GraphLime将LIME算法扩展到深度图模型,并研究不同节点特征对节点分类任务的重要性。
- 论文标题:GraphLIME: Local Interpretable Model Explanations for Graph Neural Networks
- 论文地址:https://arxiv.org/pdf/2001.06216.pdf
GraphLIME实验
实验目的
研究GraphLIME的有效性。
首先,研究GraphLIME能否过滤无用的特征并选择有用的特征作为解释。
其次,研究GraphLIME的解释能否帮助用户确定预测是否可信。
最后,研究GraphLIME的解释能否帮助用户选择更好的分类器。
实验方案
验证GraphLIME对特征的过滤能力
与其他解释器做对比实验
首先,我们在每个样本的特征向量中人工随机添加10个“噪声”特征。
然后,我们训练出GraphSAGE模型或GAT模型,让其测试准确率均在80%以上。因此,我们获得了训练模型的无用特征集(10个“噪声特征”)。
最后,我们对每个解释框架的200个测试样本进行了解释,并根据样本在不同数量噪声特征上的频率分布来比较它们的性能。
我们利用核密度估计(KDE)在Cora和Pubmed上绘制5种不同解释框架下,样本在不同数量噪声特征上的频率分布,并使用高斯核拟合分布的形状,以比较5种框架去噪数据的能力。
验证GraphLIME对预测的判断能力
与其他解释器做对比实验
首先,我们随机选取30%的特征作为“不可信”特征。然后,对GraphSAGE或GAT分类器进行训练,得到对测试样本的预测结果。我们假设用户可以识别出这些“不值得信任”的特征,并且他们不会想要这些特征作为解释。
然后,我们开发了甲骨文的“可信度”。如果在从样本中移除那些“不可信”特征后,预测发生变化(因为这意味着预测主要由那些“不可信”特征决定),则将分类器的预测标记为“不可信”,否则就是“可信赖”。我们把“可信度”作为判断预测是否可信的真实标签。
其次,对于GraphLIME和LIME,我们假设当删除解释中出现的所有“不可信”特征时,另一个近似线性模型所做的预测发生变化,则模拟用户会认为来自分类器的预测是“不可信的”。对于GNNexplexer、贪婪和随机解释器,如果他们的解释中出现了任何“不值得信任”的特征,用户就会认为这个预测是不可信的。
最后,我们将模拟用户的决策与Oracle的“可信性”理论进行了比较。
我们将所选特征的数量设置为K=10,15,20,25,并报告了100轮以上每个解释框架的可信度预测的平均F1得分。
验证GraphLIME对模型的判断能力
与其他解释器做对比实验
在最后的模拟用户实验中,我们探索解释框架是否可以用于模型选择,并指导用户在两个不同的GNN分类器中选择更好的分类器。
首先,我们人为地在数据中添加了10个噪声特征,并将它们标记为不可信的特征。我们通过重复训练GraphSAGE和GAT模型来生成分类器,直到它们的训练准确率和测试准确率都在70%以上,并且它们的测试准确率的差异超过5%。
然后,我们对这两个分类器的样本进行解释,并记录这两个分类器样本的解释中出现的不可信特征的数量。请注意,较好的分类器在其解释中应该具有较少的不可信特征;因此,我们选择不可信特征较少的分类器作为较好的分类器,并将此选择与真正具有较高测试准确率的分类器进行比较。
实验结果
GraphLIME能够过滤图数据中的无用特征并选择有用的特征作为解释
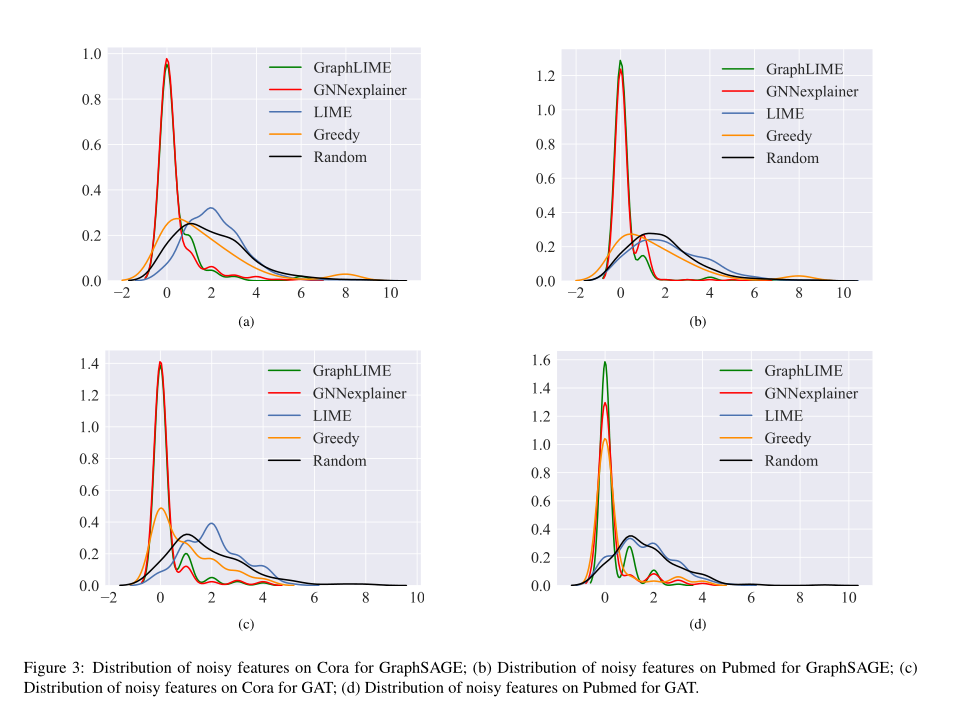
由上图可分析得到:
- 本文提出的框架GraphLIME和gnexplainer选择的噪声特征在数量上小于其他解释框架选择的噪声特征数量。
- 对于GraphLIME和gnexplainer,在选择不同数量的噪声特征时,样本的频率在0左右。这意味着GraphLIME和gnnexplain框架很少选择无用的特性作为解释,这在图形数据有大量噪声时非常有用。
- LIME不能忽略噪声特征,LIME的分布主要在1 - 4左右。对于随机过程,其频率分布与LIME相似。Greedy解释程序只是比LIME和Random稍微好一点,但不能与GraphLIME和gnexplainer相比。
结果表明,当GNN模型的图数据包含大量的噪声特征(无用特征)时,该框架可以对图数据进行去噪,并且更有能力找到有用的特征作为解释。
GraphLIME的解释既实现了高准确率又实现了高召回率
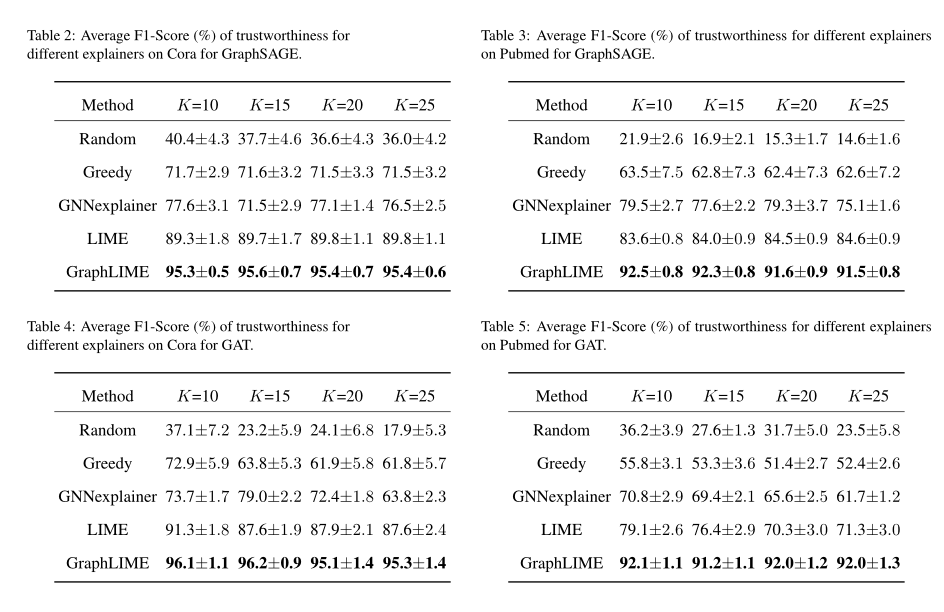
结果表明,在这两个数据集上,GraphLIME优于其他解释方法。其他解释方法的F1分较低表明它们达到了较低的准确率(即相信太多的预测)或较低的召回率(即对预测的不信任程度超过了应有的水平),而GraphLIME框架的较高的F1分表明它既实现了高准确率又实现了高召回率。
GraphLIME的解释能够选择性能更优的模型
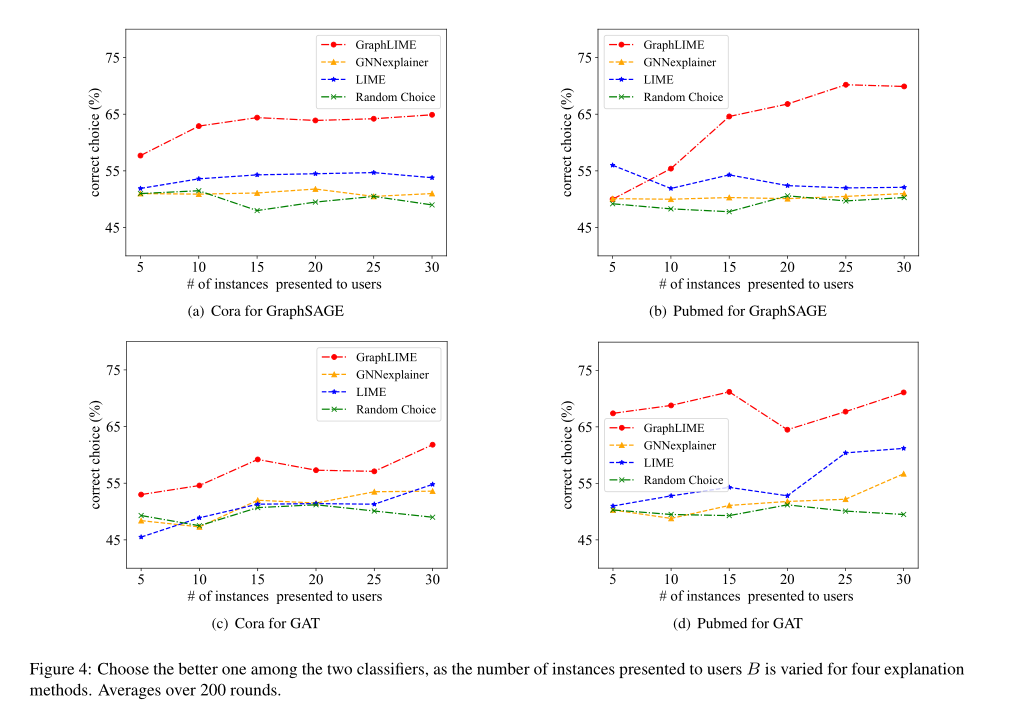
上图给出了当样本数量在5到30之间变化时,不同解释框架选择更好分类器的准确性,平均超过200轮。
结果表明,GraphLIME方法可以用于模型选择,并且其性能优于其他解释框架。
值得注意的是,GraphLIME的性能会随着呈现实例数量的增加而提高。
数据集
此实验只用了真实数据集,没有使用合成数据集。
两个出版物数据集:
- CORA
- Pubmed
总结
本实验在两种GNN模型的两个真实图形数据集上证明了GraphLIME的有效性。
它可以过滤无用特征,选择有用特征,指导用户确定预测的信任度,帮助用户识别更好的分类器。
2021.8.21 by YI