记录网络表示学习方面的一些基础知识
表示学习
-
表示学习是一种对于数据广义的特征表示
-
数据 特征表示 网络结构 邻接矩阵 列表结构 链表 文本 TF-IDF 图像 SIFT
TF-IDF(term frequency–inverse document frequency)是一种用于信息检索与数据挖掘的常用加权技术。TF是词频(Term Frequency),IDF是逆文本频率指数(Inverse Document Frequency)
SIFT,即尺度不变特征变换(Scale-invariant feature transform,SIFT),是用于图像处理领域的一种描述。这种描述具有尺度不变性,可在图像中检测出关键点,是一种局部特征描述子。
-
分布式表示
- 与分布式表示相对应的为离散表示。离散的表示方法侧重于对每个对象进行单独建模。比如star和sun的离散式表示如图2,由于只有在该位置出现的地方为1,其他维度都为0,因此star和sun的语义尽管有些相近,但计算相似度时仍然为0。
- 分布式表示是基于通过与他周围同时出现的词来表示它。比如拿‘’银行‘’举例,经常与它一同出现的词为“政府、借贷、存款”等,这样一来两个相似的词就不会出现相似度完全为0的情况。比如star和sun的分布式表示如图3。分布式表示相比于离散的表示方法有如下优点:维度大大减小,语义信息相对保留。

网络结构(图结构)
-
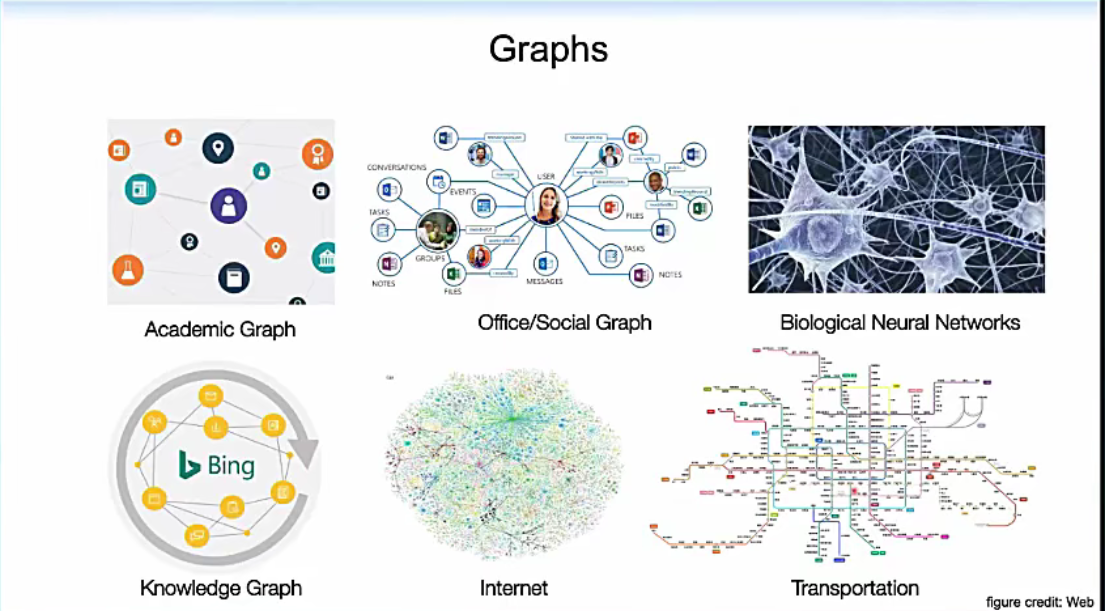
什么是网络结构
-
对于网络结构表示的复杂关系,我们比较关心图结构中的节点分类、预测、节点间关系等问题。
-
如何解决上述问题:对于一个输入的图结构,借助深度学习技术进行复杂的结构化特征抽取,形成一个结构化的特征矩阵,最后将这个特征矩阵输入机器学习或者数据挖掘算法当中,从而解决我们所关心的节点分类预测等问题。
深度学习中的特征提取是在隐空间上,大多数情况下人类并知道每一维代表的意思
-
应用:可以描述现实世界中的复杂关系
1.学术网络
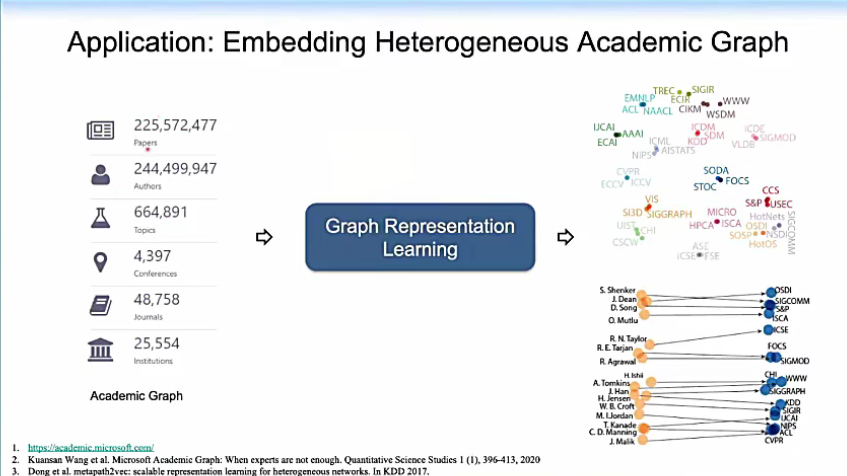
我们可以把被检索的两亿多篇文章、两亿多位学者、四千多场会议、四万多篇期刊的这个异构的学术网络输入到网络表示学习算法当中,生成它的节点表示。有了节点表示,我们就可以进行许多下游的任务。
例如相似性搜索和推理。
比如我们关心与Nature这个期刊最相似的期刊有什么,相似性搜索结果是Proceedings of the National Academy of Sciences和 Nature Communications;我们关心与哈佛大学在学术上接近的学术机构有哪些,相似性搜索结果如图所示

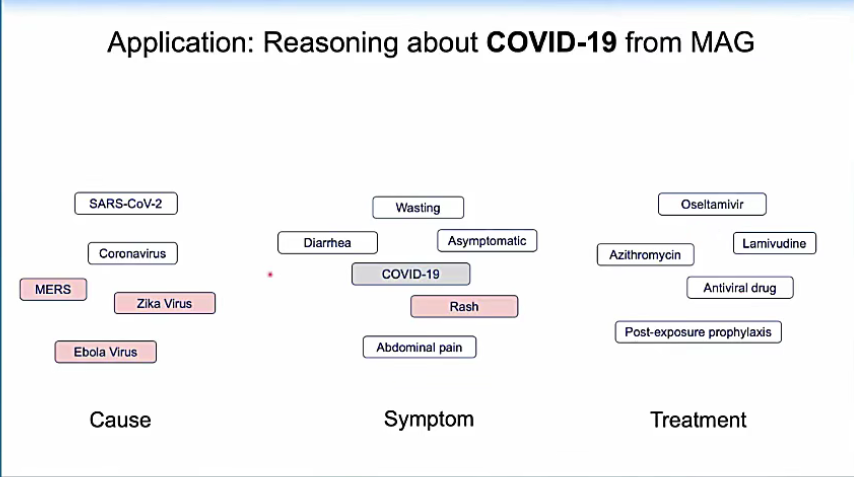
比如我们关心新馆肺炎,我们可以从所有与新馆肺炎有关的学术文章中的数据推理出新馆肺炎的症状、起因、治疗方法
网络表示学习(Network Representation Learing)
-
又名 网络嵌入(Network Embedding)、图嵌入(Graph Embedding)
-
网络表示学习是表示学习技术的一个子集
-
网络表示学习是对于网络结构中的节点的一种分布式表示方案
-
该方案旨在将网络中的节点表示成低维、实值、稠密的向量形式
-
应用:将节点表示成向量形式可以在向量空间中具有表示以及推理的能力,同时可轻松方便的作为机器学习模型的输入,进而可将得到的向量表示运用到社交网络中常见的应用中,如可视化任务、节点分类任务、链接预测等任务,还可以作为社交边信息应用到推荐系统等其他常见任务中
网络表示学习方法的分类
-
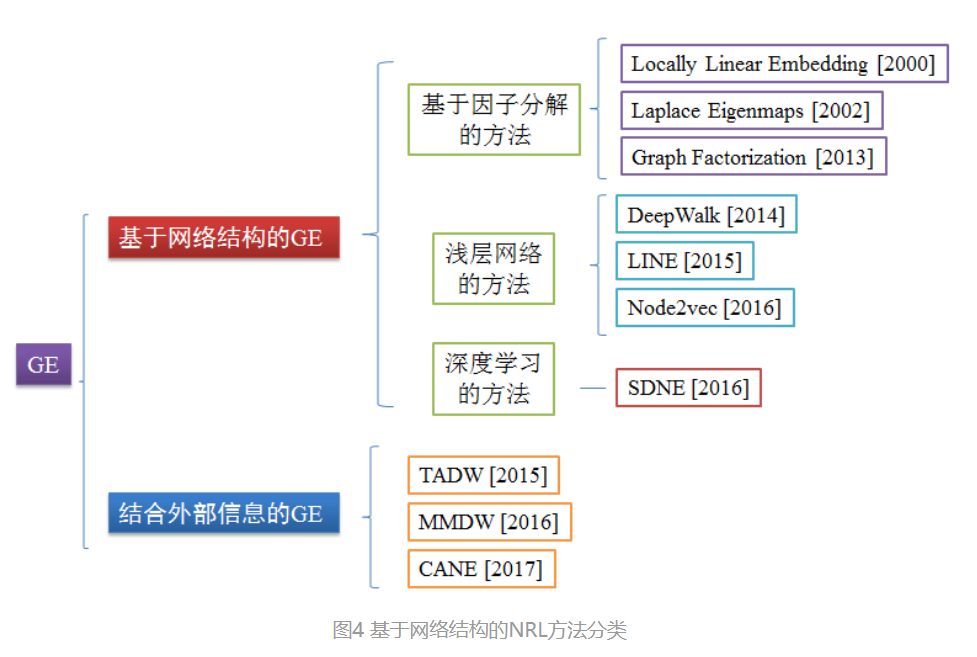
分类图
-
图4的分类方法中,主要侧重在于基于网络结构的方法,又可进一步分为基于分解的方法、浅层网络的方法和深度学习的方法。另外结合外部信息的方法在这主要是介绍结合丰富的文本信息以及借鉴自然语言处理领域的经典模型等。接下来主要以此为框架来分别对代表性方法进行介绍。
1. Locally Linear Embedding
2. Laplace Eigenmaps
3. Graph Factorization
4. Deepwalk
Word2vec,是一群用来产生词向量的相关模型。
word2vec模型可用来映射每个词到一个向量,可用来表示词对词之间的关系,该向量为神经网络之隐藏层。
Word2Vec模型中,主要有Skip-Gram和CBOW两种模型,从直观上理解,Skip-Gram是给定input word来预测上下文。而CBOW是给定上下文,来预测input word。
节点链输入word2vec后就能得到节点链上每个节点的节点表示
-
哈里斯分布假设

在自然语言中,两个单词如果经常在相同的语境下出现。他认为这两个单词应该具有相似的意义
在网络结构中,如果两个节点经常在相似的结构中出现,我们认为这两个节点应该具有相似的意义。
在deepwalk中,相似的结构是通过在网络结构中随机游走来生成节点链来捕捉
5. LINE
-
Deepwalk是根据节点之间的连边进行随机游走,继而产生节点序列,因此只考虑了节点的一阶近邻。实际上网络中的一阶近邻是非常稀疏的,因此LINE认为应该考虑更多的近邻来丰富节点的表示。其中,二阶近邻就是看两个节点的共同邻居,共同邻居数越多,两个节点的二阶邻近度越高。
-
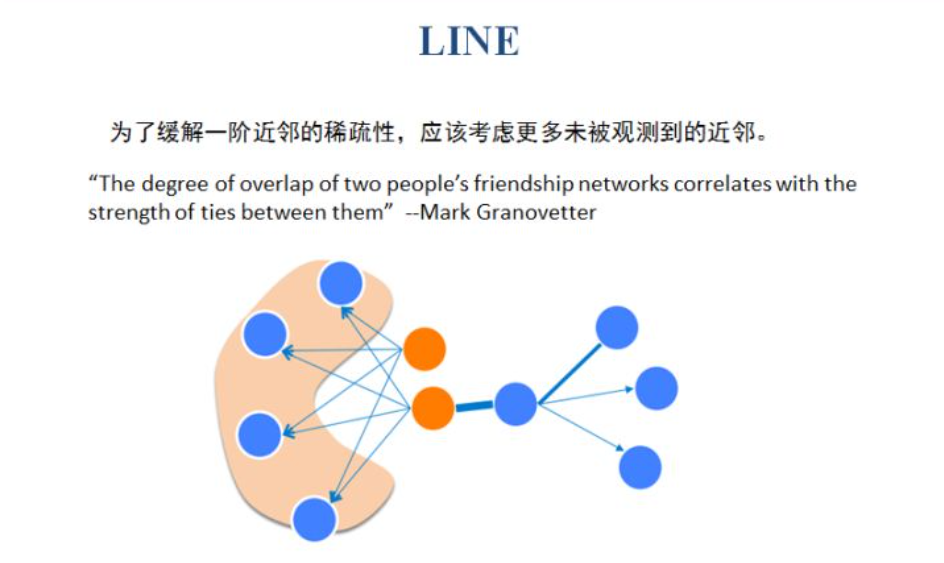
-
6. Node2vec
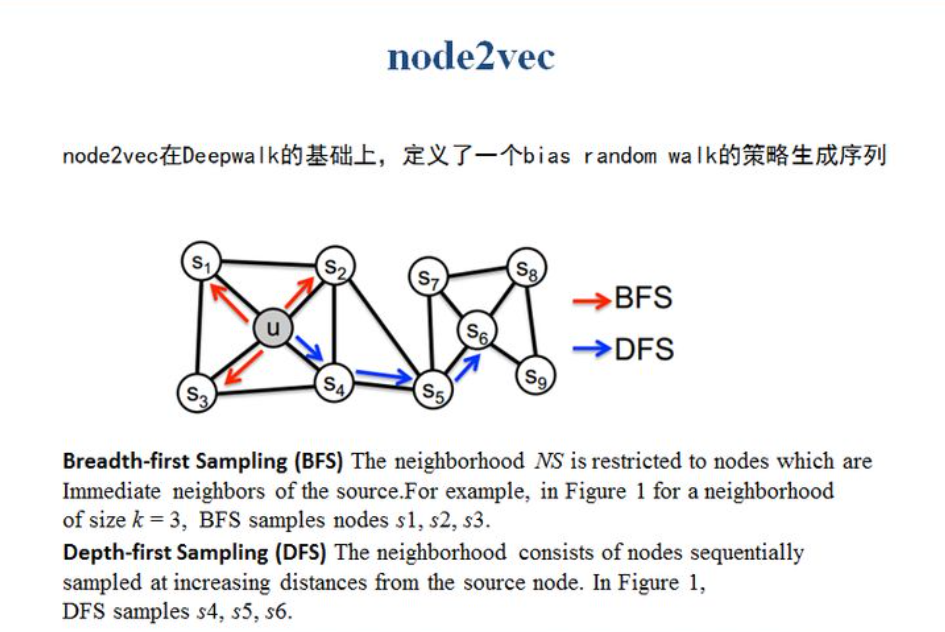
Deepwalk中的随机游走策略是完全随机的,node2vec认为我们应该保证网络结构中的结构等价性与同质性,因此分别对应于宽度优先搜索与广度优先搜索。所以定义了一个偏置参数来控制模型更倾向于BFS还是DFS。
同时将邻居节点分成了三类,假设节点已经从t节点到达了v节点,那么对于v节点的下一跳有4种选择,分别是再次回到t节点、访问x1、x2、x3中任意一个节点,由于x2,x3都距离t节点的跳数为2,因此属于一种情况,因此即使4种选择,但是3类情况。所以如果序列为(t-v-t),则表示节点返回到t的概率;如果序列为(t-v-x1),则表示节点进行宽度优先搜索的概率;如果序列为(t-v-x2或者t-v-x3),则表示节点进行广度优先搜索的概率。因此p参数用来控制模型是否更倾向于返回重新访问已经访问的节点概率,q参数用来控制模型更倾向于进行广度还是深度优先搜索的概率。
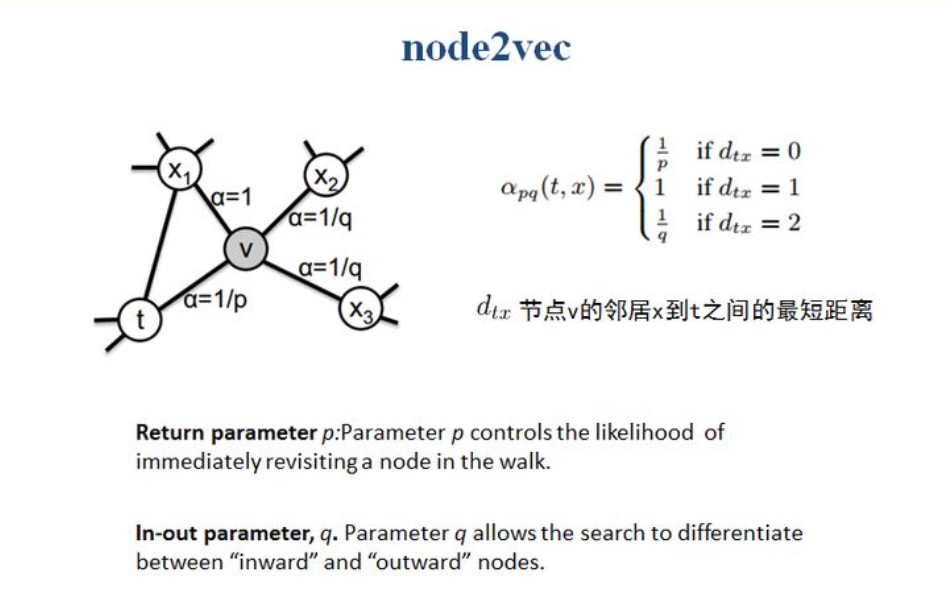
理解:基于网络中的三角形结构进行随机游走
-
7. SDNE
上述介绍的模型虽然可以学到网络中的节点表示,但大部分都是基于线性的表示,或者浅层神经网络的表示。往往现实世界中的节点之间存在着千丝万缕的非线性的关系,因此SDNE认为我们应该利用深度学习模型来捕捉节点间高度的非线性关系。因此SDNE通过无监督学习方法autoencoder来自动捕捉节点的局部关系,通过将节点的二阶近邻来作为输入,进而学习二阶近邻的低维表示。同时将Laplacian Eigenmaps作为autoencoder之后的输入,来保证两个节点之间的一阶邻近关系,以此来保护网络的全局的结构信息。
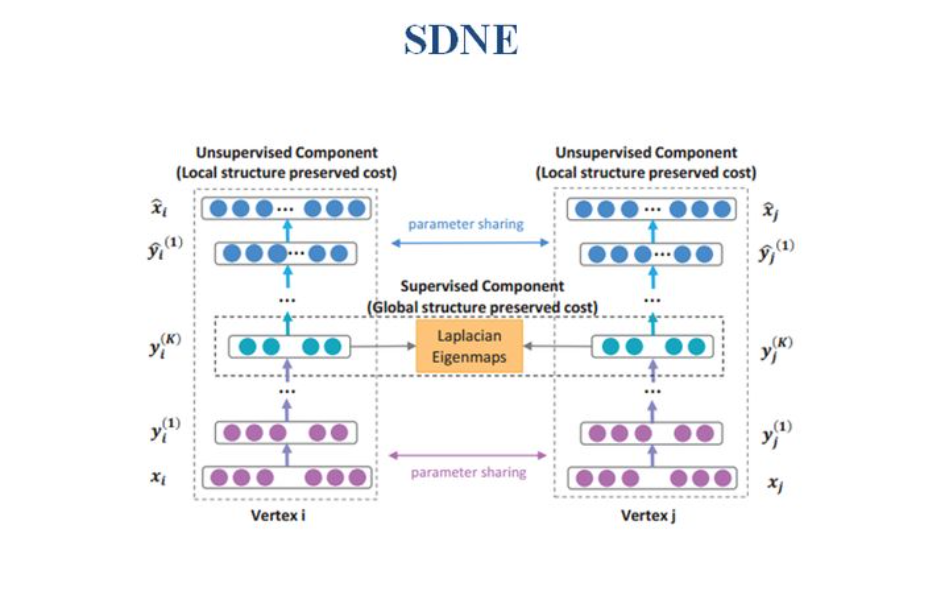
-
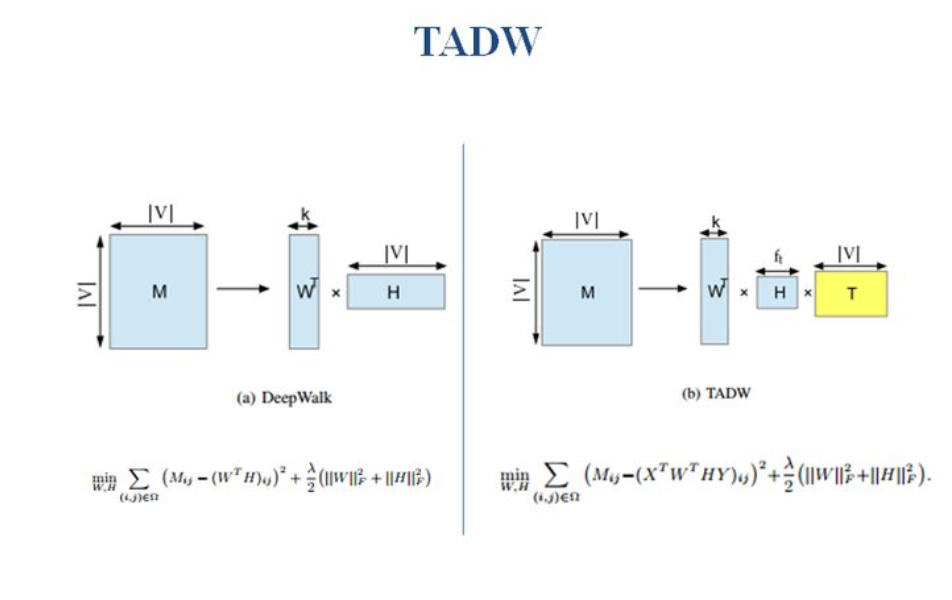
8. TADW
Deepwalk只是考虑了网络中的结构属性,往往在现实世界中节点存在丰富的文本信息,因此TADW认为我们在对于节点进行表示的过程中,不仅要考虑网络的结构信息,还应利用节点产生的文本信息。因此它在矩阵分解的基础上,通过将邻接矩阵进行分解,同时用节点的文本表示矩阵来进行约束,以此来缓解网络结构的稀疏问题。
常用包库
1、DeepWalk
论文提出作者实现的python版deepwalk方法,支持两种图存储结构输入。
2、OpenNE
清华刘知远团队总结实现的GE方法集合,包括deepwalk,node2vec等常见GE方法。
3、GEM
实现了一些经典的GE方法集合,包括LE,LLE,GF,HOPE,SDNE等GE方法,同时存在配套综述论文。
参考文献
【北京智源大会2020】 图表示学习 (图嵌入,图卷积,图预训练)_哔哩哔哩_bilibili