左部,且它们的SELECT集也互不相交;所以这个文法是一个LL(1)文法
对于LL(1)文法,可以根据产生式的SELECT集来构造文法的预测分析表,预测分析表的每一行对应一个非终结符,每一列对应一个输入符号。
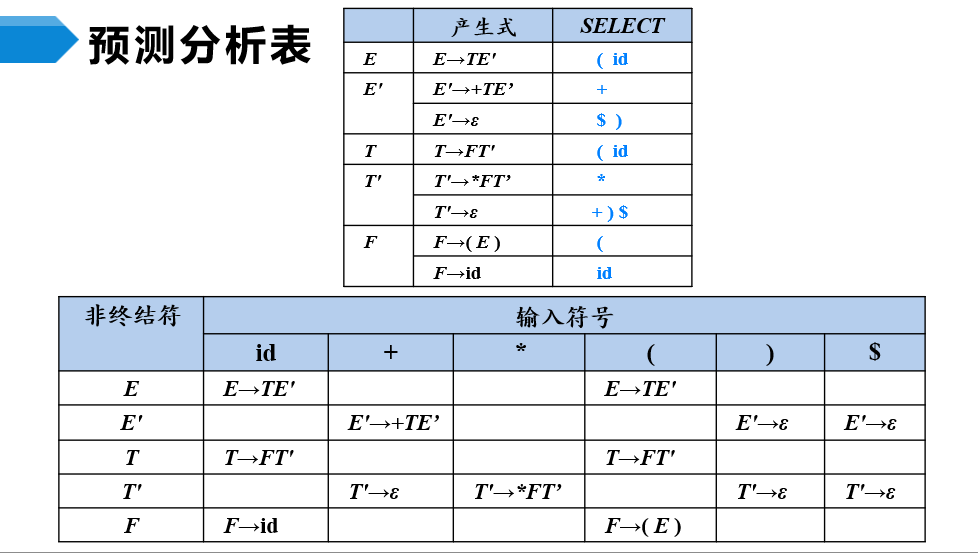
预测分析法可分为
- 递归的预测分析法
- 非递归的预测分析法
递归的预测分析法

【例】递归的预测分析法
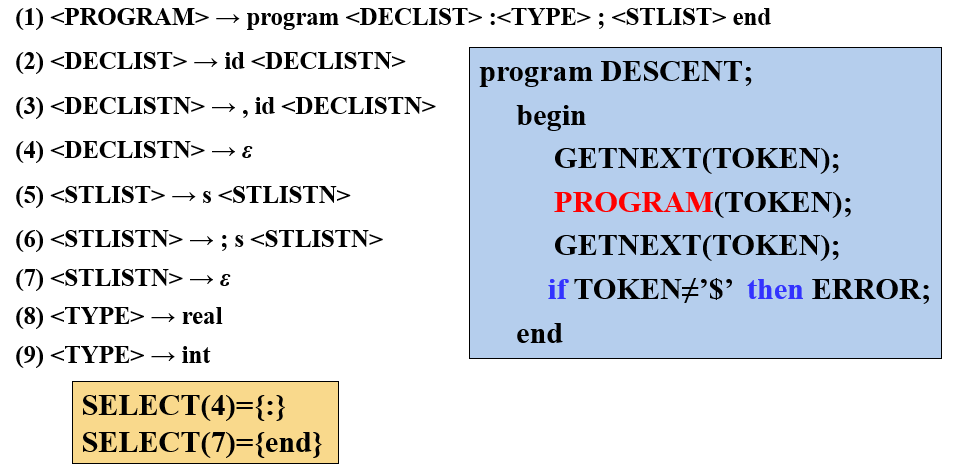
- 除了47的产生式是空串,其他的产生式都以终结符开头,所以除47外的其他产生式的SELECT集就是其开头的终结符
- 47产生式是空串,所以它们的SELECT集就是FOLLOW集中的终结符
- 由产生式12可知产生式4的FOLLOW集中包含
: - 由产生式15可知产生式7的FOLLOW集中包含
end procedure过程、recursive descent递归下降- 文法中每一个非终结符都对应一个过程
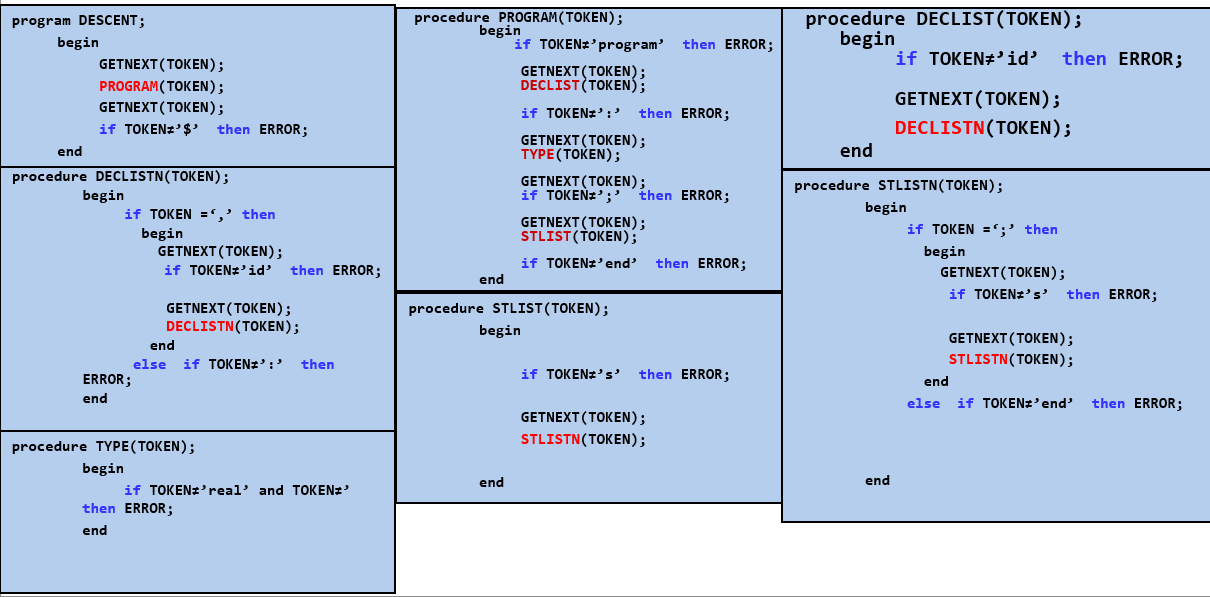
非递归的预测分析法
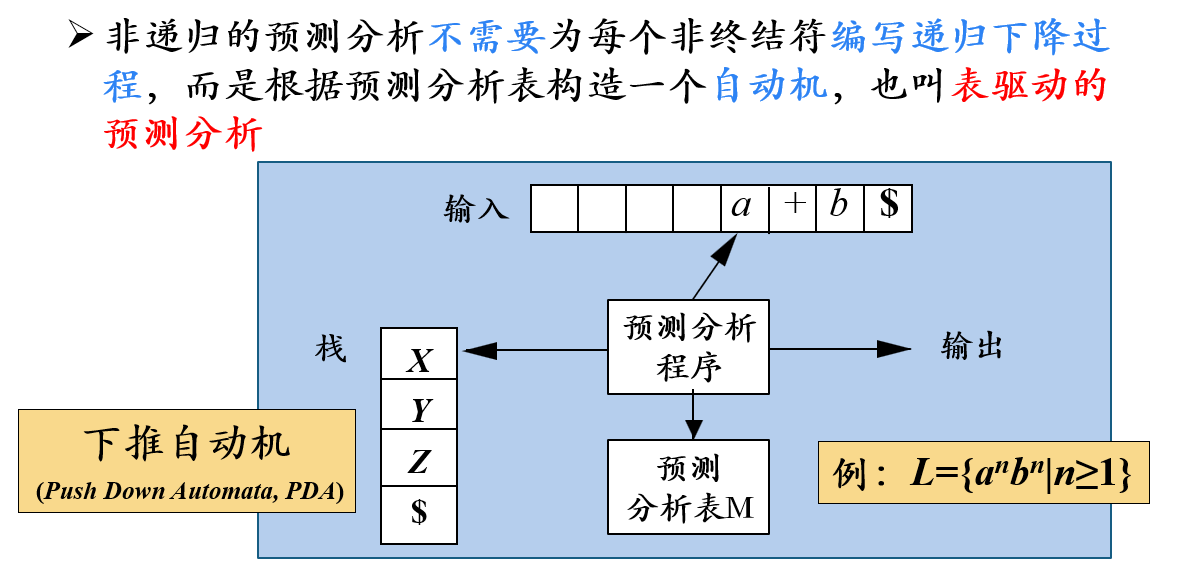
- 预测分析器由一个输入带、一个读头和一个带有预测分析表的控制器构成,与第三章词法分析中介绍的有穷自动机不同的是,这个自动机增加了个栈,也叫下推存储器,它起到记忆的作用。因此这个自动机也叫下推自动机。
- 下推自动机比有穷自动机的预测功能更强,因为下推自动机的记忆功能更强。
- 例如:有一个语言,它的句子是由
n个符号a连接同样个数n个符号b构成。- 如果想识别这个语言中的句子,就需要记录读入的
a的个数。 - 由于有穷自动机不具备专门的存储器,因此它要利用不同的状态记录
a的个数n。这里n是趋于无穷的,而有穷自动机的状态个数又是有穷的。这对矛盾就导致了有穷自动机无法识别该语言。 - 如果给有穷自动机增加一个栈的话,每当遇到一个输入符号
a,就把a压入栈中;每遇到一个输入符号b,就把一个a出栈,如果到串尾时,最后一个a出栈,即a的个数与b的个数相等。这样就成功识别了该语言。
- 如果想识别这个语言中的句子,就需要记录读入的
下推自动机的工作过程
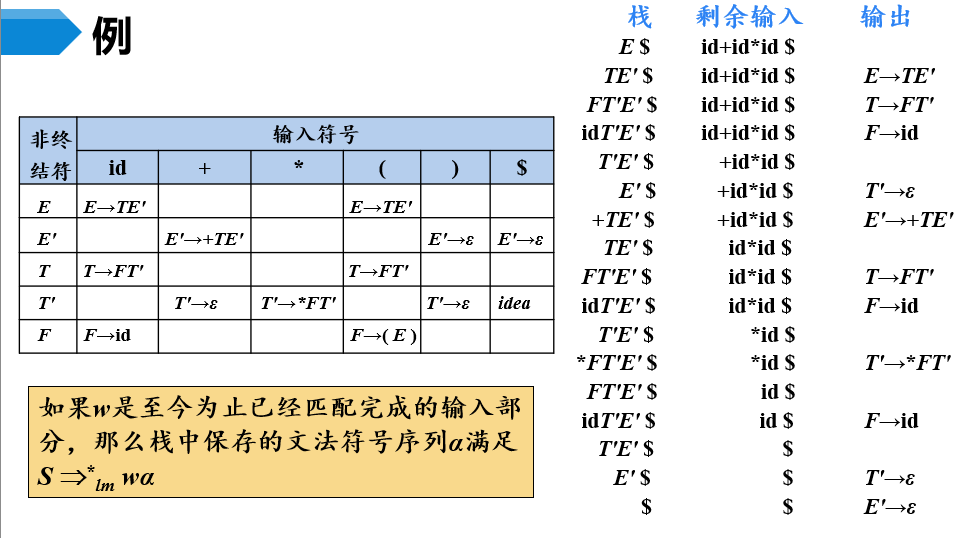
- 初始时,输入带上存放的是待分析的输入串,输入串结尾连接结束符号
$。同时,将$也作为栈底的标记(栈顶在左侧,栈底在右侧)。初始时,栈中只有唯一的符号,也就是文法的开始符号E。 - 栈顶是符号
E,当前输入指针指向符号id,通过查预测分析表得知,需要选择产生式E→TE',用TE'来替换E。因此栈顶元素E出栈,TE'进栈,并且输出产生式E→TE'。 - ……
- 输出的产生式序列就对应一个最左推导
将上述下推自动机的工作过程总结如下:

递归与非递归的对比
| 递归的预测分析法 | 非递归的预测分析法 | |
|---|---|---|
| 程序规模 | 程序规模较大,不需载入分析表 | 主控程序规模较小,需载入分析表(表较小) |
| 直观性 | 较好 | 较差 |
| 效率 | 较低 | 分析时间大约正比于待分析程序的长度 |
| 自动生成 | 较难 | 较易 |
- 由于递归的预测分析法需要为文法中的每一个非终结符编写一个递归下降过程。因此它的程序规模较大,但它不需要载入分析表。
- 由于递归的预测分析法是根据产生式的右部来编写程序,因此它的直观性比较好。
- 由于高深度的递归调用需要在递归子程序间进行连接,因此分析器的效率会降低。
- 由于递归的预测分析法需要根据产生式的右部来编写过程,因此比较难自动生成。而非递归地预测分析法采用自动机的方式,因此比较容易自动生成。
预测分析法的总结
总结预测分析法的实现步骤:
- 构造文法
- 改造文法:消除二义性、消除左递归、消除回溯
- 求每个变量的FIRST集和FOLLOW集,从而求得每个候选式的SELECT集
- 检查是不是 LL(1) 文法。若是,构造预测分析表
- 对于递归的预测分析,根据预测分析表为每一个非终结符编写一个过程;对于非递归的预测分析,实现表驱动的预测分析算法
预测分析中的错误检测
两种情况下可以检测到错误
- 栈顶的终结符和当前输入符号不匹配
- 栈顶非终结符与当前输入符号在预测分析表对应项中的信息为空
解决办法
- 恐慌模式
- 弹出该终结符
恐慌模式
恐慌模式:忽略输入中的一些符号,直到输入中出现合法的词法单元。事实上,设计者可以事先设定同步词法单元,一旦输入中出现同步词法单元,就可以立即进行同步。
- 忽略输入中的一些符号,直到输入中出现由设计者选定的同步词法单元(synchronizing token)集合中的某个词法单元
- 其效果依赖于同步集合的选取。集合的选取应该使得语法分析器能从实际遇到的错误中快速恢复
- 例如可以把FOLLOW(A)中的所有终结符放入非终结符A的同步记号集合。
- 意思是当栈顶是非终结符A的时候,检测到错误,说明A在识别过程中遇到了问题。
- 这时就可以放弃对A的识别,转而去分析A后面的成分。
- 也就是说当识别A遇到错误,往后扫描到FOLLOW(A)中的终结符时,将A出栈,将扫描到的FOLLOW(A)中的某个终结符入栈,从该成分开始继续分析
- 其效果依赖于同步集合的选取。集合的选取应该使得语法分析器能从实际遇到的错误中快速恢复
弹栈
如果终结符在栈顶而不能匹配,一个最简单的办法就是弹出此终结符
【例】根据非终结符的FOLLOW集构造非终结符的同步词法单元
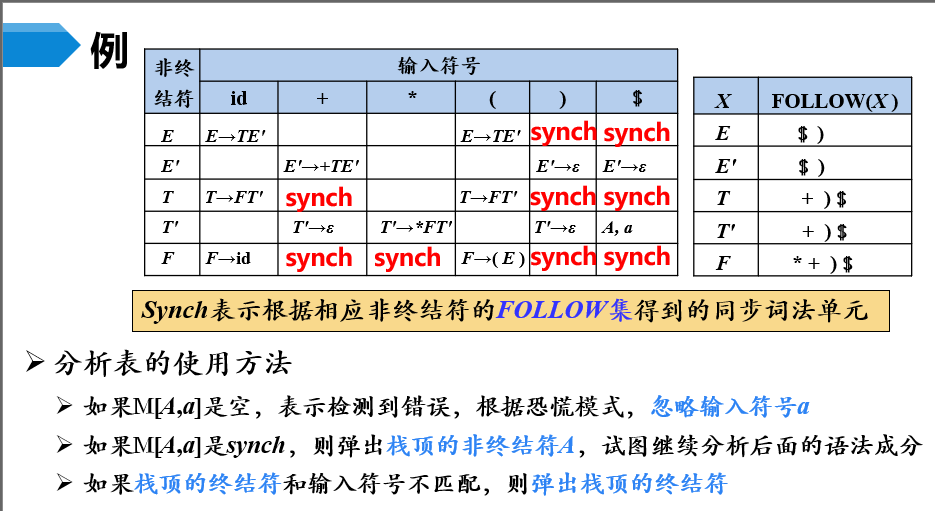
synch表示该终结符是对应非终结符的同步词法单元- 分析表的使用方法
M[A,a]中的A表示栈顶符号,a表示输入符号,M是预测分析表
【例】预测分析表工作过程
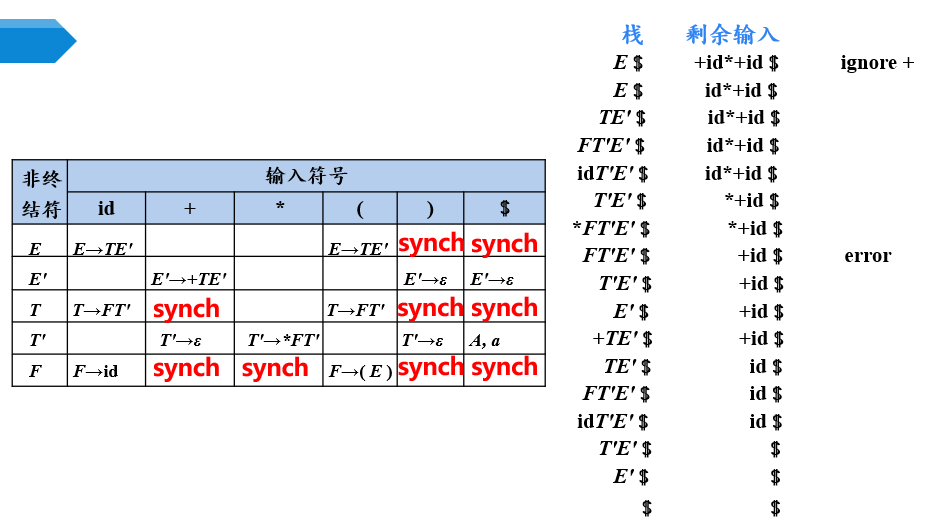
M[E,+]为空,忽略+M[F,+]是synch,弹出F