图神经网络的可解释性是目前比较值得探索的方向,这篇综述论文针对近期提出的 GNN 解释技术进行了系统的总结和分析,归纳对比了该问题的解决思路。作者还为GNN解释性问题提供了标准的图数据集和评估指标,将是这一方向非常值得参考的一篇文章。
- 论文标题:Explainability in Graph Neural Networks: A Taxonomic Survey
- 论文地址:https://arxiv.org/pdf/2012.15445.pdf
图神经网络的解释性问题综述
摘要
在这篇论文中,作者对目前的GNN解释技术从统一和分类的角度进行了总结,阐明了现有方法的共性和差异,并为进一步的方法发展奠定了基础。此外,作者专门为GNN解释技术生成了基准图数据集,并总结了当前用于评估GNN解释技术的数据集和评估方法。
介绍
解释黑箱模型很重要
深层模型的解释技术大致分为两类:
- 依赖输入的解释方法
- 独立于输入的解释方法
这些研究只关注图像和文本领域的解释方法,而忽略了深度图模型的可解释性。
近年来,图神经网络很火,因为许多真实世界的数据都是用图来表示的。近年来,人们提出了几种解释 GNN 预测的方法,如XGNN[43]、gnexplainer[44]、PGExplainer[45]和subgraphx[46]等。这些方法是从不同的角度提供了不同层次的解释。但至今仍然缺乏标准的数据集和度量来评估解释结果。
本研究提供了对不同GNN解释技术的系统研究,论文贡献如下:
- 对现有的深度图模型的解释技术进行了系统和全面的回顾。
- 提出了现有GNN解释技术的新型分类框架,总结了每个类别的关键思想,并进行了深刻的分析。
- 详细介绍了每种GNN解释方法,包括其方法论、优势、缺点,与其他方法的区别。
- 总结了GNN解释任务中常用的数据集和评价指标,讨论了它们的局限性,并提出了几点建议。
- 通过将句子转换为图,针对文本领域构建了三个人类可理解的数据集。这些数据集即将公开,可以直接用于GNN解释任务。
- 我们为GNN解释研究开发了一个开源库。在这个库中,我们包含了几种现有技术的实现、常用的数据集和不同的评估指标。它可以用来复制现有的方法和发展新的GNN解释技术。
术语区分:‘’Explainability‘’ 与 ‘’Interpretability‘’
interpretable:能够对其预测提供人类可理解的解释的模型(决策树模型)
explainable:该模型仍然是一个黑盒子,其预测有可能被一些事后解释技术所理解
面对的挑战
- 图包含重要的拓扑信息,并用特征矩阵和邻接矩阵表示。
- 对图数据的结构信息的研究更为重要
- 对数据集的了解很重要
分类的综述
解释方法一般都会从几个问题出发实现对图模型的解释:
- 哪些输入边更重要?
- 哪些输入节点更重要?
- 哪些节点特征更重要?
- 什么样的图模式会最大限度地预测某个类?
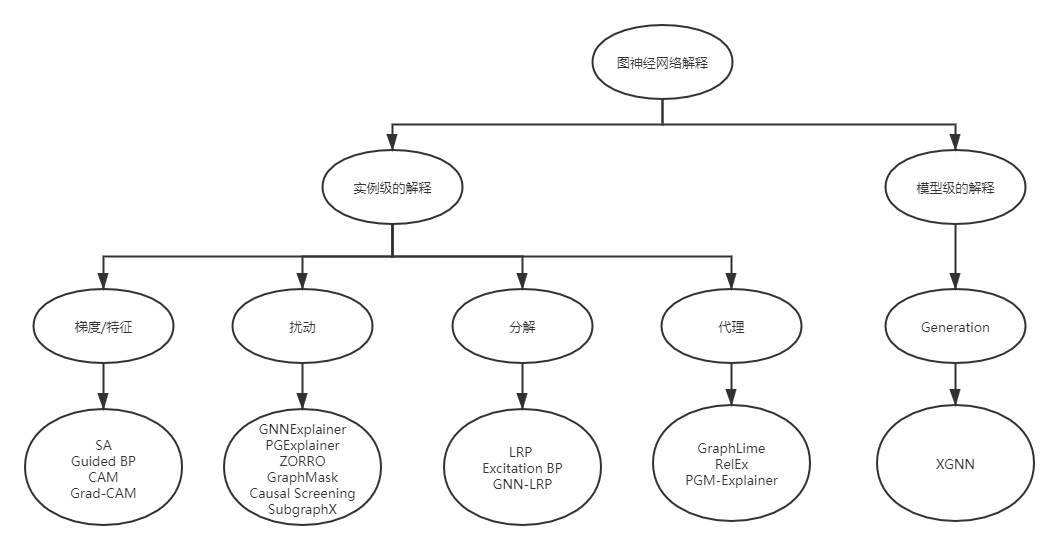
实例级方法与特征工程的思想有些类似,旨在找到输入数据中最能够影响预测结果的部分特征,为每个输入图提供 依赖输入 的解释。给定一个输入图,**实例级方法旨在探究影响模型预测的重要特征实现对深度模型的解释。**根据特征重要性分数的获得方式,作者将实例级方法分为四个不同的分支:
- 基于梯度/特征的方法[52],[53],采用梯度或特征值来表示不同输入特征的重要程度
- 基于扰动的方法[44],[45],[46],[54],[55],[56],监测在不同输入扰动下预测值的变化,从而学习输入特征的重要性分数。
- 基于分解的方法[52],[53],[57],[58],首先将预测分数,如预测概率,分解到最后一个隐藏层的神经元。然后将这样的分数逐层反向传播,直到输入空间,并将分解分数作为重要性分数。
- 基于代理的方法[59],[60],[61],首先从给定例子的邻居中抽取一个数据集的样本。接下来对采样的数据集合拟合一个简单且可解释的模型,如决策树。通过解释代理模型实现对原始预测的解释。
模型级方法直接解释图神经网络的模型,不考虑任何具体的输入实例。这种 独立于输入 的解释是高层次的,能够解释一般性行为。与实例级方法相比,这个方向的探索还比较少。现有的模型级方法只有XGNN[43],它是基于图生成的,通过生成 图模式 使某一类的预测概率最大化,并利用 图模式 来解释这一类。
实例级方法的解释是基于真实的输入实例的,因此它们很容易理解。然而,对模型级方法的解释可能不便于人类理解,因为获得的图模式可能在现实世界中甚至不存在。
实例级解释
基于代理的方法(Surrogate Methods)
代理方法能够为图像模型提供实例级解释。其**基本思想是化繁为简,既然无法解释原始深度图模型,那么采用一个简单且可解释的代理模型来近似复杂的深层模型,实现输入实例的邻近区域预测。**需要注意的是,这些方法都是假设输入实例的邻近区域的关系不那么复杂,可以被一个较简单的代理模型很好地捕获。然后通过可解释的代理模型的来解释原始预测。将代理方法应用到图域是一个挑战,因为图数据是离散的,包含拓扑信息。那么 如何定义输入图的相邻区域,以及什么样的可解释代理模型是合适的,都是不清楚的。
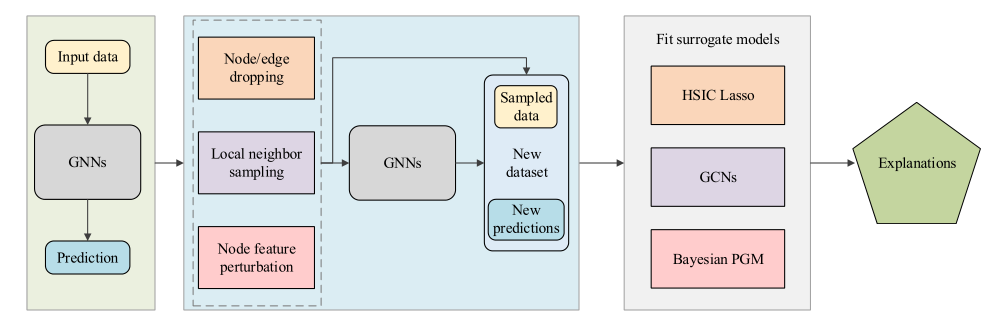
代理方法的一般框架:给定一个输入图及其预测,目的是解释给定输入图的预测。方法是它们首先对一个局部数据集进行采样,(这个局部数据集包含多个相邻数据对象及其预测);然后拟合一个可解释模型来学习局部数据集,(不同的代理方法拟合不同的可解释模型);最后,将可解释模型的解释视为原始深度模型对输入图的解释。
不同的代理方法的关键区别在于两个方面:
- 如何获得局部数据集
- 选择什么代理模型
GraphLime
GraphLime[59]将LIME[69]算法扩展到深度图模型,并研究不同节点特征对节点分类任务的重要性。
给定输入图中的一个目标节点,将其N-hop 邻居节点及其预测值视为局部数据集,其中N的合理设置是训练的GNN的层数。然后采用非线性代理模型HSIC Lasso[70]来拟合局部数据集。根据HSIC Lasso中不同特征的权重,可以选择重要的特征来解释HSIC Lasso的预测结果。这些被选取的特征被认为是对原始GNN预测的解释。
但是,GraphLime只能提供节点特征的解释,却忽略了节点和边等图结构,而这些图结构对于图数据来说更为重要。另外,GraphLime是为了解释节点分类预测而提出的,但不能直接应用于图分类模型。
- 局部数据集:目标节点的 N-hop 邻居节点及其预测值
- 代理模型:HSIC Lasso
- 代理模型的解释方法:根据重要的特征来解释结果
- 缺陷:
- 只能提供节点特征的解释,忽略了节点和边等图结构。
- 只能用于解释节点分类预测,不能直接应用于图分类模型。
RelEx
RelEx[60]结合代理和扰动的思想,研究节点分类模型的可解释性。
在给定一个目标节点及其计算图(N-hop邻居节点)的情况下,它首先从计算图中随机采样连接的子图,并将这些子图反馈给训练好的GNN,从而获得一个局部数据集。具体地说,它从目标节点开始,以BFS的方式随机选择相邻节点。RelEx采用GCN模型作为代理模型来拟合局部数据集。与GraphLime不同,RelEx中的代理模型是不可解释的。训练后,它进一步应用基于扰动的方法,如生成Sigmoid掩码或Gumbel-Softmax掩码来解释预测结果。与GraphLime相比,它可以提供关于重要节点的解释
RelEx的解释过程包含了多个近似步骤,比如使用代理模型来近似局部关系,使用掩码来近似边的重要性,从而使得解释的说服力和可信度较差。此外,由于可以直接采用基于扰动的方法来解释原有的深度图模型,因此没有必要再建立一个不可解释的深度模型作为代理模型来解释。RelEx如何应用于图分类模型也是未知的。
- 局部数据集:随机采样目标节点的 N-hop 邻居节点及其预测值
- 代理模型:GCN
- 代理模型的解释方法:根据Sigmoid掩码或Gumbel-Softmax掩码来解释结果
- 缺陷:
- 解释过程包含了多个近似步骤,说服力和可信度较差。
- 可以直接采用扰动的方法来解释模型,没有必要用一个不可解释的代理模型来解释。
- 只能用于解释节点分类预测,不能直接应用于图分类模型。
PGM-Explainer
PGM-Explainer[58]建立了一个概率图模型,为GNN提供实例级解释。
局部数据集是通过随机节点特征扰动获得的。具体来说,给定一个输入图,每次PGM-Explainer都会随机扰动计算图中几个随机节点的节点特征。然后对于计算图中的任何一个节点,PGM-Explainer都会记录一个随机变量,表示其特征是否受到扰动,及其对GNN预测的影响。通过多次重复这样的过程,就可以得到一个局部数据集。通过Grow-Shrink(GS)算法[66]选择依赖性最强的变量来减小局部数据集的大小。最后采用可解释的贝叶斯网络来拟合局部数据集,并解释原始GNN模型的预测。
PGM-Explainer可以提供有关图节点的解释,但忽略了包含重要图拓扑信息的边。此外,与GraphLime和RelEx不同的是,PGM-Explainer可以同时用于解释节点分类和图分类任务。
- 局部数据集:通过随机节点特征扰动和Grow-Shrink算法过滤获得
- 代理模型:贝叶斯网络
- 代理模型的解释方法:概率图
- 缺陷:忽略了包含重要图拓扑信息的边