类型表达式
- 基本类型是类型表达式
- integer、real、char、boolean、type_error (出错类型)、void (无类型)
- 可以为类型表达式命名,类型名也是类型表达式
- 将类型构造符(type constructor)作用于类型表达式可以构成新的类型表达式
- 数组构造符array
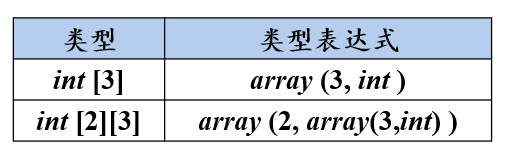
- 若T是类型表达式,则array ( I, T )是一个表示数组类型的表达式,该数组包含I个元素,每个元素都是T类型
- 指针构造符pointer
- 若T是类型表达式,则 pointer ( T ) 是一个表示指向类型T的指针类型的表达式
- 笛卡尔乘积构造符
- 若T1 和 T2是类型表达式,则笛卡尔乘积T1 × T2 是类型表达式
- 函数构造符→
- 若T1、T2、…、Tn 和R是类型表达式,则T1 × T2 ×…× Tn→ R是类型表达式(T1,T2表示函数参数类型,R表示函数返回值类型)
- 记录构造符record
- 若有标识符N1 、N2 、…、Nan 与类型表达式T1 、T2 、…、Tn , 则 record ( ( N1 × T1 ) × ( N2 × T2 )× …× ( Nan × Tn )) 是一个类型表达式 (记录中有n个字段,每个字段名为N1、N2、……,字段类型为T1、T2、……)
- 数组构造符array
【例1-1】数组类型表达式
【例1-2】结构体类型表达式

声明语句翻译
- 对于声明语句,语义分析的主要任务就是收集标识符的类型等属性信息,并为每一个名字分配一个相对地址
- 从类型表达式可以知道该类型在运行时刻所需的存储单元数量称为类型的宽度(width)
- 在编译时刻,可以使用类型的宽度为每一个名字分配一个相对地址
- 名字的类型和相对地址信息保存在相应的符号表记录中
【例2-1】声明语句(基本类型)的语法制导翻译
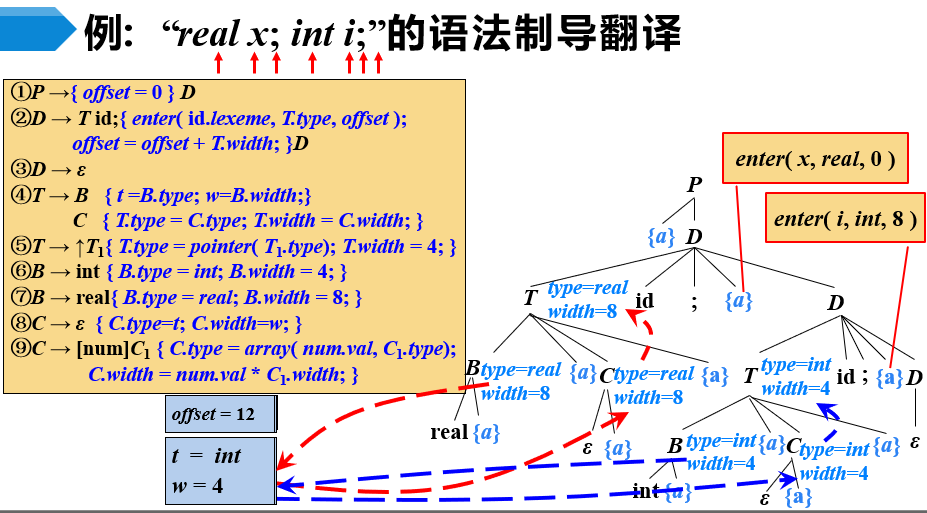
- 该SDT(语法制导翻译方案)对应的是一个L属性定义,若该L属性定义的基础文法是LL(1)文法,则可以在自顶向下分析中实现该SDT
- 验证该基础文法是否为LL(1)文法
- 判断具有相同左部的产生式,它们的可选集是否不相交
- 产生式23具有相同左部
- SELECT(2)=FIRST(T)=FIRST(B)={int,real,⬆}
- SELECT(3)=FOLLOW(D)={$}
- 产生式45具有相同左部
- SELECT(4)={int,real}
- SELECT(5)={⬆}
- 产生式67具有相同左部
- SELECT(6)={int}
- SELECT(7)={real}
- 产生式89具有相同左部
- SELECT(8)=FOLLOW(C)=FOLLOW(T)={id}
- SELECT(9)={ [ }
- 综上,该基础文法为LL(1)文法
- 初始时刻,输入指针指向real
- 从文法开始符号P开始推导,根据产生式1,将P替换2个符号
- 第一个符号是用来表示语义动作的动作符号,起名为a,
- 第二个符号是非终结符D
- 此时,动作符号a处于栈顶,执行它所对应的语义动作,即将offset置为0,随后动作符号a出栈
- 此时,栈顶为非终结符D,因为当前输入符号为real,所以选择产生式2,将D替换为4个符号
- 此时,栈顶为非终结符T,因为当前输入符号为real,所以选择产生式4,将T替换为4个符号
- 此时,栈顶为非终结符B,因为当前输入符号为real,所以选择产生式7,将B替换为2个符号
- 从文法开始符号P开始推导,根据产生式1,将P替换2个符号
- 此时,栈顶为终结符real,与输入符号匹配成功,real出栈,输入指针指向下一个输入符号x
- 此时,动作符号a处于栈顶,执行它所对应的语义动作,即将B的两个综合属性type和width分别置为real和8
- ……
- ……
- enter是一条记录
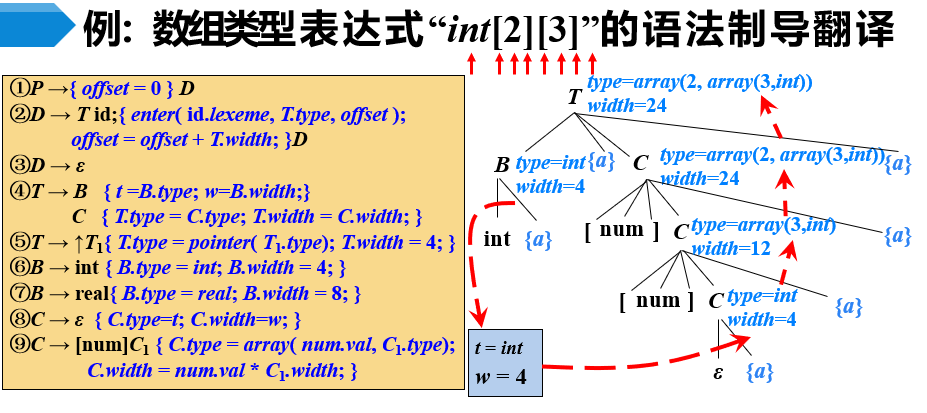
【例2-2】声明语句(数组类型)的语法制导翻译
赋值语句翻译
简单赋值语句的翻译


- lookup(name):查询符号表返回name对应的记录(值)
- gen(code):生成三地址指令code
- newtemp( ):生成一个新的临时变量t,返回t的地址

- code:表达式的值
- addr:表达式的值的存放地址
- ||:连接运算符
【例3-1】增量翻译
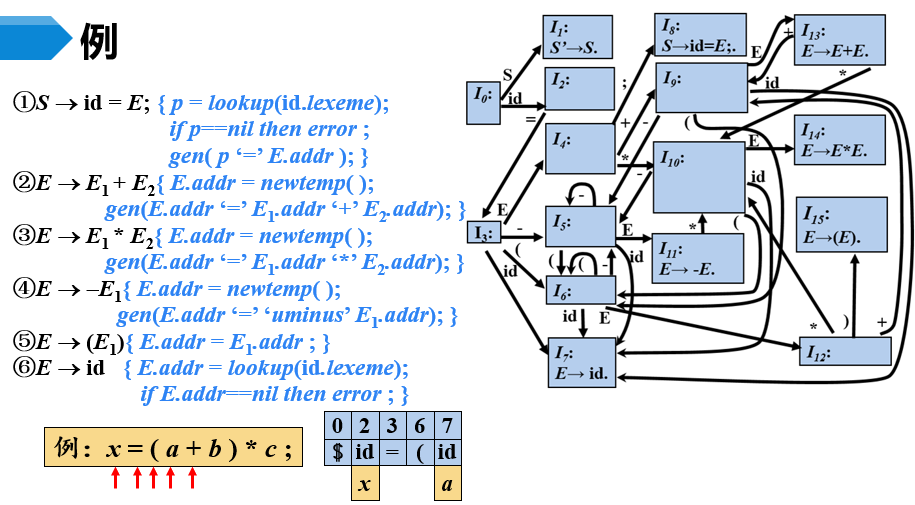
- 在第四章中曾分析过,该SDT的基础文法可以采用LR分析技术,且所有的语义动作都位于产生式右部的末尾,因此,采用自底向上的方式来翻译
- 具体翻译过程用文字描述较为繁琐,可看视频讲解:传送门
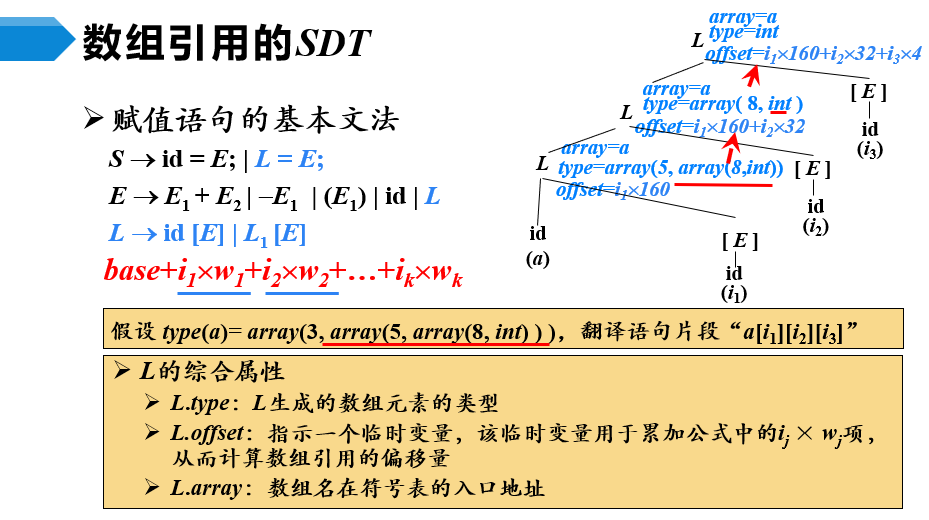
数组引用的翻译


- 地址计算公式
【例3-2】数组元素寻址

- a[i1]:二维数组,宽度为5×8×4=160bit
- a[i1] [i2]:一维数组,宽度为8×4=32bit
- a[i1] [i2] [i3]:一个整型变量,宽度为4bit
【例3-3】带有数组引用的赋值语句的翻译(一维)

【例3-4】带有数组引用的赋值语句的翻译(二维)

【例3-5】数组引用的SDT

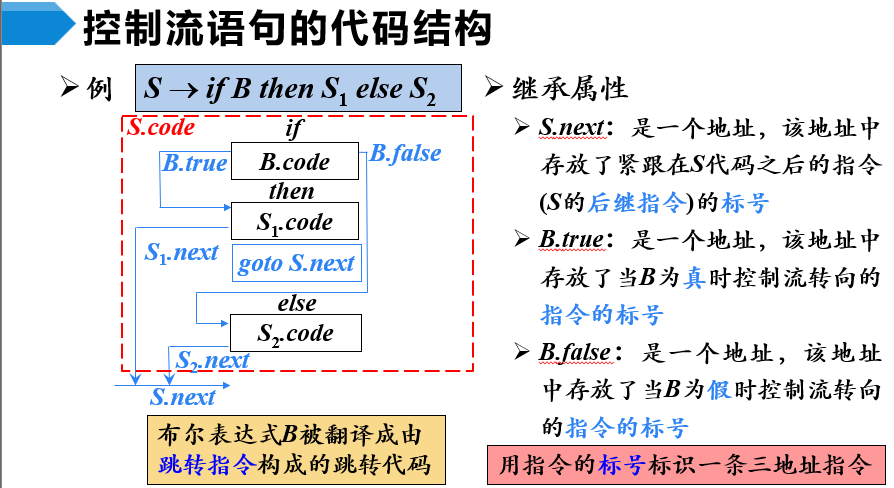
控制流语句
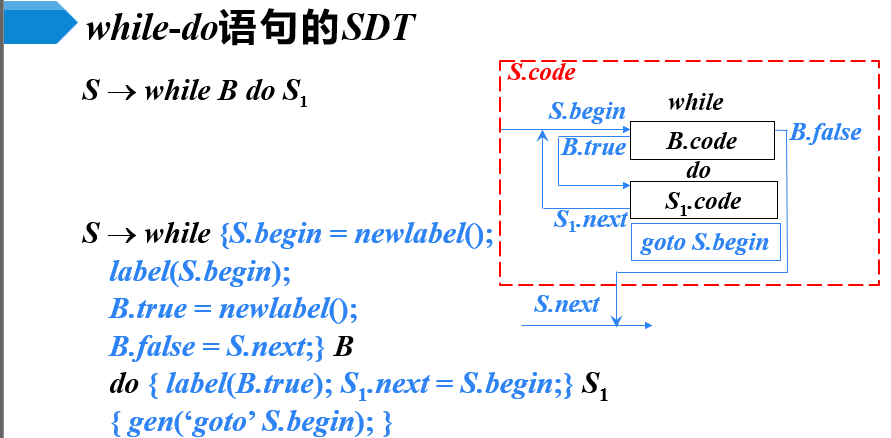
基本文法

代码结构
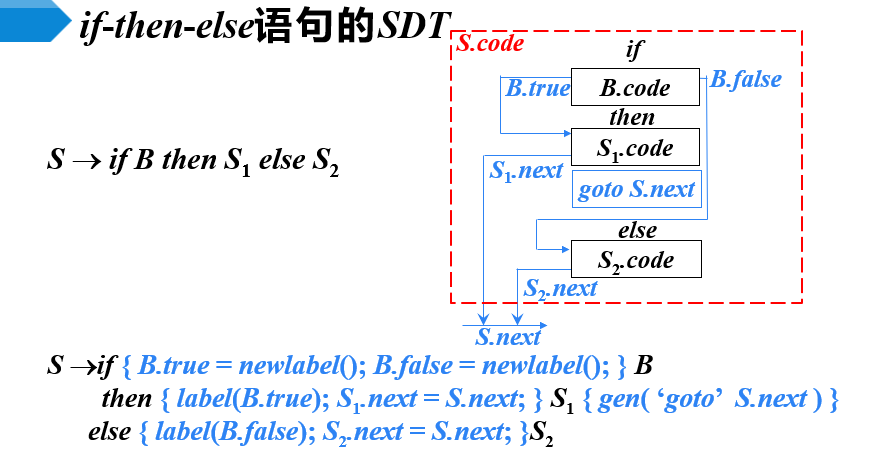
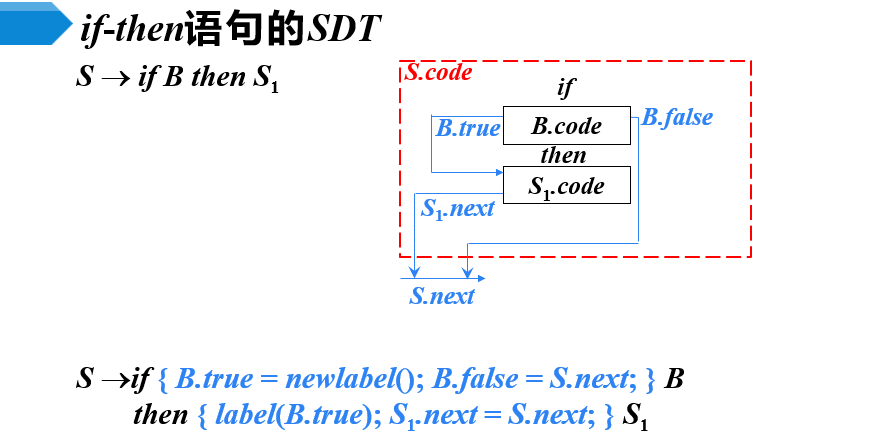
SDT

- newlabel( ): 生成一个用于存放标号的新的临时变量L,返回变量地址
- label(L): 将下一条三地址指令的标号赋给L
布尔表达式
基本文法
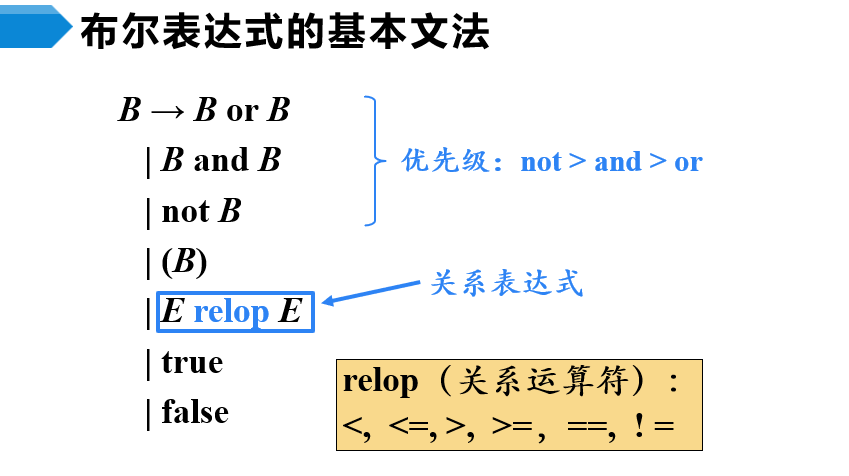
代码结构

SDT

- 对照上面的代码看

- 对照代码结构图看SDT
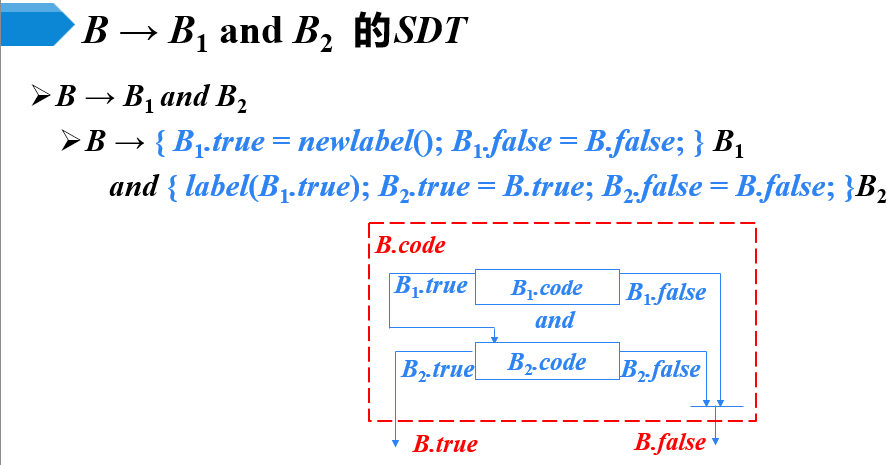
控制流语句的翻译
【例】SDT的通用翻译实现方法

- 该SDT的基础文法不是LL(1)文法,不能在自顶向下的语法分析中同时实现语义翻译
- 该SDT的产生式右部中又含有内嵌的语义动作,因此要想在自底向上的语法分析进行语义翻译,需要修改该文法,引入一些标记非终结符
- 任何SDT都可以通过下面的方法实现
- 首先建立一棵语法分析树,然后按照从左到右的深度优先顺序来执行这些动作
- 该SDT采用LR分析,为输入的语句构造语法分析树,后按照从左到右的深度优先顺序来执行这些该文法中的语义动作
【例】构造语法分析树
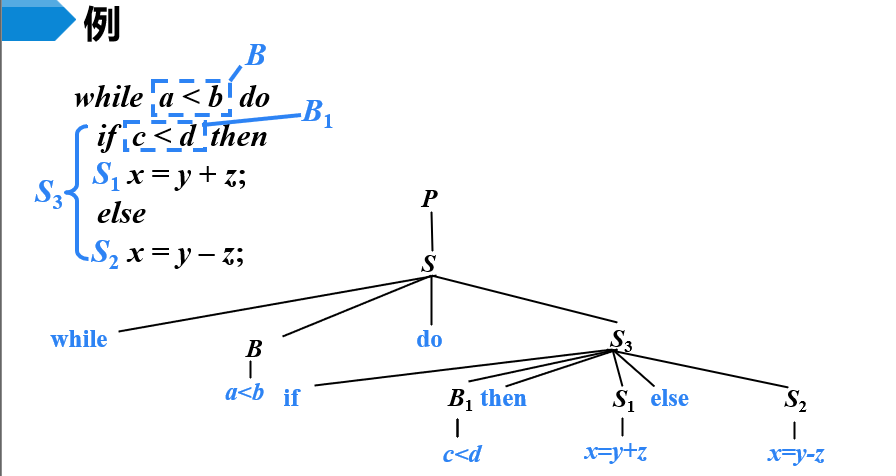
- 翻译给定的输入程序片段
- 分析树中各个节点对应的产生式如下
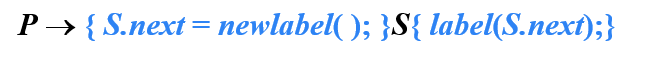
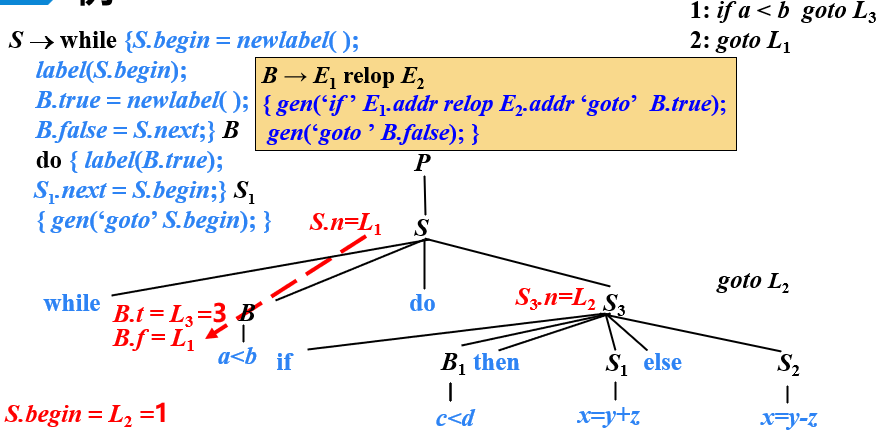
- 当S3分析完后,生成goto语句,跳转到S.begin,也就是L2,即下图的序号10指令

- L是用来存放标号变量的地址,自己定义的,随着程序的执行,每遇到新标号就+1
- 右上角,数字123……是自己定义的序号,表示指令,随着程序的执行,每遇到关系表达式或赋值语句,就生成跳转指令或三地址指令
- 最后,将标号L与地址对应,得到下图

-
右边是三地址指令对应的四元式形式
-
在为布尔表达式和控制流语句生成中间代码的过程中,最重要的是确定跳转指令的目标标号,但是在生成跳转指令的时候,目标标号还不能确定
-
为了解决这一问题,上面例题的解决方案,是将存放标号的地址作为继承属性,传递到跳转指令生成的地方,但是这样做,需要在最后将标号L与具体地址对应绑定起来
回填
-
为了解决在生成跳转指令的时候,目标标号还不能确定这一问题,可以采用回填技术
-
回填技术:把一个由跳转指令组成的列表以综合属性的形式进行传递
-
基本思想:
- 生成一个跳转指令时,暂时不指定该跳转指令的目标标号。这样的指令都被放入由跳转指令组成的列表中。同一个列表中的所有跳转指令具有相同的目标标号。等到能够确定正确的目标标号时,才去填充这些指令的目标标号
布尔表达式的回填
- 综合属性
B.truelist:指向一个包含跳转指令的列表,这些指令最终获得的目标标号就是当B为真时控制流应该转向的指令的标号B.falselist:指向一个包含跳转指令的列表,这些指令最终获得的目标标号就是当B为假时控制流应该转向的指令的标号
为了处理跳转指令,构造三个函数
- makelist( i )
- 创建一个只包含i的列表,i是跳转指令的标号,函数返回指向新创建的列表的指针
- merge( p1, p2 )
- 将 p1 和 p2 指向的列表进行合并,返回指向合并后的列表的指针
- backpatch( p, i )
- 将 i 作为目标标号插入到 p所指列表中的各指令中

_:有待回填- nextquad:下一条即将生成的指令的标号,在这里,也就是第一个gen中跳转指令的标号
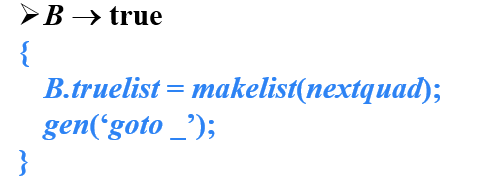
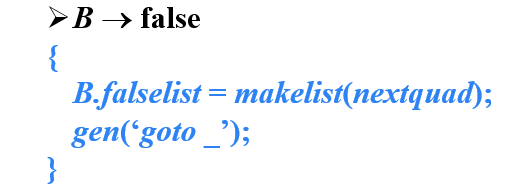
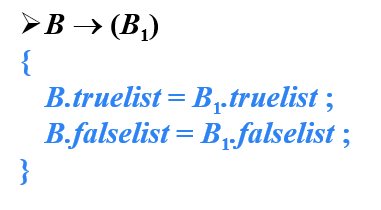
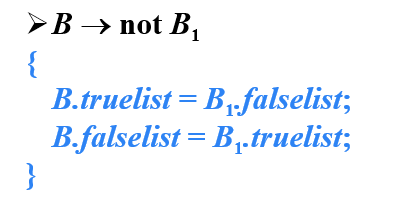

- 从翻译示意图中可以看出
- B1为真 ,B1的truelist中所有指令直接跳转到B为真
- B1为假,B1的falselist中所有指令还需跳转到B2继续判断
- 在分析B2之前,需要用B2的第一条指令的标号回填B1的falselist中所有指令,也可以记录下B2的第一条指令的标号,在归约的时候回填
- 为了记录B2的第一条指令的标号,在非终结符B之前插入标记一个非终结符M,与M关联的语义动作就是记录B2的第一条指令的标号
- M的综合属性quada记录下一条指令的标号,因为M放在B2之前,所有quada属性记录B2的第一条指令的标号
- 调用backpatch函数,用M.quad回填B1.falselist中所有指令
- 调用merge函数,将B1.truelist和B2.truelist合并,B.truelist指向合并后的指令列表

【例】布尔表达式的翻译

- 因为定义的都是综合属性,所以采用自底向上的分析,从左到右扫描字符串
- 将a<b归约为非终结符B
- 假设下一条指令从100开始编写


- and优先级高于or
- 将B and B归约B,并执行该产生式相关语义动作
- 用M.quad=104回填B1.truelist={102},也就是回填标号102的跳转指令
- B.truelist=B2.truelist={104}
- 将B1.falselist与B2.falselist合并后赋给B.falselist,即{103,105}
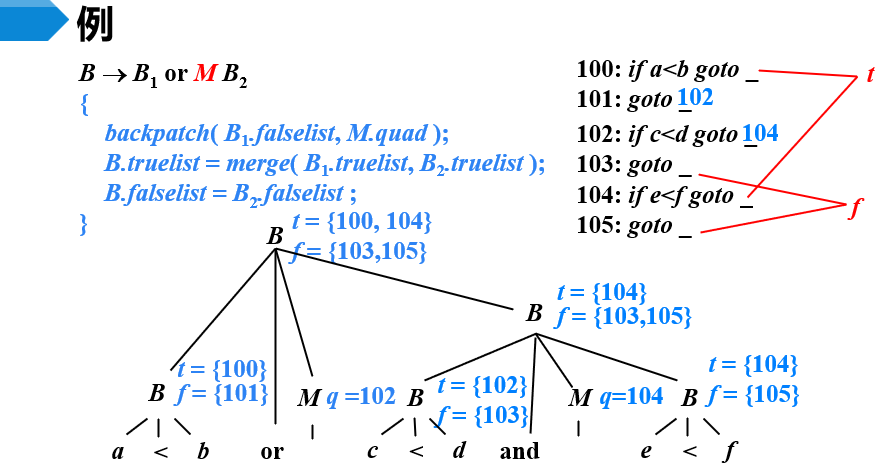
- 将B or B归约B,并执行该产生式相关语义动作
- 用M.quad回填B1.falselist
- 将B1.truelist与B2.truelist合并后赋给B.truelist,即{100,104}
- B.falselist=B2.falselist={103,105}
- 当B的真出口确定后,回填B.truelist
- 当B的假出口确定后,回填B.falselist
控制流语句的回填

- 综合属性
- S.nextlist:指向一个包含跳转指令的列表,这些指令最终获得的目标标号就是按照运行顺序紧跟在S代码之后的指令的标号
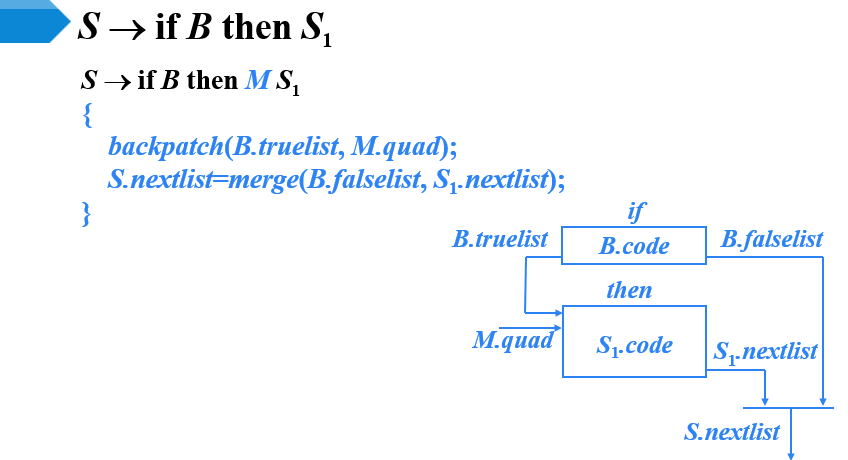

- 由图可知
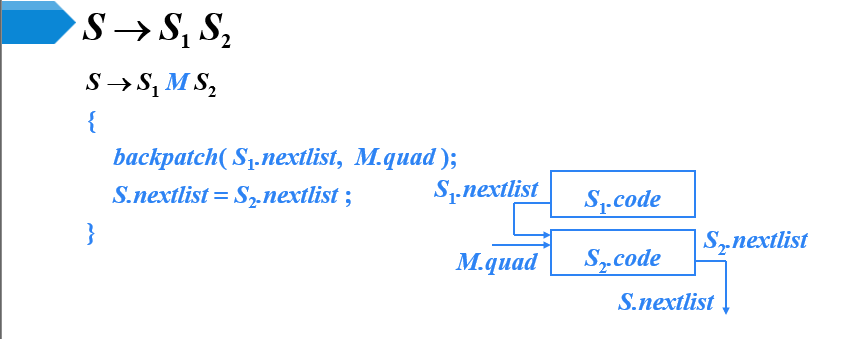
- 在S1执行完之后,要显式的生成一条跳转指令,跳转到S之后的第一条指令
- 要由S1的第一条指令的标号回填B.truelist,S2的第一条指令的标号回填B.falselist
- 在S1之后设置一个标记非终结符N,用来生成跳转指令
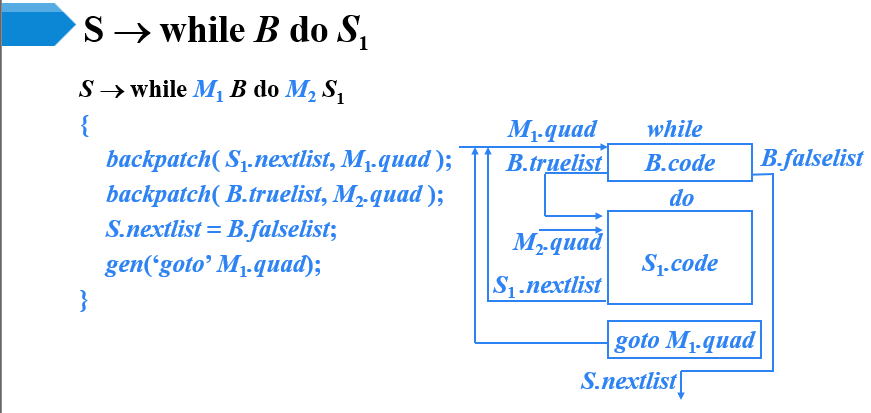
- 由翻译方案示意图可知
- 在S1执行完之后,要显式的生成一条跳转指令,跳转到WHILE语句的第一条指令
- 用B的第一条指令的标号回填S1.nextlist中的指令
- 用S1的第一条指令的标号回填B.truelist中的指令
- 用M1和M2分别记录B和S1的第一条指令的标号
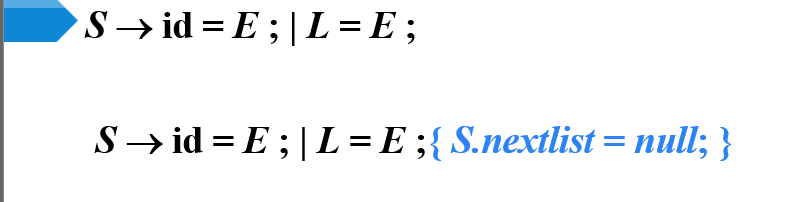
- 赋值语句不需要跳转,所以为空
【例】控制流语句的翻译
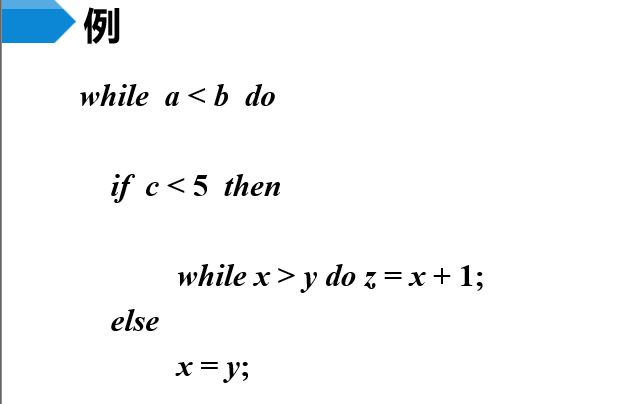
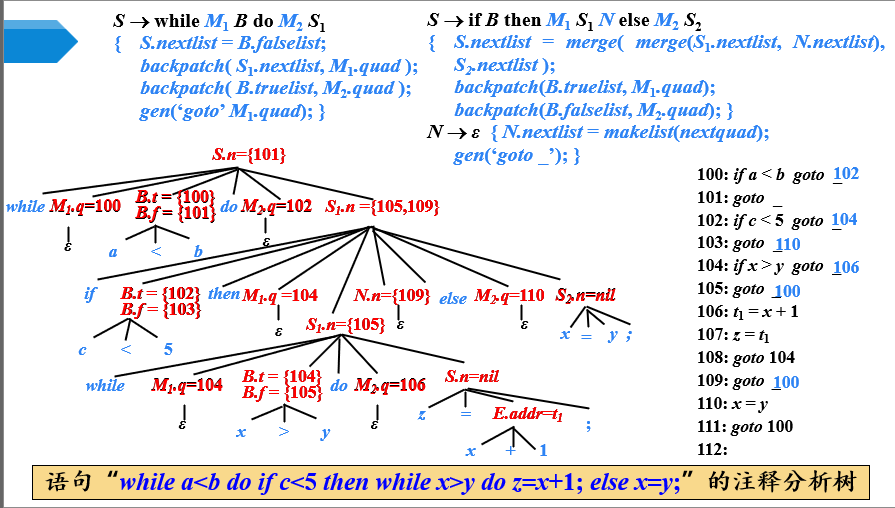
- 输入的控制流语句对应的注释分析树构造过程,可看视频讲解,方法与之前的布尔表达式大同小异,不同的是控制流语句是自顶向下分析
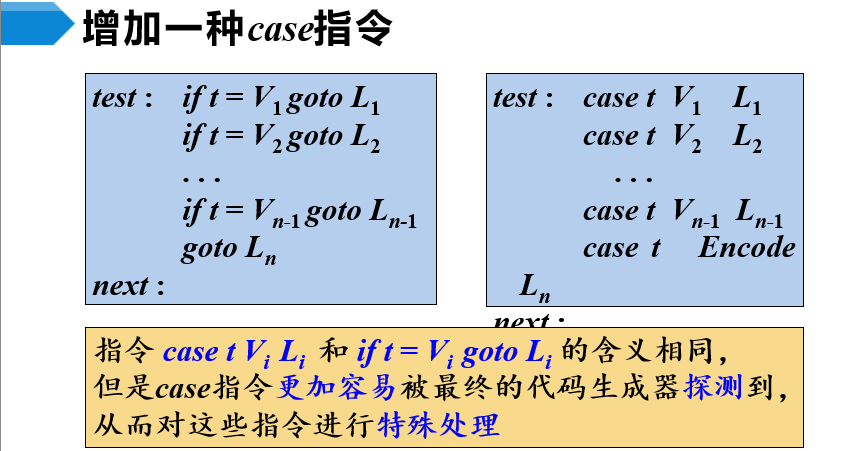
switch语句的翻译

- 从代码结构图可看出
- 将表达式E的值存到临时变量t中
- Ln-1是Sn.code中第一条指令的标号
- 在生成每个S的代码之后,要生成一条跳转指令,next是Sn的代码之后的第一条指令的标号,也就是整个switch语句之后的第一条指令的标号

- 根据代码结构图编写出switch语句的翻译方案


- 将分支测试指令集中在一起,提高代码执行效率
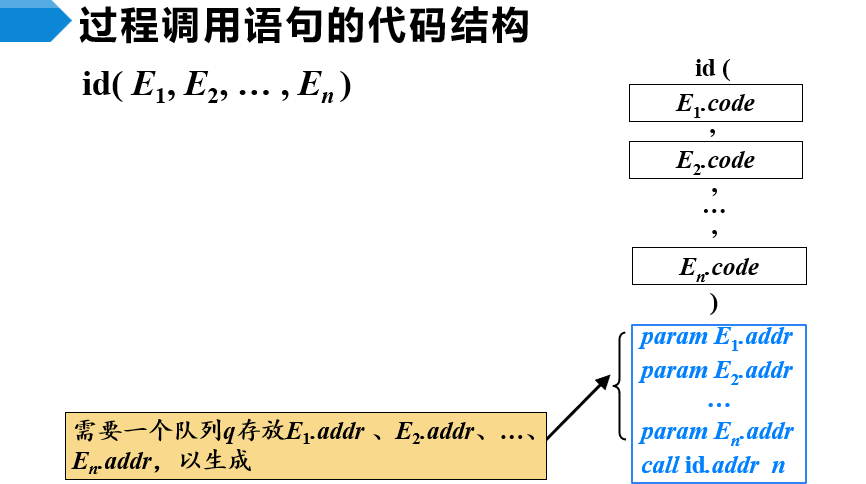
过程调用语句的翻译

- id是过程名,Elist是过程的参数表达式列表
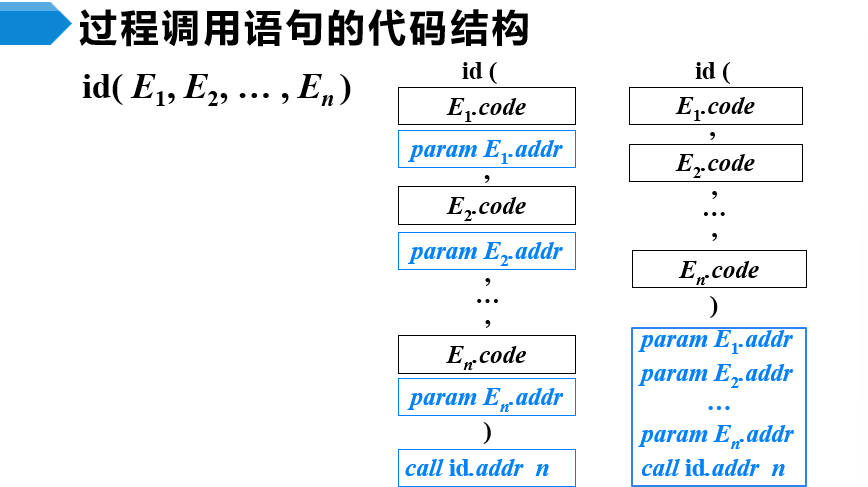
- 由参数表达式的代码构成,每一个表达式的值存放在非终结符Ei的address属性中,在生成各个表达式的代码之后,各生成一条param指令,将这些表达式的值设置为实参
- 可以将各个param指令集中在一起

【例】过程调用语句的翻译

- 过程名是f,有4个参数