本文转载自:小林coding
硬件结构
CPU是如何执行程序的?
代码写了那么多,你知道 a = 1 + 2 这条代码是怎么被 CPU 执行的吗?
软件用了那么多,你知道软件的 32 位和 64 位之间的区别吗?32 位的操作系统可以运行在 64 位的电脑上吗?64 位的操作系统可以运行在 32 位的电脑上吗?如果不行,原因是什么?
CPU 看了那么多,我们都知道 CPU 通常分为 32 位和 64 位,你知道 64 位相比 32 位 CPU 的优势在哪吗?64 位 CPU 的计算性能一定比 32 位 CPU 高很多吗?
不知道也不用慌张,接下来就循序渐进的、一层一层的攻破这些问题。
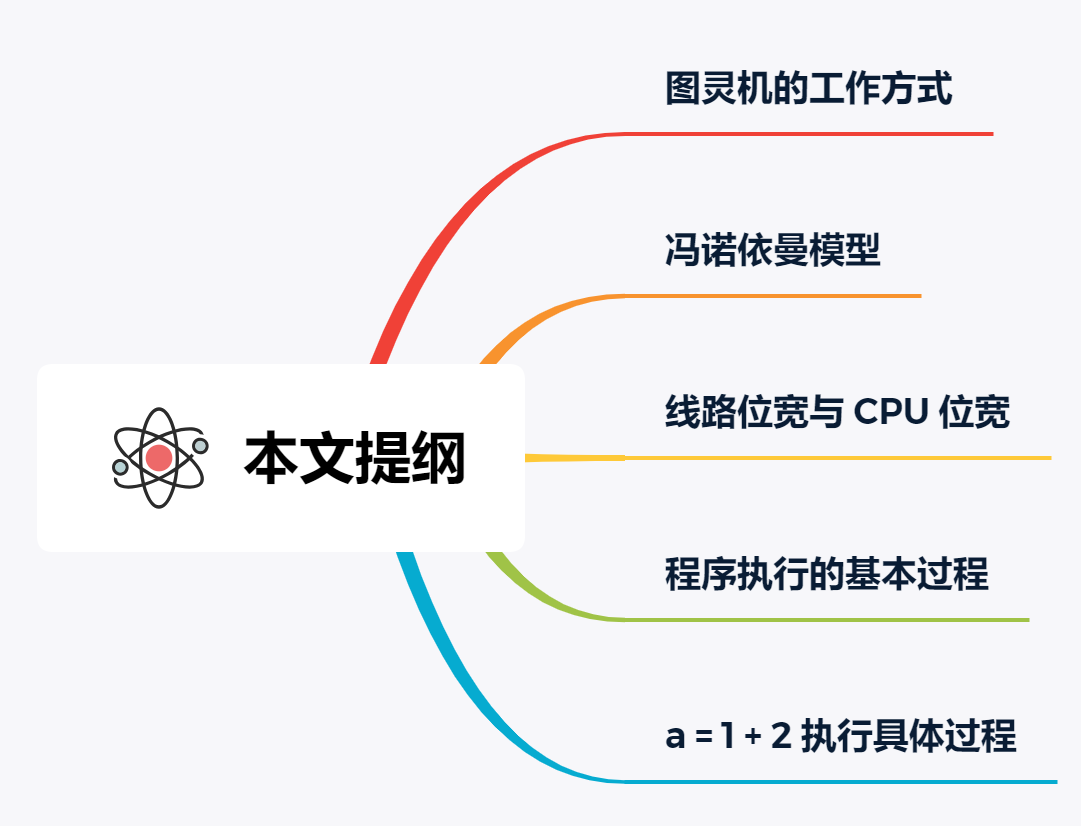
图灵机的工作方式
要想知道程序执行的原理,我们可以先从「图灵机」说起,图灵的基本思想是用机器来模拟人们用纸笔进行数学运算的过程,而且还定义了计算机由哪些部分组成,程序又是如何执行的。
图灵机长什么样子呢?你从下图可以看到图灵机的实际样子:
图灵机的基本组成如下:
- 有一条「纸带」,纸带由一个个连续的格子组成,每个格子可以写入字符,纸带就好比内存,而纸带上的格子的字符就好比内存中的数据或程序;
- 有一个「读写头」,读写头可以读取纸带上任意格子的字符,也可以把字符写入到纸带的格子;
- 读写头上有一些部件,比如存储单元、控制单元以及运算单元: 1、存储单元用于存放数据; 2、控制单元用于识别字符是数据还是指令,以及控制程序的流程等; 3、运算单元用于执行运算指令;
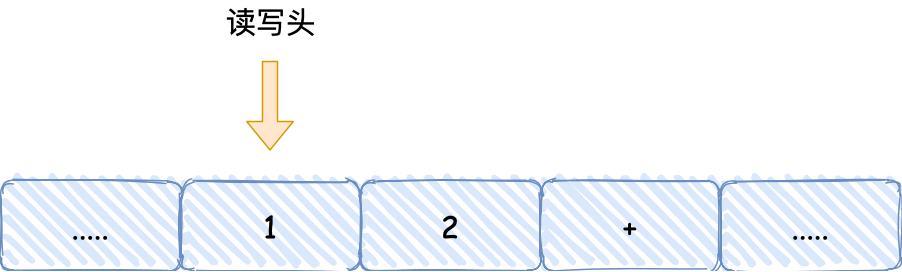
知道了图灵机的组成后,我们以简单数学运算的 1 + 2 作为例子,来看看它是怎么执行这行代码的。
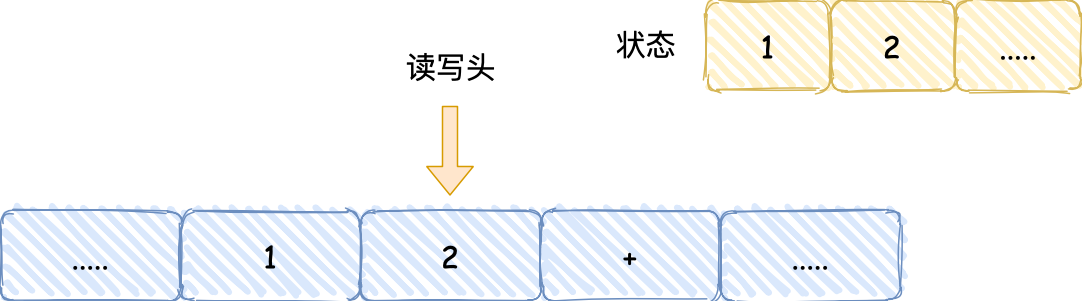
- 首先,用读写头把 「1、2、+」这 3 个字符分别写入到纸带上的 3 个格子,然后读写头先停在 1 字符对应的格子上;
- 接着,读写头读入 1 到存储设备中,这个存储设备称为图灵机的状态;
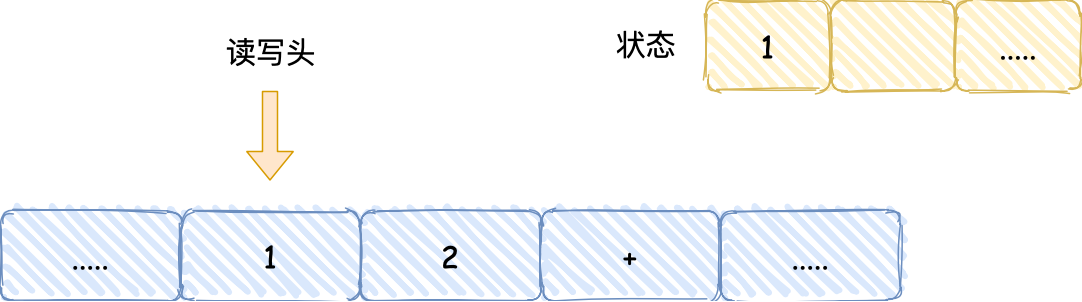
- 然后读写头向右移动一个格,用同样的方式把 2 读入到图灵机的状态,于是现在图灵机的状态中存储着两个连续的数字, 1 和 2;
- 读写头再往右移动一个格,就会碰到 + 号,读写头读到 + 号后,将 + 号传输给「控制单元」,控制单元发现是一个 + 号而不是数字,所以没有存入到状态中,因为
+号是运算符指令,作用是加和目前的状态,于是通知「运算单元」工作。运算单元收到要加和状态中的值的通知后,就会把状态中的 1 和 2 读入并计算,再将计算的结果 3 存放到状态中;
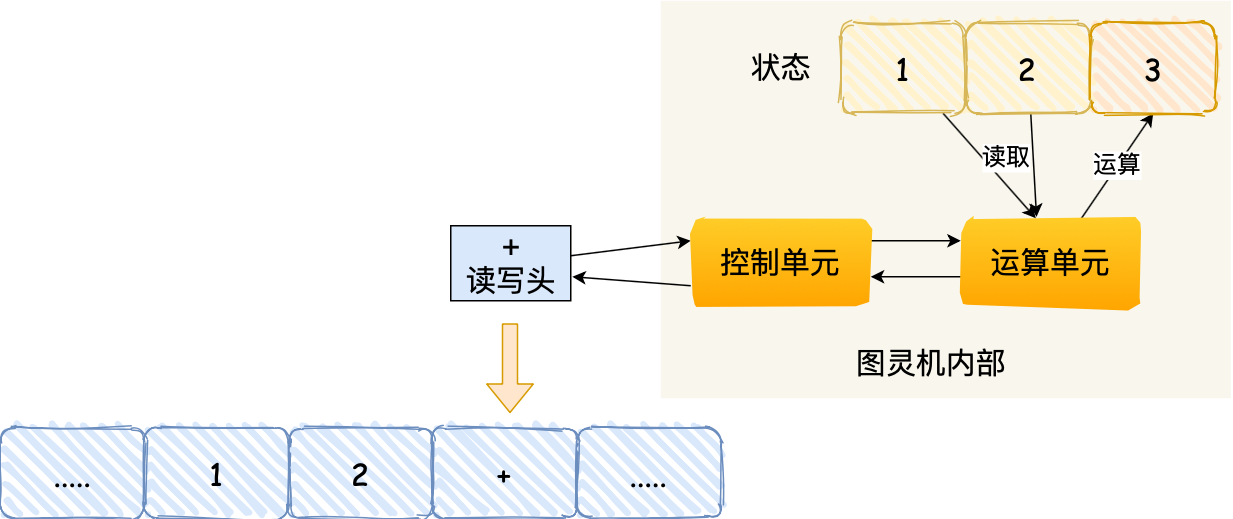
- 最后,运算单元将结果返回给控制单元,控制单元将结果传输给读写头,读写头向右移动,把结果 3 写入到纸带的格子中;
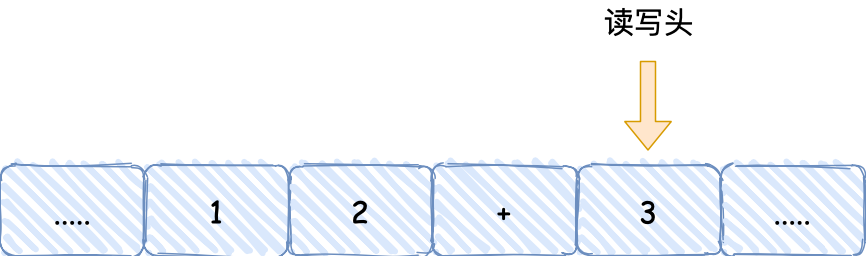
通过上面的图灵机计算 1 + 2 的过程,可以发现图灵机主要功能就是读取纸带格子中的内容,然后交给控制单元识别字符是数字还是运算符指令,如果是数字则存入到图灵机状态中,如果是运算符,则通知运算符单元读取状态中的数值进行计算,计算结果最终返回给读写头,读写头把结果写入到纸带的格子中。
事实上,图灵机这个看起来很简单的工作方式,和我们今天的计算机是基本一样的。接下来,我们一同再看看当今计算机的组成以及工作方式。
冯诺依曼模型
在 1945 年冯诺依曼和其他计算机科学家们提出了计算机具体实现的报告,其遵循了图灵机的设计,而且还提出用电子元件构造计算机,并约定了用二进制进行计算和存储。
最重要的是定义计算机基本结构为 5 个部分,分别是运算器、控制器、存储器、输入设备、输出设备,这 5 个部分也被称为冯诺依曼模型。

运算器、控制器是在中央处理器里的,存储器就我们常见的内存,输入输出设备则是计算机外接的设备,比如键盘就是输入设备,显示器就是输出设备。
存储单元和输入输出设备要与中央处理器打交道的话,离不开总线。所以,它们之间的关系如下图:
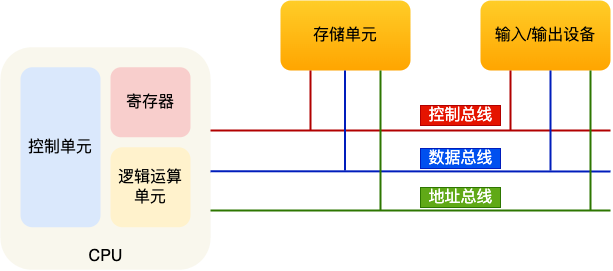
接下来,分别介绍内存、中央处理器、总线、输入输出设备。
内存
我们的程序和数据都是存储在内存,存储的区域是线性的。
在计算机数据存储中,存储数据的基本单位是字节(*byte*),1 字节等于 8 位(8 bit)。每一个字节都对应一个内存地址。
内存的地址是从 0 开始编号的,然后自增排列,最后一个地址为内存总字节数 - 1,这种结构好似我们程序里的数组,所以内存的读写任何一个数据的速度都是一样的。
中央处理器
中央处理器也就是我们常说的 CPU,32 位和 64 位 CPU 最主要区别在于一次能计算多少字节数据:
- 32 位 CPU 一次可以计算 4 个字节;
- 64 位 CPU 一次可以计算 8 个字节;
这里的 32 位和 64 位,通常称为 CPU 的位宽,代表的是 CPU 一次可以计算(运算)的数据量。
之所以 CPU 要这样设计,是为了能计算更大的数值,如果是 8 位的 CPU,那么一次只能计算 1 个字节 0~255 范围内的数值,这样就无法一次完成计算 10000 * 500 ,于是为了能一次计算大数的运算,CPU 需要支持多个 byte 一起计算,所以 CPU 位宽越大,可以计算的数值就越大,比如说 32 位 CPU 能计算的最大整数是 4294967295。
CPU 内部还有一些组件,常见的有寄存器、控制单元和逻辑运算单元等。其中,控制单元负责控制 CPU 工作,逻辑运算单元负责计算,而寄存器可以分为多种类,每种寄存器的功能又不尽相同。
CPU 中的寄存器主要作用是存储计算时的数据,你可能好奇为什么有了内存还需要寄存器?原因很简单,因为内存离 CPU 太远了,而寄存器就在 CPU 里,还紧挨着控制单元和逻辑运算单元,自然计算时速度会很快。
常见的寄存器种类:
- 通用寄存器,用来存放需要进行运算的数据,比如需要进行加和运算的两个数据。
- 程序计数器,用来存储 CPU 要执行下一条指令「所在的内存地址」,注意不是存储了下一条要执行的指令,此时指令还在内存中,程序计数器只是存储了下一条指令「的地址」。
- 指令寄存器,用来存放当前正在执行的指令,也就是指令本身,指令被执行完成之前,指令都存储在这里。
总线
总线是用于 CPU 和内存以及其他设备之间的通信,总线可分为 3 种:
- 地址总线,用于指定 CPU 将要操作的内存地址;
- 数据总线,用于读写内存的数据;
- 控制总线,用于发送和接收信号,比如中断、设备复位等信号,CPU 收到信号后自然进行响应,这时也需要控制总线;
当 CPU 要读写内存数据的时候,一般需要通过下面这三个总线:
- 首先要通过「地址总线」来指定内存的地址;
- 然后通过「控制总线」控制是读或写命令;
- 最后通过「数据总线」来传输数据;
输入、输出设备
输入设备向计算机输入数据,计算机经过计算后,把数据输出给输出设备。期间,如果输入设备是键盘,按下按键时是需要和 CPU 进行交互的,这时就需要用到控制总线了。
线路位宽与 CPU 位宽
数据是如何通过线路传输的呢?其实是通过操作电压,低电压表示 0,高压电压则表示 1。
如果构造了高低高这样的信号,其实就是 101 二进制数据,十进制则表示 5,如果只有一条线路,就意味着每次只能传递 1 bit 的数据,即 0 或 1,那么传输 101 这个数据,就需要 3 次才能传输完成,这样的效率非常低。
这样一位一位传输的方式,称为串行,下一个 bit 必须等待上一个 bit 传输完成才能进行传输。当然,想一次多传一些数据,增加线路即可,这时数据就可以并行传输。
为了避免低效率的串行传输的方式,线路的位宽最好一次就能访问到所有的内存地址。
CPU 想要操作「内存地址」就需要「地址总线」:
- 如果地址总线只有 1 条,那每次只能表示 「0 或 1」这两种地址,所以 CPU 能操作的内存地址最大数量为 2(2^1)个(注意,不要理解成同时能操作 2 个内存地址);
- 如果地址总线有 2 条,那么能表示 00、01、10、11 这四种地址,所以 CPU 能操作的内存地址最大数量为 4(2^2)个。
那么,想要 CPU 操作 4G 大的内存,那么就需要 32 条地址总线,因为 2 ^ 32 = 4G。
知道了线路位宽的意义后,我们再来看看 CPU 位宽。
CPU 的位宽最好不要小于线路位宽,比如 32 位 CPU 控制 40 位宽的地址总线和数据总线的话,工作起来就会非常复杂且麻烦,所以 32 位的 CPU 最好和 32 位宽的线路搭配,因为 32 位 CPU 一次最多只能操作 32 位宽的地址总线和数据总线。
如果用 32 位 CPU 去加和两个 64 位大小的数字,就需要把这 2 个 64 位的数字分成 2 个低位 32 位数字和 2 个高位 32 位数字来计算,先加个两个低位的 32 位数字,算出进位,然后加和两个高位的 32 位数字,最后再加上进位,就能算出结果了,可以发现 32 位 CPU 并不能一次性计算出加和两个 64 位数字的结果。
对于 64 位 CPU 就可以一次性算出加和两个 64 位数字的结果,因为 64 位 CPU 可以一次读入 64 位的数字,并且 64 位 CPU 内部的逻辑运算单元也支持 64 位数字的计算。
但是并不代表 64 位 CPU 性能比 32 位 CPU 高很多,很少应用需要算超过 32 位的数字,所以如果计算的数额不超过 32 位数字的情况下,32 位和 64 位 CPU 之间没什么区别的,只有当计算超过 32 位数字的情况下,64 位的优势才能体现出来。
另外,32 位 CPU 最大只能操作 4GB 内存,就算你装了 8 GB 内存条,也没用。而 64 位 CPU 寻址范围则很大,理论最大的寻址空间为 2^64。
程序执行的基本过程
在前面,我们知道了程序在图灵机的执行过程,接下来我们来看看程序在冯诺依曼模型上是怎么执行的。
程序实际上是一条一条指令,所以程序的运行过程就是把每一条指令一步一步的执行起来,负责执行指令的就是 CPU 了。
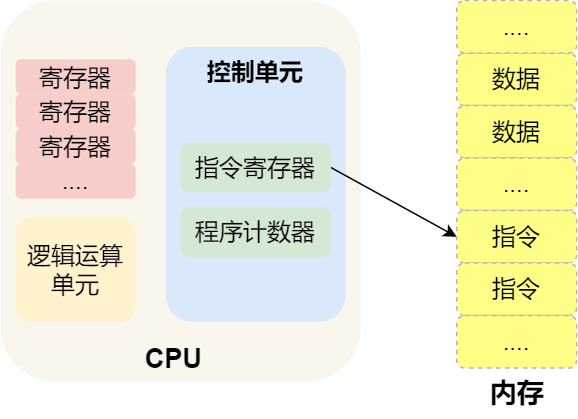
那 CPU 执行程序的过程如下:
- 第一步,CPU 读取「程序计数器」的值,这个值是指令的内存地址,然后 CPU 的「控制单元」操作「地址总线」指定需要访问的内存地址,接着通知内存设备准备数据,数据准备好后通过「数据总线」将指令数据传给 CPU,CPU 收到内存传来的数据后,将这个指令数据存入到「指令寄存器」。
- 第二步,「程序计数器」的值自增,表示指向下一条指令。这个自增的大小,由 CPU 的位宽决定,比如 32 位的 CPU,指令是 4 个字节,需要 4 个内存地址存放,因此「程序计数器」的值会自增 4;
- 第三步,CPU 分析「指令寄存器」中的指令,确定指令的类型和参数,如果是计算类型的指令,就把指令交给「逻辑运算单元」运算;如果是存储类型的指令,则交由「控制单元」执行;
简单总结一下就是,一个程序执行的时候,CPU 会根据程序计数器里的内存地址,从内存里面把需要执行的指令读取到指令寄存器里面执行,然后根据指令长度自增,开始顺序读取下一条指令。
CPU 从程序计数器读取指令、到执行、再到下一条指令,这个过程会不断循环,直到程序执行结束,这个不断循环的过程被称为 CPU 的指令周期。
a = 1 + 2 执行具体过程
知道了基本的程序执行过程后,接下来用 a = 1 + 2 的作为例子,进一步分析该程序在冯诺伊曼模型的执行过程。
CPU 是不认识 a = 1 + 2 这个字符串,这些字符串只是方便我们程序员认识,要想这段程序能跑起来,还需要把整个程序翻译成汇编语言的程序,这个过程称为编译成汇编代码。
针对汇编代码,我们还需要用汇编器翻译成机器码,这些机器码由 0 和 1 组成的机器语言,这一条条机器码,就是一条条的计算机指令,这个才是 CPU 能够真正认识的东西。
下面来看看 a = 1 + 2 在 32 位 CPU 的执行过程。
程序编译过程中,编译器通过分析代码,发现 1 和 2 是数据,于是程序运行时,内存会有个专门的区域来存放这些数据,这个区域就是「数据段」。如下图,数据 1 和 2 的区域位置:
- 数据 1 被存放到 0x200 位置;
- 数据 2 被存放到 0x204 位置;
注意,数据和指令是分开区域存放的,存放指令区域的地方称为「正文段」。
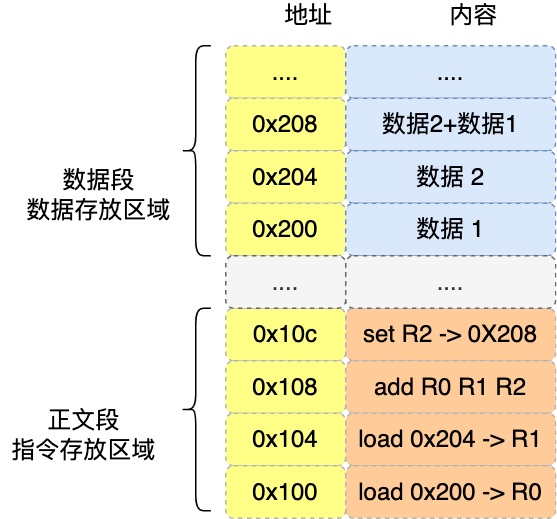
编译器会把 a = 1 + 2 翻译成 4 条指令,存放到正文段中。如图,这 4 条指令被存放到了 0x100 ~ 0x10c 的区域中:
- 0x100 的内容是
load指令将 0x200 地址中的数据 1 装入到寄存器R0; - 0x104 的内容是
load指令将 0x204 地址中的数据 2 装入到寄存器R1; - 0x108 的内容是
add指令将寄存器R0和R1的数据相加,并把结果存放到寄存器R2; - 0x10c 的内容是
store指令将寄存器R2中的数据存回数据段中的 0x208 地址中,这个地址也就是变量a内存中的地址;
编译完成后,具体执行程序的时候,程序计数器会被设置为 0x100 地址,然后依次执行这 4 条指令。
上面的例子中,由于是在 32 位 CPU 执行的,因此一条指令是占 32 位大小,所以你会发现每条指令间隔 4 个字节。
而数据的大小是根据你在程序中指定的变量类型,比如 int 类型的数据则占 4 个字节,char 类型的数据则占 1 个字节。
指令
上面的例子中,图中指令的内容我写的是简易的汇编代码,目的是为了方便理解指令的具体内容,事实上指令的内容是一串二进制数字的机器码,每条指令都有对应的机器码,CPU 通过解析机器码来知道指令的内容。
不同的 CPU 有不同的指令集,也就是对应着不同的汇编语言和不同的机器码,接下来选用最简单的 MIPS 指集,来看看机器码是如何生成的,这样也能明白二进制的机器码的具体含义。
MIPS 的指令是一个 32 位的整数,高 6 位代表着操作码,表示这条指令是一条什么样的指令,剩下的 26 位不同指令类型所表示的内容也就不相同,主要有三种类型R、I 和 J。
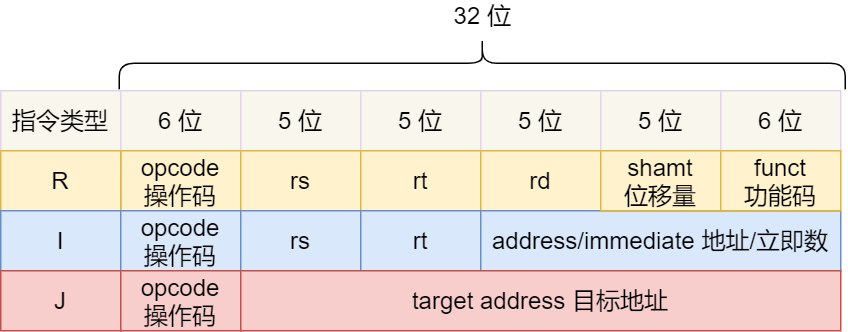
一起具体看看这三种类型的含义:
- R 指令,用在算术和逻辑操作,里面有读取和写入数据的寄存器地址。如果是逻辑位移操作,后面还有位移操作的「位移量」,而最后的「功能码」则是再前面的操作码不够的时候,扩展操作码来表示对应的具体指令的;
- I 指令,用在数据传输、条件分支等。这个类型的指令,就没有了位移量和功能码,也没有了第三个寄存器,而是把这三部分直接合并成了一个地址值或一个常数;
- J 指令,用在跳转,高 6 位之外的 26 位都是一个跳转后的地址;
接下来,我们把前面例子的这条指令:「add 指令将寄存器 R0 和 R1 的数据相加,并把结果放入到 R2」,翻译成机器码。
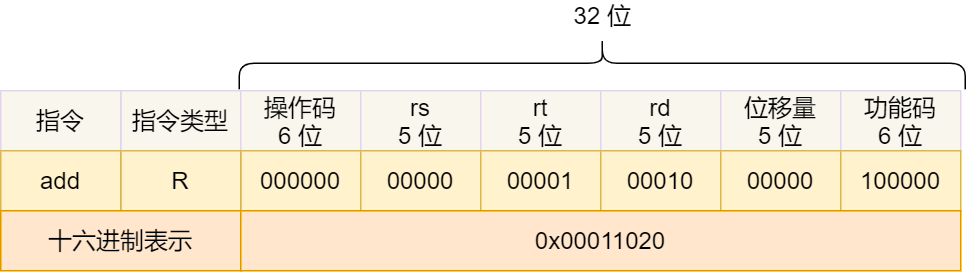
加和运算 add 指令是属于 R 指令类型:
- add 对应的 MIPS 指令里操作码是
000000,以及最末尾的功能码是100000,这些数值都是固定的,查一下 MIPS 指令集的手册就能知道的; - rs 代表第一个寄存器 R0 的编号,即
00000; - rt 代表第二个寄存器 R1 的编号,即
00001; - rd 代表目标的临时寄存器 R2 的编号,即
00010; - 因为不是位移操作,所以位移量是
00000
把上面这些数字拼在一起就是一条 32 位的 MIPS 加法指令了,那么用 16 进制表示的机器码则是 0x00011020。
编译器在编译程序的时候,会构造指令,这个过程叫做指令的编码。CPU 执行程序的时候,就会解析指令,这个过程叫作指令的解码。
现代大多数 CPU 都使用来流水线的方式来执行指令,所谓的流水线就是把一个任务拆分成多个小任务,于是一条指令通常分为 4 个阶段,称为 4 级流水线,如下图:
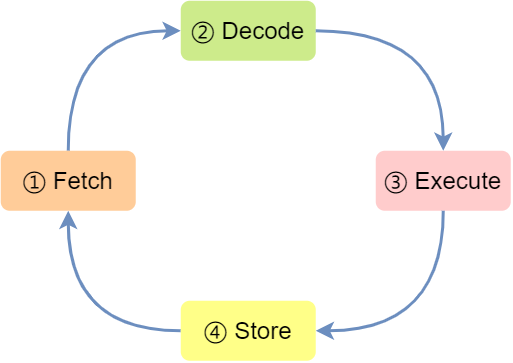
四个阶段的具体含义:
- CPU 通过程序计数器读取对应内存地址的指令,这个部分称为 Fetch(取得指令);
- CPU 对指令进行解码,这个部分称为 Decode(指令译码);
- CPU 执行指令,这个部分称为 Execution(执行指令);
- CPU 将计算结果存回寄存器或者将寄存器的值存入内存,这个部分称为 Store(数据回写);
上面这 4 个阶段,我们称为指令周期(*Instrution Cycle*),CPU 的工作就是一个周期接着一个周期,周而复始。
事实上,不同的阶段其实是由计算机中的不同组件完成的:
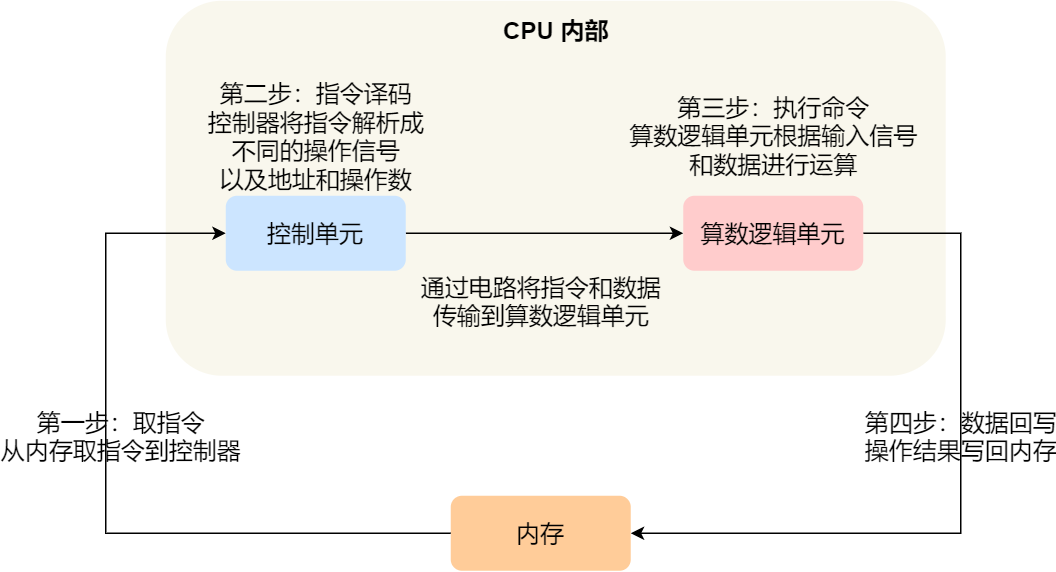
- 取指令的阶段,我们的指令是存放在存储器里的,实际上,通过程序计数器和指令寄存器取出指令的过程,是由控制器操作的;
- 指令的译码过程,也是由控制器进行的;
- 指令执行的过程,无论是进行算术操作、逻辑操作,还是进行数据传输、条件分支操作,都是由算术逻辑单元操作的,也就是由运算器处理的。但是如果是一个简单的无条件地址跳转,则是直接在控制器里面完成的,不需要用到运算器。
指令的类型
指令从功能角度划分,可以分为 5 大类:
- 数据传输类型的指令,比如
store/load是寄存器与内存间数据传输的指令,mov是将一个内存地址的数据移动到另一个内存地址的指令; - 运算类型的指令,比如加减乘除、位运算、比较大小等等,它们最多只能处理两个寄存器中的数据;
- 跳转类型的指令,通过修改程序计数器的值来达到跳转执行指令的过程,比如编程中常见的
if-else、switch-case、函数调用等。 - 信号类型的指令,比如发生中断的指令
trap; - 闲置类型的指令,比如指令
nop,执行后 CPU 会空转一个周期;
指令的执行速度
CPU 的硬件参数都会有 GHz 这个参数,比如一个 1 GHz 的 CPU,指的是时钟频率是 1 G,代表着 1 秒会产生 1G 次数的脉冲信号,每一次脉冲信号高低电平的转换就是一个周期,称为时钟周期。
对于 CPU 来说,在一个时钟周期内,CPU 仅能完成一个最基本的动作,时钟频率越高,时钟周期就越短,工作速度也就越快。
一个时钟周期一定能执行完一条指令吗?答案是不一定的,大多数指令不能在一个时钟周期完成,通常需要若干个时钟周期。不同的指令需要的时钟周期是不同的,加法和乘法都对应着一条 CPU 指令,但是乘法需要的时钟周期就要比加法多。
如何让程序跑的更快?
程序执行的时候,耗费的 CPU 时间少就说明程序是快的,对于程序的 CPU 执行时间,我们可以拆解成 CPU 时钟周期数(*CPU Cycles*)和时钟周期时间(*Clock Cycle Time*)的乘积。

时钟周期时间就是我们前面提及的 CPU 主频,主频越高说明 CPU 的工作速度就越快,比如我手头上的电脑的 CPU 是 2.4 GHz 四核 Intel Core i5,这里的 2.4 GHz 就是电脑的主频,时钟周期时间就是 1/2.4G。
要想 CPU 跑的更快,自然缩短时钟周期时间,也就是提升 CPU 主频,但是今非彼日,摩尔定律早已失效,当今的 CPU 主频已经很难再做到翻倍的效果了。
另外,换一个更好的 CPU,这个也是我们软件工程师控制不了的事情,我们应该把目光放到另外一个乘法因子 —— CPU 时钟周期数,如果能减少程序所需的 CPU 时钟周期数量,一样也是能提升程序的性能的。
对于 CPU 时钟周期数我们可以进一步拆解成:「指令数 x 每条指令的平均时钟周期数(*Cycles Per Instruction*,简称 CPI)」,于是程序的 CPU 执行时间的公式可变成如下:

因此,要想程序跑的更快,优化这三者即可:
- 指令数,表示执行程序所需要多少条指令,以及哪些指令。这个层面是基本靠编译器来优化,毕竟同样的代码,在不同的编译器,编译出来的计算机指令会有各种不同的表示方式。
- 每条指令的平均时钟周期数 CPI,表示一条指令需要多少个时钟周期数,现代大多数 CPU 通过流水线技术(Pipeline),让一条指令需要的 CPU 时钟周期数尽可能的少;
- 时钟周期时间,表示计算机主频,取决于计算机硬件。有的 CPU 支持超频技术,打开了超频意味着把 CPU 内部的时钟给调快了,于是 CPU 工作速度就变快了,但是也是有代价的,CPU 跑的越快,散热的压力就会越大,CPU 会很容易奔溃。
很多厂商为了跑分而跑分,基本都是在这三个方面入手的哦,特别是超频这一块。
总结
最后我们再来回答开头的问题。
64 位相比 32 位 CPU 的优势在哪吗?64 位 CPU 的计算性能一定比 32 位 CPU 高很多吗?
64 位相比 32 位 CPU 的优势主要体现在两个方面:
- 64 位 CPU 可以一次计算超过 32 位的数字,而 32 位 CPU 如果要计算超过 32 位的数字,要分多步骤进行计算,效率就没那么高,但是大部分应用程序很少会计算那么大的数字,所以只有运算大数字的时候,64 位 CPU 的优势才能体现出来,否则和 32 位 CPU 的计算性能相差不大。
- 通常来说 64 位 CPU 的地址总线是 48 位,而 32 位 CPU 的地址总线是 32 位,所以 64 位 CPU 可以寻址更大的物理内存空间。如果一个 32 位 CPU 的地址总线是 32 位,那么该 CPU 最大寻址能力是 4G,即使你加了 8G 大小的物理内存,也还是只能寻址到 4G 大小的地址,而如果一个 64 位 CPU 的地址总线是 48 位,那么该 CPU 最大寻址能力是
2^48,远超于 32 位 CPU 最大寻址能力。
你知道软件的 32 位和 64 位之间的区别吗?再来 32 位的操作系统可以运行在 64 位的电脑上吗?64 位的操作系统可以运行在 32 位的电脑上吗?如果不行,原因是什么?
64 位和 32 位软件,实际上代表指令是 64 位还是 32 位的:
- 如果 32 位指令在 64 位机器上执行,需要一套兼容机制,就可以做到兼容运行了。但是如果 64 位指令在 32 位机器上执行,就比较困难了,因为 32 位的寄存器存不下 64 位的指令;
- 操作系统其实也是一种程序,我们也会看到操作系统会分成 32 位操作系统、64 位操作系统,其代表意义就是操作系统中程序的指令是多少位,比如 64 位操作系统,指令也就是 64 位,因此不能装在 32 位机器上。
总之,硬件的 64 位和 32 位指的是 CPU 的位宽,软件的 64 位和 32 位指的是指令的位宽。
磁盘比内存慢几万倍?
大家如果想自己组装电脑的话,肯定需要购买一个 CPU,但是存储器方面的设备,分类比较多,那我们肯定不能只买一种存储器,比如你除了要买内存,还要买硬盘,而针对硬盘我们还可以选择是固态硬盘还是机械硬盘。
相信大家都知道内存和硬盘都属于计算机的存储设备,断电后内存的数据是会丢失的,而硬盘则不会,因为硬盘是持久化存储设备,同时也是一个 I/O 设备。
但其实 CPU 内部也有存储数据的组件,这个应该比较少人注意到,比如寄存器、CPU L1/L2/L3 Cache 也都是属于存储设备,只不过它们能存储的数据非常小,但是它们因为靠近 CPU 核心,所以访问速度都非常快,快过硬盘好几个数量级别。
问题来了,那机械硬盘、固态硬盘、内存这三个存储器,到底和 CPU L1 Cache 相比速度差多少倍呢?
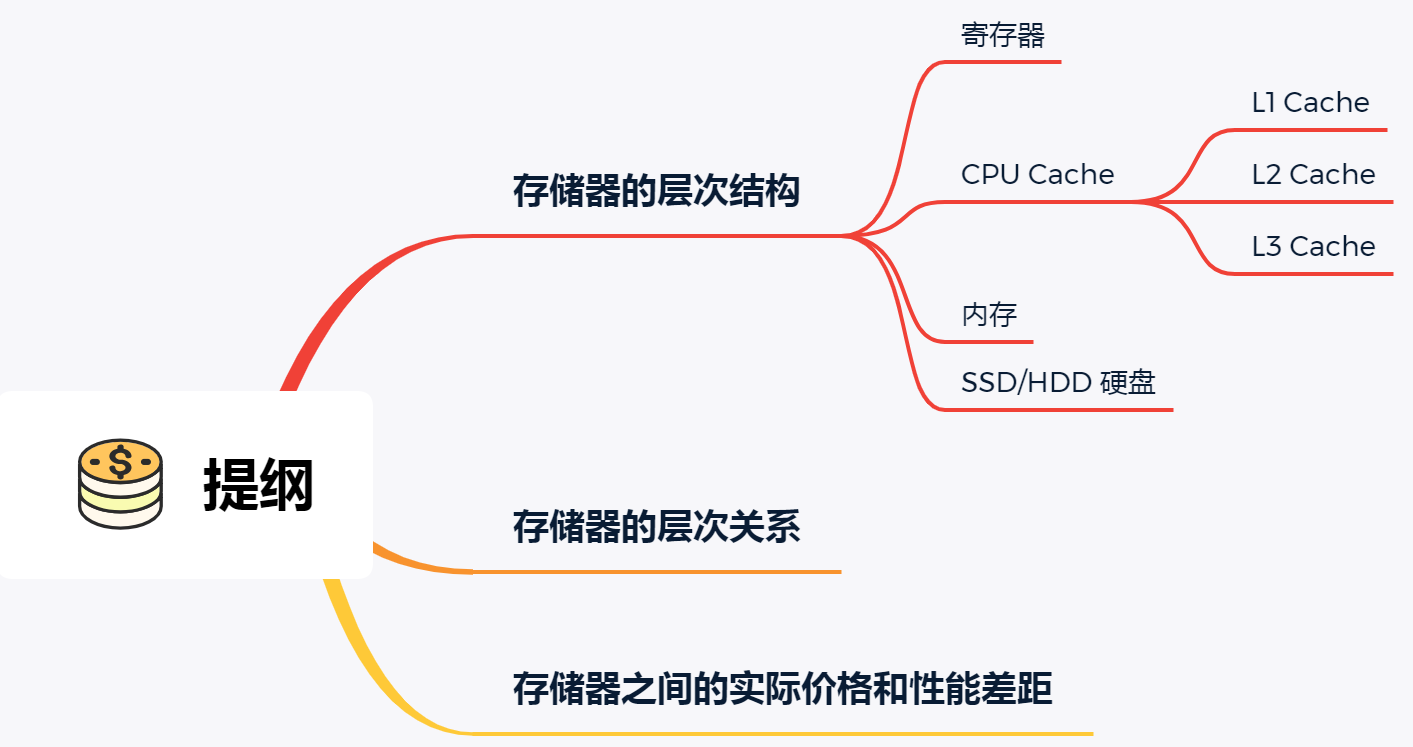
在回答这个问题之前,我们先来看看「存储器的层次结构」,好让我们对存储器设备有一个整体的认识。
存储器的层次结构
我们想象中一个场景,大学期末准备考试了,你前去图书馆临时抱佛脚。那么,在看书的时候,我们的大脑会思考问题,也会记忆知识点,另外我们通常也会把常用的书放在自己的桌子上,当我们要找一本不常用的书,则会去图书馆的书架找。
就是这么一个小小的场景,已经把计算机的存储结构基本都涵盖了。
我们可以把 CPU 比喻成我们的大脑,大脑正在思考的东西,就好比 CPU 中的寄存器,处理速度是最快的,但是能存储的数据也是最少的,毕竟我们也不能一下同时思考太多的事情,除非你练过。
我们大脑中的记忆,就好比 CPU Cache,中文称为 CPU 高速缓存,处理速度相比寄存器慢了一点,但是能存储的数据也稍微多了一些。
CPU Cache 通常会分为 L1、L2、L3 三层,其中 L1 Cache 通常分成「数据缓存」和「指令缓存」,L1 是距离 CPU 最近的,因此它比 L2、L3 的读写速度都快、存储空间都小。我们大脑中短期记忆,就好比 L1 Cache,而长期记忆就好比 L2/L3 Cache。
寄存器和 CPU Cache 都是在 CPU 内部,跟 CPU 挨着很近,因此它们的读写速度都相当的快,但是能存储的数据很少,毕竟 CPU 就这么丁点大。
知道 CPU 内部的存储器的层次分布,我们放眼看看 CPU 外部的存储器。
当我们大脑记忆中没有资料的时候,可以从书桌或书架上拿书来阅读,那我们桌子上的书,就好比内存,我们虽然可以一伸手就可以拿到,但读写速度肯定远慢于寄存器,那图书馆书架上的书,就好比硬盘,能存储的数据非常大,但是读写速度相比内存差好几个数量级,更别说跟寄存器的差距了。
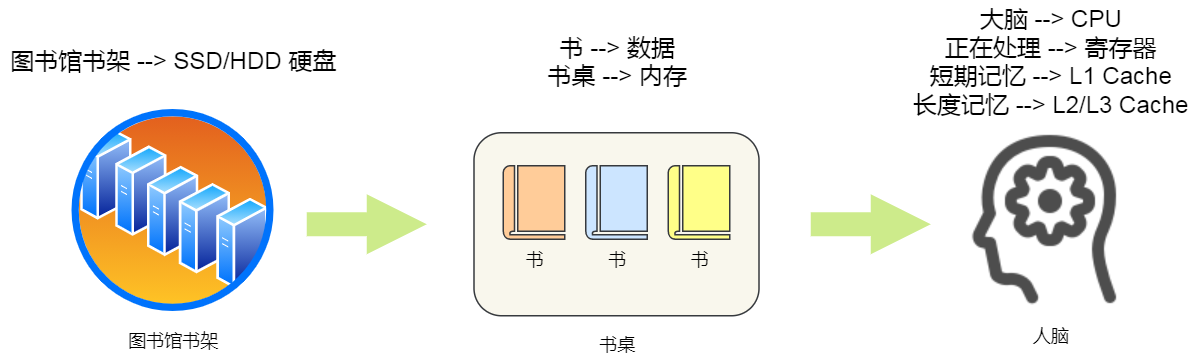
我们从图书馆书架取书,把书放到桌子上,再阅读书,我们大脑就会记忆知识点,然后再经过大脑思考,这一系列过程相当于,数据从硬盘加载到内存,再从内存加载到 CPU 的寄存器和 Cache 中,然后再通过 CPU 进行处理和计算。
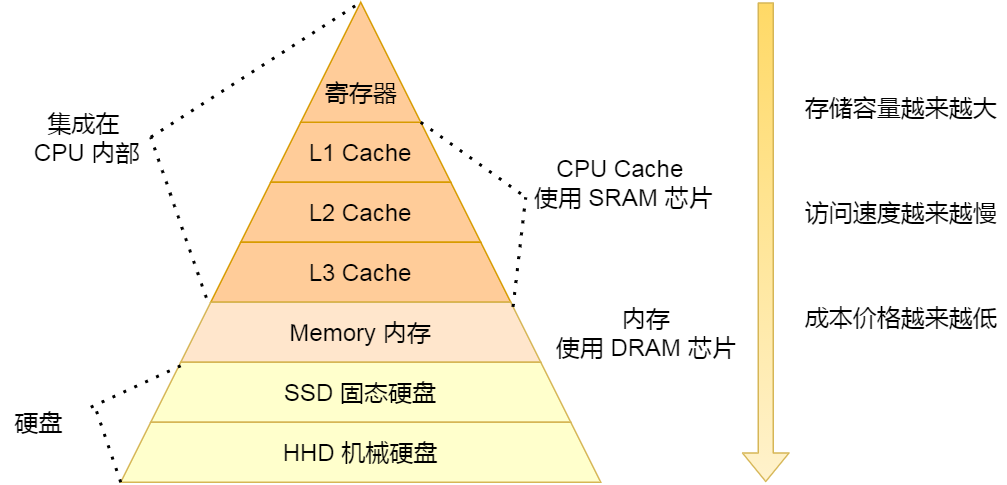
对于存储器,它的速度越快、能耗会越高、而且材料的成本也是越贵的,以至于速度快的存储器的容量都比较小。
CPU 里的寄存器和 Cache,是整个计算机存储器中价格最贵的,虽然存储空间很小,但是读写速度是极快的,而相对比较便宜的内存和硬盘,速度肯定比不上 CPU 内部的存储器,但是能弥补存储空间的不足。
存储器通常可以分为这么几个级别:
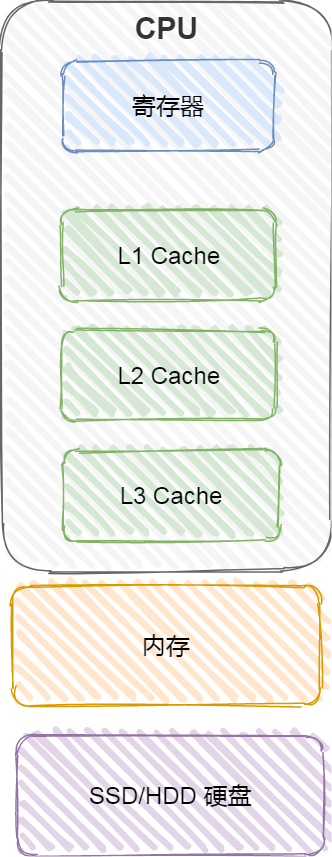
- 寄存器;
- CPU Cache;
- L1-Cache;
- L2-Cache;
- L3-Cahce;
- 内存;
- SSD/HDD 硬盘
寄存器
最靠近 CPU 的控制单元和逻辑计算单元的存储器,就是寄存器了,它使用的材料速度也是最快的,因此价格也是最贵的,那么数量不能很多。
寄存器的数量通常在几十到几百之间,每个寄存器可以用来存储一定的字节(byte)的数据。比如:
- 32 位 CPU 中大多数寄存器可以存储
4个字节; - 64 位 CPU 中大多数寄存器可以存储
8个字节。
寄存器的访问速度非常快,一般要求在半个 CPU 时钟周期内完成读写,CPU 时钟周期跟 CPU 主频息息相关,比如 2 GHz 主频的 CPU,那么它的时钟周期就是 1/2G,也就是 0.5ns(纳秒)。
CPU 处理一条指令的时候,除了读写寄存器,还需要解码指令、控制指令执行和计算。如果寄存器的速度太慢,则会拉长指令的处理周期,从而给用户的感觉,就是电脑「很慢」。
CPU Cache
CPU Cache 用的是一种叫 SRAM(*Static Random-Access* Memory,静态随机存储器) 的芯片。
SRAM 之所以叫「静态」存储器,是因为只要有电,数据就可以保持存在,而一旦断电,数据就会丢失了。
在 SRAM 里面,一个 bit 的数据,通常需要 6 个晶体管,所以 SRAM 的存储密度不高,同样的物理空间下,能存储的数据是有限的,不过也因为 SRAM 的电路简单,所以访问速度非常快。
CPU 的高速缓存,通常可以分为 L1、L2、L3 这样的三层高速缓存,也称为一级缓存、二级缓存、三级缓存。
L1 高速缓存
L1 高速缓存的访问速度几乎和寄存器一样快,通常只需要 2~4 个时钟周期,而大小在几十 KB 到几百 KB 不等。
每个 CPU 核心都有一块属于自己的 L1 高速缓存,指令和数据在 L1 是分开存放的,所以 L1 高速缓存通常分成指令缓存和数据缓存。
在 Linux 系统,我们可以通过这条命令,查看 CPU 里的 L1 Cache 「数据」缓存的容量大小:
|
|
而查看 L1 Cache 「指令」缓存的容量大小,则是:
|
|
L2 高速缓存
L2 高速缓存同样每个 CPU 核心都有,但是 L2 高速缓存位置比 L1 高速缓存距离 CPU 核心 更远,它大小比 L1 高速缓存更大,CPU 型号不同大小也就不同,通常大小在几百 KB 到几 MB 不等,访问速度则更慢,速度在 10~20 个时钟周期。
在 Linux 系统,我们可以通过这条命令,查看 CPU 里的 L2 Cache 的容量大小:
|
|
L3 高速缓存
L3 高速缓存通常是多个 CPU 核心共用的,位置比 L2 高速缓存距离 CPU 核心 更远,大小也会更大些,通常大小在几 MB 到几十 MB 不等,具体值根据 CPU 型号而定。
访问速度相对也比较慢一些,访问速度在 20~60个时钟周期。
在 Linux 系统,我们可以通过这条命令,查看 CPU 里的 L3 Cache 的容量大小:
|
|
内存
内存用的芯片和 CPU Cache 有所不同,它使用的是一种叫作 DRAM (*Dynamic Random Access Memory*,动态随机存取存储器) 的芯片。
相比 SRAM,DRAM 的密度更高,功耗更低,有更大的容量,而且造价比 SRAM 芯片便宜很多。
DRAM 存储一个 bit 数据,只需要一个晶体管和一个电容就能存储,但是因为数据会被存储在电容里,电容会不断漏电,所以需要「定时刷新」电容,才能保证数据不会被丢失,这就是 DRAM 之所以被称为「动态」存储器的原因,只有不断刷新,数据才能被存储起来。
DRAM 的数据访问电路和刷新电路都比 SRAM 更复杂,所以访问的速度会更慢,内存速度大概在 200~300 个 时钟周期之间。
SSD/HDD 硬盘
SSD(Solid-state disk) 就是我们常说的固体硬盘,结构和内存类似,但是它相比内存的优点是断电后数据还是存在的,而内存、寄存器、高速缓存断电后数据都会丢失。内存的读写速度比 SSD 大概快 10~1000 倍。
当然,还有一款传统的硬盘,也就是机械硬盘(Hard Disk Drive, HDD),它是通过物理读写的方式来访问数据的,因此它访问速度是非常慢的,它的速度比内存慢 10W 倍左右。
由于 SSD 的价格快接近机械硬盘了,因此机械硬盘已经逐渐被 SSD 替代了。
存储器的层次关系
现代的一台计算机,都用上了 CPU Cahce、内存、到 SSD 或 HDD 硬盘这些存储器设备了。
其中,存储空间越大的存储器设备,其访问速度越慢,所需成本也相对越少。
CPU 并不会直接和每一种存储器设备直接打交道,而是每一种存储器设备只和它相邻的存储器设备打交道。
比如,CPU Cache 的数据是从内存加载过来的,写回数据的时候也只写回到内存,CPU Cache 不会直接把数据写到硬盘,也不会直接从硬盘加载数据,而是先加载到内存,再从内存加载到 CPU Cache 中。
所以,每个存储器只和相邻的一层存储器设备打交道,并且存储设备为了追求更快的速度,所需的材料成本必然也是更高,也正因为成本太高,所以 CPU 内部的寄存器、L1\L2\L3 Cache 只好用较小的容量,相反内存、硬盘则可用更大的容量,这就我们今天所说的存储器层次结构。
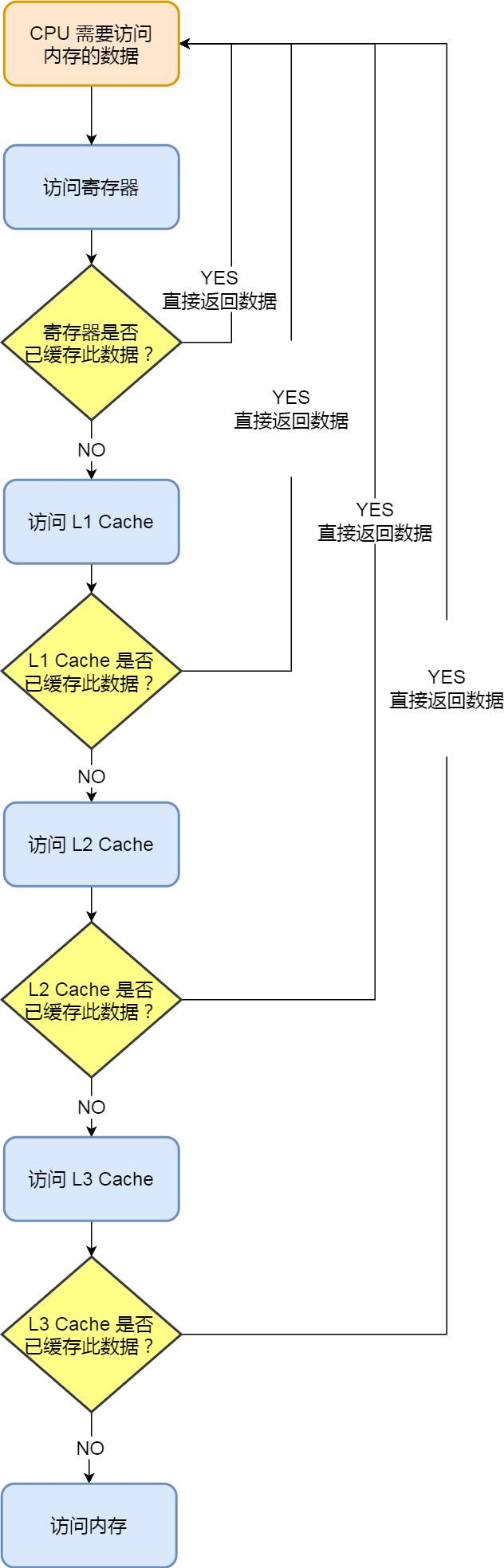
另外,当 CPU 需要访问内存中某个数据的时候,如果寄存器有这个数据,CPU 就直接从寄存器取数据即可,如果寄存器没有这个数据,CPU 就会查询 L1 高速缓存,如果 L1 没有,则查询 L2 高速缓存,L2 还是没有的话就查询 L3 高速缓存,L3 依然没有的话,才去内存中取数据。
所以,存储层次结构也形成了缓存的体系。
存储器之间的实际价格和性能差距
前面我们知道了,速度越快的存储器,造价成本往往也越高,那我们就以实际的数据来看看,不同层级的存储器之间的性能和价格差异。
下面这张表格是不同层级的存储器之间的成本对比图:
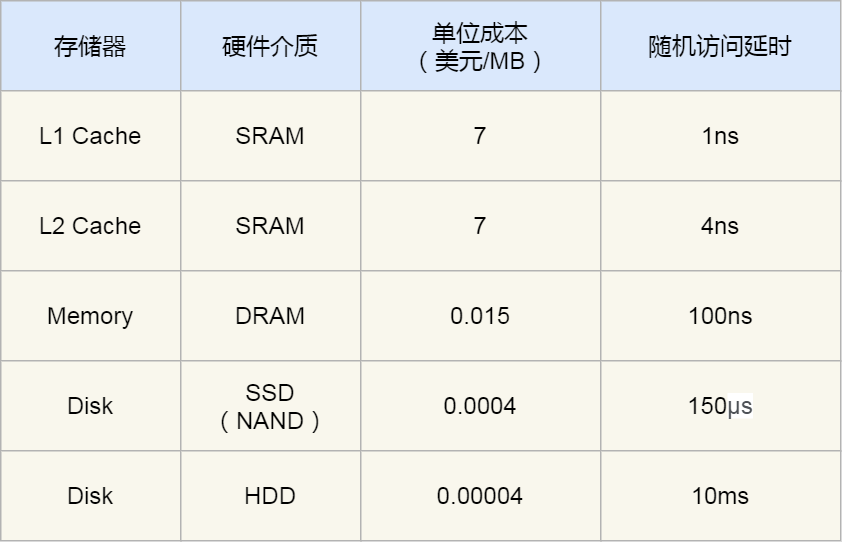
你可以看到 L1 Cache 的访问延时是 1 纳秒,而内存已经是 100 纳秒了,相比 L1 Cache 速度慢了 100 倍。另外,机械硬盘的访问延时更是高达 10 毫秒,相比 L1 Cache 速度慢了 10000000 倍,差了好几个数量级别。
在价格上,每生成 MB 大小的 L1 Cache 相比内存贵了 466 倍,相比机械硬盘那更是贵了 175000 倍。
我在某东逛了下各个存储器设备的零售价,8G 内存 + 1T 机械硬盘 + 256G 固态硬盘的总价格,都不及一块 Intle i5-10400 的 CPU 的价格,这款 CPU 的高速缓存的总大小也就十多 MB。
总结
各种存储器之间的关系,可以用我们在图书馆学习这个场景来理解。
CPU 可以比喻成我们的大脑,我们当前正在思考和处理的知识的过程,就好比 CPU 中的寄存器处理数据的过程,速度极快,但是容量很小。而 CPU 中的 L1-L3 Cache 好比我们大脑中的短期记忆和长期记忆,需要小小花费点时间来调取数据并处理。
我们面前的桌子就相当于内存,能放下更多的书(数据),但是找起来和看起来就要花费一些时间,相比 CPU Cache 慢不少。而图书馆的书架相当于硬盘,能放下比内存更多的数据,但找起来就更费时间了,可以说是最慢的存储器设备了。
从 寄存器、CPU Cache,到内存、硬盘,这样一层层下来的存储器,访问速度越来越慢,存储容量越来越大,价格也越来越便宜,而且每个存储器只和相邻的一层存储器设备打交道,于是这样就形成了存储器的层次结构。
再来回答,开头的问题:那机械硬盘、固态硬盘、内存这三个存储器,到底和 CPU L1 Cache 相比速度差多少倍呢?
CPU L1 Cache 随机访问延时是 1 纳秒,内存则是 100 纳秒,所以 CPU L1 Cache 比内存快 100 倍左右。
SSD 随机访问延时是 150 微秒,所以 CPU L1 Cache 比 SSD 快 150000 倍左右。
最慢的机械硬盘随机访问延时已经高达 10 毫秒,我们来看看机械硬盘到底有多「龟速」:
- SSD 比机械硬盘快 70 倍左右;
- 内存比机械硬盘快 100000 倍左右;
- CPU L1 Cache 比机械硬盘快 10000000 倍左右;
我们把上述的时间比例差异放大后,就能非常直观感受到它们的性能差异了。如果 CPU 访问 L1 Cache 的缓存时间是 1 秒,那访问内存则需要大约 2 分钟,随机访问 SSD 里的数据则需要 1.7 天,访问机械硬盘那更久,长达近 4 个月。
可以发现,不同的存储器之间性能差距很大,构造存储器分级很有意义,分级的目的是要构造缓存体系。
如何写出让CPU跑得更快的代码?
代码都是由 CPU 跑起来的,我们代码写的好与坏就决定了 CPU 的执行效率,特别是在编写计算密集型的程序,更要注重 CPU 的执行效率,否则将会大大影响系统性能。
CPU 内部嵌入了 CPU Cache(高速缓存),它的存储容量很小,但是离 CPU 核心很近,所以缓存的读写速度是极快的,那么如果 CPU 运算时,直接从 CPU Cache 读取数据,而不是从内存的话,运算速度就会很快。
但是,大多数人不知道 CPU Cache 的运行机制,以至于不知道如何才能够写出能够配合 CPU Cache 工作机制的代码,一旦你掌握了它,你写代码的时候,就有新的优化思路了。
那么,接下来我们就来看看,CPU Cache 到底是什么样的,是如何工作的呢,又该如何写出让 CPU 执行更快的代码呢?

CPU Cache 有多快?
你可能会好奇为什么有了内存,还需要 CPU Cache?根据摩尔定律,CPU 的访问速度每 18 个月就会翻倍,相当于每年增长 60% 左右,内存的速度当然也会不断增长,但是增长的速度远小于 CPU,平均每年只增长 7% 左右。于是,CPU 与内存的访问性能的差距不断拉大。
到现在,一次内存访问所需时间是 200~300 多个时钟周期,这意味着 CPU 和内存的访问速度已经相差 200~300 多倍了。
为了弥补 CPU 与内存两者之间的性能差异,就在 CPU 内部引入了 CPU Cache,也称高速缓存。
CPU Cache 通常分为大小不等的三级缓存,分别是 L1 Cache、L2 Cache 和 L3 Cache。
由于 CPU Cache 所使用的材料是 SRAM,价格比内存使用的 DRAM 高出很多,在当今每生产 1 MB 大小的 CPU Cache 需要 7 美金的成本,而内存只需要 0.015 美金的成本,成本方面相差了 466 倍,所以 CPU Cache 不像内存那样动辄以 GB 计算,它的大小是以 KB 或 MB 来计算的。
在 Linux 系统中,我们可以使用下图的方式来查看各级 CPU Cache 的大小,比如我这手上这台服务器,离 CPU 核心最近的 L1 Cache 是 32KB,其次是 L2 Cache 是 256KB,最大的 L3 Cache 则是 3MB。

其中,L1 Cache 通常会分为「数据缓存」和「指令缓存」,这意味着数据和指令在 L1 Cache 这一层是分开缓存的,上图中的 index0 也就是数据缓存,而 index1 则是指令缓存,它两的大小通常是一样的。
另外,你也会注意到,L3 Cache 比 L1 Cache 和 L2 Cache 大很多,这是因为 L1 Cache 和 L2 Cache 都是每个 CPU 核心独有的,而 L3 Cache 是多个 CPU 核心共享的。
程序执行时,会先将内存中的数据加载到共享的 L3 Cache 中,再加载到每个核心独有的 L2 Cache,最后进入到最快的 L1 Cache,之后才会被 CPU 读取。它们之间的层级关系,如下图:
越靠近 CPU 核心的缓存其访问速度越快,CPU 访问 L1 Cache 只需要 2~4 个时钟周期,访问 L2 Cache 大约 10~20 个时钟周期,访问 L3 Cache 大约 20~60 个时钟周期,而访问内存速度大概在 200~300 个 时钟周期之间。如下表格:
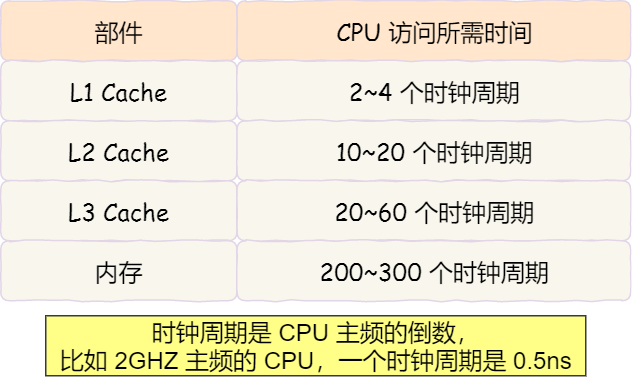
所以,CPU 从 L1 Cache 读取数据的速度,相比从内存读取的速度,会快 100 多倍。
CPU Cache 的数据结构和读取过程是什么样的?
我们先简单了解下 CPU Cache 的结构,CPU Cache 是由很多个 Cache Line 组成的,Cache Line 是 CPU 从内存读取数据的基本单位,而 Cache Line 是由各种标志(Tag)+ 数据块(Data Block)组成,你可以在下图清晰的看到:
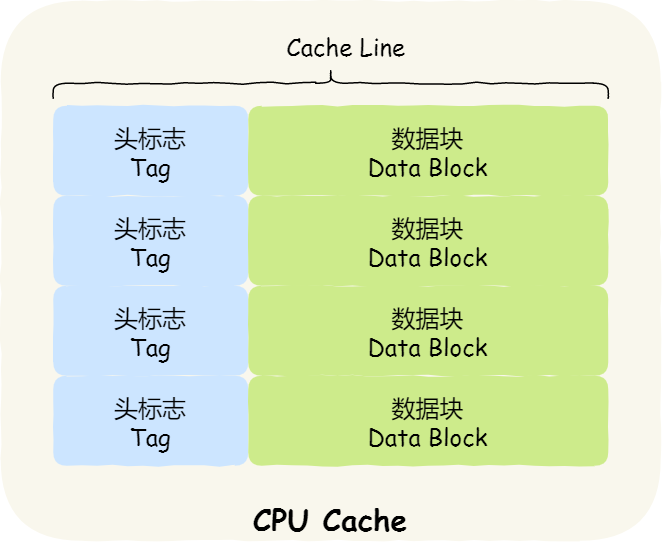
CPU Cache 的数据是从内存中读取过来的,它是以一小块一小块读取数据的,而不是按照单个数组元素来读取数据的,在 CPU Cache 中的,这样一小块一小块的数据,称为 Cache Line(缓存块)。
你可以在你的 Linux 系统,用下面这种方式来查看 CPU 的 Cache Line,你可以看我服务器的 L1 Cache Line 大小是 64 字节,也就意味着 L1 Cache 一次载入数据的大小是 64 字节。

比如,有一个 int array[100] 的数组,当载入 array[0] 时,由于这个数组元素的大小在内存只占 4 字节,不足 64 字节,CPU 就会顺序加载数组元素到 array[15],意味着 array[0]~array[15] 数组元素都会被缓存在 CPU Cache 中了,因此当下次访问这些数组元素时,会直接从 CPU Cache 读取,而不用再从内存中读取,大大提高了 CPU 读取数据的性能。
事实上,CPU 读取数据的时候,无论数据是否存放到 Cache 中,CPU 都是先访问 Cache,只有当 Cache 中找不到数据时,才会去访问内存,并把内存中的数据读入到 Cache 中,CPU 再从 CPU Cache 读取数据。
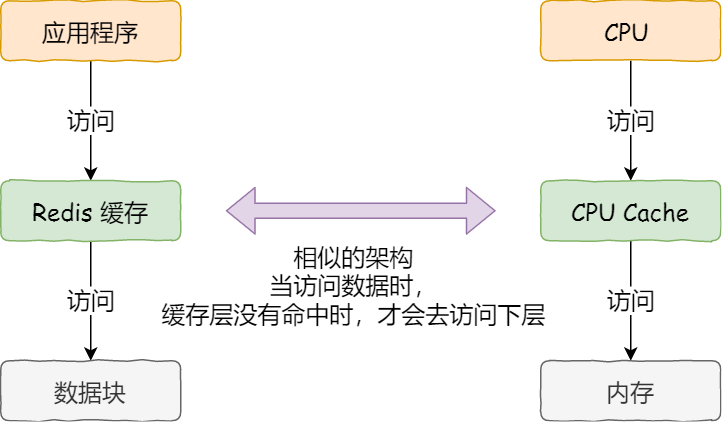
这样的访问机制,跟我们使用「内存作为硬盘的缓存」的逻辑是一样的,如果内存有缓存的数据,则直接返回,否则要访问龟速一般的硬盘。
那 CPU 怎么知道要访问的内存数据,是否在 Cache 里?如果在的话,如何找到 Cache 对应的数据呢?我们从最简单、基础的直接映射 Cache(*Direct Mapped Cache*) 说起,来看看整个 CPU Cache 的数据结构和访问逻辑。
前面,我们提到 CPU 访问内存数据时,是一小块一小块数据读取的,具体这一小块数据的大小,取决于 coherency_line_size 的值,一般 64 字节。在内存中,这一块的数据我们称为内存块(*Block*),读取的时候我们要拿到数据所在内存块的地址。
对于直接映射 Cache 采用的策略,就是把内存块的地址始终「映射」在一个 CPU Cache Line(缓存块) 的地址,至于映射关系实现方式,则是使用「取模运算」,取模运算的结果就是内存块地址对应的 CPU Cache Line(缓存块) 的地址。
举个例子,内存共被划分为 32 个内存块,CPU Cache 共有 8 个 CPU Cache Line,假设 CPU 想要访问第 15 号内存块,如果 15 号内存块中的数据已经缓存在 CPU Cache Line 中的话,则是一定映射在 7 号 CPU Cache Line 中,因为 15 % 8 的值是 7。
机智的你肯定发现了,使用取模方式映射的话,就会出现多个内存块对应同一个 CPU Cache Line,比如上面的例子,除了 15 号内存块是映射在 7 号 CPU Cache Line 中,还有 7 号、23 号、31 号内存块都是映射到 7 号 CPU Cache Line 中。
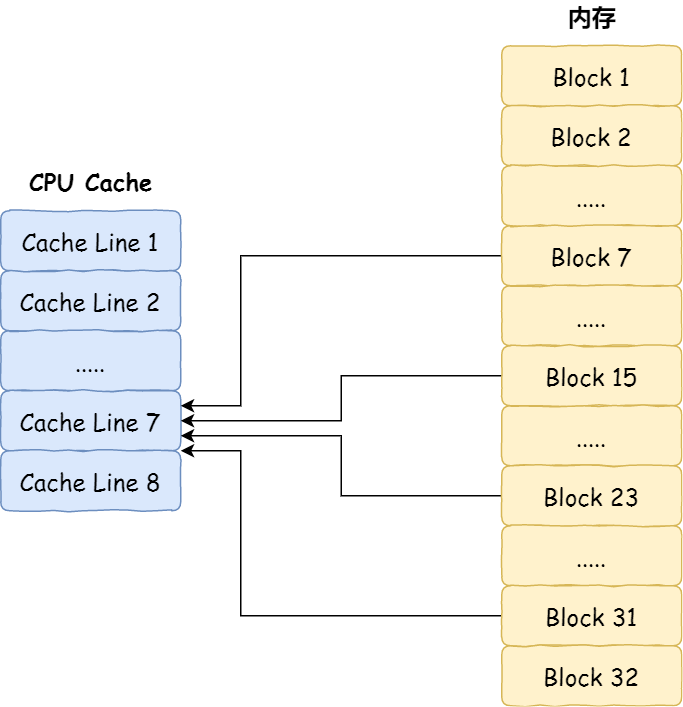
因此,为了区别不同的内存块,在对应的 CPU Cache Line 中我们还会存储一个组标记(Tag)。这个组标记会记录当前 CPU Cache Line 中存储的数据对应的内存块,我们可以用这个组标记来区分不同的内存块。
除了组标记信息外,CPU Cache Line 还有两个信息:
- 一个是,从内存加载过来的实际存放数据(*Data*)。
- 另一个是,有效位(*Valid bit*),它是用来标记对应的 CPU Cache Line 中的数据是否是有效的,如果有效位是 0,无论 CPU Cache Line 中是否有数据,CPU 都会直接访问内存,重新加载数据。
CPU 在从 CPU Cache 读取数据的时候,并不是读取 CPU Cache Line 中的整个数据块,而是读取 CPU 所需要的一个数据片段,这样的数据统称为一个字(*Word*)。那怎么在对应的 CPU Cache Line 中数据块中找到所需的字呢?答案是,需要一个偏移量(Offset)。
因此,一个内存的访问地址,包括组标记、CPU Cache Line 索引、偏移量这三种信息,于是 CPU 就能通过这些信息,在 CPU Cache 中找到缓存的数据。而对于 CPU Cache 里的数据结构,则是由索引 + 有效位 + 组标记 + 数据块组成。
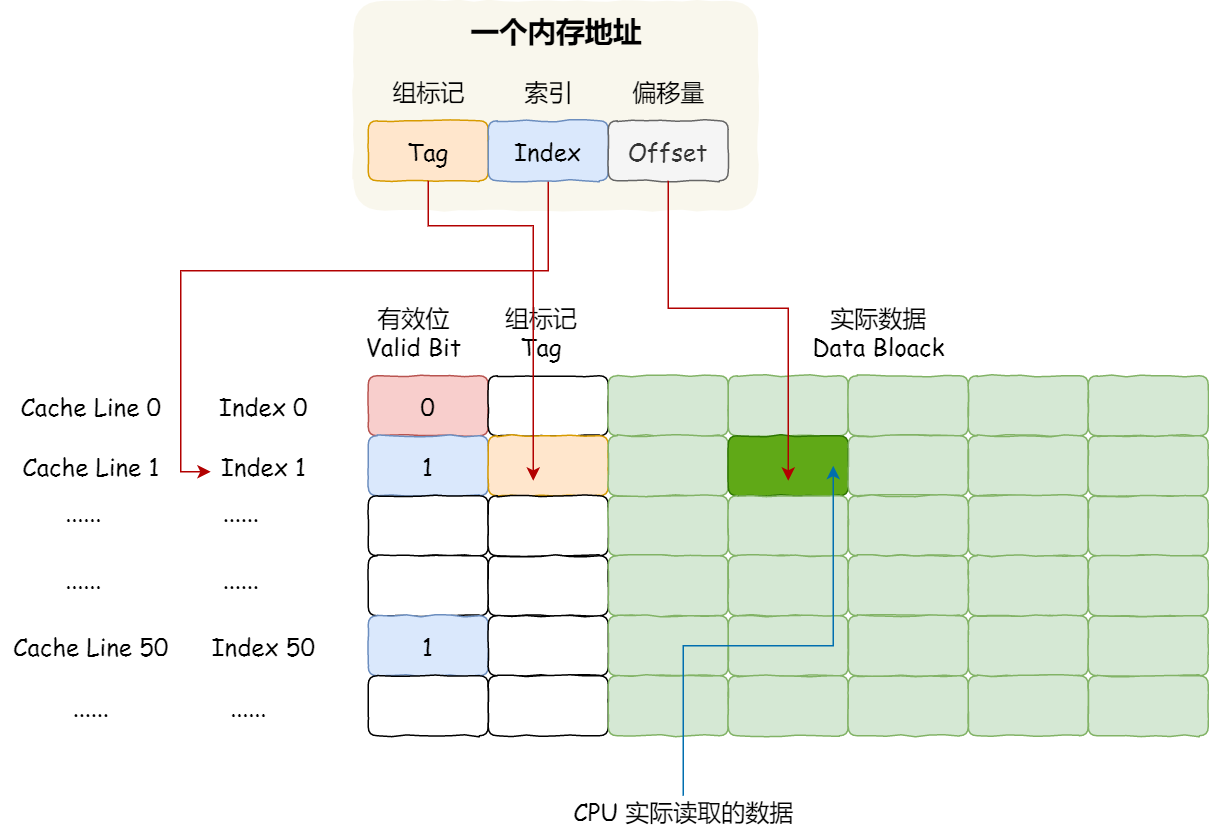
如果内存中的数据已经在 CPU Cache 中了,那 CPU 访问一个内存地址的时候,会经历这 4 个步骤:
- 根据内存地址中索引信息,计算在 CPU Cache 中的索引,也就是找出对应的 CPU Cache Line 的地址;
- 找到对应 CPU Cache Line 后,判断 CPU Cache Line 中的有效位,确认 CPU Cache Line 中数据是否是有效的,如果是无效的,CPU 就会直接访问内存,并重新加载数据,如果数据有效,则往下执行;
- 对比内存地址中组标记和 CPU Cache Line 中的组标记,确认 CPU Cache Line 中的数据是我们要访问的内存数据,如果不是的话,CPU 就会直接访问内存,并重新加载数据,如果是的话,则往下执行;
- 根据内存地址中偏移量信息,从 CPU Cache Line 的数据块中,读取对应的字。
到这里,相信你对直接映射 Cache 有了一定认识,但其实除了直接映射 Cache 之外,还有其他通过内存地址找到 CPU Cache 中的数据的策略,比如全相连 Cache (Fully Associative Cache)、组相连 Cache (Set Associative Cache)等,这几种策策略的数据结构都比较相似,我们理解了直接映射 Cache 的工作方式,其他的策略如果你有兴趣去看,相信很快就能理解的了。
如何写出让 CPU 跑得更快的代码?
我们知道 CPU 访问内存的速度,比访问 CPU Cache 的速度慢了 100 多倍,所以如果 CPU 所要操作的数据在 CPU Cache 中的话,这样将会带来很大的性能提升。访问的数据在 CPU Cache 中的话,意味着缓存命中,缓存命中率越高的话,代码的性能就会越好,CPU 也就跑的越快。
于是,「如何写出让 CPU 跑得更快的代码?」这个问题,可以改成「如何写出 CPU 缓存命中率高的代码?」。
在前面我也提到, L1 Cache 通常分为「数据缓存」和「指令缓存」,这是因为 CPU 会分别处理数据和指令,比如 1+1=2 这个运算,+ 就是指令,会被放在「指令缓存」中,而输入数字 1 则会被放在「数据缓存」里。
因此,我们要分开来看「数据缓存」和「指令缓存」的缓存命中率。
如何提升数据缓存的命中率?
假设要遍历二维数组,有以下两种形式,虽然代码执行结果是一样,但你觉得哪种形式效率最高呢?为什么高呢?

经过测试,形式一 array[i][j] 执行时间比形式二 array[j][i] 快好几倍。
之所以有这么大的差距,是因为二维数组 array 所占用的内存是连续的,比如长度 N 的值是 2 的话,那么内存中的数组元素的布局顺序是这样的:

形式一用 array[i][j] 访问数组元素的顺序,正是和内存中数组元素存放的顺序一致。当 CPU 访问 array[0][0] 时,由于该数据不在 Cache 中,于是会「顺序」把跟随其后的 3 个元素从内存中加载到 CPU Cache,这样当 CPU 访问后面的 3 个数组元素时,就能在 CPU Cache 中成功地找到数据,这意味着缓存命中率很高,缓存命中的数据不需要访问内存,这便大大提高了代码的性能。
而如果用形式二的 array[j][i] 来访问,则访问的顺序就是:

你可以看到,访问的方式跳跃式的,而不是顺序的,那么如果 N 的数值很大,那么操作 array[j][i] 时,是没办法把 array[j+1][i] 也读入到 CPU Cache 中的,既然 array[j+1][i] 没有读取到 CPU Cache,那么就需要从内存读取该数据元素了。很明显,这种不连续性、跳跃式访问数据元素的方式,可能不能充分利用到了 CPU Cache 的特性,从而代码的性能不高。
那访问 array[0][0] 元素时,CPU 具体会一次从内存中加载多少元素到 CPU Cache 呢?这个问题,在前面我们也提到过,这跟 CPU Cache Line 有关,它表示 CPU Cache 一次性能加载数据的大小,可以在 Linux 里通过 coherency_line_size 配置查看 它的大小,通常是 64 个字节。
也就是说,当 CPU 访问内存数据时,如果数据不在 CPU Cache 中,则会一次性会连续加载 64 字节大小的数据到 CPU Cache,那么当访问 array[0][0] 时,由于该元素不足 64 字节,于是就会往后顺序读取 array[0][0]~array[0][15] 到 CPU Cache 中。顺序访问的 array[i][j] 因为利用了这一特点,所以就会比跳跃式访问的 array[j][i] 要快。
因此,遇到这种遍历数组的情况时,按照内存布局顺序访问,将可以有效的利用 CPU Cache 带来的好处,这样我们代码的性能就会得到很大的提升,
如何提升指令缓存的命中率?
提升数据的缓存命中率的方式,是按照内存布局顺序访问,那针对指令的缓存该如何提升呢?
我们以一个例子来看看,有一个元素为 0 到 100 之间随机数字组成的一维数组:

接下来,对这个数组做两个操作:

- 第一个操作,循环遍历数组,把小于 50 的数组元素置为 0;
- 第二个操作,将数组排序;
那么问题来了,你觉得先遍历再排序速度快,还是先排序再遍历速度快呢?
在回答这个问题之前,我们先了解 CPU 的分支预测器。对于 if 条件语句,意味着此时至少可以选择跳转到两段不同的指令执行,也就是 if 还是 else 中的指令。那么,如果分支预测可以预测到接下来要执行 if 里的指令,还是 else 指令的话,就可以「提前」把这些指令放在指令缓存中,这样 CPU 可以直接从 Cache 读取到指令,于是执行速度就会很快。
当数组中的元素是随机的,分支预测就无法有效工作,而当数组元素都是是顺序的,分支预测器会动态地根据历史命中数据对未来进行预测,这样命中率就会很高。
因此,先排序再遍历速度会更快,这是因为排序之后,数字是从小到大的,那么前几次循环命中 if < 50 的次数会比较多,于是分支预测就会缓存 if 里的 array[i] = 0 指令到 Cache 中,后续 CPU 执行该指令就只需要从 Cache 读取就好了。
如果你肯定代码中的 if 中的表达式判断为 true 的概率比较高,我们可以使用显示分支预测工具,比如在 C/C++ 语言中编译器提供了 likely 和 unlikely 这两种宏,如果 if 条件为 ture 的概率大,则可以用 likely 宏把 if 里的表达式包裹起来,反之用 unlikely 宏。

实际上,CPU 自身的动态分支预测已经是比较准的了,所以只有当非常确信 CPU 预测的不准,且能够知道实际的概率情况时,才建议使用这两种宏。
如何提升多核 CPU 的缓存命中率?
在单核 CPU,虽然只能执行一个线程,但是操作系统给每个线程分配了一个时间片,时间片用完了,就调度下一个线程,于是各个线程就按时间片交替地占用 CPU,从宏观上看起来各个线程同时在执行。
而现代 CPU 都是多核心的,线程可能在不同 CPU 核心来回切换执行,这对 CPU Cache 不是有利的,虽然 L3 Cache 是多核心之间共享的,但是 L1 和 L2 Cache 都是每个核心独有的,如果一个线程在不同核心来回切换,各个核心的缓存命中率就会受到影响,相反如果线程都在同一个核心上执行,那么其数据的 L1 和 L2 Cache 的缓存命中率可以得到有效提高,缓存命中率高就意味着 CPU 可以减少访问 内存的频率。
当有多个同时执行「计算密集型」的线程,为了防止因为切换到不同的核心,而导致缓存命中率下降的问题,我们可以把线程绑定在某一个 CPU 核心上,这样性能可以得到非常可观的提升。
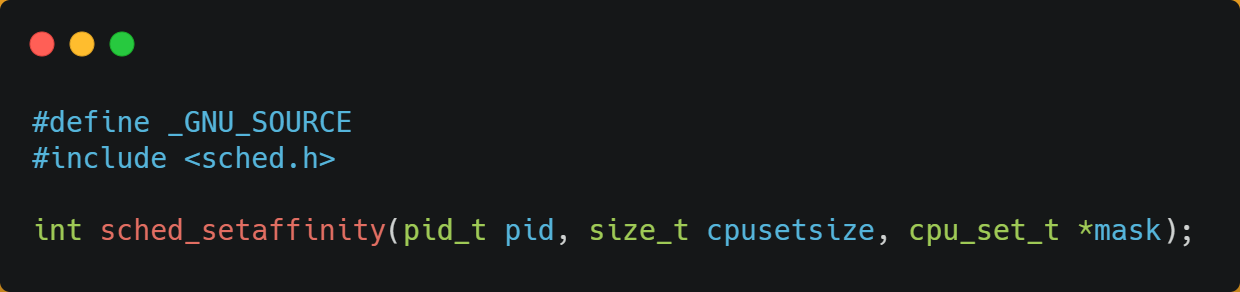
在 Linux 上提供了 sched_setaffinity 方法,来实现将线程绑定到某个 CPU 核心这一功能。
总结
由于随着计算机技术的发展,CPU 与 内存的访问速度相差越来越多,如今差距已经高达好几百倍了,所以 CPU 内部嵌入了 CPU Cache 组件,作为内存与 CPU 之间的缓存层,CPU Cache 由于离 CPU 核心很近,所以访问速度也是非常快的,但由于所需材料成本比较高,它不像内存动辄几个 GB 大小,而是仅有几十 KB 到 MB 大小。
当 CPU 访问数据的时候,先是访问 CPU Cache,如果缓存命中的话,则直接返回数据,就不用每次都从内存读取数据了。因此,缓存命中率越高,代码的性能越好。
但需要注意的是,当 CPU 访问数据时,如果 CPU Cache 没有缓存该数据,则会从内存读取数据,但是并不是只读一个数据,而是一次性读取一块一块的数据存放到 CPU Cache 中,之后才会被 CPU 读取。
内存地址映射到 CPU Cache 地址里的策略有很多种,其中比较简单是直接映射 Cache,它巧妙的把内存地址拆分成「索引 + 组标记 + 偏移量」的方式,使得我们可以将很大的内存地址,映射到很小的 CPU Cache 地址里。
要想写出让 CPU 跑得更快的代码,就需要写出缓存命中率高的代码,CPU L1 Cache 分为数据缓存和指令缓存,因而需要分别提高它们的缓存命中率:
- 对于数据缓存,我们在遍历数据的时候,应该按照内存布局的顺序操作,这是因为 CPU Cache 是根据 CPU Cache Line 批量操作数据的,所以顺序地操作连续内存数据时,性能能得到有效的提升;
- 对于指令缓存,有规律的条件分支语句能够让 CPU 的分支预测器发挥作用,进一步提高执行的效率;
另外,对于多核 CPU 系统,线程可能在不同 CPU 核心来回切换,这样各个核心的缓存命中率就会受到影响,于是要想提高线程的缓存命中率,可以考虑把线程绑定 CPU 到某一个 CPU 核心。
CPU缓存一致性
CPU Cache 的数据写入
随着时间的推移,CPU 和内存的访问性能相差越来越大,于是就在 CPU 内部嵌入了 CPU Cache(高速缓存),CPU Cache 离 CPU 核心相当近,因此它的访问速度是很快的,于是它充当了 CPU 与内存之间的缓存角色。
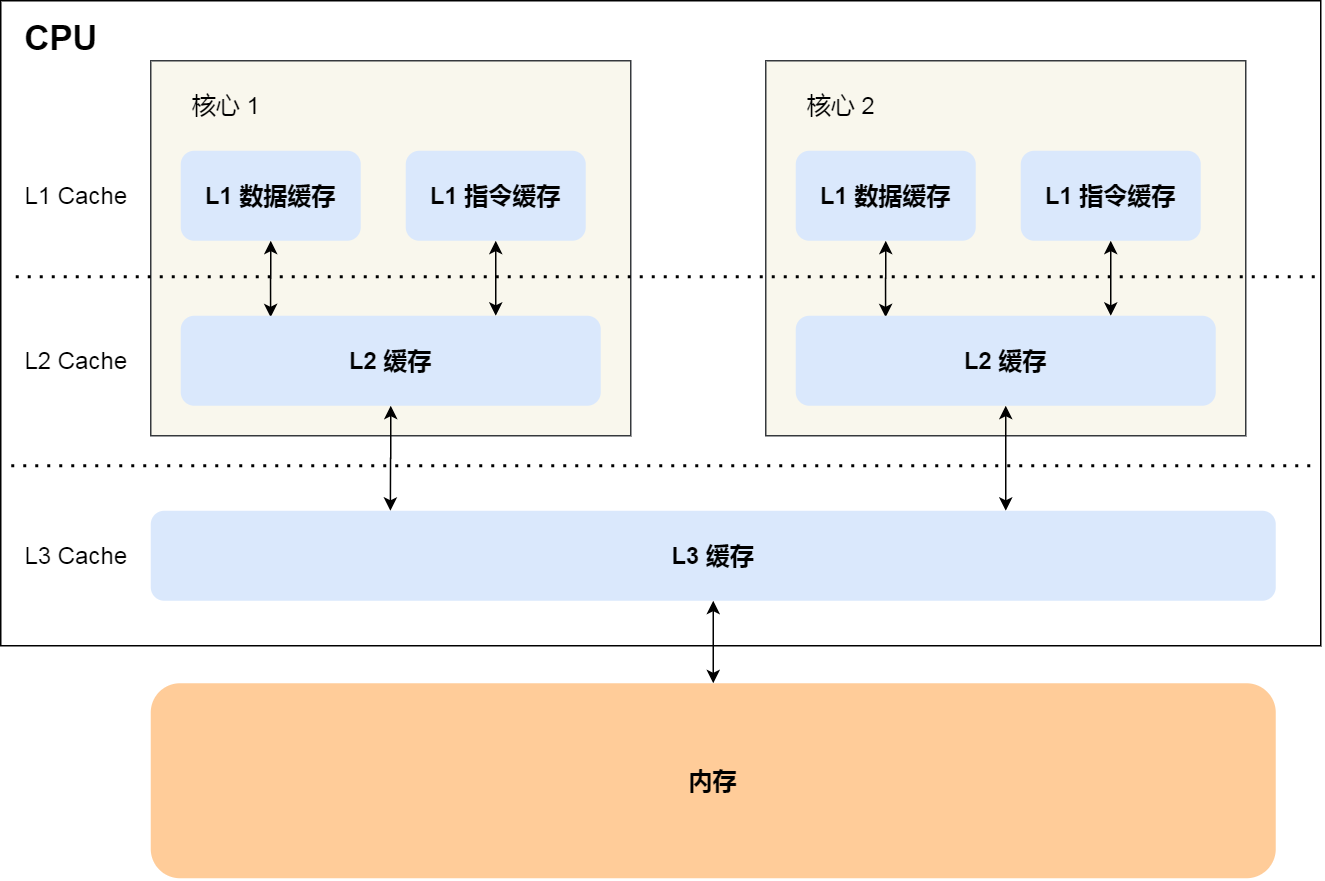
CPU Cache 通常分为三级缓存:L1 Cache、L2 Cache、L3 Cache,级别越低的离 CPU 核心越近,访问速度也快,但是存储容量相对就会越小。其中,在多核心的 CPU 里,每个核心都有各自的 L1/L2 Cache,而 L3 Cache 是所有核心共享使用的。
我们先简单了解下 CPU Cache 的结构,CPU Cache 是由很多个 Cache Line 组成的,CPU Line 是 CPU 从内存读取数据的基本单位,而 CPU Line 是由各种标志(Tag)+ 数据块(Data Block)组成,你可以在下图清晰的看到:
我们当然期望 CPU 读取数据的时候,都是尽可能地从 CPU Cache 中读取,而不是每一次都要从内存中获取数据。所以,身为程序员,我们要尽可能写出缓存命中率高的代码,这样就有效提高程序的性能,具体的做法,你可以参考我上一篇文章「如何写出让 CPU 跑得更快的代码?」(opens new window)
事实上,数据不光是只有读操作,还有写操作,那么如果数据写入 Cache 之后,内存与 Cache 相对应的数据将会不同,这种情况下 Cache 和内存数据都不一致了,于是我们肯定是要把 Cache 中的数据同步到内存里的。
问题来了,那在什么时机才把 Cache 中的数据写回到内存呢?为了应对这个问题,下面介绍两种针对写入数据的方法:
- 写直达(Write Through)
- 写回(Write Back)
写直达
保持内存与 Cache 一致性最简单的方式是,把数据同时写入内存和 Cache 中,这种方法称为写直达(*Write Through*)。
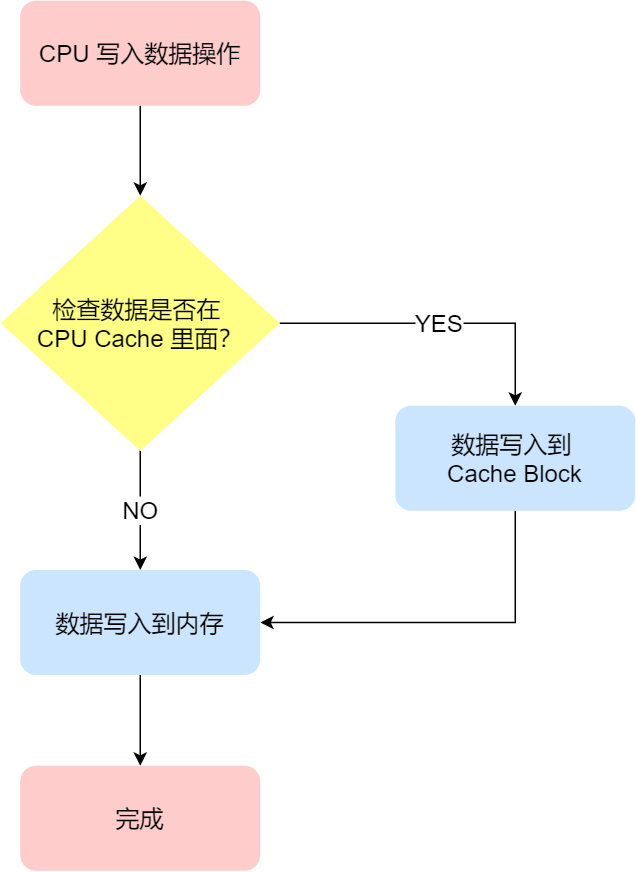
在这个方法里,写入前会先判断数据是否已经在 CPU Cache 里面了:
- 如果数据已经在 Cache 里面,先将数据更新到 Cache 里面,再写入到内存里面;
- 如果数据没有在 Cache 里面,就直接把数据更新到内存里面。
写直达法很直观,也很简单,但是问题明显,无论数据在不在 Cache 里面,每次写操作都会写回到内存,这样写操作将会花费大量的时间,无疑性能会受到很大的影响。
写回
既然写直达由于每次写操作都会把数据写回到内存,而导致影响性能,于是为了要减少数据写回内存的频率,就出现了写回(*Write Back*)的方法。
在写回机制中,当发生写操作时,新的数据仅仅被写入 Cache Block 里,只有当修改过的 Cache Block「被替换」时才需要写到内存中,减少了数据写回内存的频率,这样便可以提高系统的性能。
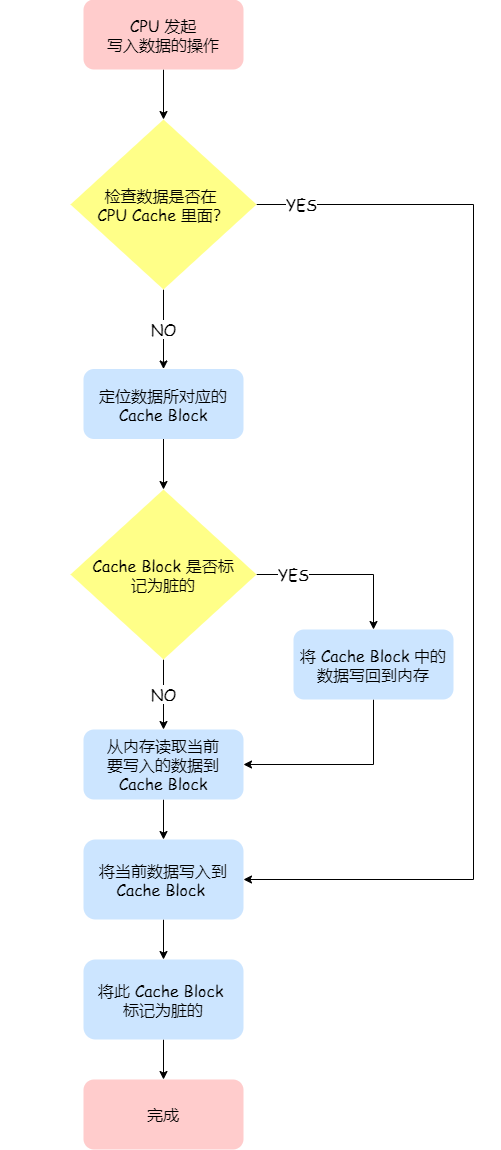
那具体如何做到的呢?下面来详细说一下:
- 如果当发生写操作时,数据已经在 CPU Cache 里的话,则把数据更新到 CPU Cache 里,同时标记 CPU Cache 里的这个 Cache Block 为脏(Dirty)的,这个脏的标记代表这个时候,我们 CPU Cache 里面的这个 Cache Block 的数据和内存是不一致的,这种情况是不用把数据写到内存里的;
- 如果当发生写操作时,数据所对应的 Cache Block 里存放的是「别的内存地址的数据」的话,就要检查这个 Cache Block 里的数据有没有被标记为脏的:
- 如果是脏的话,我们就要把这个 Cache Block 里的数据写回到内存,然后再把当前要写入的数据,先从内存读入到 Cache Block 里(注意,这一步不是没用的,具体为什么要这一步,可以看这个「回答 (opens new window)」),然后再把当前要写入的数据写入到 Cache Block,最后也把它标记为脏的;
- 如果不是脏的话,把当前要写入的数据先从内存读入到 Cache Block 里,接着将数据写入到这个 Cache Block 里,然后再把这个 Cache Block 标记为脏的就好了。
可以发现写回这个方法,在把数据写入到 Cache 的时候,只有在缓存不命中,同时数据对应的 Cache 中的 Cache Block 为脏标记的情况下,才会将数据写到内存中,而在缓存命中的情况下,则在写入后 Cache 后,只需把该数据对应的 Cache Block 标记为脏即可,而不用写到内存里。
这样的好处是,如果我们大量的操作都能够命中缓存,那么大部分时间里 CPU 都不需要读写内存,自然性能相比写直达会高很多。
为什么缓存没命中时,还要定位 Cache Block?这是因为此时是要判断数据即将写入到 cache block 里的位置,是否被「其他数据」占用了此位置,如果这个「其他数据」是脏数据,那么就要帮忙把它写回到内存。
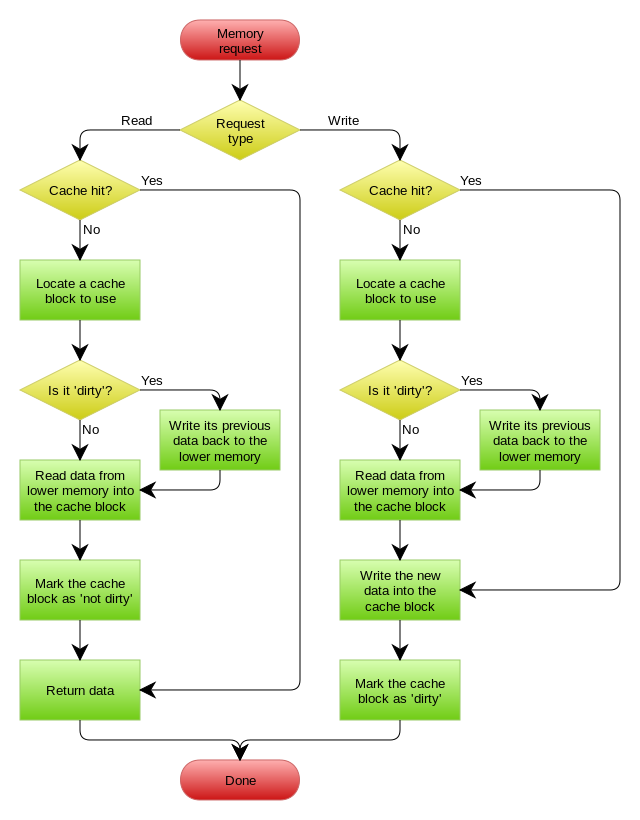
CPU 缓存与内存使用「写回」机制的流程图如下,左半部分就是读操作的流程,右半部分就是写操作的流程,也就是我们上面讲的内容。
缓存一致性问题
现在 CPU 都是多核的,由于 L1/L2 Cache 是多个核心各自独有的,那么会带来多核心的缓存一致性(*Cache Coherence*) 的问题,如果不能保证缓存一致性的问题,就可能造成结果错误。
那缓存一致性的问题具体是怎么发生的呢?我们以一个含有两个核心的 CPU 作为例子看一看。
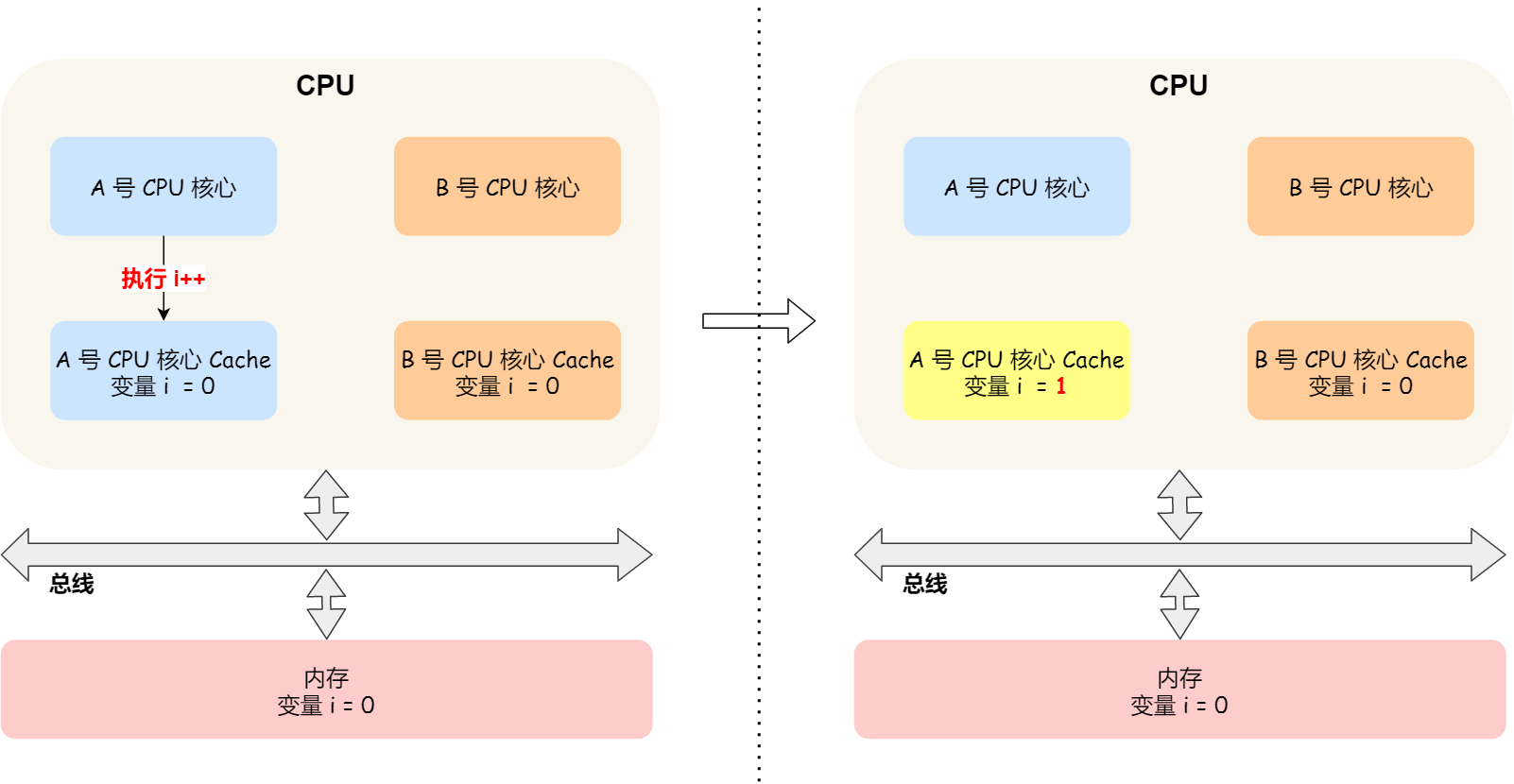
假设 A 号核心和 B 号核心同时运行两个线程,都操作共同的变量 i(初始值为 0 )。
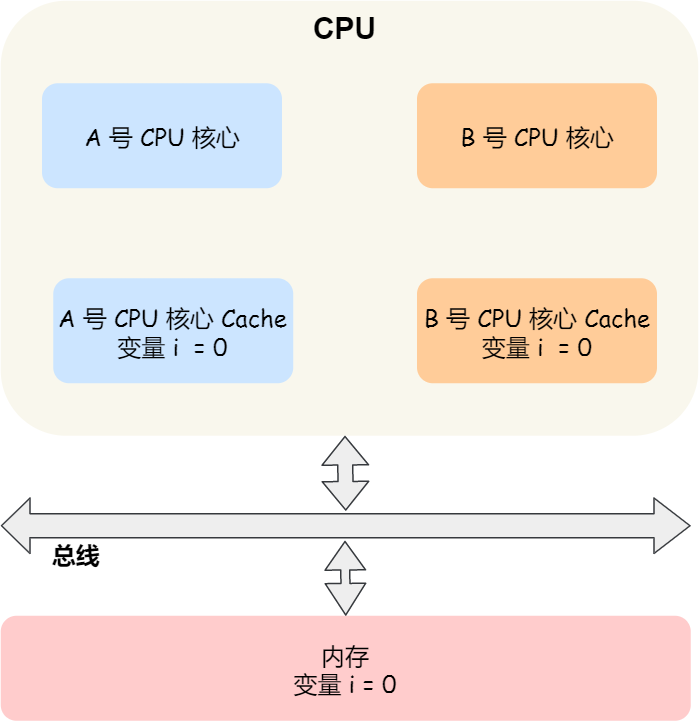
这时如果 A 号核心执行了 i++ 语句的时候,为了考虑性能,使用了我们前面所说的写回策略,先把值为 1 的执行结果写入到 L1/L2 Cache 中,然后把 L1/L2 Cache 中对应的 Block 标记为脏的,这个时候数据其实没有被同步到内存中的,因为写回策略,只有在 A 号核心中的这个 Cache Block 要被替换的时候,数据才会写入到内存里。
如果这时旁边的 B 号核心尝试从内存读取 i 变量的值,则读到的将会是错误的值,因为刚才 A 号核心更新 i 值还没写入到内存中,内存中的值还依然是 0。这个就是所谓的缓存一致性问题,A 号核心和 B 号核心的缓存,在这个时候是不一致,从而会导致执行结果的错误。
那么,要解决这一问题,就需要一种机制,来同步两个不同核心里面的缓存数据。要实现的这个机制的话,要保证做到下面这 2 点:
- 第一点,某个 CPU 核心里的 Cache 数据更新时,必须要传播到其他核心的 Cache,这个称为写传播(*Write Propagation*);
- 第二点,某个 CPU 核心里对数据的操作顺序,必须在其他核心看起来顺序是一样的,这个称为事务的串行化(*Transaction Serialization*)。
第一点写传播很容易就理解,当某个核心在 Cache 更新了数据,就需要同步到其他核心的 Cache 里。而对于第二点事务的串行化,我们举个例子来理解它。
假设我们有一个含有 4 个核心的 CPU,这 4 个核心都操作共同的变量 i(初始值为 0 )。A 号核心先把 i 值变为 100,而此时同一时间,B 号核心先把 i 值变为 200,这里两个修改,都会「传播」到 C 和 D 号核心。
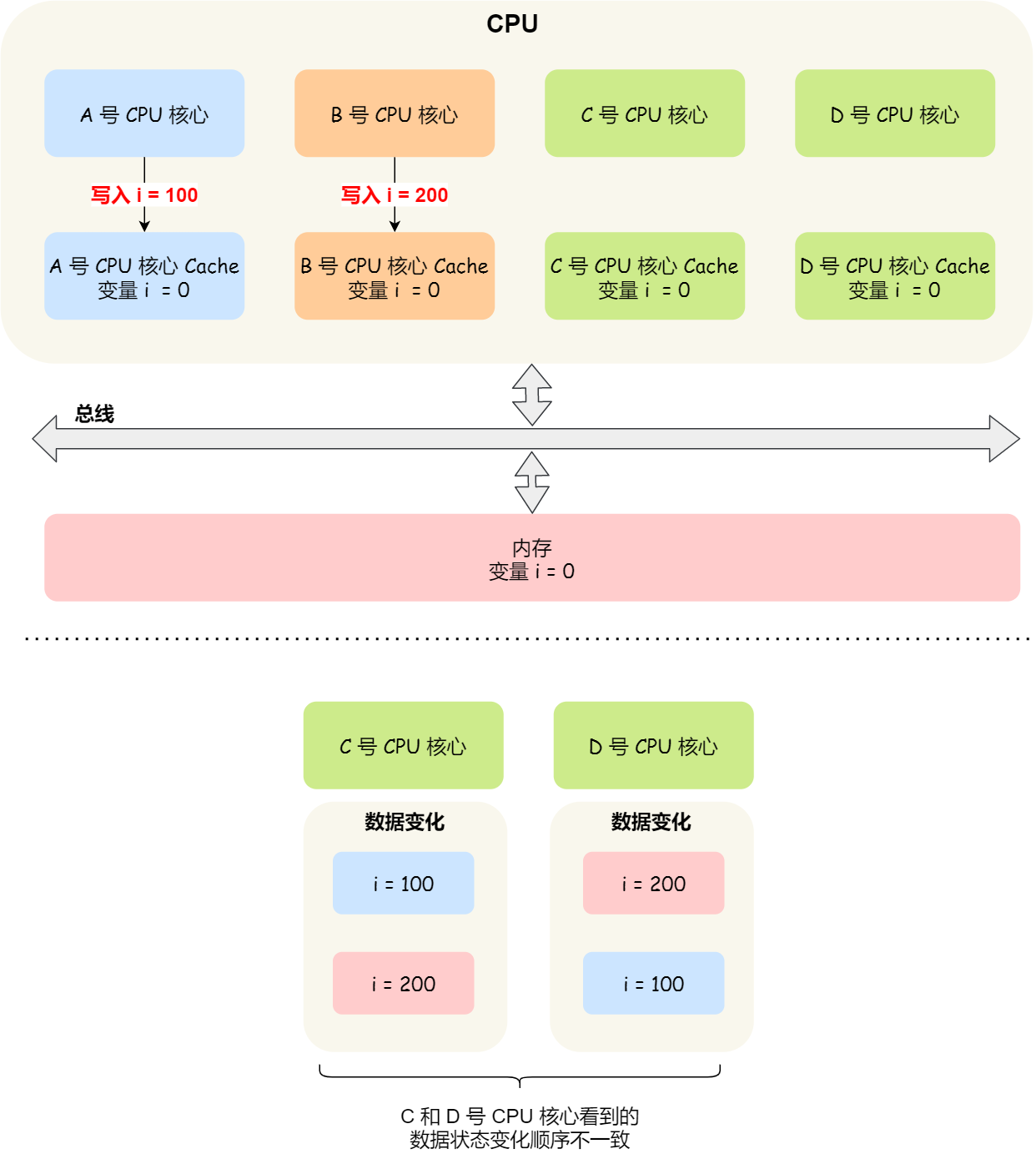
那么问题就来了,C 号核心先收到了 A 号核心更新数据的事件,再收到 B 号核心更新数据的事件,因此 C 号核心看到的变量 i 是先变成 100,后变成 200。
而如果 D 号核心收到的事件是反过来的,则 D 号核心看到的是变量 i 先变成 200,再变成 100,虽然是做到了写传播,但是各个 Cache 里面的数据还是不一致的。
所以,我们要保证 C 号核心和 D 号核心都能看到相同顺序的数据变化,比如变量 i 都是先变成 100,再变成 200,这样的过程就是事务的串行化。
要实现事务串行化,要做到 2 点:
- CPU 核心对于 Cache 中数据的操作,需要同步给其他 CPU 核心;
- 要引入「锁」的概念,如果两个 CPU 核心里有相同数据的 Cache,那么对于这个 Cache 数据的更新,只有拿到了「锁」,才能进行对应的数据更新。
那接下来我们看看,写传播和事务串行化具体是用什么技术实现的。
总线嗅探
写传播的原则就是当某个 CPU 核心更新了 Cache 中的数据,要把该事件广播通知到其他核心。最常见实现的方式是总线嗅探(*Bus Snooping*)。
我还是以前面的 i 变量例子来说明总线嗅探的工作机制,当 A 号 CPU 核心修改了 L1 Cache 中 i 变量的值,通过总线把这个事件广播通知给其他所有的核心,然后每个 CPU 核心都会监听总线上的广播事件,并检查是否有相同的数据在自己的 L1 Cache 里面,如果 B 号 CPU 核心的 L1 Cache 中有该数据,那么也需要把该数据更新到自己的 L1 Cache。
可以发现,总线嗅探方法很简单, CPU 需要每时每刻监听总线上的一切活动,但是不管别的核心的 Cache 是否缓存相同的数据,都需要发出一个广播事件,这无疑会加重总线的负载。
另外,总线嗅探只是保证了某个 CPU 核心的 Cache 更新数据这个事件能被其他 CPU 核心知道,但是并不能保证事务串行化。
于是,有一个协议基于总线嗅探机制实现了事务串行化,也用状态机机制降低了总线带宽压力,这个协议就是 MESI 协议,这个协议就做到了 CPU 缓存一致性。
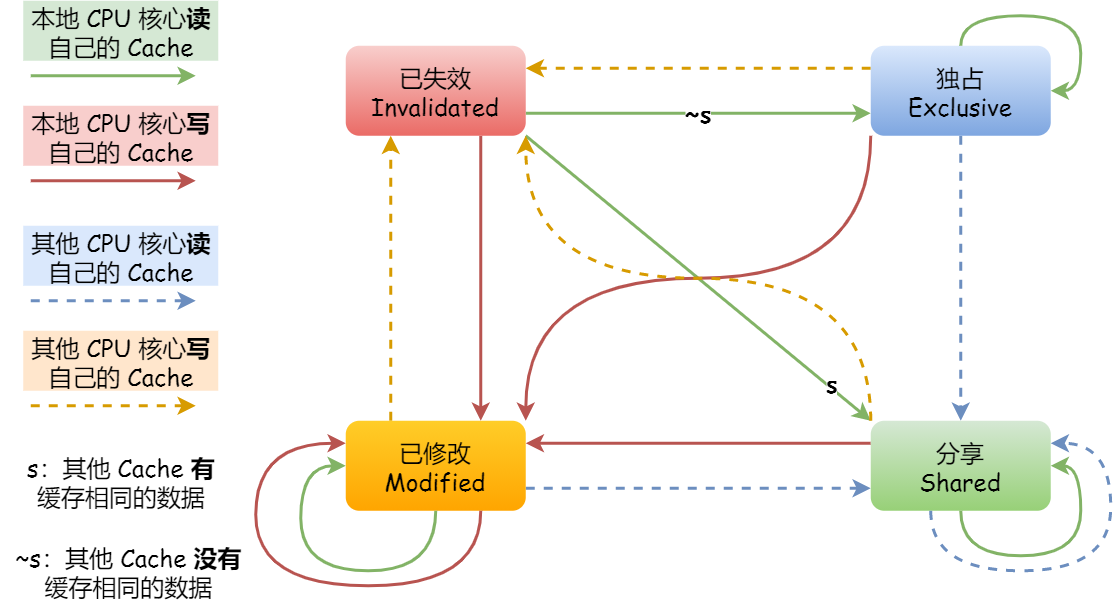
MESI 协议
MESI 协议其实是 4 个状态单词的开头字母缩写,分别是:
- Modified,已修改
- Exclusive,独占
- Shared,共享
- Invalidated,已失效
这四个状态来标记 Cache Line 四个不同的状态。
「已修改」状态就是我们前面提到的脏标记,代表该 Cache Block 上的数据已经被更新过,但是还没有写到内存里。而「已失效」状态,表示的是这个 Cache Block 里的数据已经失效了,不可以读取该状态的数据。
「独占」和「共享」状态都代表 Cache Block 里的数据是干净的,也就是说,这个时候 Cache Block 里的数据和内存里面的数据是一致性的。
「独占」和「共享」的差别在于,独占状态的时候,数据只存储在一个 CPU 核心的 Cache 里,而其他 CPU 核心的 Cache 没有该数据。这个时候,如果要向独占的 Cache 写数据,就可以直接自由地写入,而不需要通知其他 CPU 核心,因为只有你这有这个数据,就不存在缓存一致性的问题了,于是就可以随便操作该数据。
另外,在「独占」状态下的数据,如果有其他核心从内存读取了相同的数据到各自的 Cache ,那么这个时候,独占状态下的数据就会变成共享状态。
那么,「共享」状态代表着相同的数据在多个 CPU 核心的 Cache 里都有,所以当我们要更新 Cache 里面的数据的时候,不能直接修改,而是要先向所有的其他 CPU 核心广播一个请求,要求先把其他核心的 Cache 中对应的 Cache Line 标记为「无效」状态,然后再更新当前 Cache 里面的数据。
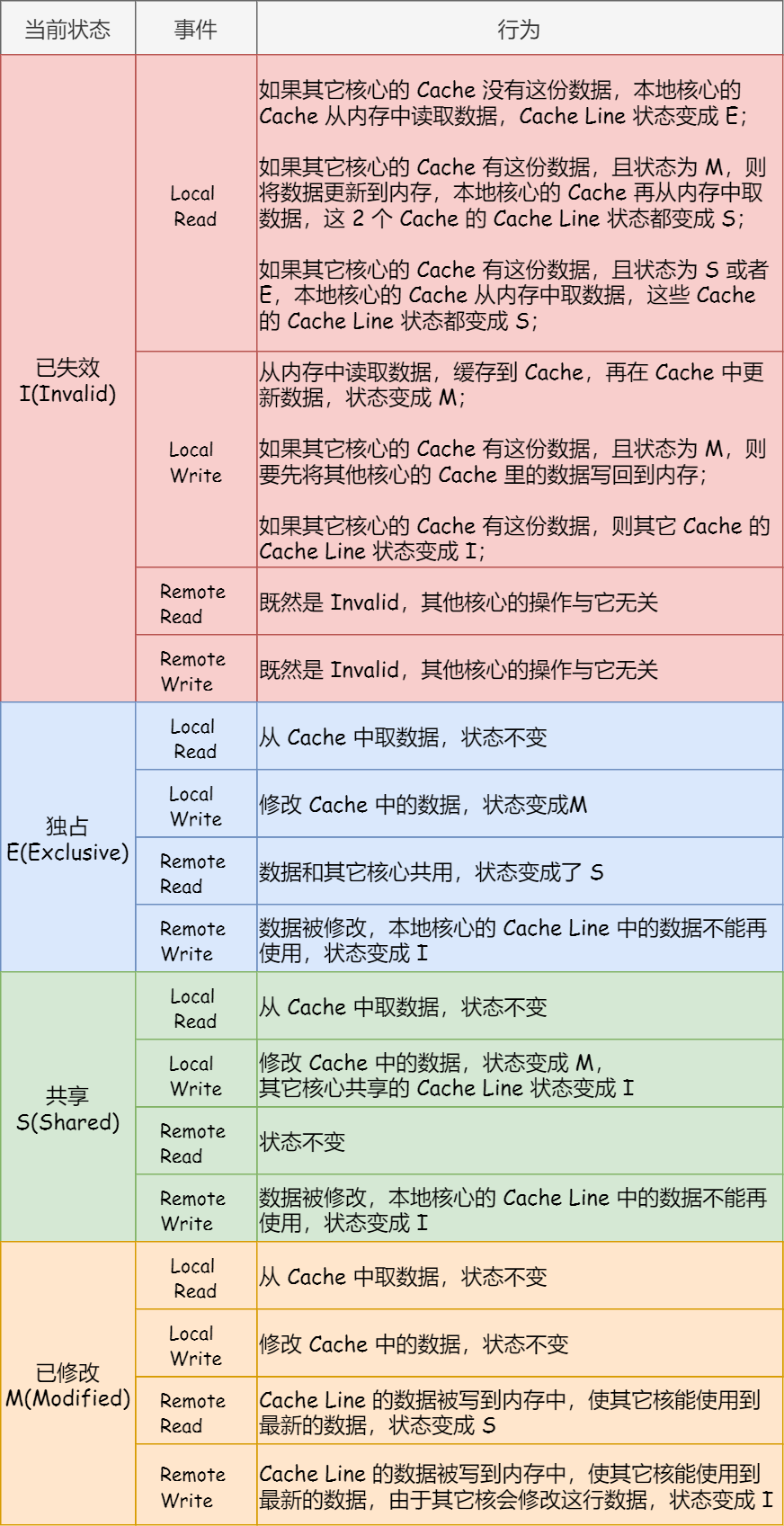
我们举个具体的例子来看看这四个状态的转换:
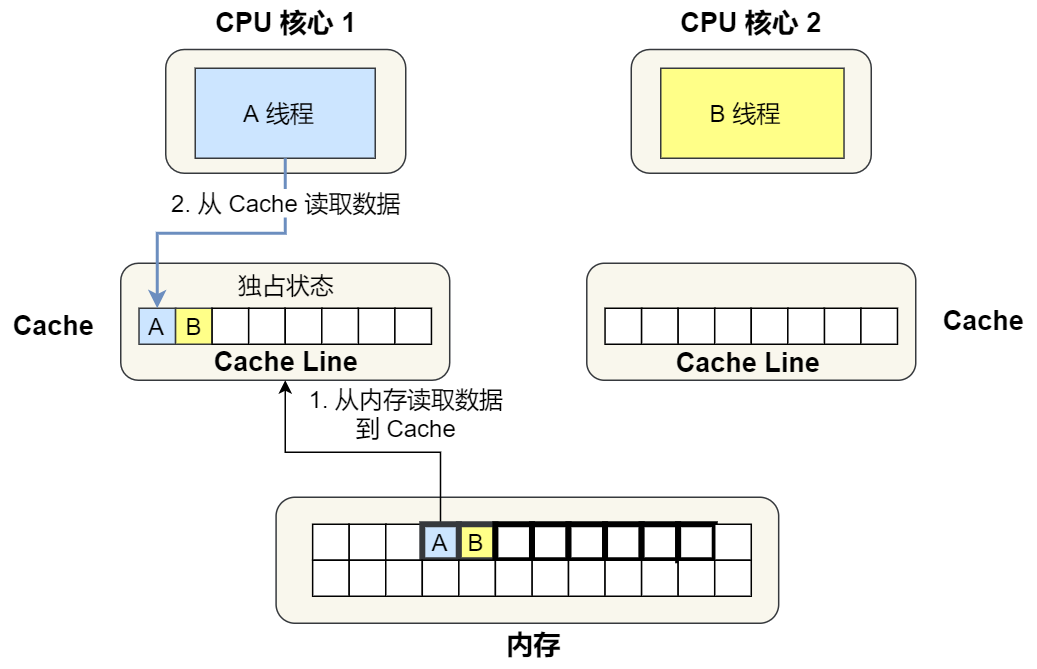
- 当 A 号 CPU 核心从内存读取变量 i 的值,数据被缓存在 A 号 CPU 核心自己的 Cache 里面,此时其他 CPU 核心的 Cache 没有缓存该数据,于是标记 Cache Line 状态为「独占」,此时其 Cache 中的数据与内存是一致的;
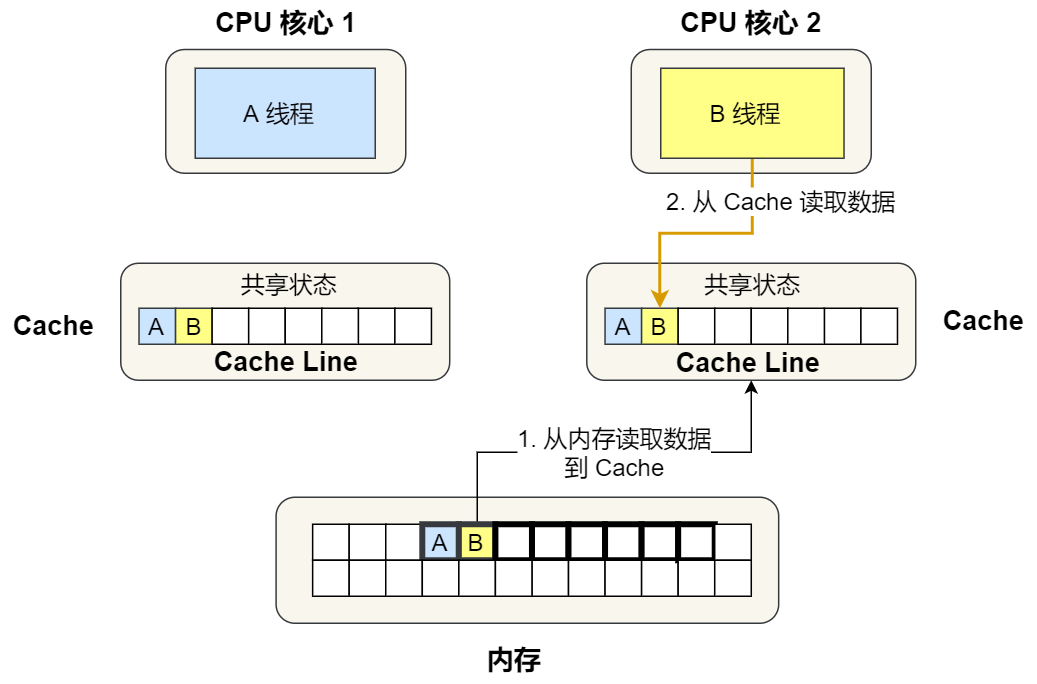
- 然后 B 号 CPU 核心也从内存读取了变量 i 的值,此时会发送消息给其他 CPU 核心,由于 A 号 CPU 核心已经缓存了该数据,所以会把数据返回给 B 号 CPU 核心。在这个时候, A 和 B 核心缓存了相同的数据,Cache Line 的状态就会变成「共享」,并且其 Cache 中的数据与内存也是一致的;
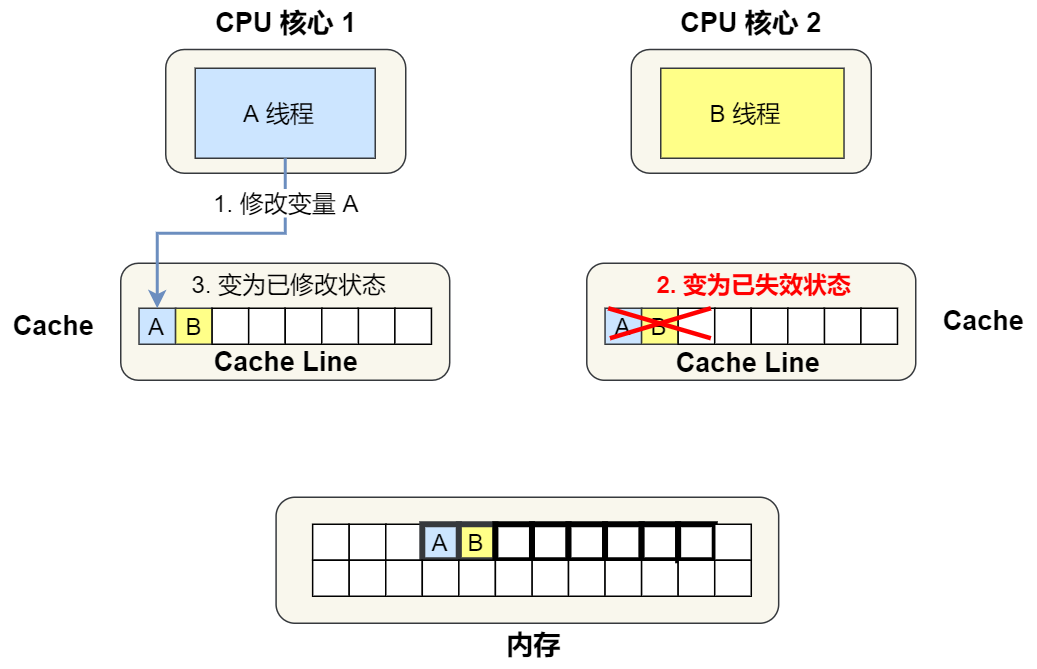
- 当 A 号 CPU 核心要修改 Cache 中 i 变量的值,发现数据对应的 Cache Line 的状态是共享状态,则要向所有的其他 CPU 核心广播一个请求,要求先把其他核心的 Cache 中对应的 Cache Line 标记为「无效」状态,然后 A 号 CPU 核心才更新 Cache 里面的数据,同时标记 Cache Line 为「已修改」状态,此时 Cache 中的数据就与内存不一致了。
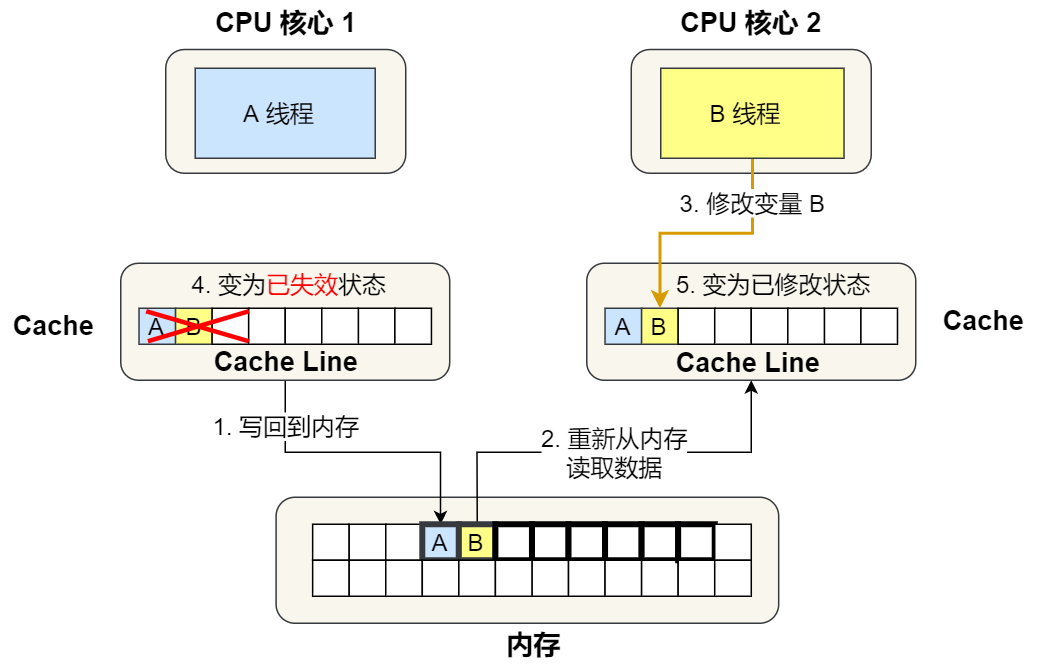
- 如果 A 号 CPU 核心「继续」修改 Cache 中 i 变量的值,由于此时的 Cache Line 是「已修改」状态,因此不需要给其他 CPU 核心发送消息,直接更新数据即可。
- 如果 A 号 CPU 核心的 Cache 里的 i 变量对应的 Cache Line 要被「替换」,发现 Cache Line 状态是「已修改」状态,就会在替换前先把数据同步到内存。
所以,可以发现当 Cache Line 状态是「已修改」或者「独占」状态时,修改更新其数据不需要发送广播给其他 CPU 核心,这在一定程度上减少了总线带宽压力。
事实上,整个 MESI 的状态可以用一个有限状态机来表示它的状态流转。还有一点,对于不同状态触发的事件操作,可能是来自本地 CPU 核心发出的广播事件,也可以是来自其他 CPU 核心通过总线发出的广播事件。下图即是 MESI 协议的状态图:
MESI 协议的四种状态之间的流转过程,我汇总成了下面的表格,你可以更详细的看到每个状态转换的原因:
总结
CPU 在读写数据的时候,都是在 CPU Cache 读写数据的,原因是 Cache 离 CPU 很近,读写性能相比内存高出很多。对于 Cache 里没有缓存 CPU 所需要读取的数据的这种情况,CPU 则会从内存读取数据,并将数据缓存到 Cache 里面,最后 CPU 再从 Cache 读取数据。
而对于数据的写入,CPU 都会先写入到 Cache 里面,然后再在找个合适的时机写入到内存,那就有「写直达」和「写回」这两种策略来保证 Cache 与内存的数据一致性:
- 写直达,只要有数据写入,都会直接把数据写入到内存里面,这种方式简单直观,但是性能就会受限于内存的访问速度;
- 写回,对于已经缓存在 Cache 的数据的写入,只需要更新其数据就可以,不用写入到内存,只有在需要把缓存里面的脏数据交换出去的时候,才把数据同步到内存里,这种方式在缓存命中率高的情况,性能会更好;
当今 CPU 都是多核的,每个核心都有各自独立的 L1/L2 Cache,只有 L3 Cache 是多个核心之间共享的。所以,我们要确保多核缓存是一致性的,否则会出现错误的结果。
要想实现缓存一致性,关键是要满足 2 点:
- 第一点是写传播,也就是当某个 CPU 核心发生写入操作时,需要把该事件广播通知给其他核心;
- 第二点是事物的串行化,这个很重要,只有保证了这个,才能保障我们的数据是真正一致的,我们的程序在各个不同的核心上运行的结果也是一致的;
基于总线嗅探机制的 MESI 协议,就满足上面了这两点,因此它是保障缓存一致性的协议。
MESI 协议,是已修改、独占、共享、已失效这四个状态的英文缩写的组合。整个 MSI 状态的变更,则是根据来自本地 CPU 核心的请求,或者来自其他 CPU 核心通过总线传输过来的请求,从而构成一个流动的状态机。另外,对于在「已修改」或者「独占」状态的 Cache Line,修改更新其数据不需要发送广播给其他 CPU 核心。
CPU是如何执行任务的?
你清楚下面这几个问题吗?
- 有了内存,为什么还需要 CPU Cache?
- CPU 是怎么读写数据的?
- 如何让 CPU 能读取数据更快一些?
- CPU 伪共享是如何发生的?又该如何避免?
- CPU 是如何调度任务的?如果你的任务对响应要求很高,你希望它总是能被先调度,这该怎么办?
- …
这篇,我们就来回答这些问题。
CPU 如何读写数据的?
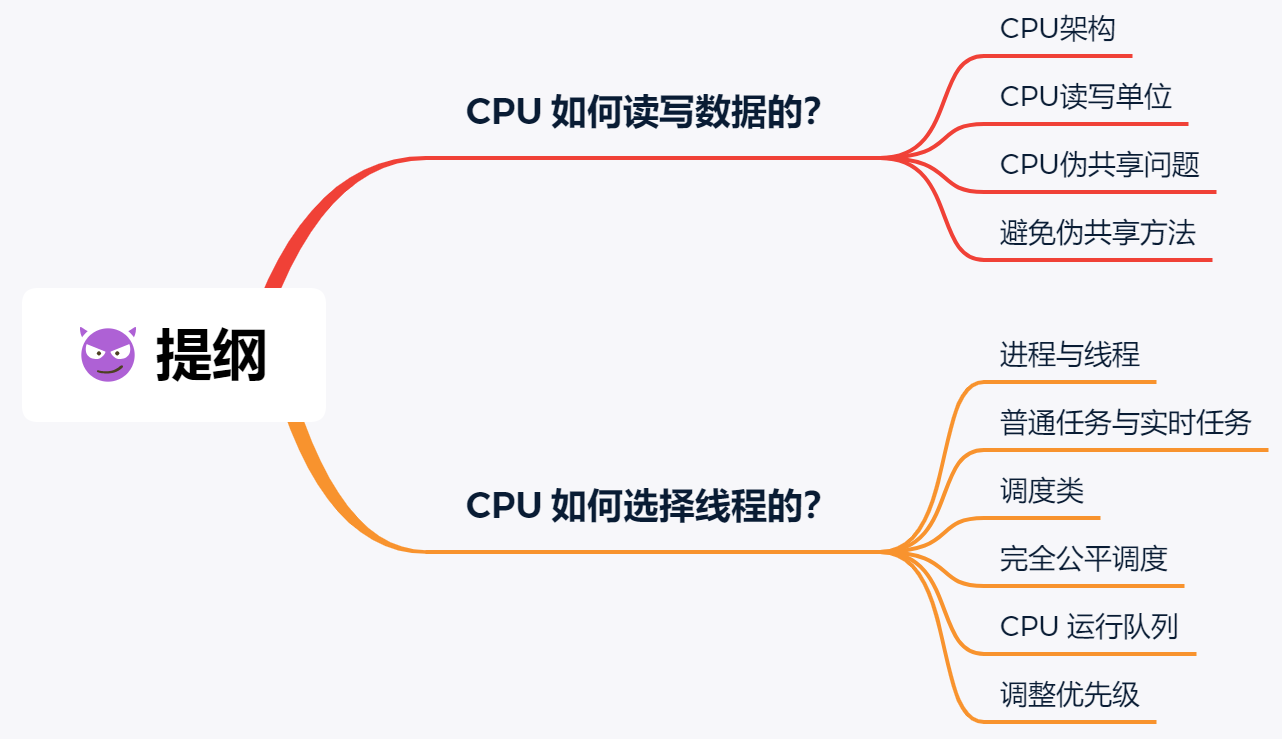
先来认识 CPU 的架构,只有理解了 CPU 的架构,才能更好地理解 CPU 是如何读写数据的,对于现代 CPU 的架构图如下:
可以看到,一个 CPU 里通常会有多个 CPU 核心,比如上图中的 1 号和 2 号 CPU 核心,并且每个 CPU 核心都有自己的 L1 Cache 和 L2 Cache,而 L1 Cache 通常分为 dCache(数据缓存) 和 iCache(指令缓存),L3 Cache 则是多个核心共享的,这就是 CPU 典型的缓存层次。
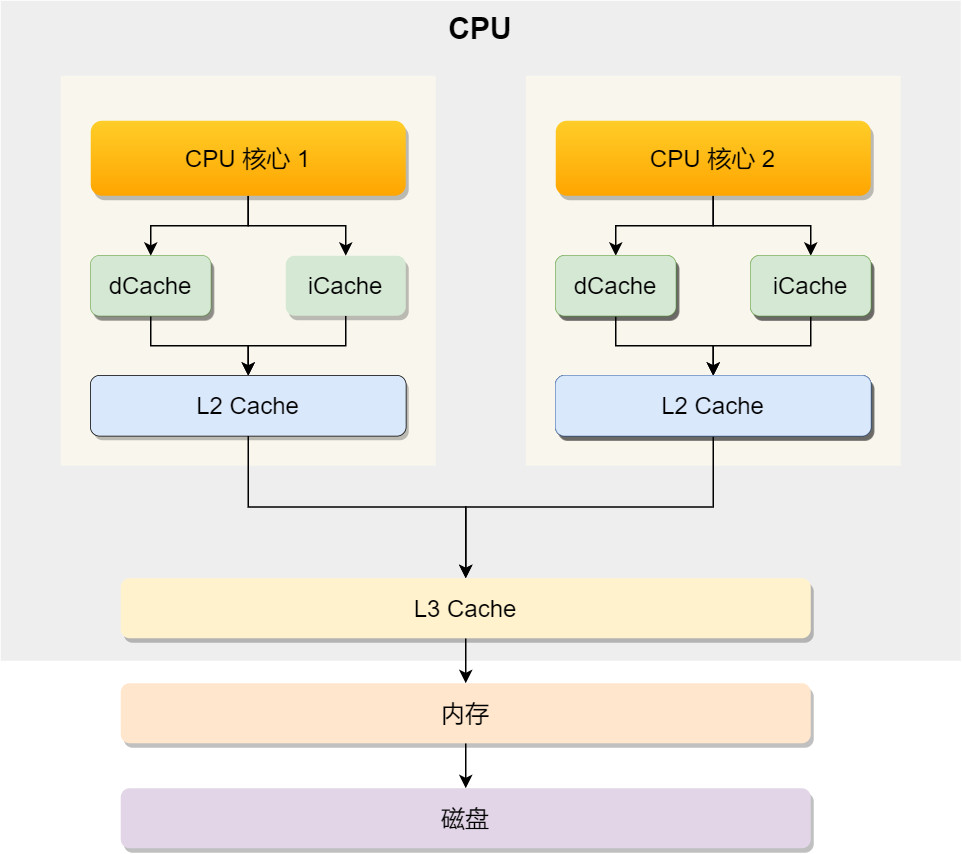
上面提到的都是 CPU 内部的 Cache,放眼外部的话,还会有内存和硬盘,这些存储设备共同构成了金字塔存储层次。如下图所示:
从上图也可以看到,从上往下,存储设备的容量会越大,而访问速度会越慢。至于每个存储设备的访问延时,你可以看下图的表格:
你可以看到, CPU 访问 L1 Cache 速度比访问内存快 100 倍,这就是为什么 CPU 里会有 L1~L3 Cache 的原因,目的就是把 Cache 作为 CPU 与内存之间的缓存层,以减少对内存的访问频率。
CPU 从内存中读取数据到 Cache 的时候,并不是一个字节一个字节读取,而是一块一块的方式来读取数据的,这一块一块的数据被称为 CPU Cache Line(缓存块),所以 CPU Cache Line 是 CPU 从内存读取数据到 Cache 的单位。
至于 CPU Cache Line 大小,在 Linux 系统可以用下面的方式查看到,你可以看我服务器的 L1 Cache Line 大小是 64 字节,也就意味着 L1 Cache 一次载入数据的大小是 64 字节。
那么对数组的加载, CPU 就会加载数组里面连续的多个数据到 Cache 里,因此我们应该按照物理内存地址分布的顺序去访问元素,这样访问数组元素的时候,Cache 命中率就会很高,于是就能减少从内存读取数据的频率, 从而可提高程序的性能。
但是,在我们不使用数组,而是使用单独的变量的时候,则会有 Cache 伪共享的问题,Cache 伪共享问题上是一个性能杀手,我们应该要规避它。
接下来,就来看看 Cache 伪共享是什么?又如何避免这个问题?
现在假设有一个双核心的 CPU,这两个 CPU 核心并行运行着两个不同的线程,它们同时从内存中读取两个不同的数据,分别是类型为 long 的变量 A 和 B,这个两个数据的地址在物理内存上是连续的,如果 Cahce Line 的大小是 64 字节,并且变量 A 在 Cahce Line 的开头位置,那么这两个数据是位于同一个 Cache Line 中,又因为 CPU Cache Line 是 CPU 从内存读取数据到 Cache 的单位,所以这两个数据会被同时读入到了两个 CPU 核心中各自 Cache 中。
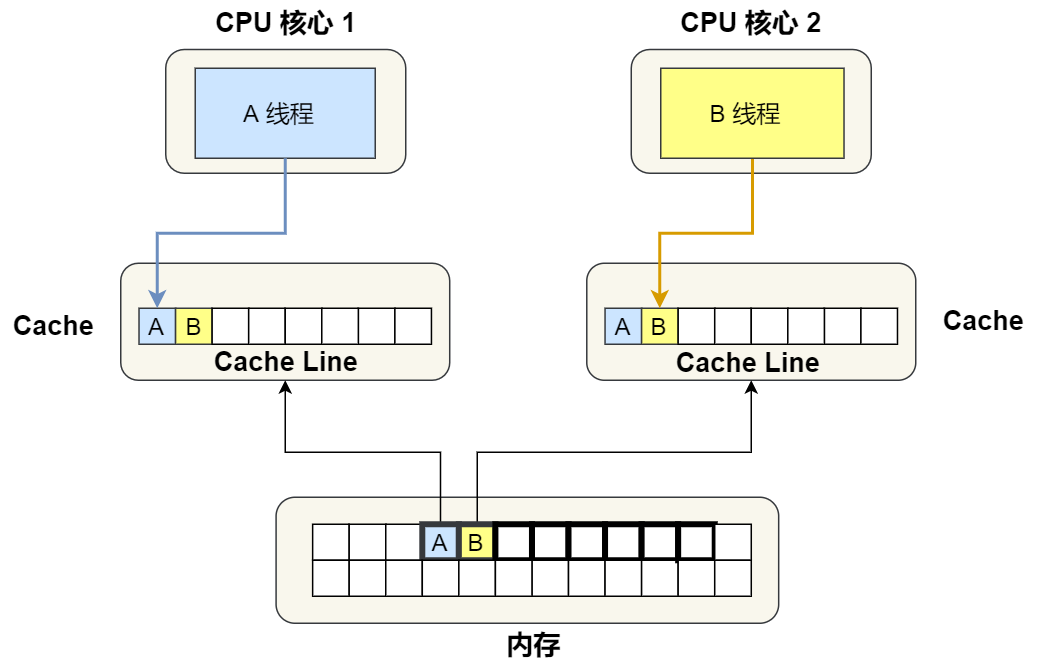
我们来思考一个问题,如果这两个不同核心的线程分别修改不同的数据,比如 1 号 CPU 核心的线程只修改了 变量 A,或 2 号 CPU 核心的线程的线程只修改了变量 B,会发生什么呢?
分析伪共享的问题
现在我们结合保证多核缓存一致的 MESI 协议,来说明这一整个的过程,如果你还不知道 MESI 协议,你可以看我这篇文章「10 张图打开 CPU 缓存一致性的大门 (opens new window)」。
①. 最开始变量 A 和 B 都还不在 Cache 里面,假设 1 号核心绑定了线程 A,2 号核心绑定了线程 B,线程 A 只会读写变量 A,线程 B 只会读写变量 B。
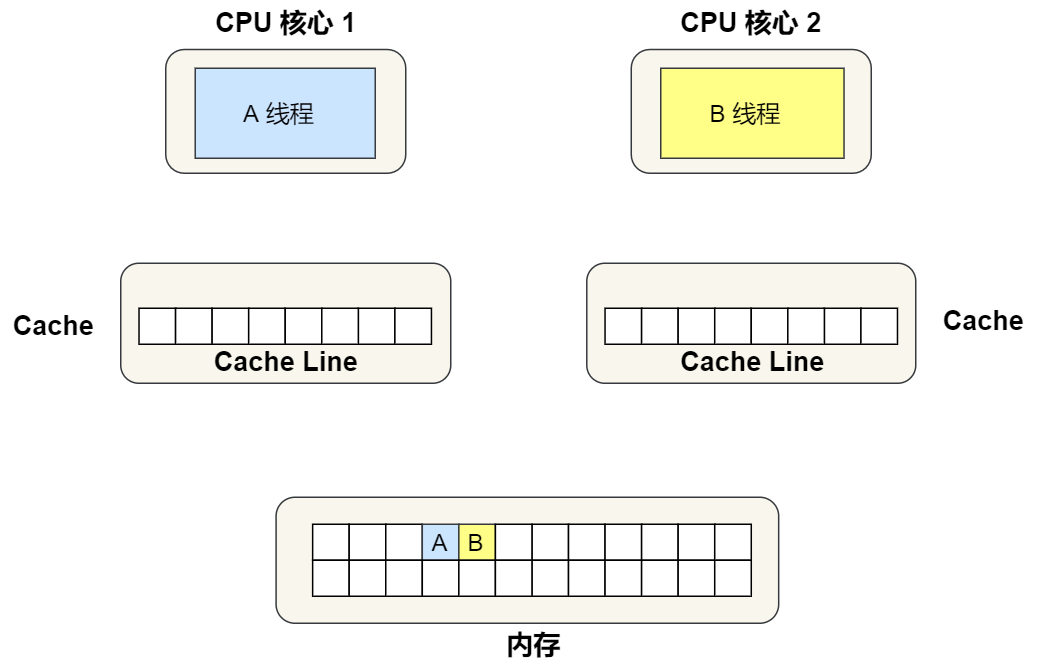
②. 1 号核心读取变量 A,由于 CPU 从内存读取数据到 Cache 的单位是 Cache Line,也正好变量 A 和 变量 B 的数据归属于同一个 Cache Line,所以 A 和 B 的数据都会被加载到 Cache,并将此 Cache Line 标记为「独占」状态。
③. 接着,2 号核心开始从内存里读取变量 B,同样的也是读取 Cache Line 大小的数据到 Cache 中,此 Cache Line 中的数据也包含了变量 A 和 变量 B,此时 1 号和 2 号核心的 Cache Line 状态变为「共享」状态。
④. 1 号核心需要修改变量 A,发现此 Cache Line 的状态是「共享」状态,所以先需要通过总线发送消息给 2 号核心,通知 2 号核心把 Cache 中对应的 Cache Line 标记为「已失效」状态,然后 1 号核心对应的 Cache Line 状态变成「已修改」状态,并且修改变量 A。
⑤. 之后,2 号核心需要修改变量 B,此时 2 号核心的 Cache 中对应的 Cache Line 是已失效状态,另外由于 1 号核心的 Cache 也有此相同的数据,且状态为「已修改」状态,所以要先把 1 号核心的 Cache 对应的 Cache Line 写回到内存,然后 2 号核心再从内存读取 Cache Line 大小的数据到 Cache 中,最后把变量 B 修改到 2 号核心的 Cache 中,并将状态标记为「已修改」状态。
所以,可以发现如果 1 号和 2 号 CPU 核心这样持续交替的分别修改变量 A 和 B,就会重复 ④ 和 ⑤ 这两个步骤,Cache 并没有起到缓存的效果,虽然变量 A 和 B 之间其实并没有任何的关系,但是因为同时归属于一个 Cache Line ,这个 Cache Line 中的任意数据被修改后,都会相互影响,从而出现 ④ 和 ⑤ 这两个步骤。
因此,这种因为多个线程同时读写同一个 Cache Line 的不同变量时,而导致 CPU Cache 失效的现象称为伪共享(*False Sharing*)。
避免伪共享的方法
因此,对于多个线程共享的热点数据,即经常会修改的数据,应该避免这些数据刚好在同一个 Cache Line 中,否则就会出现为伪共享的问题。
接下来,看看在实际项目中是用什么方式来避免伪共享的问题的。
在 Linux 内核中存在 __cacheline_aligned_in_smp 宏定义,是用于解决伪共享的问题。
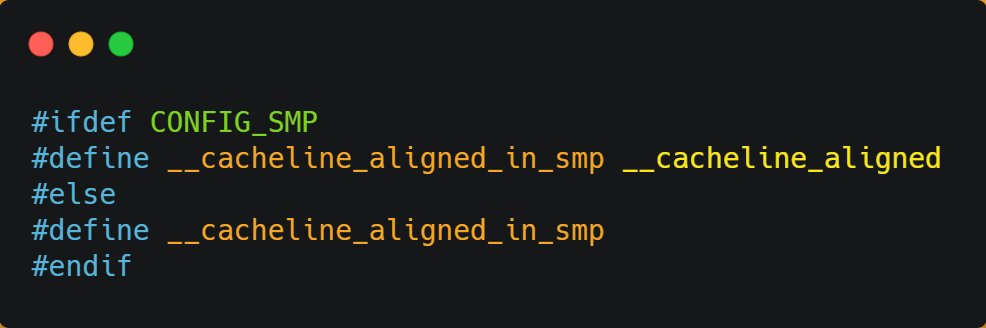
从上面的宏定义,我们可以看到:
- 如果在多核(MP)系统里,该宏定义是
__cacheline_aligned,也就是 Cache Line 的大小; - 而如果在单核系统里,该宏定义是空的;
因此,针对在同一个 Cache Line 中的共享的数据,如果在多核之间竞争比较严重,为了防止伪共享现象的发生,可以采用上面的宏定义使得变量在 Cache Line 里是对齐的。
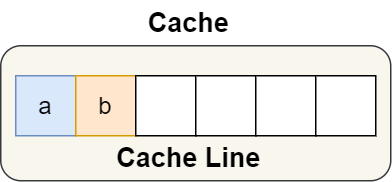
举个例子,有下面这个结构体:

结构体里的两个成员变量 a 和 b 在物理内存地址上是连续的,于是它们可能会位于同一个 Cache Line 中,如下图:
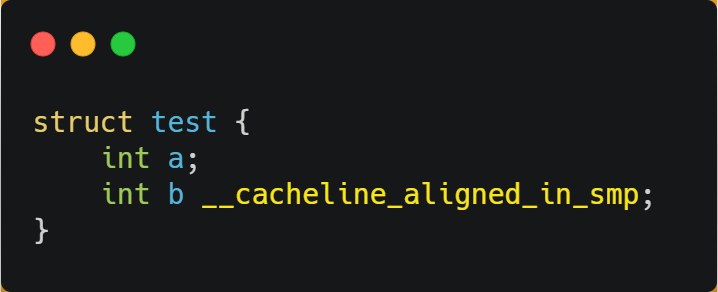
所以,为了防止前面提到的 Cache 伪共享问题,我们可以使用上面介绍的宏定义,将 b 的地址设置为 Cache Line 对齐地址,如下:
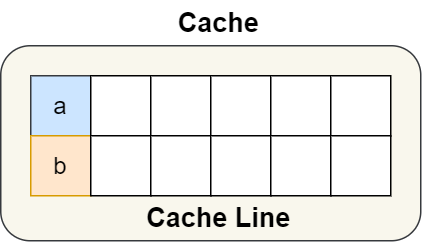
这样 a 和 b 变量就不会在同一个 Cache Line 中了,如下图:
所以,避免 Cache 伪共享实际上是用空间换时间的思想,浪费一部分 Cache 空间,从而换来性能的提升。
我们再来看一个应用层面的规避方案,有一个 Java 并发框架 Disruptor 使用「字节填充 + 继承」的方式,来避免伪共享的问题。
Disruptor 中有一个 RingBuffer 类会经常被多个线程使用,代码如下:
你可能会觉得 RingBufferPad 类里 7 个 long 类型的名字很奇怪,但事实上,它们虽然看起来毫无作用,但却对性能的提升起到了至关重要的作用。
我们都知道,CPU Cache 从内存读取数据的单位是 CPU Cache Line,一般 64 位 CPU 的 CPU Cache Line 的大小是 64 个字节,一个 long 类型的数据是 8 个字节,所以 CPU 一下会加载 8 个 long 类型的数据。
根据 JVM 对象继承关系中父类成员和子类成员,内存地址是连续排列布局的,因此 RingBufferPad 中的 7 个 long 类型数据作为 Cache Line 前置填充,而 RingBuffer 中的 7 个 long 类型数据则作为 Cache Line 后置填充,这 14 个 long 变量没有任何实际用途,更不会对它们进行读写操作。
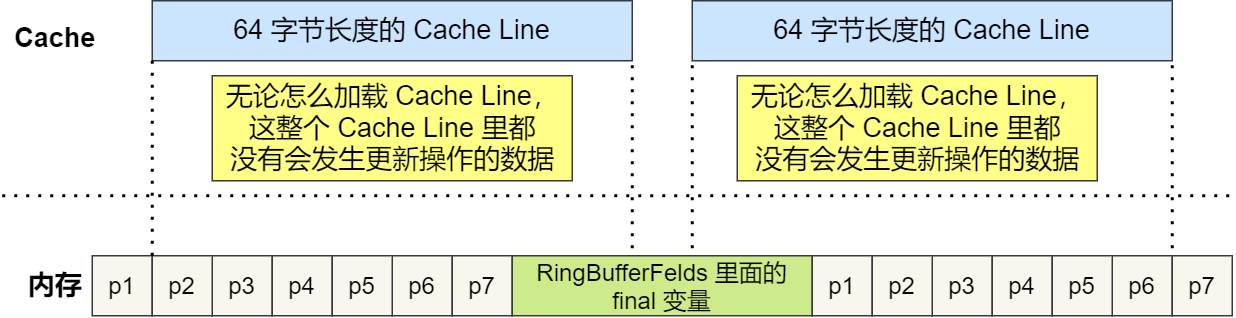
另外,RingBufferFelds 里面定义的这些变量都是 final 修饰的,意味着第一次加载之后不会再修改, 又由于「前后」各填充了 7 个不会被读写的 long 类型变量,所以无论怎么加载 Cache Line,这整个 Cache Line 里都没有会发生更新操作的数据,于是只要数据被频繁地读取访问,就自然没有数据被换出 Cache 的可能,也因此不会产生伪共享的问题。
CPU 如何选择线程的?
了解完 CPU 读取数据的过程后,我们再来看看 CPU 是根据什么来选择当前要执行的线程。
在 Linux 内核中,进程和线程都是用 task_struct 结构体表示的,区别在于线程的 task_struct 结构体里部分资源是共享了进程已创建的资源,比如内存地址空间、代码段、文件描述符等,所以 Linux 中的线程也被称为轻量级进程,因为线程的 task_struct 相比进程的 task_struct 承载的 资源比较少,因此以「轻」得名。
一般来说,没有创建线程的进程,是只有单个执行流,它被称为是主线程。如果想让进程处理更多的事情,可以创建多个线程分别去处理,但不管怎么样,它们对应到内核里都是 task_struct。
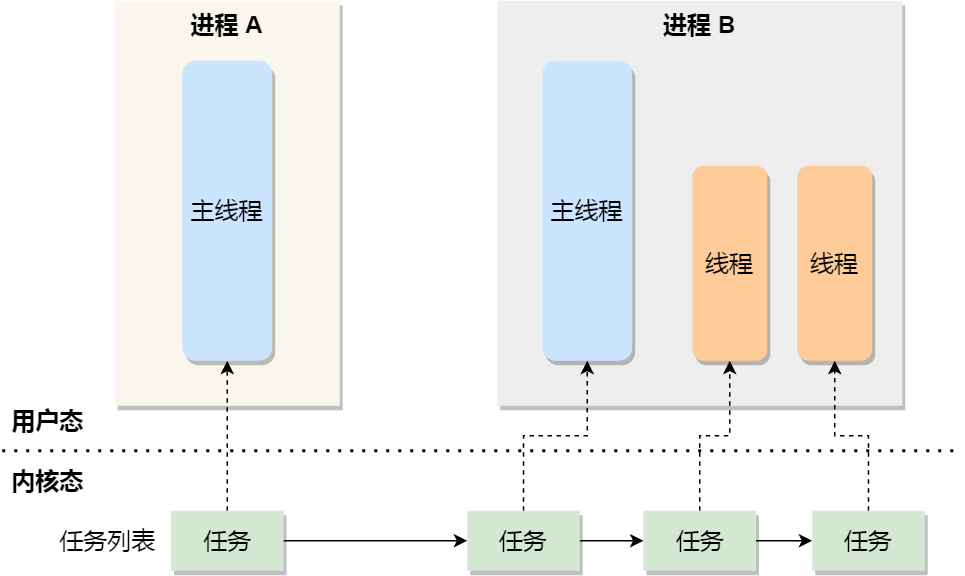
所以,Linux 内核里的调度器,调度的对象就是 task_struct,接下来我们就把这个数据结构统称为任务。
在 Linux 系统中,根据任务的优先级以及响应要求,主要分为两种,其中优先级的数值越小,优先级越高:
- 实时任务,对系统的响应时间要求很高,也就是要尽可能快的执行实时任务,优先级在
0~99范围内的就算实时任务; - 普通任务,响应时间没有很高的要求,优先级在
100~139范围内都是普通任务级别;
调度类
由于任务有优先级之分,Linux 系统为了保障高优先级的任务能够尽可能早的被执行,于是分为了这几种调度类,如下图:
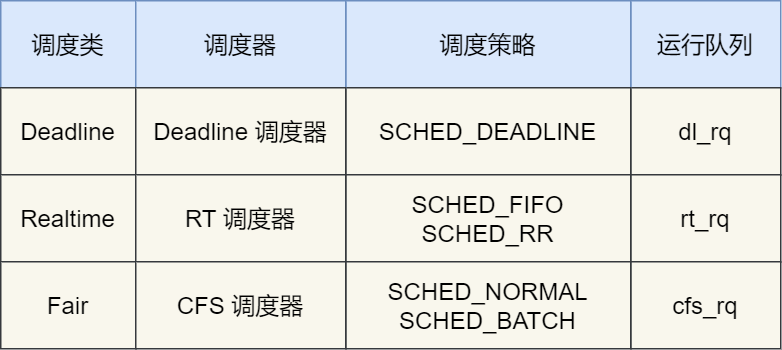
Deadline 和 Realtime 这两个调度类,都是应用于实时任务的,这两个调度类的调度策略合起来共有这三种,它们的作用如下:
- SCHED_DEADLINE:是按照 deadline 进行调度的,距离当前时间点最近的 deadline 的任务会被优先调度;
- SCHED_FIFO:对于相同优先级的任务,按先来先服务的原则,但是优先级更高的任务,可以抢占低优先级的任务,也就是优先级高的可以「插队」;
- SCHED_RR:对于相同优先级的任务,轮流着运行,每个任务都有一定的时间片,当用完时间片的任务会被放到队列尾部,以保证相同优先级任务的公平性,但是高优先级的任务依然可以抢占低优先级的任务;
而 Fair 调度类是应用于普通任务,都是由 CFS 调度器管理的,分为两种调度策略:
- SCHED_NORMAL:普通任务使用的调度策略;
- SCHED_BATCH:后台任务的调度策略,不和终端进行交互,因此在不影响其他需要交互的任务,可以适当降低它的优先级。
完全公平调度
我们平日里遇到的基本都是普通任务,对于普通任务来说,公平性最重要,在 Linux 里面,实现了一个基于 CFS 的调度算法,也就是完全公平调度(*Completely Fair Scheduling*)。
这个算法的理念是想让分配给每个任务的 CPU 时间是一样,于是它为每个任务安排一个虚拟运行时间 vruntime,如果一个任务在运行,其运行的越久,该任务的 vruntime 自然就会越大,而没有被运行的任务,vruntime 是不会变化的。
那么,在 CFS 算法调度的时候,会优先选择 vruntime 少的任务,以保证每个任务的公平性。
这就好比,让你把一桶的奶茶平均分到 10 杯奶茶杯里,你看着哪杯奶茶少,就多倒一些;哪个多了,就先不倒,这样经过多轮操作,虽然不能保证每杯奶茶完全一样多,但至少是公平的。
当然,上面提到的例子没有考虑到优先级的问题,虽然是普通任务,但是普通任务之间还是有优先级区分的,所以在计算虚拟运行时间 vruntime 还要考虑普通任务的权重值,注意权重值并不是优先级的值,内核中会有一个 nice 级别与权重值的转换表,nice 级别越低的权重值就越大,至于 nice 值是什么,我们后面会提到。 于是就有了以下这个公式:

你可以不用管 NICE_0_LOAD 是什么,你就认为它是一个常量,那么在「同样的实际运行时间」里,高权重任务的 vruntime 比低权重任务的 vruntime 少,你可能会奇怪为什么是少的?你还记得 CFS 调度吗,它是会优先选择 vruntime 少的任务进行调度,所以高权重的任务就会被优先调度了,于是高权重的获得的实际运行时间自然就多了。
CPU 运行队列
一个系统通常都会运行着很多任务,多任务的数量基本都是远超 CPU 核心数量,因此这时候就需要排队。
事实上,每个 CPU 都有自己的运行队列(*Run Queue, rq*),用于描述在此 CPU 上所运行的所有进程,其队列包含三个运行队列,Deadline 运行队列 dl_rq、实时任务运行队列 rt_rq 和 CFS 运行队列 cfs_rq,其中 cfs_rq 是用红黑树来描述的,按 vruntime 大小来排序的,最左侧的叶子节点,就是下次会被调度的任务。
PS:下图中的 csf_rq 应该是 cfs_rq,由于找不到原图了,我偷个懒,我就不重新画了,嘻嘻。
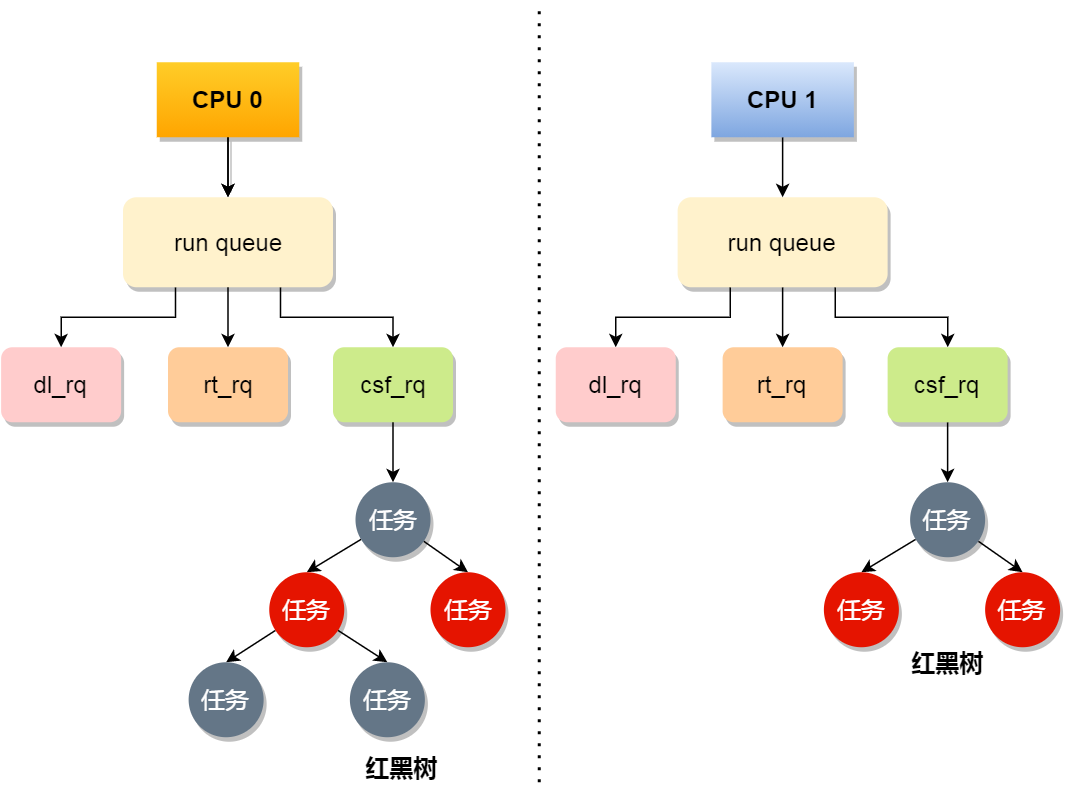
这几种调度类是有优先级的,优先级如下:Deadline > Realtime > Fair,这意味着 Linux 选择下一个任务执行的时候,会按照此优先级顺序进行选择,也就是说先从 dl_rq 里选择任务,然后从 rt_rq 里选择任务,最后从 cfs_rq 里选择任务。因此,实时任务总是会比普通任务优先被执行。
调整优先级
如果我们启动任务的时候,没有特意去指定优先级的话,默认情况下都是普通任务,普通任务的调度类是 Fair,由 CFS 调度器来进行管理。CFS 调度器的目的是实现任务运行的公平性,也就是保障每个任务的运行的时间是差不多的。
如果你想让某个普通任务有更多的执行时间,可以调整任务的 nice 值,从而让优先级高一些的任务执行更多时间。nice 的值能设置的范围是 -20~19, 值越低,表明优先级越高,因此 -20 是最高优先级,19 则是最低优先级,默认优先级是 0。
是不是觉得 nice 值的范围很诡异?事实上,nice 值并不是表示优先级,而是表示优先级的修正数值,它与优先级(priority)的关系是这样的:priority(new) = priority(old) + nice。内核中,priority 的范围是 0~139,值越低,优先级越高,其中前面的 0~99 范围是提供给实时任务使用的,而 nice 值是映射到 100~139,这个范围是提供给普通任务用的,因此 nice 值调整的是普通任务的优先级。

在前面我们提到了,权重值与 nice 值的关系的,nice 值越低,权重值就越大,计算出来的 vruntime 就会越少,由于 CFS 算法调度的时候,就会优先选择 vruntime 少的任务进行执行,所以 nice 值越低,任务的优先级就越高。
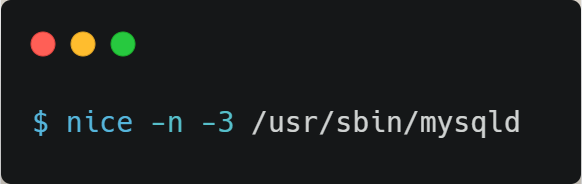
我们可以在启动任务的时候,可以指定 nice 的值,比如将 mysqld 以 -3 优先级:
如果想修改已经运行中的任务的优先级,则可以使用 renice 来调整 nice 值:

nice 调整的是普通任务的优先级,所以不管怎么缩小 nice 值,任务永远都是普通任务,如果某些任务要求实时性比较高,那么你可以考虑改变任务的优先级以及调度策略,使得它变成实时任务,比如:

总结
理解 CPU 是如何读写数据的前提,是要理解 CPU 的架构,CPU 内部的多个 Cache + 外部的内存和磁盘都就构成了金字塔的存储器结构,在这个金字塔中,越往下,存储器的容量就越大,但访问速度就会小。
CPU 读写数据的时候,并不是按一个一个字节为单位来进行读写,而是以 CPU Cache Line 大小为单位,CPU Cache Line 大小一般是 64 个字节,也就意味着 CPU 读写数据的时候,每一次都是以 64 字节大小为一块进行操作。
因此,如果我们操作的数据是数组,那么访问数组元素的时候,按内存分布的地址顺序进行访问,这样能充分利用到 Cache,程序的性能得到提升。但如果操作的数据不是数组,而是普通的变量,并在多核 CPU 的情况下,我们还需要避免 Cache Line 伪共享的问题。
所谓的 Cache Line 伪共享问题就是,多个线程同时读写同一个 Cache Line 的不同变量时,而导致 CPU Cache 失效的现象。那么对于多个线程共享的热点数据,即经常会修改的数据,应该避免这些数据刚好在同一个 Cache Line 中,避免的方式一般有 Cache Line 大小字节对齐,以及字节填充等方法。
系统中需要运行的多线程数一般都会大于 CPU 核心,这样就会导致线程排队等待 CPU,这可能会产生一定的延时,如果我们的任务对延时容忍度很低,则可以通过一些人为手段干预 Linux 的默认调度策略和优先级。
什么是软中断?
今日的技术主题:什么是软中断?。
中断是什么?
先来看看什么是中断?在计算机中,中断是系统用来响应硬件设备请求的一种机制,操作系统收到硬件的中断请求,会打断正在执行的进程,然后调用内核中的中断处理程序来响应请求。
这样的解释可能过于学术了,容易云里雾里,我就举个生活中取外卖的例子。
小林中午搬完砖,肚子饿了,点了份白切鸡外卖,这次我带闪了,没有被某团大数据杀熟。虽然平台上会显示配送进度,但是我也不能一直傻傻地盯着呀,时间很宝贵,当然得去干别的事情,等外卖到了配送员会通过「电话」通知我,电话响了,我就会停下手中地事情,去拿外卖。
这里的打电话,其实就是对应计算机里的中断,没接到电话的时候,我可以做其他的事情,只有接到了电话,也就是发生中断,我才会停下当前的事情,去进行另一个事情,也就是拿外卖。
从这个例子,我们可以知道,中断是一种异步的事件处理机制,可以提高系统的并发处理能力。
操作系统收到了中断请求,会打断其他进程的运行,所以中断请求的响应程序,也就是中断处理程序,要尽可能快的执行完,这样可以减少对正常进程运行调度地影响。
而且,中断处理程序在响应中断时,可能还会「临时关闭中断」,这意味着,如果当前中断处理程序没有执行完之前,系统中其他的中断请求都无法被响应,也就说中断有可能会丢失,所以中断处理程序要短且快。
还是回到外卖的例子,小林到了晚上又点起了外卖,这次为了犒劳自己,共点了两份外卖,一份小龙虾和一份奶茶,并且是由不同地配送员来配送,那么问题来了,当第一份外卖送到时,配送员给我打了长长的电话,说了一些杂七杂八的事情,比如给个好评等等,但如果这时另一位配送员也想给我打电话。
很明显,这时第二位配送员因为我在通话中(相当于关闭了中断响应),自然就无法打通我的电话,他可能尝试了几次后就走掉了(相当于丢失了一次中断)。
什么是软中断?
前面我们也提到了,中断请求的处理程序应该要短且快,这样才能减少对正常进程运行调度地影响,而且中断处理程序可能会暂时关闭中断,这时如果中断处理程序执行时间过长,可能在还未执行完中断处理程序前,会丢失当前其他设备的中断请求。
那 Linux 系统为了解决中断处理程序执行过长和中断丢失的问题,将中断过程分成了两个阶段,分别是「上半部和下半部分」。
- 上半部用来快速处理中断,一般会暂时关闭中断请求,主要负责处理跟硬件紧密相关或者时间敏感的事情。
- 下半部用来延迟处理上半部未完成的工作,一般以「内核线程」的方式运行。
前面的外卖例子,由于第一个配送员长时间跟我通话,则导致第二位配送员无法拨通我的电话,其实当我接到第一位配送员的电话,可以告诉配送员说我现在下楼,剩下的事情,等我们见面再说(上半部),然后就可以挂断电话,到楼下后,在拿外卖,以及跟配送员说其他的事情(下半部)。
这样,第一位配送员就不会占用我手机太多时间,当第二位配送员正好过来时,会有很大几率拨通我的电话。
再举一个计算机中的例子,常见的网卡接收网络包的例子。
网卡收到网络包后,通过 DMA 方式将接收到的数据写入内存,接着会通过硬件中断通知内核有新的数据到了,于是内核就会调用对应的中断处理程序来处理该事件,这个事件的处理也是会分成上半部和下半部。
上部分要做的事情很少,会先禁止网卡中断,避免频繁硬中断,而降低内核的工作效率。接着,内核会触发一个软中断,把一些处理比较耗时且复杂的事情,交给「软中断处理程序」去做,也就是中断的下半部,其主要是需要从内存中找到网络数据,再按照网络协议栈,对网络数据进行逐层解析和处理,最后把数据送给应用程序。
所以,中断处理程序的上部分和下半部可以理解为:
- 上半部直接处理硬件请求,也就是硬中断,主要是负责耗时短的工作,特点是快速执行;
- 下半部是由内核触发,也就说软中断,主要是负责上半部未完成的工作,通常都是耗时比较长的事情,特点是延迟执行;
还有一个区别,硬中断(上半部)是会打断 CPU 正在执行的任务,然后立即执行中断处理程序,而软中断(下半部)是以内核线程的方式执行,并且每一个 CPU 都对应一个软中断内核线程,名字通常为「ksoftirqd/CPU 编号」,比如 0 号 CPU 对应的软中断内核线程的名字是 ksoftirqd/0
不过,软中断不只是包括硬件设备中断处理程序的下半部,一些内核自定义事件也属于软中断,比如内核调度等、RCU 锁(内核里常用的一种锁)等。
系统里有哪些软中断?
在 Linux 系统里,我们可以通过查看 /proc/softirqs 的 内容来知晓「软中断」的运行情况,以及 /proc/interrupts 的 内容来知晓「硬中断」的运行情况。
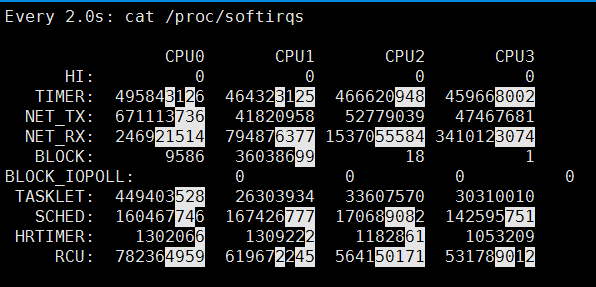
接下来,就来简单的解析下 /proc/softirqs 文件的内容,在我服务器上查看到的文件内容如下:
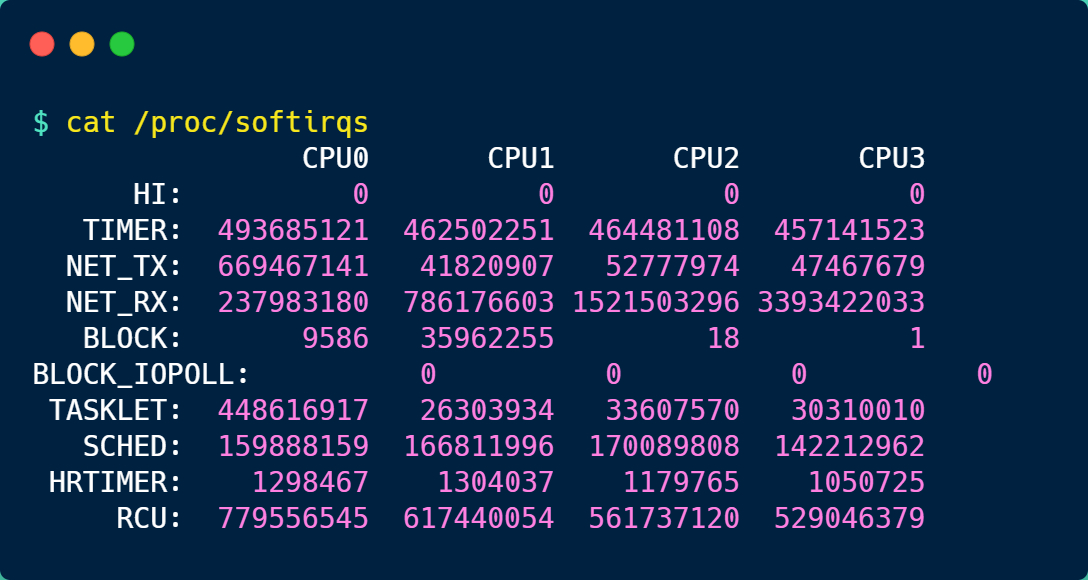
你可以看到,每一个 CPU 都有自己对应的不同类型软中断的累计运行次数,有 3 点需要注意下。
第一点,要注意第一列的内容,它是代表着软中断的类型,在我的系统里,软中断包括了 10 个类型,分别对应不同的工作类型,比如 NET_RX 表示网络接收中断,NET_TX 表示网络发送中断、TIMER 表示定时中断、RCU 表示 RCU 锁中断、SCHED 表示内核调度中断。
第二点,要注意同一种类型的软中断在不同 CPU 的分布情况,正常情况下,同一种中断在不同 CPU 上的累计次数相差不多,比如我的系统里,NET_RX 在 CPU0 、CPU1、CPU2、CPU3 上的中断次数基本是同一个数量级,相差不多。
第三点,这些数值是系统运行以来的累计中断次数,数值的大小没什么参考意义,但是系统的中断次数的变化速率才是我们要关注的,我们可以使用 watch -d cat /proc/softirqs 命令查看中断次数的变化速率。
前面提到过,软中断是以内核线程的方式执行的,我们可以用 ps 命令可以查看到,下面这个就是在我的服务器上查到软中断内核线程的结果:
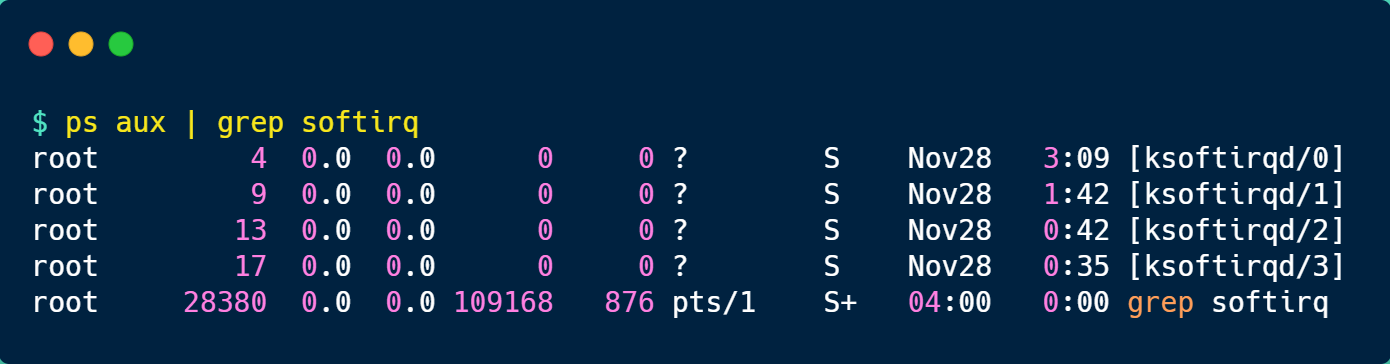
可以发现,内核线程的名字外面都有有中括号,这说明 ps 无法获取它们的命令行参数,所以一般来说,名字在中括号里的都可以认为是内核线程。
而且,你可以看到有 4 个 ksoftirqd 内核线程,这是因为我这台服务器的 CPU 是 4 核心的,每个 CPU 核心都对应着一个内核线程。
如何定位软中断 CPU 使用率过高的问题?
要想知道当前的系统的软中断情况,我们可以使用 top 命令查看,下面是一台服务器上的 top 的数据:
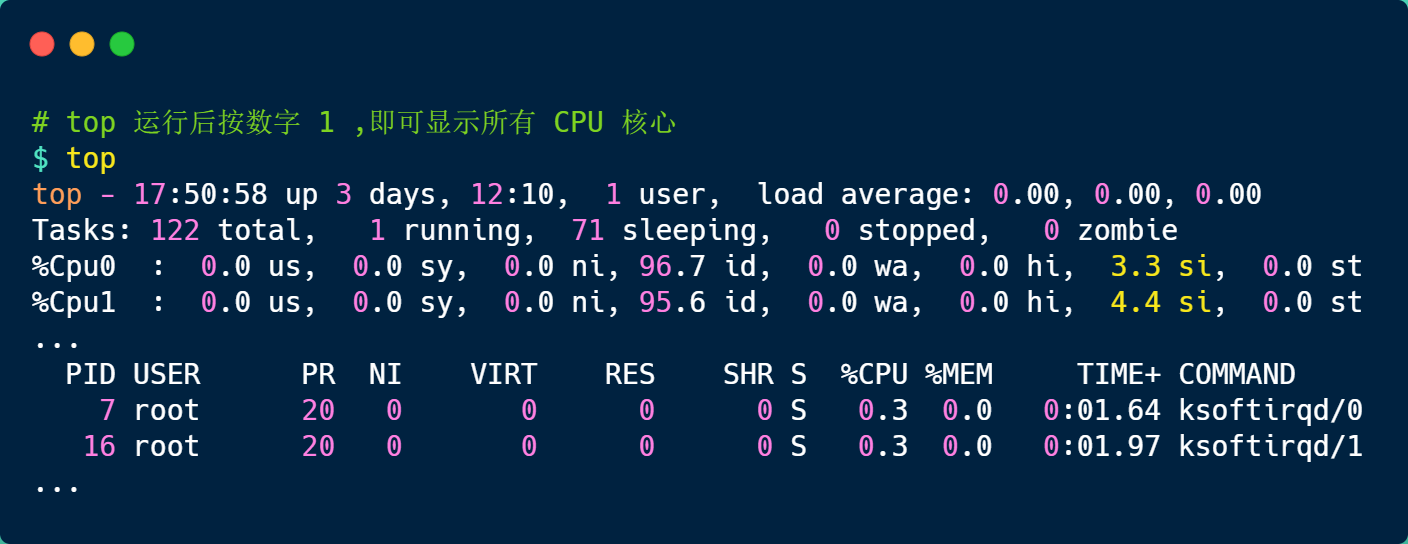
上图中的黄色部分 si,就是 CPU 在软中断上的使用率,而且可以发现,每个 CPU 使用率都不高,两个 CPU 的使用率虽然只有 3% 和 4% 左右,但是都是用在软中断上了。
另外,也可以看到 CPU 使用率最高的进程也是软中断 ksoftirqd,因此可以认为此时系统的开销主要来源于软中断。
如果要知道是哪种软中断类型导致的,我们可以使用 watch -d cat /proc/softirqs 命令查看每个软中断类型的中断次数的变化速率。
一般对于网络 I/O 比较高的 Web 服务器,NET_RX 网络接收中断的变化速率相比其他中断类型快很多。
如果发现 NET_RX 网络接收中断次数的变化速率过快,接下来就可以使用 sar -n DEV 查看网卡的网络包接收速率情况,然后分析是哪个网卡有大量的网络包进来。

接着,在通过 tcpdump 抓包,分析这些包的来源,如果是非法的地址,可以考虑加防火墙,如果是正常流量,则要考虑硬件升级等。
总结
为了避免由于中断处理程序执行时间过长,而影响正常进程的调度,Linux 将中断处理程序分为上半部和下半部:
- 上半部,对应硬中断,由硬件触发中断,用来快速处理中断;
- 下半部,对应软中断,由内核触发中断,用来异步处理上半部未完成的工作;
Linux 中的软中断包括网络收发、定时、调度、RCU 锁等各种类型,可以通过查看 /proc/softirqs 来观察软中断的累计中断次数情况,如果要实时查看中断次数的变化率,可以使用 watch -d cat /proc/softirqs 命令。
每一个 CPU 都有各自的软中断内核线程,我们还可以用 ps 命令来查看内核线程,一般名字在中括号里面到,都认为是内核线程。
如果在 top 命令发现,CPU 在软中断上的使用率比较高,而且 CPU 使用率最高的进程也是软中断 ksoftirqd 的时候,这种一般可以认为系统的开销被软中断占据了。
这时我们就可以分析是哪种软中断类型导致的,一般来说都是因为网络接收软中断导致的,如果是的话,可以用 sar 命令查看是哪个网卡的有大量的网络包接收,再用 tcpdump 抓网络包,做进一步分析该网络包的源头是不是非法地址,如果是就需要考虑防火墙增加规则,如果不是,则考虑硬件升级等。
为什么0.1+0.2不等于0.3?
我们来思考几个问题:
- 为什么负数要用补码表示?
- 十进制小数怎么转成二进制?
- 计算机是怎么存小数的?
- 0.1 + 0.2 == 0.3 吗?
- …
别看这些问题都看似简单,但是其实还是有点东西的这些问题。
为什么负数要用补码表示?
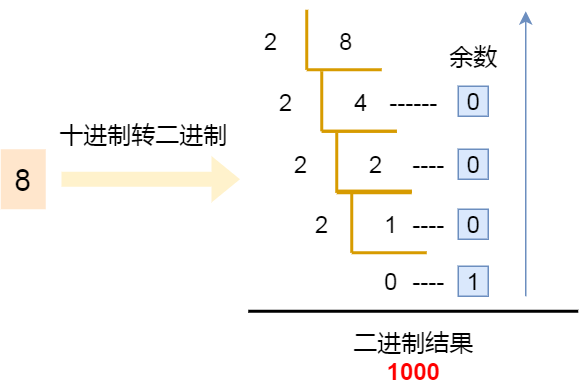
十进制转换二进制的方法相信大家都熟能生巧了,如果你说你还不知道,我觉得你还是太谦虚,可能你只是忘记了,即使你真的忘记了,不怕,贴心的小林在和你一起回忆一下。
十进制数转二进制采用的是除 2 取余法,比如数字 8 转二进制的过程如下图:
接着,我们看看「整数类型」的数字在计算机的存储方式,这其实很简单,也很直观,就是将十进制的数字转换成二进制即可。
我们以 int 类型的数字作为例子,int 类型是 32 位的,其中最高位是作为「符号标志位」,正数的符号位是 0,负数的符号位是 1,剩余的 31 位则表示二进制数据。
那么,对于 int 类型的数字 1 的二进制数表示如下:

而负数就比较特殊了点,负数在计算机中是以「补码」表示的,所谓的补码就是把正数的二进制全部取反再加 1,比如 -1 的二进制是把数字 1 的二进制取反后再加 1,如下图:
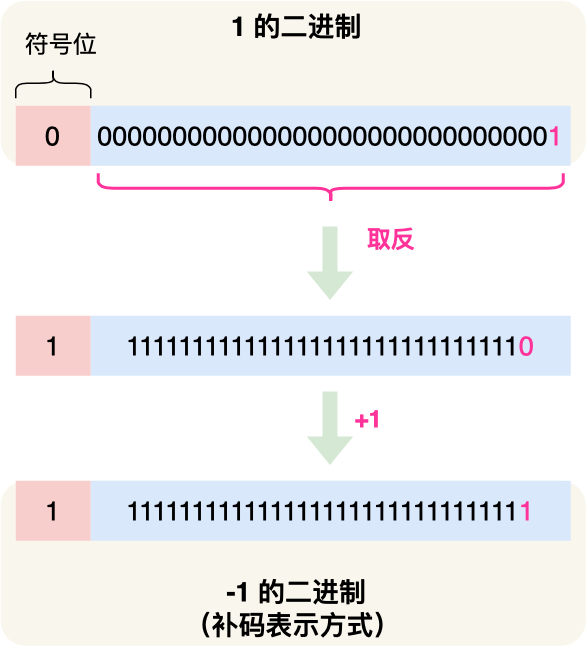
不知道你有没有想过,为什么计算机要用补码的方式来表示负数?在回答这个问题前,我们假设不用补码的方式来表示负数,而只是把最高位的符号标志位变为 1 表示负数,如下图过程:

如果采用这种方式来表示负数的二进制的话,试想一下 -2 + 1 的运算过程,如下图:
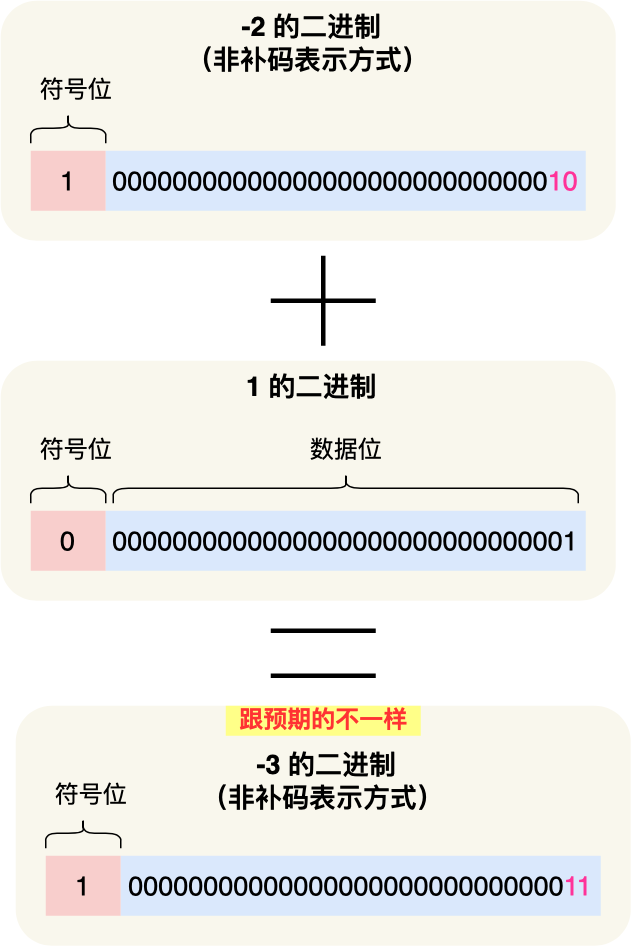
按道理,-2 + 1 = -1,但是上面的运算过程中得到结果却是 -3,所以发现,这种负数的表示方式是不能用常规的加法来计算了,就需要特殊处理,要先判断数字是否为负数,如果是负数就要把加法操作变成减法操作才可以得到正确对结果。
到这里,我们就可以回答前面提到的「负数为什么要用补码方式来表示」的问题了。
如果负数不是使用补码的方式表示,则在做基本对加减法运算的时候,还需要多一步操作来判断是否为负数,如果为负数,还得把加法反转成减法,或者把减法反转成加法,这就非常不好了,毕竟加减法运算在计算机里是很常使用的,所以为了性能考虑,应该要尽量简化这个运算过程。
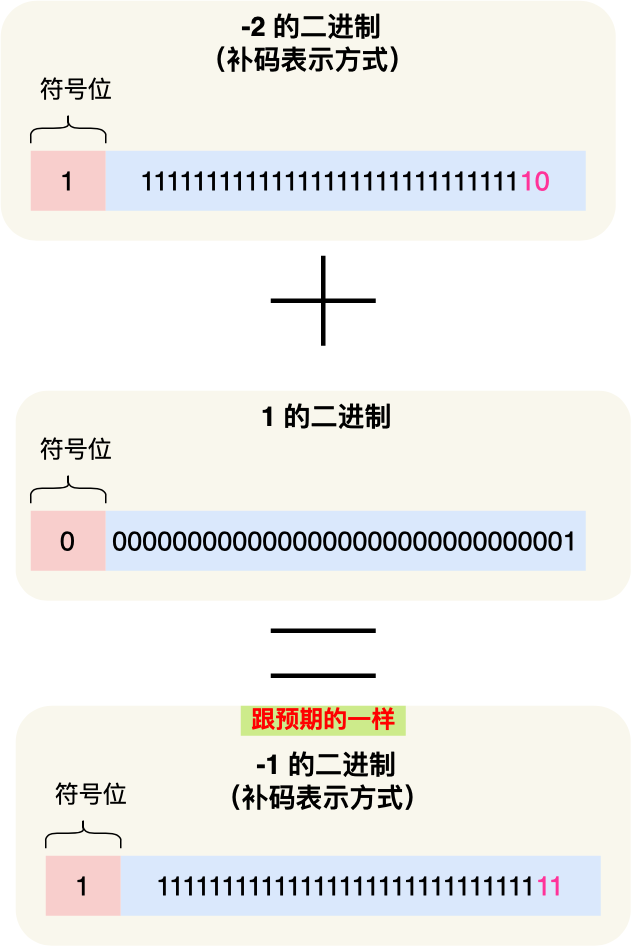
而用了补码的表示方式,对于负数的加减法操作,实际上是和正数加减法操作一样的。你可以看到下图,用补码表示的负数在运算 -2 + 1 过程的时候,其结果是正确的:
十进制小数与二进制的转换
好了,整数十进制转二进制我们知道了,接下来看看小数是怎么转二进制的,小数部分的转换不同于整数部分,它采用的是乘 2 取整法,将十进制中的小数部分乘以 2 作为二进制的一位,然后继续取小数部分乘以 2 作为下一位,直到不存在小数为止。
话不多说,我们就以 8.625 转二进制作为例子,直接上图:
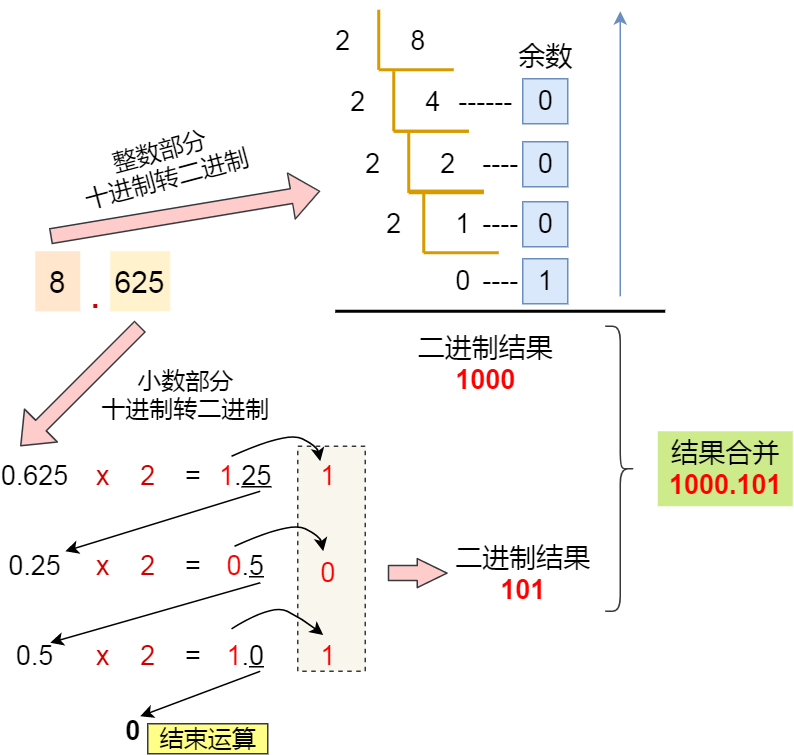
最后把「整数部分 + 小数部分」结合在一起后,其结果就是 1000.101。
但是,并不是所有小数都可以用二进制表示,前面提到的 0.625 小数是一个特例,刚好通过乘 2 取整法的方式完整的转换成二进制。
如果我们用相同的方式,来把 0.1 转换成二进制,过程如下:
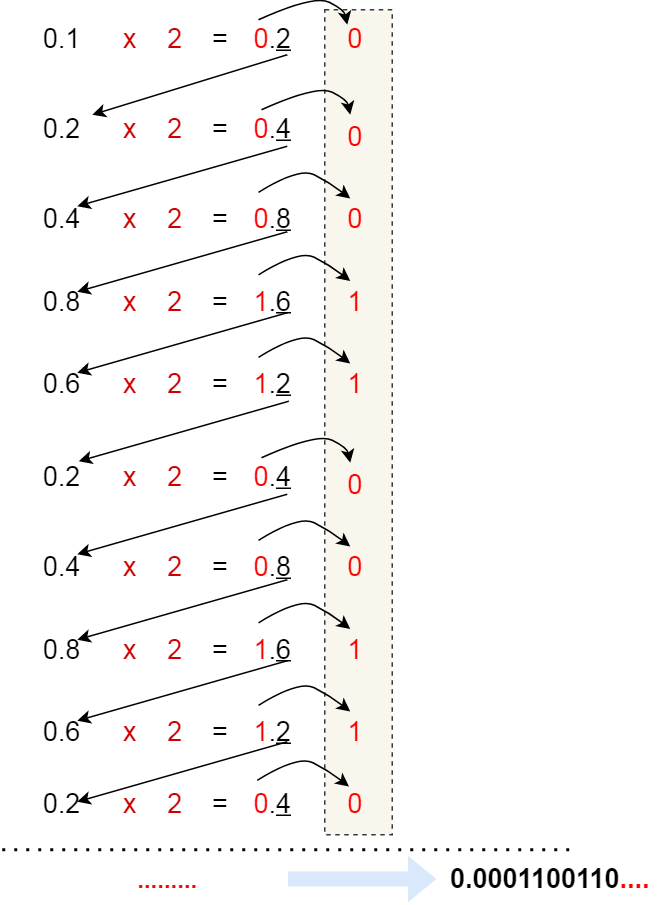
可以发现,0.1 的二进制表示是无限循环的。
由于计算机的资源是有限的,所以是没办法用二进制精确的表示 0.1,只能用「近似值」来表示,就是在有限的精度情况下,最大化接近 0.1 的二进制数,于是就会造成精度缺失的情况。
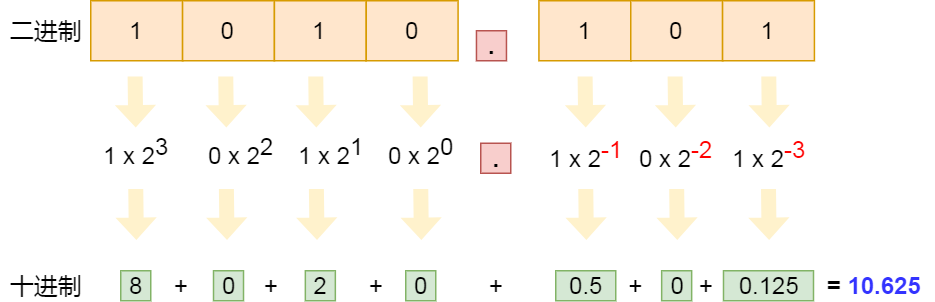
对于二进制小数转十进制时,需要注意一点,小数点后面的指数幂是负数。
比如,二进制 0.1 转成十进制就是 2^(-1),也就是十进制 0.5,二进制 0.01 转成十进制就是 2^-2,也就是十进制 0.25,以此类推。
举个例子,二进制 1010.101 转十进制的过程,如下图:
计算机是怎么存小数的?
1000.101 这种二进制小数是「定点数」形式,代表着小数点是定死的,不能移动,如果你移动了它的小数点,这个数就变了, 就不再是它原来的值了。
然而,计算机并不是这样存储的小数的,计算机存储小数的采用的是浮点数,名字里的「浮点」表示小数点是可以浮动的。
比如 1000.101 这个二进制数,可以表示成 1.000101 x 2^3,类似于数学上的科学记数法。
既然提到了科学计数法,我再帮大家复习一下。
比如有个很大的十进制数 1230000,我们可以也可以表示成 1.23 x 10^6,这种方式就称为科学记数法。
该方法在小数点左边只有一个数字,而且把这种整数部分没有前导 0 的数字称为规格化,比如 1.0 x 10^(-9) 是规格化的科学记数法,而 0.1 x 10^(-9) 和 10.0 x 10^(-9) 就不是了。
因此,如果二进制要用到科学记数法,同时要规范化,那么不仅要保证基数为 2,还要保证小数点左侧只有 1 位,而且必须为 1。
所以通常将 1000.101 这种二进制数,规格化表示成 1.000101 x 2^3,其中,最为关键的是 000101 和 3 这两个东西,它就可以包含了这个二进制小数的所有信息:
000101称为尾数,即小数点后面的数字;3称为指数,指定了小数点在数据中的位置;
现在绝大多数计算机使用的浮点数,一般采用的是 IEEE 制定的国际标准,这种标准形式如下图:

这三个重要部分的意义如下:
- 符号位:表示数字是正数还是负数,为 0 表示正数,为 1 表示负数;
- 指数位:指定了小数点在数据中的位置,指数可以是负数,也可以是正数,指数位的长度越长则数值的表达范围就越大;
- 尾数位:小数点右侧的数字,也就是小数部分,比如二进制 1.0011 x 2^(-2),尾数部分就是 0011,而且尾数的长度决定了这个数的精度,因此如果要表示精度更高的小数,则就要提高尾数位的长度;
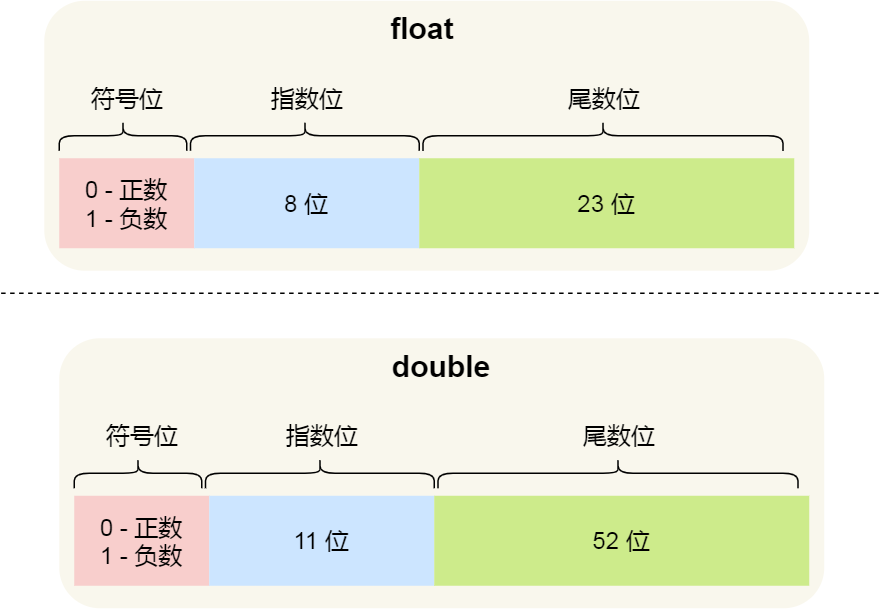
用 32 位来表示的浮点数,则称为单精度浮点数,也就是我们编程语言中的 float 变量,而用 64 位来表示的浮点数,称为双精度浮点数,也就是 double 变量,它们的结构如下:
可以看到:
- double 的尾数部分是 52 位,float 的尾数部分是 23 位,由于同时都带有一个固定隐含位(这个后面会说),所以 double 有 53 个二进制有效位,float 有 24 个二进制有效位,所以所以它们的精度在十进制中分别是
log10(2^53)约等于15.95和log10(2^24)约等于7.22位,因此 double 的有效数字是15~16位,float 的有效数字是7~8位,这些有效位是包含整数部分和小数部分; - double 的指数部分是 11 位,而 float 的指数位是 8 位,意味着 double 相比 float 能表示更大的数值范围;
那二进制小数,是如何转换成二进制浮点数的呢?
我们就以 10.625 作为例子,看看这个数字在 float 里是如何存储的。
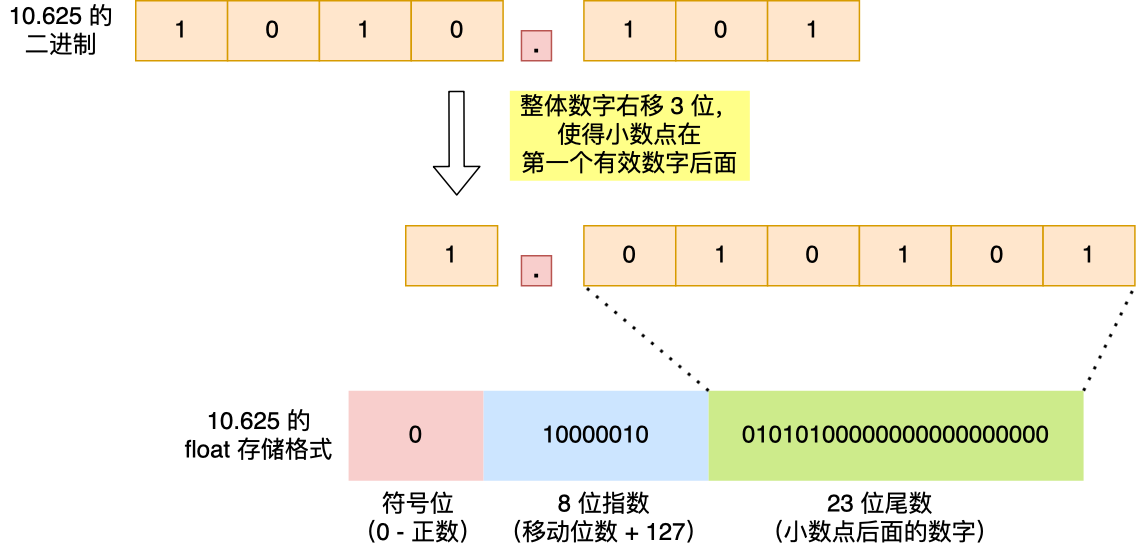
首先,我们计算出 10.625 的二进制小数为 1010.101。
然后把小数点,移动到第一个有效数字后面,即将 1010.101 右移 3 位成 1.010101,右移 3 位就代表 +3,左移 3 位就是 -3。
float 中的「指数位」就跟这里移动的位数有关系,把移动的位数再加上「偏移量」,float 的话偏移量是 127,相加后就是指数位的值了,即指数位这 8 位存的是 10000010(十进制 130),因此你可以认为「指数位」相当于指明了小数点在数据中的位置。
1.010101 这个数的小数点右侧的数字就是 float 里的「尾数位」,由于尾数位是 23 位,则后面要补充 0,所以最终尾数位存储的数字是 01010100000000000000000。
在算指数的时候,你可能会有疑问为什么要加上偏移量呢?
前面也提到,指数可能是正数,也可能是负数,即指数是有符号的整数,而有符号整数的计算是比无符号整数麻烦的,所以为了减少不必要的麻烦,在实际存储指数的时候,需要把指数转换成无符号整数。
float 的指数部分是 8 位,IEEE 标准规定单精度浮点的指数取值范围是 -126 ~ +127,于是为了把指数转换成无符号整数,就要加个偏移量,比如 float 的指数偏移量是 127,这样指数就不会出现负数了。
比如,指数如果是 8,则实际存储的指数是 8 + 127(偏移量)= 135,即把 135 转换为二进制之后再存储,而当我们需要计算实际的十进制数的时候,再把指数减去「偏移量」即可。
细心的朋友肯定发现,移动后的小数点左侧的有效位(即 1)消失了,它并没有存储到 float 里。
这是因为 IEEE 标准规定,二进制浮点数的小数点左侧只能有 1 位,并且还只能是 1,既然这一位永远都是 1,那就可以不用存起来了。
于是就让 23 位尾数只存储小数部分,然后在计算时会自动把这个 1 加上,这样就可以节约 1 位的空间,尾数就能多存一位小数,相应的精度就更高了一点。
那么,对于我们在从 float 的二进制浮点数转换成十进制时,要考虑到这个隐含的 1,转换公式如下:

举个例子,我们把下图这个 float 的数据转换成十进制,过程如下:
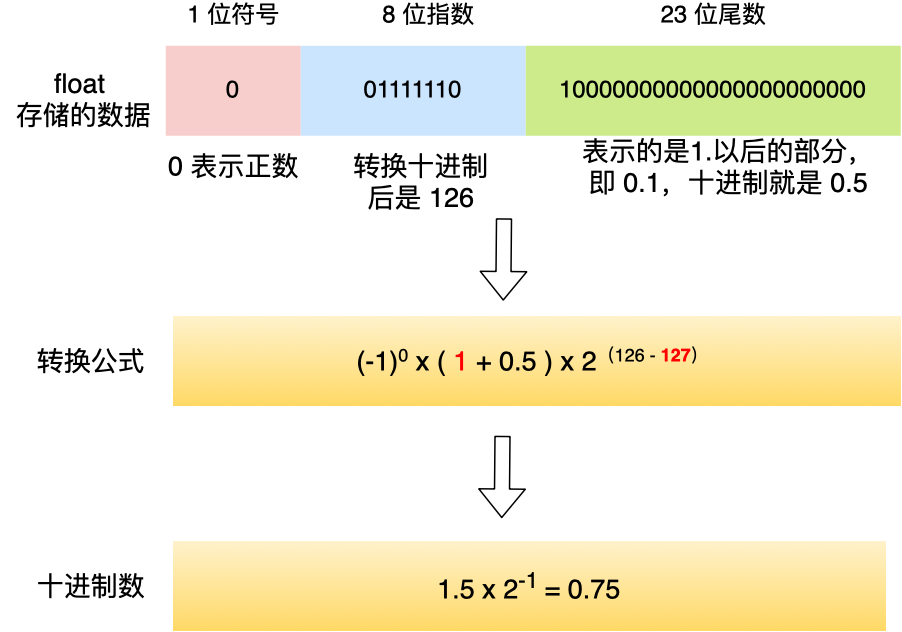
0.1 + 0.2 == 0.3 ?
前面提到过,并不是所有小数都可以用「完整」的二进制来表示的,比如十进制 0.1 在转换成二进制小数的时候,是一串无限循环的二进制数,计算机是无法表达无限循环的二进制数的,毕竟计算机的资源是有限。
因此,计算机只能用「近似值」来表示该二进制,那么意味着计算机存放的小数可能不是一个真实值。
现在基本都是用 IEEE 754 规范的「单精度浮点类型」或「双精度浮点类型」来存储小数的,根据精度的不同,近似值也会不同。
那计算机是存储 0.1 是一个怎么样的二进制浮点数呢?
偷个懒,我就不自己手动算了,可以使用 binaryconvert 这个工具,将十进制 0.1 小数转换成 float 浮点数:
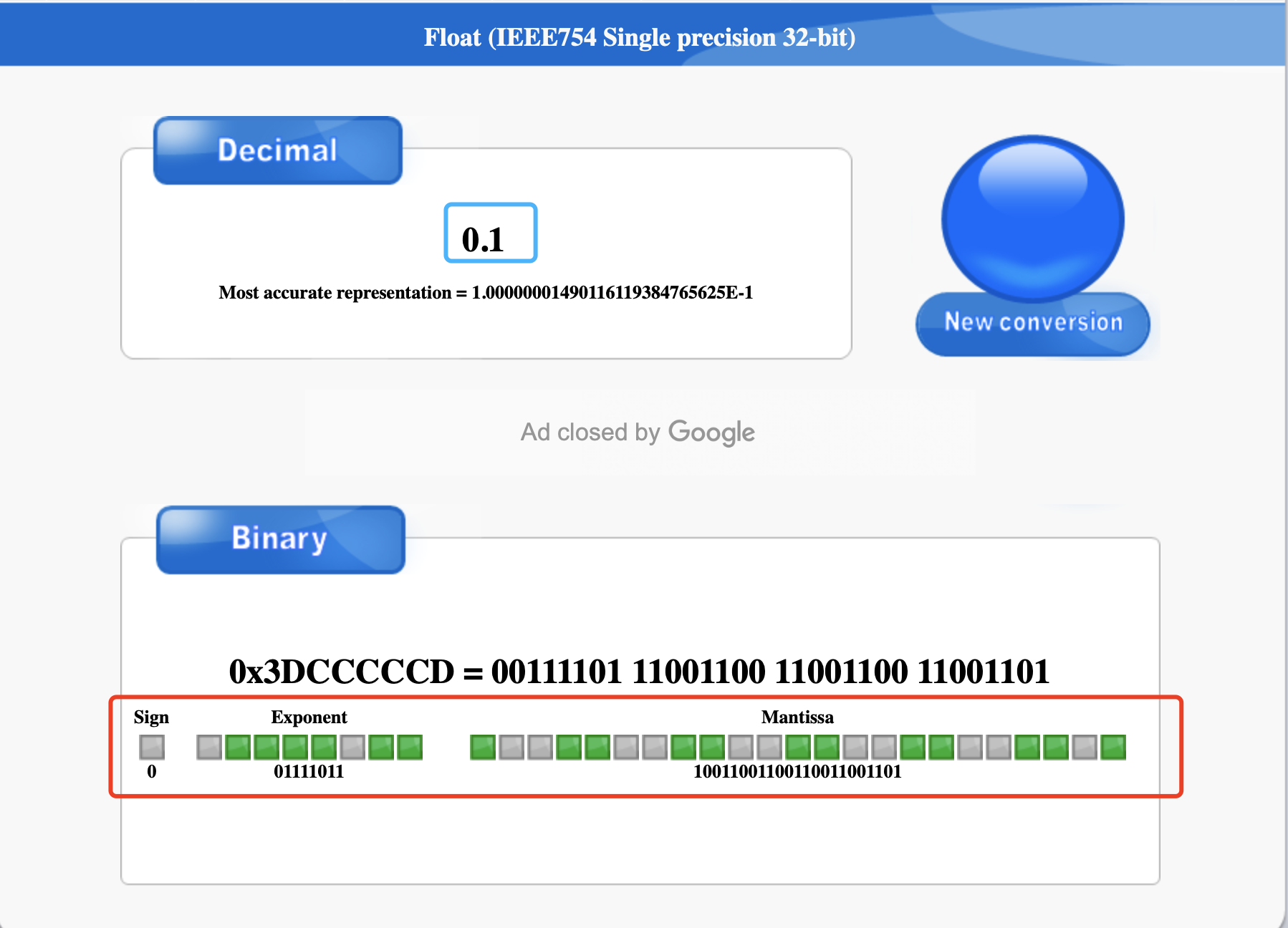
可以看到,8 位指数部分是 01111011,23 位的尾数部分是 10011001100110011001101,可以看到尾数部分是 0011 是一直循环的,只不过尾数是有长度限制的,所以只会显示一部分,所以是一个近似值,精度十分有限。
接下来,我们看看 0.2 的 float 浮点数:

可以看到,8 位指数部分是 01111100,稍微和 0.1 的指数不同,23 位的尾数部分是 10011001100110011001101 和 0.1 的尾数部分是相同的,也是一个近似值。
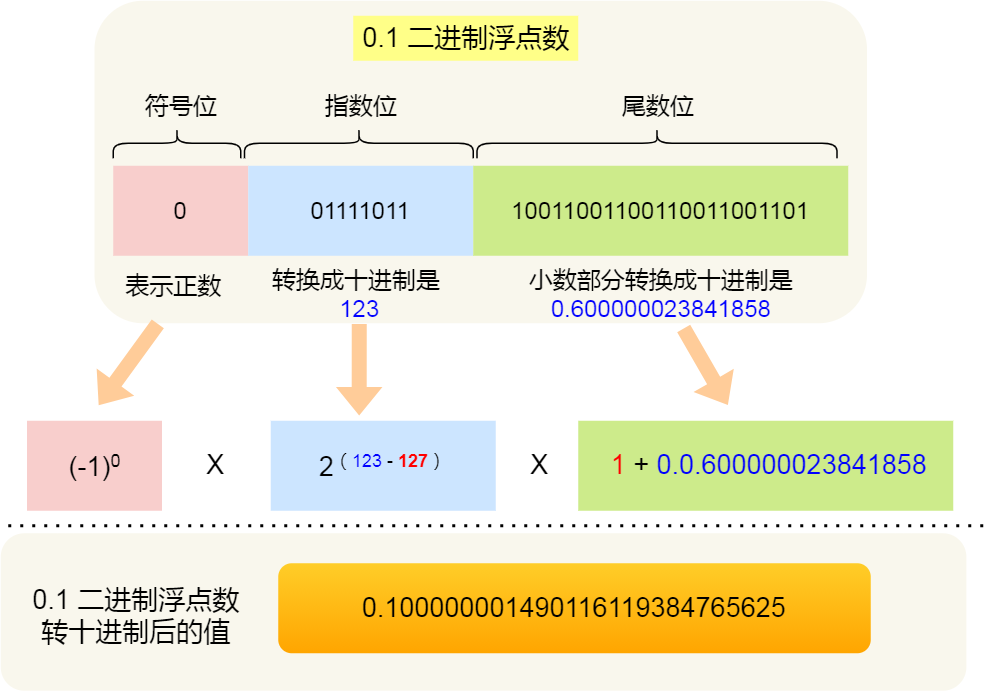
0.1 的二进制浮点数转换成十进制的结果是 0.100000001490116119384765625:
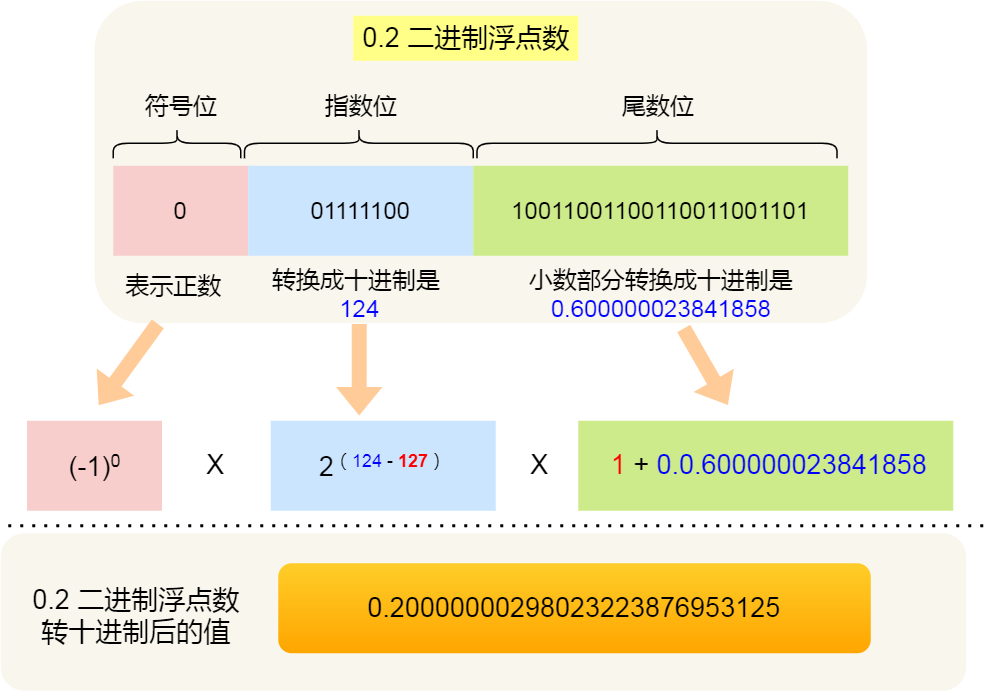
0.2 的二进制浮点数转换成十进制的结果是 0.20000000298023223876953125:
这两个结果相加就是 0.300000004470348358154296875:

所以,你会看到在计算机中 0.1 + 0.2 并不等于完整的 0.3。
这主要是因为有的小数无法可以用「完整」的二进制来表示,所以计算机里只能采用近似数的方式来保存,那两个近似数相加,得到的必然也是一个近似数。
我们在 JavaScript 里执行 0.1 + 0.2,你会得到下面这个结果:
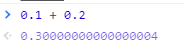
结果和我们前面推到的类似,因为 JavaScript 对于数字都是使用 IEEE 754 标准下的双精度浮点类型来存储的。
而我们二进制只能精准表达 2 除尽的数字 1/2, 1/4, 1/8,但是对于 0.1(1/10) 和 0.2(1/5),在二进制中都无法精准表示时,需要根据精度舍入。
我们人类熟悉的十进制运算系统,可以精准表达 2 和 5 除尽的数字,例如 1/2, 1/4, 1/5(0.2), 1/8, 1/10(0.1)。
当然,十进制也有无法除尽的地方,例如 1/3, 1/7,也需要根据精度舍入。
总结
最后,再来回答开头的问题。
为什么负数要用补码表示?
负数之所以用补码的方式来表示,主要是为了统一和正数的加减法操作一样,毕竟数字的加减法是很常用的一个操作,就不要搞特殊化,尽量以统一的方式来运算。
十进制小数怎么转成二进制?
十进制整数转二进制使用的是「除 2 取余法」,十进制小数使用的是「乘 2 取整法」。
计算机是怎么存小数的?
计算机是以浮点数的形式存储小数的,大多数计算机都是 IEEE 754 标准定义的浮点数格式,包含三个部分:
- 符号位:表示数字是正数还是负数,为 0 表示正数,为 1 表示负数;
- 指数位:指定了小数点在数据中的位置,指数可以是负数,也可以是正数,指数位的长度越长则数值的表达范围就越大;
- 尾数位:小数点右侧的数字,也就是小数部分,比如二进制 1.0011 x 2^(-2),尾数部分就是 0011,而且尾数的长度决定了这个数的精度,因此如果要表示精度更高的小数,则就要提高尾数位的长度;
用 32 位来表示的浮点数,则称为单精度浮点数,也就是我们编程语言中的 float 变量,而用 64 位来表示的浮点数,称为双精度浮点数,也就是 double 变量。
0.1 + 0.2 == 0.3 吗?
不是的,0.1 和 0.2 这两个数字用二进制表达会是一个一直循环的二进制数,比如 0.1 的二进制表示为 0.0 0011 0011 0011… (0011 无限循环),对于计算机而言,0.1 无法精确表达,这是浮点数计算造成精度损失的根源。
因此,IEEE 754 标准定义的浮点数只能根据精度舍入,然后用「近似值」来表示该二进制,那么意味着计算机存放的小数可能不是一个真实值。
0.1 + 0.2 并不等于完整的 0.3,这主要是因为这两个小数无法用「完整」的二进制来表示,只能根据精度舍入,所以计算机里只能采用近似数的方式来保存,那两个近似数相加,得到的必然也是一个近似数。
操作系统结构
Linux内核 vs Windows内核
Windows 和 Linux 可以说是我们比较常见的两款操作系统的。
Windows 基本占领了电脑时代的市场,商业上取得了很大成就,但是它并不开源,所以要想接触源码得加入 Windows 的开发团队中。
对于服务器使用的操作系统基本上都是 Linux,而且内核源码也是开源的,任何人都可以下载,并增加自己的改动或功能,Linux 最大的魅力在于,全世界有非常多的技术大佬为它贡献代码。
这两个操作系统各有千秋,不分伯仲。
操作系统核心的东西就是内核,这次我们就来看看,Linux 内核和 Windows 内核有什么区别?
内核
什么是内核呢?
计算机是由各种外部硬件设备组成的,比如内存、cpu、硬盘等,如果每个应用都要和这些硬件设备对接通信协议,那这样太累了,所以这个中间人就由内核来负责,让内核作为应用连接硬件设备的桥梁,应用程序只需关心与内核交互,不用关心硬件的细节。
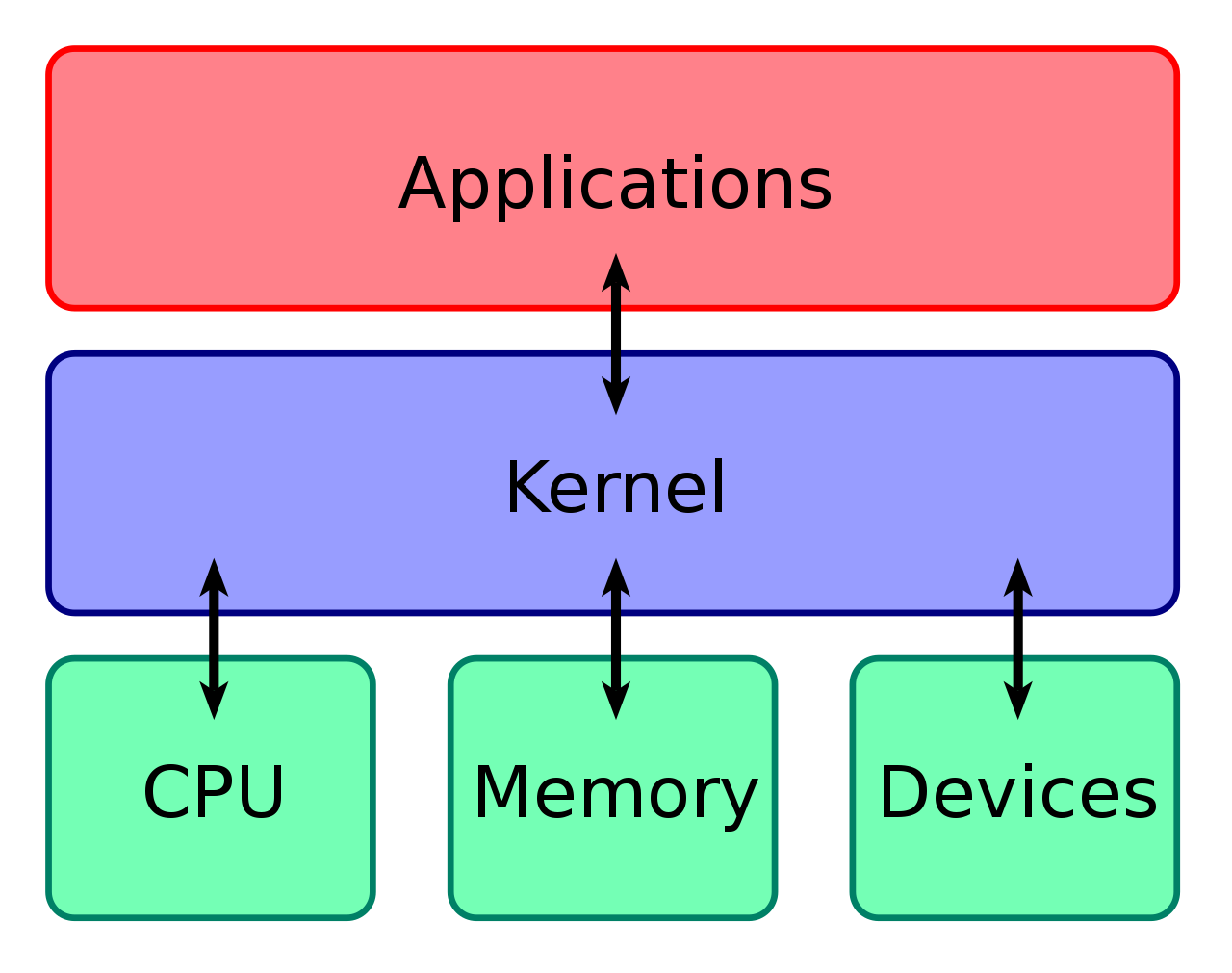
内核有哪些能力呢?
现代操作系统,内核一般会提供 4 个基本能力:
- 管理进程、线程,决定哪个进程、线程使用 CPU,也就是进程调度的能力;
- 管理内存,决定内存的分配和回收,也就是内存管理的能力;
- 管理硬件设备,为进程与硬件设备之间提供通信能力,也就是硬件通信能力;
- 提供系统调用,如果应用程序要运行更高权限运行的服务,那么就需要有系统调用,它是用户程序与操作系统之间的接口。
内核是怎么工作的?
内核具有很高的权限,可以控制 cpu、内存、硬盘等硬件,而应用程序具有的权限很小,因此大多数操作系统,把内存分成了两个区域:
- 内核空间,这个内存空间只有内核程序可以访问;
- 用户空间,这个内存空间专门给应用程序使用;
用户空间的代码只能访问一个局部的内存空间,而内核空间的代码可以访问所有内存空间。因此,当程序使用用户空间时,我们常说该程序在用户态执行,而当程序使用内核空间时,程序则在内核态执行。
应用程序如果需要进入内核空间,就需要通过系统调用,下面来看看系统调用的过程:
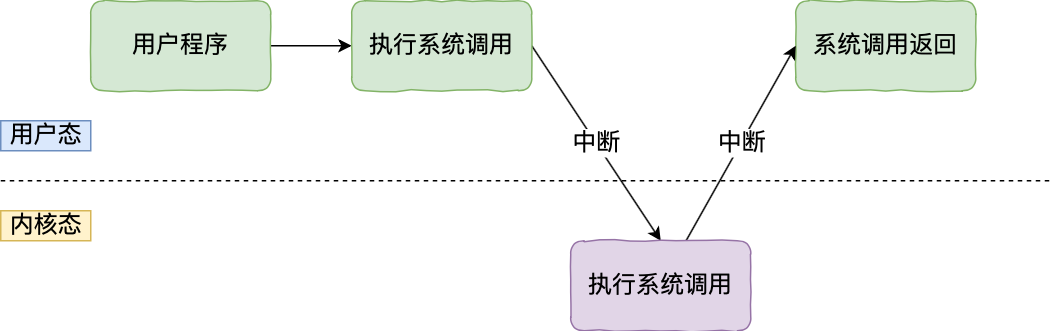
内核程序执行在内核态,用户程序执行在用户态。当应用程序使用系统调用时,会产生一个中断。发生中断后, CPU 会中断当前在执行的用户程序,转而跳转到中断处理程序,也就是开始执行内核程序。内核处理完后,主动触发中断,把 CPU 执行权限交回给用户程序,回到用户态继续工作。
Linux 的设计
Linux 的开山始祖是来自一位名叫 Linus Torvalds 的芬兰小伙子,他在 1991 年用 C 语言写出了第一版的 Linux 操作系统,那年他 22 岁。
完成第一版 Linux 后,Linus Torvalds 就在网络上发布了 Linux 内核的源代码,每个人都可以免费下载和使用。
Linux 内核设计的理念主要有这几个点:
- MultiTask,多任务
- SMP,对称多处理
- ELF,可执行文件链接格式
- Monolithic Kernel,宏内核
MultiTask
MultiTask 的意思是多任务,代表着 Linux 是一个多任务的操作系统。
多任务意味着可以有多个任务同时执行,这里的「同时」可以是并发或并行:
- 对于单核 CPU 时,可以让每个任务执行一小段时间,时间到就切换另外一个任务,从宏观角度看,一段时间内执行了多个任务,这被称为并发。
- 对于多核 CPU 时,多个任务可以同时被不同核心的 CPU 同时执行,这被称为并行。
SMP
SMP 的意思是对称多处理,代表着每个 CPU 的地位是相等的,对资源的使用权限也是相同的,多个 CPU 共享同一个内存,每个 CPU 都可以访问完整的内存和硬件资源。
这个特点决定了 Linux 操作系统不会有某个 CPU 单独服务应用程序或内核程序,而是每个程序都可以被分配到任意一个 CPU 上被执行。
ELF
ELF 的意思是可执行文件链接格式,它是 Linux 操作系统中可执行文件的存储格式,你可以从下图看到它的结构:
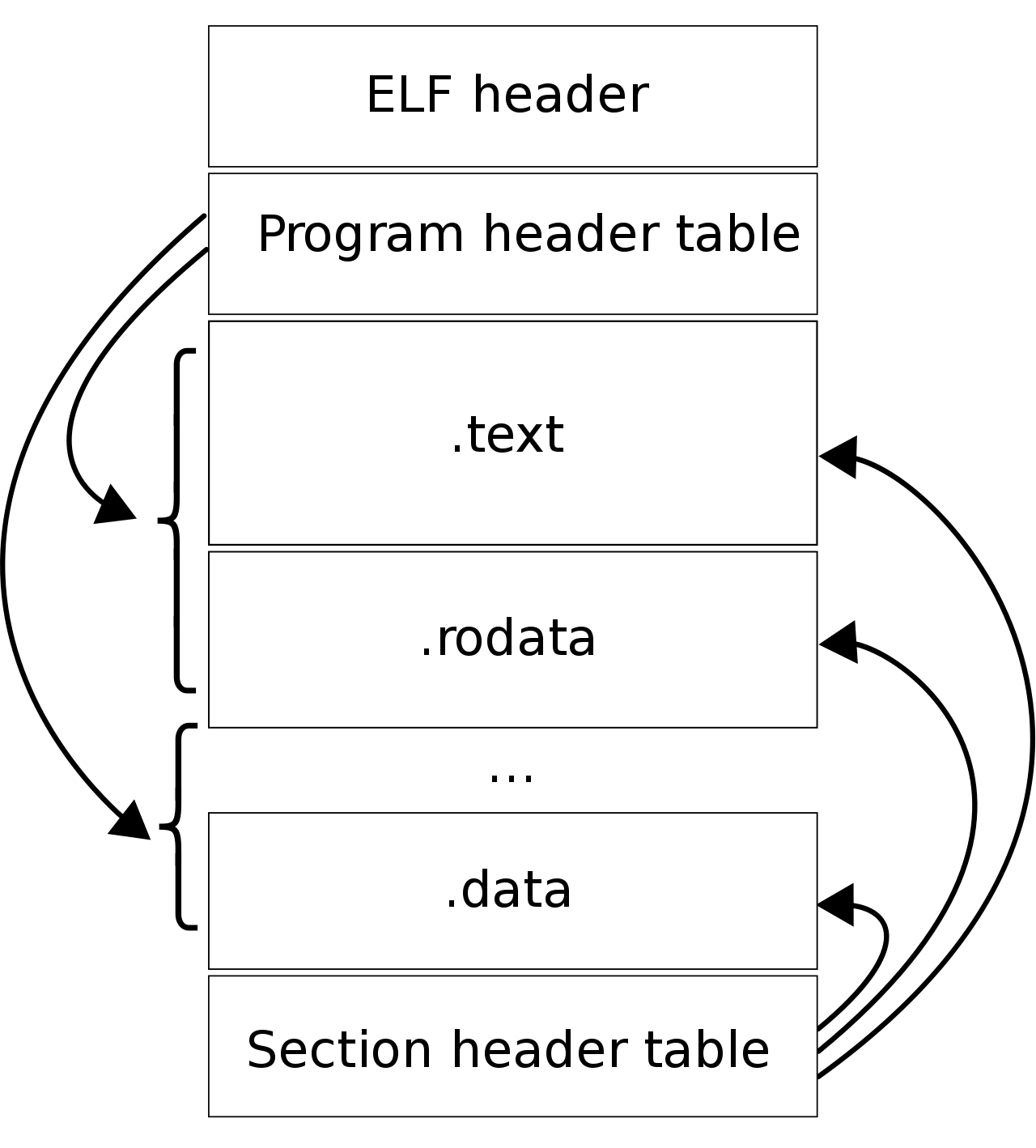
ELF 把文件分成了一个个分段,每一个段都有自己的作用,具体每个段的作用这里我就不详细说明了,感兴趣的同学可以去看《程序员的自我修养——链接、装载和库》这本书。
另外,ELF 文件有两种索引,Program header table 中记录了「运行时」所需的段,而 Section header table 记录了二进制文件中各个「段的首地址」。
那 ELF 文件怎么生成的呢?
我们编写的代码,首先通过「编译器」编译成汇编代码,接着通过「汇编器」变成目标代码,也就是目标文件,最后通过「链接器」把多个目标文件以及调用的各种函数库链接起来,形成一个可执行文件,也就是 ELF 文件。
那 ELF 文件是怎么被执行的呢?
执行 ELF 文件的时候,会通过「装载器」把 ELF 文件装载到内存里,CPU 读取内存中的指令和数据,于是程序就被执行起来了。
Monolithic Kernel
Monolithic Kernel 的意思是宏内核,Linux 内核架构就是宏内核,意味着 Linux 的内核是一个完整的可执行程序,且拥有最高的权限。
宏内核的特征是系统内核的所有模块,比如进程调度、内存管理、文件系统、设备驱动等,都运行在内核态。
不过,Linux 也实现了动态加载内核模块的功能,例如大部分设备驱动是以可加载模块的形式存在的,与内核其他模块解耦,让驱动开发和驱动加载更为方便、灵活。
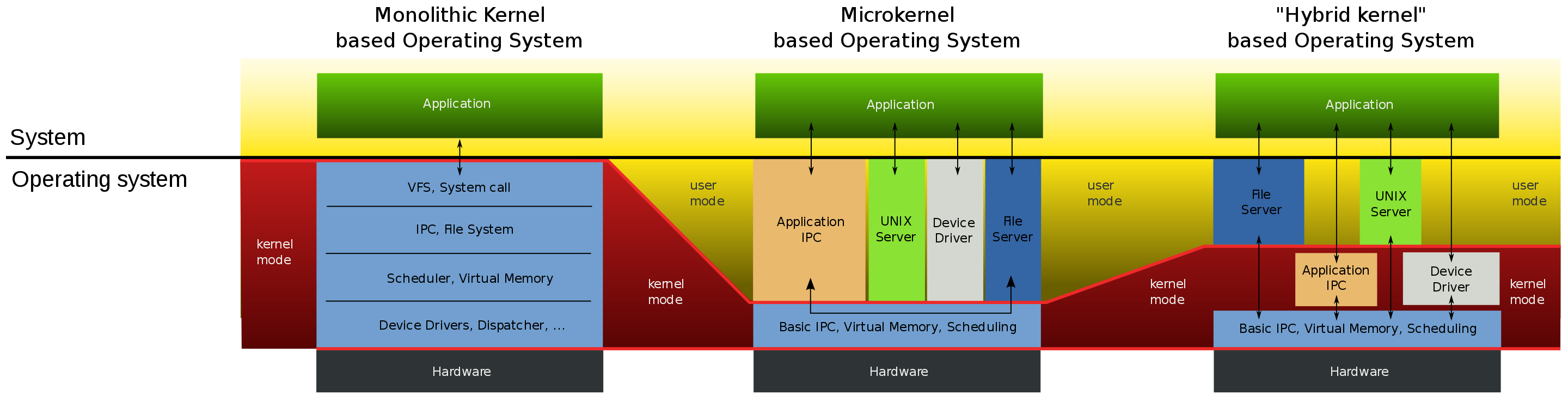
与宏内核相反的是微内核,微内核架构的内核只保留最基本的能力,比如进程调度、虚拟机内存、中断等,把一些应用放到了用户空间,比如驱动程序、文件系统等。这样服务与服务之间是隔离的,单个服务出现故障或者完全攻击,也不会导致整个操作系统挂掉,提高了操作系统的稳定性和可靠性。
微内核内核功能少,可移植性高,相比宏内核有一点不好的地方在于,由于驱动程序不在内核中,而且驱动程序一般会频繁调用底层能力的,于是驱动和硬件设备交互就需要频繁切换到内核态,这样会带来性能损耗。华为的鸿蒙操作系统的内核架构就是微内核。
还有一种内核叫混合类型内核,它的架构有点像微内核,内核里面会有一个最小版本的内核,然后其他模块会在这个基础上搭建,然后实现的时候会跟宏内核类似,也就是把整个内核做成一个完整的程序,大部分服务都在内核中,这就像是宏内核的方式包裹着一个微内核。
Windows 设计
当今 Windows 7、Windows 10 使用的内核叫 Windows NT,NT 全称叫 New Technology。
下图是 Windows NT 的结构图片:
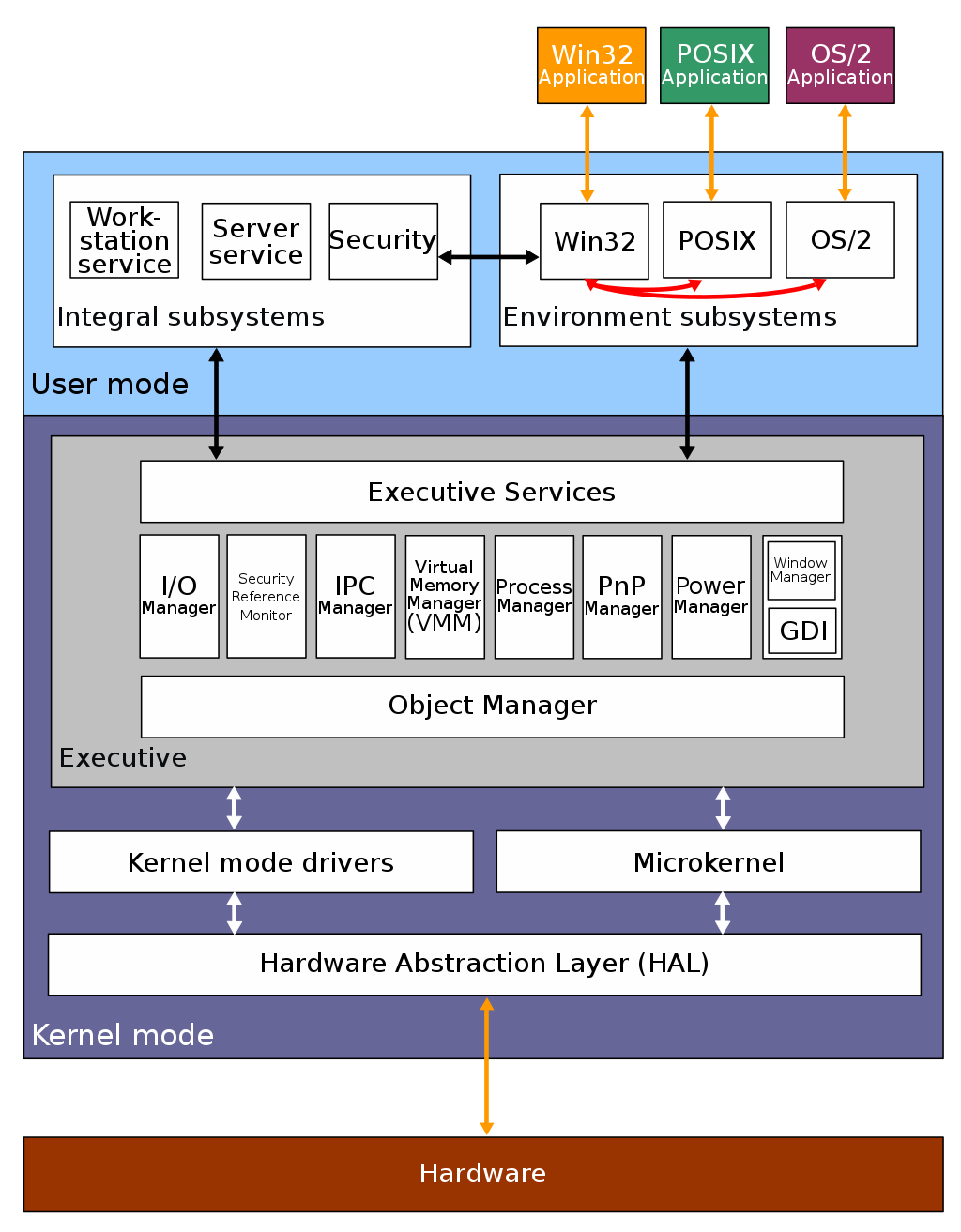
Windows 和 Linux 一样,同样支持 MultiTask 和 SMP,但不同的是,Window 的内核设计是混合型内核,在上图你可以看到内核中有一个 MicroKernel 模块,这个就是最小版本的内核,而整个内核实现是一个完整的程序,含有非常多模块。
Windows 的可执行文件的格式与 Linux 也不同,所以这两个系统的可执行文件是不可以在对方上运行的。
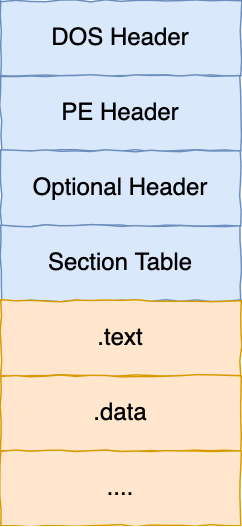
Windows 的可执行文件格式叫 PE,称为可移植执行文件,扩展名通常是.exe、.dll、.sys等。
PE 的结构你可以从下图中看到,它与 ELF 结构有一点相似。
总结
对于内核的架构一般有这三种类型:
- 宏内核,包含多个模块,整个内核像一个完整的程序;
- 微内核,有一个最小版本的内核,一些模块和服务则由用户态管理;
- 混合内核,是宏内核和微内核的结合体,内核中抽象出了微内核的概念,也就是内核中会有一个小型的内核,其他模块就在这个基础上搭建,整个内核是个完整的程序;
Linux 的内核设计是采用了宏内核,Window 的内核设计则是采用了混合内核。
这两个操作系统的可执行文件格式也不一样, Linux 可执行文件格式叫作 ELF,Windows 可执行文件格式叫作 PE。
内存管理
为什么要有虚拟内存?
本篇跟大家说说内存管理,内存管理还是比较重要的一个环节,理解了它,至少对整个操作系统的工作会有一个初步的轮廓,这也难怪面试的时候常问内存管理。
干就完事,本文的提纲:
虚拟内存
如果你是电子相关专业的,肯定在大学里捣鼓过单片机。
单片机是没有操作系统的,所以每次写完代码,都需要借助工具把程序烧录进去,这样程序才能跑起来。
另外,单片机的 CPU 是直接操作内存的「物理地址」。

在这种情况下,要想在内存中同时运行两个程序是不可能的。如果第一个程序在 2000 的位置写入一个新的值,将会擦掉第二个程序存放在相同位置上的所有内容,所以同时运行两个程序是根本行不通的,这两个程序会立刻崩溃。
操作系统是如何解决这个问题呢?
这里关键的问题是这两个程序都引用了绝对物理地址,而这正是我们最需要避免的。
我们可以把进程所使用的地址「隔离」开来,即让操作系统为每个进程分配独立的一套「虚拟地址」,人人都有,大家自己玩自己的地址就行,互不干涉。但是有个前提每个进程都不能访问物理地址,至于虚拟地址最终怎么落到物理内存里,对进程来说是透明的,操作系统已经把这些都安排的明明白白了。

操作系统会提供一种机制,将不同进程的虚拟地址和不同内存的物理地址映射起来。
如果程序要访问虚拟地址的时候,由操作系统转换成不同的物理地址,这样不同的进程运行的时候,写入的是不同的物理地址,这样就不会冲突了。
于是,这里就引出了两种地址的概念:
- 我们程序所使用的内存地址叫做虚拟内存地址(Virtual Memory Address)
- 实际存在硬件里面的空间地址叫物理内存地址(Physical Memory Address)。
操作系统引入了虚拟内存,进程持有的虚拟地址会通过 CPU 芯片中的内存管理单元(MMU)的映射关系,来转换变成物理地址,然后再通过物理地址访问内存,如下图所示:
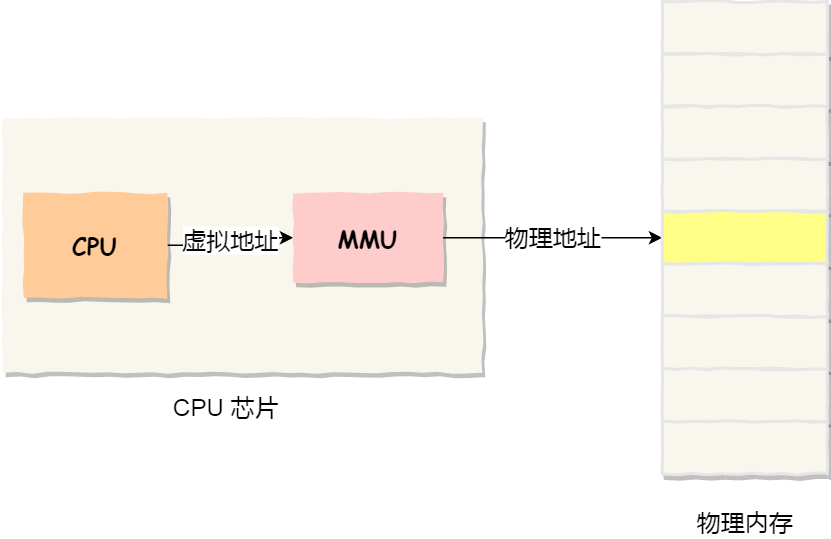
操作系统是如何管理虚拟地址与物理地址之间的关系?
主要有两种方式,分别是内存分段和内存分页,分段是比较早提出的,我们先来看看内存分段。
内存分段
程序是由若干个逻辑分段组成的,如可由代码分段、数据分段、栈段、堆段组成。不同的段是有不同的属性的,所以就用分段(*Segmentation*)的形式把这些段分离出来。
分段机制下,虚拟地址和物理地址是如何映射的?
分段机制下的虚拟地址由两部分组成,段选择因子和段内偏移量。
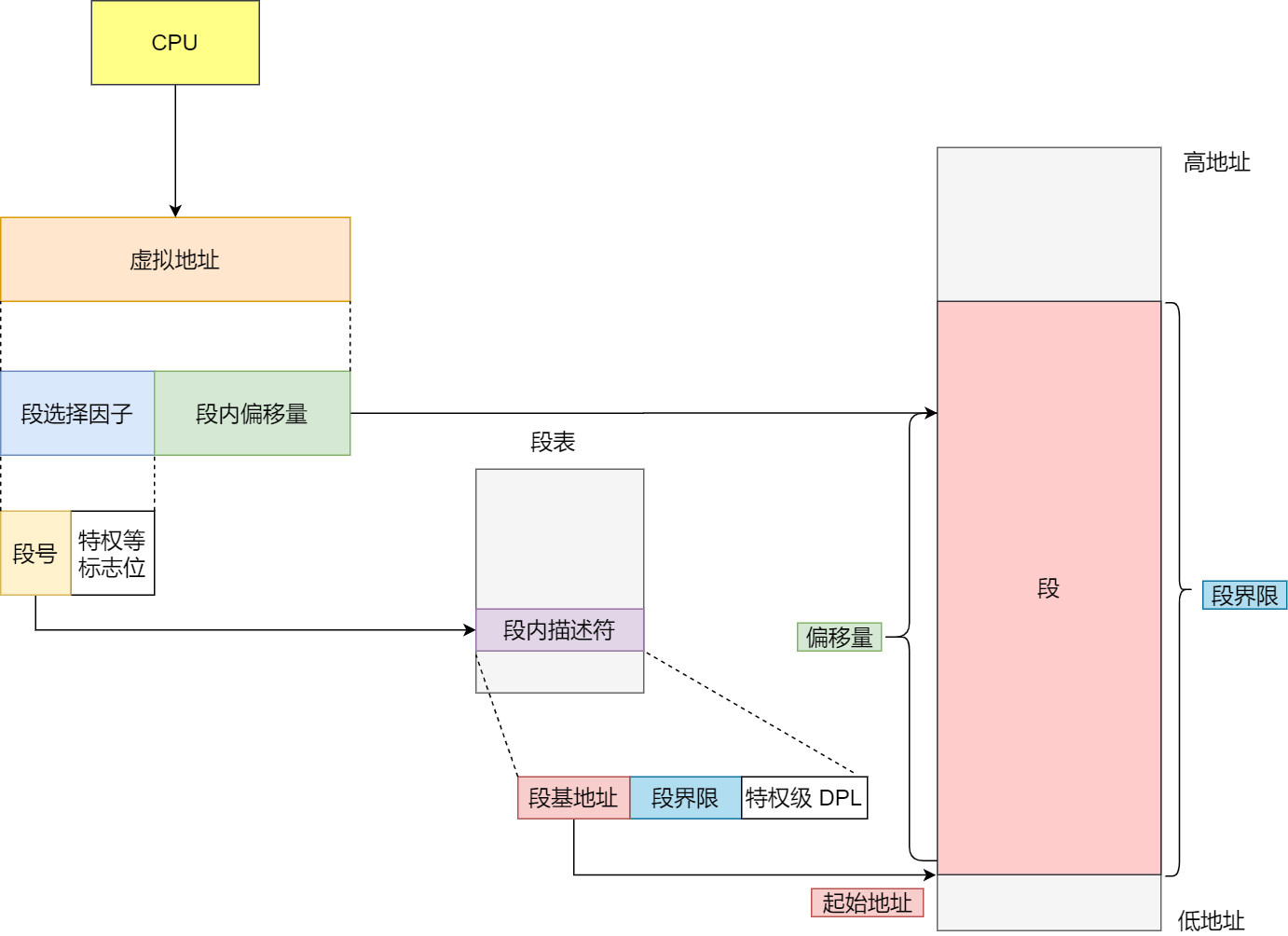
段选择因子和段内偏移量:
- 段选择因子就保存在段寄存器里面。段选择因子里面最重要的是段号,用作段表的索引。段表里面保存的是这个段的基地址、段的界限和特权等级等。
- 虚拟地址中的段内偏移量应该位于 0 和段界限之间,如果段内偏移量是合法的,就将段基地址加上段内偏移量得到物理内存地址。
在上面,知道了虚拟地址是通过段表与物理地址进行映射的,分段机制会把程序的虚拟地址分成 4 个段,每个段在段表中有一个项,在这一项找到段的基地址,再加上偏移量,于是就能找到物理内存中的地址,如下图:
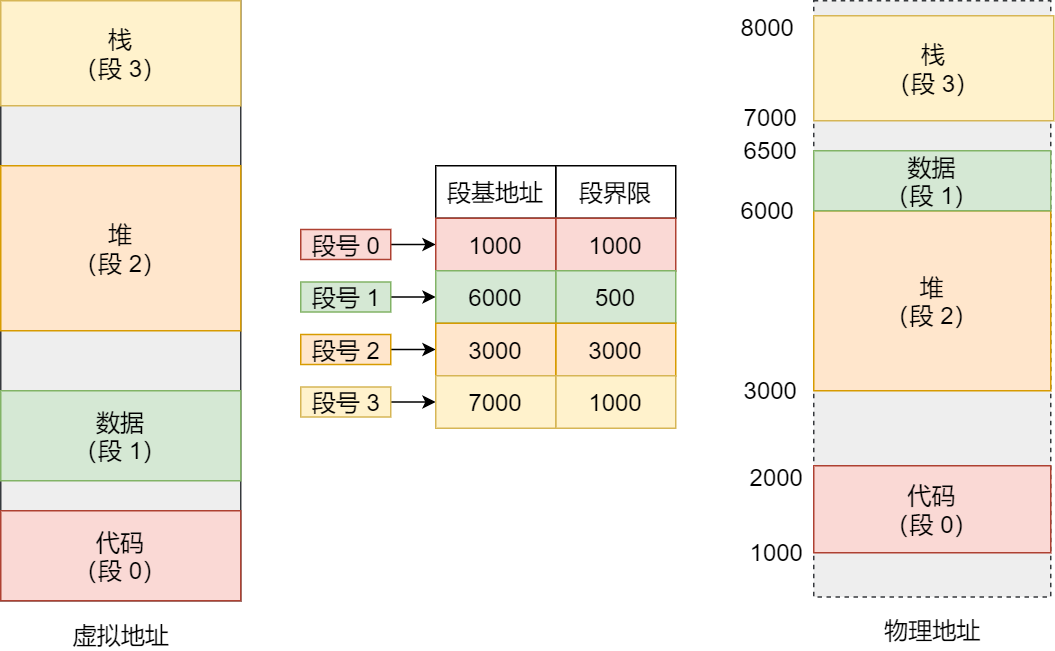
如果要访问段 3 中偏移量 500 的虚拟地址,我们可以计算出物理地址为,段 3 基地址 7000 + 偏移量 500 = 7500。
分段的办法很好,解决了程序本身不需要关心具体的物理内存地址的问题,但它也有一些不足之处:
- 第一个就是内存碎片的问题。
- 第二个就是内存交换的效率低的问题。
接下来,说说为什么会有这两个问题。
我们先来看看,分段为什么会产生内存碎片的问题?
我们来看看这样一个例子。假设有 1G 的物理内存,用户执行了多个程序,其中:
- 游戏占用了 512MB 内存
- 浏览器占用了 128MB 内存
- 音乐占用了 256 MB 内存。
这个时候,如果我们关闭了浏览器,则空闲内存还有 1024 - 512 - 256 = 256MB。
如果这个 256MB 不是连续的,被分成了两段 128 MB 内存,这就会导致没有空间再打开一个 200MB 的程序。
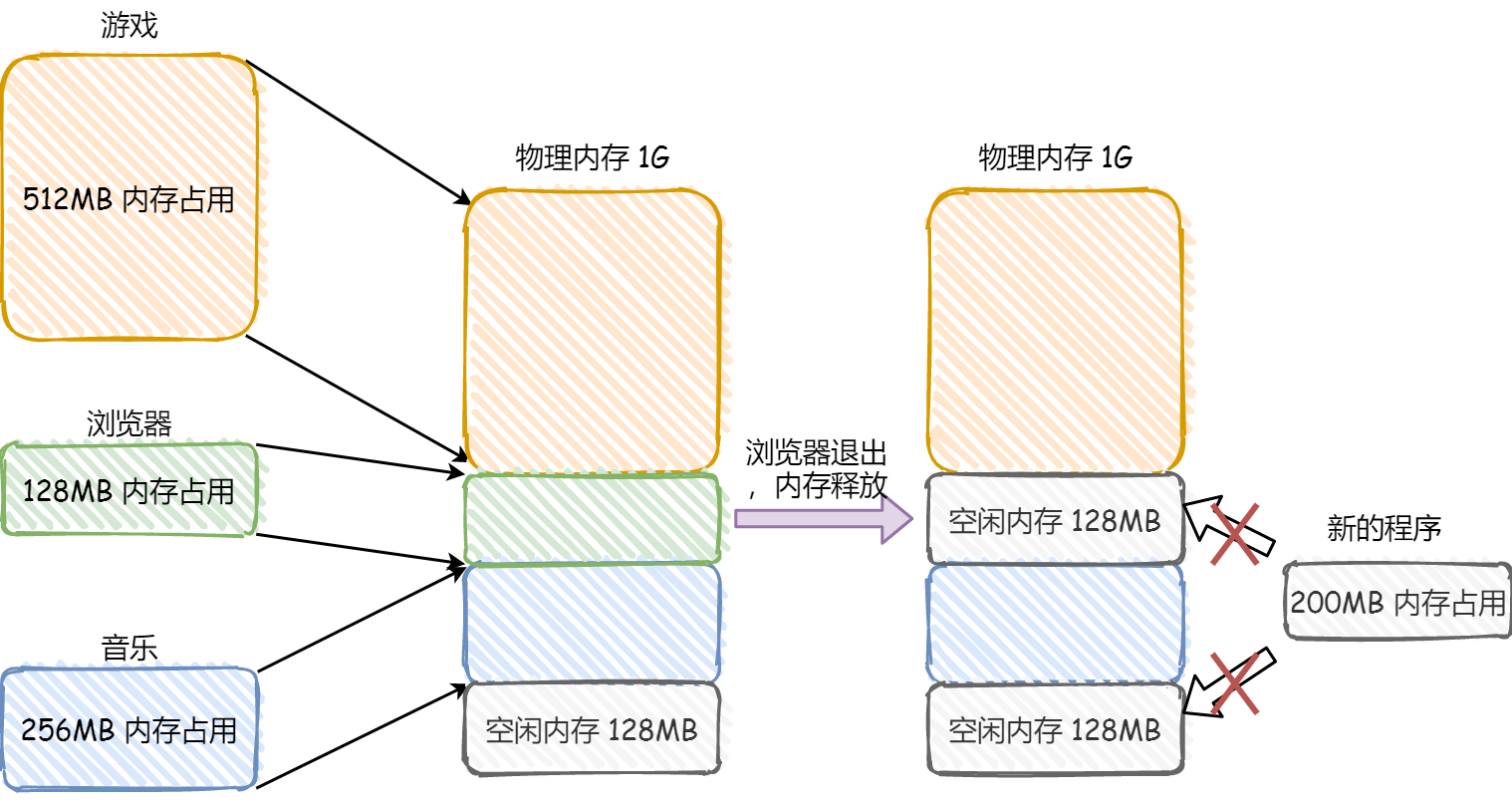
内存分段会出现内存碎片吗?
内存碎片主要分为,内部内存碎片和外部内存碎片。
内存分段管理可以做到段根据实际需求分配内存,所以有多少需求就分配多大的段,所以不会出现内部内存碎片。
但是由于每个段的长度不固定,所以多个段未必能恰好使用所有的内存空间,会产生了多个不连续的小物理内存,导致新的程序无法被装载,所以会出现外部内存碎片的问题。
解决「外部内存碎片」的问题就是内存交换。
可以把音乐程序占用的那 256MB 内存写到硬盘上,然后再从硬盘上读回来到内存里。不过再读回的时候,我们不能装载回原来的位置,而是紧紧跟着那已经被占用了的 512MB 内存后面。这样就能空缺出连续的 256MB 空间,于是新的 200MB 程序就可以装载进来。
这个内存交换空间,在 Linux 系统里,也就是我们常看到的 Swap 空间,这块空间是从硬盘划分出来的,用于内存与硬盘的空间交换。
再来看看,分段为什么会导致内存交换效率低的问题?
对于多进程的系统来说,用分段的方式,外部内存碎片是很容易产生的,产生了外部内存碎片,那不得不重新 Swap 内存区域,这个过程会产生性能瓶颈。
因为硬盘的访问速度要比内存慢太多了,每一次内存交换,我们都需要把一大段连续的内存数据写到硬盘上。
所以,如果内存交换的时候,交换的是一个占内存空间很大的程序,这样整个机器都会显得卡顿。
为了解决内存分段的「外部内存碎片和内存交换效率低」的问题,就出现了内存分页。
内存分页
分段的好处就是能产生连续的内存空间,但是会出现「外部内存碎片和内存交换的空间太大」的问题。
要解决这些问题,那么就要想出能少出现一些内存碎片的办法。另外,当需要进行内存交换的时候,让需要交换写入或者从磁盘装载的数据更少一点,这样就可以解决问题了。这个办法,也就是内存分页(Paging)。
分页是把整个虚拟和物理内存空间切成一段段固定尺寸的大小。这样一个连续并且尺寸固定的内存空间,我们叫页(Page)。在 Linux 下,每一页的大小为 4KB。
虚拟地址与物理地址之间通过页表来映射,如下图:
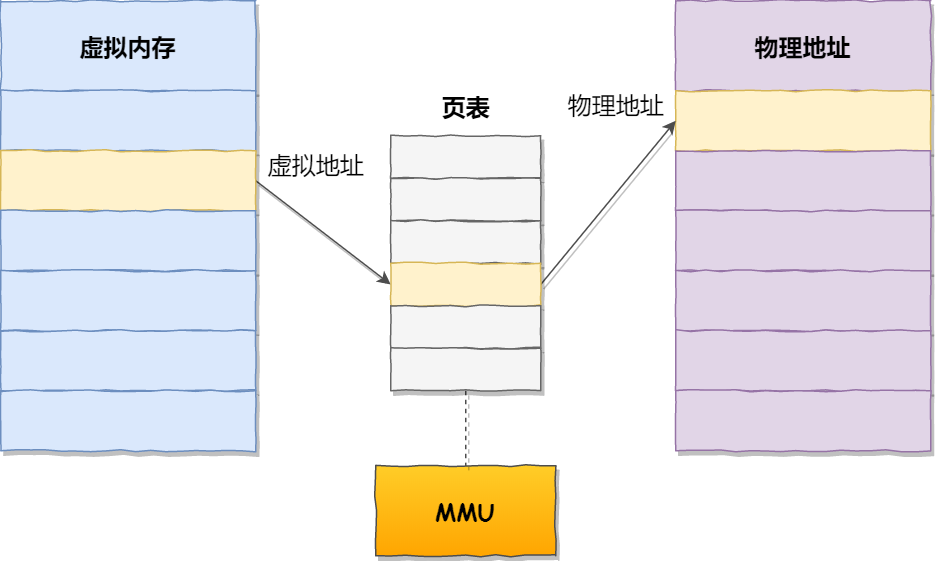
页表是存储在内存里的,内存管理单元 (MMU)就做将虚拟内存地址转换成物理地址的工作。
而当进程访问的虚拟地址在页表中查不到时,系统会产生一个缺页异常,进入系统内核空间分配物理内存、更新进程页表,最后再返回用户空间,恢复进程的运行。
分页是怎么解决分段的「外部内存碎片和内存交换效率低」的问题?
内存分页由于内存空间都是预先划分好的,也就不会像内存分段一样,在段与段之间会产生间隙非常小的内存,这正是分段会产生外部内存碎片的原因。而采用了分页,页与页之间是紧密排列的,所以不会有外部碎片。
但是,因为内存分页机制分配内存的最小单位是一页,即使程序不足一页大小,我们最少只能分配一个页,所以页内会出现内存浪费,所以针对内存分页机制会有内部内存碎片的现象。
如果内存空间不够,操作系统会把其他正在运行的进程中的「最近没被使用」的内存页面给释放掉,也就是暂时写在硬盘上,称为换出(Swap Out)。一旦需要的时候,再加载进来,称为换入(Swap In)。所以,一次性写入磁盘的也只有少数的一个页或者几个页,不会花太多时间,内存交换的效率就相对比较高。
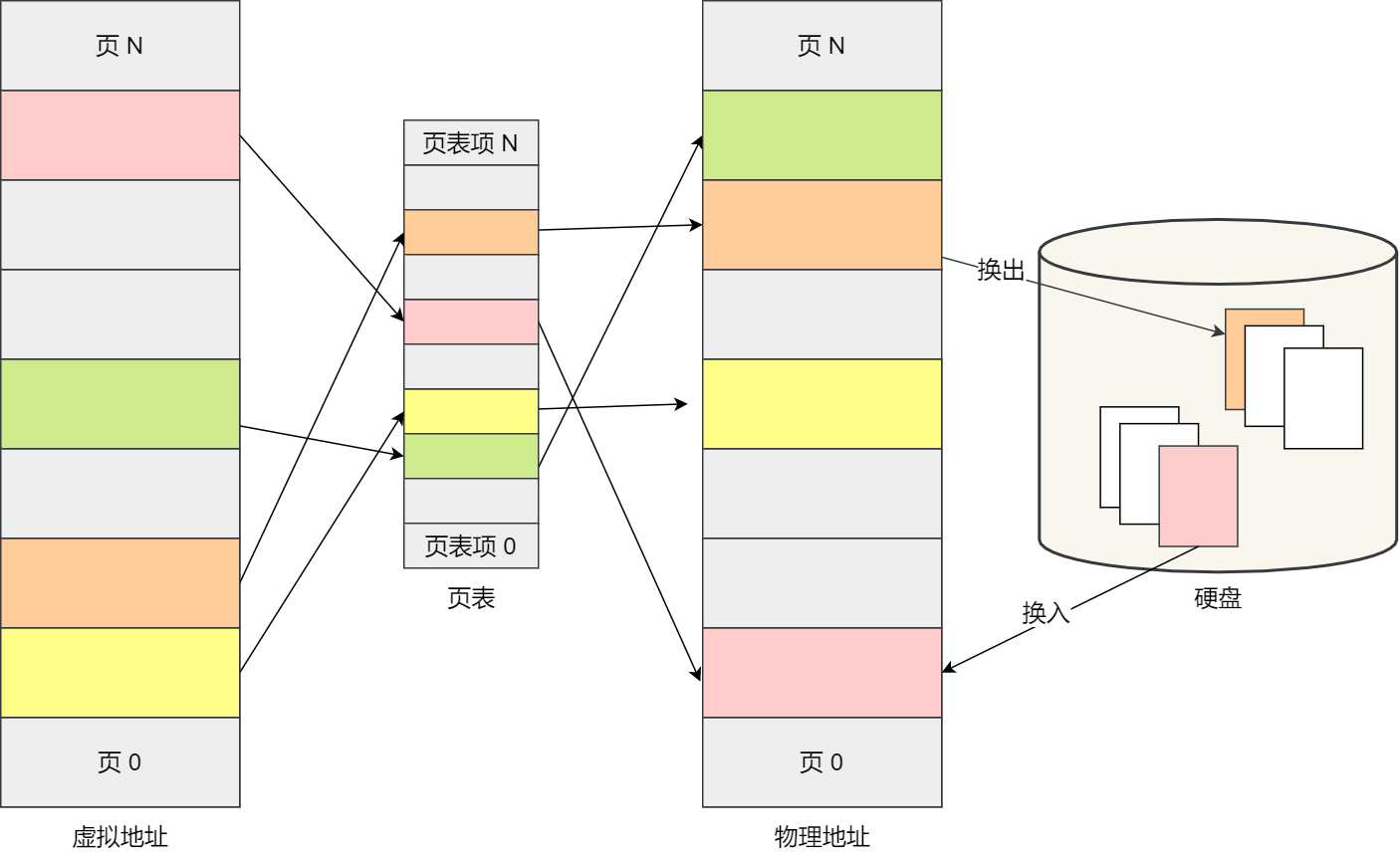
更进一步地,分页的方式使得我们在加载程序的时候,不再需要一次性都把程序加载到物理内存中。我们完全可以在进行虚拟内存和物理内存的页之间的映射之后,并不真的把页加载到物理内存里,而是只有在程序运行中,需要用到对应虚拟内存页里面的指令和数据时,再加载到物理内存里面去。
分页机制下,虚拟地址和物理地址是如何映射的?
在分页机制下,虚拟地址分为两部分,页号和页内偏移。页号作为页表的索引,页表包含物理页每页所在物理内存的基地址,这个基地址与页内偏移的组合就形成了物理内存地址,见下图。
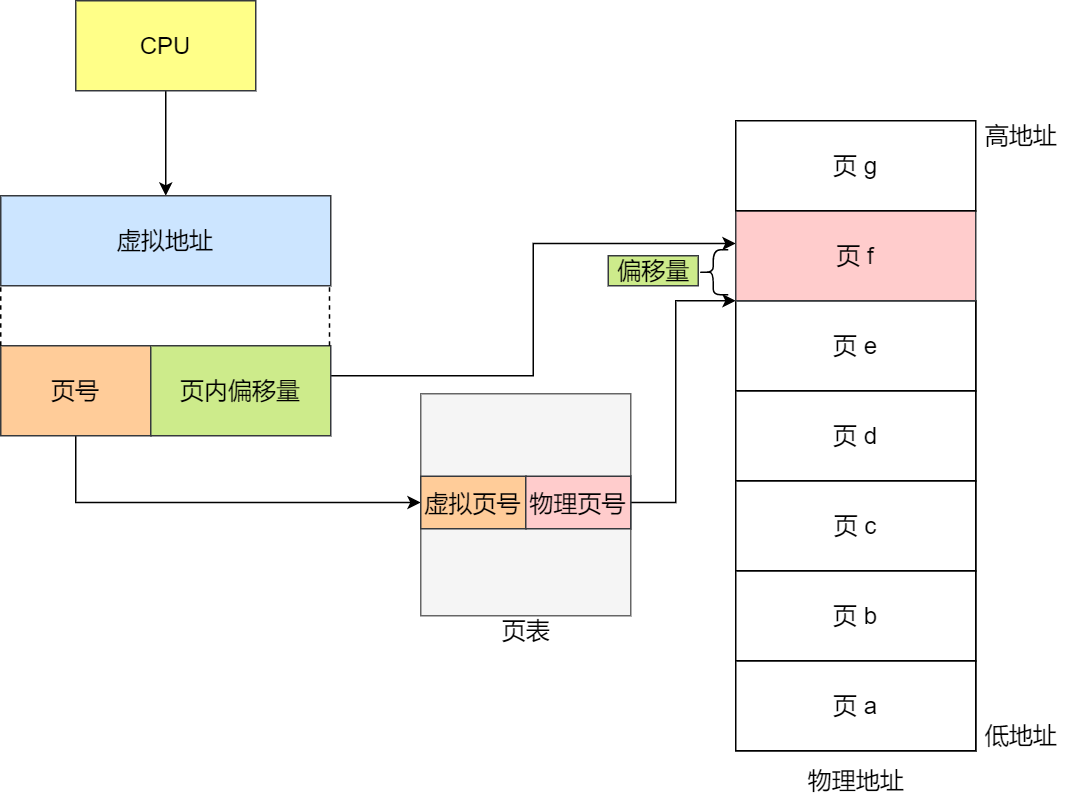
总结一下,对于一个内存地址转换,其实就是这样三个步骤:
- 把虚拟内存地址,切分成页号和偏移量;
- 根据页号,从页表里面,查询对应的物理页号;
- 直接拿物理页号,加上前面的偏移量,就得到了物理内存地址。
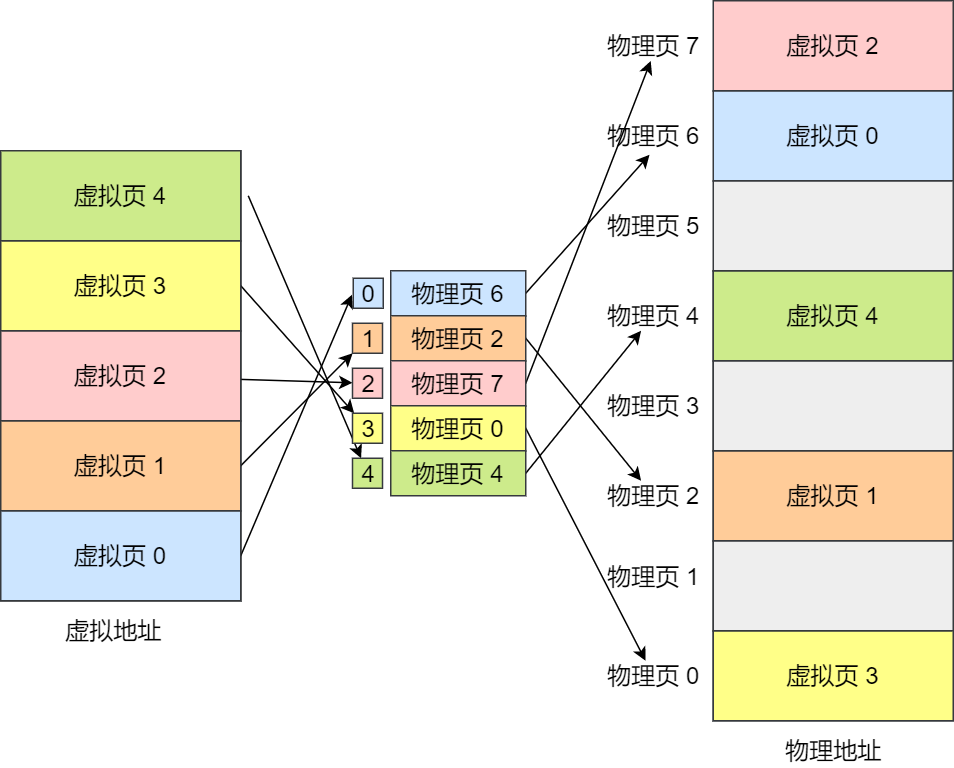
下面举个例子,虚拟内存中的页通过页表映射为了物理内存中的页,如下图:
这看起来似乎没什么毛病,但是放到实际中操作系统,这种简单的分页是肯定是会有问题的。
简单的分页有什么缺陷吗?
有空间上的缺陷。
因为操作系统是可以同时运行非常多的进程的,那这不就意味着页表会非常的庞大。
在 32 位的环境下,虚拟地址空间共有 4GB,假设一个页的大小是 4KB(2^12),那么就需要大约 100 万 (2^20) 个页,每个「页表项」需要 4 个字节大小来存储,那么整个 4GB 空间的映射就需要有 4MB 的内存来存储页表。
这 4MB 大小的页表,看起来也不是很大。但是要知道每个进程都是有自己的虚拟地址空间的,也就说都有自己的页表。
那么,100 个进程的话,就需要 400MB 的内存来存储页表,这是非常大的内存了,更别说 64 位的环境了。
多级页表
要解决上面的问题,就需要采用一种叫作多级页表(Multi-Level Page Table)的解决方案。
在前面我们知道了,对于单页表的实现方式,在 32 位和页大小 4KB 的环境下,一个进程的页表需要装下 100 多万个「页表项」,并且每个页表项是占用 4 字节大小的,于是相当于每个页表需占用 4MB 大小的空间。
我们把这个 100 多万个「页表项」的单级页表再分页,将页表(一级页表)分为 1024 个页表(二级页表),每个表(二级页表)中包含 1024 个「页表项」,形成二级分页。如下图所示:
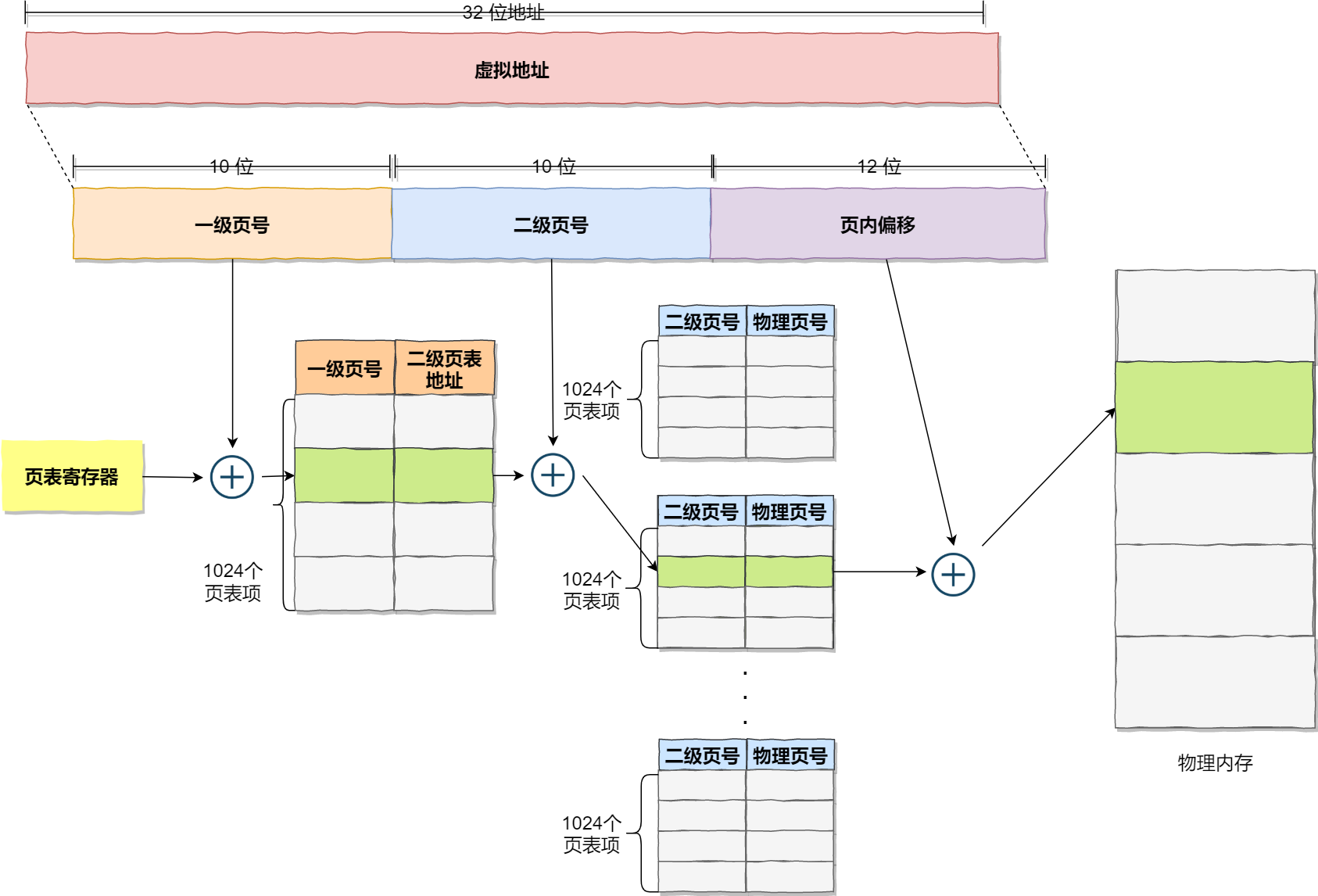
你可能会问,分了二级表,映射 4GB 地址空间就需要 4KB(一级页表)+ 4MB(二级页表)的内存,这样占用空间不是更大了吗?
当然如果 4GB 的虚拟地址全部都映射到了物理内存上的话,二级分页占用空间确实是更大了,但是,我们往往不会为一个进程分配那么多内存。
其实我们应该换个角度来看问题,还记得计算机组成原理里面无处不在的局部性原理么?
每个进程都有 4GB 的虚拟地址空间,而显然对于大多数程序来说,其使用到的空间远未达到 4GB,因为会存在部分对应的页表项都是空的,根本没有分配,对于已分配的页表项,如果存在最近一定时间未访问的页表,在物理内存紧张的情况下,操作系统会将页面换出到硬盘,也就是说不会占用物理内存。
如果使用了二级分页,一级页表就可以覆盖整个 4GB 虚拟地址空间,但如果某个一级页表的页表项没有被用到,也就不需要创建这个页表项对应的二级页表了,即可以在需要时才创建二级页表。做个简单的计算,假设只有 20% 的一级页表项被用到了,那么页表占用的内存空间就只有 4KB(一级页表) + 20% * 4MB(二级页表)= 0.804MB,这对比单级页表的 4MB 是不是一个巨大的节约?
那么为什么不分级的页表就做不到这样节约内存呢?
我们从页表的性质来看,保存在内存中的页表承担的职责是将虚拟地址翻译成物理地址。假如虚拟地址在页表中找不到对应的页表项,计算机系统就不能工作了。所以页表一定要覆盖全部虚拟地址空间,不分级的页表就需要有 100 多万个页表项来映射,而二级分页则只需要 1024 个页表项(此时一级页表覆盖到了全部虚拟地址空间,二级页表在需要时创建)。
我们把二级分页再推广到多级页表,就会发现页表占用的内存空间更少了,这一切都要归功于对局部性原理的充分应用。
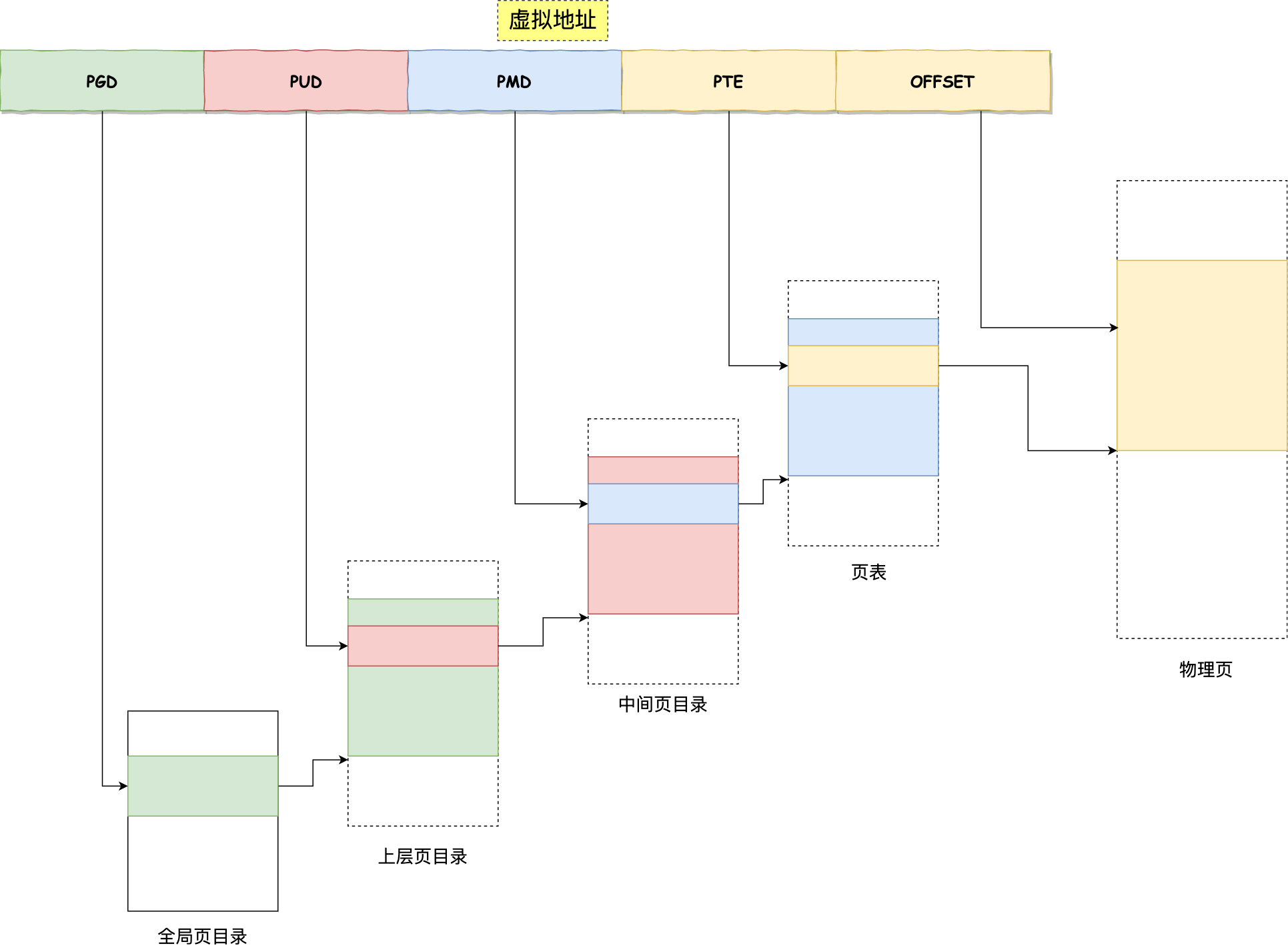
对于 64 位的系统,两级分页肯定不够了,就变成了四级目录,分别是:
- 全局页目录项 PGD(Page Global Directory);
- 上层页目录项 PUD(Page Upper Directory);
- 中间页目录项 PMD(Page Middle Directory);
- 页表项 PTE(Page Table Entry);
TLB
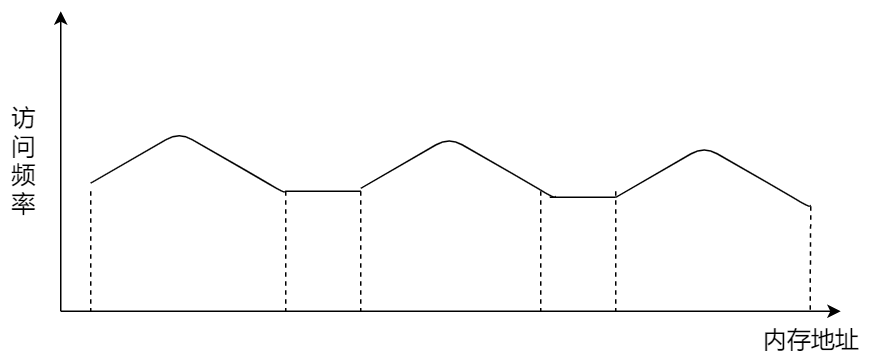
多级页表虽然解决了空间上的问题,但是虚拟地址到物理地址的转换就多了几道转换的工序,这显然就降低了这俩地址转换的速度,也就是带来了时间上的开销。
程序是有局部性的,即在一段时间内,整个程序的执行仅限于程序中的某一部分。相应地,执行所访问的存储空间也局限于某个内存区域。
我们就可以利用这一特性,把最常访问的几个页表项存储到访问速度更快的硬件,于是计算机科学家们,就在 CPU 芯片中,加入了一个专门存放程序最常访问的页表项的 Cache,这个 Cache 就是 TLB(Translation Lookaside Buffer) ,通常称为页表缓存、转址旁路缓存、快表等。
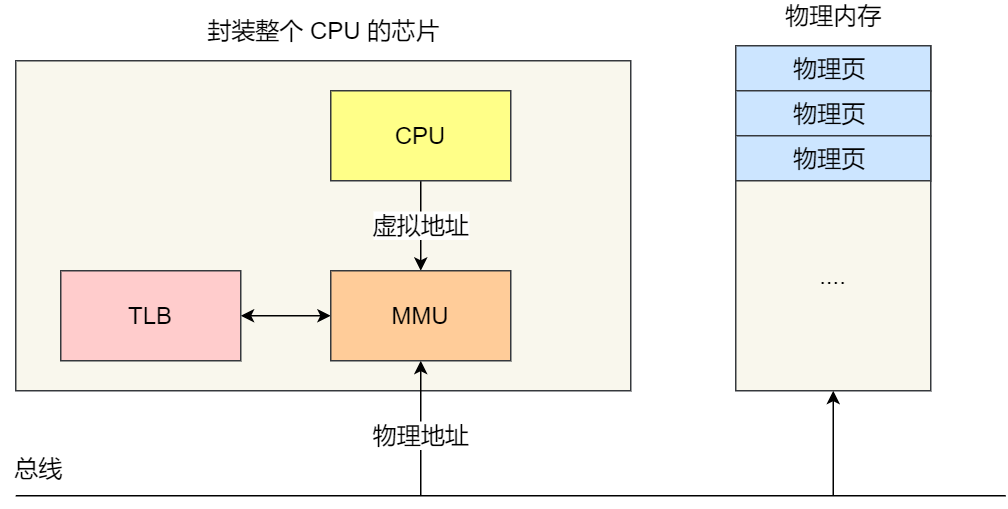
在 CPU 芯片里面,封装了内存管理单元(Memory Management Unit)芯片,它用来完成地址转换和 TLB 的访问与交互。
有了 TLB 后,那么 CPU 在寻址时,会先查 TLB,如果没找到,才会继续查常规的页表。
TLB 的命中率其实是很高的,因为程序最常访问的页就那么几个。
段页式内存管理
内存分段和内存分页并不是对立的,它们是可以组合起来在同一个系统中使用的,那么组合起来后,通常称为段页式内存管理。
段页式内存管理实现的方式:
- 先将程序划分为多个有逻辑意义的段,也就是前面提到的分段机制;
- 接着再把每个段划分为多个页,也就是对分段划分出来的连续空间,再划分固定大小的页;
这样,地址结构就由段号、段内页号和页内位移三部分组成。
用于段页式地址变换的数据结构是每一个程序一张段表,每个段又建立一张页表,段表中的地址是页表的起始地址,而页表中的地址则为某页的物理页号,如图所示:
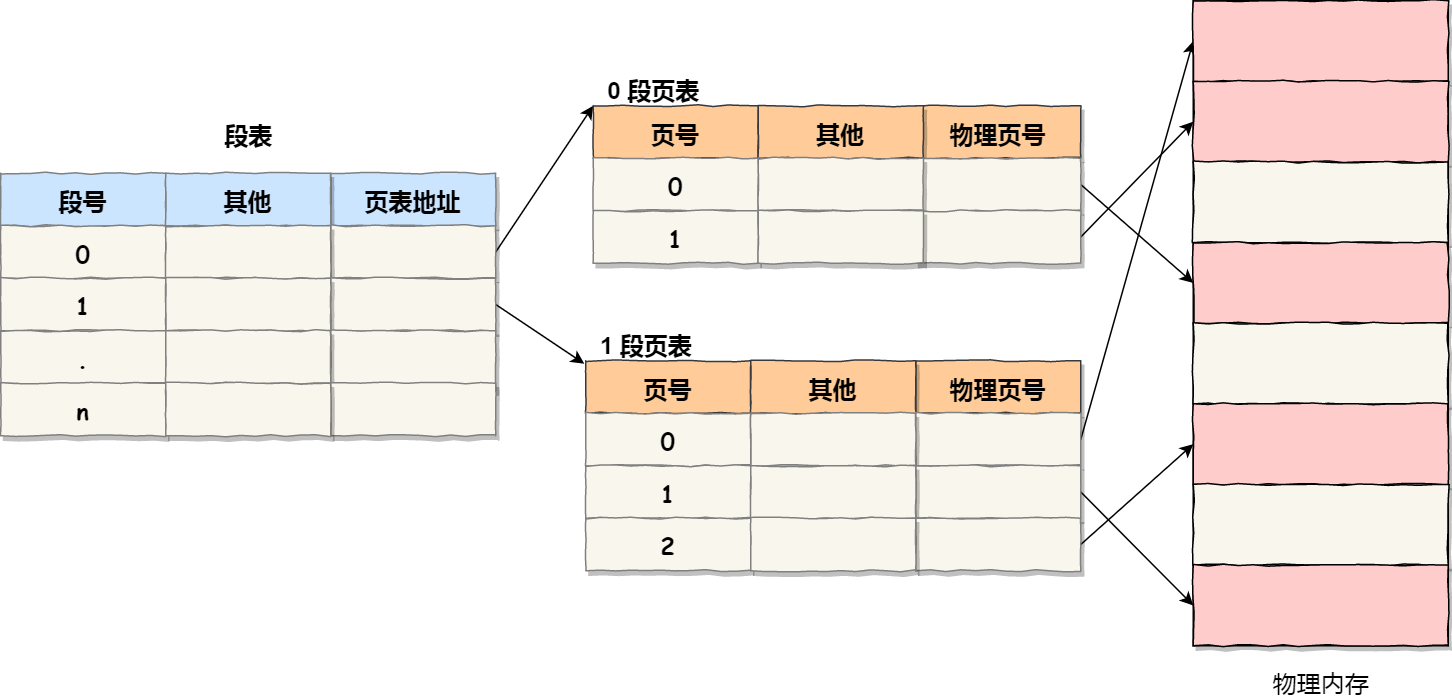
段页式地址变换中要得到物理地址须经过三次内存访问:
- 第一次访问段表,得到页表起始地址;
- 第二次访问页表,得到物理页号;
- 第三次将物理页号与页内位移组合,得到物理地址。
可用软、硬件相结合的方法实现段页式地址变换,这样虽然增加了硬件成本和系统开销,但提高了内存的利用率。
Linux 内存布局
那么,Linux 操作系统采用了哪种方式来管理内存呢?
在回答这个问题前,我们得先看看 Intel 处理器的发展历史。
早期 Intel 的处理器从 80286 开始使用的是段式内存管理。但是很快发现,光有段式内存管理而没有页式内存管理是不够的,这会使它的 X86 系列会失去市场的竞争力。因此,在不久以后的 80386 中就实现了页式内存管理。也就是说,80386 除了完成并完善从 80286 开始的段式内存管理的同时还实现了页式内存管理。
但是这个 80386 的页式内存管理设计时,没有绕开段式内存管理,而是建立在段式内存管理的基础上,这就意味着,页式内存管理的作用是在由段式内存管理所映射而成的地址上再加上一层地址映射。
由于此时由段式内存管理映射而成的地址不再是“物理地址”了,Intel 就称之为“线性地址”(也称虚拟地址)。于是,段式内存管理先将逻辑地址映射成线性地址,然后再由页式内存管理将线性地址映射成物理地址。

这里说明下逻辑地址和线性地址:
- 程序所使用的地址,通常是没被段式内存管理映射的地址,称为逻辑地址;
- 通过段式内存管理映射的地址,称为线性地址,也叫虚拟地址;
逻辑地址是「段式内存管理」转换前的地址,线性地址则是「页式内存管理」转换前的地址。
了解完 Intel 处理器的发展历史后,我们再来说说 Linux 采用了什么方式管理内存?
Linux 内存主要采用的是页式内存管理,但同时也不可避免地涉及了段机制。
这主要是上面 Intel 处理器发展历史导致的,因为 Intel X86 CPU 一律对程序中使用的地址先进行段式映射,然后才能进行页式映射。既然 CPU 的硬件结构是这样,Linux 内核也只好服从 Intel 的选择。
但是事实上,Linux 内核所采取的办法是使段式映射的过程实际上不起什么作用。也就是说,“上有政策,下有对策”,若惹不起就躲着走。
Linux 系统中的每个段都是从 0 地址开始的整个 4GB 虚拟空间(32 位环境下),也就是所有的段的起始地址都是一样的。这意味着,Linux 系统中的代码,包括操作系统本身的代码和应用程序代码,所面对的地址空间都是线性地址空间(虚拟地址),这种做法相当于屏蔽了处理器中的逻辑地址概念,段只被用于访问控制和内存保护。
我们再来瞧一瞧,Linux 的虚拟地址空间是如何分布的?
在 Linux 操作系统中,虚拟地址空间的内部又被分为内核空间和用户空间两部分,不同位数的系统,地址空间的范围也不同。比如最常见的 32 位和 64 位系统,如下所示:
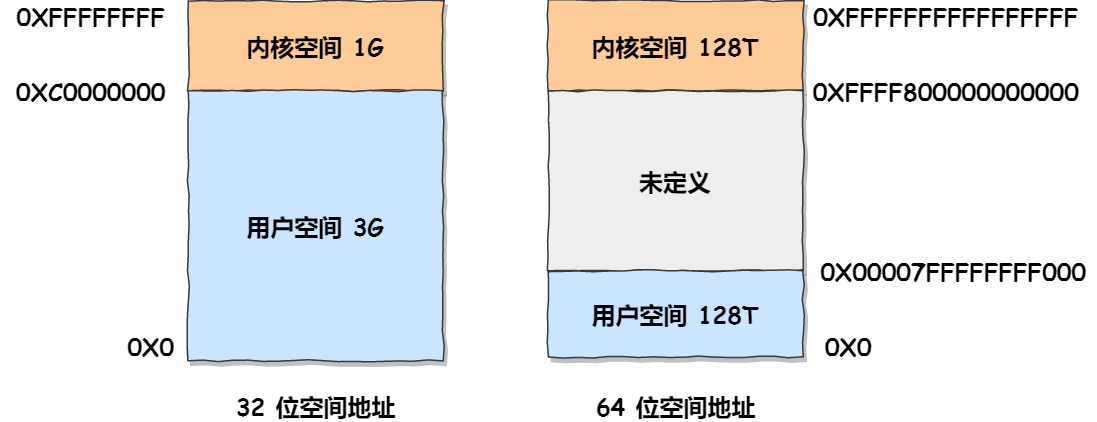
通过这里可以看出:
32位系统的内核空间占用1G,位于最高处,剩下的3G是用户空间;64位系统的内核空间和用户空间都是128T,分别占据整个内存空间的最高和最低处,剩下的中间部分是未定义的。
再来说说,内核空间与用户空间的区别:
- 进程在用户态时,只能访问用户空间内存;
- 只有进入内核态后,才可以访问内核空间的内存;
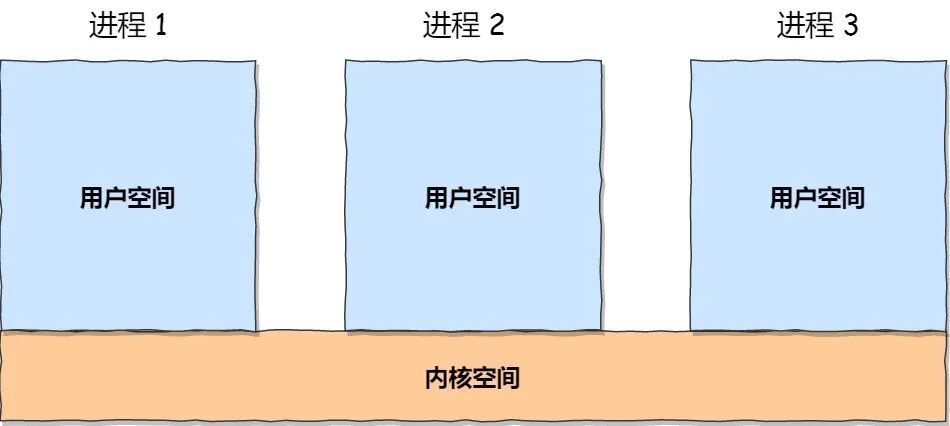
虽然每个进程都各自有独立的虚拟内存,但是每个虚拟内存中的内核地址,其实关联的都是相同的物理内存。这样,进程切换到内核态后,就可以很方便地访问内核空间内存。
接下来,进一步了解虚拟空间的划分情况,用户空间和内核空间划分的方式是不同的,内核空间的分布情况就不多说了。
我们看看用户空间分布的情况,以 32 位系统为例,我画了一张图来表示它们的关系:
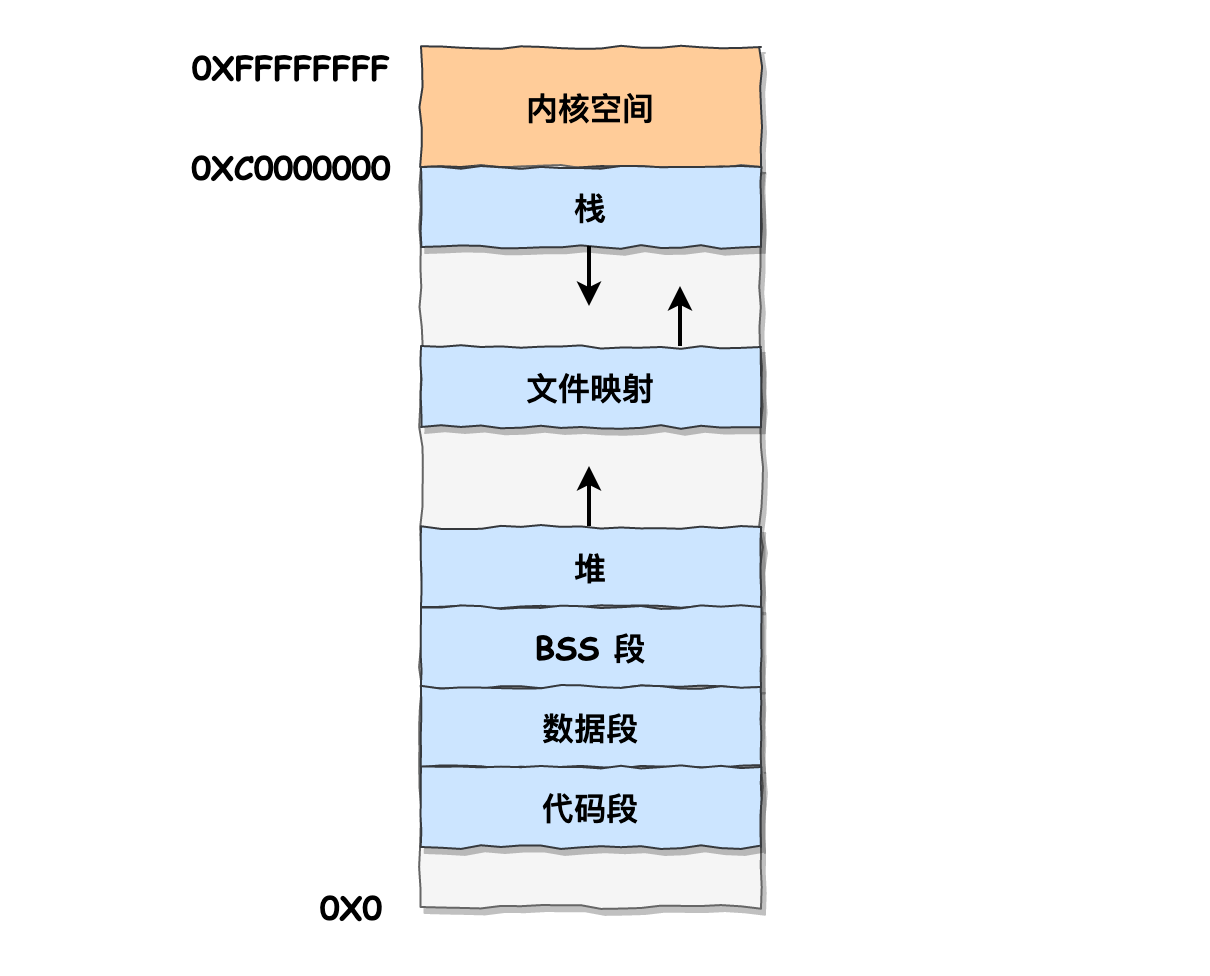
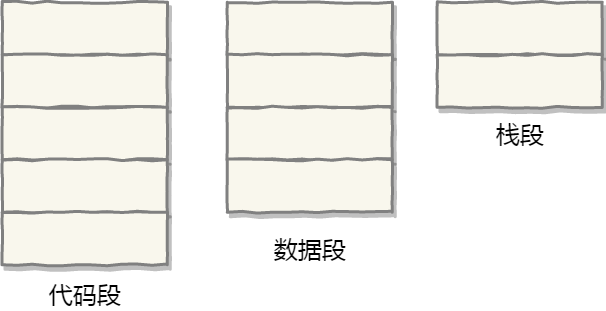
通过这张图你可以看到,用户空间内存,从低到高分别是 6 种不同的内存段:
- 代码段,包括二进制可执行代码;
- 数据段,包括已初始化的静态常量和全局变量;
- BSS 段,包括未初始化的静态变量和全局变量;
- 堆段,包括动态分配的内存,从低地址开始向上增长;
- 文件映射段,包括动态库、共享内存等,从低地址开始向上增长(跟硬件和内核版本有关 (opens new window));
- 栈段,包括局部变量和函数调用的上下文等。栈的大小是固定的,一般是
8 MB。当然系统也提供了参数,以便我们自定义大小;
上图中的内存布局可以看到,代码段下面还有一段内存空间的(灰色部分),这一块区域是「保留区」,之所以要有保留区这是因为在大多数的系统里,我们认为比较小数值的地址不是一个合法地址,例如,我们通常在 C 的代码里会将无效的指针赋值为 NULL。因此,这里会出现一段不可访问的内存保留区,防止程序因为出现 bug,导致读或写了一些小内存地址的数据,而使得程序跑飞。
在这 7 个内存段中,堆和文件映射段的内存是动态分配的。比如说,使用 C 标准库的 malloc() 或者 mmap() ,就可以分别在堆和文件映射段动态分配内存。
总结
为了在多进程环境下,使得进程之间的内存地址不受影响,相互隔离,于是操作系统就为每个进程独立分配一套虚拟地址空间,每个程序只关心自己的虚拟地址就可以,实际上大家的虚拟地址都是一样的,但分布到物理地址内存是不一样的。作为程序,也不用关心物理地址的事情。
每个进程都有自己的虚拟空间,而物理内存只有一个,所以当启用了大量的进程,物理内存必然会很紧张,于是操作系统会通过内存交换技术,把不常使用的内存暂时存放到硬盘(换出),在需要的时候再装载回物理内存(换入)。
那既然有了虚拟地址空间,那必然要把虚拟地址「映射」到物理地址,这个事情通常由操作系统来维护。
那么对于虚拟地址与物理地址的映射关系,可以有分段和分页的方式,同时两者结合都是可以的。
内存分段是根据程序的逻辑角度,分成了栈段、堆段、数据段、代码段等,这样可以分离出不同属性的段,同时是一块连续的空间。但是每个段的大小都不是统一的,这就会导致外部内存碎片和内存交换效率低的问题。
于是,就出现了内存分页,把虚拟空间和物理空间分成大小固定的页,如在 Linux 系统中,每一页的大小为 4KB。由于分了页后,就不会产生细小的内存碎片,解决了内存分段的外部内存碎片问题。同时在内存交换的时候,写入硬盘也就一个页或几个页,这就大大提高了内存交换的效率。
再来,为了解决简单分页产生的页表过大的问题,就有了多级页表,它解决了空间上的问题,但这就会导致 CPU 在寻址的过程中,需要有很多层表参与,加大了时间上的开销。于是根据程序的局部性原理,在 CPU 芯片中加入了 TLB,负责缓存最近常被访问的页表项,大大提高了地址的转换速度。
Linux 系统主要采用了分页管理,但是由于 Intel 处理器的发展史,Linux 系统无法避免分段管理。于是 Linux 就把所有段的基地址设为 0,也就意味着所有程序的地址空间都是线性地址空间(虚拟地址),相当于屏蔽了 CPU 逻辑地址的概念,所以段只被用于访问控制和内存保护。
另外,Linux 系统中虚拟空间分布可分为用户态和内核态两部分,其中用户态的分布:代码段、全局变量、BSS、函数栈、堆内存、映射区。
最后,说下虚拟内存有什么作用?
- 第一,虚拟内存可以使得进程对运行内存超过物理内存大小,因为程序运行符合局部性原理,CPU 访问内存会有很明显的重复访问的倾向性,对于那些没有被经常使用到的内存,我们可以把它换出到物理内存之外,比如硬盘上的 swap 区域。
- 第二,由于每个进程都有自己的页表,所以每个进程的虚拟内存空间就是相互独立的。进程也没有办法访问其他进程的页表,所以这些页表是私有的,这就解决了多进程之间地址冲突的问题。
- 第三,页表里的页表项中除了物理地址之外,还有一些标记属性的比特,比如控制一个页的读写权限,标记该页是否存在等。在内存访问方面,操作系统提供了更好的安全性。
malloc是如何分配内存的?
这次我们就以 malloc 动态内存分配为切入点,我在文中也做了小实验:
- malloc 是如何分配内存的?
- malloc 分配的是物理内存吗?
- malloc(1) 会分配多大的内存?
- free 释放内存,会归还给操作系统吗?
- free() 函数只传入一个内存地址,为什么能知道要释放多大的内存?
发车!
Linux 进程的内存分布长什么样?
在 Linux 操作系统中,虚拟地址空间的内部又被分为内核空间和用户空间两部分,不同位数的系统,地址空间的范围也不同。比如最常见的 32 位和 64 位系统,如下所示:
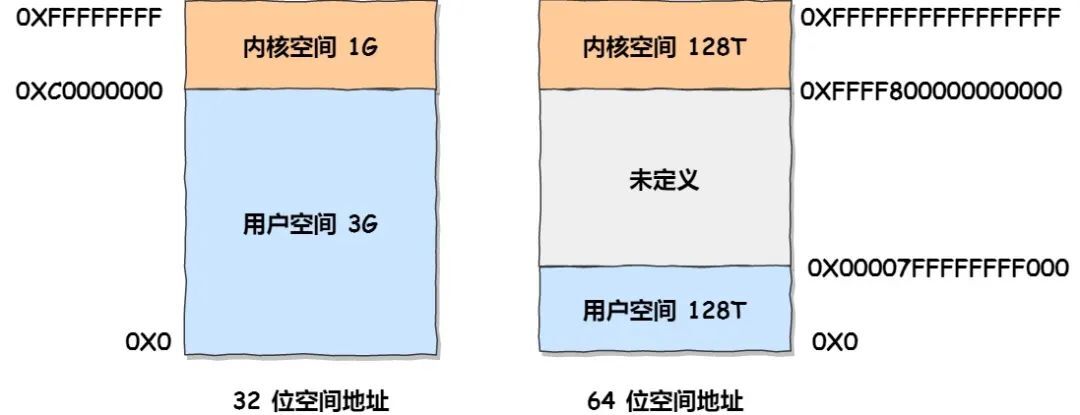
通过这里可以看出:
32位系统的内核空间占用1G,位于最高处,剩下的3G是用户空间;64位系统的内核空间和用户空间都是128T,分别占据整个内存空间的最高和最低处,剩下的中间部分是未定义的。
再来说说,内核空间与用户空间的区别:
- 进程在用户态时,只能访问用户空间内存;
- 只有进入内核态后,才可以访问内核空间的内存;
虽然每个进程都各自有独立的虚拟内存,但是每个虚拟内存中的内核地址,其实关联的都是相同的物理内存。这样,进程切换到内核态后,就可以很方便地访问内核空间内存。
接下来,进一步了解虚拟空间的划分情况,用户空间和内核空间划分的方式是不同的,内核空间的分布情况就不多说了。
我们看看用户空间分布的情况,以 32 位系统为例,我画了一张图来表示它们的关系:
通过这张图你可以看到,用户空间内存从低到高分别是 6 种不同的内存段:
- 代码段,包括二进制可执行代码;
- 数据段,包括已初始化的静态常量和全局变量;
- BSS 段,包括未初始化的静态变量和全局变量;
- 堆段,包括动态分配的内存,从低地址开始向上增长;
- 文件映射段,包括动态库、共享内存等,从低地址开始向上增长(跟硬件和内核版本有关 (opens new window));
- 栈段,包括局部变量和函数调用的上下文等。栈的大小是固定的,一般是
8 MB。当然系统也提供了参数,以便我们自定义大小;
在这 6 个内存段中,堆和文件映射段的内存是动态分配的。比如说,使用 C 标准库的 malloc() 或者 mmap() ,就可以分别在堆和文件映射段动态分配内存。
malloc 是如何分配内存的?
实际上,malloc() 并不是系统调用,而是 C 库里的函数,用于动态分配内存。
malloc 申请内存的时候,会有两种方式向操作系统申请堆内存。
- 方式一:通过 brk() 系统调用从堆分配内存
- 方式二:通过 mmap() 系统调用在文件映射区域分配内存;
方式一实现的方式很简单,就是通过 brk() 函数将「堆顶」指针向高地址移动,获得新的内存空间。如下图:
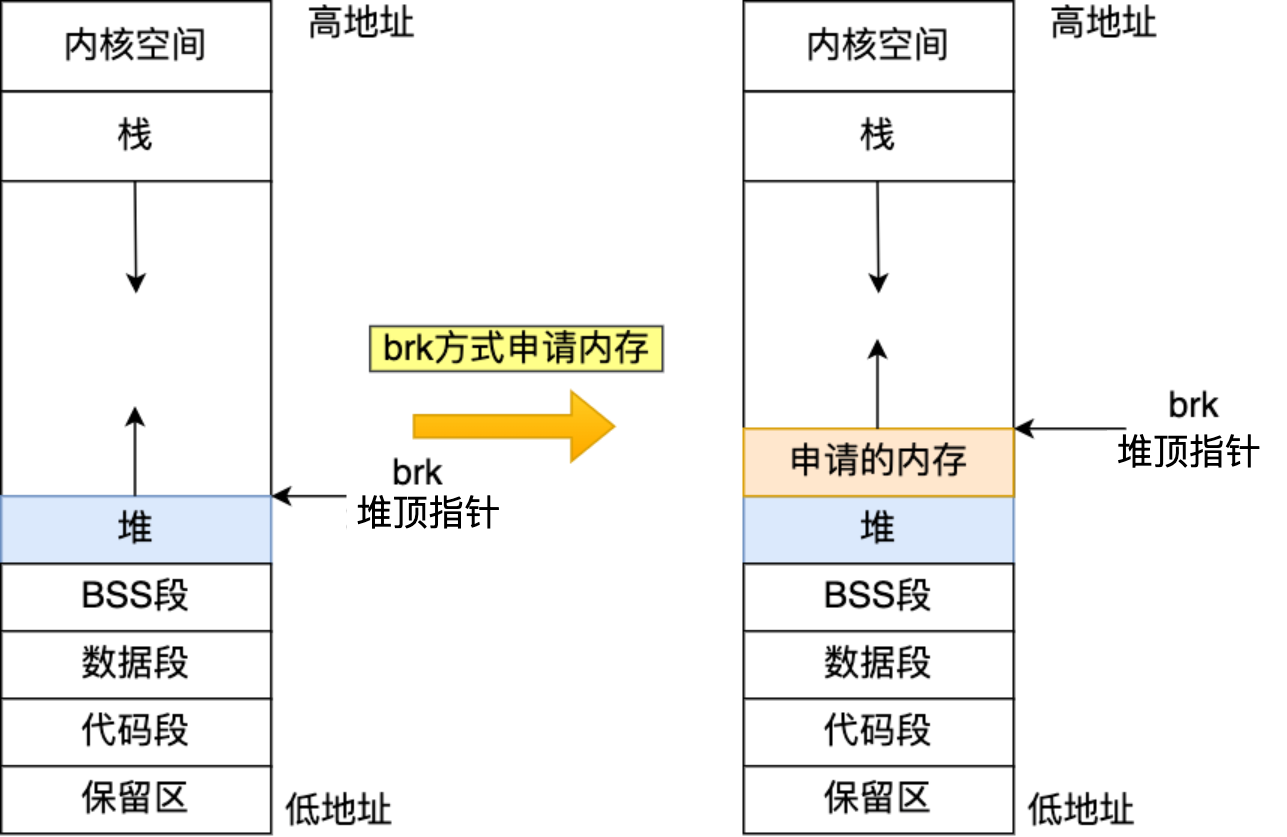
方式二通过 mmap() 系统调用中「私有匿名映射」的方式,在文件映射区分配一块内存,也就是从文件映射区“偷”了一块内存。如下图:
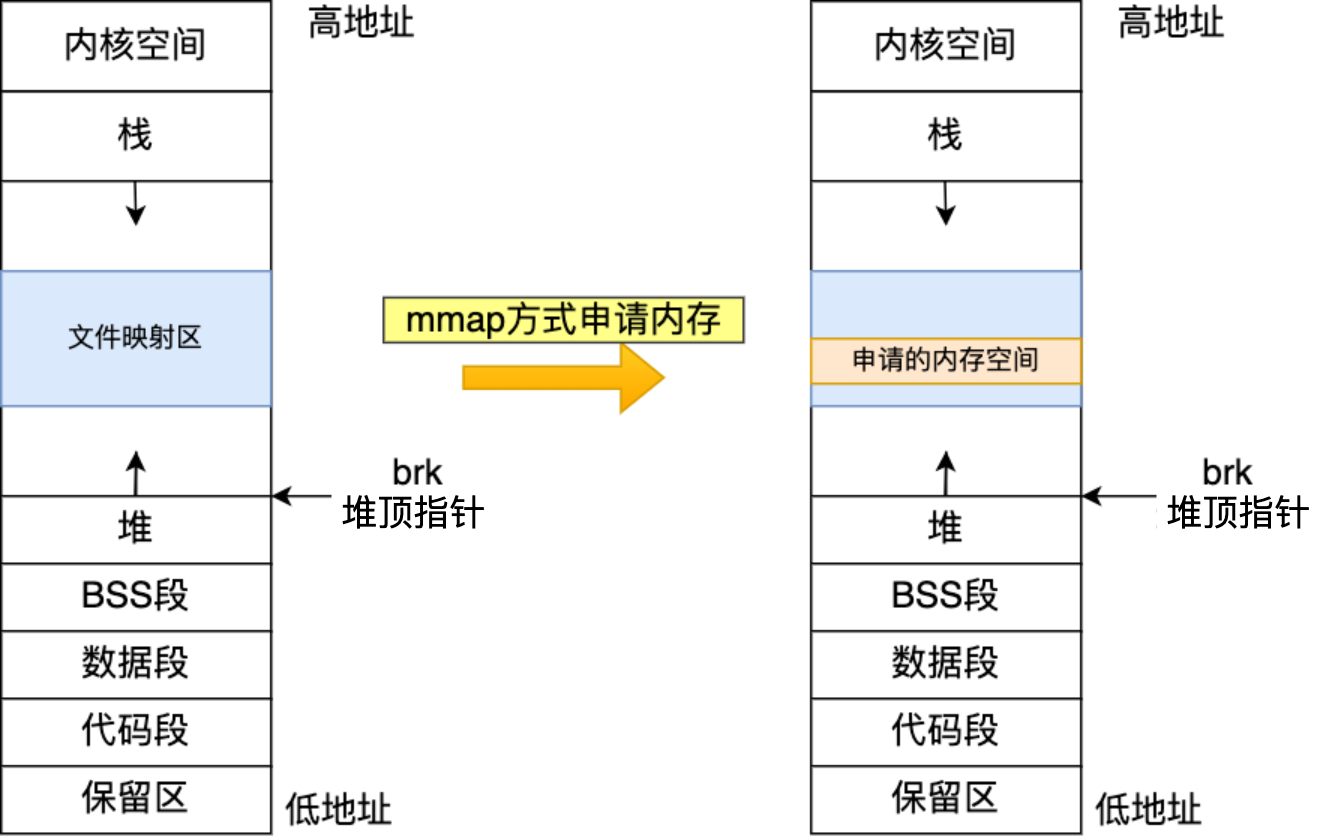
什么场景下 malloc() 会通过 brk() 分配内存?又是什么场景下通过 mmap() 分配内存?
malloc() 源码里默认定义了一个阈值:
- 如果用户分配的内存小于 128 KB,则通过 brk() 申请内存;
- 如果用户分配的内存大于 128 KB,则通过 mmap() 申请内存;
注意,不同的 glibc 版本定义的阈值也是不同的。
malloc() 分配的是物理内存吗?
不是的,malloc() 分配的是虚拟内存。
如果分配后的虚拟内存没有被访问的话,虚拟内存是不会映射到物理内存的,这样就不会占用物理内存了。
只有在访问已分配的虚拟地址空间的时候,操作系统通过查找页表,发现虚拟内存对应的页没有在物理内存中,就会触发缺页中断,然后操作系统会建立虚拟内存和物理内存之间的映射关系。
malloc(1) 会分配多大的虚拟内存?
malloc() 在分配内存的时候,并不是老老实实按用户预期申请的字节数来分配内存空间大小,而是会预分配更大的空间作为内存池。
具体会预分配多大的空间,跟 malloc 使用的内存管理器有关系,我们就以 malloc 默认的内存管理器(Ptmalloc2)来分析。
接下里,我们做个实验,用下面这个代码,通过 malloc 申请 1 字节的内存时,看看操作系统实际分配了多大的内存空间。
|
|
执行代码(先提前说明,我使用的 glibc 库的版本是 2.17):
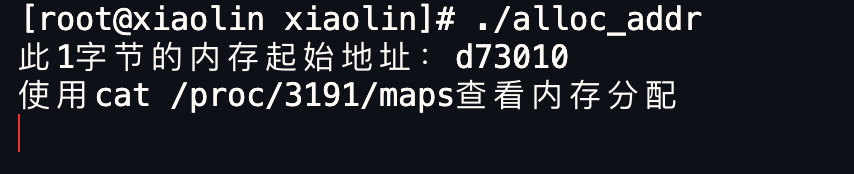
我们可以通过 /proc//maps 文件查看进程的内存分布情况。我在 maps 文件通过此 1 字节的内存起始地址过滤出了内存地址的范围。
|
|
这个例子分配的内存小于 128 KB,所以是通过 brk() 系统调用向堆空间申请的内存,因此可以看到最右边有 [heap] 的标识。
可以看到,堆空间的内存地址范围是 00d73000-00d94000,这个范围大小是 132KB,也就说明了 malloc(1) 实际上预分配 132K 字节的内存。
可能有的同学注意到了,程序里打印的内存起始地址是 d73010,而 maps 文件显示堆内存空间的起始地址是 d73000,为什么会多出来 0x10 (16字节)呢?这个问题,我们先放着,后面会说。
free 释放内存,会归还给操作系统吗?
我们在上面的进程往下执行,看看通过 free() 函数释放内存后,堆内存还在吗?
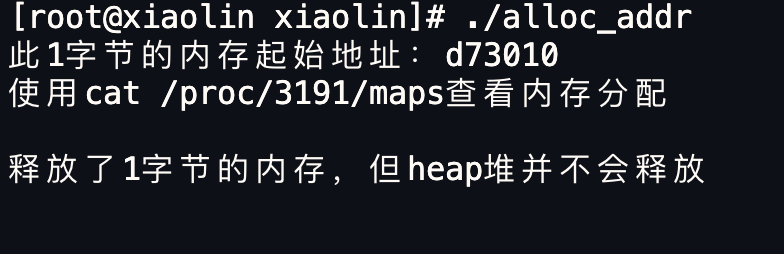
从下图可以看到,通过 free 释放内存后,堆内存还是存在的,并没有归还给操作系统。

这是因为与其把这 1 字节释放给操作系统,不如先缓存着放进 malloc 的内存池里,当进程再次申请 1 字节的内存时就可以直接复用,这样速度快了很多。
当然,当进程退出后,操作系统就会回收进程的所有资源。
上面说的 free 内存后堆内存还存在,是针对 malloc 通过 brk() 方式申请的内存的情况。
如果 malloc 通过 mmap 方式申请的内存,free 释放内存后就会归归还给操作系统。
我们做个实验验证下, 通过 malloc 申请 128 KB 字节的内存,来使得 malloc 通过 mmap 方式来分配内存。
|
|
执行代码:

查看进程的内存的分布情况,可以发现最右边没有 [heap] 标志,说明是通过 mmap 以匿名映射的方式从文件映射区分配的匿名内存。

然后我们释放掉这个内存看看:
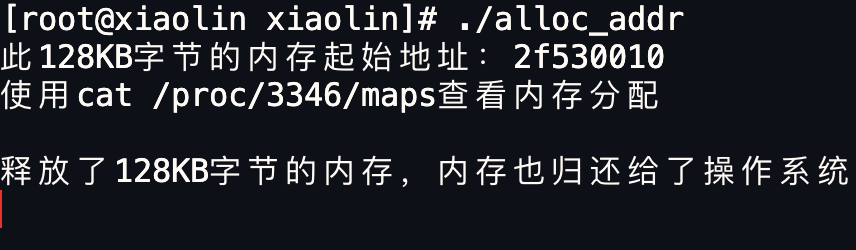
再次查看该 128 KB 内存的起始地址,可以发现已经不存在了,说明归还给了操作系统。

对于 「malloc 申请的内存,free 释放内存会归还给操作系统吗?」这个问题,我们可以做个总结了:
- malloc 通过 brk() 方式申请的内存,free 释放内存的时候,并不会把内存归还给操作系统,而是缓存在 malloc 的内存池中,待下次使用;
- malloc 通过 mmap() 方式申请的内存,free 释放内存的时候,会把内存归还给操作系统,内存得到真正的释放。
为什么不全部使用 mmap 来分配内存?
因为向操作系统申请内存,是要通过系统调用的,执行系统调用是要进入内核态的,然后在回到用户态,运行态的切换会耗费不少时间。
所以,申请内存的操作应该避免频繁的系统调用,如果都用 mmap 来分配内存,等于每次都要执行系统调用。
另外,因为 mmap 分配的内存每次释放的时候,都会归还给操作系统,于是每次 mmap 分配的虚拟地址都是缺页状态的,然后在第一次访问该虚拟地址的时候,就会触发缺页中断。
也就是说,频繁通过 mmap 分配的内存话,不仅每次都会发生运行态的切换,还会发生缺页中断(在第一次访问虚拟地址后),这样会导致 CPU 消耗较大。
为了改进这两个问题,malloc 通过 brk() 系统调用在堆空间申请内存的时候,由于堆空间是连续的,所以直接预分配更大的内存来作为内存池,当内存释放的时候,就缓存在内存池中。
等下次在申请内存的时候,就直接从内存池取出对应的内存块就行了,而且可能这个内存块的虚拟地址与物理地址的映射关系还存在,这样不仅减少了系统调用的次数,也减少了缺页中断的次数,这将大大降低 CPU 的消耗。
既然 brk 那么牛逼,为什么不全部使用 brk 来分配?
前面我们提到通过 brk 从堆空间分配的内存,并不会归还给操作系统,那么我们那考虑这样一个场景。
如果我们连续申请了 10k,20k,30k 这三片内存,如果 10k 和 20k 这两片释放了,变为了空闲内存空间,如果下次申请的内存小于 30k,那么就可以重用这个空闲内存空间。
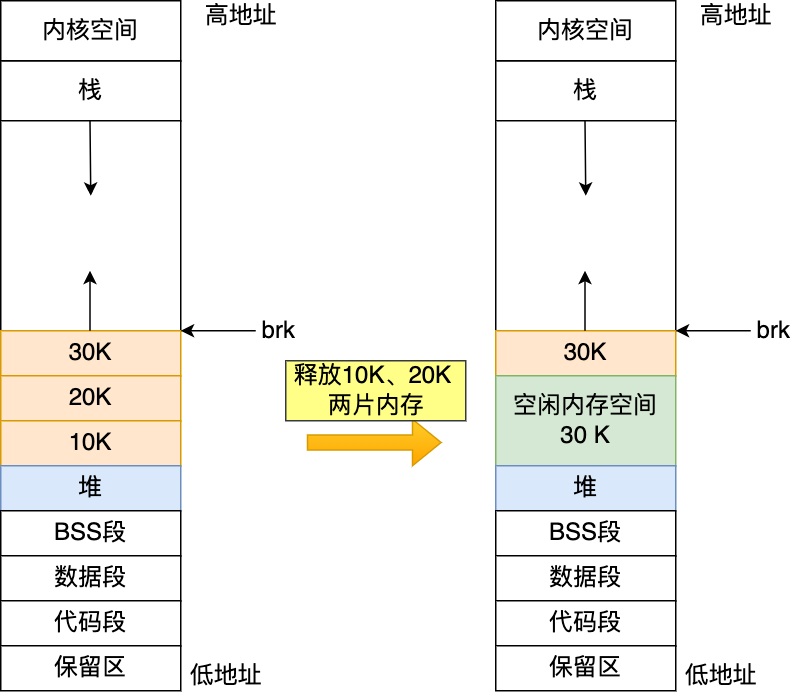
但是如果下次申请的内存大于 30k,没有可用的空闲内存空间,必须向 OS 申请,实际使用内存继续增大。
因此,随着系统频繁地 malloc 和 free ,尤其对于小块内存,堆内将产生越来越多不可用的碎片,导致“内存泄露”。而这种“泄露”现象使用 valgrind 是无法检测出来的。
所以,malloc 实现中,充分考虑了 brk 和 mmap 行为上的差异及优缺点,默认分配大块内存 (128KB) 才使用 mmap 分配内存空间。
free() 函数只传入一个内存地址,为什么能知道要释放多大的内存?
还记得,我前面提到, malloc 返回给用户态的内存起始地址比进程的堆空间起始地址多了 16 字节吗?
这个多出来的 16 字节就是保存了该内存块的描述信息,比如有该内存块的大小。
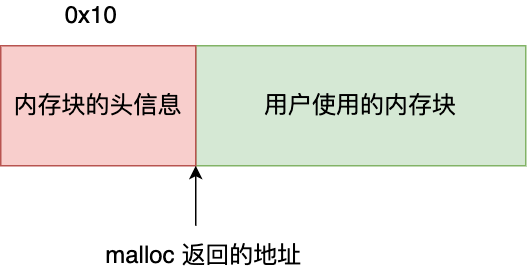
这样当执行 free() 函数时,free 会对传入进来的内存地址向左偏移 16 字节,然后从这个 16 字节的分析出当前的内存块的大小,自然就知道要释放多大的内存了。
内存满了,会发生什么?
前几天有位读者留言说,面腾讯时,被问了两个内存管理的问题:


先来说说第一个问题:虚拟内存有什么作用?
- 第一,虚拟内存可以使得进程对运行内存超过物理内存大小,因为程序运行符合局部性原理,CPU 访问内存会有很明显的重复访问的倾向性,对于那些没有被经常使用到的内存,我们可以把它换出到物理内存之外,比如硬盘上的 swap 区域。
- 第二,由于每个进程都有自己的页表,所以每个进程的虚拟内存空间就是相互独立的。进程也没有办法访问其他进程的页表,所以这些页表是私有的,这就解决了多进程之间地址冲突的问题。
- 第三,页表里的页表项中除了物理地址之外,还有一些标记属性的比特,比如控制一个页的读写权限,标记该页是否存在等。在内存访问方面,操作系统提供了更好的安全性。
然后今天主要是聊聊第二个问题,「系统内存紧张时,会发生什么?」
发车!
内存分配的过程是怎样的?
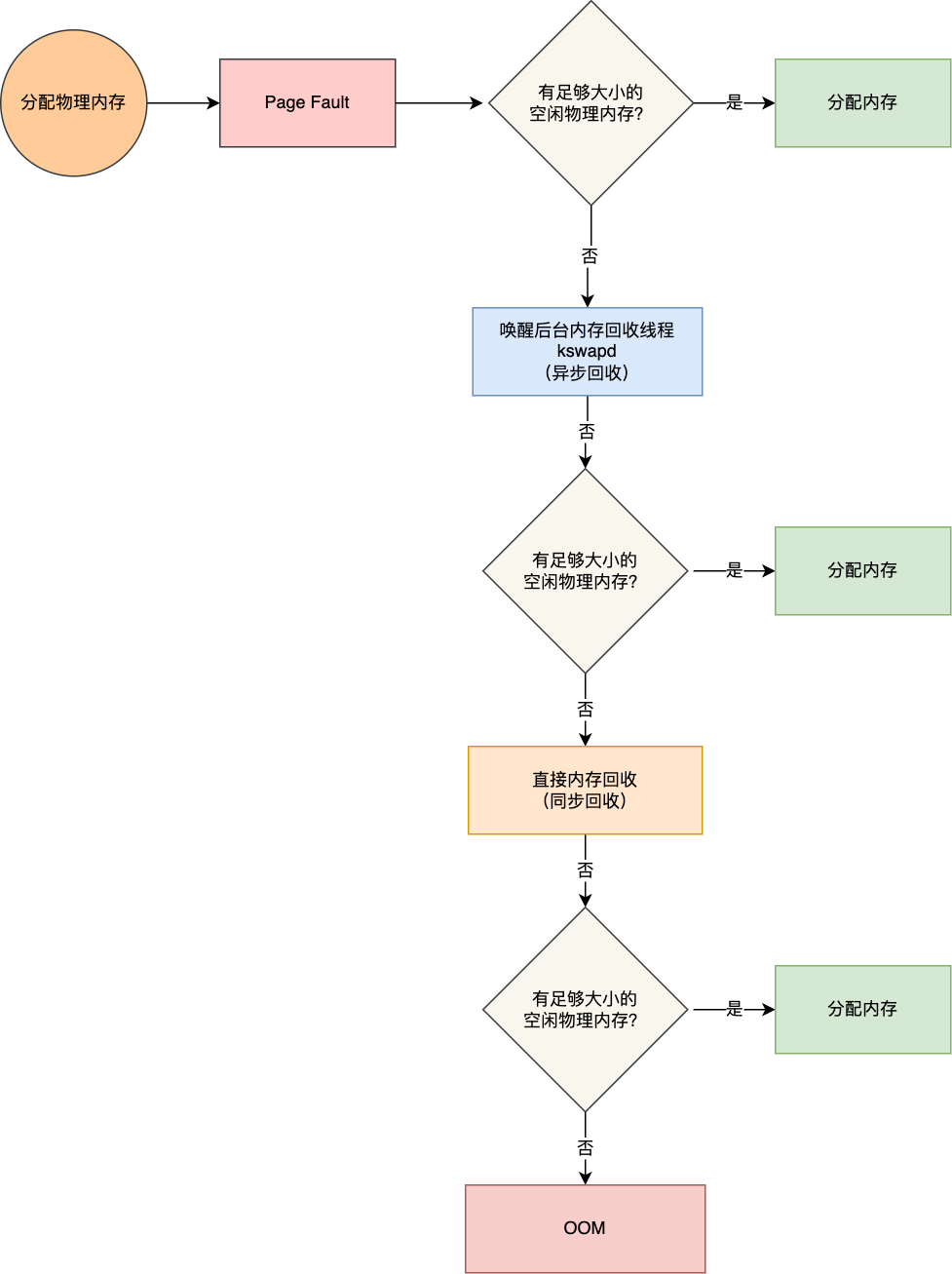
应用程序通过 malloc 函数申请内存的时候,实际上申请的是虚拟内存,此时并不会分配物理内存。
当应用程序读写了这块虚拟内存,CPU 就会去访问这个虚拟内存, 这时会发现这个虚拟内存没有映射到物理内存, CPU 就会产生缺页中断,进程会从用户态切换到内核态,并将缺页中断交给内核的 Page Fault Handler (缺页中断函数)处理。
缺页中断处理函数会看是否有空闲的物理内存,如果有,就直接分配物理内存,并建立虚拟内存与物理内存之间的映射关系。
如果没有空闲的物理内存,那么内核就会开始进行回收内存的工作,回收的方式主要是两种:直接内存回收和后台内存回收。
- 后台内存回收(kswapd):在物理内存紧张的时候,会唤醒 kswapd 内核线程来回收内存,这个回收内存的过程异步的,不会阻塞进程的执行。
- 直接内存回收(direct reclaim):如果后台异步回收跟不上进程内存申请的速度,就会开始直接回收,这个回收内存的过程是同步的,会阻塞进程的执行。
如果直接内存回收后,空闲的物理内存仍然无法满足此次物理内存的申请,那么内核就会放最后的大招了 ——触发 OOM (Out of Memory)机制。
OOM Killer 机制会根据算法选择一个占用物理内存较高的进程,然后将其杀死,以便释放内存资源,如果物理内存依然不足,OOM Killer 会继续杀死占用物理内存较高的进程,直到释放足够的内存位置。
申请物理内存的过程如下图:
哪些内存可以被回收?
系统内存紧张的时候,就会进行回收内存的工作,那具体哪些内存是可以被回收的呢?
主要有两类内存可以被回收,而且它们的回收方式也不同。
- 文件页(File-backed Page):内核缓存的磁盘数据(Buffer)和内核缓存的文件数据(Cache)都叫作文件页。大部分文件页,都可以直接释放内存,以后有需要时,再从磁盘重新读取就可以了。而那些被应用程序修改过,并且暂时还没写入磁盘的数据(也就是脏页),就得先写入磁盘,然后才能进行内存释放。所以,回收干净页的方式是直接释放内存,回收脏页的方式是先写回磁盘后再释放内存。
- 匿名页(Anonymous Page):这部分内存没有实际载体,不像文件缓存有硬盘文件这样一个载体,比如堆、栈数据等。这部分内存很可能还要再次被访问,所以不能直接释放内存,它们回收的方式是通过 Linux 的 Swap 机制,Swap 会把不常访问的内存先写到磁盘中,然后释放这些内存,给其他更需要的进程使用。再次访问这些内存时,重新从磁盘读入内存就可以了。
文件页和匿名页的回收都是基于 LRU 算法,也就是优先回收不常访问的内存。LRU 回收算法,实际上维护着 active 和 inactive 两个双向链表,其中:
- active_list 活跃内存页链表,这里存放的是最近被访问过(活跃)的内存页;
- inactive_list 不活跃内存页链表,这里存放的是很少被访问(非活跃)的内存页;
越接近链表尾部,就表示内存页越不常访问。这样,在回收内存时,系统就可以根据活跃程度,优先回收不活跃的内存。
活跃和非活跃的内存页,按照类型的不同,又分别分为文件页和匿名页。可以从 /proc/meminfo 中,查询它们的大小,比如:
|
|
回收内存带来的性能影响
在前面我们知道了回收内存有两种方式。
- 一种是后台内存回收,也就是唤醒 kswapd 内核线程,这种方式是异步回收的,不会阻塞进程。
- 一种是直接内存回收,这种方式是同步回收的,会阻塞进程,这样就会造成很长时间的延迟,以及系统的 CPU 利用率会升高,最终引起系统负荷飙高。
可被回收的内存类型有文件页和匿名页:
- 文件页的回收:对于干净页是直接释放内存,这个操作不会影响性能,而对于脏页会先写回到磁盘再释放内存,这个操作会发生磁盘 I/O 的,这个操作是会影响系统性能的。
- 匿名页的回收:如果开启了 Swap 机制,那么 Swap 机制会将不常访问的匿名页换出到磁盘中,下次访问时,再从磁盘换入到内存中,这个操作是会影响系统性能的。
可以看到,回收内存的操作基本都会发生磁盘 I/O 的,如果回收内存的操作很频繁,意味着磁盘 I/O 次数会很多,这个过程势必会影响系统的性能,整个系统给人的感觉就是很卡。
下面针对回收内存导致的性能影响,说说常见的解决方式。
调整文件页和匿名页的回收倾向
从文件页和匿名页的回收操作来看,文件页的回收操作对系统的影响相比匿名页的回收操作会少一点,因为文件页对于干净页回收是不会发生磁盘 I/O 的,而匿名页的 Swap 换入换出这两个操作都会发生磁盘 I/O。
Linux 提供了一个 /proc/sys/vm/swappiness 选项,用来调整文件页和匿名页的回收倾向。
swappiness 的范围是 0-100,数值越大,越积极使用 Swap,也就是更倾向于回收匿名页;数值越小,越消极使用 Swap,也就是更倾向于回收文件页。
|
|
一般建议 swappiness 设置为 0(默认值是 60),这样在回收内存的时候,会更倾向于文件页的回收,但是并不代表不会回收匿名页。
尽早触发 kswapd 内核线程异步回收内存
如何查看系统的直接内存回收和后台内存回收的指标?
我们可以使用 sar -B 1 命令来观察:

图中红色框住的就是后台内存回收和直接内存回收的指标,它们分别表示:
- pgscank/s : kswapd(后台回收线程) 每秒扫描的 page 个数。
- pgscand/s: 应用程序在内存申请过程中每秒直接扫描的 page 个数。
- pgsteal/s: 扫描的 page 中每秒被回收的个数(pgscank+pgscand)。
如果系统时不时发生抖动,并且在抖动的时间段里如果通过 sar -B 观察到 pgscand 数值很大,那大概率是因为「直接内存回收」导致的。
针对这个问题,解决的办法就是,可以通过尽早的触发「后台内存回收」来避免应用程序进行直接内存回收。
什么条件下才能触发 kswapd 内核线程回收内存呢?
内核定义了三个内存阈值(watermark,也称为水位),用来衡量当前剩余内存(pages_free)是否充裕或者紧张,分别是:
- 页最小阈值(pages_min);
- 页低阈值(pages_low);
- 页高阈值(pages_high);
这三个内存阈值会划分为四种内存使用情况,如下图:
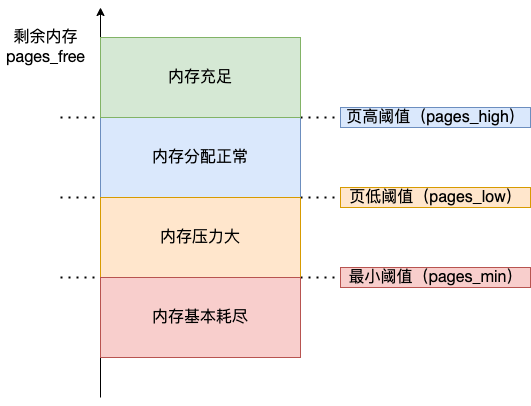
kswapd 会定期扫描内存的使用情况,根据剩余内存(pages_free)的情况来进行内存回收的工作。
- 图中绿色部分:如果剩余内存(pages_free)大于 页高阈值(pages_high),说明剩余内存是充足的;
- 图中蓝色部分:如果剩余内存(pages_free)在页高阈值(pages_high)和页低阈值(pages_low)之间,说明内存有一定压力,但还可以满足应用程序申请内存的请求;
- 图中橙色部分:如果剩余内存(pages_free)在页低阈值(pages_low)和页最小阈值(pages_min)之间,说明内存压力比较大,剩余内存不多了。这时 kswapd0 会执行内存回收,直到剩余内存大于高阈值(pages_high)为止。虽然会触发内存回收,但是不会阻塞应用程序,因为两者关系是异步的。
- 图中红色部分:如果剩余内存(pages_free)小于页最小阈值(pages_min),说明用户可用内存都耗尽了,此时就会触发直接内存回收,这时应用程序就会被阻塞,因为两者关系是同步的。
可以看到,当剩余内存页(pages_free)小于页低阈值(pages_low),就会触发 kswapd 进行后台回收,然后 kswapd 会一直回收到剩余内存页(pages_free)大于页高阈值(pages_high)。
也就是说 kswapd 的活动空间只有 pages_low 与 pages_min 之间的这段区域,如果剩余内存低于了 pages_min 会触发直接内存回收,高于了 pages_high 又不会唤醒 kswapd。
页低阈值(pages_low)可以通过内核选项 /proc/sys/vm/min_free_kbytes (该参数代表系统所保留空闲内存的最低限)来间接设置。
min_free_kbytes 虽然设置的是页最小阈值(pages_min),但是页高阈值(pages_high)和页低阈值(pages_low)都是根据页最小阈值(pages_min)计算生成的,它们之间的计算关系如下:
|
|
如果系统时不时发生抖动,并且通过 sar -B 观察到 pgscand 数值很大,那大概率是因为直接内存回收导致的,这时可以增大 min_free_kbytes 这个配置选项来及早地触发后台回收,然后继续观察 pgscand 是否会降为 0。
增大了 min_free_kbytes 配置后,这会使得系统预留过多的空闲内存,从而在一定程度上降低了应用程序可使用的内存量,这在一定程度上浪费了内存。极端情况下设置 min_free_kbytes 接近实际物理内存大小时,留给应用程序的内存就会太少而可能会频繁地导致 OOM 的发生。
所以在调整 min_free_kbytes 之前,需要先思考一下,应用程序更加关注什么,如果关注延迟那就适当地增大 min_free_kbytes,如果关注内存的使用量那就适当地调小 min_free_kbytes。
NUMA 架构下的内存回收策略
什么是 NUMA 架构?
再说 NUMA 架构前,先给大家说说 SMP 架构,这两个架构都是针对 CPU 的。
SMP 指的是一种多个 CPU 处理器共享资源的电脑硬件架构,也就是说每个 CPU 地位平等,它们共享相同的物理资源,包括总线、内存、IO、操作系统等。每个 CPU 访问内存所用时间都是相同的,因此,这种系统也被称为一致存储访问结构(UMA,Uniform Memory Access)。
随着 CPU 处理器核数的增多,多个 CPU 都通过一个总线访问内存,这样总线的带宽压力会越来越大,同时每个 CPU 可用带宽会减少,这也就是 SMP 架构的问题。
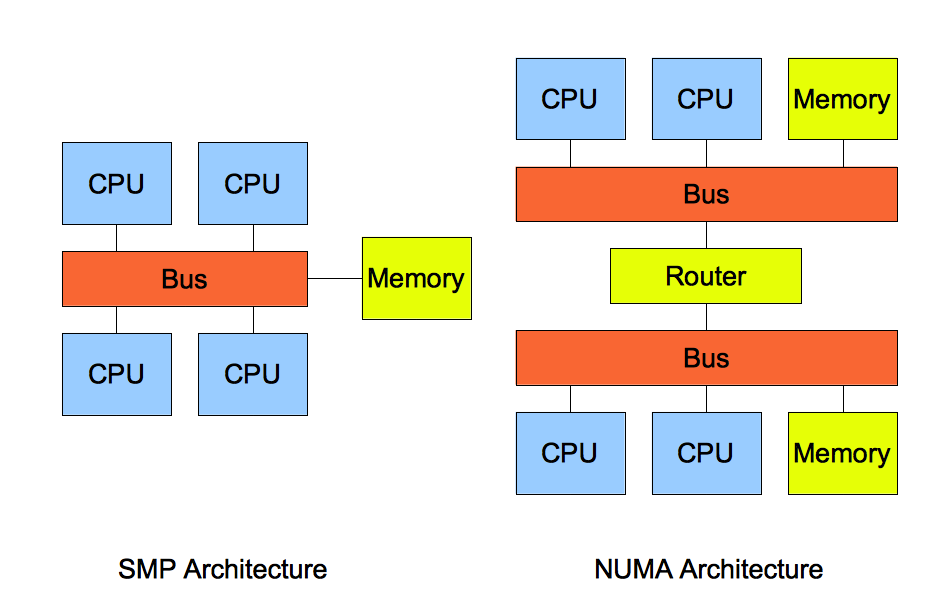
为了解决 SMP 架构的问题,就研制出了 NUMA 结构,即非一致存储访问结构(Non-uniform memory access,NUMA)。
NUMA 架构将每个 CPU 进行了分组,每一组 CPU 用 Node 来表示,一个 Node 可能包含多个 CPU 。
每个 Node 有自己独立的资源,包括内存、IO 等,每个 Node 之间可以通过互联模块总线(QPI)进行通信,所以,也就意味着每个 Node 上的 CPU 都可以访问到整个系统中的所有内存。但是,访问远端 Node 的内存比访问本地内存要耗时很多。
NUMA 架构跟回收内存有什么关系?
在 NUMA 架构下,当某个 Node 内存不足时,系统可以从其他 Node 寻找空闲内存,也可以从本地内存中回收内存。
具体选哪种模式,可以通过 /proc/sys/vm/zone_reclaim_mode 来控制。它支持以下几个选项:
- 0 (默认值):在回收本地内存之前,在其他 Node 寻找空闲内存;
- 1:只回收本地内存;
- 2:只回收本地内存,在本地回收内存时,可以将文件页中的脏页写回硬盘,以回收内存。
- 4:只回收本地内存,在本地回收内存时,可以用 swap 方式回收内存。
在使用 NUMA 架构的服务器,如果系统出现还有一半内存的时候,却发现系统频繁触发「直接内存回收」,导致了影响了系统性能,那么大概率是因为 zone_reclaim_mode 没有设置为 0 ,导致当本地内存不足的时候,只选择回收本地内存的方式,而不去使用其他 Node 的空闲内存。
虽然说访问远端 Node 的内存比访问本地内存要耗时很多,但是相比内存回收的危害而言,访问远端 Node 的内存带来的性能影响还是比较小的。因此,zone_reclaim_mode 一般建议设置为 0。
如何保护一个进程不被 OOM 杀掉呢?
在系统空闲内存不足的情况,进程申请了一个很大的内存,如果直接内存回收都无法回收出足够大的空闲内存,那么就会触发 OOM 机制,内核就会根据算法选择一个进程杀掉。
Linux 到底是根据什么标准来选择被杀的进程呢?这就要提到一个在 Linux 内核里有一个 oom_badness() 函数,它会把系统中可以被杀掉的进程扫描一遍,并对每个进程打分,得分最高的进程就会被首先杀掉。
进程得分的结果受下面这两个方面影响:
- 第一,进程已经使用的物理内存页面数。
- 第二,每个进程的 OOM 校准值 oom_score_adj。它是可以通过
/proc/[pid]/oom_score_adj来配置的。我们可以在设置 -1000 到 1000 之间的任意一个数值,调整进程被 OOM Kill 的几率。
函数 oom_badness() 里的最终计算方法是这样的:
|
|
用「系统总的可用页面数」乘以 「OOM 校准值 oom_score_adj」再除以 1000,最后再加上进程已经使用的物理页面数,计算出来的值越大,那么这个进程被 OOM Kill 的几率也就越大。
每个进程的 oom_score_adj 默认值都为 0,所以最终得分跟进程自身消耗的内存有关,消耗的内存越大越容易被杀掉。我们可以通过调整 oom_score_adj 的数值,来改成进程的得分结果:
- 如果你不想某个进程被首先杀掉,那你可以调整该进程的 oom_score_adj,从而改变这个进程的得分结果,降低该进程被 OOM 杀死的概率。
- 如果你想某个进程无论如何都不能被杀掉,那你可以将 oom_score_adj 配置为 -1000。
我们最好将一些很重要的系统服务的 oom_score_adj 配置为 -1000,比如 sshd,因为这些系统服务一旦被杀掉,我们就很难再登陆进系统了。
但是,不建议将我们自己的业务程序的 oom_score_adj 设置为 -1000,因为业务程序一旦发生了内存泄漏,而它又不能被杀掉,这就会导致随着它的内存开销变大,OOM killer 不停地被唤醒,从而把其他进程一个个给杀掉。
参考资料:
- https://time.geekbang.org/column/article/277358
- https://time.geekbang.org/column/article/75797
- https://www.jianshu.com/p/e40e8813842f
总结
内核在给应用程序分配物理内存的时候,如果空闲物理内存不够,那么就会进行内存回收的工作,主要有两种方式:
- 后台内存回收:在物理内存紧张的时候,会唤醒 kswapd 内核线程来回收内存,这个回收内存的过程异步的,不会阻塞进程的执行。
- 直接内存回收:如果后台异步回收跟不上进程内存申请的速度,就会开始直接回收,这个回收内存的过程是同步的,会阻塞进程的执行。
可被回收的内存类型有文件页和匿名页:
- 文件页的回收:对于干净页是直接释放内存,这个操作不会影响性能,而对于脏页会先写回到磁盘再释放内存,这个操作会发生磁盘 I/O 的,这个操作是会影响系统性能的。
- 匿名页的回收:如果开启了 Swap 机制,那么 Swap 机制会将不常访问的匿名页换出到磁盘中,下次访问时,再从磁盘换入到内存中,这个操作是会影响系统性能的。
文件页和匿名页的回收都是基于 LRU 算法,也就是优先回收不常访问的内存。回收内存的操作基本都会发生磁盘 I/O 的,如果回收内存的操作很频繁,意味着磁盘 I/O 次数会很多,这个过程势必会影响系统的性能。
针对回收内存导致的性能影响,常见的解决方式。
- 设置 /proc/sys/vm/swappiness,调整文件页和匿名页的回收倾向,尽量倾向于回收文件页;
- 设置 /proc/sys/vm/min_free_kbytes,调整 kswapd 内核线程异步回收内存的时机;
- 设置 /proc/sys/vm/zone_reclaim_mode,调整 NUMA 架构下内存回收策略,建议设置为 0,这样在回收本地内存之前,会在其他 Node 寻找空闲内存,从而避免在系统还有很多空闲内存的情况下,因本地 Node 的本地内存不足,发生频繁直接内存回收导致性能下降的问题;
在经历完直接内存回收后,空闲的物理内存大小依然不够,那么就会触发 OOM 机制,OOM killer 就会根据每个进程的内存占用情况和 oom_score_adj 的值进行打分,得分最高的进程就会被首先杀掉。
我们可以通过调整进程的 /proc/[pid]/oom_score_adj 值,来降低被 OOM killer 杀掉的概率。
在4GB物理内存的机器上,申情8G内存会怎么样?
看到读者在群里讨论这些面试题:
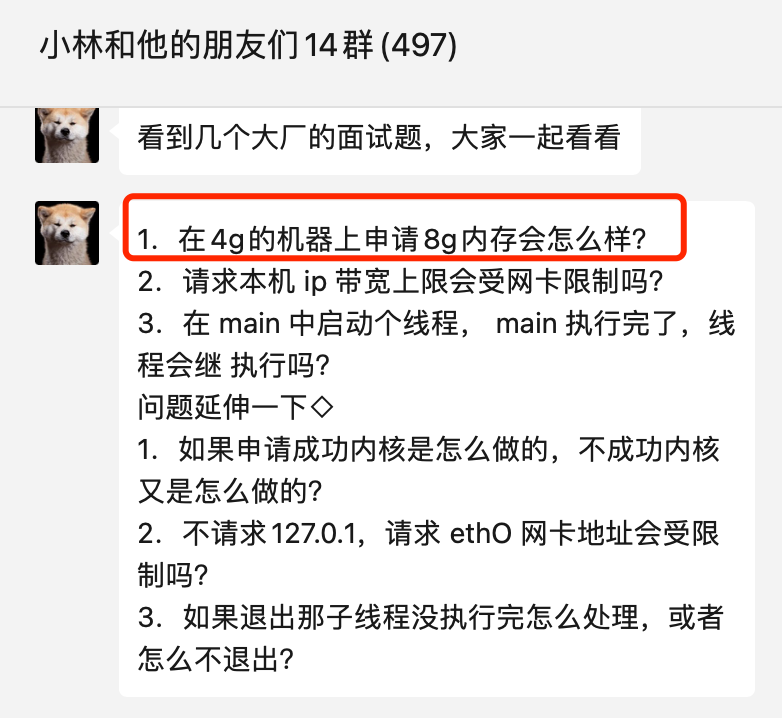
其中,第一个问题「在 4GB 物理内存的机器上,申请 8G 内存会怎么样?」存在比较大的争议,有人说会申请失败,有的人说可以申请成功。
这个问题在没有前置条件下,就说出答案就是耍流氓。这个问题要考虑三个前置条件:
- 操作系统是 32 位的,还是 64 位的?
- 申请完 8G 内存后会不会被使用?
- 操作系统有没有使用 Swap 机制?
所以,我们要分场景讨论。
操作系统虚拟内存大小
应用程序通过 malloc 函数申请内存的时候,实际上申请的是虚拟内存,此时并不会分配物理内存。
当应用程序读写了这块虚拟内存,CPU 就会去访问这个虚拟内存, 这时会发现这个虚拟内存没有映射到物理内存, CPU 就会产生缺页中断,进程会从用户态切换到内核态,并将缺页中断交给内核的 Page Fault Handler (缺页中断函数)处理。
缺页中断处理函数会看是否有空闲的物理内存:
- 如果有,就直接分配物理内存,并建立虚拟内存与物理内存之间的映射关系。
- 如果没有空闲的物理内存,那么内核就会开始进行回收内存 (opens new window)的工作,如果回收内存工作结束后,空闲的物理内存仍然无法满足此次物理内存的申请,那么内核就会放最后的大招了触发 OOM (Out of Memory)机制。
32 位操作系统和 64 位操作系统的虚拟地址空间大小是不同的,在 Linux 操作系统中,虚拟地址空间的内部又被分为内核空间和用户空间两部分,如下所示:
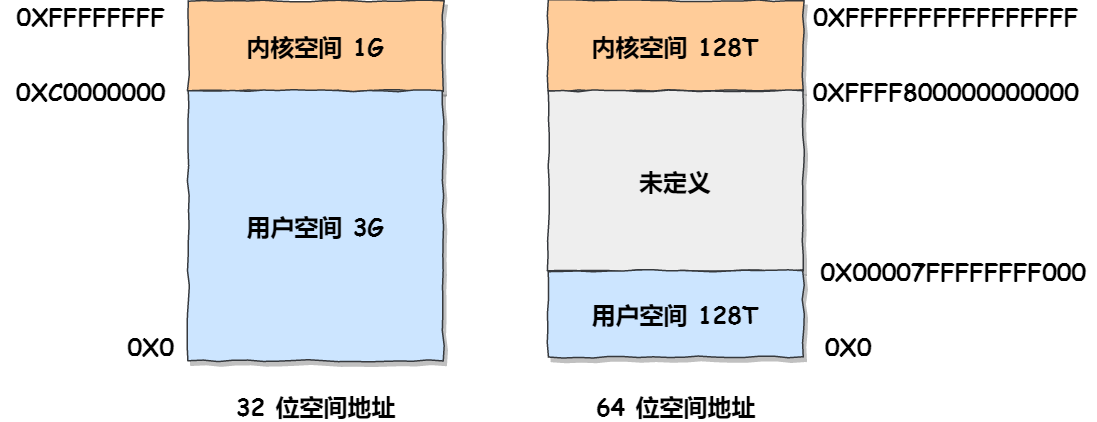
通过这里可以看出:
32位系统的内核空间占用1G,位于最高处,剩下的3G是用户空间;64位系统的内核空间和用户空间都是128T,分别占据整个内存空间的最高和最低处,剩下的中间部分是未定义的。
32 位系统的场景
现在可以回答这个问题了:在 32 位操作系统、4GB 物理内存的机器上,申请 8GB 内存,会怎么样?
因为 32 位操作系统,进程最多只能申请 3 GB 大小的虚拟内存空间,所以进程申请 8GB 内存的话,在申请虚拟内存阶段就会失败(我手上没有 32 位操作系统测试,我估计失败的错误是 cannot allocate memory,也就是无法申请内存失败)。
64 位系统的场景
在 64 位操作系统、4GB 物理内存的机器上,申请 8G 内存,会怎么样?
64 位操作系统,进程可以使用 128 TB 大小的虚拟内存空间,所以进程申请 8GB 内存是没问题的,因为进程申请内存是申请虚拟内存,只要不读写这个虚拟内存,操作系统就不会分配物理内存。
我们可以简单做个测试,我的服务器是 64 位操作系统,但是物理内存只有 2 GB:

现在,我在机器上,连续申请 4 次 1 GB 内存,也就是一共申请了 4 GB 内存,注意下面代码只是单纯分配了虚拟内存,并没有使用该虚拟内存:
|
|
然后运行这个代码,可以看到,我的物理内存虽然只有 2GB,但是程序正常分配了 4GB 大小的虚拟内存:

我们可以通过下面这条命令查看进程(test)的虚拟内存大小:
|
|
其中,VSZ 就代表进程使用的虚拟内存大小,RSS 代表进程使用的物理内存大小。可以看到,VSZ 大小为 4198540,也就是 4GB 的虚拟内存。
之前有读者跟我反馈,说他自己也做了这个实验,然后发现 64 位操作系统,在申请 4GB 虚拟内存的时候失败了,这是为什么呢?
失败的错误:

我当时帮他排查了下,发现跟 Linux 中的 overcommit_memory (opens new window)参数有关,可以使用 cat /proc/sys/vm/overcommit_memory 来查看这个参数,这个参数接受三个值:
- 如果值为 0(默认值),代表:Heuristic overcommit handling,它允许overcommit,但过于明目张胆的overcommit会被拒绝,比如malloc一次性申请的内存大小就超过了系统总内存。Heuristic的意思是“试探式的”,内核利用某种算法猜测你的内存申请是否合理,大概可以理解为单次申请不能超过free memory + free swap + pagecache的大小 + SLAB中可回收的部分 ,超过了就会拒绝overcommit。
- 如果值为 1,代表:Always overcommit. 允许overcommit,对内存申请来者不拒。
- 如果值为 2,代表:Don’t overcommit. 禁止overcommit。
当时那位读者的 overcommit_memory 参数是默认值 0 ,所以申请失败的原因可能是内核认为我们申请的内存太大了,它认为不合理,所以 malloc() 返回了 Cannot allocate memory 错误,这里申请 4GB 虚拟内存失败的同学可以将这个 overcommit_memory 设置为1,就可以 overcommit 了。
|
|
设置完为 1 后,读者的机子就可以正常申请 4GB 虚拟内存了。

不过我的环境 overcommit_memory 是 0,在 64 系统、2 G 物理内存场景下,也是可以成功申请 4 G 内存的,我怀疑可能是不同版本的内核在 overcommit_memory 为 0 时,检测内存申请是否合理的算法可能是不同的。
总之,如果你申请大内存的时候,不想被内核检测内存申请是否合理的算法干扰的话,将 overcommit_memory 设置为 1 就行。
那么将这个 overcommit_memory 设置为 1 之后,64 位的主机就可以申请接近 128T 虚拟内存了吗?
不一定,还得看你服务器的物理内存大小。
读者的服务器物理内存是 2 GB,实验后发现,进程还没有申请到 128T 虚拟内存的时候就被杀死了。
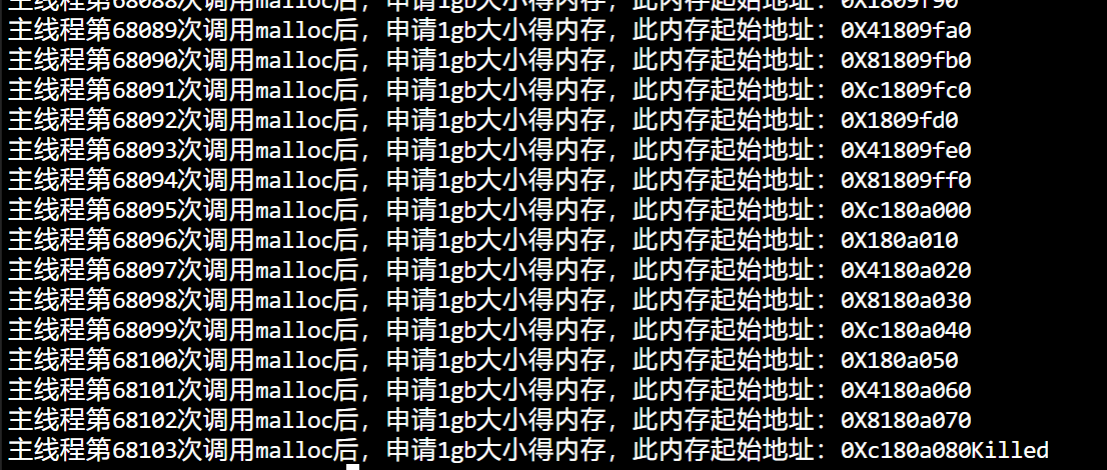
注意,这次是 killed,而不是 Cannot Allocate Memory,说明并不是内存申请有问题,而是触发 OOM 了。
但是为什么会触发 OOM 呢?
那得看你的主机的「物理内存」够不够大了,即使 malloc 申请的是虚拟内存,只要不去访问就不会映射到物理内存,但是申请虚拟内存的过程中,还是使用到了物理内存(比如内核保存虚拟内存的数据结构,也是占用物理内存的),如果你的主机是只有 2GB 的物理内存的话,大概率会触发 OOM。
可以使用 top 命令,点击两下 m,通过进度条观察物理内存使用情况。

可以看到申请虚拟内存的过程中物理内存使用量一直在增长。



直到直接内存回收之后,也无法回收出一块空间供这个进程使用,这个时候就会触发 OOM,给所有能杀死的进程打分,分数越高的进程越容易被杀死。
在这里当然是这个进程得分最高,那么操作系统就会将这个进程杀死,所以最后会出现 killed,而不是Cannot allocate memory。
那么 2GB 的物理内存的 64 位操作系统,就不能申请128T的虚拟内存了吗?
其实可以,上面的情况是还没开启 swap 的情况。
使用 swapfile 的方式开启了 1GB 的 swap 空间之后再做实验:

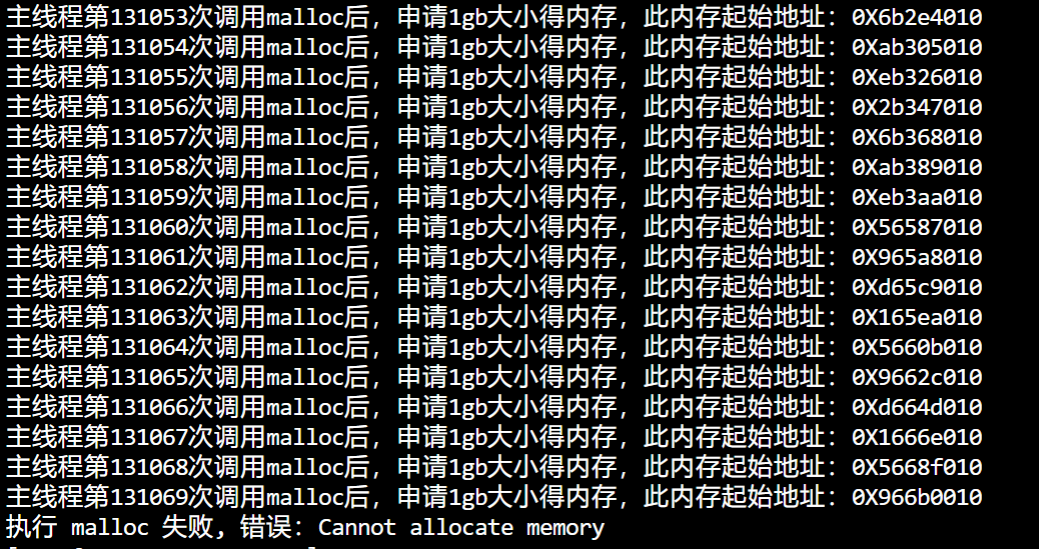
发现出现了 Cannot allocate memory,但是其实到这里已经成功了,
打开计算器计算一下,发现已经申请了 127.998T 虚拟内存了。

实际上我们是不可能申请完整个 128T 的用户空间的,因为程序运行本身也需要申请虚拟空间
申请 127T 虚拟内存试试:
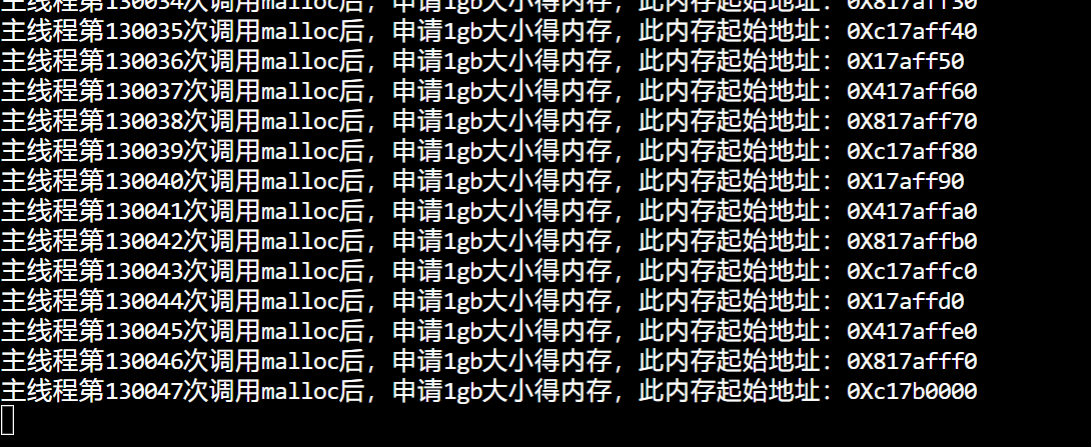
发现进程没有被杀死,也没有 Cannot allocate memory,也正好是 127T 虚拟内存空间。
在 top 中我们可以看到这个申请了127T虚拟内存的进程。

Swap 机制的作用
前面讨论在 32 位/64 位操作系统环境下,申请的虚拟内存超过物理内存后会怎么样?
- 在 32 位操作系统,因为进程最大只能申请 3 GB 大小的虚拟内存,所以直接申请 8G 内存,会申请失败。
- 在 64 位操作系统,因为进程最大只能申请 128 TB 大小的虚拟内存,即使物理内存只有 4GB,申请 8G 内存也是没问题,因为申请的内存是虚拟内存。
程序申请的虚拟内存,如果没有被使用,它是不会占用物理空间的。当访问这块虚拟内存后,操作系统才会进行物理内存分配。
如果申请物理内存大小超过了空闲物理内存大小,就要看操作系统有没有开启 Swap 机制:
- 如果没有开启 Swap 机制,程序就会直接 OOM;
- 如果有开启 Swap 机制,程序可以正常运行。
什么是 Swap 机制?
当系统的物理内存不够用的时候,就需要将物理内存中的一部分空间释放出来,以供当前运行的程序使用。那些被释放的空间可能来自一些很长时间没有什么操作的程序,这些被释放的空间会被临时保存到磁盘,等到那些程序要运行时,再从磁盘中恢复保存的数据到内存中。
另外,当内存使用存在压力的时候,会开始触发内存回收行为,会把这些不常访问的内存先写到磁盘中,然后释放这些内存,给其他更需要的进程使用。再次访问这些内存时,重新从磁盘读入内存就可以了。
这种,将内存数据换出磁盘,又从磁盘中恢复数据到内存的过程,就是 Swap 机制负责的。
Swap 就是把一块磁盘空间或者本地文件,当成内存来使用,它包含换出和换入两个过程:
- 换出(Swap Out) ,是把进程暂时不用的内存数据存储到磁盘中,并释放这些数据占用的内存;
- 换入(Swap In),是在进程再次访问这些内存的时候,把它们从磁盘读到内存中来;
Swap 换入换出的过程如下图:
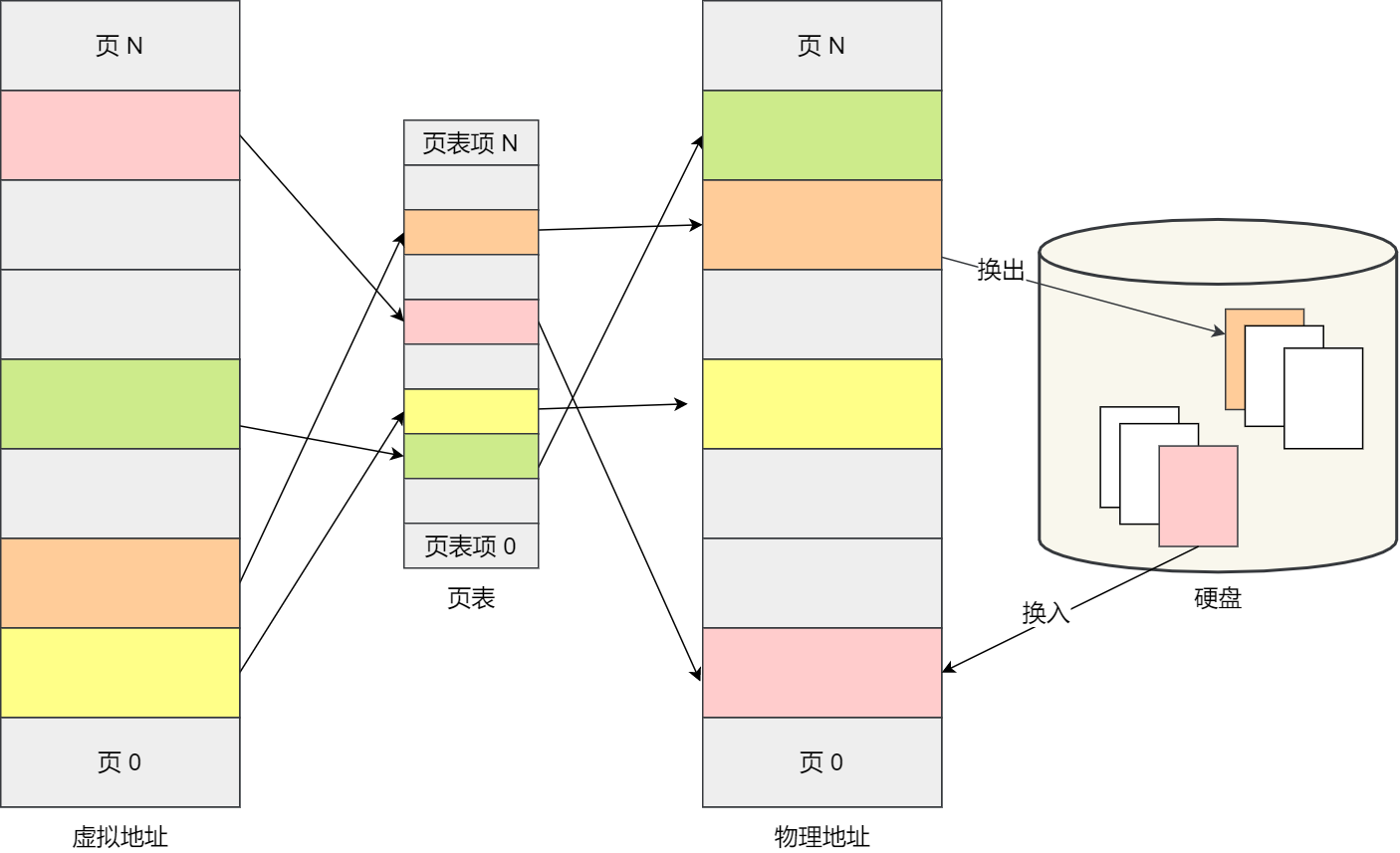
使用 Swap 机制优点是,应用程序实际可以使用的内存空间将远远超过系统的物理内存。由于硬盘空间的价格远比内存要低,因此这种方式无疑是经济实惠的。当然,频繁地读写硬盘,会显著降低操作系统的运行速率,这也是 Swap 的弊端。
Linux 中的 Swap 机制会在内存不足和内存闲置的场景下触发:
- 内存不足:当系统需要的内存超过了可用的物理内存时,内核会将内存中不常使用的内存页交换到磁盘上为当前进程让出内存,保证正在执行的进程的可用性,这个内存回收的过程是强制的直接内存回收(Direct Page Reclaim)。直接内存回收是同步的过程,会阻塞当前申请内存的进程。
- 内存闲置:应用程序在启动阶段使用的大量内存在启动后往往都不会使用,通过后台运行的守护进程(kSwapd),我们可以将这部分只使用一次的内存交换到磁盘上为其他内存的申请预留空间。kSwapd 是 Linux 负责页面置换(Page replacement)的守护进程,它也是负责交换闲置内存的主要进程,它会在空闲内存低于一定水位 (opens new window)时,回收内存页中的空闲内存保证系统中的其他进程可以尽快获得申请的内存。kSwapd 是后台进程,所以回收内存的过程是异步的,不会阻塞当前申请内存的进程。
Linux 提供了两种不同的方法启用 Swap,分别是 Swap 分区(Swap Partition)和 Swap 文件(Swapfile),开启方法可以看这个资料 (opens new window):
- Swap 分区是硬盘上的独立区域,该区域只会用于交换分区,其他的文件不能存储在该区域上,我们可以使用
swapon -s命令查看当前系统上的交换分区; - Swap 文件是文件系统中的特殊文件,它与文件系统中的其他文件也没有太多的区别;
Swap 换入换出的是什么类型的内存?
内核缓存的文件数据,因为都有对应的磁盘文件,所以在回收文件数据的时候, 直接写回到对应的文件就可以了。
但是像进程的堆、栈数据等,它们是没有实际载体,这部分内存被称为匿名页。而且这部分内存很可能还要再次被访问,所以不能直接释放内存,于是就需要有一个能保存匿名页的磁盘载体,这个载体就是 Swap 分区。
匿名页回收的方式是通过 Linux 的 Swap 机制,Swap 会把不常访问的内存先写到磁盘中,然后释放这些内存,给其他更需要的进程使用。再次访问这些内存时,重新从磁盘读入内存就可以了。
接下来,通过两个实验,看看申请的物理内存超过物理内存会怎样?
- 实验一:没有开启 Swap 机制
- 实验二:有开启 Swap 机制
实验一:没有开启 Swap 机制
我的服务器是 64 位操作系统,但是物理内存只有 2 GB,而且没有 Swap 分区:
我们改一下前面的代码,使得在申请完 4GB 虚拟内存后,通过 memset 函数访问这个虚拟内存,看看在没有 Swap 分区的情况下,会发生什么?
|
|
运行结果:
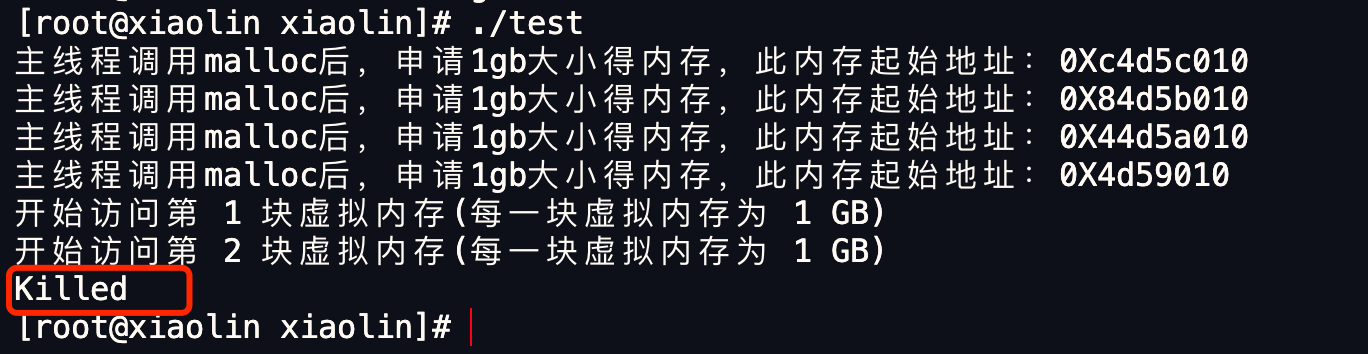
可以看到,在访问第 2 块虚拟内存(每一块虚拟内存是 1 GB)的时候,因为超过了机器的物理内存(2GB),进程(test)被操作系统杀掉了。
通过查看 message 系统日志,可以发现该进程是被操作系统 OOM killer 机制杀掉了,日志里报错了 Out of memory,也就是发生 OOM(内存溢出错误)。

什么是 OOM?
内存溢出(Out Of Memory,简称OOM)是指应用系统中存在无法回收的内存或使用的内存过多,最终使得程序运行要用到的内存大于能提供的最大内存。此时程序就运行不了,系统会提示内存溢出。
实验二:有开启 Swap 机制
我用我的 mac book pro 笔记本做测试,我的笔记本是 64 位操作系统,物理内存是 8 GB, 目前 Swap 分区大小为 1 GB(注意这个大小不是固定不变的,Swap 分区总大小是会动态变化的,当没有使用 Swap 分区时,Swap 分区总大小是 0;当使用了 Swap 分区,Swap 分区总大小会增加至 1 GB;当 Swap 分区已使用的大小超过 1 GB 时;Swap 分区总大小就会增加到至 2 GB;当 Swap 分区已使用的大小超过 2 GB 时;Swap 分区总大小就增加至 3GB,如此往复。这个估计是 macos 自己实现的,Linux 的分区则是固定大小的,Swap 分区不会根据使用情况而自动增长)。
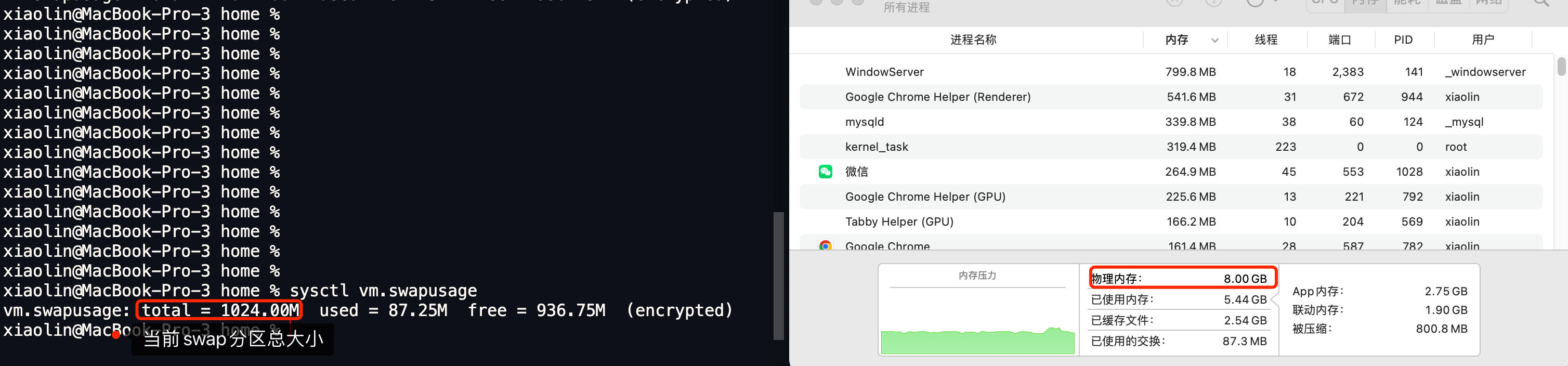
为了方便观察磁盘 I/O 情况,我们改进一下前面的代码,分配完 32 GB虚拟内存后(笔记本物理内存是 8 GB),通过一个 while 循环频繁访问虚拟内存,代码如下:
|
|
运行结果如下:
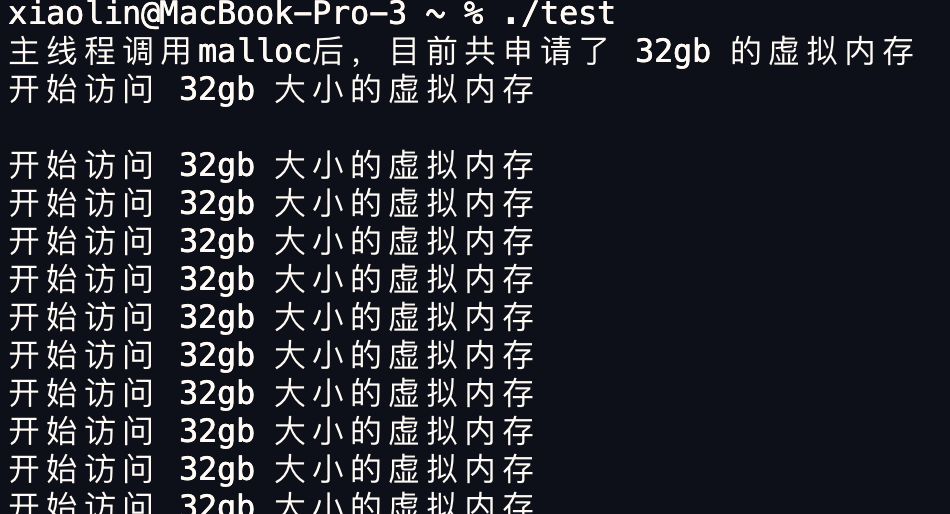
可以看到,在有 Swap 分区的情况下,即使笔记本物理内存是 8 GB,申请并使用 32 GB 内存是没问题,程序正常运行了,并没有发生 OOM。
从下图可以看到,进程的内存显示 32 GB(这个不要理解为占用的物理内存,理解为已被访问的虚拟内存大小,也就是在物理内存呆过的内存大小),系统已使用的 Swap 分区达到 2.3 GB。
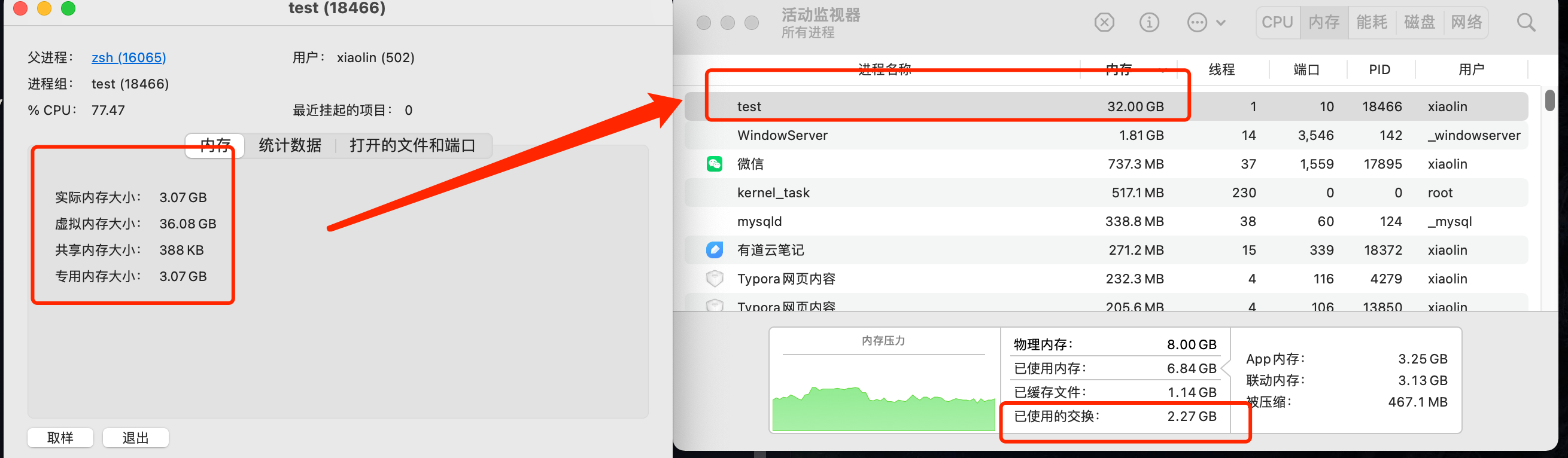
此时我的笔记本电脑的磁盘开始出现“沙沙”的声音,通过查看磁盘的 I/O 情况,可以看到磁盘 I/O 达到了一个峰值,非常高:
有了 Swap 分区,是不是意味着进程可以使用的内存是无上限的?
当然不是,我把上面的代码改成了申请 64GB 内存后,当进程申请完 64GB 虚拟内存后,使用到 56 GB (这个不要理解为占用的物理内存,理解为已被访问的虚拟内存大小,也就是在物理内存呆过的内存大小)的时候,进程就被系统 kill 掉了,如下图:
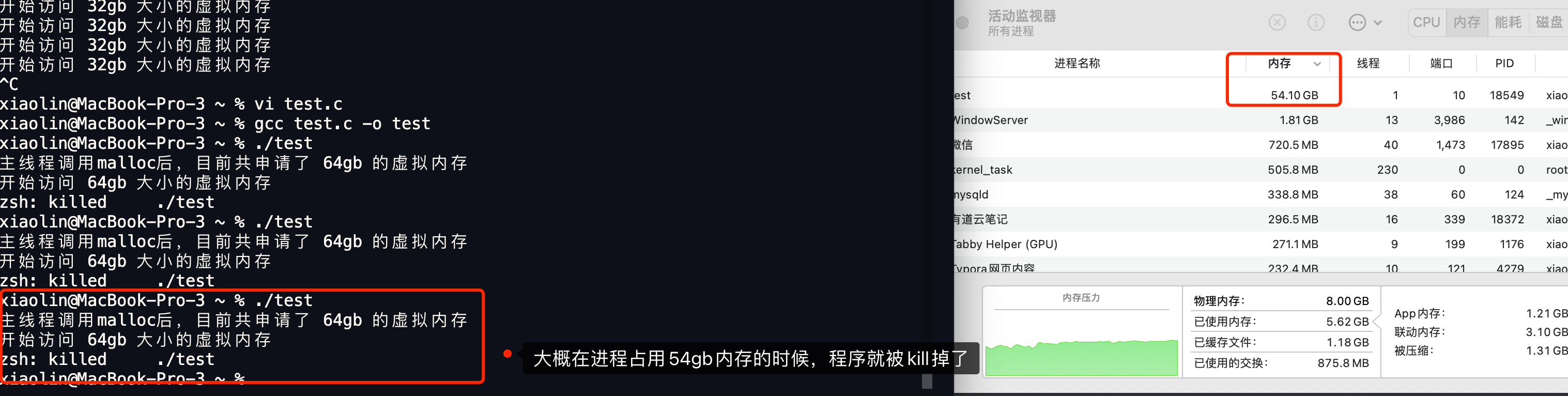
当系统多次尝试回收内存,还是无法满足所需使用的内存大小,进程就会被系统 kill 掉了,意味着发生了 OOM (PS:我没有在 macos 系统找到像 linux 系统里的 /var/log/message 系统日志文件,所以无法通过查看日志确认是否发生了 OOM)。
总结
至此, 验证完成了。简单总结下:
- 在 32 位操作系统,因为进程理论上最大能申请 3 GB 大小的虚拟内存,所以直接申请 8G 内存,会申请失败。
- 在 64位 位操作系统,因为进程理论上最大能申请 128 TB 大小的虚拟内存,即使物理内存只有 4GB,申请 8G 内存也是没问题,因为申请的内存是虚拟内存。如果这块虚拟内存被访问了,要看系统有没有 Swap 分区:
- 如果没有 Swap 分区,因为物理空间不够,进程会被操作系统杀掉,原因是 OOM(内存溢出);
- 如果有 Swap 分区,即使物理内存只有 4GB,程序也能正常使用 8GB 的内存,进程可以正常运行;
如何避免预读失效和缓存污染的问题?
上周群里看到有位小伙伴面试时,被问到这两个问题:
咋一看,以为是在问操作系统的问题,其实这两个题目都是在问如何改进 LRU 算法。
因为传统的 LRU 算法存在这两个问题:
- 「预读失效」导致缓存命中率下降(对应第一个题目)
- 「缓存污染」导致缓存命中率下降(对应第二个题目)
Redis 的缓存淘汰算法则是通过实现 LFU 算法来避免「缓存污染」而导致缓存命中率下降的问题(Redis 没有预读机制)。
MySQL 和 Linux 操作系统是通过改进 LRU 算法来避免「预读失效和缓存污染」而导致缓存命中率下降的问题。
这次,就重点讲讲 MySQL 和 Linux 操作系统是如何改进 LRU 算法的?
好了,开始发车,坐稳了!
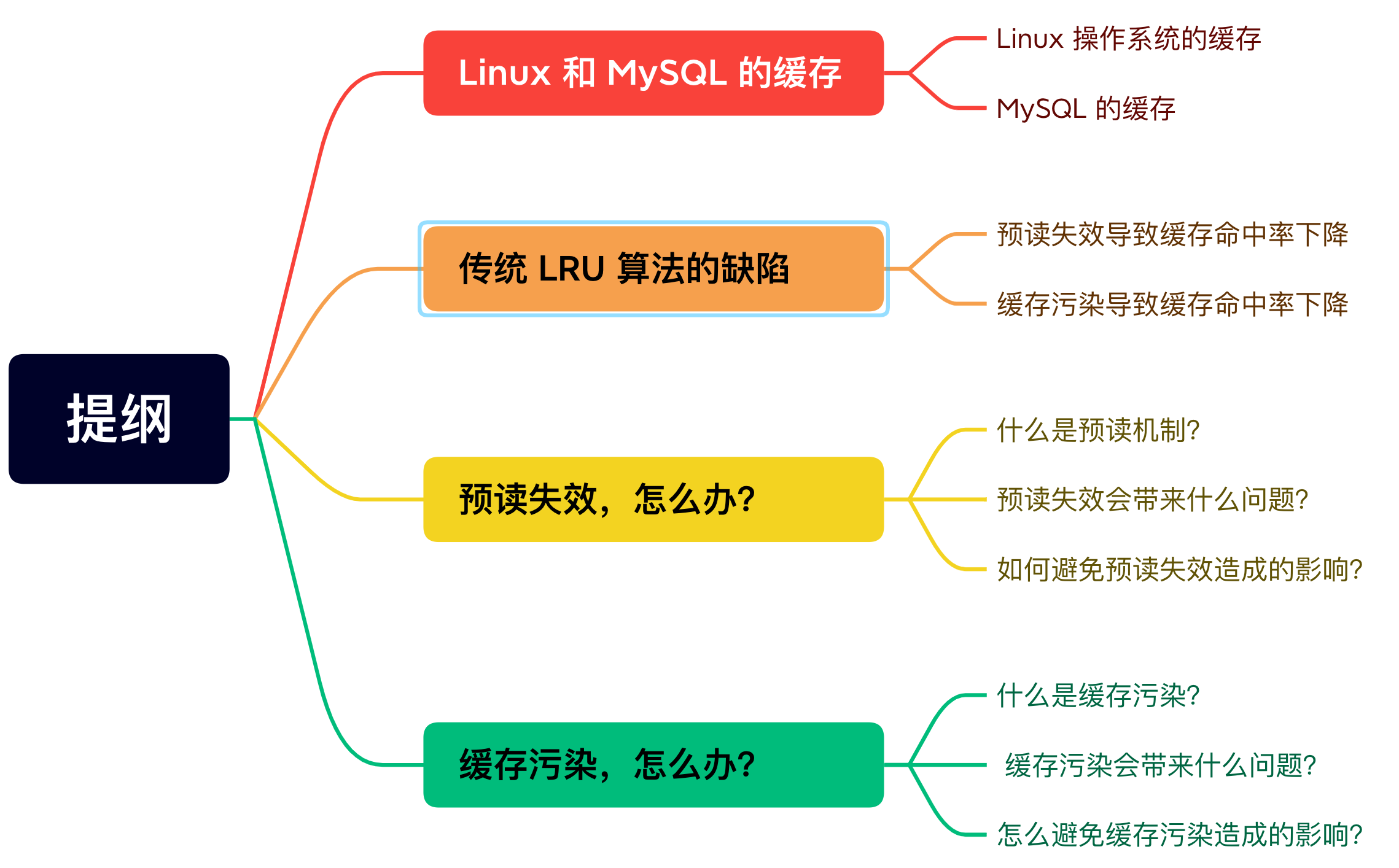
Linux 和 MySQL 的缓存
Linux 操作系统的缓存
在应用程序读取文件的数据的时候,Linux 操作系统是会对读取的文件数据进行缓存的,会缓存在文件系统中的 Page Cache(如下图中的页缓存)。
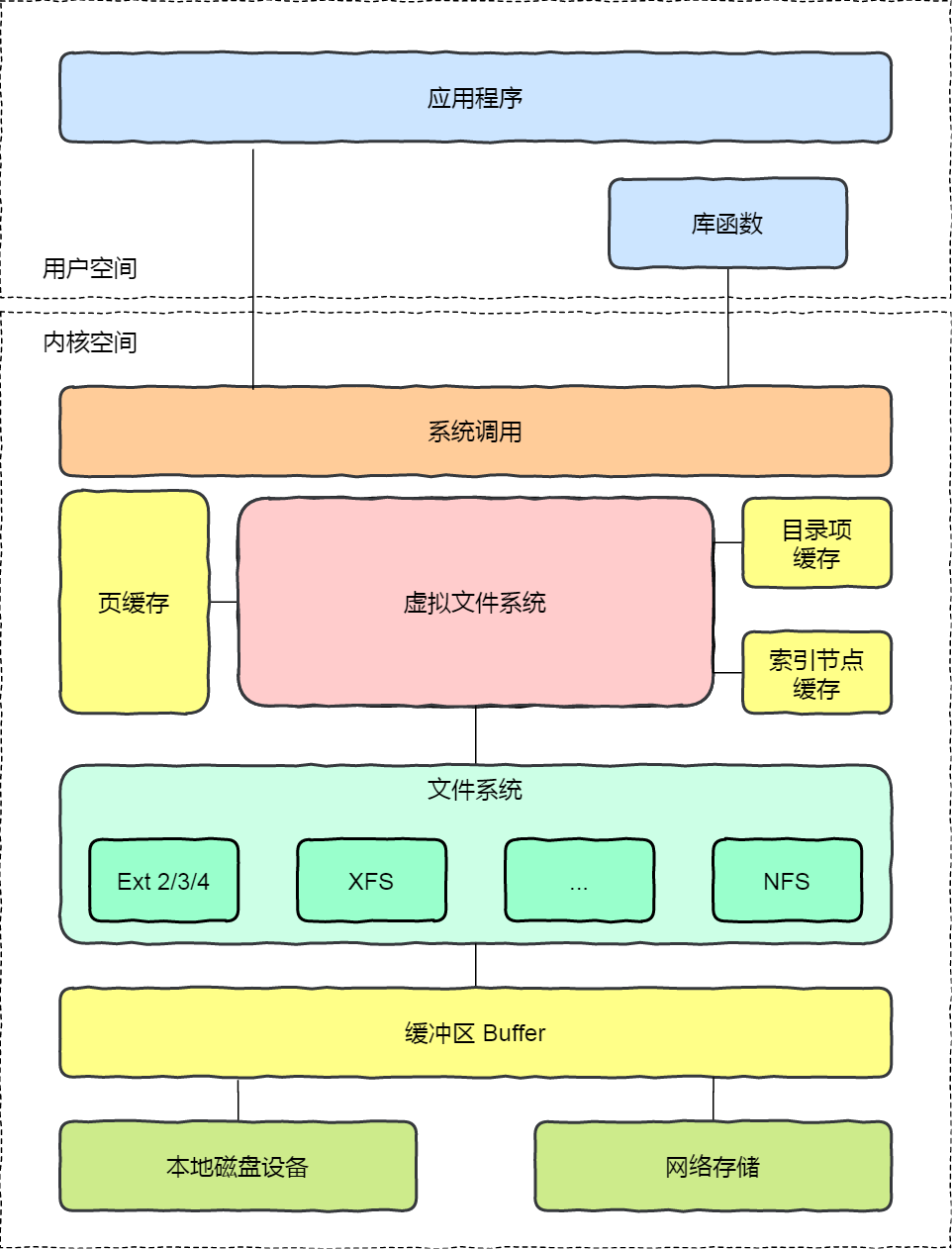
Page Cache 属于内存空间里的数据,由于内存访问比磁盘访问快很多,在下一次访问相同的数据就不需要通过磁盘 I/O 了,命中缓存就直接返回数据即可。
因此,Page Cache 起到了加速访问数据的作用。
MySQL 的缓存
MySQL 的数据是存储在磁盘里的,为了提升数据库的读写性能,Innodb 存储引擎设计了一个缓冲池(Buffer Pool),Buffer Pool 属于内存空间里的数据。
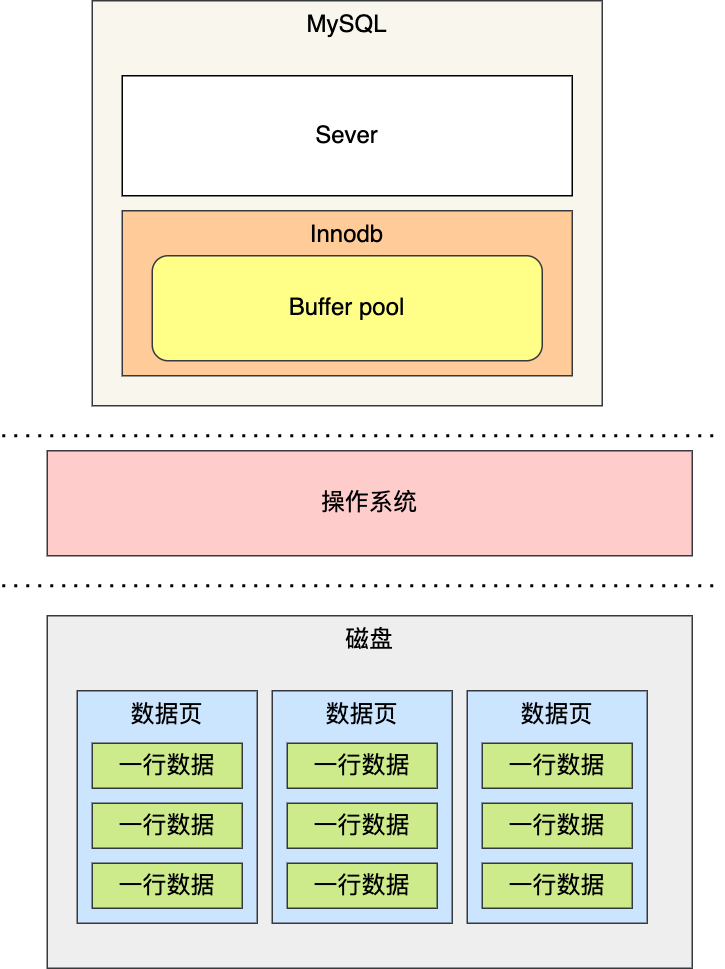
有了缓冲池后:
- 当读取数据时,如果数据存在于 Buffer Pool 中,客户端就会直接读取 Buffer Pool 中的数据,否则再去磁盘中读取。
- 当修改数据时,首先是修改 Buffer Pool 中数据所在的页,然后将其页设置为脏页,最后由后台线程将脏页写入到磁盘。
传统 LRU 是如何管理内存数据的?
Linux 的 Page Cache 和 MySQL 的 Buffer Pool 的大小是有限的,并不能无限的缓存数据,对于一些频繁访问的数据我们希望可以一直留在内存中,而一些很少访问的数据希望可以在某些时机可以淘汰掉,从而保证内存不会因为满了而导致无法再缓存新的数据,同时还能保证常用数据留在内存中。
要实现这个,最容易想到的就是 LRU(Least recently used)算法。
LRU 算法一般是用「链表」作为数据结构来实现的,链表头部的数据是最近使用的,而链表末尾的数据是最久没被使用的。那么,当空间不够了,就淘汰最久没被使用的节点,也就是链表末尾的数据,从而腾出内存空间。
因为 Linux 的 Page Cache 和 MySQL 的 Buffer Pool 缓存的基本数据单位都是页(Page)单位,所以后续以「页」名称代替「数据」。
传统的 LRU 算法的实现思路是这样的:
- 当访问的页在内存里,就直接把该页对应的 LRU 链表节点移动到链表的头部。
- 当访问的页不在内存里,除了要把该页放入到 LRU 链表的头部,还要淘汰 LRU 链表末尾的页。
比如下图,假设 LRU 链表长度为 5,LRU 链表从左到右有编号为 1,2,3,4,5 的页。

如果访问了 3 号页,因为 3 号页已经在内存了,所以把 3 号页移动到链表头部即可,表示最近被访问了。

而如果接下来,访问了 8 号页,因为 8 号页不在内存里,且 LRU 链表长度为 5,所以必须要淘汰数据,以腾出内存空间来缓存 8 号页,于是就会淘汰末尾的 5 号页,然后再将 8 号页加入到头部。
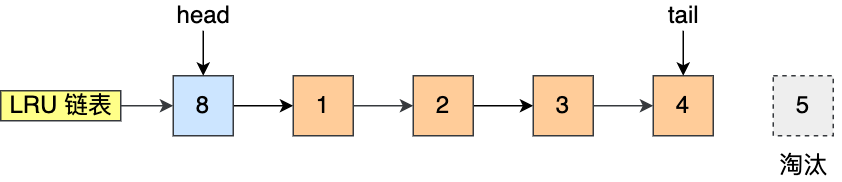
传统的 LRU 算法并没有被 Linux 和 MySQL 使用,因为传统的 LRU 算法无法避免下面这两个问题:
- 预读失效导致缓存命中率下降;
- 缓存污染导致缓存命中率下降;
预读失效,怎么办?
什么是预读机制?
Linux 操作系统为基于 Page Cache 的读缓存机制提供预读机制,一个例子是:
- 应用程序只想读取磁盘上文件 A 的 offset 为 0-3KB 范围内的数据,由于磁盘的基本读写单位为 block(4KB),于是操作系统至少会读 0-4KB 的内容,这恰好可以在一个 page 中装下。
- 但是操作系统出于空间局部性原理(靠近当前被访问数据的数据,在未来很大概率会被访问到),会选择将磁盘块 offset [4KB,8KB)、[8KB,12KB) 以及 [12KB,16KB) 都加载到内存,于是额外在内存中申请了 3 个 page;
下图代表了操作系统的预读机制:
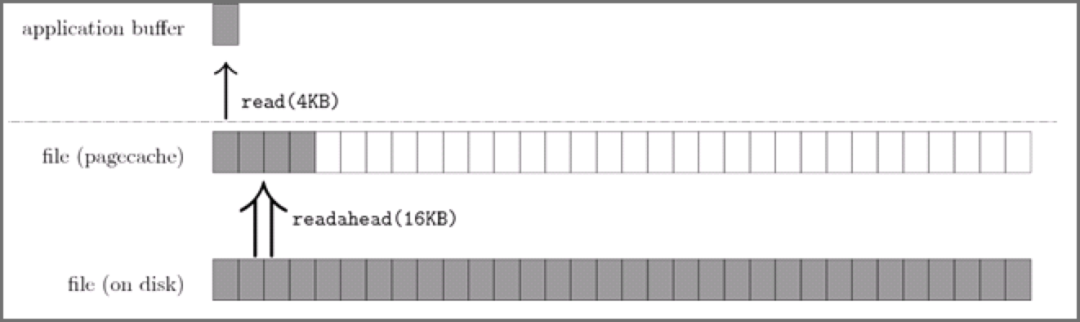
上图中,应用程序利用 read 系统调动读取 4KB 数据,实际上内核使用预读机制(ReadaHead) 机制完成了 16KB 数据的读取,也就是通过一次磁盘顺序读将多个 Page 数据装入 Page Cache。
这样下次读取 4KB 数据后面的数据的时候,就不用从磁盘读取了,直接在 Page Cache 即可命中数据。因此,预读机制带来的好处就是减少了 磁盘 I/O 次数,提高系统磁盘 I/O 吞吐量。
MySQL Innodb 存储引擎的 Buffer Pool 也有类似的预读机制,MySQL 从磁盘加载页时,会提前把它相邻的页一并加载进来,目的是为了减少磁盘 IO。
预读失效会带来什么问题?
如果这些被提前加载进来的页,并没有被访问,相当于这个预读工作是白做了,这个就是预读失效。
如果使用传统的 LRU 算法,就会把「预读页」放到 LRU 链表头部,而当内存空间不够的时候,还需要把末尾的页淘汰掉。
如果这些「预读页」如果一直不会被访问到,就会出现一个很奇怪的问题,不会被访问的预读页却占用了 LRU 链表前排的位置,而末尾淘汰的页,可能是热点数据,这样就大大降低了缓存命中率 。
如何避免预读失效造成的影响?
我们不能因为害怕预读失效,而将预读机制去掉,大部分情况下,空间局部性原理还是成立的。
要避免预读失效带来影响,最好就是让预读页停留在内存里的时间要尽可能的短,让真正被访问的页才移动到 LRU 链表的头部,从而保证真正被读取的热数据留在内存里的时间尽可能长。
那到底怎么才能避免呢?
Linux 操作系统和 MySQL Innodb 通过改进传统 LRU 链表来避免预读失效带来的影响,具体的改进分别如下:
- Linux 操作系统实现两个了 LRU 链表:活跃 LRU 链表(active_list)和非活跃 LRU 链表(inactive_list);
- MySQL 的 Innodb 存储引擎是在一个 LRU 链表上划分来 2 个区域:young 区域 和 old 区域。
这两个改进方式,设计思想都是类似的,都是将数据分为了冷数据和热数据,然后分别进行 LRU 算法。不再像传统的 LRU 算法那样,所有数据都只用一个 LRU 算法管理。
接下来,具体聊聊 Linux 和 MySQL 是如何避免预读失效带来的影响?
Linux 是如何避免预读失效带来的影响?
Linux 操作系统实现两个了 LRU 链表:活跃 LRU 链表(active_list)和非活跃 LRU 链表(inactive_list)。
- active list 活跃内存页链表,这里存放的是最近被访问过(活跃)的内存页;
- inactive list 不活跃内存页链表,这里存放的是很少被访问(非活跃)的内存页;
有了这两个 LRU 链表后,预读页就只需要加入到 inactive list 区域的头部,当页被真正访问的时候,才将页插入 active list 的头部。如果预读的页一直没有被访问,就会从 inactive list 移除,这样就不会影响 active list 中的热点数据。
接下来,给大家举个例子。
假设 active list 和 inactive list 的长度为 5,目前内存中已经有如下 10 个页:
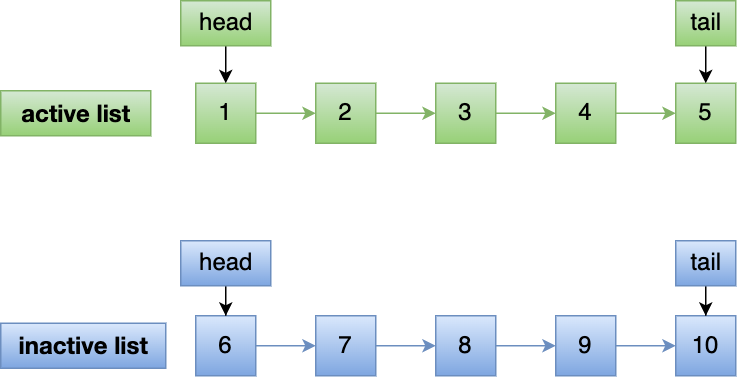
现在有个编号为 20 的页被预读了,这个页只会被插入到 inactive list 的头部,而 inactive list 末尾的页(10号)会被淘汰掉。
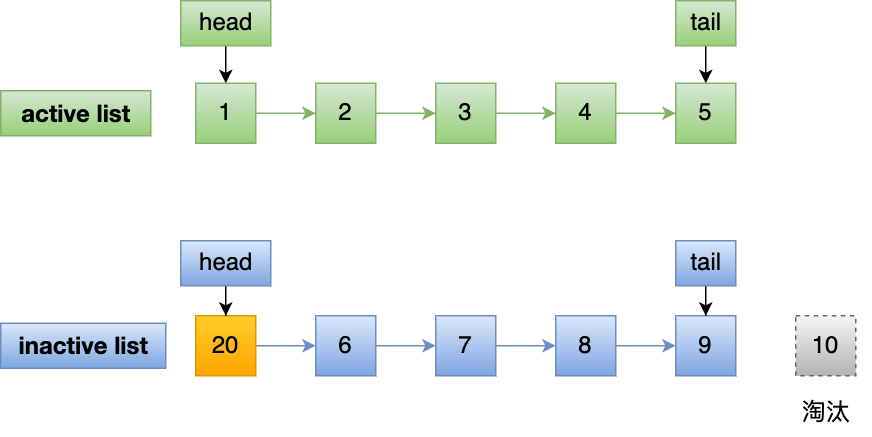
即使编号为 20 的预读页一直不会被访问,它也没有占用到 active list 的位置,而且还会比 active list 中的页更早被淘汰出去。
如果 20 号页被预读后,立刻被访问了,那么就会将它插入到 active list 的头部, active list 末尾的页(5号),会被降级到 inactive list ,作为 inactive list 的头部,这个过程并不会有数据被淘汰。
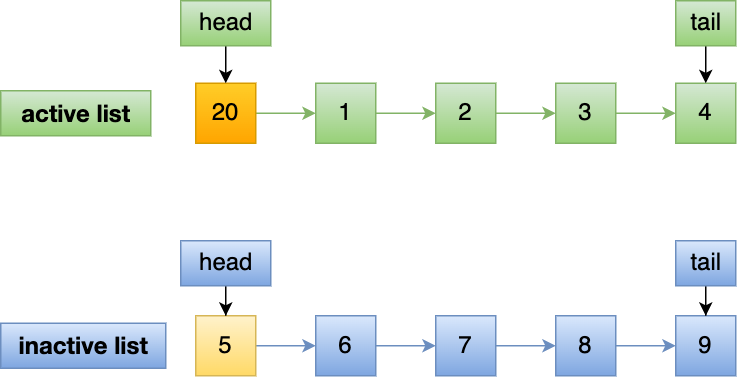
MySQL 是如何避免预读失效带来的影响?
MySQL 的 Innodb 存储引擎是在一个 LRU 链表上划分来 2 个区域,young 区域 和 old 区域。
young 区域在 LRU 链表的前半部分,old 区域则是在后半部分,这两个区域都有各自的头和尾节点,如下图:
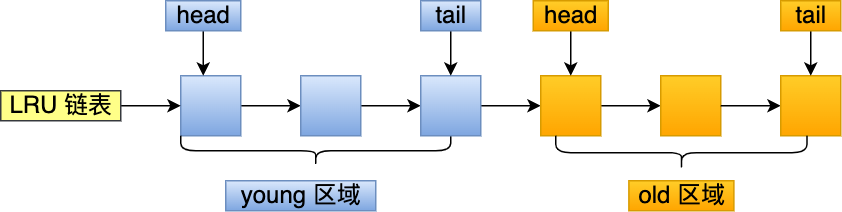
young 区域与 old 区域在 LRU 链表中的占比关系并不是一比一的关系,而是 63:37(默认比例)的关系。
划分这两个区域后,预读的页就只需要加入到 old 区域的头部,当页被真正访问的时候,才将页插入 young 区域的头部。如果预读的页一直没有被访问,就会从 old 区域移除,这样就不会影响 young 区域中的热点数据。
接下来,给大家举个例子。
假设有一个长度为 10 的 LRU 链表,其中 young 区域占比 70 %,old 区域占比 30 %。

现在有个编号为 20 的页被预读了,这个页只会被插入到 old 区域头部,而 old 区域末尾的页(10号)会被淘汰掉。

如果 20 号页一直不会被访问,它也没有占用到 young 区域的位置,而且还会比 young 区域的数据更早被淘汰出去。
如果 20 号页被预读后,立刻被访问了,那么就会将它插入到 young 区域的头部,young 区域末尾的页(7号),会被挤到 old 区域,作为 old 区域的头部,这个过程并不会有页被淘汰。

缓存污染,怎么办?
什么是缓存污染?
虽然 Linux (实现两个 LRU 链表)和 MySQL (划分两个区域)通过改进传统的 LRU 数据结构,避免了预读失效带来的影响。
但是如果还是使用「只要数据被访问一次,就将数据加入到活跃 LRU 链表头部(或者 young 区域)」这种方式的话,那么还存在缓存污染的问题。
当我们在批量读取数据的时候,由于数据被访问了一次,这些大量数据都会被加入到「活跃 LRU 链表」里,然后之前缓存在活跃 LRU 链表(或者 young 区域)里的热点数据全部都被淘汰了,如果这些大量的数据在很长一段时间都不会被访问的话,那么整个活跃 LRU 链表(或者 young 区域)就被污染了。
缓存污染会带来什么问题?
缓存污染带来的影响就是很致命的,等这些热数据又被再次访问的时候,由于缓存未命中,就会产生大量的磁盘 I/O,系统性能就会急剧下降。
我以 MySQL 举例子,Linux 发生缓存污染的现象也是类似。
当某一个 SQL 语句扫描了大量的数据时,在 Buffer Pool 空间比较有限的情况下,可能会将 Buffer Pool 里的所有页都替换出去,导致大量热数据被淘汰了,等这些热数据又被再次访问的时候,由于缓存未命中,就会产生大量的磁盘 I/O,MySQL 性能就会急剧下降。
注意, 缓存污染并不只是查询语句查询出了大量的数据才出现的问题,即使查询出来的结果集很小,也会造成缓存污染。
比如,在一个数据量非常大的表,执行了这条语句:
|
|
可能这个查询出来的结果就几条记录,但是由于这条语句会发生索引失效,所以这个查询过程是全表扫描的,接着会发生如下的过程:
- 从磁盘读到的页加入到 LRU 链表的 old 区域头部;
- 当从页里读取行记录时,也就是页被访问的时候,就要将该页放到 young 区域头部;
- 接下来拿行记录的 name 字段和字符串 xiaolin 进行模糊匹配,如果符合条件,就加入到结果集里;
- 如此往复,直到扫描完表中的所有记录。
经过这一番折腾,由于这条 SQL 语句访问的页非常多,每访问一个页,都会将其加入 young 区域头部,那么原本 young 区域的热点数据都会被替换掉,导致缓存命中率下降。那些在批量扫描时,而被加入到 young 区域的页,如果在很长一段时间都不会再被访问的话,那么就污染了 young 区域。
举个例子,假设需要批量扫描:21,22,23,24,25 这五个页,这些页都会被逐一访问(读取页里的记录)。
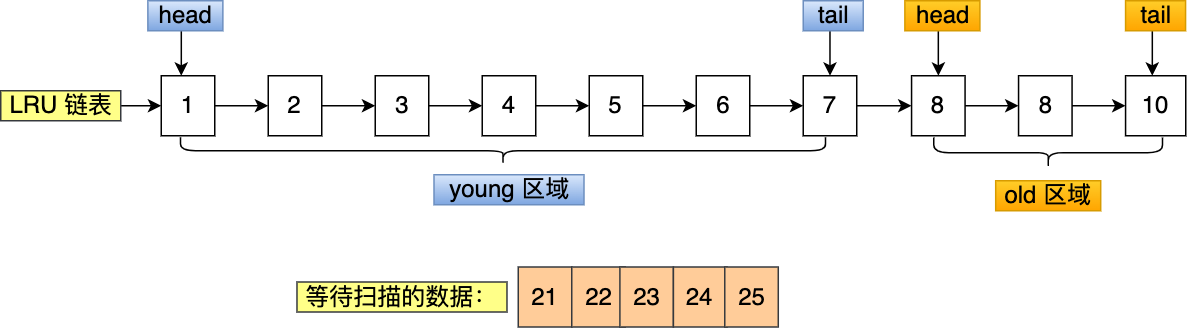
在批量访问这些页的时候,会被逐一插入到 young 区域头部。

可以看到,原本在 young 区域的 6 和 7 号页都被淘汰了,而批量扫描的页基本占满了 young 区域,如果这些页在很长一段时间都不会被访问,那么就对 young 区域造成了污染。
如果 6 和 7 号页是热点数据,那么在被淘汰后,后续有 SQL 再次读取 6 和 7 号页时,由于缓存未命中,就要从磁盘中读取了,降低了 MySQL 的性能,这就是缓存污染带来的影响。
怎么避免缓存污染造成的影响?
前面的 LRU 算法只要数据被访问一次,就将数据加入活跃 LRU 链表(或者 young 区域),这种 LRU 算法进入活跃 LRU 链表的门槛太低了!正式因为门槛太低,才导致在发生缓存污染的时候,很容就将原本在活跃 LRU 链表里的热点数据淘汰了。
所以,只要我们提高进入到活跃 LRU 链表(或者 young 区域)的门槛,就能有效地保证活跃 LRU 链表(或者 young 区域)里的热点数据不会被轻易替换掉。
Linux 操作系统和 MySQL Innodb 存储引擎分别是这样提高门槛的:
- Linux 操作系统:在内存页被访问第二次的时候,才将页从 inactive list 升级到 active list 里。
- MySQL Innodb:在内存页被访问第二次的时候,并不会马上将该页从 old 区域升级到 young 区域,因为还要进行停留在 old 区域的时间判断:
- 如果第二次的访问时间与第一次访问的时间在 1 秒内(默认值),那么该页就不会被从 old 区域升级到 young 区域;
- 如果第二次的访问时间与第一次访问的时间超过 1 秒,那么该页就会从 old 区域升级到 young 区域;
提高了进入活跃 LRU 链表(或者 young 区域)的门槛后,就很好了避免缓存污染带来的影响。
在批量读取数据时候,如果这些大量数据只会被访问一次,那么它们就不会进入到活跃 LRU 链表(或者 young 区域),也就不会把热点数据淘汰,只会待在非活跃 LRU 链表(或者 old 区域)中,后续很快也会被淘汰。
总结
传统的 LRU 算法法无法避免下面这两个问题:
- 预读失效导致缓存命中率下降;
- 缓存污染导致缓存命中率下降;
为了避免「预读失效」造成的影响,Linux 和 MySQL 对传统的 LRU 链表做了改进:
- Linux 操作系统实现两个了 LRU 链表:活跃 LRU 链表(active list)和非活跃 LRU 链表(inactive list)。
- MySQL Innodb 存储引擎是在一个 LRU 链表上划分来 2 个区域:young 区域 和 old 区域。
但是如果还是使用「只要数据被访问一次,就将数据加入到活跃 LRU 链表头部(或者 young 区域)」这种方式的话,那么还存在缓存污染的问题。
为了避免「缓存污染」造成的影响,Linux 操作系统和 MySQL Innodb 存储引擎分别提高了升级为热点数据的门槛:
- Linux 操作系统:在内存页被访问第二次的时候,才将页从 inactive list 升级到 active list 里。
- MySQL Innodb:在内存页被访问第二次的时候,并不会马上将该页从 old 区域升级到 young 区域,因为还要进行停留在 old 区域的时间判断:
- 如果第二次的访问时间与第一次访问的时间在 1 秒内(默认值),那么该页就不会被从 old 区域升级到 young 区域;
- 如果第二次的访问时间与第一次访问的时间超过 1 秒,那么该页就会从 old 区域升级到 young 区域;
通过提高了进入 active list (或者 young 区域)的门槛后,就很好了避免缓存污染带来的影响。
深入理解Linux虚拟内存管理
这一篇会比较硬核,是比较全面的一篇 Linux 虚拟内存管理的文章,文章多达 3.5 万字 + 60 张图,耐心读下去,肯定对 Linux 虚拟内存管理有很深刻的理解!
内存管理子系统可谓是 Linux 内核众多子系统中最为复杂最为庞大的一个,其中包含了众多繁杂的概念和原理,通过内存管理这条主线我们把可以把操作系统的众多核心系统给拎出来,比如:进程管理子系统,网络子系统,文件子系统等。
由于内存管理子系统过于复杂庞大,其中涉及到的众多繁杂的概念又是一环套一环,层层递进。如何把这些繁杂的概念具有层次感地,并且清晰地,给大家梳理呈现出来真是一件比较有难度的事情,因此关于这个问题,我在动笔写这个内存管理源码解析系列之前也是思考了很久。
万事开头难,那么到底什么内容适合作为这个系列的开篇呢 ?我还是觉得从大家日常开发工作中接触最多最为熟悉的部分开始比较好,比如:在我们日常开发中创建的类,调用的函数,在函数中定义的局部变量以及 new 出来的数据容器(Map,List,Set …..等)都需要存储在物理内存中的某个角落。
而我们在程序中编写业务逻辑代码的时候,往往需要引用这些创建出来的数据结构,并通过这些引用对相关数据结构进行业务处理。
当程序运行起来之后就变成了进程,而这些业务数据结构的引用在进程的视角里全都都是虚拟内存地址,因为进程无论是在用户态还是在内核态能够看到的都是虚拟内存空间,物理内存空间被操作系统所屏蔽进程是看不到的。
进程通过虚拟内存地址访问这些数据结构的时候,虚拟内存地址会在内存管理子系统中被转换成物理内存地址,通过物理内存地址就可以访问到真正存储这些数据结构的物理内存了。随后就可以对这块物理内存进行各种业务操作,从而完成业务逻辑。
- 那么到底什么是虚拟内存地址 ?
- Linux 内核为啥要引入虚拟内存而不直接使用物理内存 ?
- 虚拟内存空间到底长啥样?
- 内核如何管理虚拟内存?
- 什么又是物理内存地址 ?如何访问物理内存?
本文我就来为大家详细一一解答上述几个问题,让我们马上开始吧~~~~
到底什么是虚拟内存地址
首先人们提出地址这个概念的目的就是用来方便定位现实世界中某一个具体事物的真实地理位置,它是一种用于定位的概念模型。
举一个生活中的例子,比如大家在日常生活中给亲朋好友邮寄一些本地特产时,都会填写收件人地址以及寄件人地址。以及在日常网上购物时,都会在相应电商 APP 中填写自己的收货地址。
随后快递小哥就会根据我们填写的收货地址找到我们的真实住所,将我们网购的商品送达到我们的手里。
收货地址是用来定位我们在现实世界中真实住所地理位置的,而现实世界中我们所在的城市,街道,小区,房屋都是一砖一瓦,一草一木真实存在的。但收货地址这个概念模型在现实世界中并不真实存在,它只是人们提出的一个虚拟概念,通过收货地址这个虚拟概念将它和现实世界真实存在的城市,小区,街道的地理位置一一映射起来,这样我们就可以通过这个虚拟概念来找到现实世界中的具体地理位置。
综上所述,收货地址是一个虚拟地址,它是人为定义的,而我们的城市,小区,街道是真实存在的,他们的地理位置就是物理地址。
比如现在的广东省深圳市在过去叫宝安县,河北省的石家庄过去叫常山,安徽省的合肥过去叫泸州。不管是常山也好,石家庄也好,又或是合肥也好,泸州也罢,这些都是人为定义的名字而已,但是地方还是那个地方,它所在的地理位置是不变的。也就说虚拟地址可以人为的变来变去,但是物理地址永远是不变的。
现在让我们把视角在切换到计算机的世界,在计算机的世界里内存地址用来定义数据在内存中的存储位置的,内存地址也分为虚拟地址和物理地址。而虚拟地址也是人为设计的一个概念,类比我们现实世界中的收货地址,而物理地址则是数据在物理内存中的真实存储位置,类比现实世界中的城市,街道,小区的真实地理位置。
说了这么多,那么到底虚拟内存地址长什么样子呢?
我们还是以日常生活中的收货地址为例做出类比,我们都很熟悉收货地址的格式:xx省xx市xx区xx街道xx小区xx室,它是按照地区层次递进的。同样,在计算机世界中的虚拟内存地址也有这样的递进关系。
这里我们以 Intel Core i7 处理器为例,64 位虚拟地址的格式为:全局页目录项(9位)+ 上层页目录项(9位)+ 中间页目录项(9位)+ 页表项(9位)+ 页内偏移(12位)。共 48 位组成的虚拟内存地址。
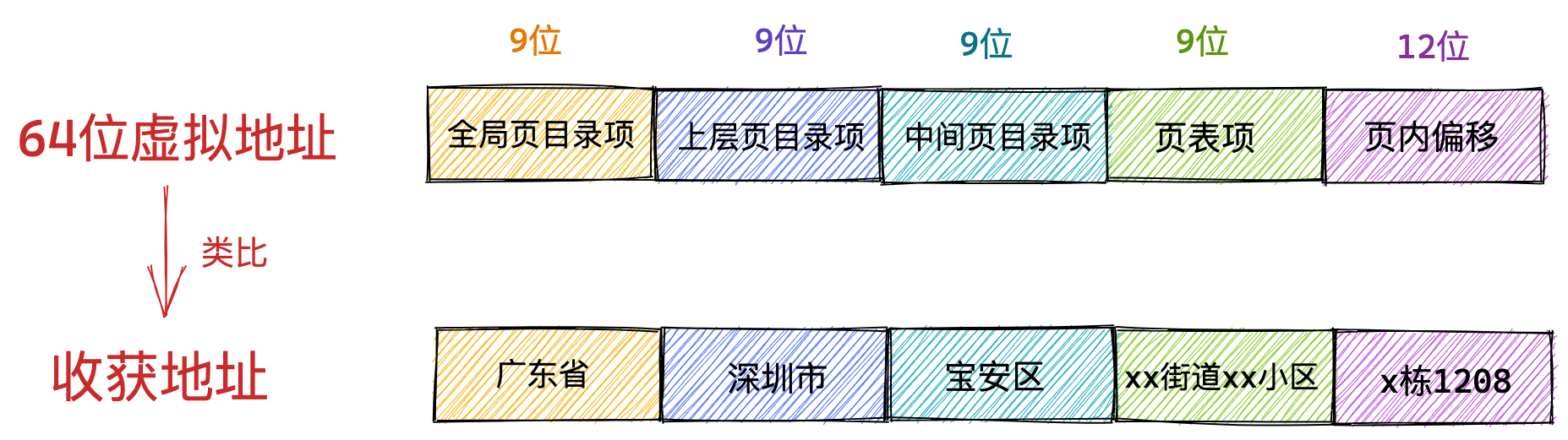
虚拟内存地址中的全局页目录项就类比我们日常生活中收获地址里的省,上层页目录项就类比市,中间层页目录项类比区县,页表项类比街道小区,页内偏移类比我们所在的楼栋和几层几号。
这里大家只需要大体明白虚拟内存地址到底长什么样子,它的格式是什么,能够和日常生活中的收货地址对比理解起来就可以了,至于页目录项,页表项以及页内偏移这些计算机世界中的概念,大家暂时先不用管,后续文章中我会慢慢给大家解释清楚。
32 位虚拟地址的格式为:页目录项(10位)+ 页表项(10位) + 页内偏移(12位)。共 32 位组成的虚拟内存地址。
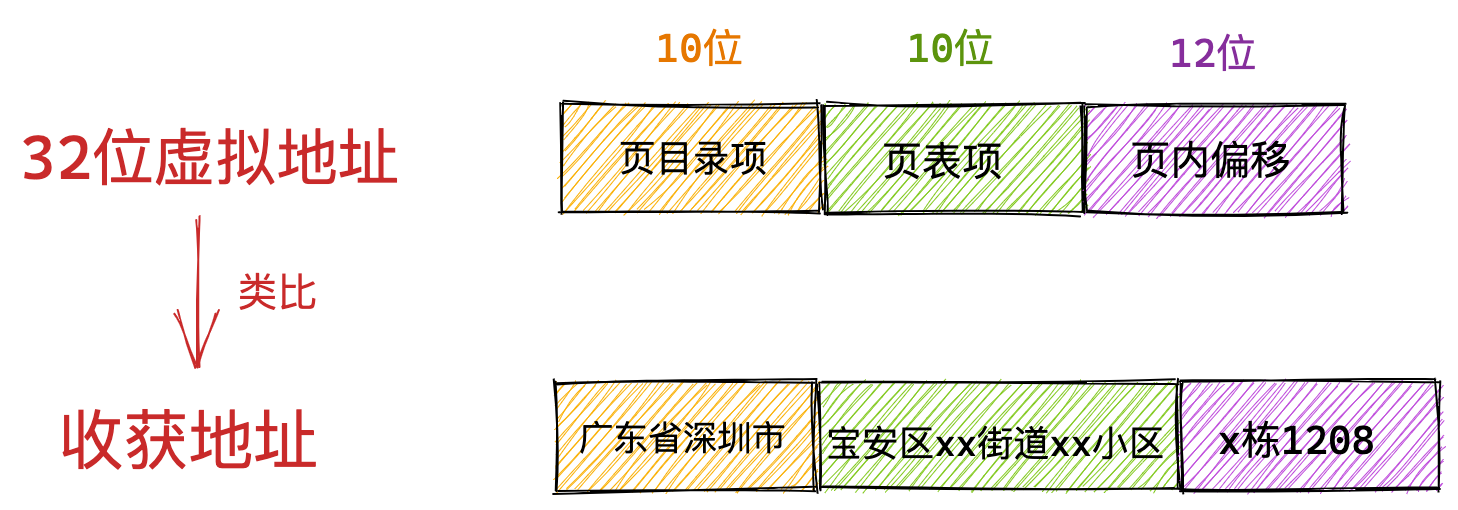
进程虚拟内存空间中的每一个字节都有与其对应的虚拟内存地址,一个虚拟内存地址表示进程虚拟内存空间中的一个特定的字节。
为什么要使用虚拟地址访问内存
经过第一小节的介绍,我们现在明白了计算机世界中的虚拟内存地址的含义及其展现形式。那么大家可能会问了,既然物理内存地址可以直接定位到数据在内存中的存储位置,那为什么我们不直接使用物理内存地址去访问内存而是选择用虚拟内存地址去访问内存呢?
在回答大家的这个疑问之前,让我们先来看下,如果在程序中直接使用物理内存地址会发生什么情况?
假设现在没有虚拟内存地址,我们在程序中对内存的操作全都都是使用物理内存地址,在这种情况下,程序员就需要精确的知道每一个变量在内存中的具体位置,我们需要手动对物理内存进行布局,明确哪些数据存储在内存的哪些位置,除此之外我们还需要考虑为每个进程究竟要分配多少内存?内存紧张的时候该怎么办?如何避免进程与进程之间的地址冲突?等等一系列复杂且琐碎的细节。
如果我们在单进程系统中比如嵌入式设备上开发应用程序,系统中只有一个进程,这单个进程独享所有的物理资源包括内存资源。在这种情况下,上述提到的这些直接使用物理内存的问题可能还好处理一些,但是仍然具有很高的开发门槛。
然而在现代操作系统中往往支持多个进程,需要处理多进程之间的协同问题,在多进程系统中直接使用物理内存地址操作内存所带来的上述问题就变得非常复杂了。
这里我为大家举一个简单的例子来说明在多进程系统中直接使用物理内存地址的复杂性。
比如我们现在有这样一个简单的 Java 程序。
|
|
在程序代码相同的情况下,我们用这份代码同时启动三个 JVM 进程,我们暂时将进程依次命名为 a , b , c 。
这三个进程用到的代码是一样的,都是我们提前写好的,可以被多次运行。由于我们是直接操作物理内存地址,假设变量 i 保存在 0x354 这个物理地址上。这三个进程运行起来之后,同时操作这个 0x354 物理地址,这样这个变量 i 的值不就混乱了吗? 三个进程就会出现变量的地址冲突。
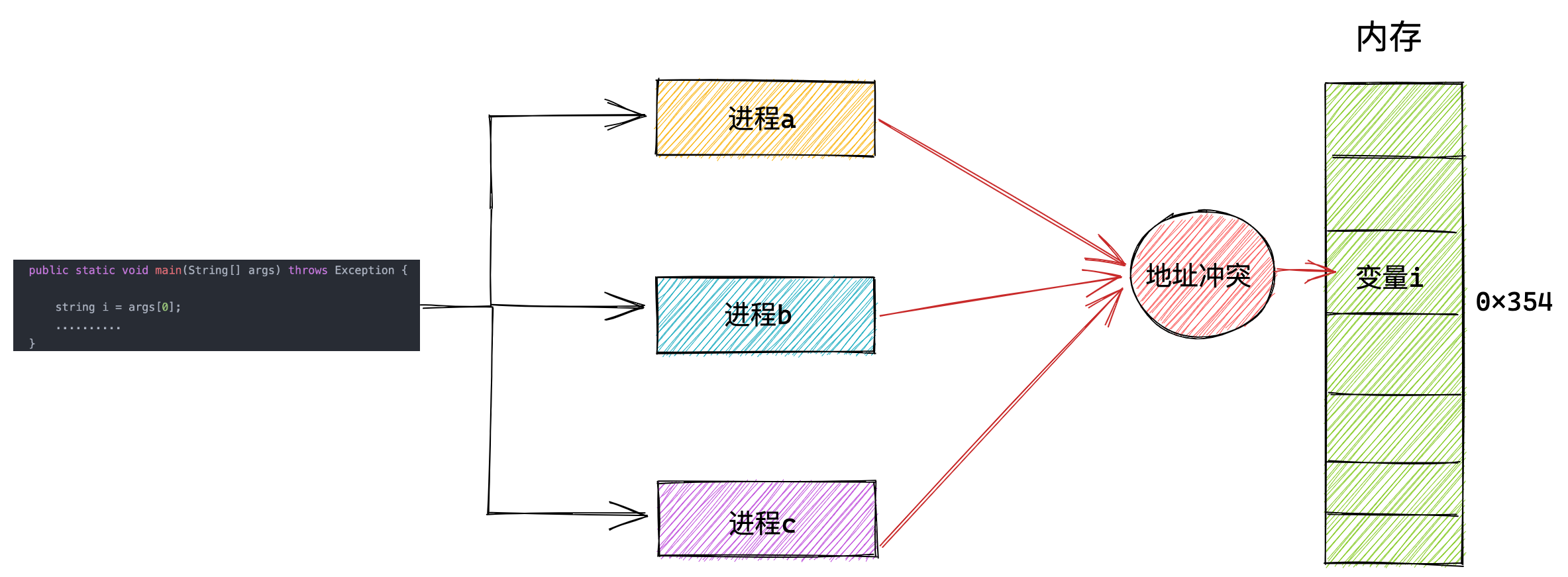
所以在直接操作物理内存的情况下,我们需要知道每一个变量的位置都被安排在了哪里,而且还要注意和多个进程同时运行的时候,不能共用同一个地址,否则就会造成地址冲突。
现实中一个程序会有很多的变量和函数,这样一来我们给它们都需要计算一个合理的位置,还不能与其他进程冲突,这就很复杂了。
那么我们该如何解决这个问题呢?程序的局部性原理再一次救了我们~~
程序局部性原理表现为:时间局部性和空间局部性。时间局部性是指如果程序中的某条指令一旦执行,则不久之后该指令可能再次被执行;如果某块数据被访问,则不久之后该数据可能再次被访问。空间局部性是指一旦程序访问了某个存储单元,则不久之后,其附近的存储单元也将被访问。
从程序局部性原理的描述中我们可以得出这样一个结论:进程在运行之后,对于内存的访问不会一下子就要访问全部的内存,相反进程对于内存的访问会表现出明显的倾向性,更加倾向于访问最近访问过的数据以及热点数据附近的数据。
根据这个结论我们就清楚了,无论一个进程实际可以占用的内存资源有多大,根据程序局部性原理,在某一段时间内,进程真正需要的物理内存其实是很少的一部分,我们只需要为每个进程分配很少的物理内存就可以保证进程的正常执行运转。
而虚拟内存的引入正是要解决上述的问题,虚拟内存引入之后,进程的视角就会变得非常开阔,每个进程都拥有自己独立的虚拟地址空间,进程与进程之间的虚拟内存地址空间是相互隔离,互不干扰的。每个进程都认为自己独占所有内存空间,自己想干什么就干什么。
系统上还运行了哪些进程和我没有任何关系。这样一来我们就可以将多进程之间协同的相关复杂细节统统交给内核中的内存管理模块来处理,极大地解放了程序员的心智负担。这一切都是因为虚拟内存能够提供内存地址空间的隔离,极大地扩展了可用空间。
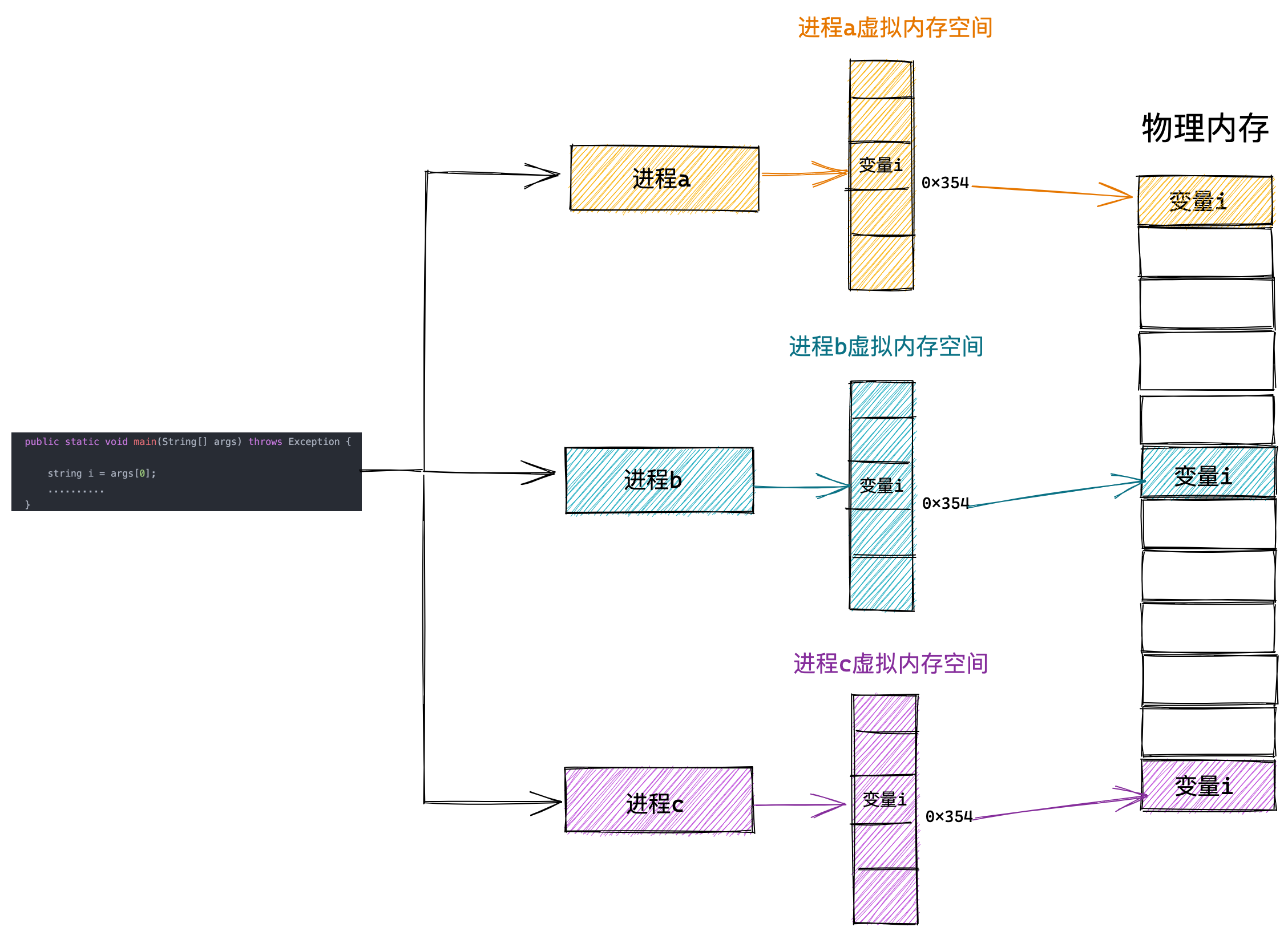
这样进程就以为自己独占了整个内存空间资源,给进程产生了所有内存资源都属于它自己的幻觉,这其实是 CPU 和操作系统使用的一个障眼法罢了,任何一个虚拟内存里所存储的数据,本质上还是保存在真实的物理内存里的。只不过内核帮我们做了虚拟内存到物理内存的这一层映射,将不同进程的虚拟地址和不同内存的物理地址映射起来。
当 CPU 访问进程的虚拟地址时,经过地址翻译硬件将虚拟地址转换成不同的物理地址,这样不同的进程运行的时候,虽然操作的是同一虚拟地址,但其实背后写入的是不同的物理地址,这样就不会冲突了。
进程虚拟内存空间
上小节中,我们介绍了为了防止多进程运行时造成的内存地址冲突,内核引入了虚拟内存地址,为每个进程提供了一个独立的虚拟内存空间,使得进程以为自己独占全部内存资源。
那么这个进程独占的虚拟内存空间到底是什么样子呢?在本小节中,我就为大家揭开这层神秘的面纱~~~
在本小节内容开始之前,我们先想象一下,如果我们是内核的设计人员,我们该从哪些方面来规划进程的虚拟内存空间呢?
本小节我们只讨论进程用户态虚拟内存空间的布局,我们先把内核态的虚拟内存空间当做一个黑盒来看待,在后面的小节中我再来详细介绍内核态相关内容。
首先我们会想到的是一个进程运行起来是为了执行我们交代给进程的工作,执行这些工作的步骤我们通过程序代码事先编写好,然后编译成二进制文件存放在磁盘中,CPU 会执行二进制文件中的机器码来驱动进程的运行。所以在进程运行之前,这些存放在二进制文件中的机器码需要被加载进内存中,而用于存放这些机器码的虚拟内存空间叫做代码段。
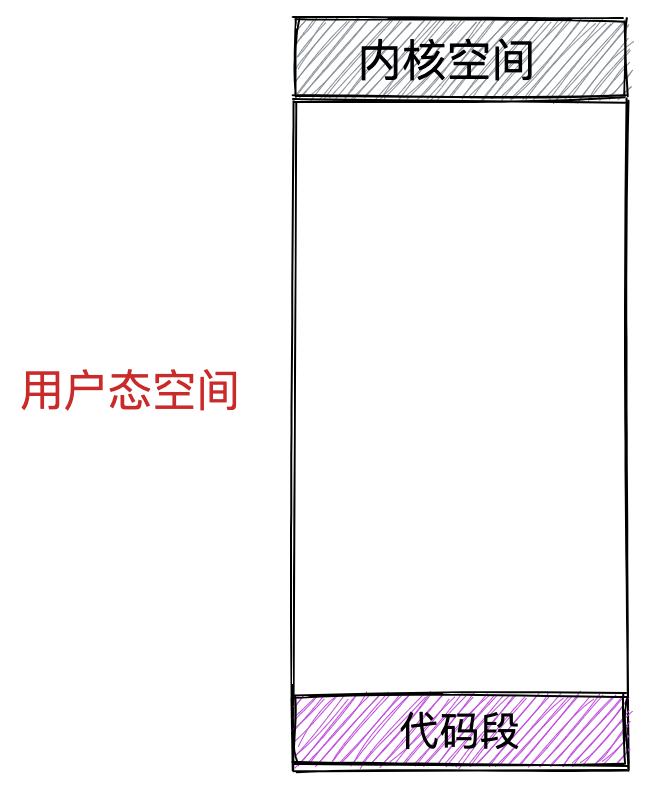
在程序运行起来之后,总要操作变量吧,在程序代码中我们通常会定义大量的全局变量和静态变量,这些全局变量在程序编译之后也会存储在二进制文件中,在程序运行之前,这些全局变量也需要被加载进内存中供程序访问。所以在虚拟内存空间中也需要一段区域来存储这些全局变量。
- 那些在代码中被我们指定了初始值的全局变量和静态变量在虚拟内存空间中的存储区域我们叫做数据段。
- 那些没有指定初始值的全局变量和静态变量在虚拟内存空间中的存储区域我们叫做 BSS 段。这些未初始化的全局变量被加载进内存之后会被初始化为 0 值。
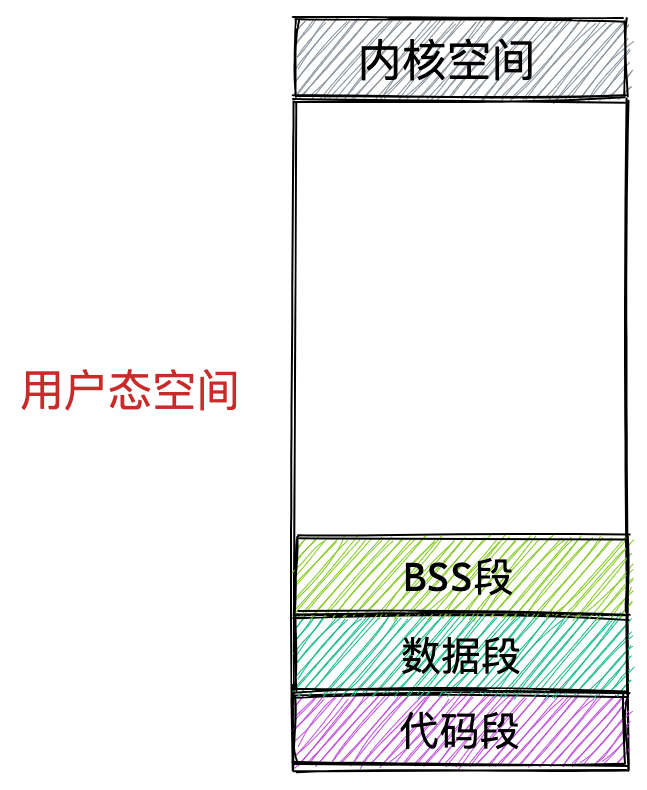
上面介绍的这些全局变量和静态变量都是在编译期间就确定的,但是我们程序在运行期间往往需要动态的申请内存,所以在虚拟内存空间中也需要一块区域来存放这些动态申请的内存,这块区域就叫做堆。注意这里的堆指的是 OS 堆并不是 JVM 中的堆。
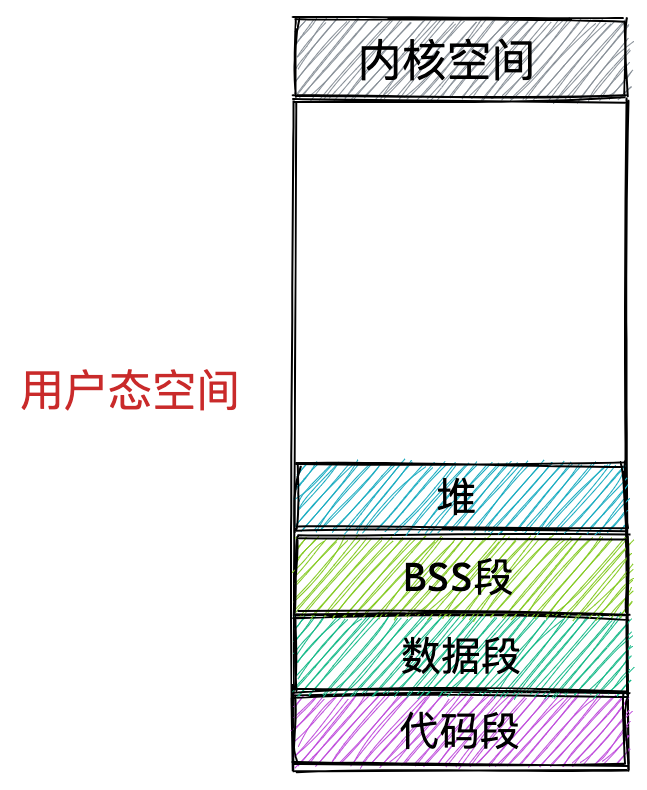
除此之外,我们的程序在运行过程中还需要依赖动态链接库,这些动态链接库以 .so 文件的形式存放在磁盘中,比如 C 程序中的 glibc,里边对系统调用进行了封装。glibc 库里提供的用于动态申请堆内存的 malloc 函数就是对系统调用 sbrk 和 mmap 的封装。这些动态链接库也有自己的对应的代码段,数据段,BSS 段,也需要一起被加载进内存中。
还有用于内存文件映射的系统调用 mmap,会将文件与内存进行映射,那么映射的这块内存(虚拟内存)也需要在虚拟地址空间中有一块区域存储。
这些动态链接库中的代码段,数据段,BSS 段,以及通过 mmap 系统调用映射的共享内存区,在虚拟内存空间的存储区域叫做文件映射与匿名映射区。
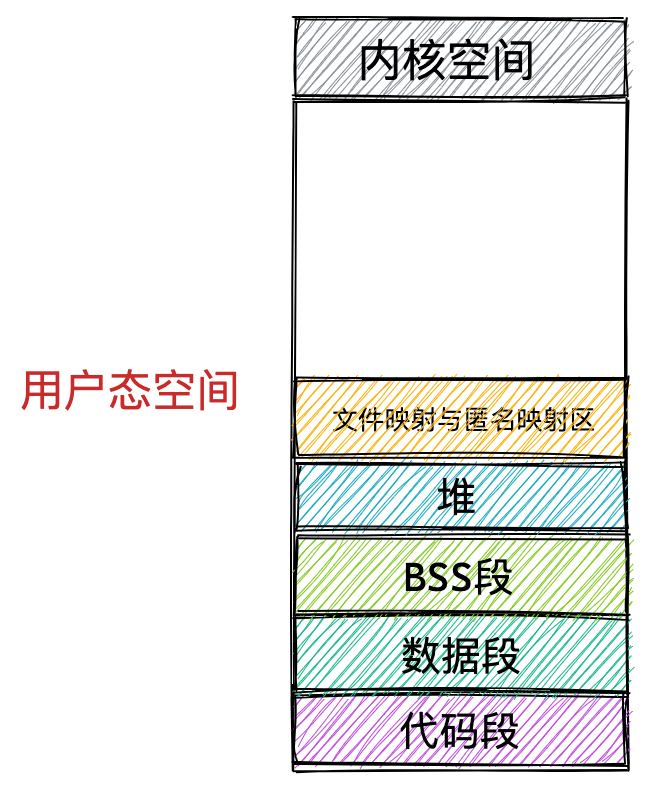
最后我们在程序运行的时候总该要调用各种函数吧,那么调用函数过程中使用到的局部变量和函数参数也需要一块内存区域来保存。这一块区域在虚拟内存空间中叫做栈。
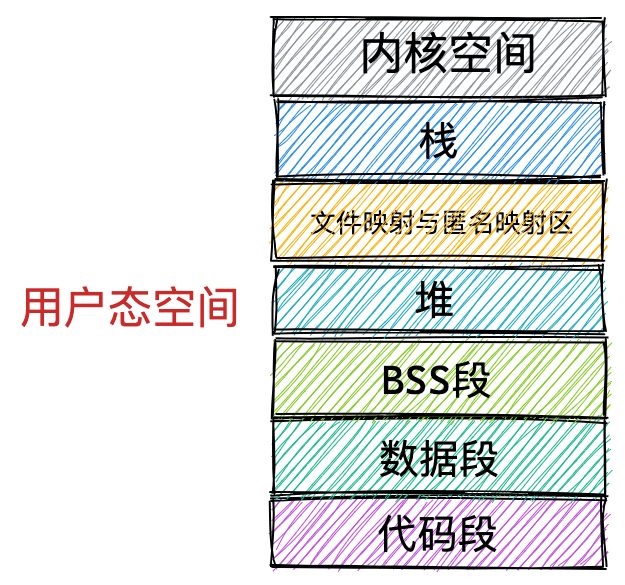
现在进程的虚拟内存空间所包含的主要区域,我就为大家介绍完了,我们看到内核根据进程运行的过程中所需要不同种类的数据而为其开辟了对应的地址空间。分别为:
- 用于存放进程程序二进制文件中的机器指令的代码段
- 用于存放程序二进制文件中定义的全局变量和静态变量的数据段和 BSS 段。
- 用于在程序运行过程中动态申请内存的堆。
- 用于存放动态链接库以及内存映射区域的文件映射与匿名映射区。
- 用于存放函数调用过程中的局部变量和函数参数的栈。
以上就是我们通过一个程序在运行过程中所需要的数据所规划出的虚拟内存空间的分布,这些只是一个大概的规划,那么在真实的 Linux 系统中,进程的虚拟内存空间的具体规划又是如何的呢?我们接着往下看~~
Linux 进程虚拟内存空间
在上小节中我们介绍了进程虚拟内存空间中各个内存区域的一个大概分布,在此基础之上,本小节我就带大家分别从 32 位 和 64 位机器上看下在 Linux 系统中进程虚拟内存空间的真实分布情况。
32 位机器上进程虚拟内存空间分布
在 32 位机器上,指针的寻址范围为 2^32,所能表达的虚拟内存空间为 4 GB。所以在 32 位机器上进程的虚拟内存地址范围为:0x0000 0000 - 0xFFFF FFFF。
其中用户态虚拟内存空间为 3 GB,虚拟内存地址范围为:0x0000 0000 - 0xC000 000 。
内核态虚拟内存空间为 1 GB,虚拟内存地址范围为:0xC000 000 - 0xFFFF FFFF。
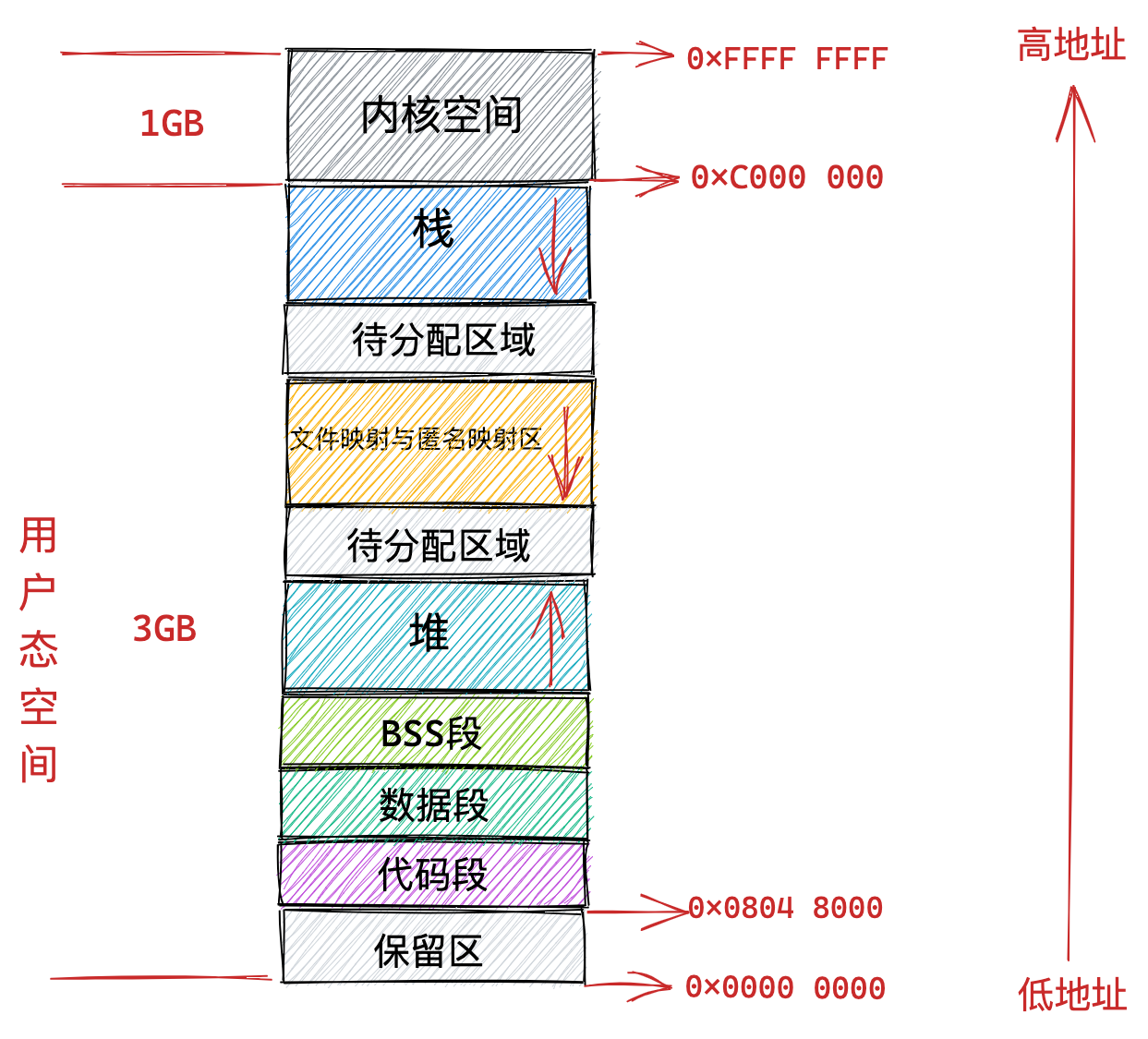
但是用户态虚拟内存空间中的代码段并不是从 0x0000 0000 地址开始的,而是从 0x0804 8000 地址开始。
0x0000 0000 到 0x0804 8000 这段虚拟内存地址是一段不可访问的保留区,因为在大多数操作系统中,数值比较小的地址通常被认为不是一个合法的地址,这块小地址是不允许访问的。比如在 C 语言中我们通常会将一些无效的指针设置为 NULL,指向这块不允许访问的地址。
保留区的上边就是代码段和数据段,它们是从程序的二进制文件中直接加载进内存中的,BSS 段中的数据也存在于二进制文件中,因为内核知道这些数据是没有初值的,所以在二进制文件中只会记录 BSS 段的大小,在加载进内存时会生成一段 0 填充的内存空间。
紧挨着 BSS 段的上边就是我们经常使用到的堆空间,从图中的红色箭头我们可以知道在堆空间中地址的增长方向是从低地址到高地址增长。
内核中使用 start_brk 标识堆的起始位置,brk 标识堆当前的结束位置。当堆申请新的内存空间时,只需要将 brk 指针增加对应的大小,回收地址时减少对应的大小即可。比如当我们通过 malloc 向内核申请很小的一块内存时(128K 之内),就是通过改变 brk 位置实现的。
堆空间的上边是一段待分配区域,用于扩展堆空间的使用。接下来就来到了文件映射与匿名映射区域。进程运行时所依赖的动态链接库中的代码段,数据段,BSS 段就加载在这里。还有我们调用 mmap 映射出来的一段虚拟内存空间也保存在这个区域。注意:在文件映射与匿名映射区的地址增长方向是从高地址向低地址增长。
接下来用户态虚拟内存空间的最后一块区域就是栈空间了,在这里会保存函数运行过程所需要的局部变量以及函数参数等函数调用信息。栈空间中的地址增长方向是从高地址向低地址增长。每次进程申请新的栈地址时,其地址值是在减少的。
在内核中使用 start_stack 标识栈的起始位置,RSP 寄存器中保存栈顶指针 stack pointer,RBP 寄存器中保存的是栈基地址。
在栈空间的下边也有一段待分配区域用于扩展栈空间,在栈空间的上边就是内核空间了,进程虽然可以看到这段内核空间地址,但是就是不能访问。这就好比我们在饭店里虽然可以看到厨房在哪里,但是厨房门上写着 “厨房重地,闲人免进” ,我们就是进不去。
64 位机器上进程虚拟内存空间分布
上小节中介绍的 32 位虚拟内存空间布局和本小节即将要介绍的 64 位虚拟内存空间布局都可以通过 cat /proc/pid/maps 或者 pmap pid 来查看某个进程的实际虚拟内存布局。
我们知道在 32 位机器上,指针的寻址范围为 2^32,所能表达的虚拟内存空间为 4 GB。
那么我们理所应当的会认为在 64 位机器上,指针的寻址范围为 2^64,所能表达的虚拟内存空间为 16 EB 。虚拟内存地址范围为:0x0000 0000 0000 0000 0000 - 0xFFFF FFFF FFFF FFFF 。
好家伙 !!! 16 EB 的内存空间,我都没见过这么大的磁盘,在现实情况中根本不会用到这么大范围的内存空间,
事实上在目前的 64 位系统下只使用了 48 位来描述虚拟内存空间,寻址范围为 2^48 ,所能表达的虚拟内存空间为 256TB。
其中低 128 T 表示用户态虚拟内存空间,虚拟内存地址范围为:0x0000 0000 0000 0000 - 0x0000 7FFF FFFF F000 。
高 128 T 表示内核态虚拟内存空间,虚拟内存地址范围为:0xFFFF 8000 0000 0000 - 0xFFFF FFFF FFFF FFFF 。
这样一来就在用户态虚拟内存空间与内核态虚拟内存空间之间形成了一段 0x0000 7FFF FFFF F000 - 0xFFFF 8000 0000 0000 的地址空洞,我们把这个空洞叫做 canonical address 空洞。
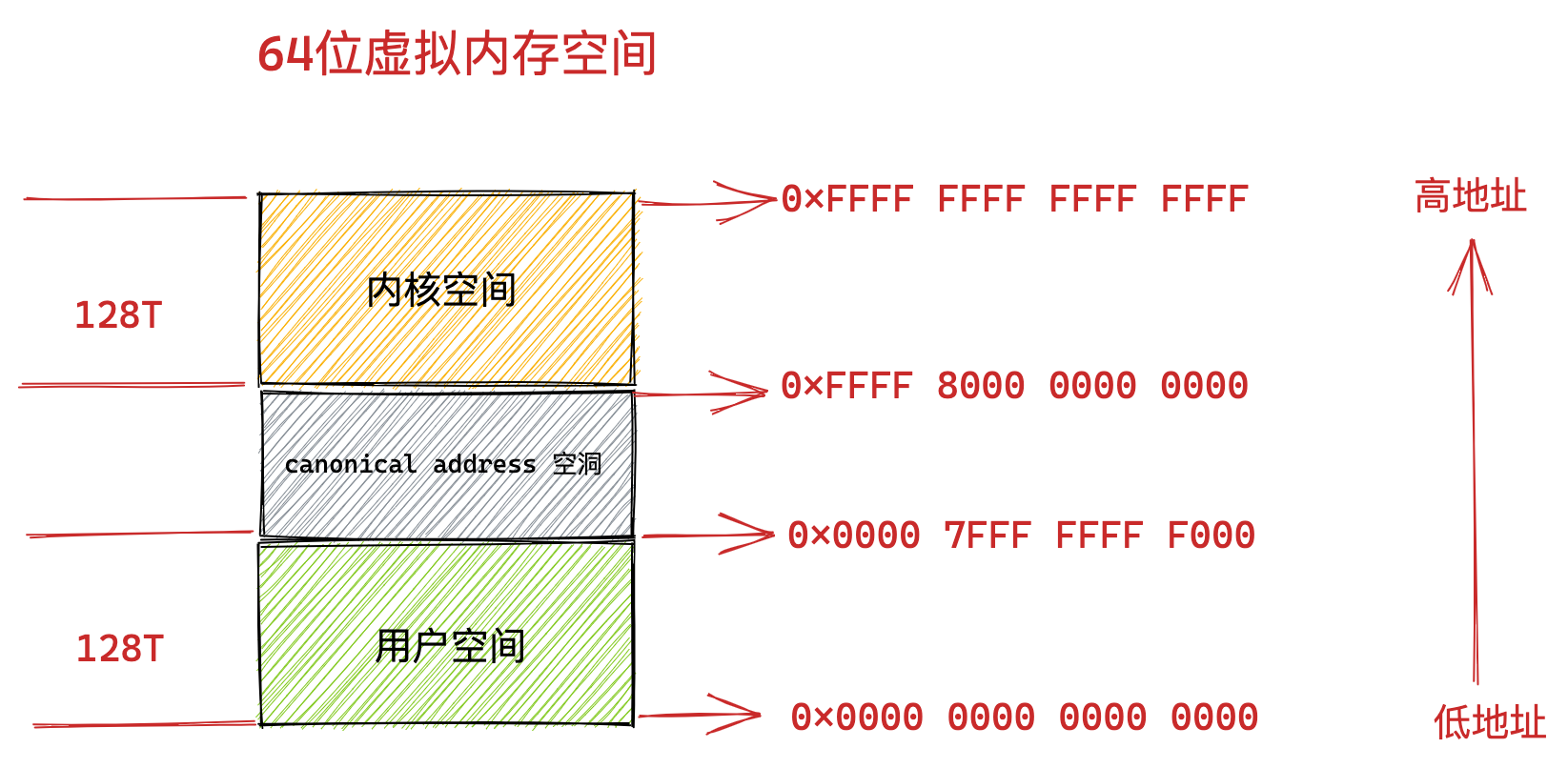
那么这个 canonical address 空洞是如何形成的呢?
我们都知道在 64 位机器上的指针寻址范围为 2^64,但是在实际使用中我们只使用了其中的低 48 位来表示虚拟内存地址,那么这多出的高 16 位就形成了这个地址空洞。
大家注意到在低 128T 的用户态地址空间:0x0000 0000 0000 0000 - 0x0000 7FFF FFFF F000 范围中,所以虚拟内存地址的高 16 位全部为 0 。
如果一个虚拟内存地址的高 16 位全部为 0 ,那么我们就可以直接判断出这是一个用户空间的虚拟内存地址。
同样的道理,在高 128T 的内核态虚拟内存空间:0xFFFF 8000 0000 0000 - 0xFFFF FFFF FFFF FFFF 范围中,所以虚拟内存地址的高 16 位全部为 1 。
也就是说内核态的虚拟内存地址的高 16 位全部为 1 ,如果一个试图访问内核的虚拟地址的高 16 位不全为 1 ,则可以快速判断这个访问是非法的。
这个高 16 位的空闲地址被称为 canonical 。如果虚拟内存地址中的高 16 位全部为 0 (表示用户空间虚拟内存地址)或者全部为 1 (表示内核空间虚拟内存地址),这种地址的形式我们叫做 canonical form,对应的地址我们称作 canonical address 。
那么处于 canonical address 空洞 :0x0000 7FFF FFFF F000 - 0xFFFF 8000 0000 0000 范围内的地址的高 16 位 不全为 0 也不全为 1 。如果某个虚拟地址落在这段 canonical address 空洞区域中,那就是既不在用户空间,也不在内核空间,肯定是非法访问了。
未来我们也可以利用这块 canonical address 空洞,来扩展虚拟内存地址的范围,比如扩展到 56 位。
在我们理解了 canonical address 这个概念之后,我们再来看下 64 位 Linux 系统下的真实虚拟内存空间布局情况:
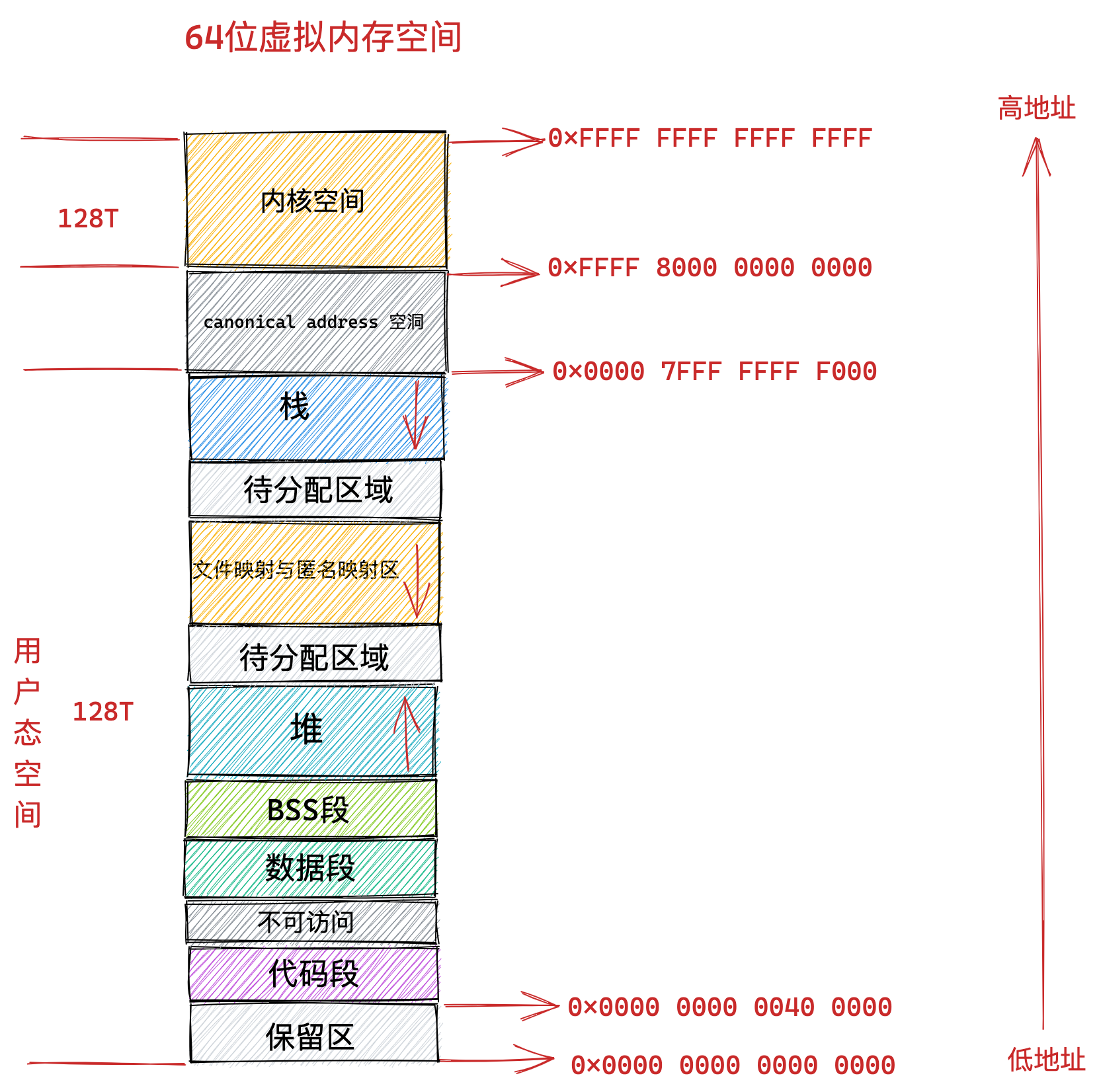
从上图中我们可以看出 64 位系统中的虚拟内存布局和 32 位系统中的虚拟内存布局大体上是差不多的。主要不同的地方有三点:
- 就是前边提到的由高 16 位空闲地址造成的 canonical address 空洞。在这段范围内的虚拟内存地址是不合法的,因为它的高 16 位既不全为 0 也不全为 1,不是一个 canonical address,所以称之为 canonical address 空洞。
- 在代码段跟数据段的中间还有一段不可以读写的保护段,它的作用是防止程序在读写数据段的时候越界访问到代码段,这个保护段可以让越界访问行为直接崩溃,防止它继续往下运行。
- 用户态虚拟内存空间与内核态虚拟内存空间分别占用 128T,其中低128T 分配给用户态虚拟内存空间,高 128T 分配给内核态虚拟内存空间。
进程虚拟内存空间的管理
在上一小节中,我为大家介绍了 Linux 操作系统在 32 位机器上和 64 位机器上进程虚拟内存空间的布局分布,我们发现无论是在 32 位机器上还是在 64 位机器上,进程虚拟内存空间的核心区域分布的相对位置是不变的,它们都包含下图所示的这几个核心内存区域。
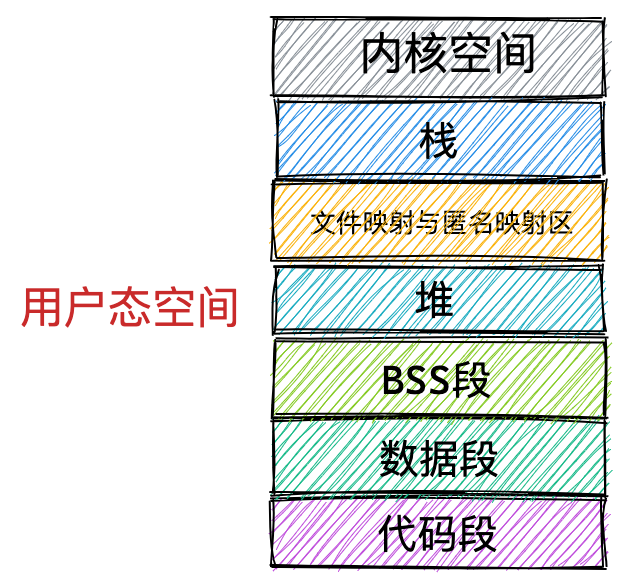
唯一不同的是这些核心内存区域在 32 位机器和 64 位机器上的绝对位置分布会有所不同。
那么在此基础之上,内核如何为进程管理这些虚拟内存区域呢?这将是本小节重点为大家介绍的内容~~
既然我们要介绍进程的虚拟内存空间管理,那就离不开进程在内核中的描述符 task_struct 结构。
|
|
在进程描述符 task_struct 结构中,有一个专门描述进程虚拟地址空间的内存描述符 mm_struct 结构,这个结构体中包含了前边几个小节中介绍的进程虚拟内存空间的全部信息。
每个进程都有唯一的 mm_struct 结构体,也就是前边提到的每个进程的虚拟地址空间都是独立,互不干扰的。
当我们调用 fork() 函数创建进程的时候,表示进程地址空间的 mm_struct 结构会随着进程描述符 task_struct 的创建而创建。
|
|
随后会在 copy_process 函数中创建 task_struct 结构,并拷贝父进程的相关资源到新进程的 task_struct 结构里,其中就包括拷贝父进程的虚拟内存空间 mm_struct 结构。这里可以看出子进程在新创建出来之后它的虚拟内存空间是和父进程的虚拟内存空间一模一样的,直接拷贝过来。
|
|
这里我们重点关注 copy_mm 函数,正是在这里完成了子进程虚拟内存空间 mm_struct 结构的的创建以及初始化。
|
|
由于本小节中我们举的示例是通过 fork() 函数创建子进程的情形,所以这里大家先占时忽略 if (clone_flags & CLONE_VM) 这个条件判断逻辑,我们先跳过往后看~~
copy_mm 函数首先会将父进程的虚拟内存空间 current->mm 赋值给指针 oldmm。然后通过 dup_mm 函数将父进程的虚拟内存空间以及相关页表拷贝到子进程的 mm_struct 结构中。最后将拷贝出来的 mm_struct 赋值给子进程的 task_struct 结构。
通过 fork() 函数创建出的子进程,它的虚拟内存空间以及相关页表相当于父进程虚拟内存空间的一份拷贝,直接从父进程中拷贝到子进程中。
而当我们通过 vfork 或者 clone 系统调用创建出的子进程,首先会设置 CLONE_VM 标识,这样来到 copy_mm 函数中就会进入 if (clone_flags & CLONE_VM) 条件中,在这个分支中会将父进程的虚拟内存空间以及相关页表直接赋值给子进程。这样一来父进程和子进程的虚拟内存空间就变成共享的了。也就是说父子进程之间使用的虚拟内存空间是一样的,并不是一份拷贝。
子进程共享了父进程的虚拟内存空间,这样子进程就变成了我们熟悉的线程,是否共享地址空间几乎是进程和线程之间的本质区别。Linux 内核并不区别对待它们,线程对于内核来说仅仅是一个共享特定资源的进程而已。
内核线程和用户态线程的区别就是内核线程没有相关的内存描述符 mm_struct ,内核线程对应的 task_struct 结构中的 mm 域指向 Null,所以内核线程之间调度是不涉及地址空间切换的。
当一个内核线程被调度时,它会发现自己的虚拟地址空间为 Null,虽然它不会访问用户态的内存,但是它会访问内核内存,聪明的内核会将调度之前的上一个用户态进程的虚拟内存空间 mm_struct 直接赋值给内核线程,因为内核线程不会访问用户空间的内存,它仅仅只会访问内核空间的内存,所以直接复用上一个用户态进程的虚拟地址空间就可以避免为内核线程分配 mm_struct 和相关页表的开销,以及避免内核线程之间调度时地址空间的切换开销。
父进程与子进程的区别,进程与线程的区别,以及内核线程与用户态线程的区别其实都是围绕着这个 mm_struct 展开的。
现在我们知道了表示进程虚拟内存空间的 mm_struct 结构是如何被创建出来的相关背景,那么接下来我就带大家深入 mm_struct 结构内部,来看一下内核如何通过这么一个 mm_struct 结构体来管理进程的虚拟内存空间的。
内核如何划分用户态和内核态虚拟内存空间
通过 《进程虚拟内存空间》小节的介绍我们知道,进程的虚拟内存空间分为两个部分:一部分是用户态虚拟内存空间,另一部分是内核态虚拟内存空间。
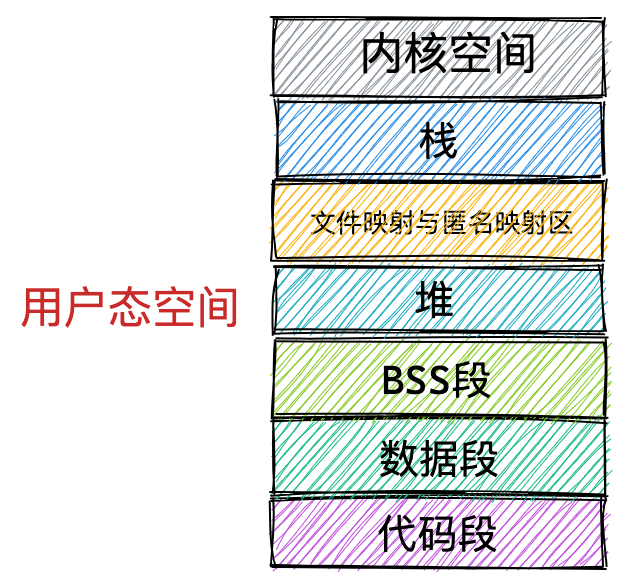
那么用户态的地址空间和内核态的地址空间在内核中是如何被划分的呢?
这就用到了进程的内存描述符 mm_struct 结构体中的 task_size 变量,task_size 定义了用户态地址空间与内核态地址空间之间的分界线。
|
|
通过前边小节的内容介绍,我们知道在 32 位系统中用户态虚拟内存空间为 3 GB,虚拟内存地址范围为:0x0000 0000 - 0xC000 000 。
内核态虚拟内存空间为 1 GB,虚拟内存地址范围为:0xC000 000 - 0xFFFF FFFF。
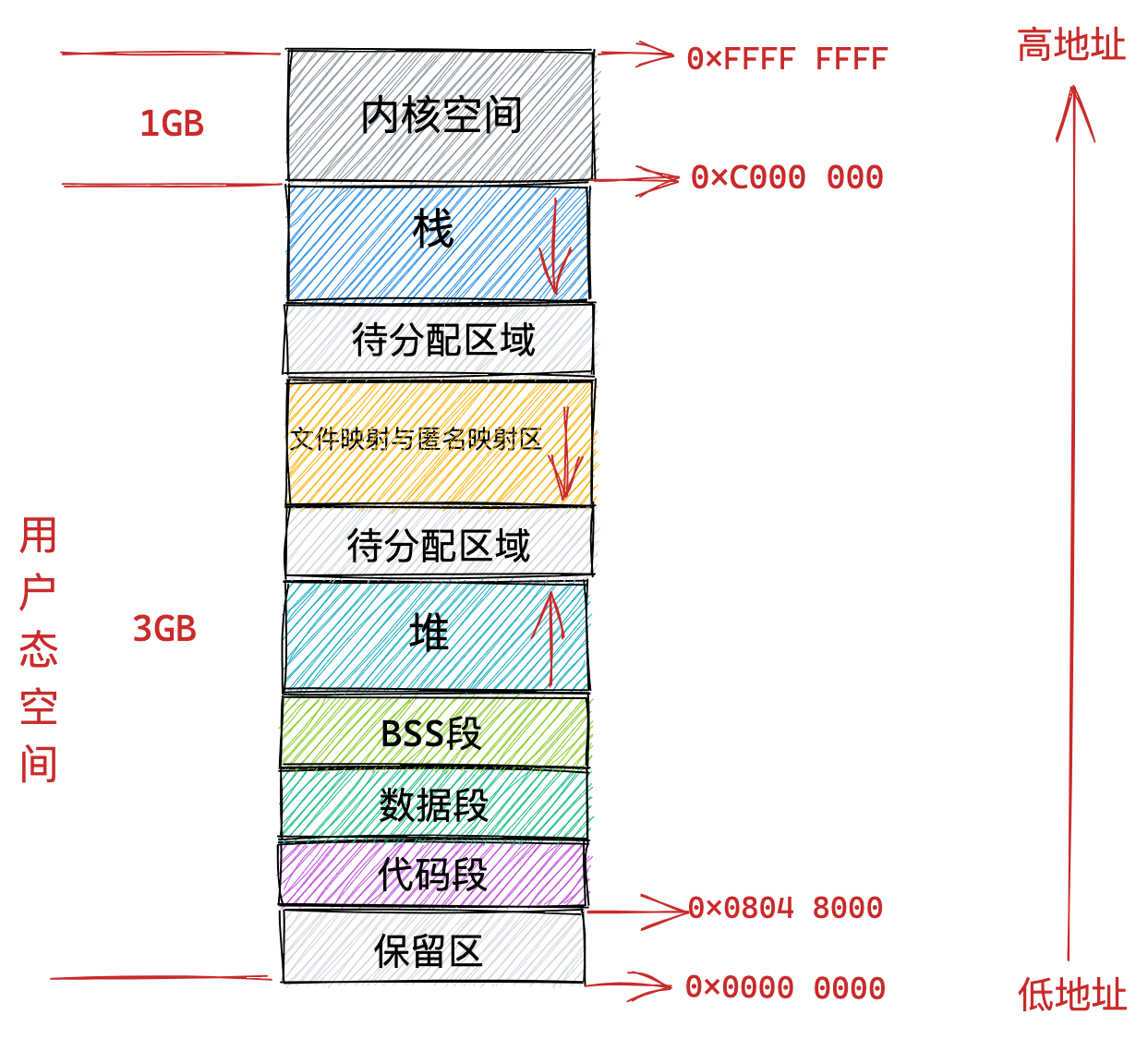
32 位系统中用户地址空间和内核地址空间的分界线在 0xC000 000 地址处,那么自然进程的 mm_struct 结构中的 task_size 为 0xC000 000。
我们来看下内核在 /arch/x86/include/asm/page_32_types.h 文件中关于 TASK_SIZE 的定义。
|
|
如下图所示:__PAGE_OFFSET 的值在 32 位系统下为 0xC000 000。
而在 64 位系统中,只使用了其中的低 48 位来表示虚拟内存地址。其中用户态虚拟内存空间为低 128 T,虚拟内存地址范围为:0x0000 0000 0000 0000 - 0x0000 7FFF FFFF F000 。
内核态虚拟内存空间为高 128 T,虚拟内存地址范围为:0xFFFF 8000 0000 0000 - 0xFFFF FFFF FFFF FFFF 。
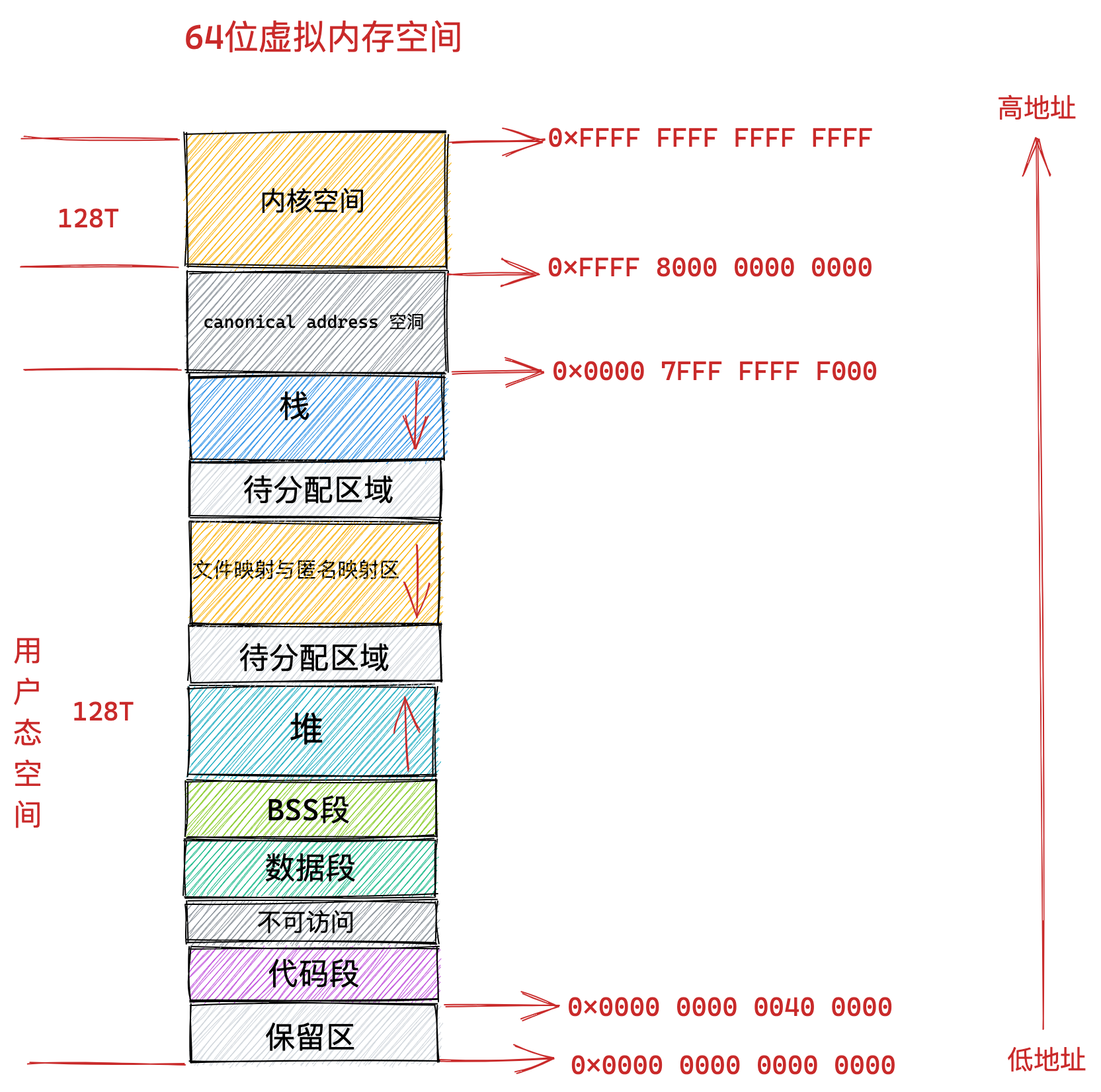
64 位系统中用户地址空间和内核地址空间的分界线在 0x0000 7FFF FFFF F000 地址处,那么自然进程的 mm_struct 结构中的 task_size 为 0x0000 7FFF FFFF F000 。
我们来看下内核在 /arch/x86/include/asm/page_64_types.h 文件中关于 TASK_SIZE 的定义。
|
|
我们来看下在 64 位系统中内核如何来计算 TASK_SIZE,在 task_size_max() 的计算逻辑中 1 左移 47 位得到的地址是 0x0000800000000000,然后减去一个 PAGE_SIZE (默认为 4K),就是 0x00007FFFFFFFF000,共 128T。所以在 64 位系统中的 TASK_SIZE 为 0x00007FFFFFFFF000 。
这里我们可以看出,64 位虚拟内存空间的布局是和物理内存页 page 的大小有关的,物理内存页 page 默认大小 PAGE_SIZE 为 4K。
PAGE_SIZE 定义在 /arch/x86/include/asm/page_types.h文件中:
|
|
而内核空间的起始地址是 0xFFFF 8000 0000 0000 。在 0x00007FFFFFFFF000 - 0xFFFF 8000 0000 0000 之间的内存区域就是我们在 《4.2 64 位机器上进程虚拟内存空间分布》小节中介绍的 canonical address 空洞。
内核如何布局进程虚拟内存空间
在我们理解了内核是如何划分进程虚拟内存空间和内核虚拟内存空间之后,那么在 《进程虚拟内存空间》小节中介绍的那些虚拟内存区域在内核中又是如何划分的呢?
接下来我就为大家介绍下内核是如何划分进程虚拟内存空间中的这些内存区域的,本小节的示例图中,我只保留了进程虚拟内存空间中的核心区域,方便大家理解。
前边我们提到,内核中采用了一个叫做内存描述符的 mm_struct 结构体来表示进程虚拟内存空间的全部信息。在本小节中我就带大家到 mm_struct 结构体内部去寻找下相关的线索。
|
|
内核中用 mm_struct 结构体中的上述属性来定义上图中虚拟内存空间里的不同内存区域。
start_code 和 end_code 定义代码段的起始和结束位置,程序编译后的二进制文件中的机器码被加载进内存之后就存放在这里。
start_data 和 end_data 定义数据段的起始和结束位置,二进制文件中存放的全局变量和静态变量被加载进内存中就存放在这里。
后面紧挨着的是 BSS 段,用于存放未被初始化的全局变量和静态变量,这些变量在加载进内存时会生成一段 0 填充的内存区域 (BSS 段), BSS 段的大小是固定的,
下面就是 OS 堆了,在堆中内存地址的增长方向是由低地址向高地址增长, start_brk 定义堆的起始位置,brk 定义堆当前的结束位置。
我们使用 malloc 申请小块内存时(低于 128K),就是通过改变 brk 位置调整堆大小实现的。
接下来就是内存映射区,在内存映射区内存地址的增长方向是由高地址向低地址增长,mmap_base 定义内存映射区的起始地址。进程运行时所依赖的动态链接库中的代码段,数据段,BSS 段以及我们调用 mmap 映射出来的一段虚拟内存空间就保存在这个区域。
start_stack 是栈的起始位置在 RBP 寄存器中存储,栈的结束位置也就是栈顶指针 stack pointer 在 RSP 寄存器中存储。在栈中内存地址的增长方向也是由高地址向低地址增长。
arg_start 和 arg_end 是参数列表的位置, env_start 和 env_end 是环境变量的位置。它们都位于栈中的最高地址处。
在 mm_struct 结构体中除了上述用于划分虚拟内存区域的变量之外,还定义了一些虚拟内存与物理内存映射内容相关的统计变量,操作系统会把物理内存划分成一页一页的区域来进行管理,所以物理内存到虚拟内存之间的映射也是按照页为单位进行的。这部分内容我会在后续的文章中详细介绍,大家这里只需要有个概念就行。
mm_struct 结构体中的 total_vm 表示在进程虚拟内存空间中总共与物理内存映射的页的总数。
注意映射这个概念,它表示只是将虚拟内存与物理内存建立关联关系,并不代表真正的分配物理内存。
当内存吃紧的时候,有些页可以换出到硬盘上,而有些页因为比较重要,不能换出。locked_vm 就是被锁定不能换出的内存页总数,pinned_vm 表示既不能换出,也不能移动的内存页总数。
data_vm 表示数据段中映射的内存页数目,exec_vm 是代码段中存放可执行文件的内存页数目,stack_vm 是栈中所映射的内存页数目,这些变量均是表示进程虚拟内存空间中的虚拟内存使用情况。
现在关于内核如何对进程虚拟内存空间进行布局的内容我们已经清楚了,那么布局之后划分出的这些虚拟内存区域在内核中又是如何被管理的呢?我们接着往下看~~~
内核如何管理虚拟内存区域
在上小节的介绍中,我们知道内核是通过一个 mm_struct 结构的内存描述符来表示进程的虚拟内存空间的,并通过 task_size 域来划分用户态虚拟内存空间和内核态虚拟内存空间。
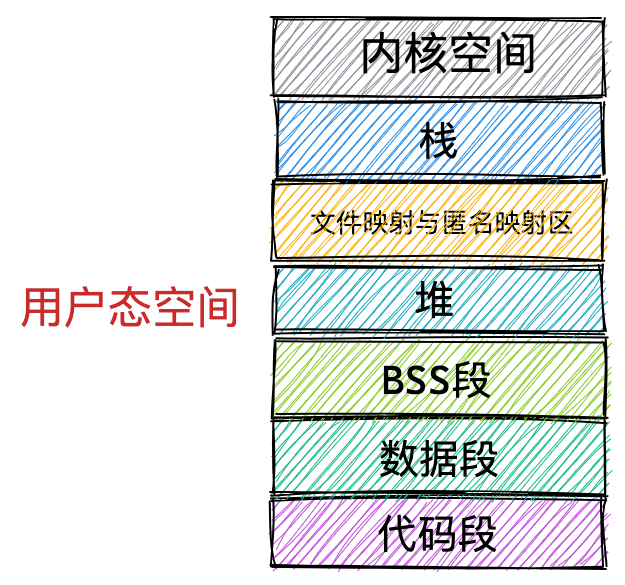
而在划分出的这些虚拟内存空间中如上图所示,里边又包含了许多特定的虚拟内存区域,比如:代码段,数据段,堆,内存映射区,栈。那么这些虚拟内存区域在内核中又是如何表示的呢?
本小节中,我将为大家介绍一个新的结构体 vm_area_struct,正是这个结构体描述了这些虚拟内存区域 VMA(virtual memory area)。
|
|
每个 vm_area_struct 结构对应于虚拟内存空间中的唯一虚拟内存区域 VMA,vm_start 指向了这块虚拟内存区域的起始地址(最低地址),vm_start 本身包含在这块虚拟内存区域内。vm_end 指向了这块虚拟内存区域的结束地址(最高地址),而 vm_end 本身包含在这块虚拟内存区域之外,所以 vm_area_struct 结构描述的是 [vm_start,vm_end) 这样一段左闭右开的虚拟内存区域。
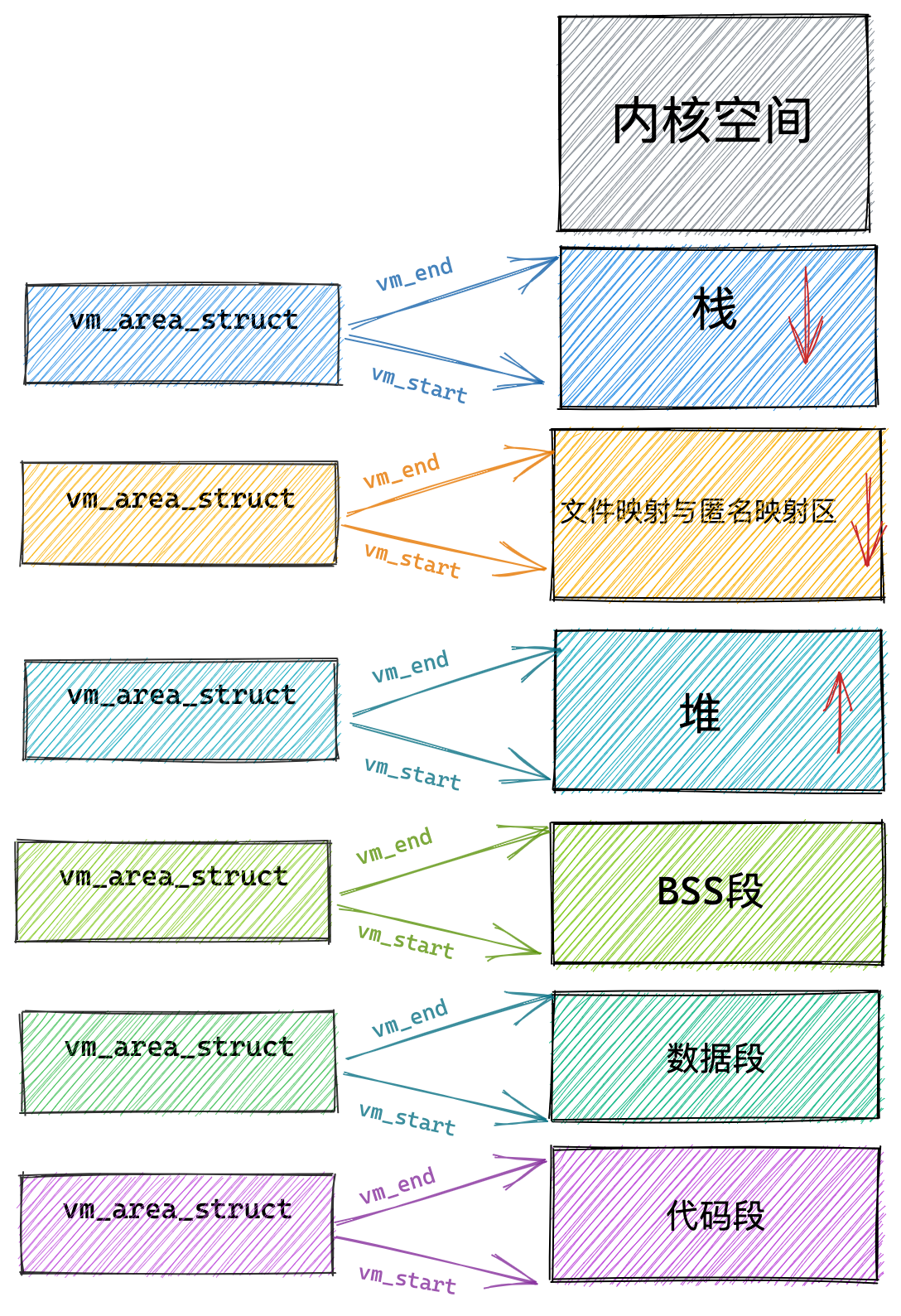
定义虚拟内存区域的访问权限和行为规范
vm_page_prot 和 vm_flags 都是用来标记 vm_area_struct 结构表示的这块虚拟内存区域的访问权限和行为规范。
上边小节中我们也提到,内核会将整块物理内存划分为一页一页大小的区域,以页为单位来管理这些物理内存,每页大小默认 4K 。而虚拟内存最终也是要和物理内存一一映射起来的,所以在虚拟内存空间中也有虚拟页的概念与之对应,虚拟内存中的虚拟页映射到物理内存中的物理页。无论是在虚拟内存空间中还是在物理内存中,内核管理内存的最小单位都是页。
vm_page_prot 偏向于定义底层内存管理架构中页这一级别的访问控制权限,它可以直接应用在底层页表中,它是一个具体的概念。
页表用于管理虚拟内存到物理内存之间的映射关系,这部分内容我后续会详细讲解,这里大家有个初步的概念就行。
虚拟内存区域 VMA 由许多的虚拟页 (page) 组成,每个虚拟页需要经过页表的转换才能找到对应的物理页面。页表中关于内存页的访问权限就是由 vm_page_prot 决定的。
vm_flags 则偏向于定于整个虚拟内存区域的访问权限以及行为规范。描述的是虚拟内存区域中的整体信息,而不是虚拟内存区域中具体的某个独立页面。它是一个抽象的概念。可以通过 vma->vm_page_prot = vm_get_page_prot(vma->vm_flags) 实现到具体页面访问权限 vm_page_prot 的转换。
下面我列举一些常用到的 vm_flags 方便大家有一个直观的感受:
| vm_flags | 访问权限 |
|---|---|
| VM_READ | 可读 |
| VM_WRITE | 可写 |
| VM_EXEC | 可执行 |
| VM_SHARD | 可多进程之间共享 |
| VM_IO | 可映射至设备 IO 空间 |
| VM_RESERVED | 内存区域不可被换出 |
| VM_SEQ_READ | 内存区域可能被顺序访问 |
| VM_RAND_READ | 内存区域可能被随机访问 |
VM_READ,VM_WRITE,VM_EXEC 定义了虚拟内存区域是否可以被读取,写入,执行等权限。
比如代码段这块内存区域的权限是可读,可执行,但是不可写。数据段具有可读可写的权限但是不可执行。堆则具有可读可写,可执行的权限(Java 中的字节码存储在堆中,所以需要可执行权限),栈一般是可读可写的权限,一般很少有可执行权限。而文件映射与匿名映射区存放了共享链接库,所以也需要可执行的权限。
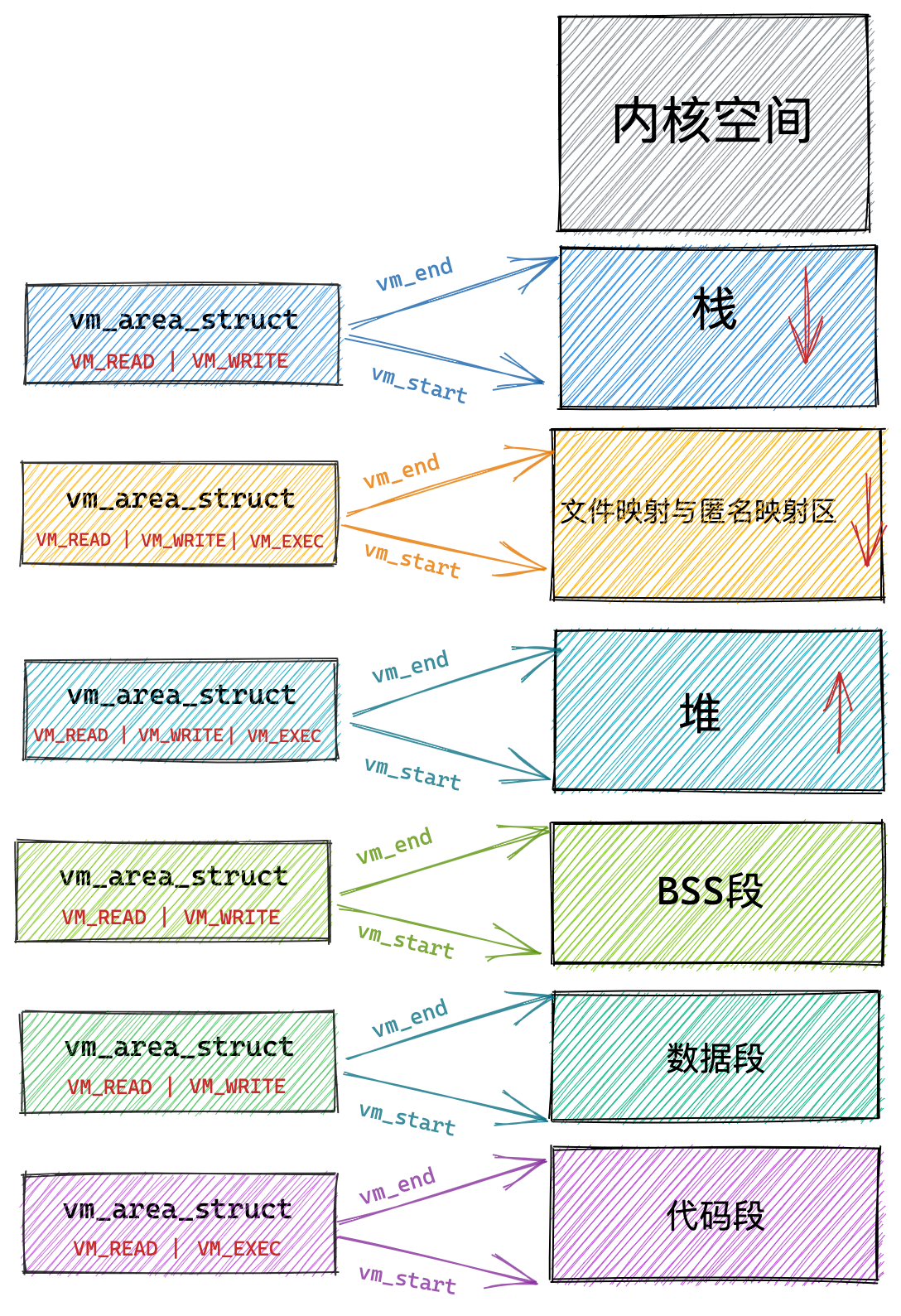
VM_SHARD 用于指定这块虚拟内存区域映射的物理内存是否可以在多进程之间共享,以便完成进程间通讯。
设置这个值即为 mmap 的共享映射,不设置的话则为私有映射。这个等后面我们讲到 mmap 的相关实现时还会再次提起。
VM_IO 的设置表示这块虚拟内存区域可以映射至设备 IO 空间中。通常在设备驱动程序执行 mmap 进行 IO 空间映射时才会被设置。
VM_RESERVED 的设置表示在内存紧张的时候,这块虚拟内存区域非常重要,不能被换出到磁盘中。
VM_SEQ_READ 的设置用来暗示内核,应用程序对这块虚拟内存区域的读取是会采用顺序读的方式进行,内核会根据实际情况决定预读后续的内存页数,以便加快下次顺序访问速度。
VM_RAND_READ 的设置会暗示内核,应用程序会对这块虚拟内存区域进行随机读取,内核则会根据实际情况减少预读的内存页数甚至停止预读。
我们可以通过 posix_fadvise,madvise 系统调用来暗示内核是否对相关内存区域进行顺序读取或者随机读取。相关的详细内容,大家可以看下我上篇文章 《从 Linux 内核角度探秘 JDK NIO 文件读写本质》 (opens new window)中的第 9 小节文件页预读部分。
通过这一系列的介绍,我们可以看到 vm_flags 就是定义整个虚拟内存区域的访问权限以及行为规范,而内存区域中内存的最小单位为页(4K),虚拟内存区域中包含了很多这样的虚拟页,对于虚拟内存区域 VMA 设置的访问权限也会全部复制到区域中包含的内存页中。
关联内存映射中的映射关系
接下来的三个属性 anon_vma,vm_file,vm_pgoff 分别和虚拟内存映射相关,虚拟内存区域可以映射到物理内存上,也可以映射到文件中,映射到物理内存上我们称之为匿名映射,映射到文件中我们称之为文件映射。
那么这个映射关系在内核中该如何表示呢?这就用到了 vm_area_struct 结构体中的上述三个属性。
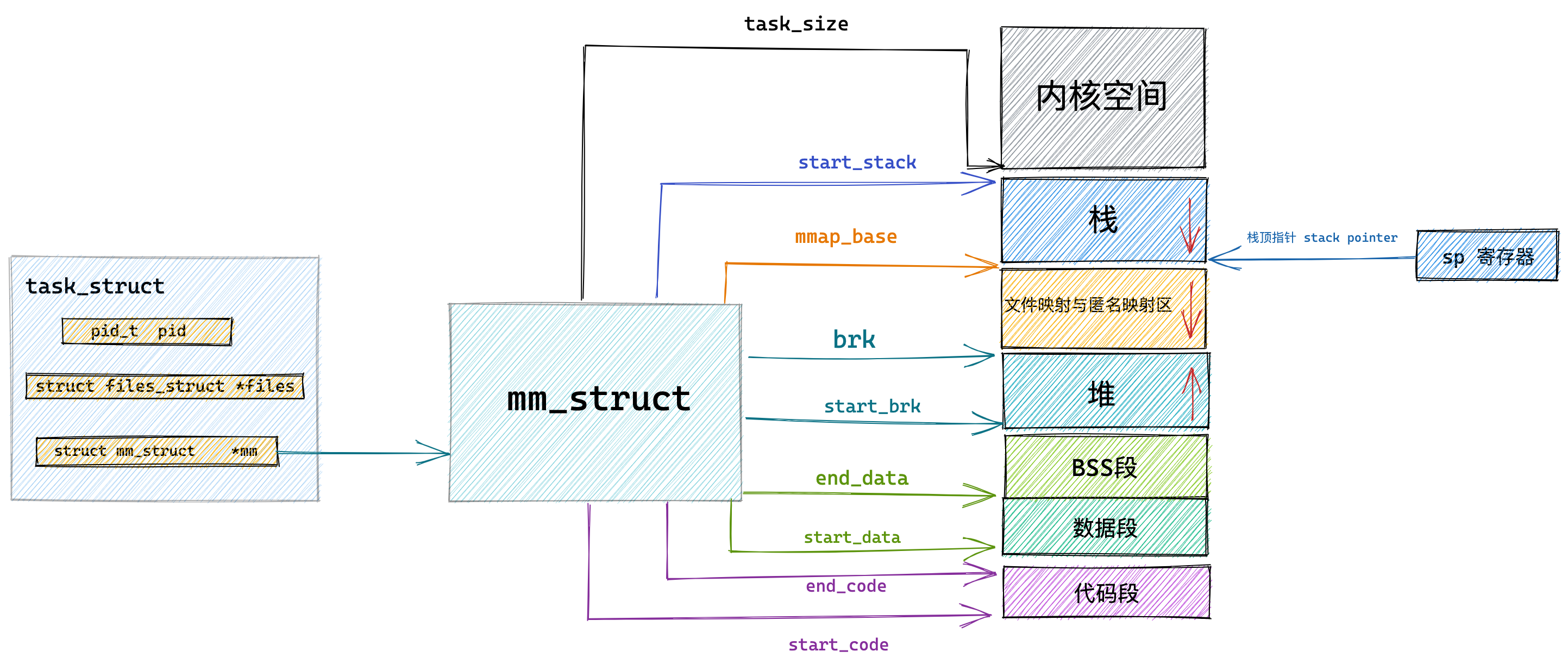
当我们调用 malloc 申请内存时,如果申请的是小块内存(低于 128K)则会使用 do_brk() 系统调用通过调整堆中的 brk 指针大小来增加或者回收堆内存。
如果申请的是比较大块的内存(超过 128K)时,则会调用 mmap 在上图虚拟内存空间中的文件映射与匿名映射区创建出一块 VMA 内存区域(这里是匿名映射)。这块匿名映射区域就用 struct anon_vma 结构表示。
当调用 mmap 进行文件映射时,vm_file 属性就用来关联被映射的文件。这样一来虚拟内存区域就与映射文件关联了起来。vm_pgoff 则表示映射进虚拟内存中的文件内容,在文件中的偏移。
当然在匿名映射中,vm_area_struct 结构中的 vm_file 就为 null,vm_pgoff 也就没有了意义。
vm_private_data 则用于存储 VMA 中的私有数据。具体的存储内容和内存映射的类型有关,我们暂不展开论述。
针对虚拟内存区域的相关操作
struct vm_area_struct 结构中还有一个 vm_ops 用来指向针对虚拟内存区域 VMA 的相关操作的函数指针。
|
|
- 当指定的虚拟内存区域被加入到进程虚拟内存空间中时,open 函数会被调用
- 当虚拟内存区域 VMA 从进程虚拟内存空间中被删除时,close 函数会被调用
- 当进程访问虚拟内存时,访问的页面不在物理内存中,可能是未分配物理内存也可能是被置换到磁盘中,这时就会产生缺页异常,fault 函数就会被调用。
- 当一个只读的页面将要变为可写时,page_mkwrite 函数会被调用。
struct vm_operations_struct 结构中定义的都是对虚拟内存区域 VMA 的相关操作函数指针。
内核中这种类似的用法其实有很多,在内核中每个特定领域的描述符都会定义相关的操作。比如在前边的文章 《从 Linux 内核角度探秘 JDK NIO 文件读写本质》 (opens new window)中我们介绍到内核中的文件描述符 struct file 中定义的 struct file_operations *f_op。里面定义了内核针对文件操作的函数指针,具体的实现根据不同的文件类型有所不同。
针对 Socket 文件类型,这里的 file_operations 指向的是 socket_file_ops。
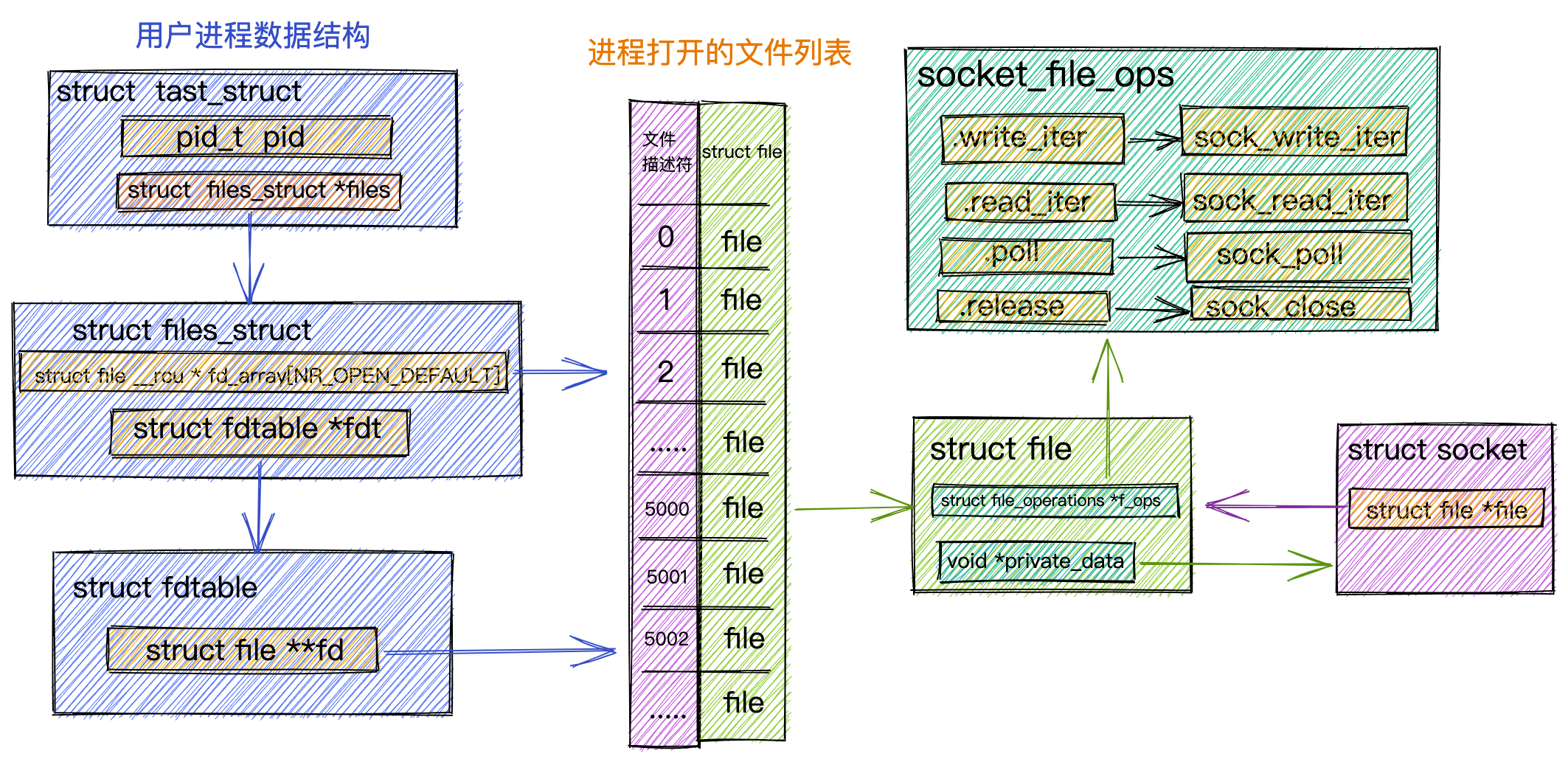
在 ext4 文件系统中管理的文件对应的 file_operations 指向 ext4_file_operations,专门用于操作 ext4 文件系统中的文件。还有针对 page cache 页高速缓存相关操作定义的 address_space_operations 。
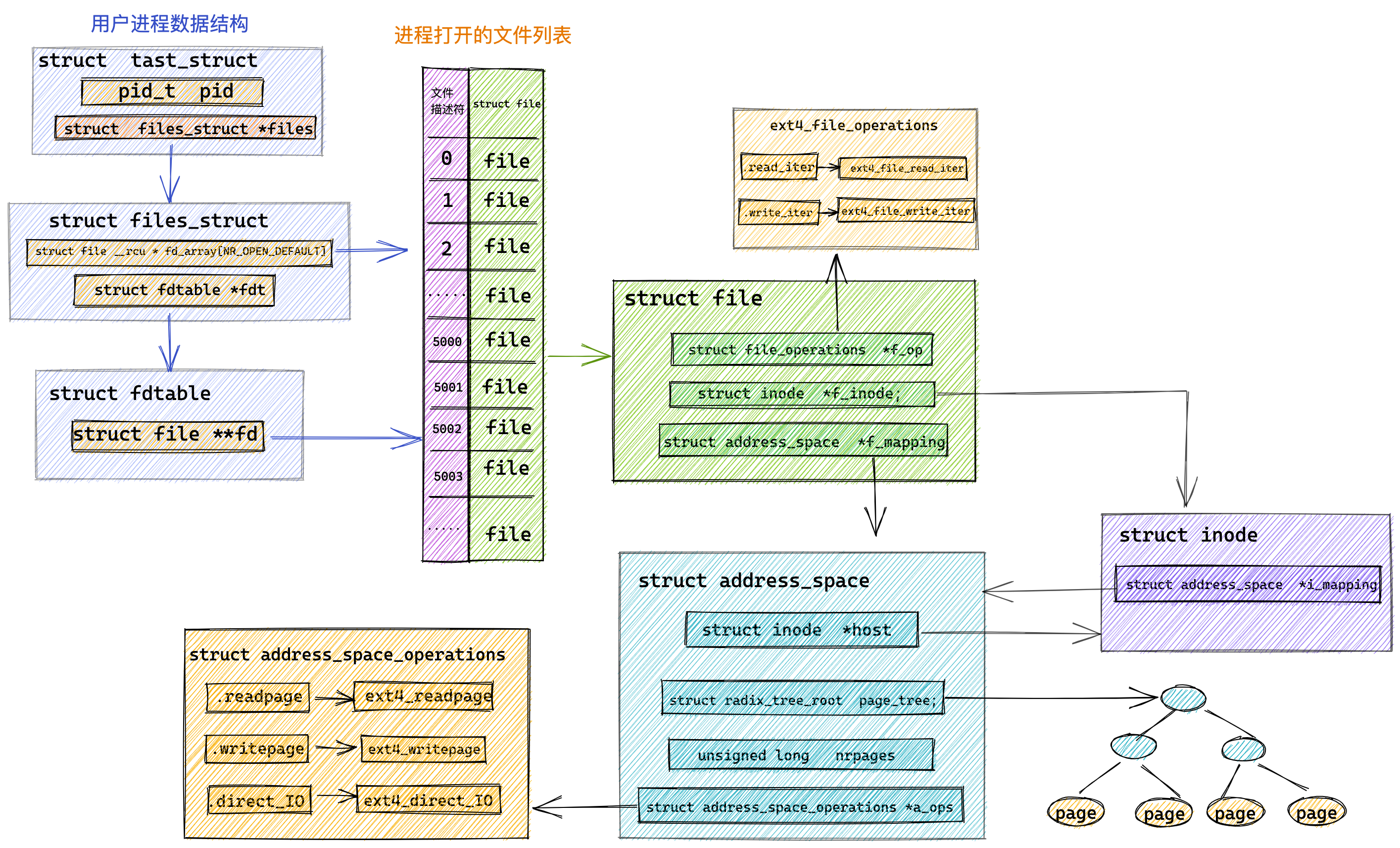
还有我们在 《从 Linux 内核角度看 IO 模型的演变》 (opens new window)一文中介绍到,socket 相关的操作接口定义在 inet_stream_ops 函数集合中,负责对上层用户提供接口。而 socket 与内核协议栈之间的操作接口定义在 struct sock 中的 sk_prot 指针上,这里指向 tcp_prot 协议操作函数集合。
对 socket 发起的系统 IO 调用时,在内核中首先会调用 socket 的文件结构 struct file 中的 file_operations 文件操作集合,然后调用 struct socket 中的 ops 指向的 inet_stream_opssocket 操作函数,最终调用到 struct sock 中 sk_prot 指针指向的 tcp_prot 内核协议栈操作函数接口集合。
虚拟内存区域在内核中是如何被组织的
在上一小节中,我们介绍了内核中用来表示虚拟内存区域 VMA 的结构体 struct vm_area_struct ,并详细为大家剖析了 struct vm_area_struct 中的一些重要的关键属性。
现在我们已经熟悉了这些虚拟内存区域,那么接下来的问题就是在内核中这些虚拟内存区域是如何被组织的呢?
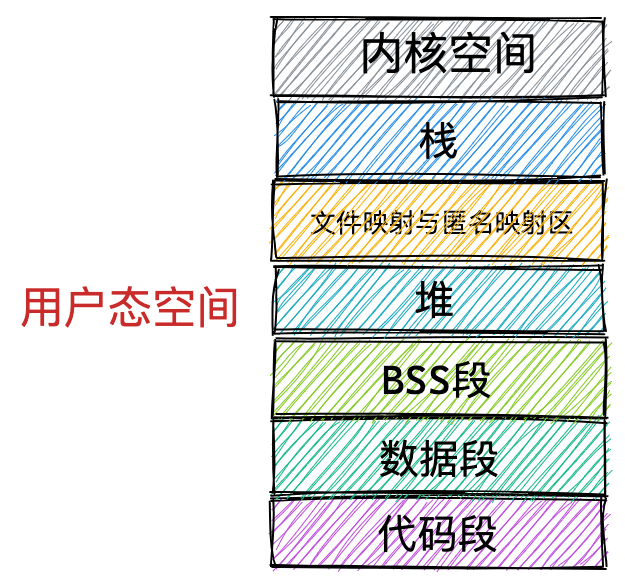
我们继续来到 struct vm_area_struct 结构中,来看一下与组织结构相关的一些属性:
|
|
在内核中其实是通过一个 struct vm_area_struct 结构的双向链表将虚拟内存空间中的这些虚拟内存区域 VMA 串联起来的。
vm_area_struct 结构中的 vm_next ,vm_prev 指针分别指向 VMA 节点所在双向链表中的后继节点和前驱节点,内核中的这个 VMA 双向链表是有顺序的,所有 VMA 节点按照低地址到高地址的增长方向排序。
双向链表中的最后一个 VMA 节点的 vm_next 指针指向 NULL,双向链表的头指针存储在内存描述符 struct mm_struct 结构中的 mmap 中,正是这个 mmap 串联起了整个虚拟内存空间中的虚拟内存区域。
|
|
在每个虚拟内存区域 VMA 中又通过 struct vm_area_struct 中的 vm_mm 指针指向了所属的虚拟内存空间 mm_struct。
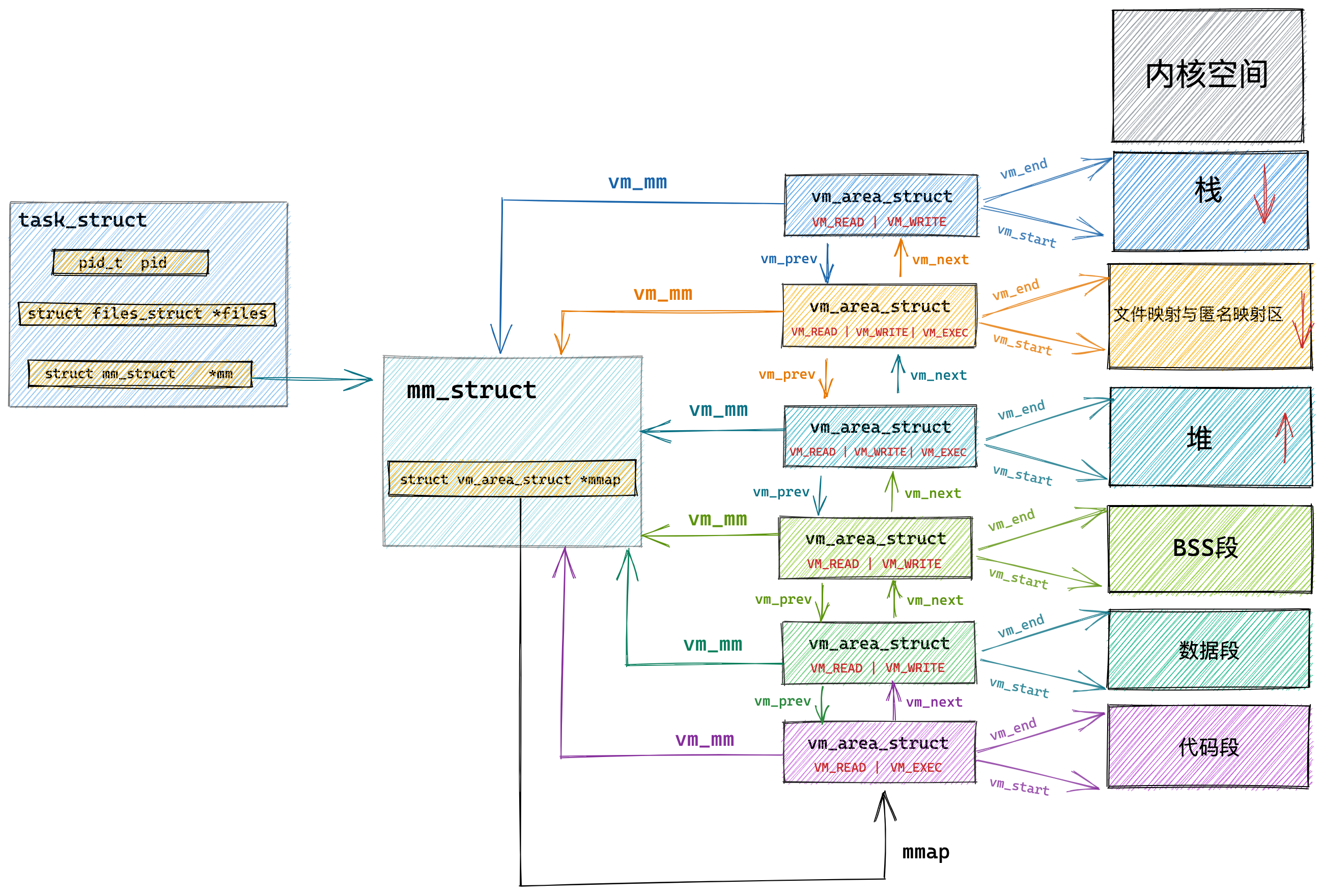
我们可以通过 cat /proc/pid/maps 或者 pmap pid 查看进程的虚拟内存空间布局以及其中包含的所有内存区域。这两个命令背后的实现原理就是通过遍历内核中的这个 vm_area_struct 双向链表获取的。
内核中关于这些虚拟内存区域的操作除了遍历之外还有许多需要根据特定虚拟内存地址在虚拟内存空间中查找特定的虚拟内存区域。
尤其在进程虚拟内存空间中包含的内存区域 VMA 比较多的情况下,使用红黑树查找特定虚拟内存区域的时间复杂度是 O( logN ) ,可以显著减少查找所需的时间。
所以在内核中,同样的内存区域 vm_area_struct 会有两种组织形式,一种是双向链表用于高效的遍历,另一种就是红黑树用于高效的查找。
每个 VMA 区域都是红黑树中的一个节点,通过 struct vm_area_struct 结构中的 vm_rb 将自己连接到红黑树中。
而红黑树中的根节点存储在内存描述符 struct mm_struct 中的 mm_rb 中:
|
|
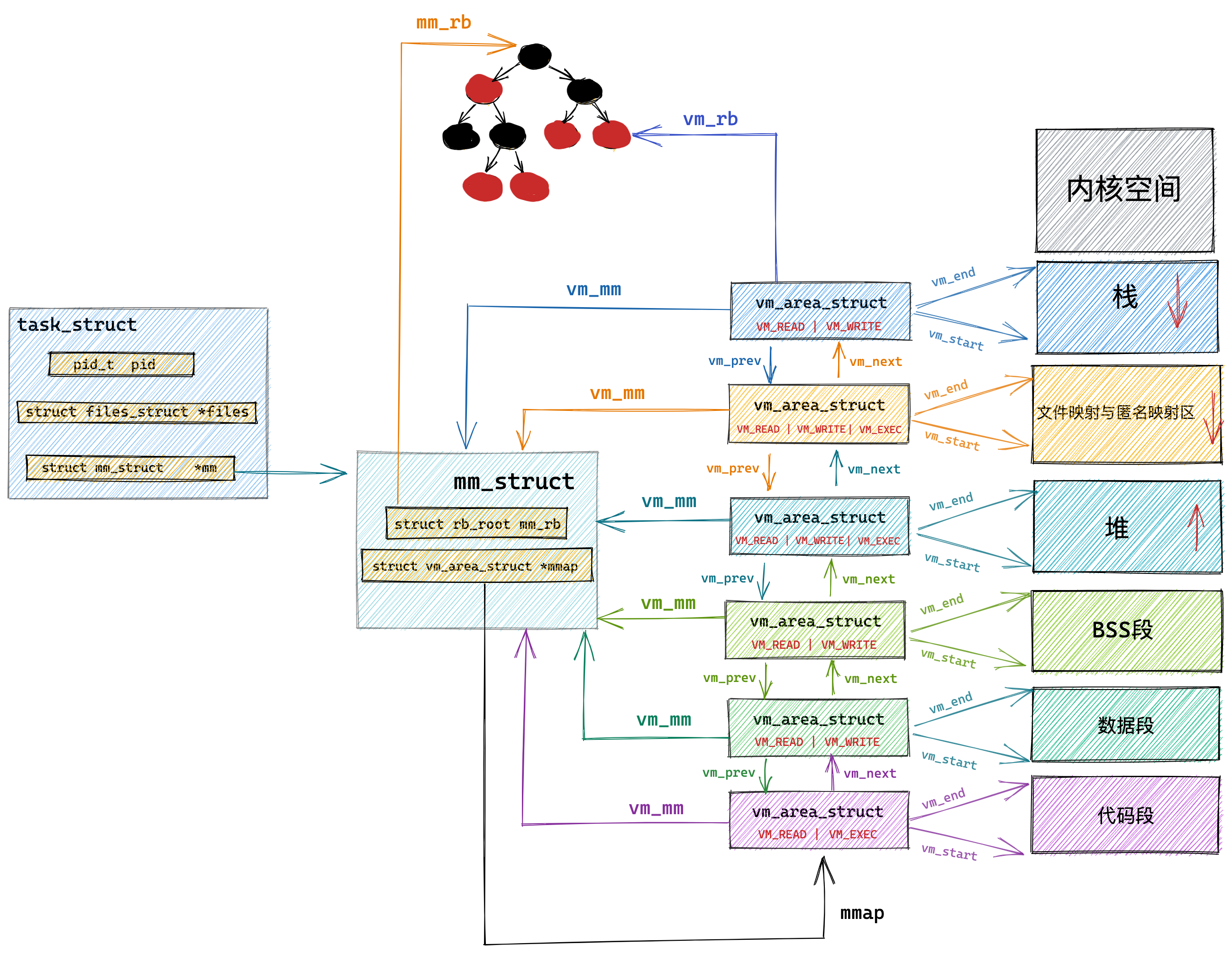
程序编译后的二进制文件如何映射到虚拟内存空间中
经过前边这么多小节的内容介绍,现在我们已经熟悉了进程虚拟内存空间的布局,以及内核如何管理这些虚拟内存区域,并对进程的虚拟内存空间有了一个完整全面的认识。
现在我们再来回到最初的起点,进程的虚拟内存空间 mm_struct 以及这些虚拟内存区域 vm_area_struct 是如何被创建并初始化的呢?
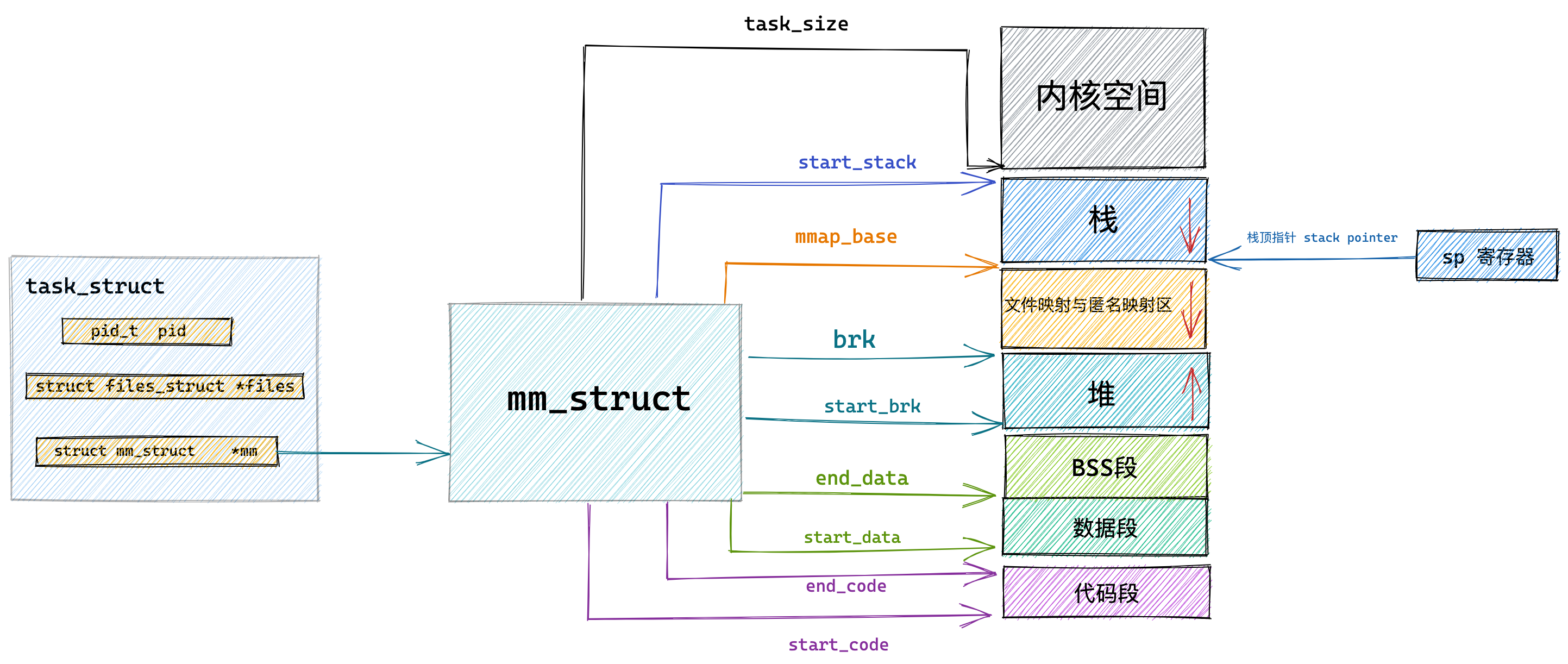
在 《3. 进程虚拟内存空间》小节中,我们介绍进程的虚拟内存空间时提到,我们写的程序代码编译之后会生成一个 ELF 格式的二进制文件,这个二进制文件中包含了程序运行时所需要的元信息,比如程序的机器码,程序中的全局变量以及静态变量等。
这个 ELF 格式的二进制文件中的布局和我们前边讲的虚拟内存空间中的布局类似,也是一段一段的,每一段包含了不同的元数据。
磁盘文件中的段我们叫做 Section,内存中的段我们叫做 Segment,也就是内存区域。
磁盘文件中的这些 Section 会在进程运行之前加载到内存中并映射到内存中的 Segment。通常是多个 Section 映射到一个 Segment。
比如磁盘文件中的 .text,.rodata 等一些只读的 Section,会被映射到内存的一个只读可执行的 Segment 里(代码段)。而 .data,.bss 等一些可读写的 Section,则会被映射到内存的一个具有读写权限的 Segment 里(数据段,BSS 段)。
那么这些 ELF 格式的二进制文件中的 Section 是如何加载并映射进虚拟内存空间的呢?
内核中完成这个映射过程的函数是 load_elf_binary ,这个函数的作用很大,加载内核的是它,启动第一个用户态进程 init 的是它,fork 完了以后,调用 exec 运行一个二进制程序的也是它。当 exec 运行一个二进制程序的时候,除了解析 ELF 的格式之外,另外一个重要的事情就是建立上述提到的内存映射。
|
|
- setup_new_exec 设置虚拟内存空间中的内存映射区域起始地址 mmap_base
- setup_arg_pages 创建并初始化栈对应的 vm_area_struct 结构。置 mm->start_stack 就是栈的起始地址也就是栈底,并将 mm->arg_start 是指向栈底的。
- elf_map 将 ELF 格式的二进制文件中.text ,.data,.bss 部分映射到虚拟内存空间中的代码段,数据段,BSS 段中。
- set_brk 创建并初始化堆对应的的 vm_area_struct 结构,设置
current->mm->start_brk = current->mm->brk,设置堆的起始地址 start_brk,结束地址 brk。 起初两者相等表示堆是空的。 - load_elf_interp 将进程依赖的动态链接库 .so 文件映射到虚拟内存空间中的内存映射区域
- 初始化内存描述符 mm_struct
内核虚拟内存空间
现在我们已经知道了进程虚拟内存空间在内核中的布局以及管理,那么内核态的虚拟内存空间又是什么样子的呢?本小节我就带大家来一层一层地拆开这个黑盒子。
之前在介绍进程虚拟内存空间的时候,我提到不同进程之间的虚拟内存空间是相互隔离的,彼此之间相互独立,相互感知不到其他进程的存在。使得进程以为自己拥有所有的内存资源。
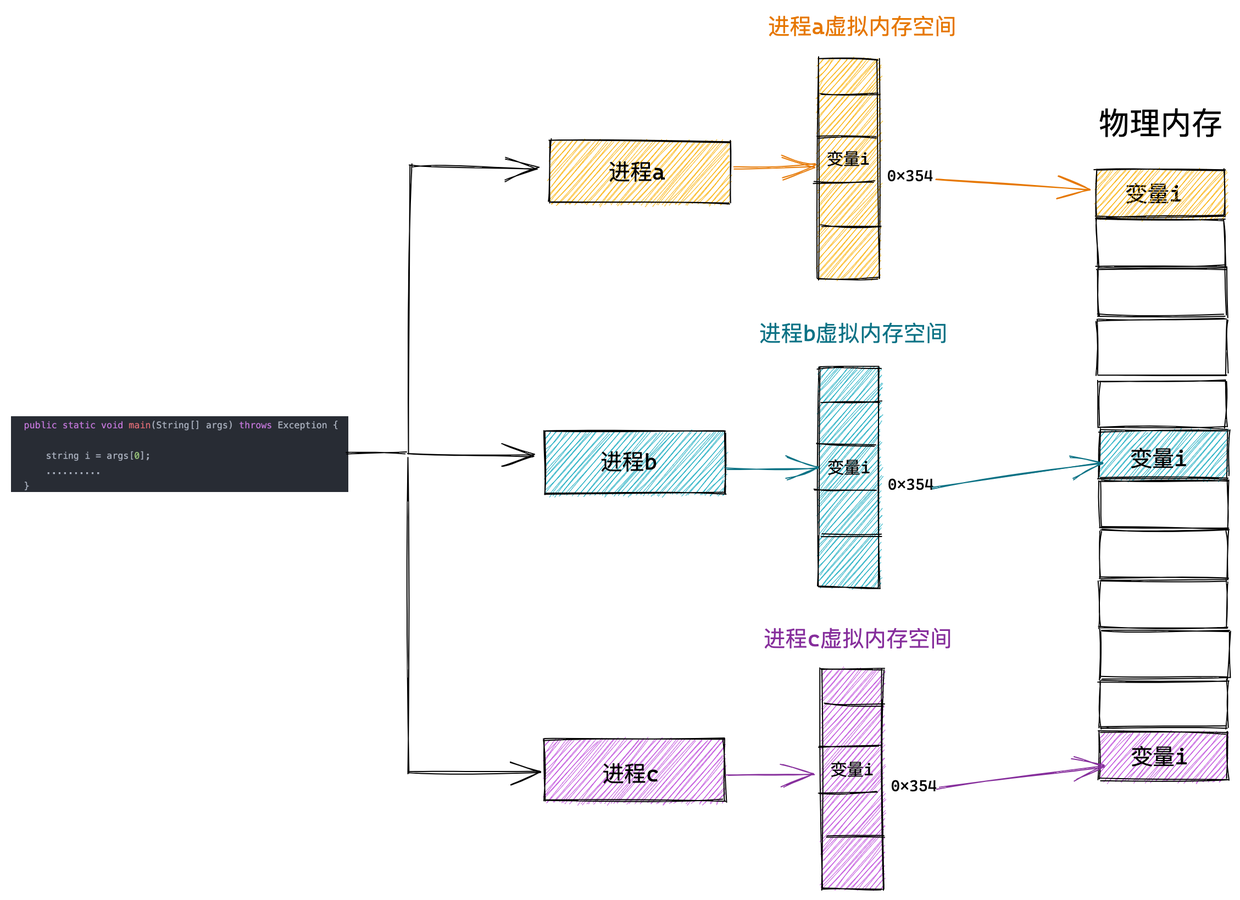
而内核态虚拟内存空间是所有进程共享的,不同进程进入内核态之后看到的虚拟内存空间全部是一样的。
什么意思呢?比如上图中的进程 a,进程 b,进程 c 分别在各自的用户态虚拟内存空间中访问虚拟地址 x 。由于进程之间的用户态虚拟内存空间是相互隔离相互独立的,虽然在进程a,进程b,进程c 访问的都是虚拟地址 x 但是看到的内容却是不一样的(背后可能映射到不同的物理内存中)。
但是当进程 a,进程 b,进程 c 进入到内核态之后情况就不一样了,由于内核虚拟内存空间是各个进程共享的,所以它们在内核空间中看到的内容全部是一样的,比如进程 a,进程 b,进程 c 在内核态都去访问虚拟地址 y。这时它们看到的内容就是一样的了。
这里我和大家澄清一个经常被误解的概念:由于内核会涉及到物理内存的管理,所以很多人会想当然地认为只要进入了内核态就开始使用物理地址了,这就大错特错了,千万不要这样理解,进程进入内核态之后使用的仍然是虚拟内存地址,只不过在内核中使用的虚拟内存地址被限制在了内核态虚拟内存空间范围中,这也是本小节我要为大家介绍的主题。
在清楚了这个基本概念之后,下面我分别从 32 位体系 和 64 位体系下为大家介绍内核态虚拟内存空间的布局。
32 位体系内核虚拟内存空间布局
在前边《5.1 内核如何划分用户态和内核态虚拟内存空间》小节中我们提到,内核在 /arch/x86/include/asm/page_32_types.h 文件中通过 TASK_SIZE 将进程虚拟内存空间和内核虚拟内存空间分割开来。
|
|
__PAGE_OFFSET 的值在 32 位系统下为 0xC000 000
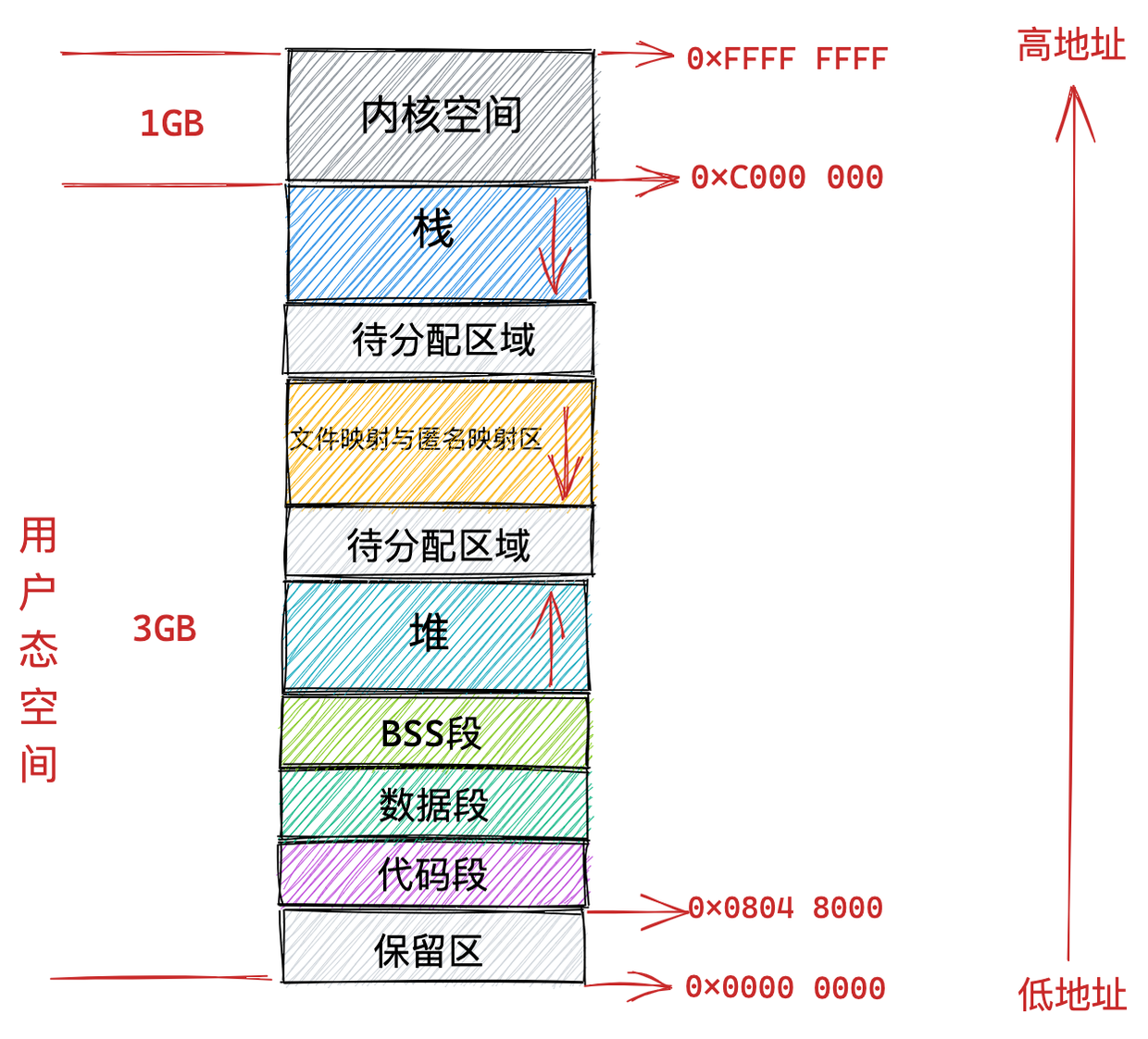
在 32 位体系结构下进程用户态虚拟内存空间为 3 GB,虚拟内存地址范围为:0x0000 0000 - 0xC000 000 。内核态虚拟内存空间为 1 GB,虚拟内存地址范围为:0xC000 000 - 0xFFFF FFFF。
本小节我们主要关注 0xC000 000 - 0xFFFF FFFF 这段虚拟内存地址区域也就是内核虚拟内存空间的布局情况。
直接映射区
在总共大小 1G 的内核虚拟内存空间中,位于最前边有一块 896M 大小的区域,我们称之为直接映射区或者线性映射区,地址范围为 3G – 3G + 896m 。
之所以这块 896M 大小的区域称为直接映射区或者线性映射区,是因为这块连续的虚拟内存地址会映射到 0 - 896M 这块连续的物理内存上。
也就是说 3G – 3G + 896m 这块 896M 大小的虚拟内存会直接映射到 0 - 896M 这块 896M 大小的物理内存上,这块区域中的虚拟内存地址直接减去 0xC000 0000 (3G) 就得到了物理内存地址。所以我们称这块区域为直接映射区。
为了方便为大家解释,我们假设现在机器上的物理内存为 4G 大小
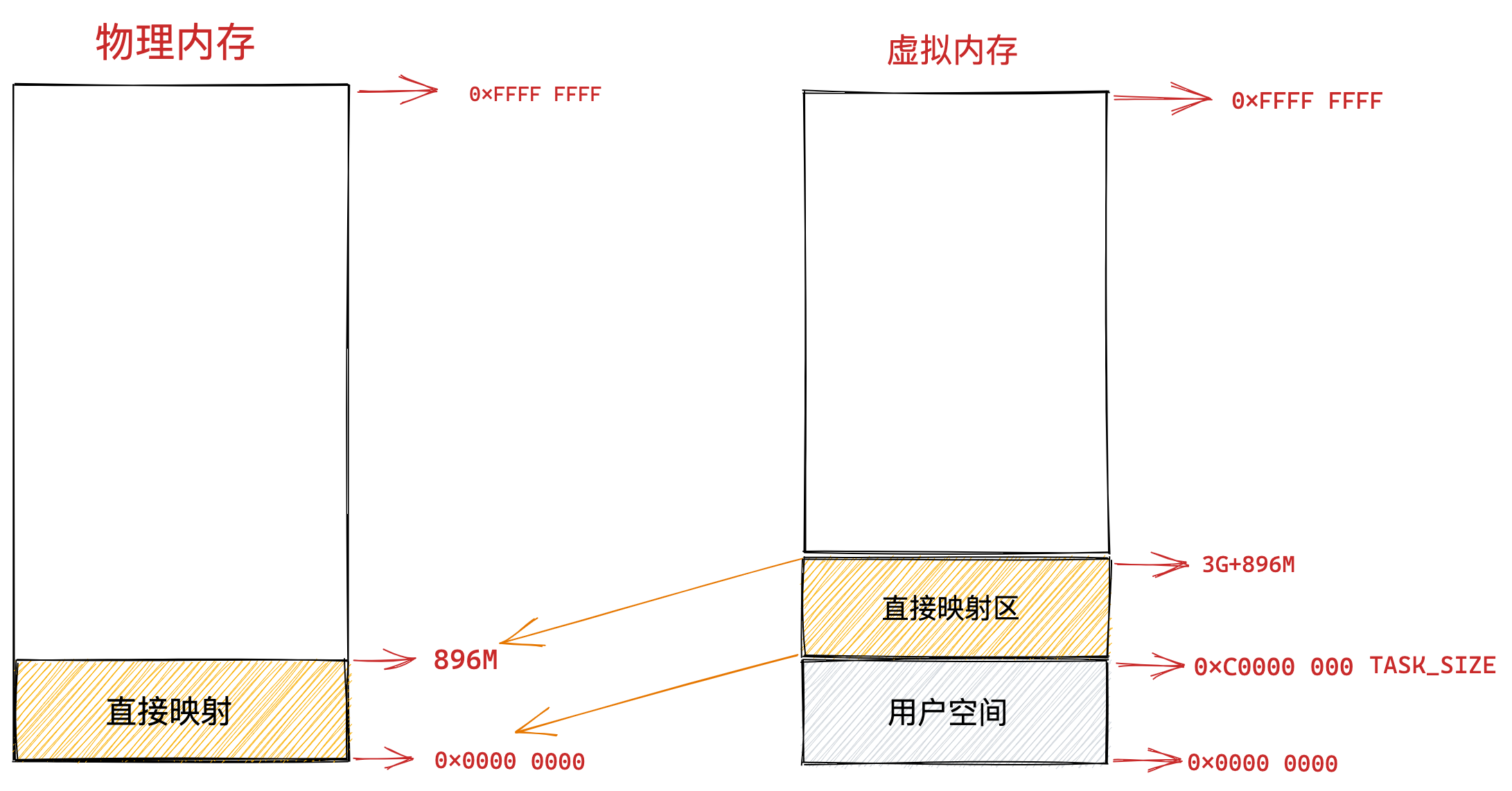
虽然这块区域中的虚拟地址是直接映射到物理地址上,但是内核在访问这段区域的时候还是走的虚拟内存地址,内核也会为这块空间建立映射页表。关于页表的概念我后续会为大家详细讲解,这里大家只需要简单理解为页表保存了虚拟地址到物理地址的映射关系即可。
大家这里只需要记得内核态虚拟内存空间的前 896M 区域是直接映射到物理内存中的前 896M 区域中的,直接映射区中的映射关系是一比一映射。映射关系是固定的不会改变。
明白了这个关系之后,我们接下来就看一下这块直接映射区域在物理内存中究竟存的是什么内容~~~
在这段 896M 大小的物理内存中,前 1M 已经在系统启动的时候被系统占用,1M 之后的物理内存存放的是内核代码段,数据段,BSS 段(这些信息起初存放在 ELF格式的二进制文件中,在系统启动的时候被加载进内存)。
我们可以通过
cat /proc/iomem命令查看具体物理内存布局情况。
当我们使用 fork 系统调用创建进程的时候,内核会创建一系列进程相关的描述符,比如之前提到的进程的核心数据结构 task_struct,进程的内存空间描述符 mm_struct,以及虚拟内存区域描述符 vm_area_struct 等。
这些进程相关的数据结构也会存放在物理内存前 896M 的这段区域中,当然也会被直接映射至内核态虚拟内存空间中的 3G – 3G + 896m 这段直接映射区域中。
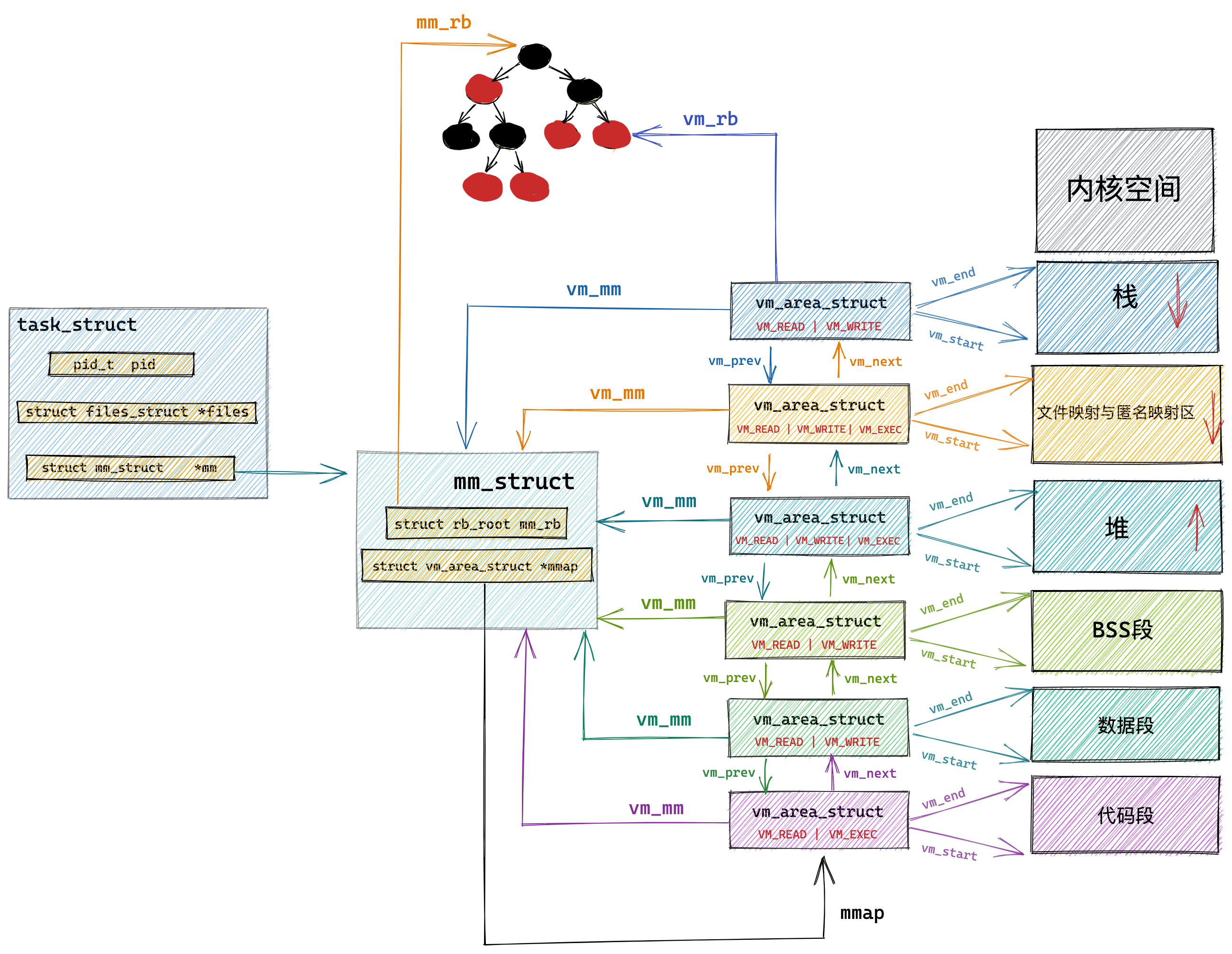
当进程被创建完毕之后,在内核运行的过程中,会涉及内核栈的分配,内核会为每个进程分配一个固定大小的内核栈(一般是两个页大小,依赖具体的体系结构),每个进程的整个调用链必须放在自己的内核栈中,内核栈也是分配在直接映射区。
与进程用户空间中的栈不同的是,内核栈容量小而且是固定的,用户空间中的栈容量大而且可以动态扩展。内核栈的溢出危害非常巨大,它会直接悄无声息的覆盖相邻内存区域中的数据,破坏数据。
通过以上内容的介绍我们了解到内核虚拟内存空间最前边的这段 896M 大小的直接映射区如何与物理内存进行映射关联,并且清楚了直接映射区主要用来存放哪些内容。
写到这里,我觉得还是有必要再次从功能划分的角度为大家介绍下这块直接映射区域。
我们都知道内核对物理内存的管理都是以页为最小单位来管理的,每页默认 4K 大小,理想状况下任何种类的数据页都可以存放在任何页框中,没有什么限制。比如:存放内核数据,用户数据,缓冲磁盘数据等。
但是实际的计算机体系结构受到硬件方面的限制制约,间接导致限制了页框的使用方式。
比如在 X86 体系结构下,ISA 总线的 DMA (直接内存存取)控制器,只能对内存的前16M 进行寻址,这就导致了 ISA 设备不能在整个 32 位地址空间中执行 DMA,只能使用物理内存的前 16M 进行 DMA 操作。
因此直接映射区的前 16M 专门让内核用来为 DMA 分配内存,这块 16M 大小的内存区域我们称之为 ZONE_DMA。
用于 DMA 的内存必须从 ZONE_DMA 区域中分配。
而直接映射区中剩下的部分也就是从 16M 到 896M(不包含 896M)这段区域,我们称之为 ZONE_NORMAL。从字面意义上我们可以了解到,这块区域包含的就是正常的页框(使用没有任何限制)。
ZONE_NORMAL 由于也是属于直接映射区的一部分,对应的物理内存 16M 到 896M 这段区域也是被直接映射至内核态虚拟内存空间中的 3G + 16M 到 3G + 896M 这段虚拟内存上。
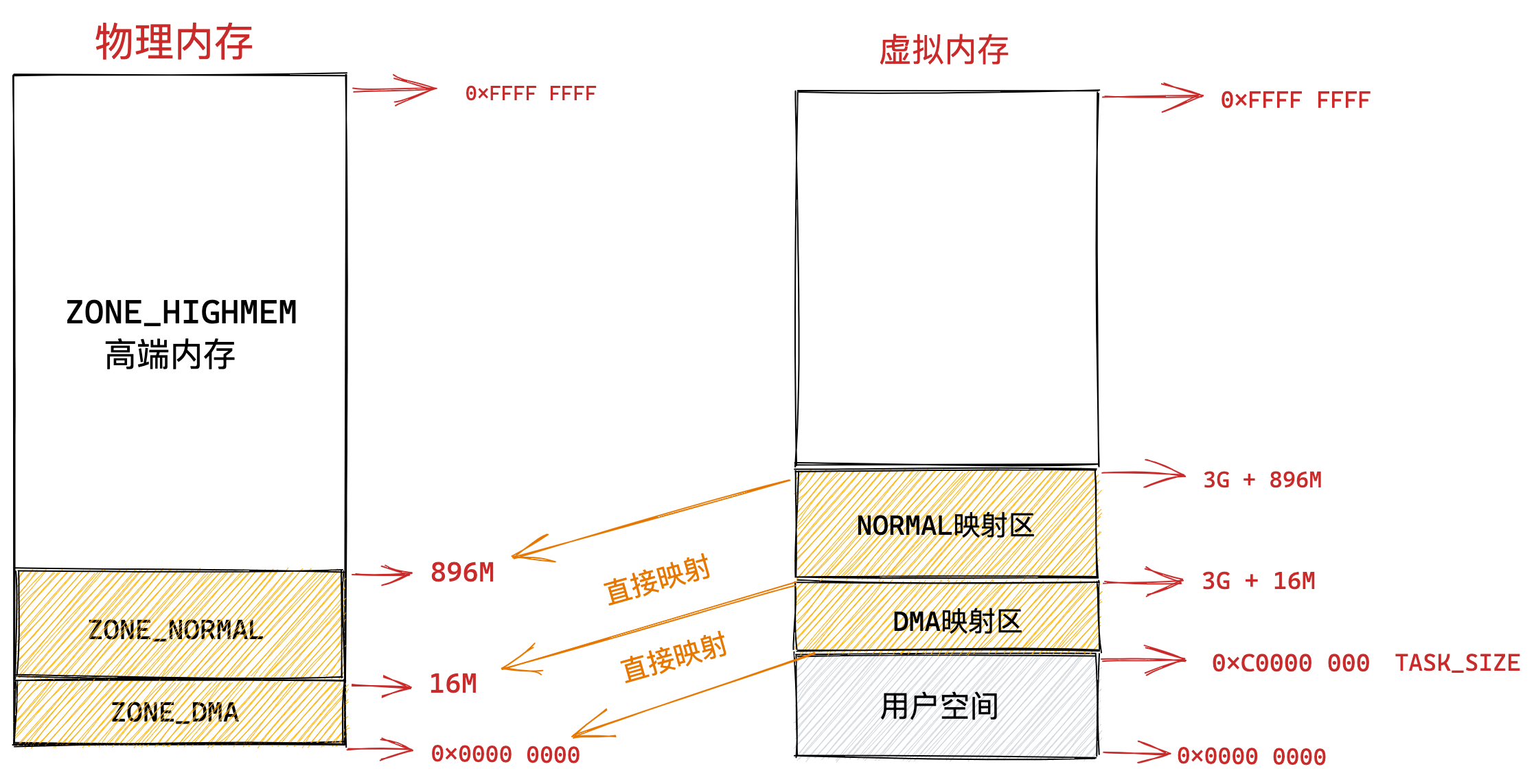
注意这里的 ZONE_DMA 和 ZONE_NORMAL 是内核针对物理内存区域的划分。
现在物理内存中的前 896M 的区域也就是前边介绍的 ZONE_DMA 和 ZONE_NORMAL 区域到内核虚拟内存空间的映射我就为大家介绍完了,它们都是采用直接映射的方式,一比一就行映射。
ZONE_HIGHMEM 高端内存
而物理内存 896M 以上的区域被内核划分为 ZONE_HIGHMEM 区域,我们称之为高端内存。
本例中我们的物理内存假设为 4G,高端内存区域为 4G - 896M = 3200M,那么这块 3200M 大小的 ZONE_HIGHMEM 区域该如何映射到内核虚拟内存空间中呢?
由于内核虚拟内存空间中的前 896M 虚拟内存已经被直接映射区所占用,而在 32 体系结构下内核虚拟内存空间总共也就 1G 的大小,这样一来内核剩余可用的虚拟内存空间就变为了 1G - 896M = 128M。
显然物理内存中 3200M 大小的 ZONE_HIGHMEM 区域无法继续通过直接映射的方式映射到这 128M 大小的虚拟内存空间中。
这样一来物理内存中的 ZONE_HIGHMEM 区域就只能采用动态映射的方式映射到 128M 大小的内核虚拟内存空间中,也就是说只能动态的一部分一部分的分批映射,先映射正在使用的这部分,使用完毕解除映射,接着映射其他部分。
知道了 ZONE_HIGHMEM 区域的映射原理,我们接着往下看这 128M 大小的内核虚拟内存空间究竟是如何布局的?
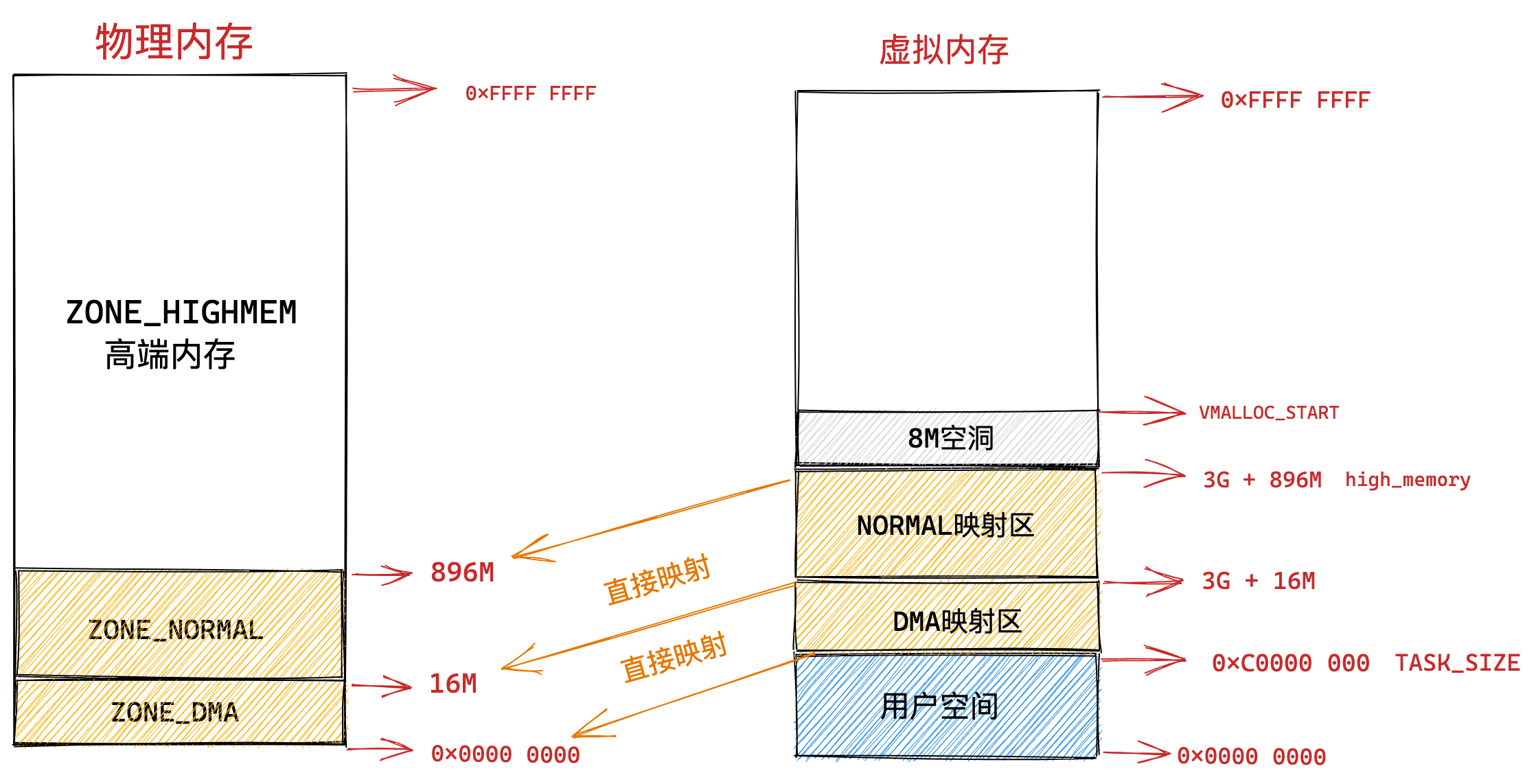
内核虚拟内存空间中的 3G + 896M 这块地址在内核中定义为 high_memory,high_memory 往上有一段 8M 大小的内存空洞。空洞范围为:high_memory 到 VMALLOC_START 。
VMALLOC_START 定义在内核源码 /arch/x86/include/asm/pgtable_32_areas.h 文件中:
|
|
vmalloc 动态映射区
接下来 VMALLOC_START 到 VMALLOC_END 之间的这块区域成为动态映射区。采用动态映射的方式映射物理内存中的高端内存。
|
|
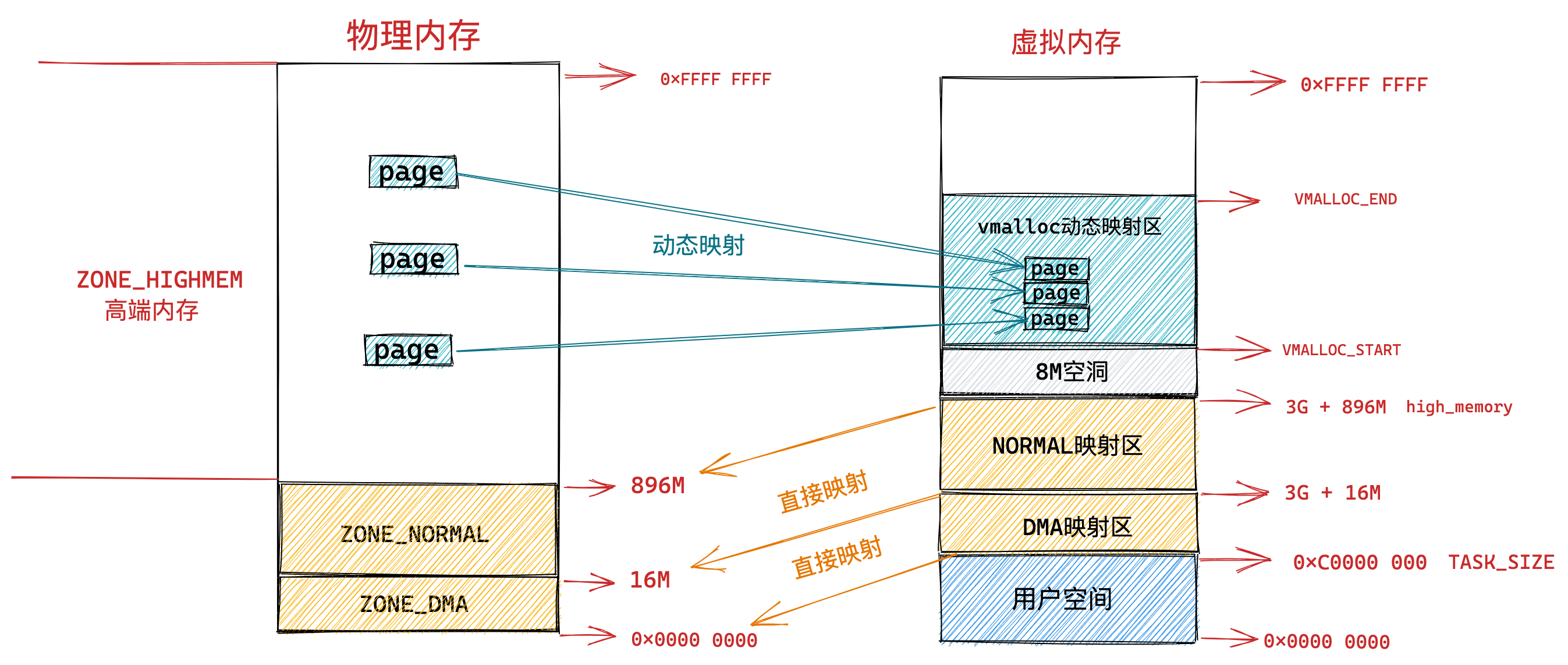
和用户态进程使用 malloc 申请内存一样,在这块动态映射区内核是使用 vmalloc 进行内存分配。由于之前介绍的动态映射的原因,vmalloc 分配的内存在虚拟内存上是连续的,但是物理内存是不连续的。通过页表来建立物理内存与虚拟内存之间的映射关系,从而可以将不连续的物理内存映射到连续的虚拟内存上。
由于 vmalloc 获得的物理内存页是不连续的,因此它只能将这些物理内存页一个一个地进行映射,在性能开销上会比直接映射大得多。
关于 vmalloc 分配内存的相关实现原理,我会在后面的文章中为大家讲解,这里大家只需要明白它在哪块虚拟内存区域中活动即可。
永久映射区
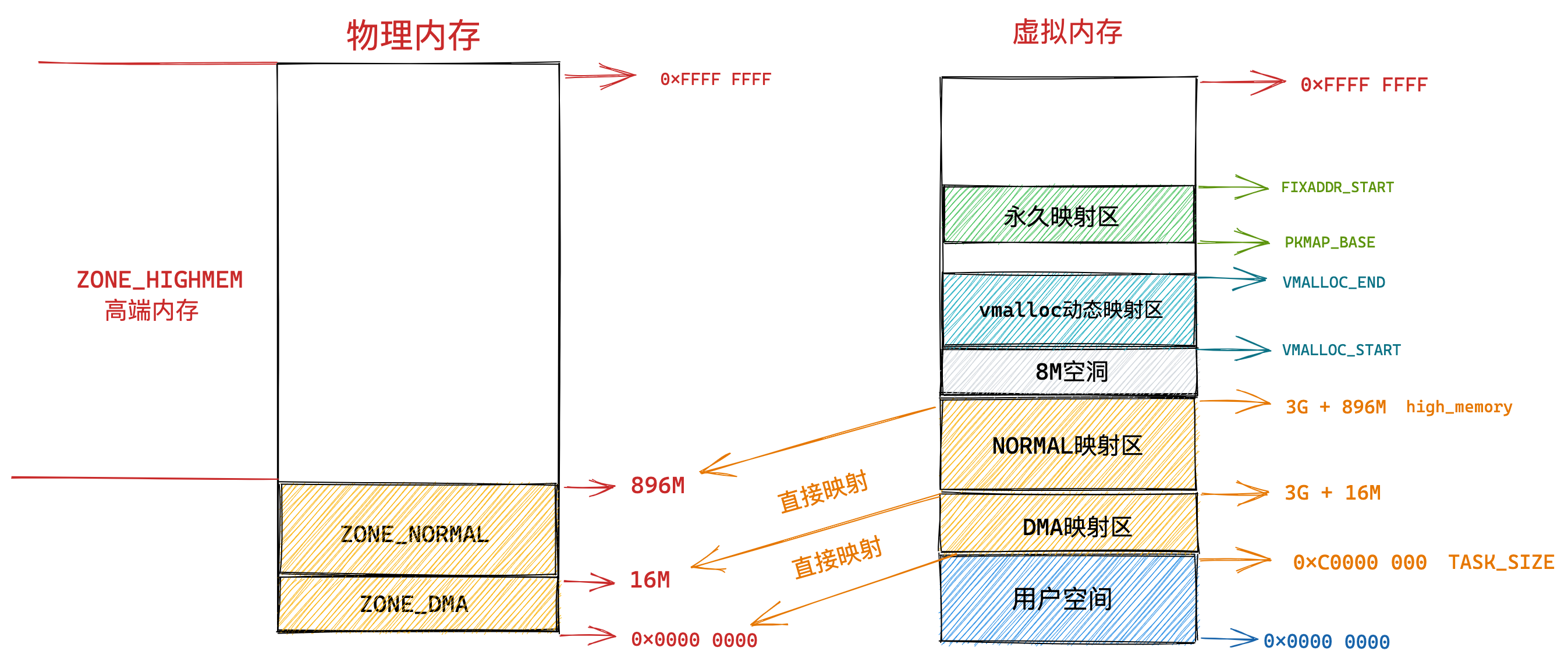
而在 PKMAP_BASE 到 FIXADDR_START 之间的这段空间称为永久映射区。在内核的这段虚拟地址空间中允许建立与物理高端内存的长期映射关系。比如内核通过 alloc_pages() 函数在物理内存的高端内存中申请获取到的物理内存页,这些物理内存页可以通过调用 kmap 映射到永久映射区中。
LAST_PKMAP 表示永久映射区可以映射的页数限制。
|
|
固定映射区
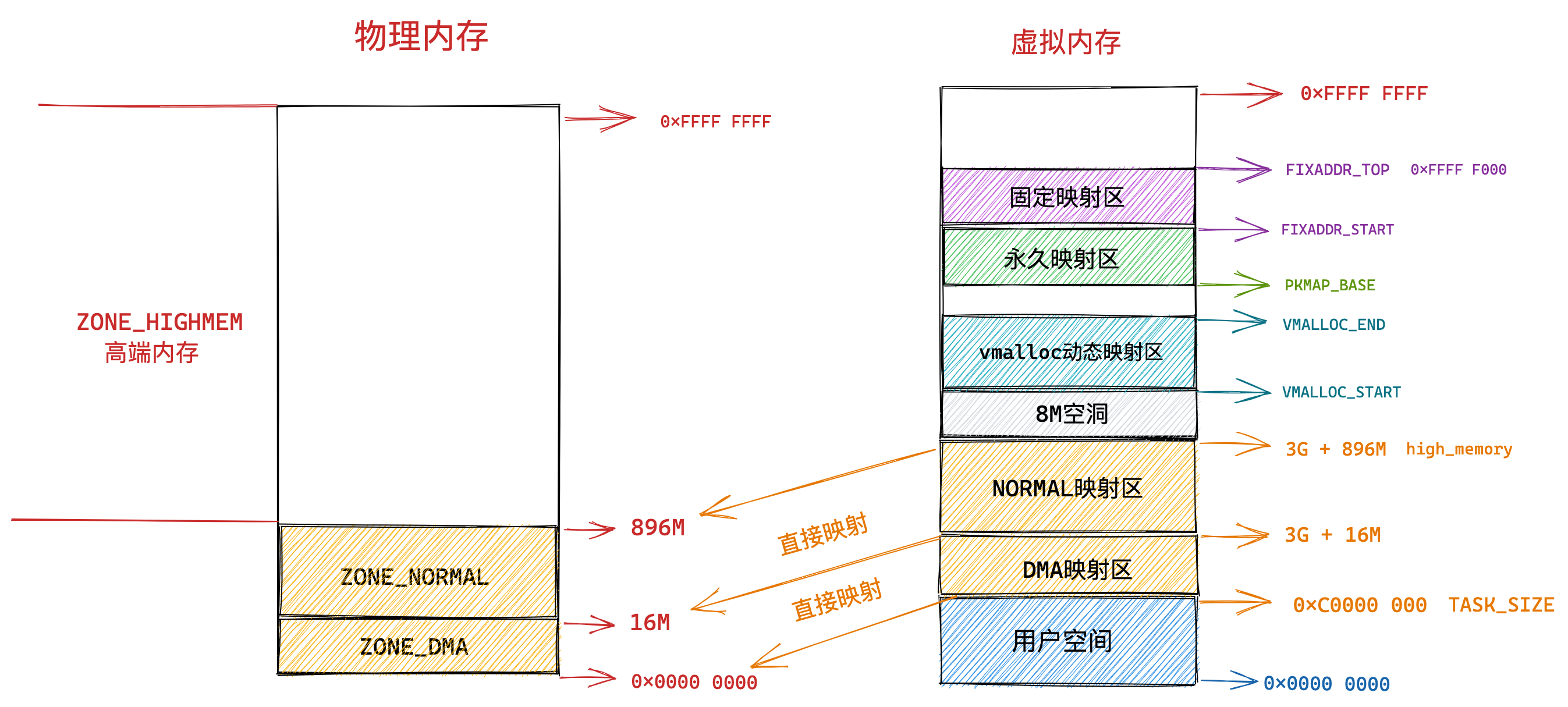
内核虚拟内存空间中的下一个区域为固定映射区,区域范围为:FIXADDR_START 到 FIXADDR_TOP。
FIXADDR_START 和 FIXADDR_TOP 定义在内核源码 /arch/x86/include/asm/fixmap.h 文件中:
|
|
在内核虚拟内存空间的直接映射区中,直接映射区中的虚拟内存地址与物理内存前 896M 的空间的映射关系都是预设好的,一比一映射。
在固定映射区中的虚拟内存地址可以自由映射到物理内存的高端地址上,但是与动态映射区以及永久映射区不同的是,在固定映射区中虚拟地址是固定的,而被映射的物理地址是可以改变的。也就是说,有些虚拟地址在编译的时候就固定下来了,是在内核启动过程中被确定的,而这些虚拟地址对应的物理地址不是固定的。采用固定虚拟地址的好处是它相当于一个指针常量(常量的值在编译时确定),指向物理地址,如果虚拟地址不固定,则相当于一个指针变量。
那为什么会有固定映射这个概念呢 ? 比如:在内核的启动过程中,有些模块需要使用虚拟内存并映射到指定的物理地址上,而且这些模块也没有办法等待完整的内存管理模块初始化之后再进行地址映射。因此,内核固定分配了一些虚拟地址,这些地址有固定的用途,使用该地址的模块在初始化的时候,将这些固定分配的虚拟地址映射到指定的物理地址上去。
临时映射区
在内核虚拟内存空间中的最后一块区域为临时映射区,那么这块临时映射区是用来干什么的呢?
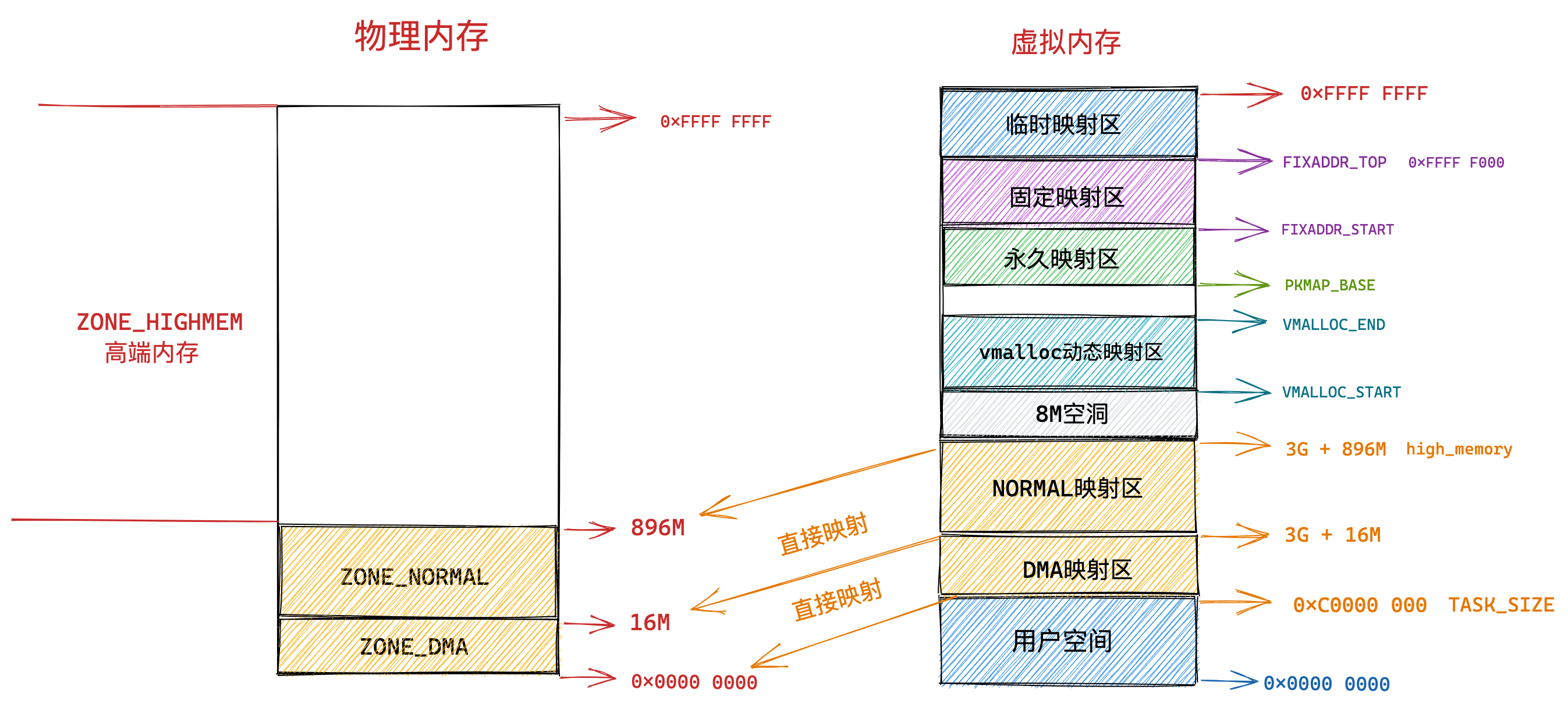
我在之前文章 《从 Linux 内核角度探秘 JDK NIO 文件读写本质》 (opens new window)的 “ 12.3 iov_iter_copy_from_user_atomic ” 小节中介绍在 Buffered IO 模式下进行文件写入的时候,在下图中的第四步,内核会调用 iov_iter_copy_from_user_atomic 函数将用户空间缓冲区 DirectByteBuffer 中的待写入数据拷贝到 page cache 中。
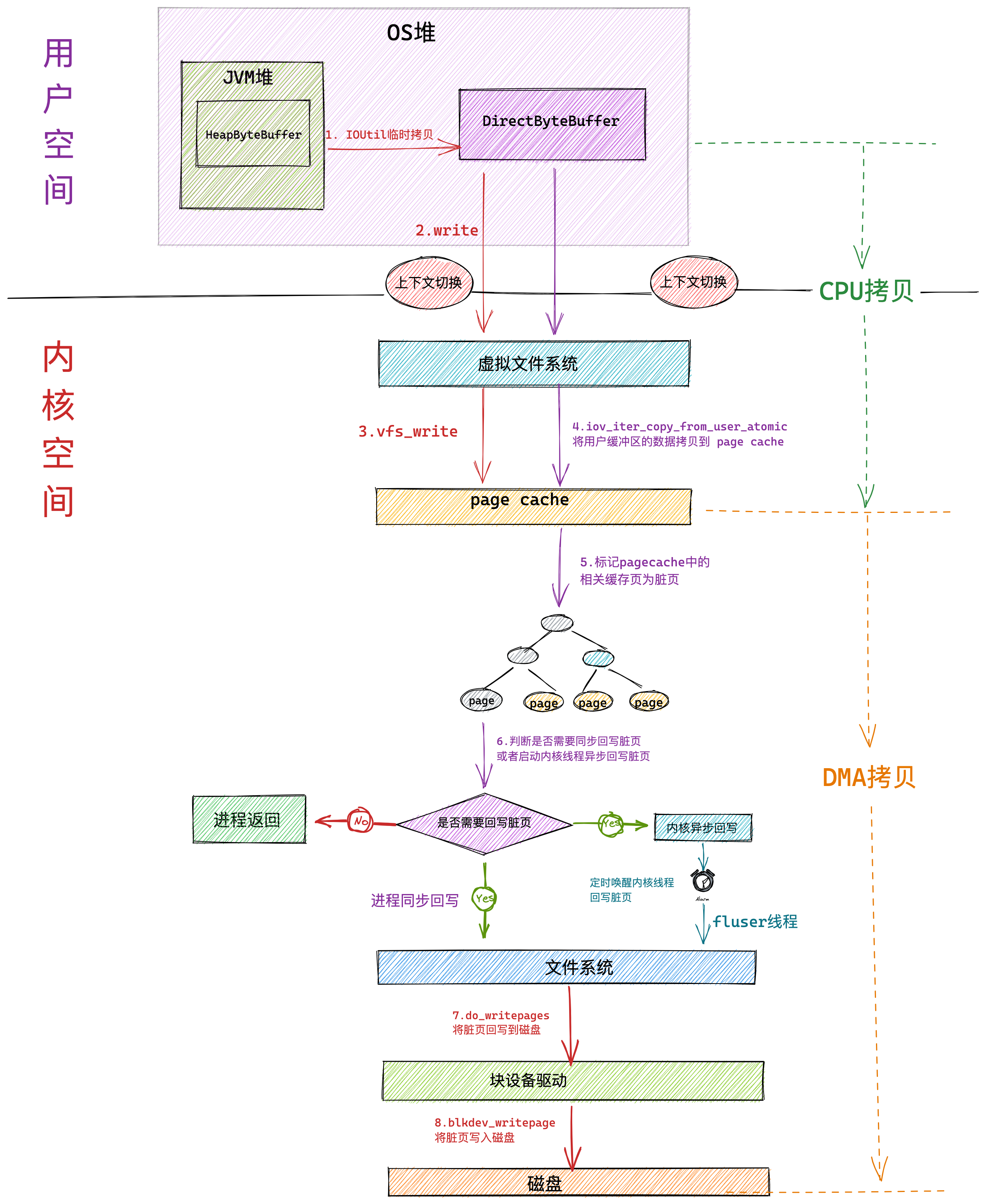
但是内核又不能直接进行拷贝,因为此时从 page cache 中取出的缓存页 page 是物理地址,而在内核中是不能够直接操作物理地址的,只能操作虚拟地址。
那怎么办呢?所以就需要使用 kmap_atomic 将缓存页临时映射到内核空间的一段虚拟地址上,这段虚拟地址就位于内核虚拟内存空间中的临时映射区上,然后将用户空间缓存区 DirectByteBuffer 中的待写入数据通过这段映射的虚拟地址拷贝到 page cache 中的相应缓存页中。这时文件的写入操作就已经完成了。
由于是临时映射,所以在拷贝完成之后,调用 kunmap_atomic 将这段映射再解除掉。
|
|
32位体系结构下 Linux 虚拟内存空间整体布局
到现在为止,整个内核虚拟内存空间在 32 位体系下的布局,我就为大家详细介绍完毕了,我们再次结合前边《4.1 32 位机器上进程虚拟内存空间分布》小节中介绍的进程虚拟内存空间和本小节介绍的内核虚拟内存空间来整体回顾下 32 位体系结构 Linux 的整个虚拟内存空间的布局:
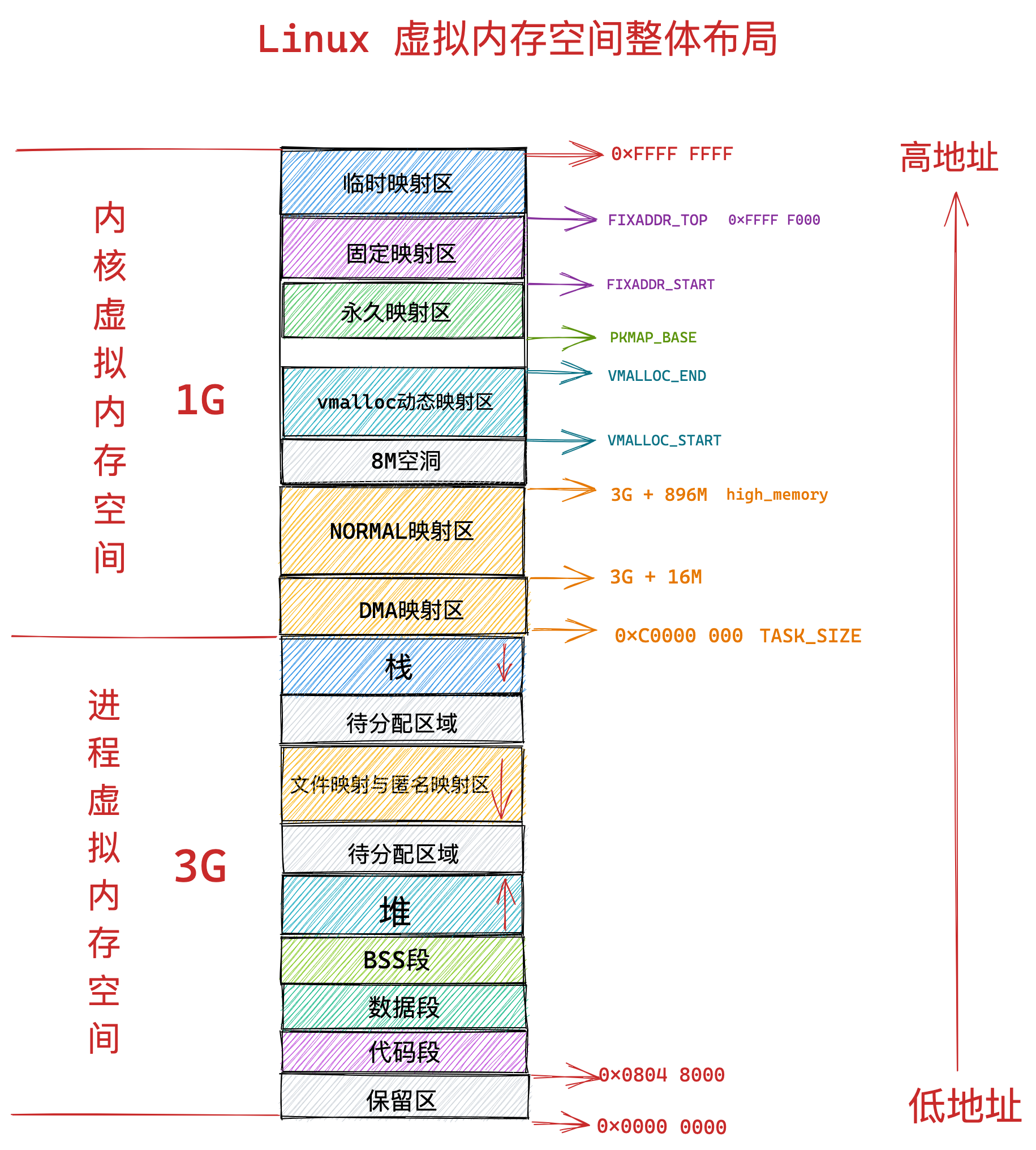
64 位体系内核虚拟内存空间布局
内核虚拟内存空间在 32 位体系下只有 1G 大小,实在太小了,因此需要精细化的管理,于是按照功能分类划分除了很多内核虚拟内存区域,这样就显得非常复杂。
到了 64 位体系下,内核虚拟内存空间的布局和管理就变得容易多了,因为进程虚拟内存空间和内核虚拟内存空间各自占用 128T 的虚拟内存,实在是太大了,我们可以在这里边随意翱翔,随意挥霍。
因此在 64 位体系下的内核虚拟内存空间与物理内存的映射就变得非常简单,由于虚拟内存空间足够的大,即便是内核要访问全部的物理内存,直接映射就可以了,不在需要用到《7.1.2 ZONE_HIGHMEM 高端内存》小节中介绍的高端内存那种动态映射方式。
在前边《5.1 内核如何划分用户态和内核态虚拟内存空间》小节中我们提到,内核在 /arch/x86/include/asm/page_64_types.h 文件中通过 TASK_SIZE 将进程虚拟内存空间和内核虚拟内存空间分割开来。
|
|
64 位系统中的 TASK_SIZE 为 0x00007FFFFFFFF000
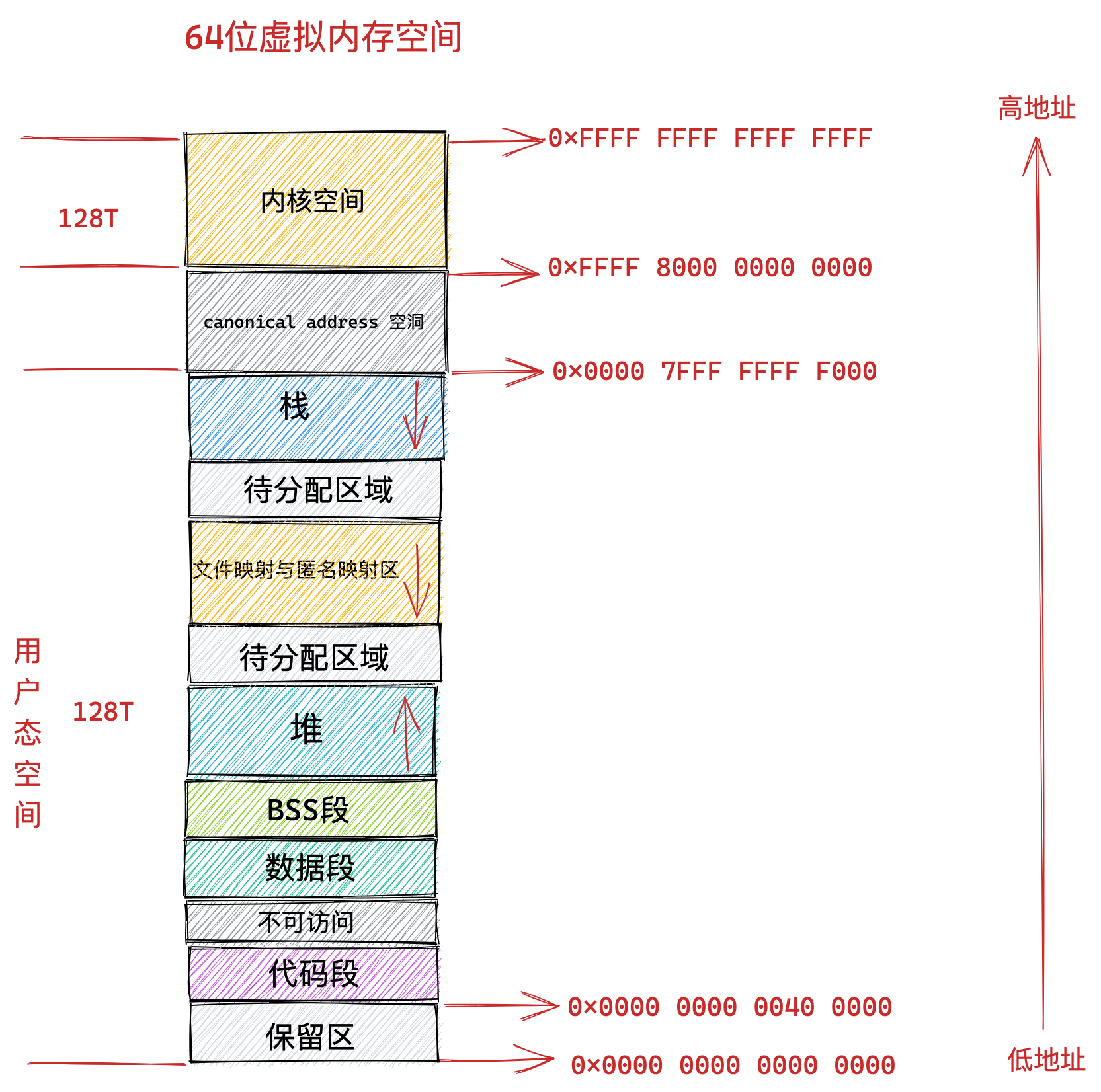
在 64 位系统中,只使用了其中的低 48 位来表示虚拟内存地址。其中用户态虚拟内存空间为低 128 T,虚拟内存地址范围为:0x0000 0000 0000 0000 - 0x0000 7FFF FFFF F000 。
内核态虚拟内存空间为高 128 T,虚拟内存地址范围为:0xFFFF 8000 0000 0000 - 0xFFFF FFFF FFFF FFFF 。
本小节我们主要关注 0xFFFF 8000 0000 0000 - 0xFFFF FFFF FFFF FFFF 这段内核虚拟内存空间的布局情况。
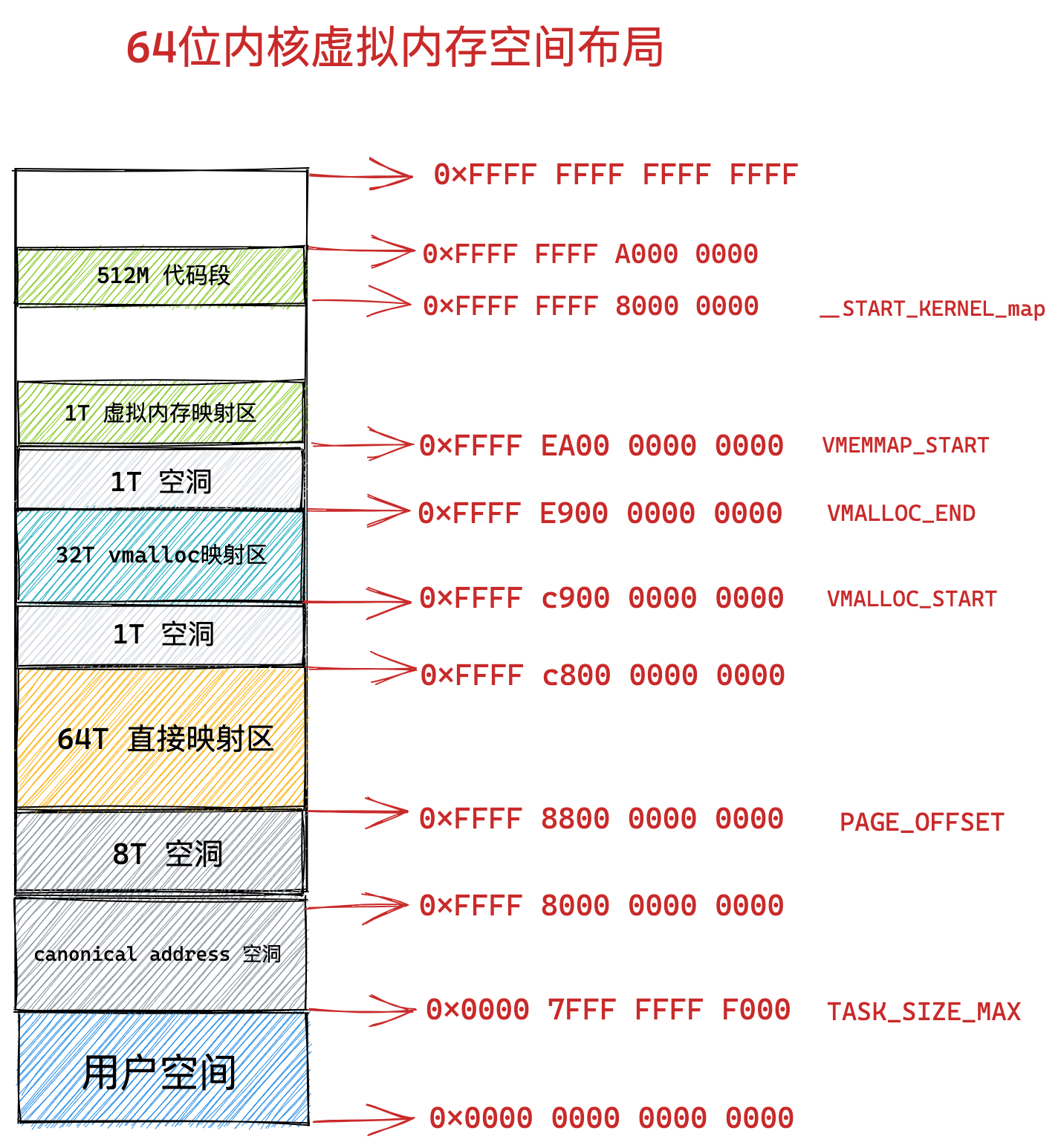
64 位内核虚拟内存空间从 0xFFFF 8000 0000 0000 开始到 0xFFFF 8800 0000 0000 这段地址空间是一个 8T 大小的内存空洞区域。
紧着着 8T 大小的内存空洞下一个区域就是 64T 大小的直接映射区。这个区域中的虚拟内存地址减去 PAGE_OFFSET 就直接得到了物理内存地址。
PAGE_OFFSET 变量定义在 /arch/x86/include/asm/page_64_types.h 文件中:
|
|
从图中 VMALLOC_START 到 VMALLOC_END 的这段区域是 32T 大小的 vmalloc 映射区,这里类似用户空间中的堆,内核在这里使用 vmalloc 系统调用申请内存。
VMALLOC_START 和 VMALLOC_END 变量定义在 /arch/x86/include/asm/pgtable_64_types.h 文件中:
|
|
从 VMEMMAP_START 开始是 1T 大小的虚拟内存映射区,用于存放物理页面的描述符 struct page 结构用来表示物理内存页。
VMEMMAP_START 变量定义在 /arch/x86/include/asm/pgtable_64_types.h 文件中:
|
|
从 __START_KERNEL_map 开始是大小为 512M 的区域用于存放内核代码段、全局变量、BSS 等。这里对应到物理内存开始的位置,减去 __START_KERNEL_map 就能得到物理内存的地址。这里和直接映射区有点像,但是不矛盾,因为直接映射区之前有 8T 的空洞区域,早就过了内核代码在物理内存中加载的位置。
__START_KERNEL_map 变量定义在 /arch/x86/include/asm/page_64_types.h 文件中:
|
|
64位体系结构下 Linux 虚拟内存空间整体布局
到现在为止,整个内核虚拟内存空间在 64 位体系下的布局我就为大家详细介绍完毕了,我们再次结合前边《4.2 64 位机器上进程虚拟内存空间分布》小节介绍的进程虚拟内存空间和本小节介绍的内核虚拟内存空间来整体回顾下 64 位体系结构 Linux 的整个虚拟内存空间的布局:
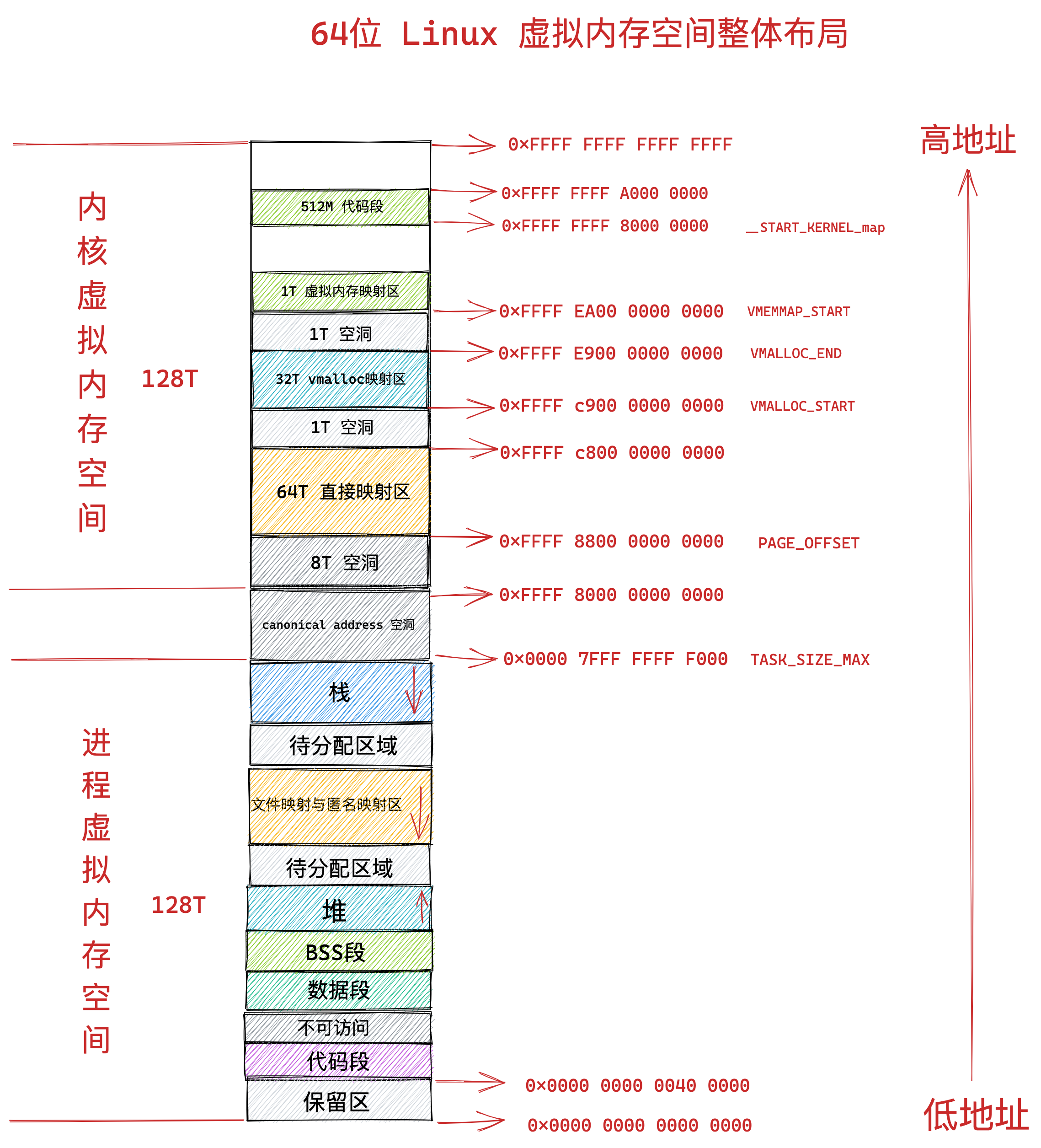
到底什么是物理内存地址
聊完了虚拟内存,我们接着聊一下物理内存,我们平时所称的内存也叫随机访问存储器( random-access memory )也叫 RAM 。而 RAM 分为两类:
- 一类是静态 RAM(
SRAM),这类 SRAM 用于 CPU 高速缓存 L1Cache,L2Cache,L3Cache。其特点是访问速度快,访问速度为 1 - 30 个时钟周期,但是容量小,造价高。
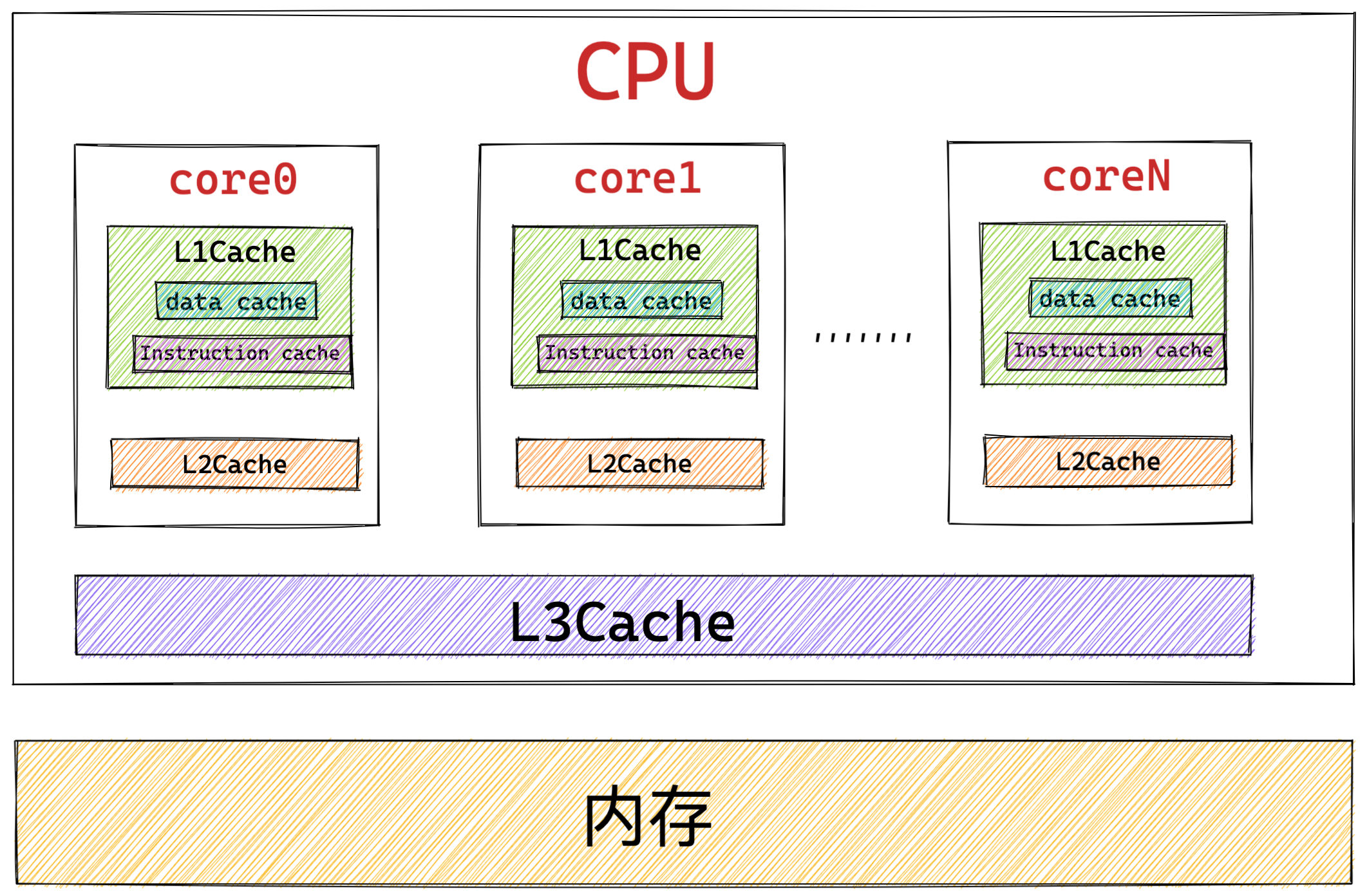
- 另一类则是动态 RAM (
DRAM),这类 DRAM 用于我们常说的主存上,其特点的是访问速度慢(相对高速缓存),访问速度为 50 - 200 个时钟周期,但是容量大,造价便宜些(相对高速缓存)。
内存由一个一个的存储器模块(memory module)组成,它们插在主板的扩展槽上。常见的存储器模块通常以 64 位为单位( 8 个字节)传输数据到存储控制器上或者从存储控制器传出数据。

如图所示内存条上黑色的元器件就是存储器模块(memory module)。多个存储器模块连接到存储控制器上,就聚合成了主存。
而 DRAM 芯片就包装在存储器模块中,每个存储器模块中包含 8 个 DRAM 芯片,依次编号为 0 - 7 。
而每一个 DRAM 芯片的存储结构是一个二维矩阵,二维矩阵中存储的元素我们称为超单元(supercell),每个 supercell 大小为一个字节(8 bit)。每个 supercell 都由一个坐标地址(i,j)。
i 表示二维矩阵中的行地址,在计算机中行地址称为 RAS (row access strobe,行访问选通脉冲)。 j 表示二维矩阵中的列地址,在计算机中列地址称为 CAS (column access strobe,列访问选通脉冲)。
下图中的 supercell 的 RAS = 2,CAS = 2。
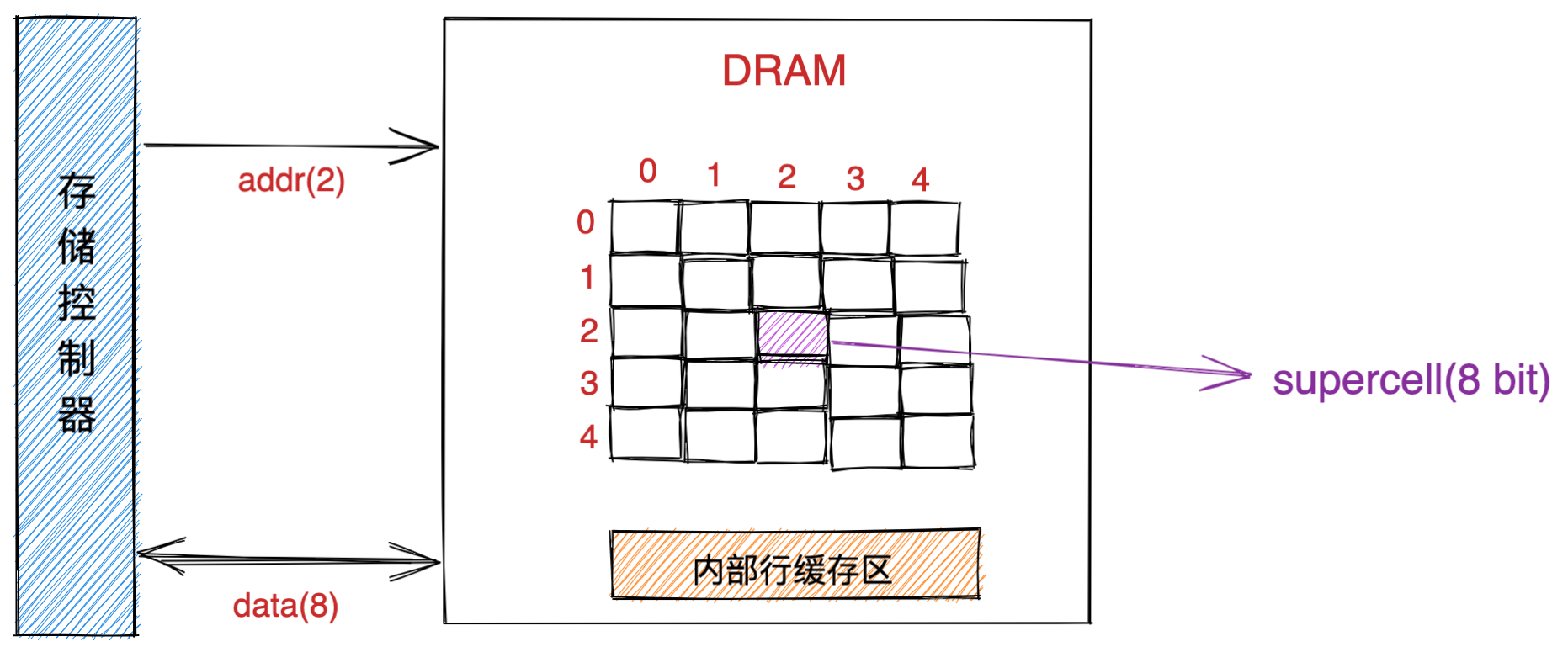
DRAM 芯片中的信息通过引脚流入流出 DRAM 芯片。每个引脚携带 1 bit的信号。
图中 DRAM 芯片包含了两个地址引脚( addr ),因为我们要通过 RAS,CAS 来定位要获取的 supercell 。还有 8 个数据引脚(data),因为 DRAM 芯片的 IO 单位为一个字节(8 bit),所以需要 8 个 data 引脚从 DRAM 芯片传入传出数据。
注意这里只是为了解释地址引脚和数据引脚的概念,实际硬件中的引脚数量是不一定的。
DRAM 芯片的访问
我们现在就以读取上图中坐标地址为(2,2)的 supercell 为例,来说明访问 DRAM 芯片的过程。
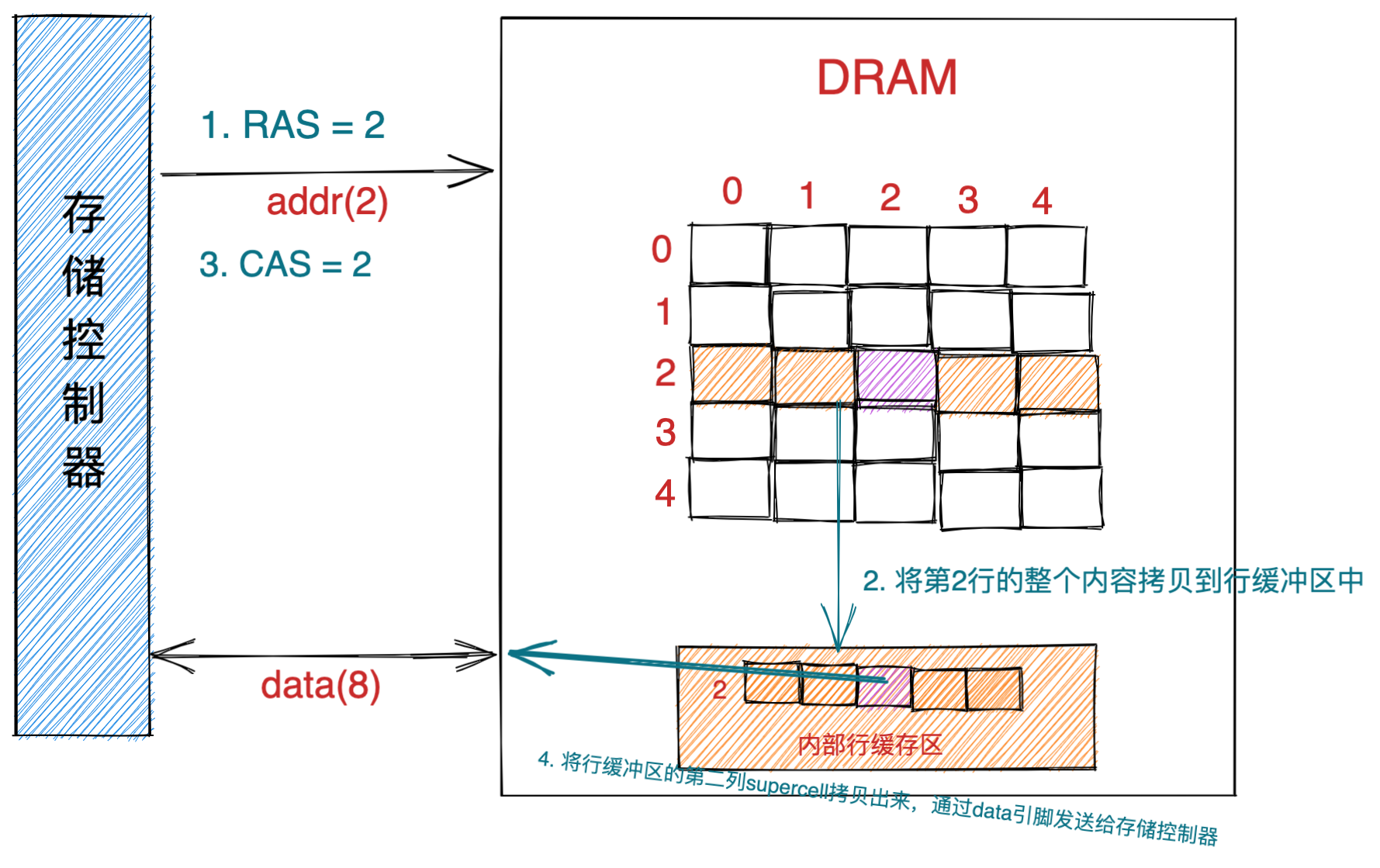
- 首先存储控制器将行地址 RAS = 2 通过地址引脚发送给 DRAM 芯片。
- DRAM 芯片根据 RAS = 2 将二维矩阵中的第二行的全部内容拷贝到内部行缓冲区中。
- 接下来存储控制器会通过地址引脚发送 CAS = 2 到 DRAM 芯片中。
- DRAM芯片从内部行缓冲区中根据 CAS = 2 拷贝出第二列的 supercell 并通过数据引脚发送给存储控制器。
DRAM 芯片的 IO 单位为一个 supercell ,也就是一个字节(8 bit)。
CPU 如何读写主存
前边我们介绍了内存的物理结构,以及如何访问内存中的 DRAM 芯片获取 supercell 中存储的数据(一个字节)。本小节我们来介绍下 CPU 是如何访问内存的:
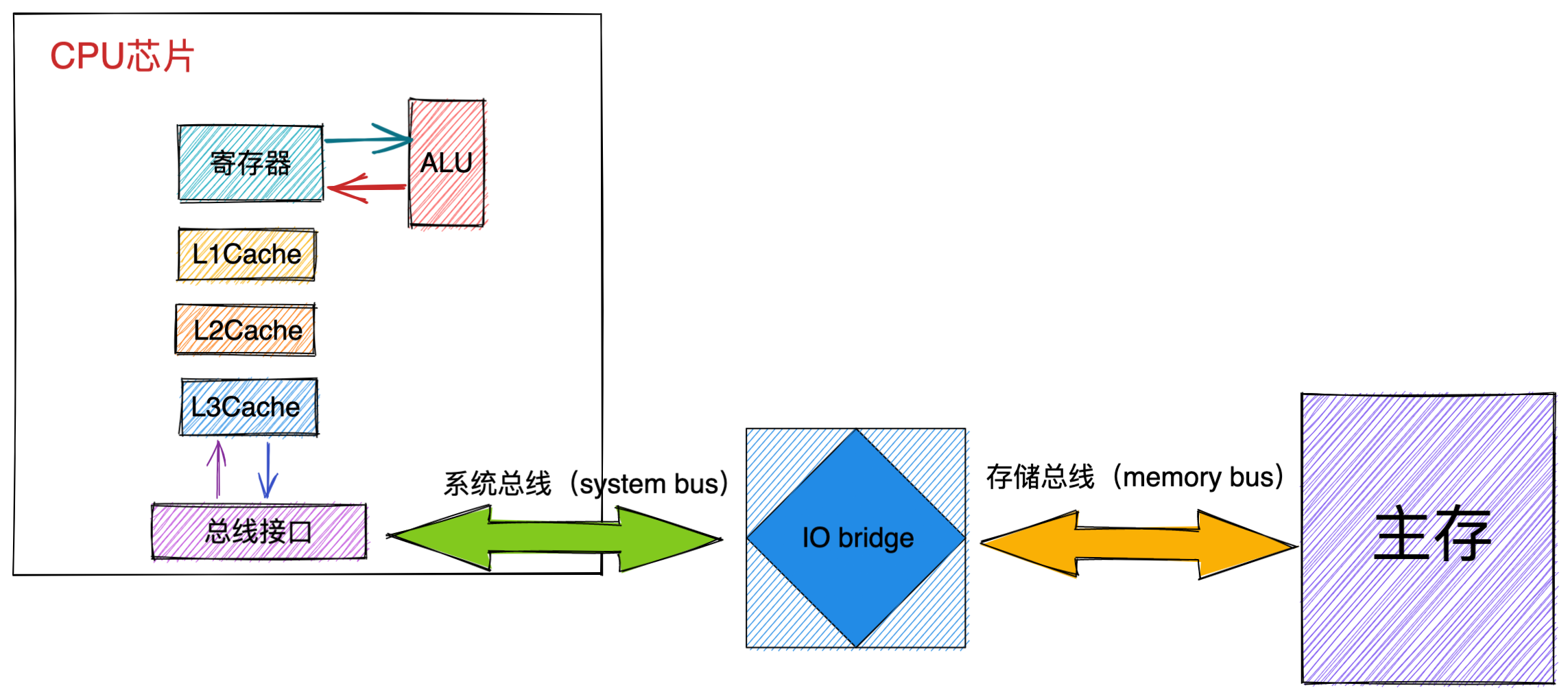
CPU 与内存之间的数据交互是通过总线(bus)完成的,而数据在总线上的传送是通过一系列的步骤完成的,这些步骤称为总线事务(bus transaction)。
其中数据从内存传送到 CPU 称之为读事务(read transaction),数据从 CPU 传送到内存称之为写事务(write transaction)。
总线上传输的信号包括:地址信号,数据信号,控制信号。其中控制总线上传输的控制信号可以同步事务,并能够标识出当前正在被执行的事务信息:
- 当前这个事务是到内存的?还是到磁盘的?或者是到其他 IO 设备的?
- 这个事务是读还是写?
- 总线上传输的地址信号(物理内存地址),还是数据信号(数据)?。
这里大家需要注意总线上传输的地址均为物理内存地址。比如:在 MESI 缓存一致性协议中当 CPU core0 修改字段 a 的值时,其他 CPU 核心会在总线上嗅探字段 a 的物理内存地址,如果嗅探到总线上出现字段 a 的物理内存地址,说明有人在修改字段 a,这样其他 CPU 核心就会失效字段 a 所在的 cache line 。
如上图所示,其中系统总线是连接 CPU 与 IO bridge 的,存储总线是来连接 IO bridge 和主存的。
IO bridge 负责将系统总线上的电子信号转换成存储总线上的电子信号。IO bridge 也会将系统总线和存储总线连接到IO总线(磁盘等IO设备)上。这里我们看到 IO bridge 其实起的作用就是转换不同总线上的电子信号。
CPU 从内存读取数据过程
假设 CPU 现在需要将物理内存地址为 A 的内容加载到寄存器中进行运算。
大家需要注意的是 CPU 只会访问虚拟内存,在操作总线之前,需要把虚拟内存地址转换为物理内存地址,总线上传输的都是物理内存地址,这里省略了虚拟内存地址到物理内存地址的转换过程,这部分内容我会在后续文章的相关章节详细为大家讲解,这里我们聚焦如何通过物理内存地址读取内存数据。
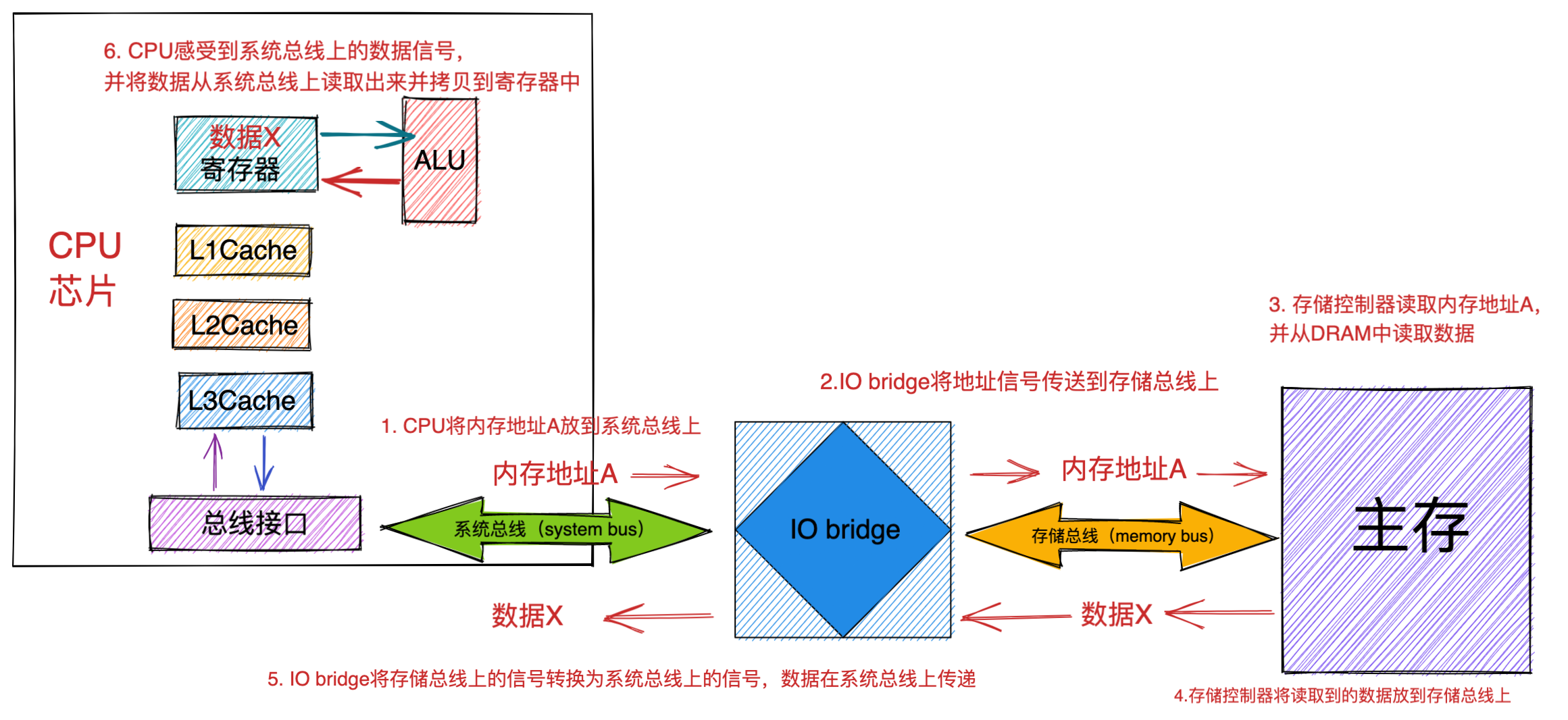
首先 CPU 芯片中的总线接口会在总线上发起读事务(read transaction)。 该读事务分为以下步骤进行:
- CPU 将物理内存地址 A 放到系统总线上。随后 IO bridge 将信号传递到存储总线上。
- 主存感受到存储总线上的地址信号并通过存储控制器将存储总线上的物理内存地址 A 读取出来。
- 存储控制器通过物理内存地址 A 定位到具体的存储器模块,从 DRAM 芯片中取出物理内存地址 A 对应的数据 X。
- 存储控制器将读取到的数据 X 放到存储总线上,随后 IO bridge 将存储总线上的数据信号转换为系统总线上的数据信号,然后继续沿着系统总线传递。
- CPU 芯片感受到系统总线上的数据信号,将数据从系统总线上读取出来并拷贝到寄存器中。
以上就是 CPU 读取内存数据到寄存器中的完整过程。
但是其中还涉及到一个重要的过程,这里我们还是需要摊开来介绍一下,那就是存储控制器如何通过物理内存地址 A 从主存中读取出对应的数据 X 的?
接下来我们结合前边介绍的内存结构以及从 DRAM 芯片读取数据的过程,来总体介绍下如何从主存中读取数据。
如何根据物理内存地址从主存中读取数据
前边介绍到,当主存中的存储控制器感受到了存储总线上的地址信号时,会将内存地址从存储总线上读取出来。
随后会通过内存地址定位到具体的存储器模块。还记得内存结构中的存储器模块吗 ?
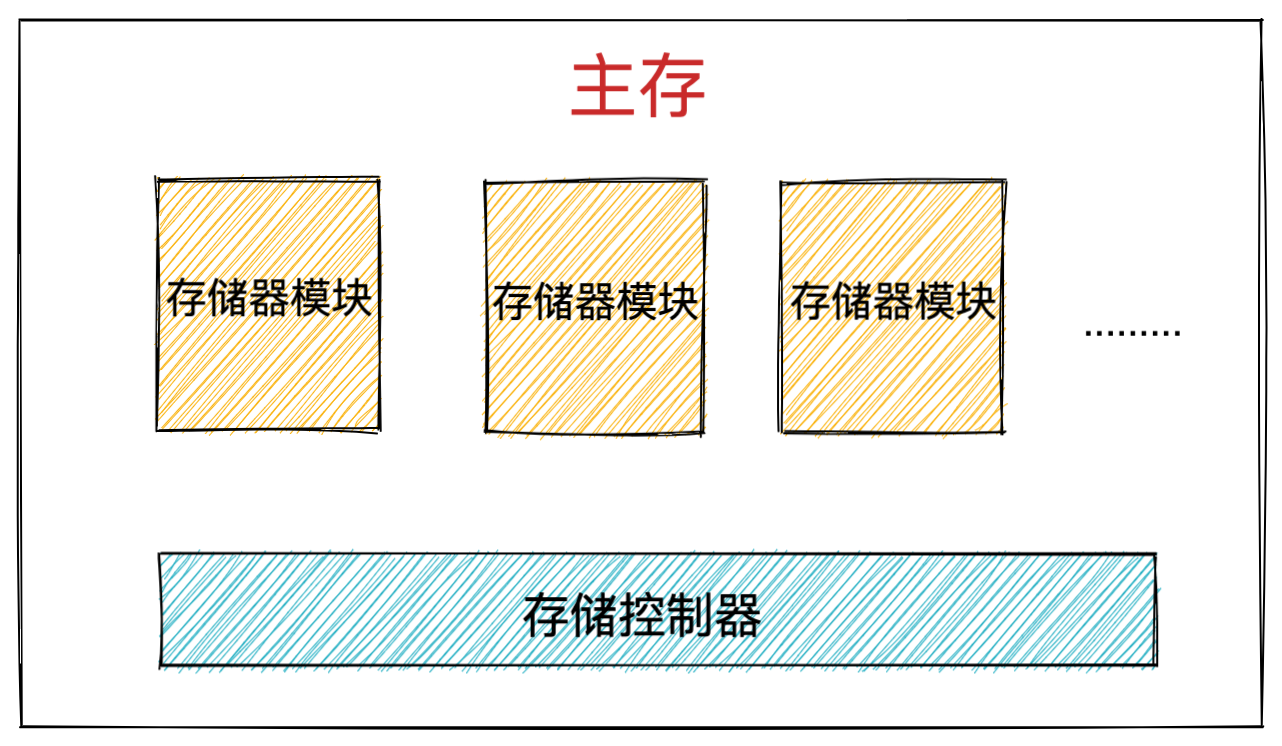
而每个存储器模块中包含了 8 个 DRAM 芯片,编号从 0 - 7 。
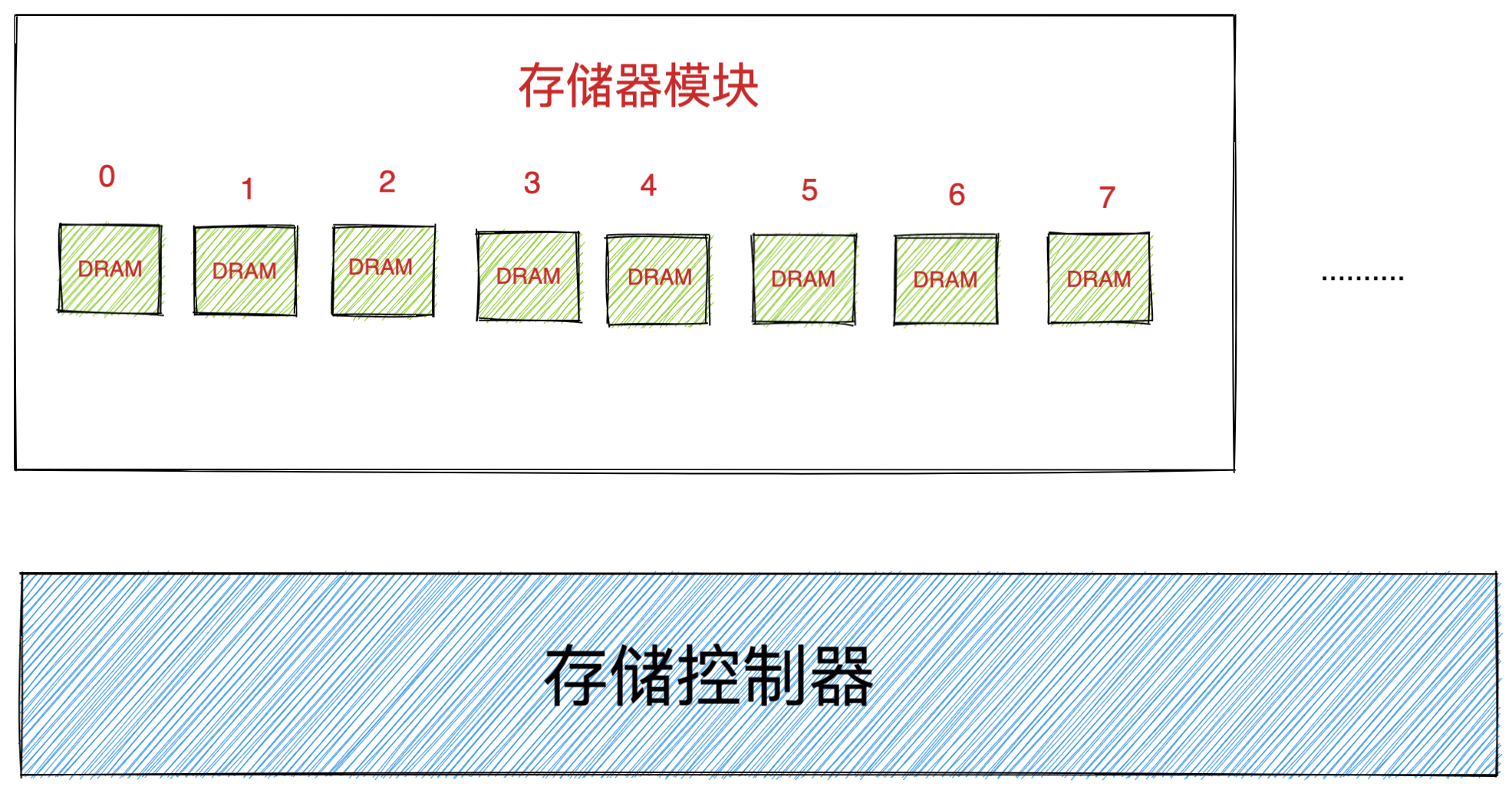
存储控制器会将物理内存地址转换为 DRAM 芯片中 supercell 在二维矩阵中的坐标地址(RAS,CAS)。并将这个坐标地址发送给对应的存储器模块。随后存储器模块会将 RAS 和 CAS 广播到存储器模块中的所有 DRAM 芯片。依次通过 (RAS,CAS) 从 DRAM0 到 DRAM7 读取到相应的 supercell 。
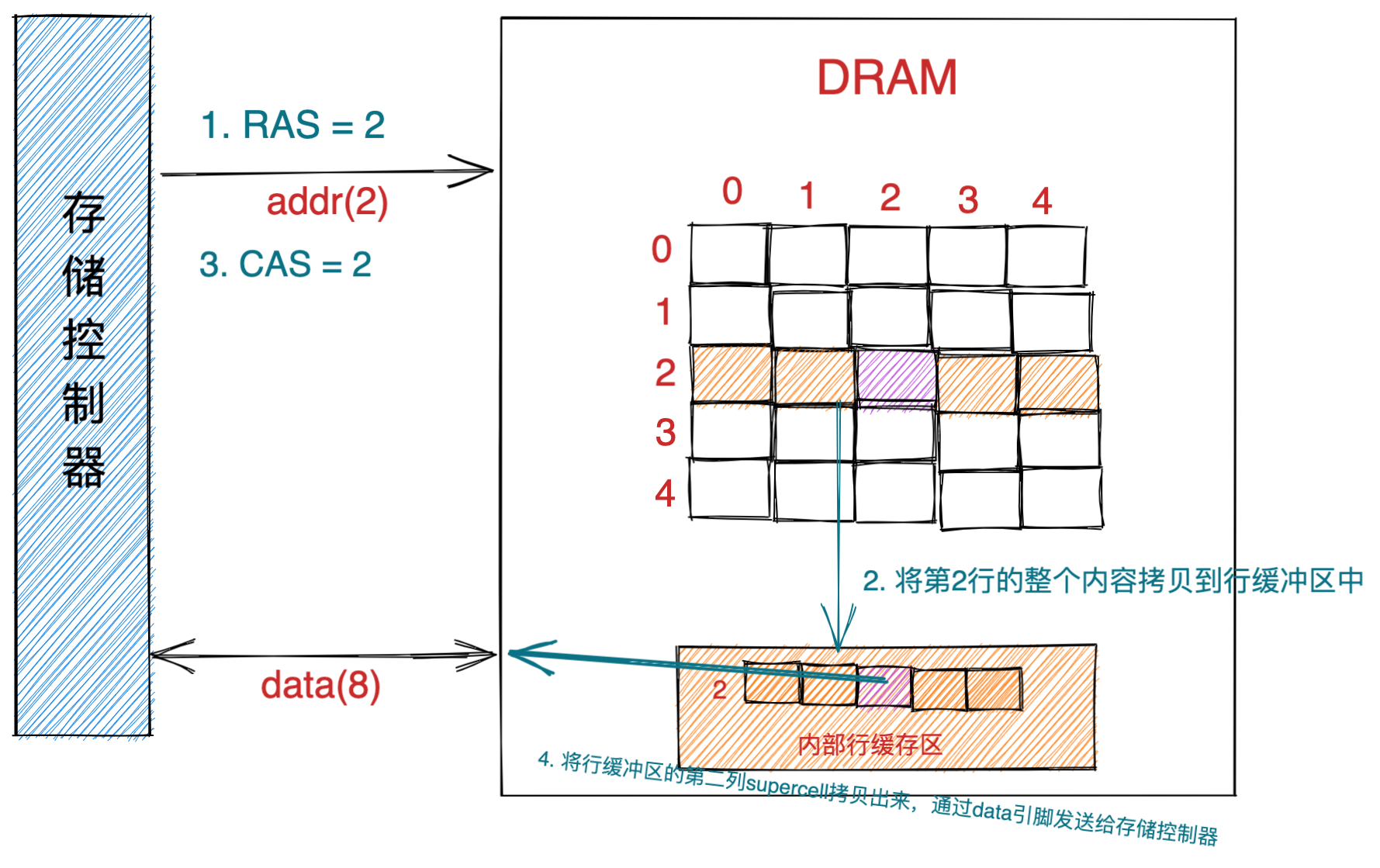
我们知道一个 supercell 存储了一个字节( 8 bit ) 数据,这里我们从 DRAM0 到 DRAM7 依次读取到了 8 个 supercell 也就是 8 个字节,然后将这 8 个字节返回给存储控制器,由存储控制器将数据放到存储总线上。
CPU 总是以 word size 为单位从内存中读取数据,在 64 位处理器中的 word size 为 8 个字节。64 位的内存每次只能吞吐 8 个字节。
CPU 每次会向内存读写一个 cache line 大小的数据( 64 个字节),但是内存一次只能吞吐 8 个字节。
所以在物理内存地址对应的存储器模块中,DRAM0 芯片存储第一个低位字节( supercell ),DRAM1 芯片存储第二个字节,……依次类推 DRAM7 芯片存储最后一个高位字节。
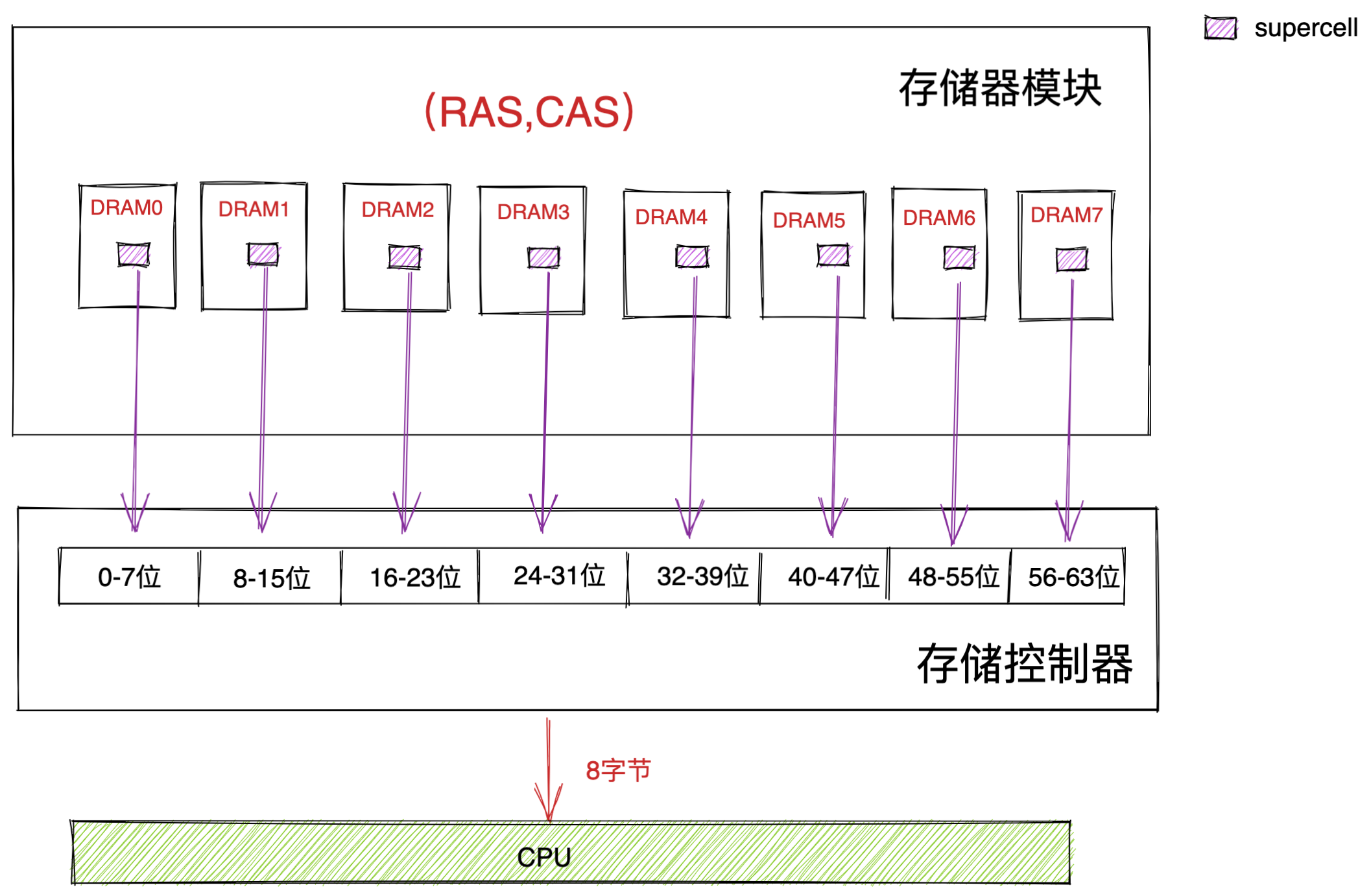
由于存储器模块中这种由 8 个 DRAM 芯片组成的物理存储结构的限制,内存读取数据只能是按照物理内存地址,8 个字节 8 个字节地顺序读取数据。所以说内存一次读取和写入的单位是 8 个字节。
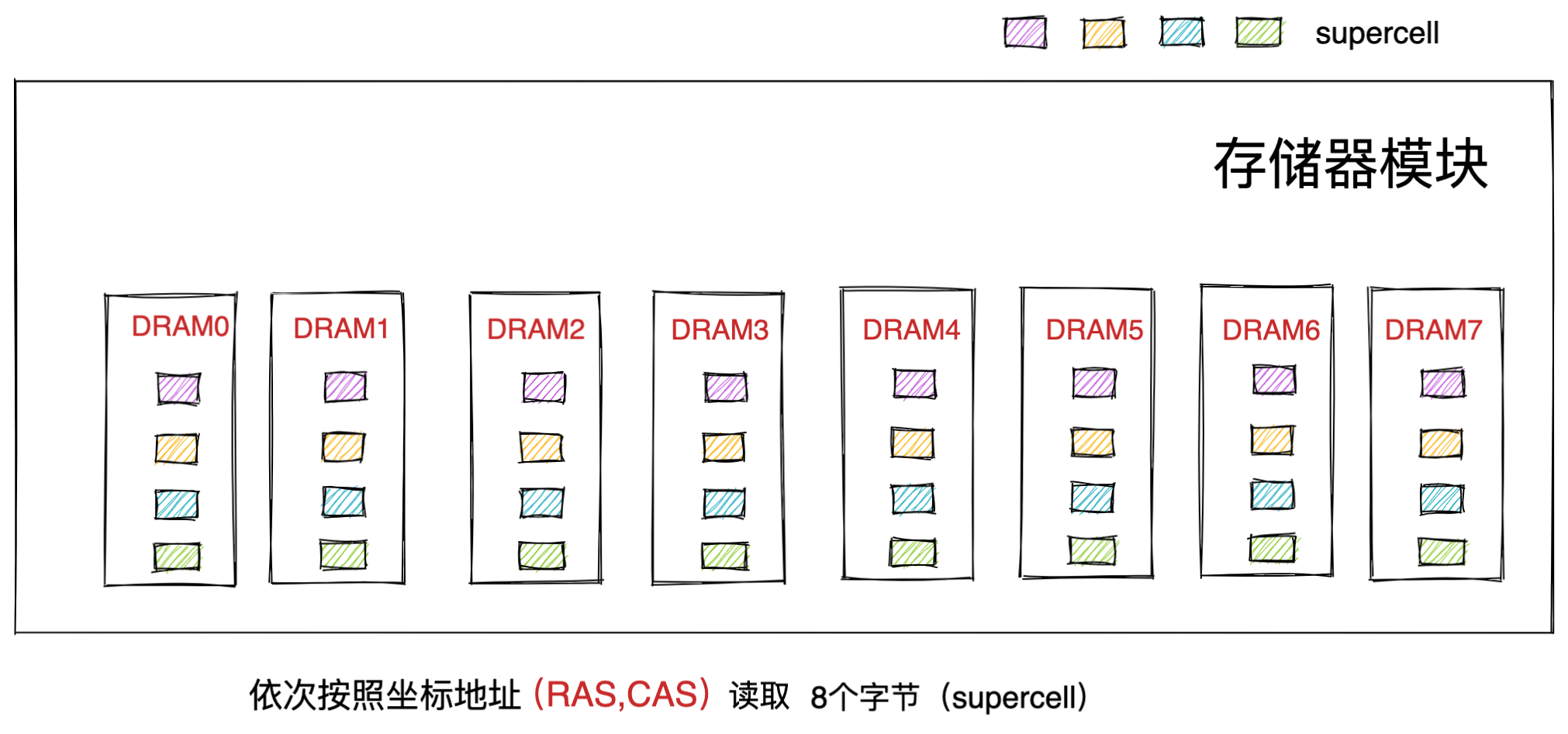
而且在程序员眼里连续的物理内存地址实际上在物理上是不连续的。因为这连续的 8 个字节其实是存储于不同的 DRAM 芯片上的。每个 DRAM 芯片存储一个字节(supercell)
CPU 向内存写入数据过程
我们现在假设 CPU 要将寄存器中的数据 X 写到物理内存地址 A 中。同样的道理,CPU 芯片中的总线接口会向总线发起写事务(write transaction)。写事务步骤如下:
- CPU 将要写入的物理内存地址 A 放入系统总线上。
- 通过 IO bridge 的信号转换,将物理内存地址 A 传递到存储总线上。
- 存储控制器感受到存储总线上的地址信号,将物理内存地址 A 从存储总线上读取出来,并等待数据的到达。
- CPU 将寄存器中的数据拷贝到系统总线上,通过 IO bridge 的信号转换,将数据传递到存储总线上。
- 存储控制器感受到存储总线上的数据信号,将数据从存储总线上读取出来。
- 存储控制器通过内存地址 A 定位到具体的存储器模块,最后将数据写入存储器模块中的 8 个 DRAM 芯片中。
总结
本文我们从虚拟内存地址开始聊起,一直到物理内存地址结束,包含的信息量还是比较大的。首先我通过一个进程的运行实例为大家引出了内核引入虚拟内存空间的目的及其需要解决的问题。
在我们有了虚拟内存空间的概念之后,我又近一步为大家介绍了内核如何划分用户态虚拟内存空间和内核态虚拟内存空间,并在次基础之上分别从 32 位体系结构和 64 位体系结构的角度详细阐述了 Linux 虚拟内存空间的整体布局分布。
- 我们可以通过
cat /proc/pid/maps或者pmap pid命令来查看进程用户态虚拟内存空间的实际分布。 - 还可以通过
cat /proc/iomem命令来查看进程内核态虚拟内存空间的的实际分布。
在我们清楚了 Linux 虚拟内存空间的整体布局分布之后,我又介绍了 Linux 内核如何对分布在虚拟内存空间中的各个虚拟内存区域进行管理,以及每个虚拟内存区域的作用。在这个过程中还介绍了相关的内核数据结构,近一步从内核源码实现角度加深大家对虚拟内存空间的理解。
最后我介绍了物理内存的结构,以及 CPU 如何通过物理内存地址来读写内存中的数据。这里我需要特地再次强调的是 CPU 只会访问虚拟内存地址,只不过在操作总线之前,通过一个地址转换硬件将虚拟内存地址转换为物理内存地址,然后将物理内存地址作为地址信号放在总线上传输,由于地址转换的内容和本文主旨无关,考虑到文章的篇幅以及复杂性,我就没有过多的介绍。
好了,本文的内容到这里就全部结束了,感谢大家的耐心观看。
深入理解Linux物理内存管理
在上篇文章 《深入理解 Linux 虚拟内存管理》 (opens new window)中,我分别从进程用户态和内核态的角度详细深入地为大家介绍了 Linux 内核如何对进程虚拟内存空间进行布局以及管理的相关实现。在我们深入理解了虚拟内存之后,那么何不顺带着也探秘一下物理内存的管理呢?
所以本文的目的是在深入理解虚拟内存管理的基础之上继续带大家向前奋进,一举击破物理内存管理的知识盲区,使大家能够俯瞰整个 Linux 内存管理子系统的整体全貌。
而在正式开始物理内存管理的主题之前,我觉得有必须在带大家回顾下上篇文章中介绍的虚拟内存管理的相关知识,方便大家来回对比虚拟内存和物理内存,从而可以全面整体地掌握 Linux 内存管理子系统。
在上篇文章的一开始,我首先为大家展现了我们应用程序频繁接触到的虚拟内存地址,清晰地为大家介绍了到底什么是虚拟内存地址,以及虚拟内存地址分别在 32 位系统和 64 位系统中的具体表现形式:
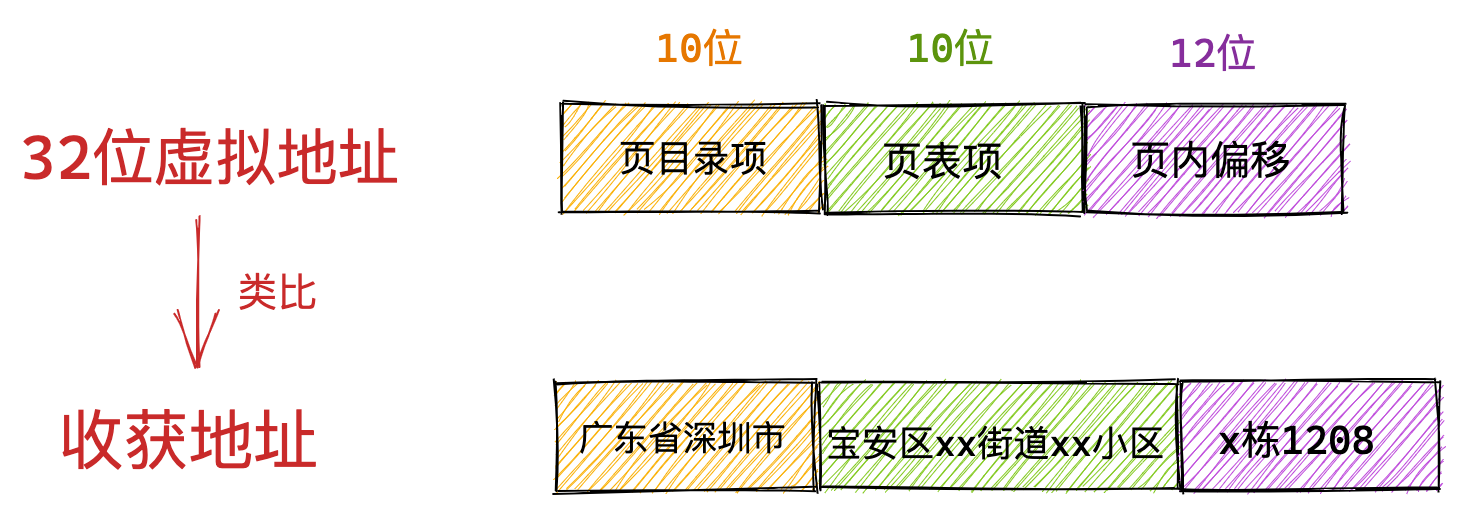
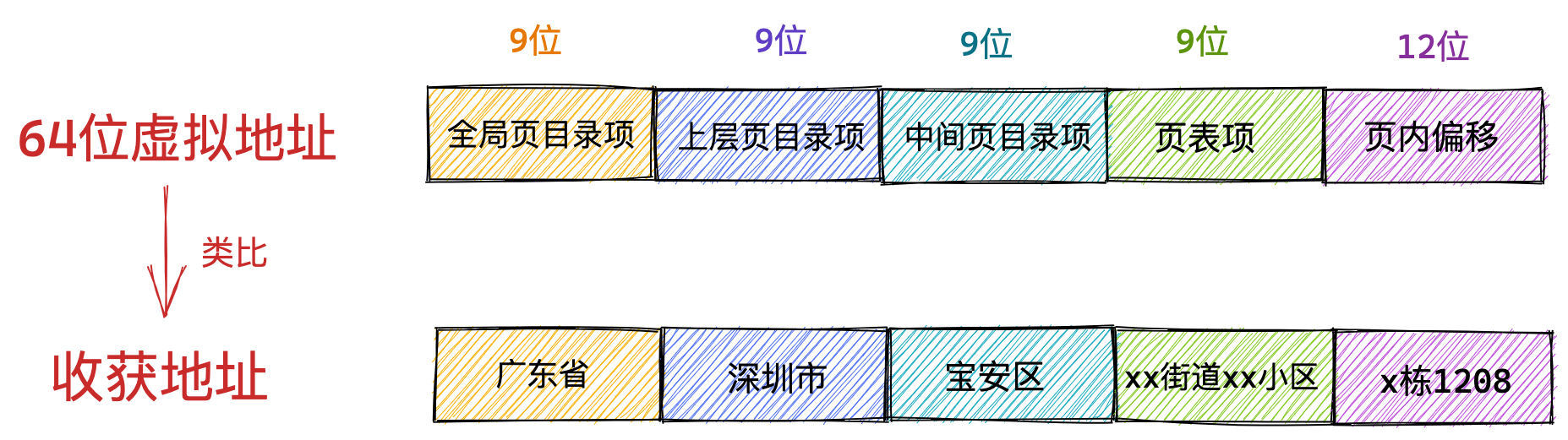
在我们清楚了虚拟内存地址这个基本概念之后,随后我又抛出了一个问题:为什么我们要通过虚拟内存地址访问内存而不是直接通过物理地址访问?
原来是在多进程系统中直接操作物理内存地址的话,我们需要精确地知道每一个变量的位置都被安排在了哪里,而且还要注意当前进程在和多个进程同时运行的时候,不能共用同一个地址,否则就会造成地址冲突。
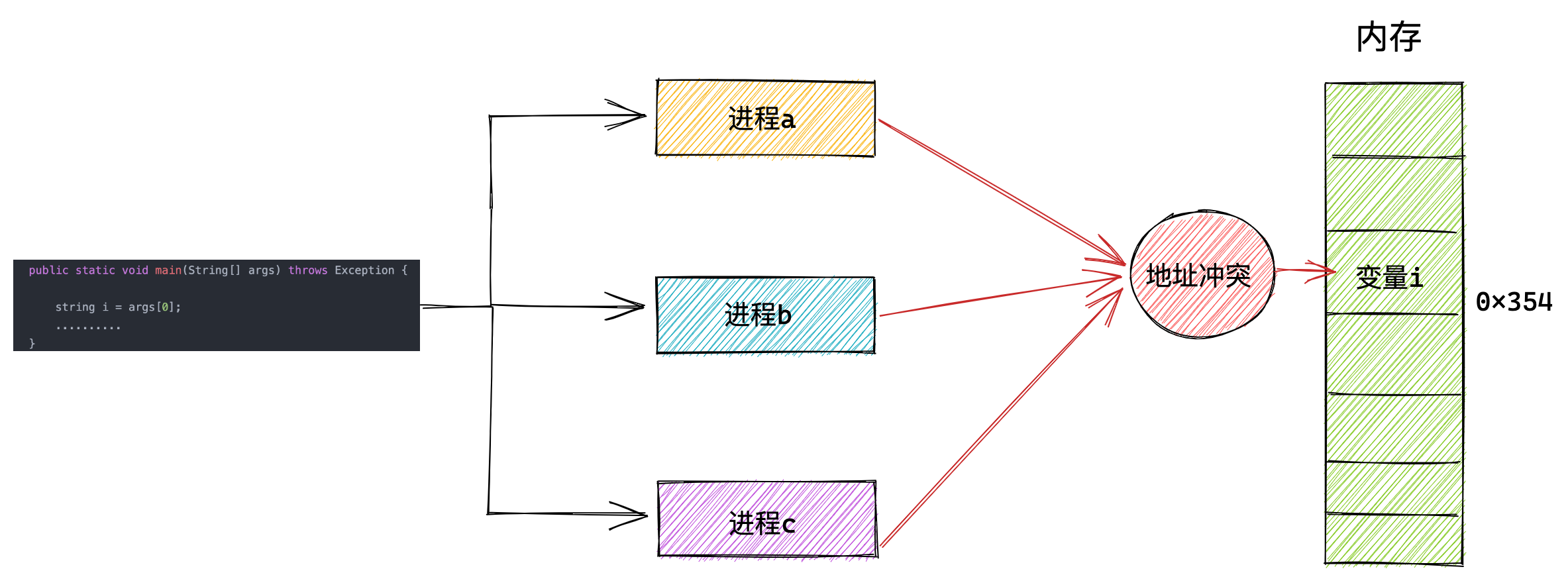
而虚拟内存空间的引入正是为了解决多进程地址冲突的问题,使得进程与进程之间的虚拟内存地址空间相互隔离,互不干扰。每个进程都认为自己独占所有内存空间,将多进程之间的协同相关细节统统交给内核中的内存管理模块来处理,极大地解放了程序员的心智负担。这一切都是因为虚拟内存能够为进程提供内存地址空间隔离的功劳。
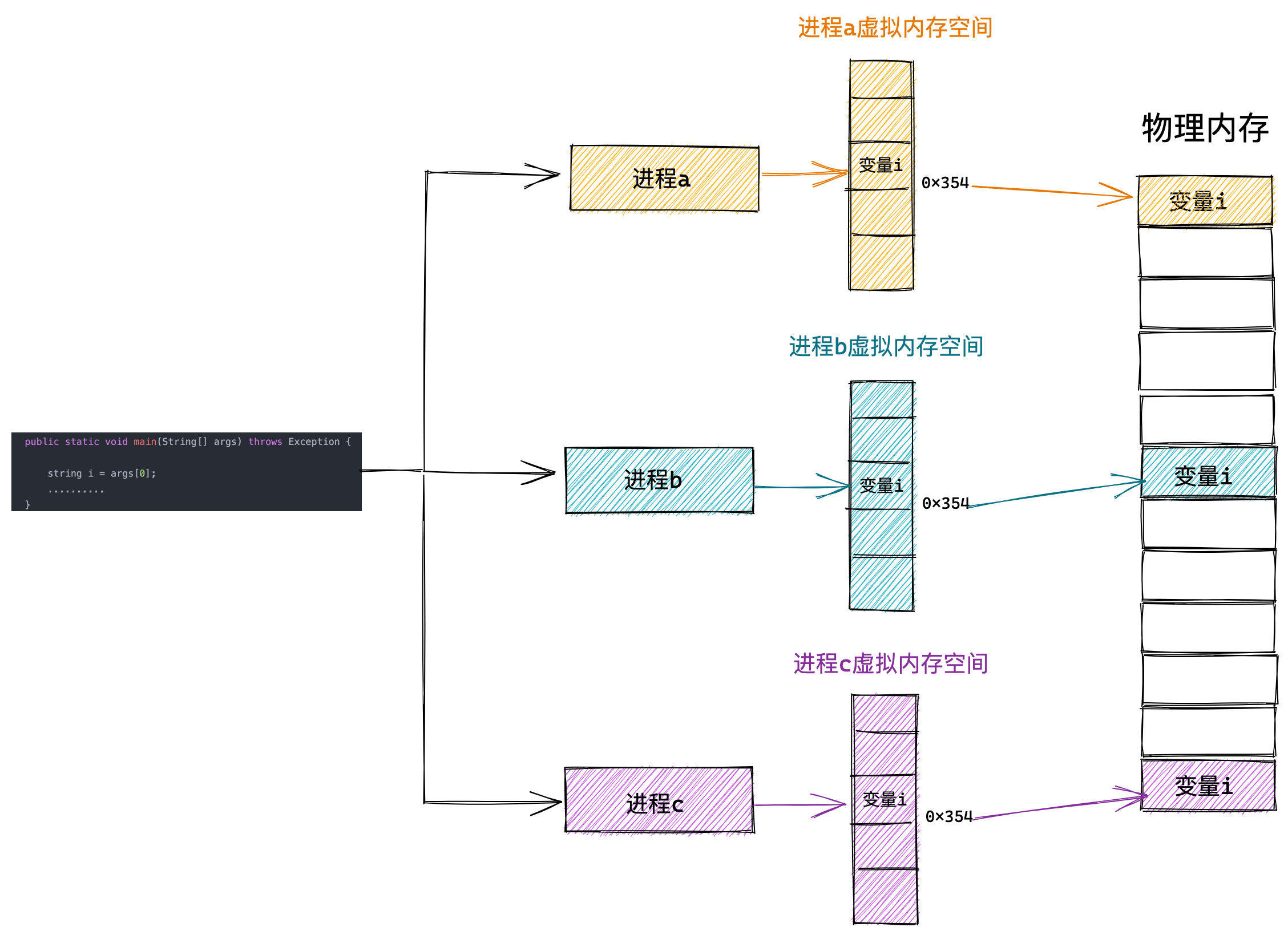
在我们清楚了虚拟内存空间引入的意义之后,我紧接着为大家介绍了进程用户态虚拟内存空间分别在 32 位机器和 64 位机器上的布局情况:
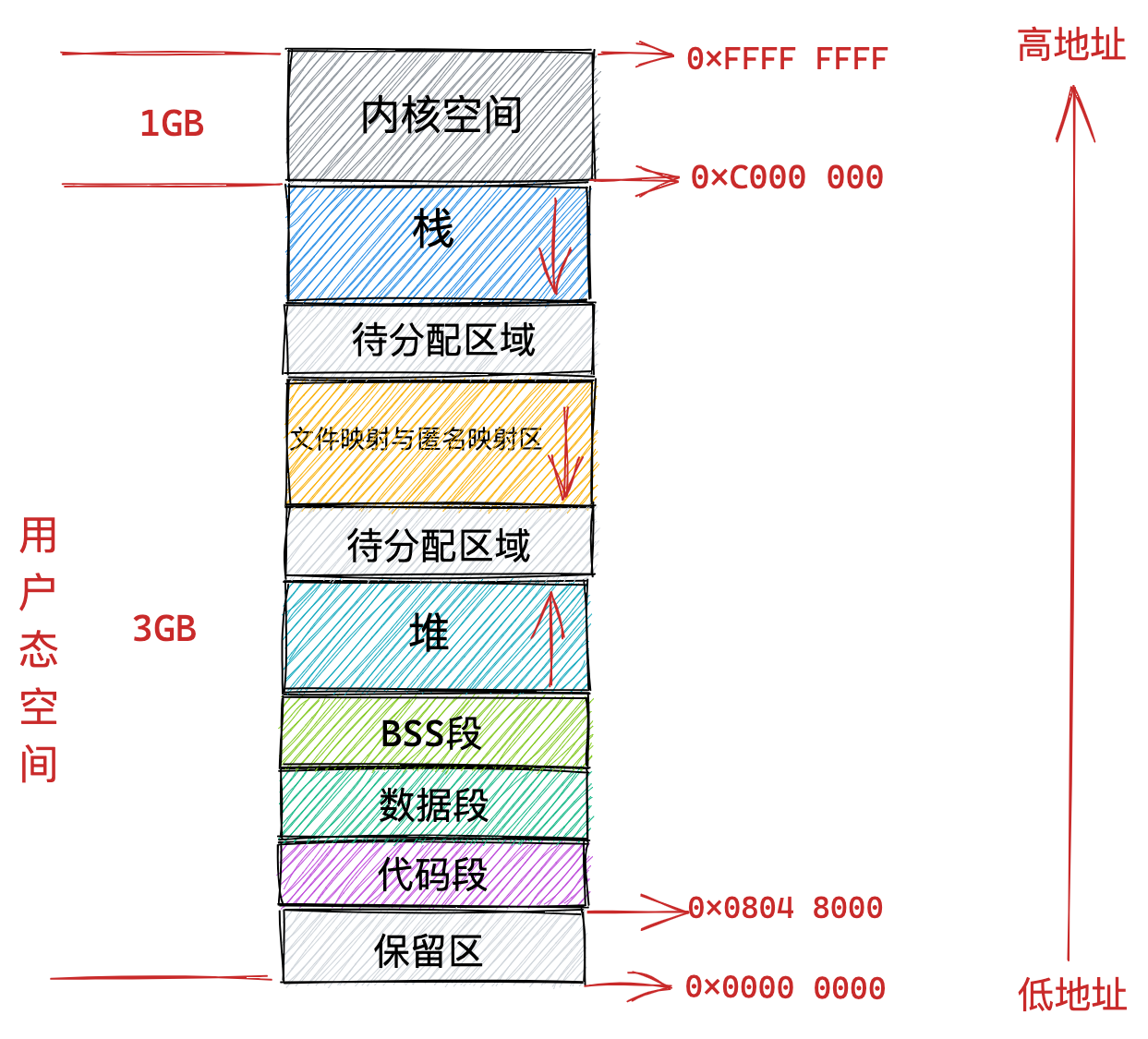
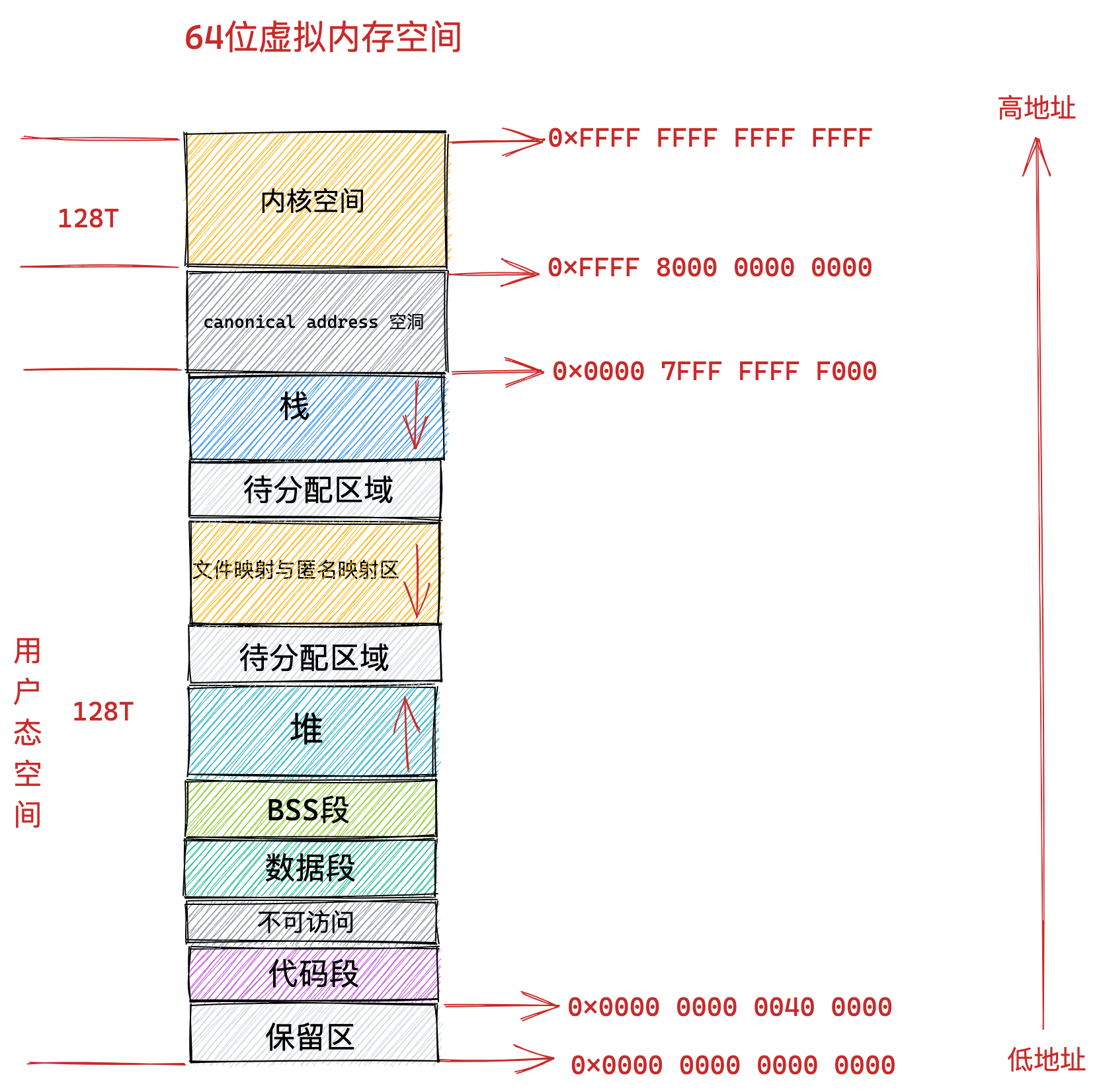
在了解了用户态虚拟内存空间的布局之后,紧接着我们又介绍了 Linux 内核如何对用户态虚拟内存空间进行管理以及相应的管理数据结构:
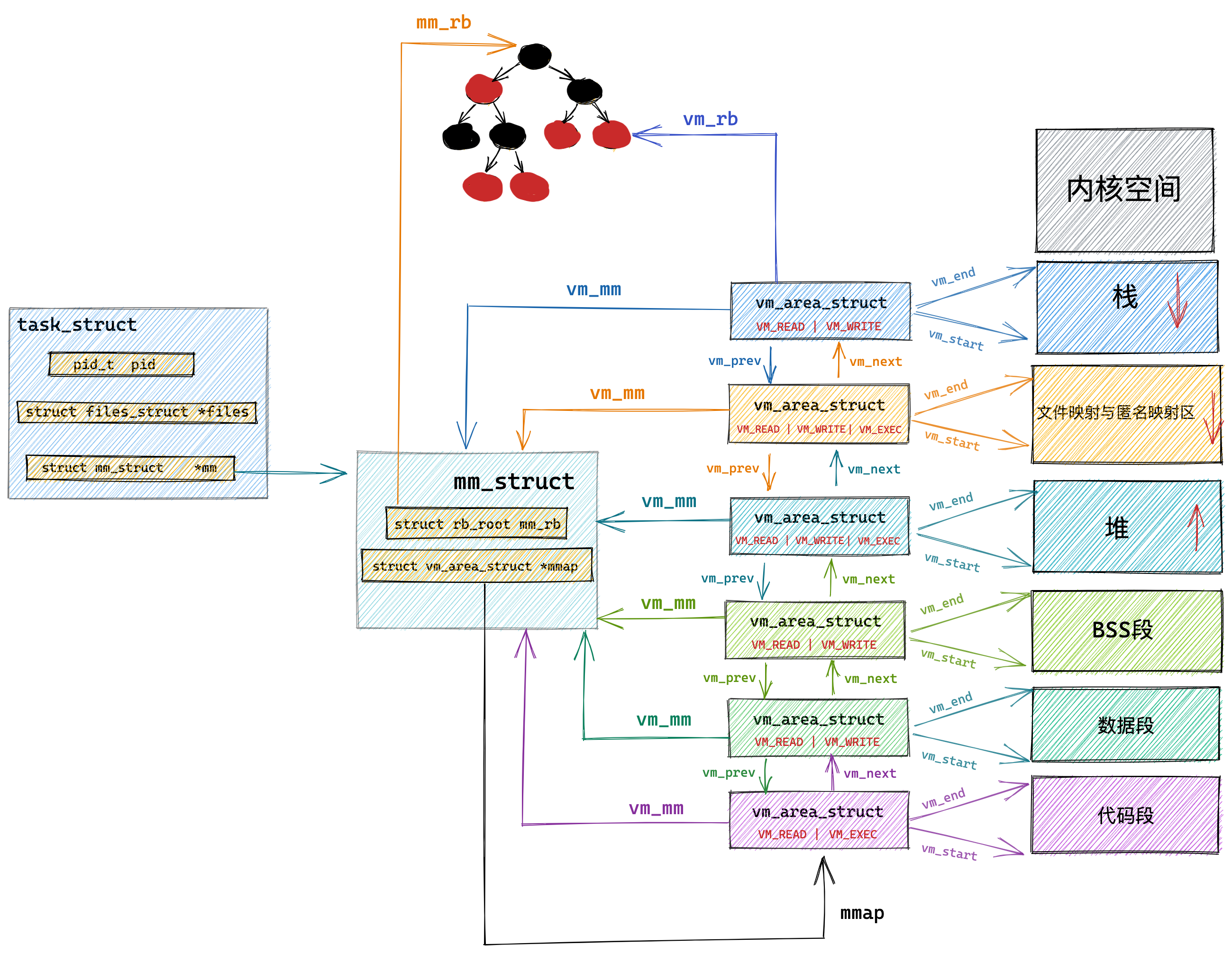
在介绍完用户态虚拟内存空间的布局以及管理之后,我们随后又介绍了内核态虚拟内存空间的布局情况,并结合之前介绍的用户态虚拟内存空间,得到了 Linux 虚拟内存空间分别在 32 位和 64 位系统中的整体布局情况:
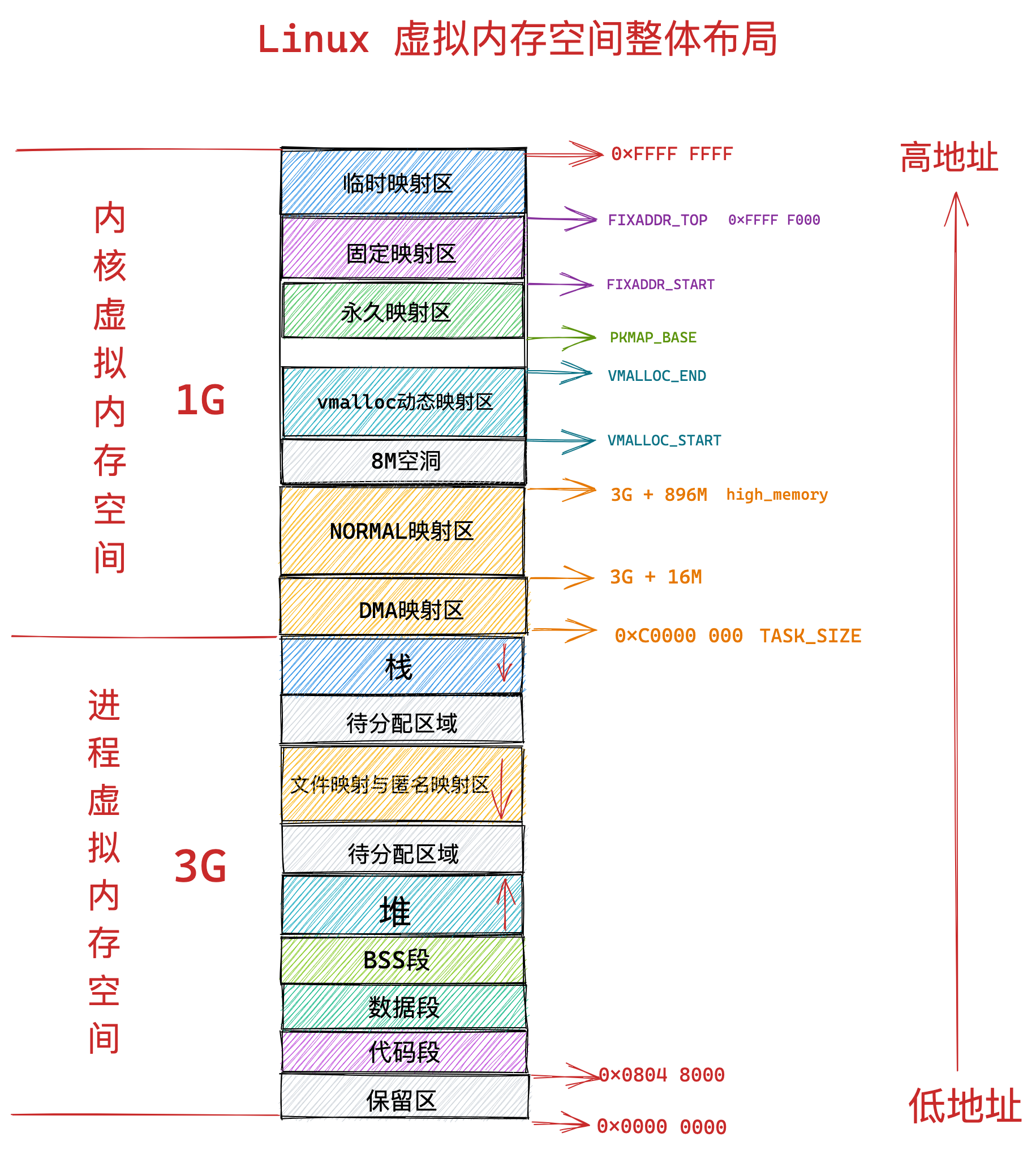
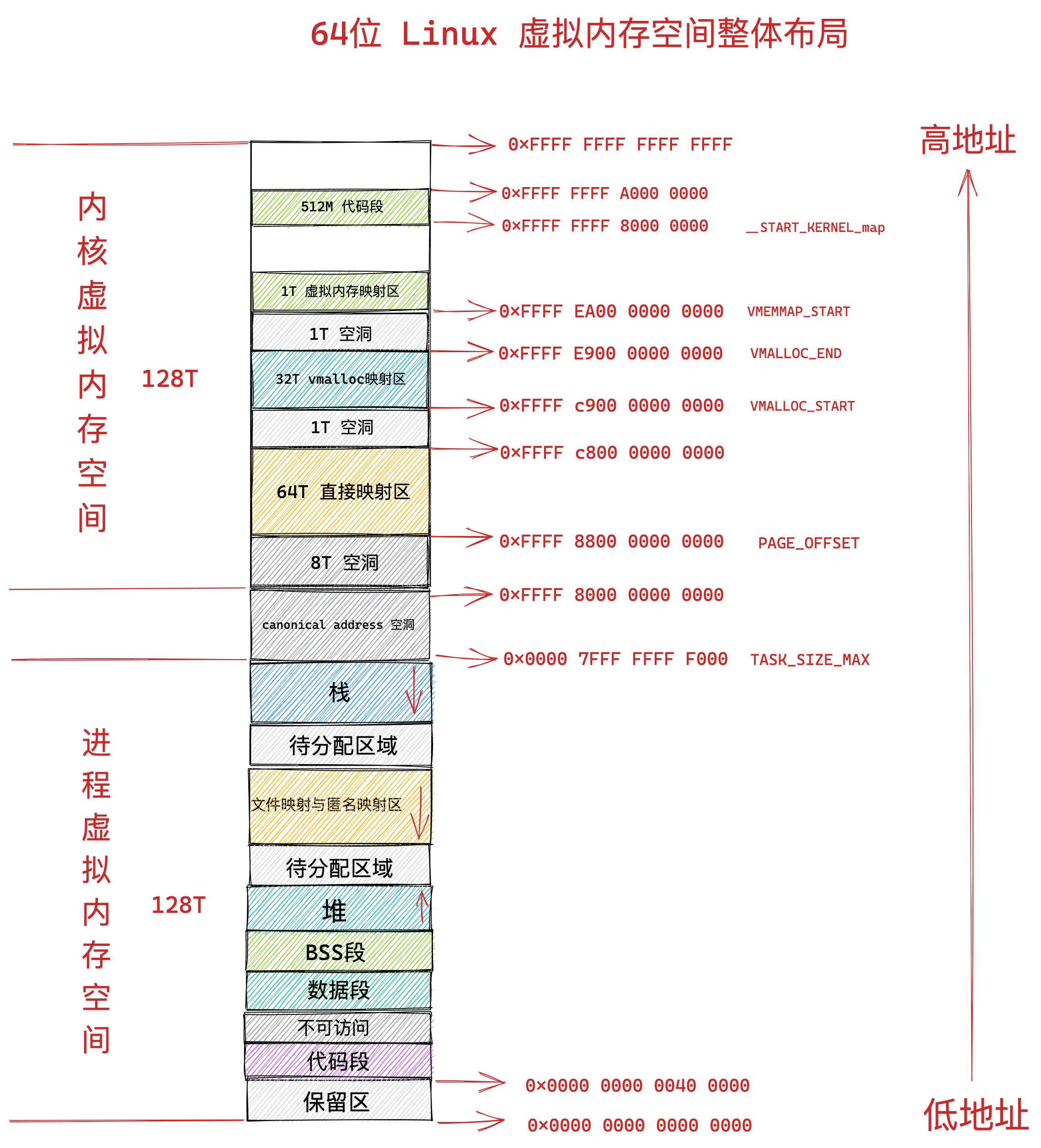
在虚拟内存全部介绍完毕之后,为了能够承上启下,于是我继续在上篇文章的最后一个小节从计算机组成原理的角度介绍了物理内存的物理组织结构,方便让大家理解到底什么是真正的物理内存 ?物理内存地址到底是什么 ?由此为本文的主题 —— 物理内存的管理 ,埋下伏笔~~~
最后我介绍了 CPU 如何通过物理内存地址向物理内存读写数据的完整过程:
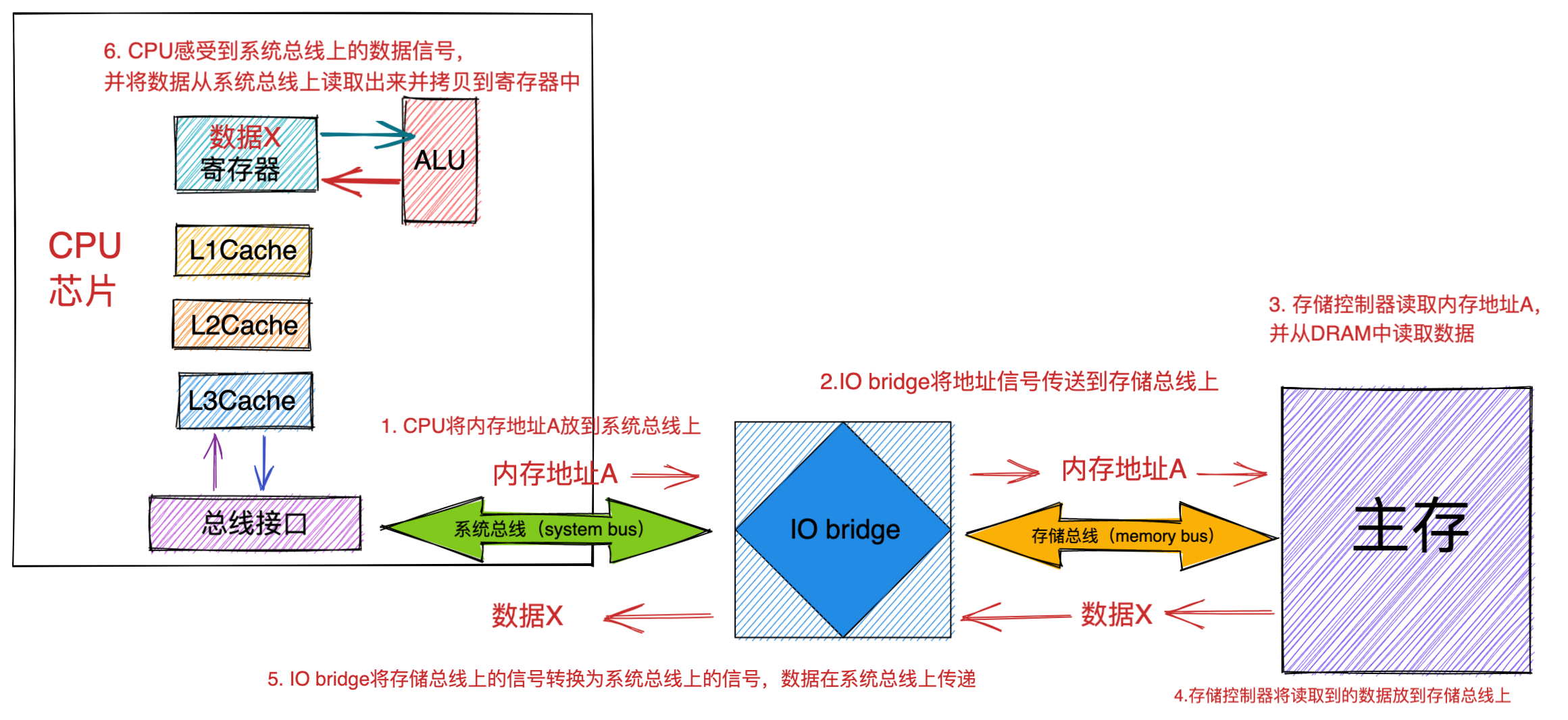
在我们回顾完上篇文章介绍的用户态和内核态虚拟内存空间的管理,以及物理内存在计算机中的真实组成结构之后,下面我就来正式地为大家介绍本文的主题 —— Linux 内核如何对物理内存进行管理
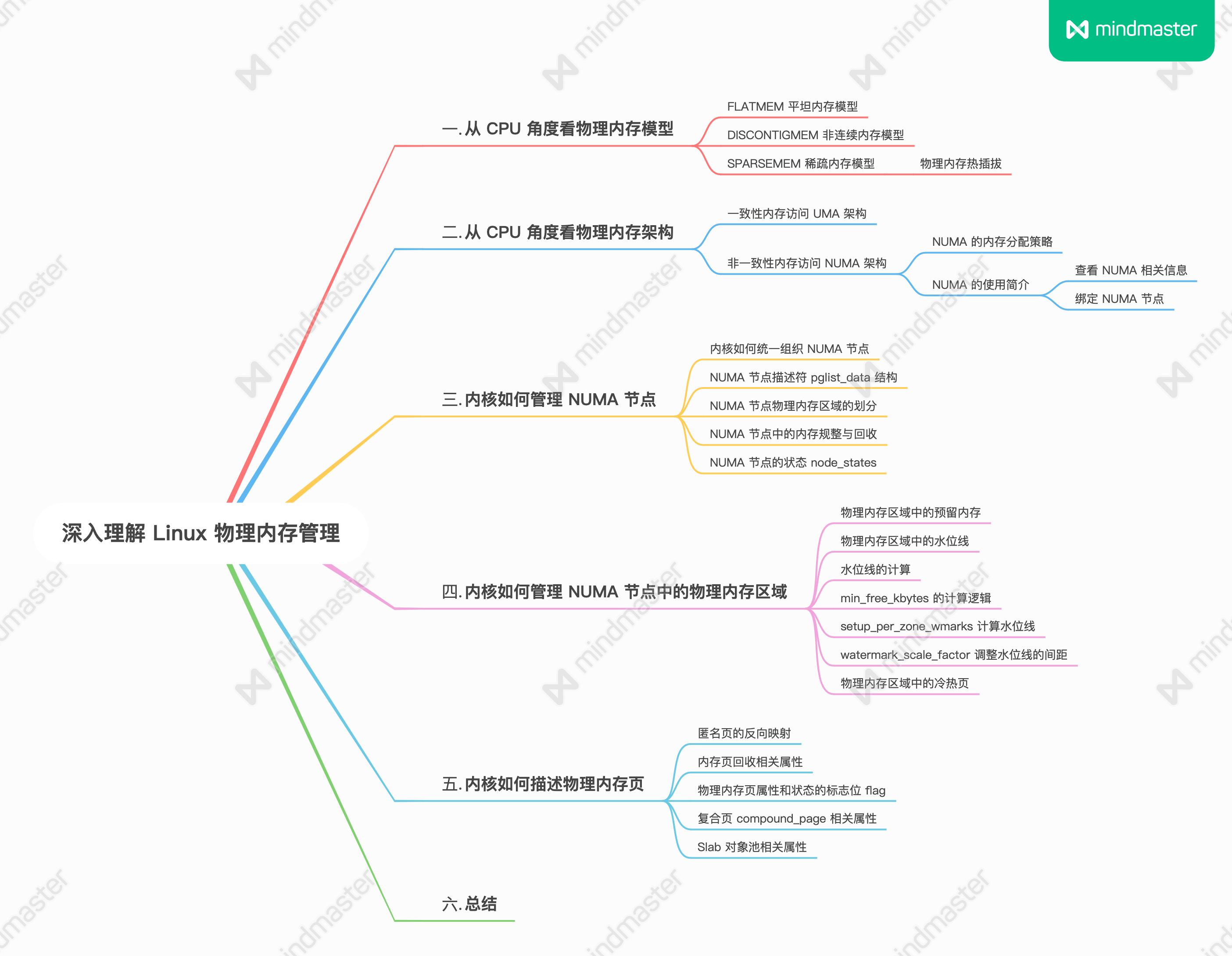
从 CPU 角度看物理内存模型
在前边的文章中,我曾多次提到内核是以页为基本单位对物理内存进行管理的,通过将物理内存划分为一页一页的内存块,每页大小为 4K。一页大小的内存块在内核中用 struct page 结构体来进行管理,struct page 中封装了每页内存块的状态信息,比如:组织结构,使用信息,统计信息,以及与其他结构的关联映射信息等。
而为了快速索引到具体的物理内存页,内核为每个物理页 struct page 结构体定义了一个索引编号:PFN(Page Frame Number)。PFN 与 struct page 是一一对应的关系。
内核提供了两个宏来完成 PFN 与 物理页结构体 struct page 之间的相互转换。它们分别是 page_to_pfn 与 pfn_to_page。
内核中如何组织管理这些物理内存页 struct page 的方式我们称之为做物理内存模型,不同的物理内存模型,应对的场景以及 page_to_pfn 与 pfn_to_page 的计算逻辑都是不一样的。
FLATMEM 平坦内存模型
我们先把物理内存想象成一片地址连续的存储空间,在这一大片地址连续的内存空间中,内核将这块内存空间分为一页一页的内存块 struct page 。
由于这块物理内存是连续的,物理地址也是连续的,划分出来的这一页一页的物理页必然也是连续的,并且每页的大小都是固定的,所以我们很容易想到用一个数组来组织这些连续的物理内存页 struct page 结构,其在数组中对应的下标即为 PFN 。这种内存模型就叫做平坦内存模型 FLATMEM 。
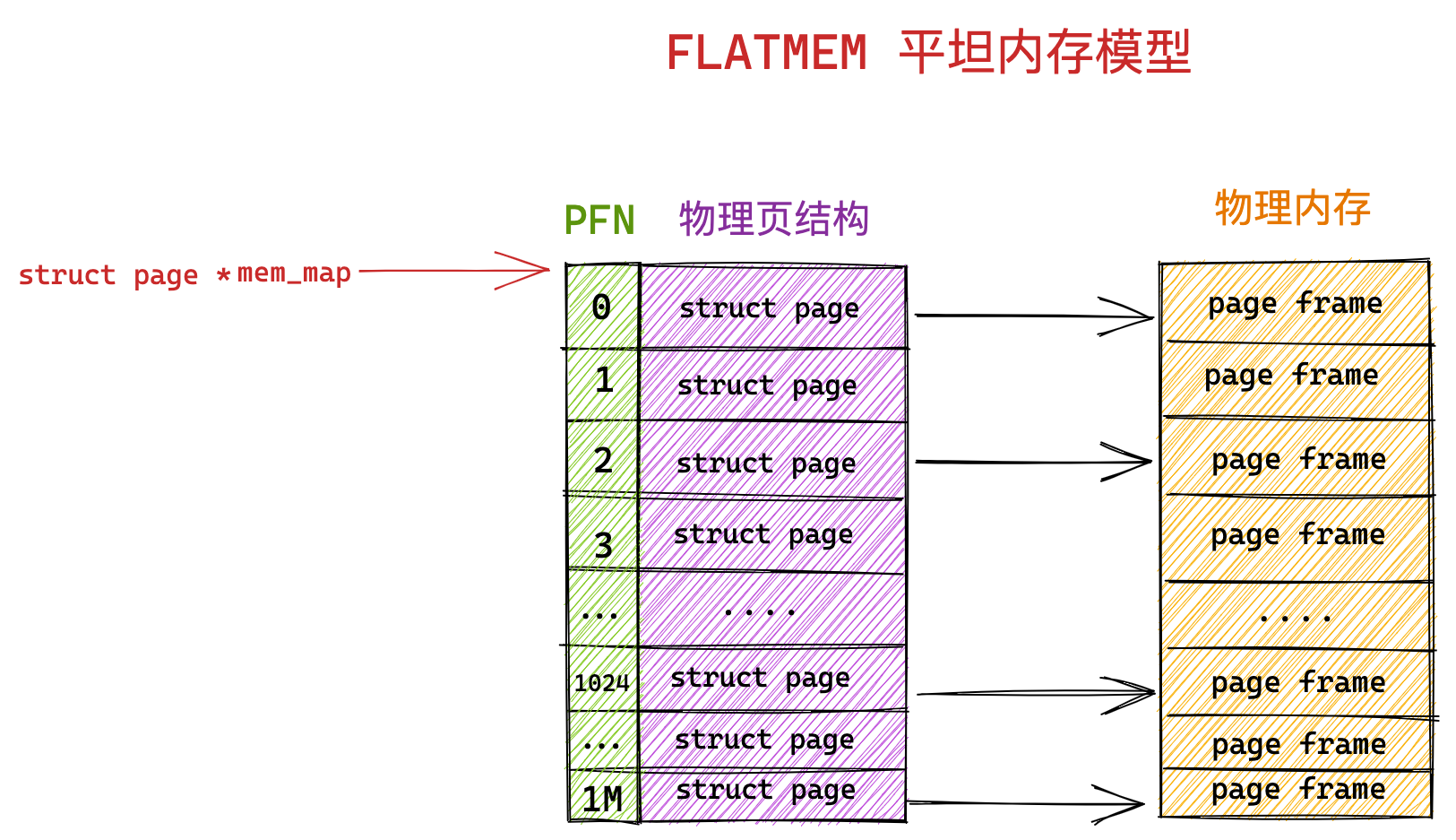
内核中使用了一个 mem_map 的全局数组用来组织所有划分出来的物理内存页。mem_map 全局数组的下标就是相应物理页对应的 PFN 。
在平坦内存模型下 ,page_to_pfn 与 pfn_to_page 的计算逻辑就非常简单,本质就是基于 mem_map 数组进行偏移操作。
|
|
ARCH_PFN_OFFSET 是 PFN 的起始偏移量。
Linux 早期使用的就是这种内存模型,因为在 Linux 发展的早期所需要管理的物理内存通常不大(比如几十 MB),那时的 Linux 使用平坦内存模型 FLATMEM 来管理物理内存就足够高效了。
内核中的默认配置是使用 FLATMEM 平坦内存模型。
DISCONTIGMEM 非连续内存模型
FLATMEM 平坦内存模型只适合管理一整块连续的物理内存,而对于多块非连续的物理内存来说使用 FLATMEM 平坦内存模型进行管理则会造成很大的内存空间浪费。
因为 FLATMEM 平坦内存模型是利用 mem_map 这样一个全局数组来组织这些被划分出来的物理页 page 的,而对于物理内存存在大量不连续的内存地址区间这种情况时,这些不连续的内存地址区间就形成了内存空洞。
由于用于组织物理页的底层数据结构是 mem_map 数组,数组的特性又要求这些物理页是连续的,所以只能为这些内存地址空洞也分配 struct page 结构用来填充数组使其连续。
而每个 struct page 结构大部分情况下需要占用 40 字节(struct page 结构在不同场景下内存占用会有所不同,这一点我们后面再说),如果物理内存中存在的大块的地址空洞,那么为这些空洞而分配的 struct page 将会占用大量的内存空间,导致巨大的浪费。
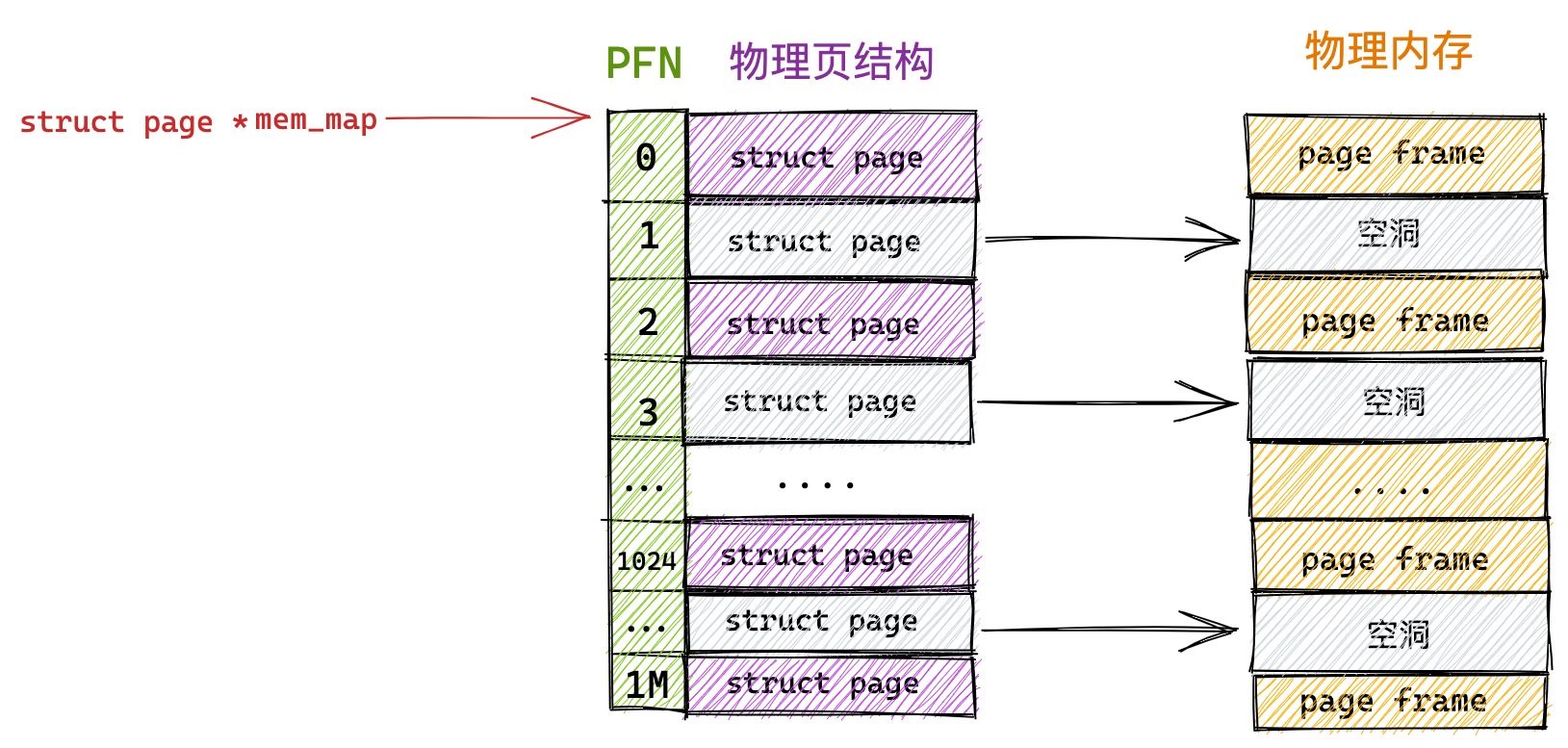
为了组织和管理这些不连续的物理内存,内核于是引入了 DISCONTIGMEM 非连续内存模型,用来消除这些不连续的内存地址空洞对 mem_map 的空间浪费。
在 DISCONTIGMEM 非连续内存模型中,内核将物理内存从宏观上划分成了一个一个的节点 node (微观上还是一页一页的物理页),每个 node 节点管理一块连续的物理内存。这样一来这些连续的物理内存页均被划归到了对应的 node 节点中管理,就避免了内存空洞造成的空间浪费。
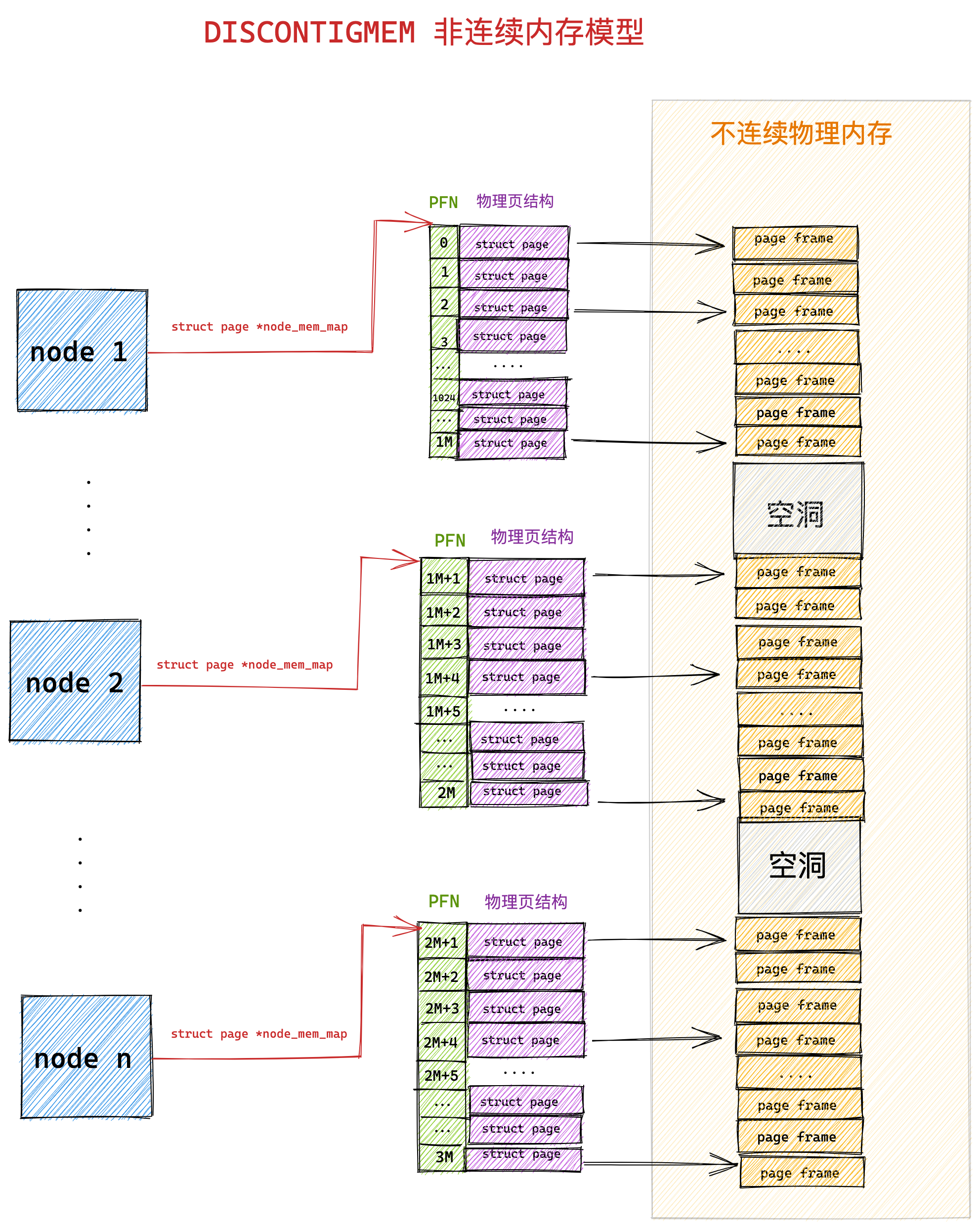
内核中使用 struct pglist_data 表示用于管理连续物理内存的 node 节点(内核假设 node 中的物理内存是连续的),既然每个 node 节点中的物理内存是连续的,于是在每个 node 节点中还是采用 FLATMEM 平坦内存模型的方式来组织管理物理内存页。每个 node 节点中包含一个 struct page *node_mem_map 数组,用来组织管理 node 中的连续物理内存页。
|
|
我们可以看出 DISCONTIGMEM 非连续内存模型其实就是 FLATMEM 平坦内存模型的一种扩展,在面对大块不连续的物理内存管理时,通过将每段连续的物理内存区间划归到 node 节点中进行管理,避免了为内存地址空洞分配 struct page 结构,从而节省了内存资源的开销。
由于引入了 node 节点这个概念,所以在 DISCONTIGMEM 非连续内存模型下 page_to_pfn 与 pfn_to_page 的计算逻辑就比 FLATMEM 内存模型下的计算逻辑多了一步定位 page 所在 node 的操作。
- 通过 arch_pfn_to_nid 可以根据物理页的 PFN 定位到物理页所在 node。
- 通过 page_to_nid 可以根据物理页结构 struct page 定义到 page 所在 node。
当定位到物理页 struct page 所在 node 之后,剩下的逻辑就和 FLATMEM 内存模型一模一样了。
|
|
SPARSEMEM 稀疏内存模型
随着内存技术的发展,内核可以支持物理内存的热插拔了(后面我会介绍),这样一来物理内存的不连续就变为常态了,在上小节介绍的 DISCONTIGMEM 内存模型中,其实每个 node 中的物理内存也不一定都是连续的。
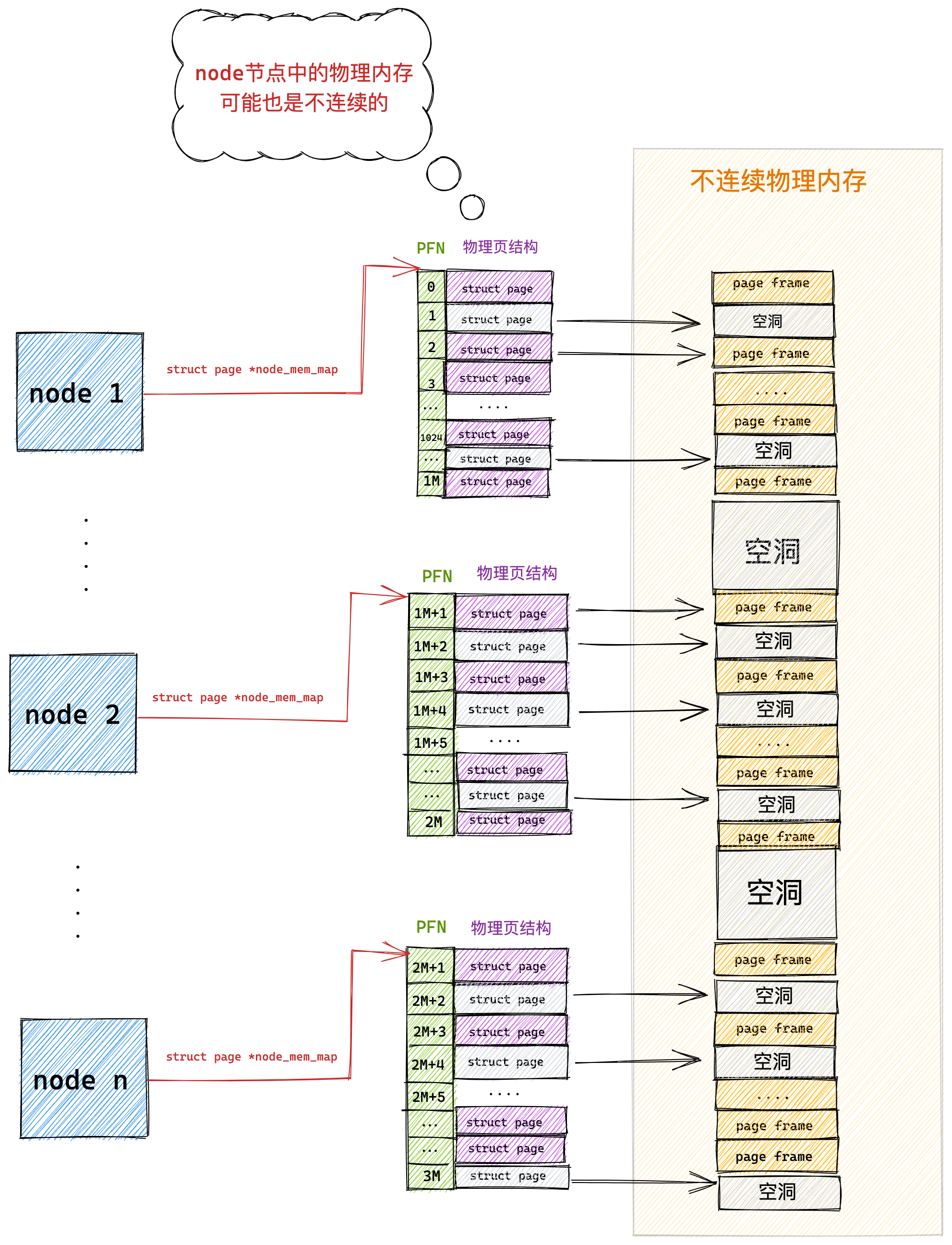
而且每个 node 中都有一套完整的内存管理系统,如果 node 数目多的话,那这个开销就大了,于是就有了对连续物理内存更细粒度的管理需求,为了能够更灵活地管理粒度更小的连续物理内存,SPARSEMEM 稀疏内存模型就此登场了。
SPARSEMEM 稀疏内存模型的核心思想就是对粒度更小的连续内存块进行精细的管理,用于管理连续内存块的单元被称作 section 。物理页大小为 4k 的情况下, section 的大小为 128M ,物理页大小为 16k 的情况下, section 的大小为 512M。
在内核中用 struct mem_section 结构体表示 SPARSEMEM 模型中的 section。
|
|
由于 section 被用作管理小粒度的连续内存块,这些小的连续物理内存在 section 中也是通过数组的方式被组织管理,每个 struct mem_section 结构体中有一个 section_mem_map 指针用于指向 section 中管理连续内存的 page 数组。
SPARSEMEM 内存模型中的这些所有的 mem_section 会被存放在一个全局的数组中,并且每个 mem_section 都可以在系统运行时改变 offline / online (下线 / 上线)状态,以便支持内存的热插拔(hotplug)功能。
|
|
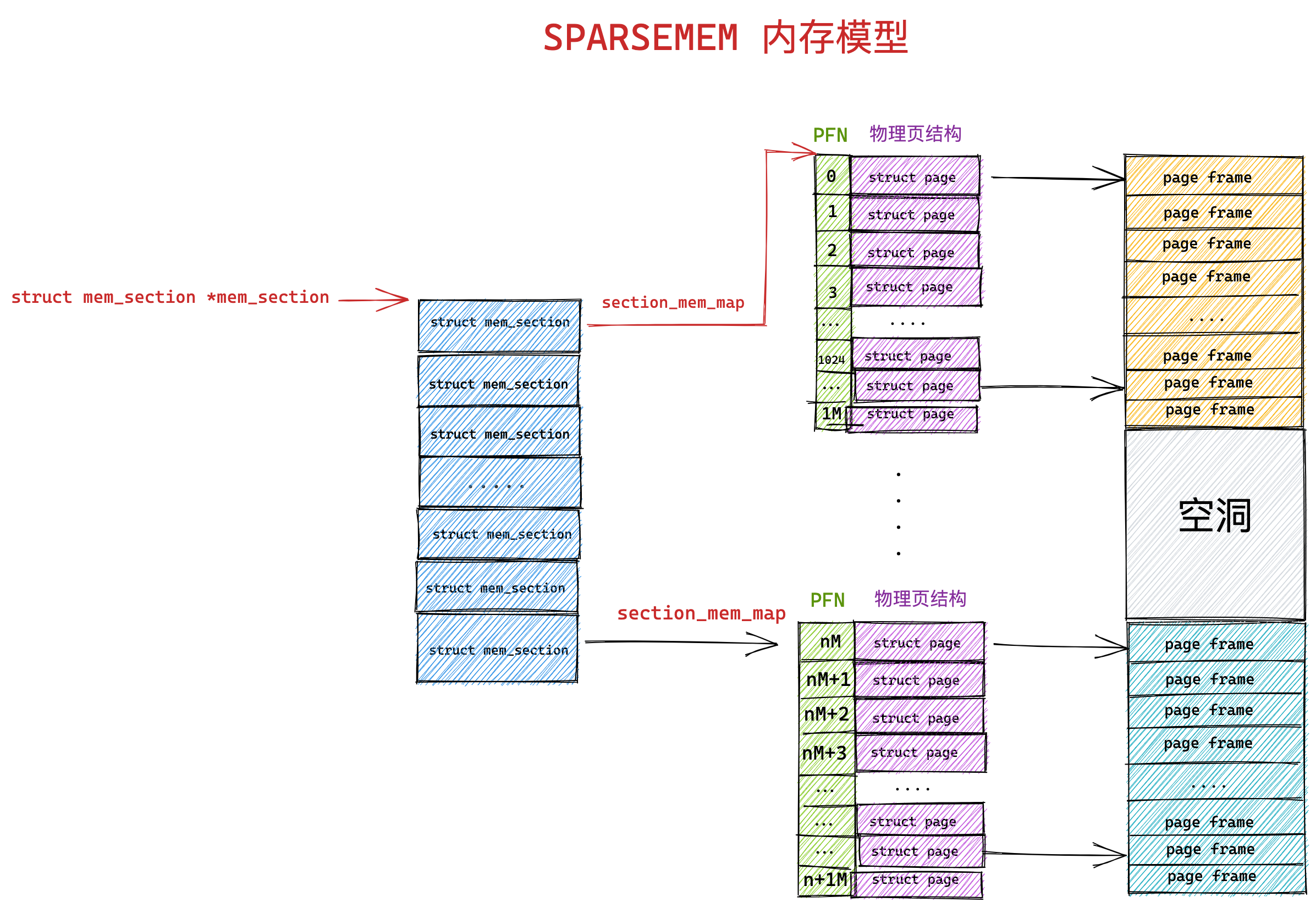
在 SPARSEMEM 稀疏内存模型下 page_to_pfn 与 pfn_to_page 的计算逻辑又发生了变化。
- 在 page_to_pfn 的转换中,首先需要通过 page_to_section 根据 struct page 结构定位到 mem_section 数组中具体的 section 结构。然后在通过 section_mem_map 定位到具体的 PFN。
在 struct page 结构中有一个
unsigned long flags属性,在 flag 的高位 bit 中存储着 page 所在 mem_section 数组中的索引,从而可以定位到所属 section。
- 在 pfn_to_page 的转换中,首先需要通过 __pfn_to_section 根据 PFN 定位到 mem_section 数组中具体的 section 结构。然后在通过 PFN 在 section_mem_map 数组中定位到具体的物理页 Page 。
PFN 的高位 bit 存储的是全局数组 mem_section 中的 section 索引,PFN 的低位 bit 存储的是 section_mem_map 数组中具体物理页 page 的索引。
|
|
从以上的内容介绍中,我们可以看出 SPARSEMEM 稀疏内存模型已经完全覆盖了前两个内存模型的所有功能,因此稀疏内存模型可被用于所有内存布局的情况。
物理内存热插拔
前面提到随着内存技术的发展,物理内存的热插拔 hotplug 在内核中得到了支持,由于物理内存可以动态的从主板中插入以及拔出,所以导致了物理内存的不连续已经成为常态,因此内核引入了 SPARSEMEM 稀疏内存模型以便应对这种情况,提供对更小粒度的连续物理内存的灵活管理能力。
本小节我就为大家介绍一下物理内存热插拔 hotplug 功能在内核中的实现原理,作为 SPARSEMEM 稀疏内存模型的扩展内容补充。
在大规模的集群中,尤其是现在我们处于云原生的时代,为了实现集群资源的动态均衡,可以通过物理内存热插拔的功能实现集群机器物理内存容量的动态增减。
集群的规模一大,那么物理内存出故障的几率也会大大增加,物理内存的热插拔对提供集群高可用性也是至关重要的。
从总体上来讲,内存的热插拔分为两个阶段:
- 物理热插拔阶段:这个阶段主要是从物理上将内存硬件插入(hot-add),拔出(hot-remove)主板的过程,其中涉及到硬件和内核的支持。
- 逻辑热插拔阶段:这一阶段主要是由内核中的内存管理子系统来负责,涉及到的主要工作为:如何动态的上线启用(online)刚刚 hot-add 的内存,如何动态下线(offline)刚刚 hot-remove 的内存。
物理内存拔出的过程需要关注的事情比插入的过程要多的多,实现起来也更加的困难, 这就好比在《Java 技术栈中间件优雅停机方案设计与实现全景图》 (opens new window)一文中我们讨论服务优雅启动,停机时提到的:优雅停机永远比优雅启动要考虑的场景要复杂的多,因为停机的时候,线上的服务正在承载着生产的流量需要确保做到业务无损。
同样的道理,物理内存插入比较好说,困难的是物理内存的动态拔出,因为此时即将要被拔出的物理内存中可能已经为进程分配了物理页,如何妥善安置这些已经被分配的物理页是一个棘手的问题。
前边我们介绍 SPARSEMEM 内存模型的时候提到,每个 mem_section 都可以在系统运行时改变 offline ,online 状态,以便支持内存的热插拔(hotplug)功能。 当 mem_section offline 时, 内核会把这部分内存隔离开, 使得该部分内存不可再被使用, 然后再把 mem_section 中已经分配的内存页迁移到其他 mem_section 的内存上. 。
但是这里会有一个问题,就是并非所有的物理页都可以迁移,因为迁移意味着物理内存地址的变化,而内存的热插拔应该对进程来说是透明的,所以这些迁移后的物理页映射的虚拟内存地址是不能变化的。
这一点在进程的用户空间是没有问题的,因为进程在用户空间访问内存都是根据虚拟内存地址通过页表找到对应的物理内存地址,这些迁移之后的物理页,虽然物理内存地址发生变化,但是内核通过修改相应页表中虚拟内存地址与物理内存地址之间的映射关系,可以保证虚拟内存地址不会改变。
但是在内核态的虚拟地址空间中,有一段直接映射区,在这段虚拟内存区域中虚拟地址与物理地址是直接映射的关系,虚拟内存地址直接减去一个固定的偏移量(0xC000 0000 ) 就得到了物理内存地址。
直接映射区中的物理页的虚拟地址会随着物理内存地址变动而变动, 因此这部分物理页是无法轻易迁移的,然而不可迁移的页会导致内存无法被拔除,因为无法妥善安置被拔出内存中已经为进程分配的物理页。那么内核是如何解决这个头疼的问题呢?
既然是这些不可迁移的物理页导致内存无法拔出,那么我们可以把内存分一下类,将内存按照物理页是否可迁移,划分为不可迁移页,可回收页,可迁移页。
大家这里需要记住一点,内核会将物理内存按照页面是否可迁移的特性进行分类,我后面在介绍内核如何避免内存碎片的时候还会在提到
然后在这些可能会被拔出的内存中只分配那些可迁移的内存页,这些信息会在内存初始化的时候被设置,这样一来那些不可迁移的页就不会包含在可能会拔出的内存中,当我们需要将这块内存热拔出时, 因为里边的内存页全部是可迁移的, 从而使内存可以被拔除。
从 CPU 角度看物理内存架构
在上小节中我为大家介绍了三种物理内存模型,这三种物理内存模型是从 CPU 的视角来看待物理内存内部是如何布局,组织以及管理的,主角是物理内存。
在本小节中我为大家提供一个新的视角,这一次我们把物理内存看成一个整体,从 CPU 访问物理内存的角度来看一下物理内存的架构,并从 CPU 与物理内存的相对位置变化来看一下不同物理内存架构下对性能的影响。
一致性内存访问 UMA 架构
我们在上篇文章 《深入理解 Linux 虚拟内存管理》 (opens new window)的 “ 8.2 CPU 如何读写主存” 小节中提到 CPU 与内存之间的交互是通过总线完成的。
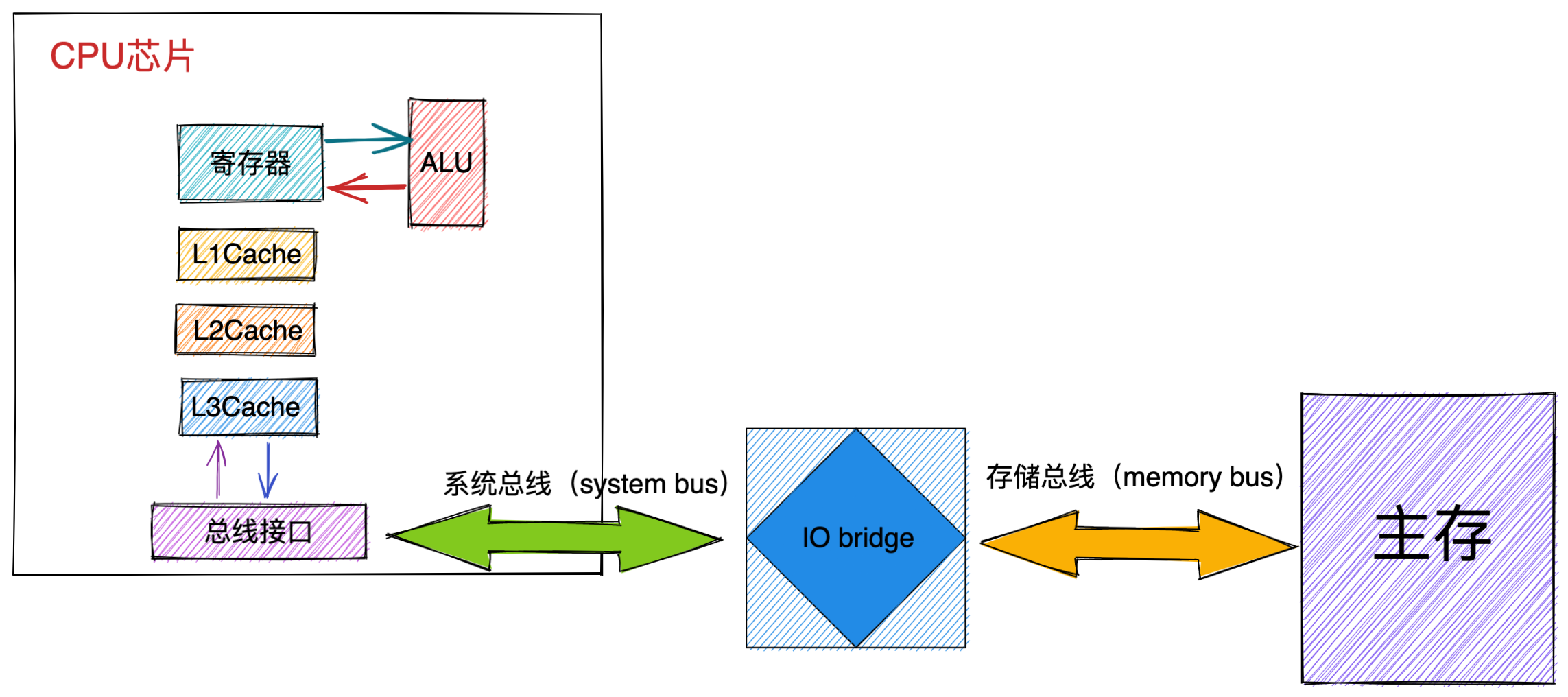
- 首先 CPU 将物理内存地址作为地址信号放到系统总线上传输。随后 IO bridge 将系统总线上的地址信号转换为存储总线上的电子信号。
- 主存感受到存储总线上的地址信号并通过存储控制器将存储总线上的物理内存地址 A 读取出来。
- 存储控制器通过物理内存地址定位到具体的存储器模块,从 DRAM 芯片中取出物理内存地址对应的数据。
- 存储控制器将读取到的数据放到存储总线上,随后 IO bridge 将存储总线上的数据信号转换为系统总线上的数据信号,然后继续沿着系统总线传递。
- CPU 芯片感受到系统总线上的数据信号,将数据从系统总线上读取出来并拷贝到寄存器中。
上图展示的是单核 CPU 访问内存的架构图,那么在多核服务器中多个 CPU 与内存之间的架构关系又是什么样子的呢?
在 UMA 架构下,多核服务器中的多个 CPU 位于总线的一侧,所有的内存条组成一大片内存位于总线的另一侧,所有的 CPU 访问内存都要过总线,而且距离都是一样的,由于所有 CPU 对内存的访问距离都是一样的,所以在 UMA 架构下所有 CPU 访问内存的速度都是一样的。这种访问模式称为 SMP(Symmetric multiprocessing),即对称多处理器。
这里的一致性是指同一个 CPU 对所有内存的访问的速度是一样的。即一致性内存访问 UMA(Uniform Memory Access)。
但是随着多核技术的发展,服务器上的 CPU 个数会越来越多,而 UMA 架构下所有 CPU 都是需要通过总线来访问内存的,这样总线很快就会成为性能瓶颈,主要体现在以下两个方面:
- 总线的带宽压力会越来越大,随着 CPU 个数的增多导致每个 CPU 可用带宽会减少
- 总线的长度也会因此而增加,进而增加访问延迟
UMA 架构的优点很明显就是结构简单,所有的 CPU 访问内存速度都是一致的,都必须经过总线。然而它的缺点我刚刚也提到了,就是随着处理器核数的增多,总线的带宽压力会越来越大。解决办法就只能扩宽总线,然而成本十分高昂,未来可能仍然面临带宽压力。
为了解决以上问题,提高 CPU 访问内存的性能和扩展性,于是引入了一种新的架构:非一致性内存访问 NUMA(Non-uniform memory access)。
非一致性内存访问 NUMA 架构
在 NUMA 架构下,内存就不是一整片的了,而是被划分成了一个一个的内存节点 (NUMA 节点),每个 CPU 都有属于自己的本地内存节点,CPU 访问自己的本地内存不需要经过总线,因此访问速度是最快的。当 CPU 自己的本地内存不足时,CPU 就需要跨节点去访问其他内存节点,这种情况下 CPU 访问内存就会慢很多。
在 NUMA 架构下,任意一个 CPU 都可以访问全部的内存节点,访问自己的本地内存节点是最快的,但访问其他内存节点就会慢很多,这就导致了 CPU 访问内存的速度不一致,所以叫做非一致性内存访问架构。
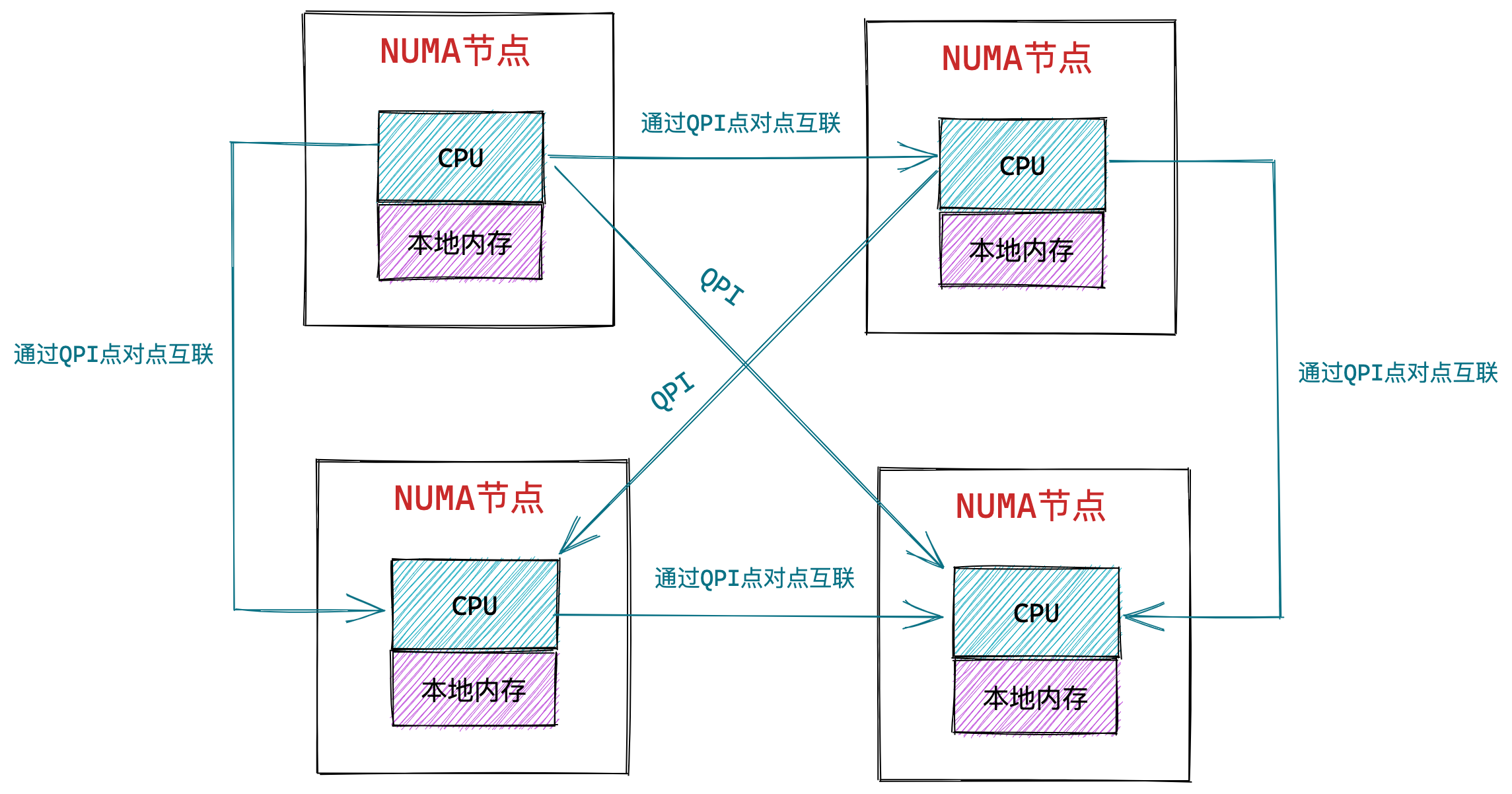
如上图所示,CPU 和它的本地内存组成了 NUMA 节点,CPU 与 CPU 之间通过 QPI(Intel QuickPath Interconnect)点对点完成互联,在 CPU 的本地内存不足的情况下,CPU 需要通过 QPI 访问远程 NUMA 节点上的内存控制器从而在远程内存节点上分配内存,这就导致了远程访问比本地访问多了额外的延迟开销(需要通过 QPI 遍历远程 NUMA 节点)。
在 NUMA 架构下,只有 DISCONTIGMEM 非连续内存模型和 SPARSEMEM 稀疏内存模型是可用的。而 UMA 架构下,前面介绍的三种内存模型都可以配置使用。
NUMA 的内存分配策略
NUMA 的内存分配策略是指在 NUMA 架构下 CPU 如何请求内存分配的相关策略,比如:是优先请求本地内存节点分配内存呢 ?还是优先请求指定的 NUMA 节点分配内存 ?是只能在本地内存节点分配呢 ?还是允许当本地内存不足的情况下可以请求远程 NUMA 节点分配内存 ?
| 内存分配策略 | 策略描述 |
|---|---|
| MPOL_BIND | 必须在绑定的节点进行内存分配,如果内存不足,则进行 swap |
| MPOL_INTERLEAVE | 本地节点和远程节点均可允许分配内存 |
| MPOL_PREFERRED | 优先在指定节点分配内存,当指定节点内存不足时,选择离指定节点最近的节点分配内存 |
| MPOL_LOCAL (默认) | 优先在本地节点分配,当本地节点内存不足时,可以在远程节点分配内存 |
我们可以在应用程序中通过 libnuma 共享库中的 API 调用 set_mempolicy 接口设置进程的内存分配策略。
|
|
- mode : 指定 NUMA 内存分配策略。
- nodemask:指定 NUMA 节点 Id。
- maxnode:指定最大 NUMA 节点 Id,用于遍历远程节点,实现跨 NUMA 节点分配内存。
libnuma 共享库 API 文档:https://man7.org/linux/man-pages/man3/numa.3.html#top_of_page
set_mempolicy 接口文档:https://man7.org/linux/man-pages/man2/set_mempolicy.2.html
NUMA 的使用简介
在我们理解了物理内存的 NUMA 架构,以及在 NUMA 架构下的内存分配策略之后,本小节我来为大家介绍下如何正确的利用 NUMA 提升我们应用程序的性能。
前边我们介绍了这么多的理论知识,但是理论的东西总是很虚,正所谓眼见为实,大家一定想亲眼看一下 NUMA 架构在计算机中的具体表现形式,比如:在支持 NUMA 架构的机器上到底有多少个 NUMA 节点?每个 NUMA 节点包含哪些 CPU 核,具体是怎样的一个分布情况?
前面也提到 CPU 在访问本地 NUMA 节点中的内存时,速度是最快的。但是当访问远程 NUMA 节点,速度就会相对很慢,那么到底有多慢?本地节点与远程节点之间的访问速度差异具体是多少 ?
查看 NUMA 相关信息
numactl 文档:https://man7.org/linux/man-pages/man8/numactl.8.html
针对以上具体问题,numactl -H 命令可以给出我们想要的答案:
|
|
numactl -H 命令可以查看服务器的 NUMA 配置,上图中的服务器配置共包含 4 个 NUMA 节点(0 - 3),每个 NUMA 节点中包含 16个 CPU 核心,本地内存大小约为 64G。
大家可以关注下最后 node distances: 这一栏,node distances 给出了不同 NUMA 节点之间的访问距离,对角线上的值均为本地节点的访问距离 10 。比如 [0,0] 表示 NUMA 节点 0 的本地内存访问距离。
我们可以很明显的看到当出现跨 NUMA 节点访问的时候,访问距离就会明显增加,比如节点 0 访问节点 1 的距离 [0,1] 是16,节点 0 访问节点 3 的距离 [0,3] 是 33。距离越远,跨 NUMA 节点内存访问的延时越大。应用程序运行时应减少跨 NUMA 节点访问内存。
此外我们还可以通过 numactl -s 来查看 NUMA 的内存分配策略设置:
|
|
通过 numastat 还可以查看各个 NUMA 节点的内存访问命中率:
|
|
- numa_hit :内存分配在该节点中成功的次数。
- numa_miss : 内存分配在该节点中失败的次数。
- numa_foreign:表示其他 NUMA 节点本地内存分配失败,跨节点(numa_miss)来到本节点分配内存的次数。
- interleave_hit : 在 MPOL_INTERLEAVE 策略下,在本地节点分配内存的次数。
- local_node:进程在本地节点分配内存成功的次数。
- other_node:运行在本节点的进程跨节点在其他节点上分配内存的次数。
numastat 文档:https://man7.org/linux/man-pages/man8/numastat.8.html
绑定 NUMA 节点
numactl 工具可以让我们应用程序指定运行在哪些 CPU 核心上,同时也可以指定我们的应用程序可以在哪些 NUMA 节点上分配内存。通过将应用程序与具体的 CPU 核心和 NUMA 节点绑定,从而可以提升程序的性能。
|
|
- 通过
--membind可以指定我们的应用程序只能在哪些具体的 NUMA 节点上分配内存,如果这些节点内存不足,则分配失败。 - 通过
--cpunodebind可以指定我们的应用程序只能运行在哪些 NUMA 节点上。
|
|
另外我们还可以通过 --physcpubind 将我们的应用程序绑定到具体的物理 CPU 上。这个选项后边指定的参数我们可以通过 cat /proc/cpuinfo 输出信息中的 processor 这一栏查看。例如:通过 numactl --physcpubind= 0-15 ./numatest.out 命令将进程 numatest 绑定到 0~15 CPU 上执行。
我们可以通过 numactl 命令将 numatest 进程分别绑定在相同的 NUMA 节点上和不同的 NUMA 节点上,运行观察。
|
|
大家肯定一眼就能看出绑定在相同 NUMA 节点的进程运行会更快,因为通过前边对 NUMA 架构的介绍,我们知道 CPU 访问本地 NUMA 节点的内存是最快的。
除了 numactl 这个工具外,我们还可以通过共享库 libnuma 在程序中进行 NUMA 相关的操作。这里我就不演示了,感兴趣可以查看下 libnuma 的 API 文档:https://man7.org/linux/man-pages/man3/numa.3.html#top_of_page
内核如何管理 NUMA 节点
在前边我们介绍物理内存模型和物理内存架构的时候提到过:在 NUMA 架构下,只有 DISCONTIGMEM 非连续内存模型和 SPARSEMEM 稀疏内存模型是可用的。而 UMA 架构下,前面介绍的三种内存模型均可以配置使用。
无论是 NUMA 架构还是 UMA 架构在内核中都是使用相同的数据结构来组织管理的,在内核的内存管理模块中会把 UMA 架构当做只有一个 NUMA 节点的伪 NUMA 架构。这样一来这两种架构模式就在内核中被统一管理起来。
下面我先从最顶层的设计开始为大家介绍一下内核是如何管理这些 NUMA 节点的~~
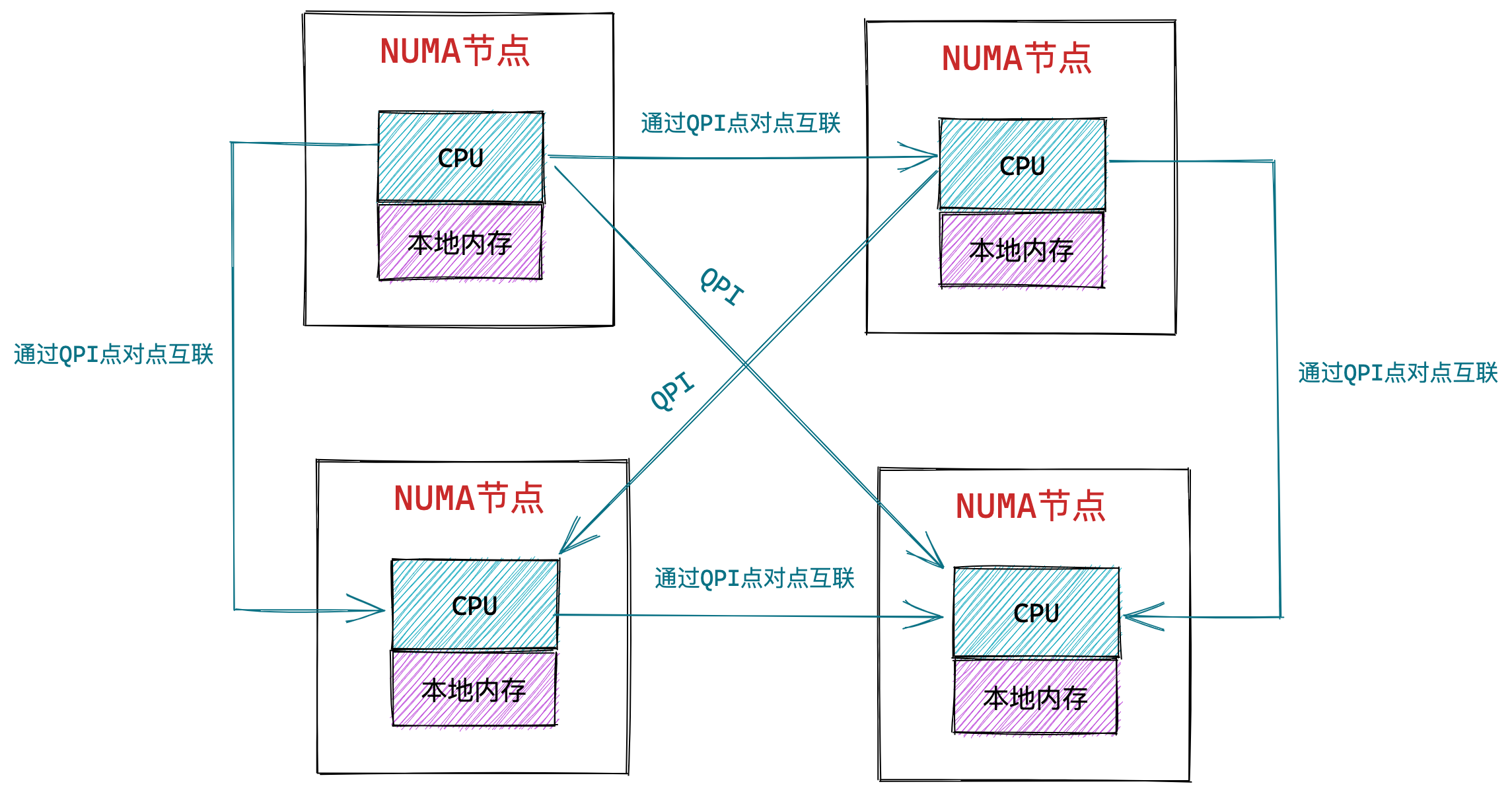
NUMA 节点中可能会包含多个 CPU,这些 CPU 均是物理 CPU,这点大家需要注意一下。
内核如何统一组织 NUMA 节点
首先我们来看第一个问题,在内核中是如何将这些 NUMA 节点统一管理起来的?
内核中使用了 struct pglist_data 这样的一个数据结构来描述 NUMA 节点,在内核 2.4 版本之前,内核是使用一个 pgdat_list 单链表将这些 NUMA 节点串联起来的,单链表定义在 /include/linux/mmzone.h 文件中:
|
|
每个 NUMA 节点的数据结构 struct pglist_data 中有一个 next 指针,用于将这些 NUMA 节点串联起来形成 pgdat_list 单链表,链表的末尾节点 next 指针指向 NULL。
|
|
在内核 2.4 之后的版本中,内核移除了 struct pglist_data 结构中的 pgdat_next 之指针, 同时也删除了 pgdat_list 单链表。取而代之的是,内核使用了一个大小为 MAX_NUMNODES ,类型为 struct pglist_data 的全局数组 node_data[] 来管理所有的 NUMA 节点。
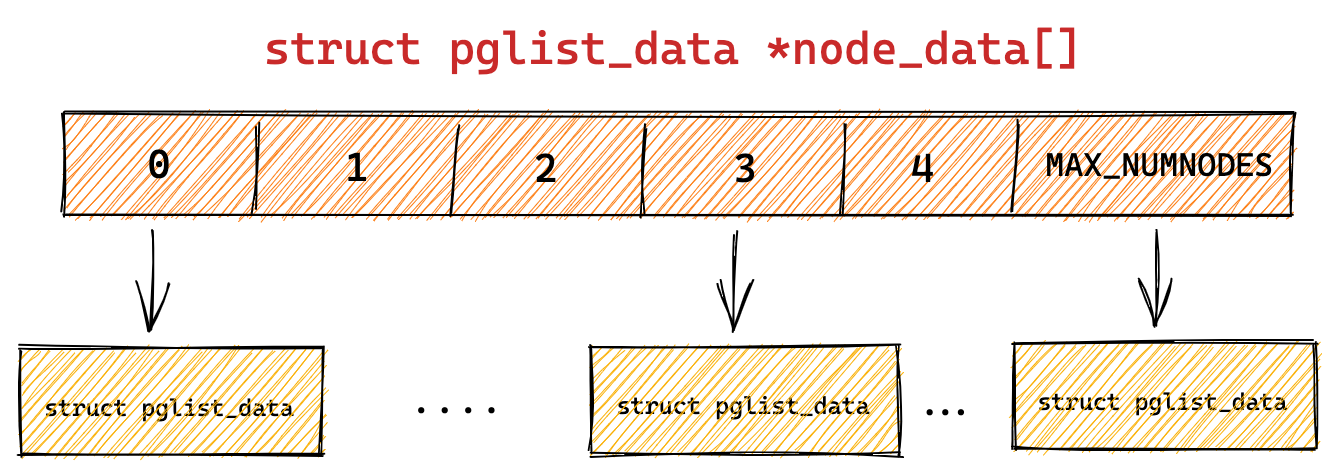
全局数组 node_data[] 定义在文件 /arch/arm64/include/asm/mmzone.h中:
|
|
NODE_DATA(nid) 宏可以通过 NUMA 节点的 nodeId,找到对应的 struct pglist_data 结构。
node_data[] 数组大小 MAX_NUMNODES 定义在 /include/linux/numa.h文件中:
|
|
UMA 架构下 NODES_SHIFT 为 0 ,所以内核中只用一个 NUMA 节点来管理所有物理内存。
NUMA 节点描述符 pglist_data 结构
|
|
node_id 表示 NUMA 节点的 id,我们可以通过 numactl -H 命令的输出结果查看节点 id。从 0 开始依次对 NUMA 节点进行编号。
struct page 类型的数组 node_mem_map 中包含了 NUMA节点内的所有的物理内存页。
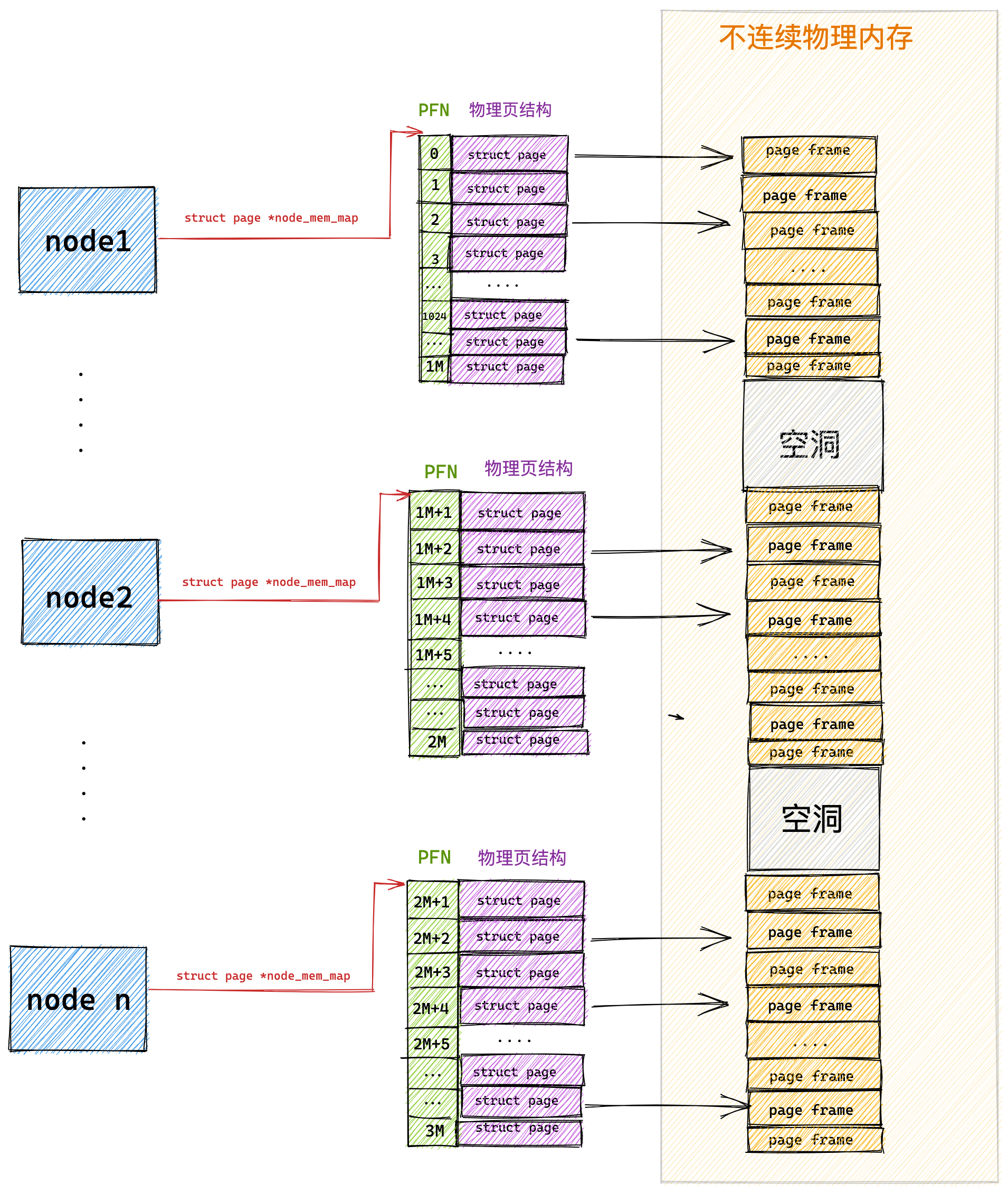
node_start_pfn 指向 NUMA 节点内第一个物理页的 PFN,系统中所有 NUMA 节点中的物理页都是依次编号的,每个物理页的 PFN 都是全局唯一的(不只是其所在 NUMA 节点内唯一)
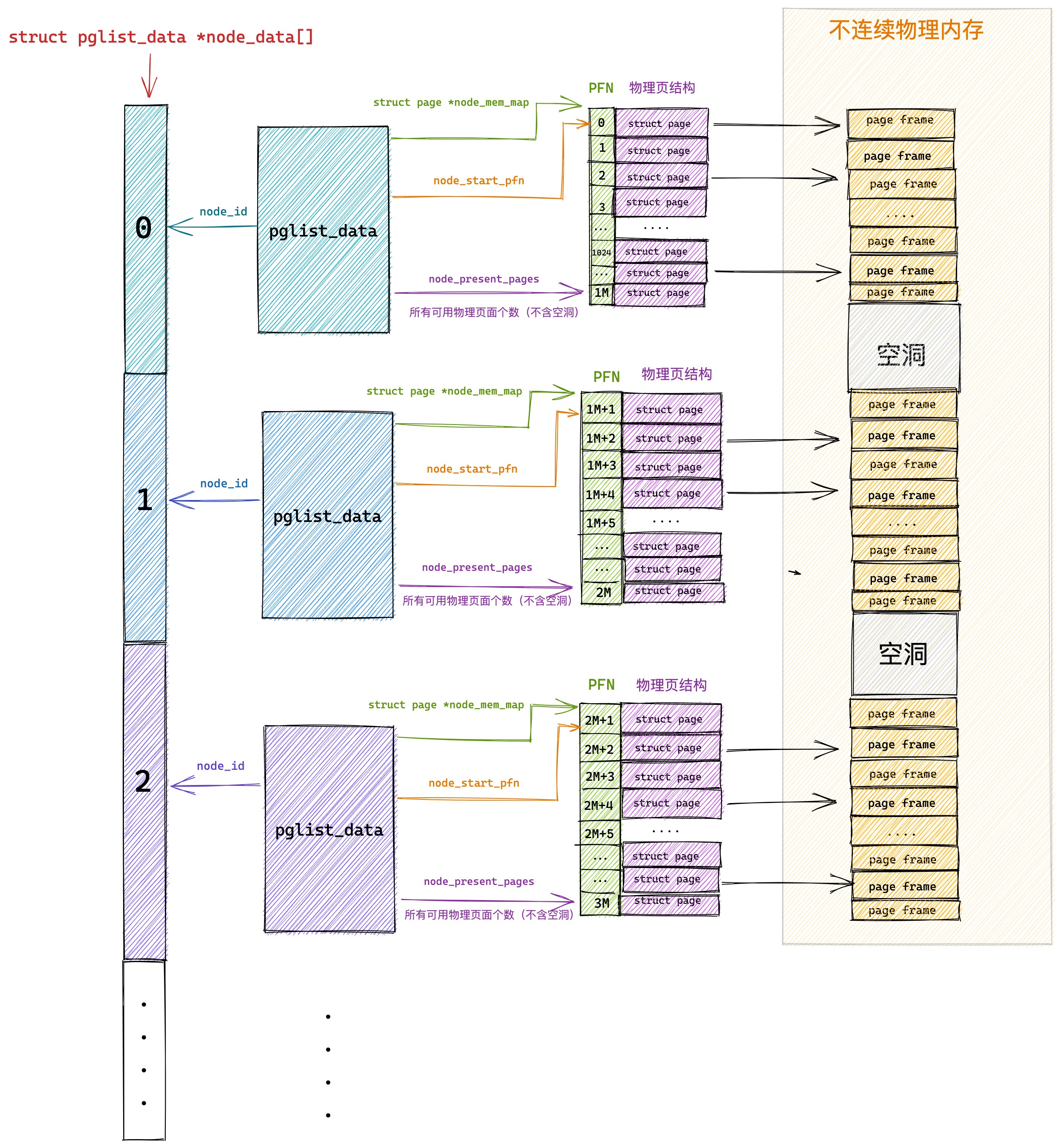
node_present_pages 用于统计 NUMA 节点内所有真正可用的物理页面数量(不包含内存空洞)。
由于 NUMA 节点内包含的物理内存并不总是连续的,可能会包含一些内存空洞,node_spanned_pages 则是用于统计 NUMA 节点内所有的内存页,包含不连续的物理内存地址(内存空洞)的页面数。
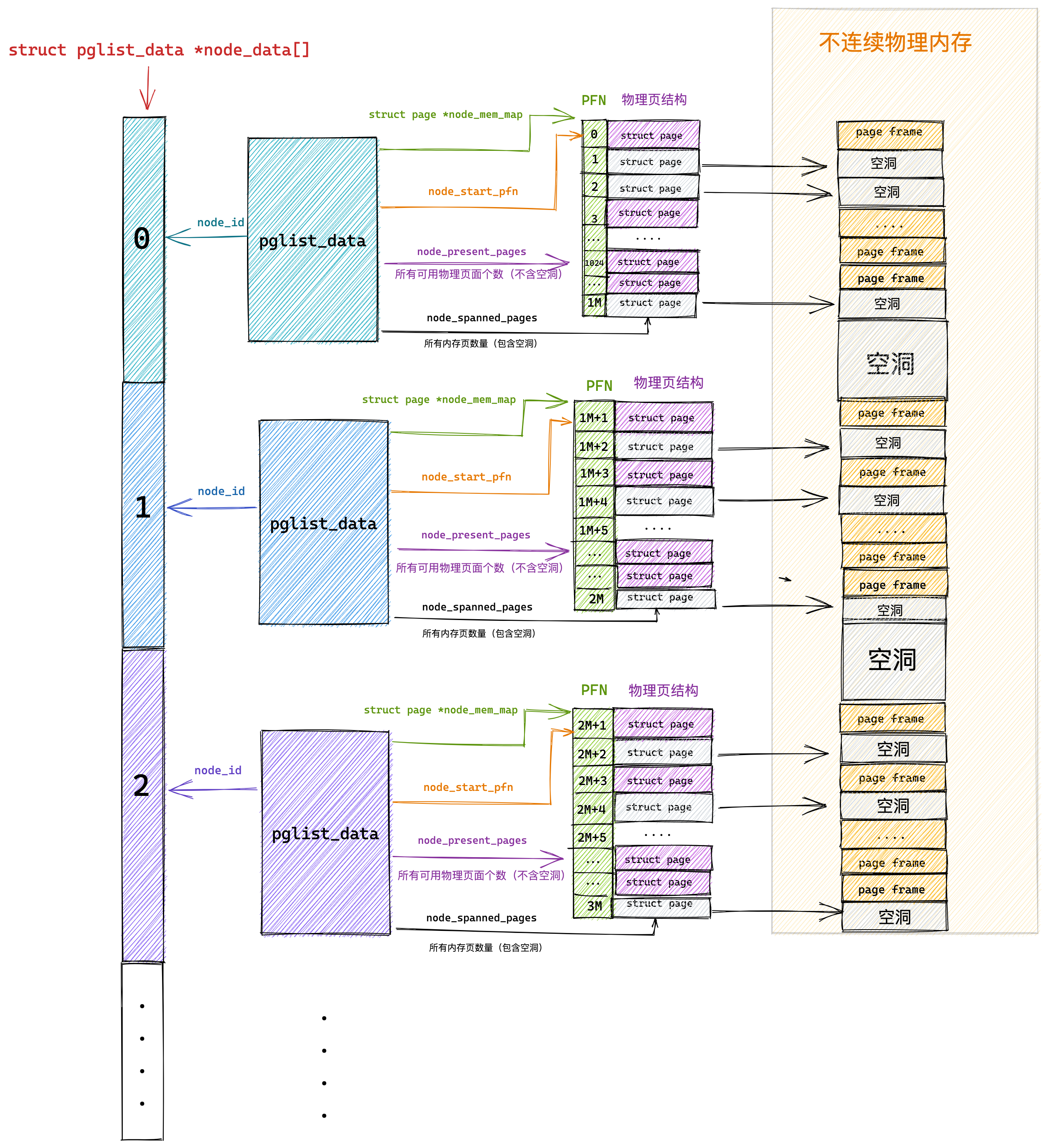
以上内容是我从整体上为大家介绍的 NUMA 节点如何管理节点内部的本地内存。事实上内核还会将 NUMA 节点中的本地内存做近一步的划分。那么为什么要近一步划分呢?
NUMA 节点物理内存区域的划分
我们都知道内核对物理内存的管理都是以页为最小单位来管理的,每页默认 4K 大小,理想状况下任何种类的数据都可以存放在任何页框中,没有什么限制。比如:存放内核数据,用户数据,磁盘缓冲数据等。
但是实际的计算机体系结构受到硬件方面的制约,间接导致限制了页框的使用方式。
比如在 X86 体系结构下,ISA 总线的 DMA (直接内存存取)控制器,只能对内存的前16M 进行寻址,这就导致了 ISA 设备不能在整个 32 位地址空间中执行 DMA,只能使用物理内存的前 16M 进行 DMA 操作。
因此直接映射区的前 16M 专门让内核用来为 DMA 分配内存,这块 16M 大小的内存区域我们称之为 ZONE_DMA。
用于 DMA 的内存必须从 ZONE_DMA 区域中分配。
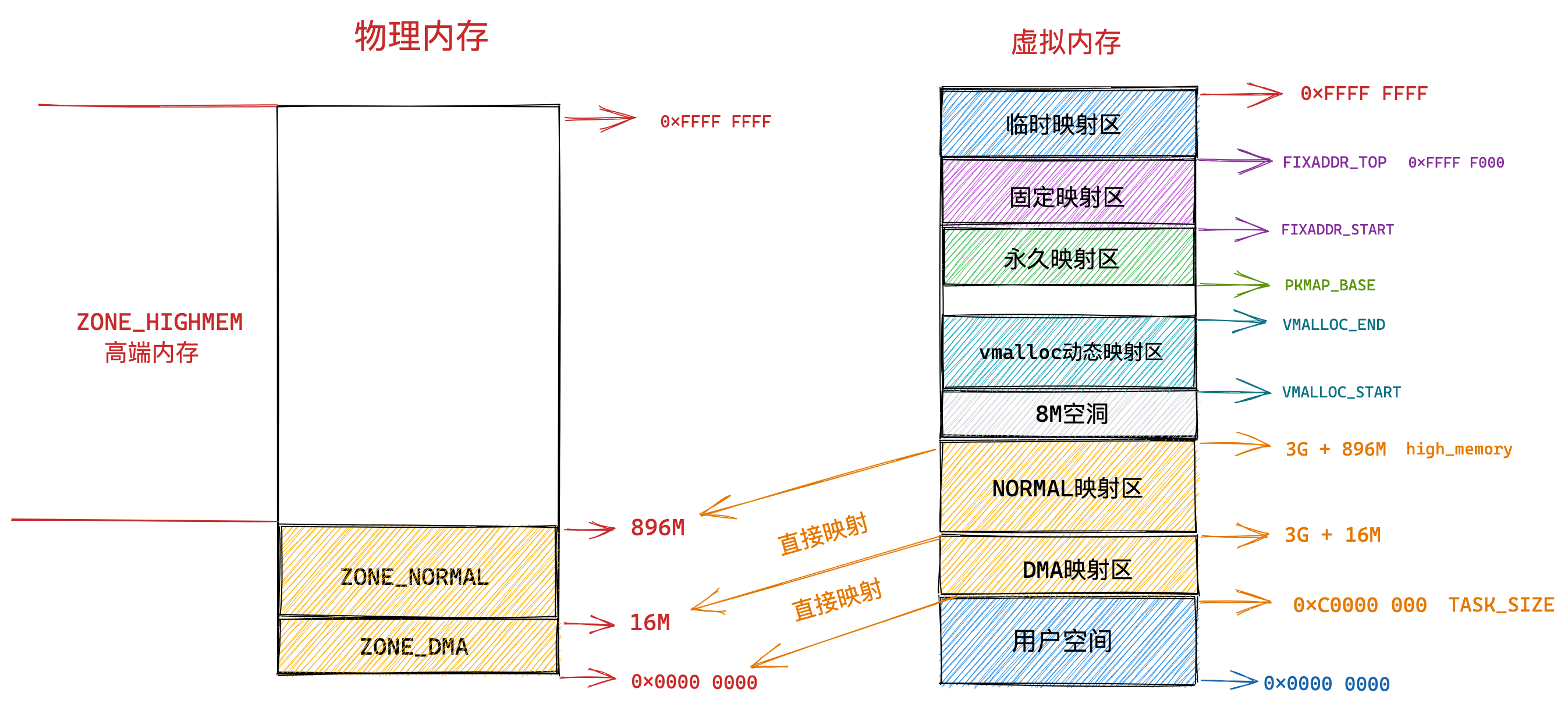
而直接映射区中剩下的部分也就是从 16M 到 896M(不包含 896M)这段区域,我们称之为 ZONE_NORMAL。从字面意义上我们可以了解到,这块区域包含的就是正常的页框(没有任何使用限制)。
ZONE_NORMAL 由于也是属于直接映射区的一部分,对应的物理内存 16M 到 896M 这段区域也是被直接映射至内核态虚拟内存空间中的 3G + 16M 到 3G + 896M 这段虚拟内存上。
而物理内存 896M 以上的区域被内核划分为 ZONE_HIGHMEM 区域,我们称之为高端内存。
由于内核虚拟内存空间中的前 896M 虚拟内存已经被直接映射区所占用,而在 32 体系结构下内核虚拟内存空间总共也就 1G 的大小,这样一来内核剩余可用的虚拟内存空间就变为了 1G - 896M = 128M。
显然物理内存中剩下的这 3200M 大小的 ZONE_HIGHMEM 区域无法继续通过直接映射的方式映射到这 128M 大小的虚拟内存空间中。
这样一来物理内存中的 ZONE_HIGHMEM 区域就只能采用动态映射的方式映射到 128M 大小的内核虚拟内存空间中,也就是说只能动态的一部分一部分的分批映射,先映射正在使用的这部分,使用完毕解除映射,接着映射其他部分。
所以内核会根据各个物理内存区域的功能不同,将 NUMA 节点内的物理内存主要划分为以下四个物理内存区域:
- ZONE_DMA:用于那些无法对全部物理内存进行寻址的硬件设备,进行 DMA 时的内存分配。例如前边介绍的 ISA 设备只能对物理内存的前 16M 进行寻址。该区域的长度依赖于具体的处理器类型。
- ZONE_DMA32:与 ZONE_DMA 区域类似,该区域内的物理页面可用于执行 DMA 操作,不同之处在于该区域是提供给 32 位设备(只能寻址 4G 物理内存)执行 DMA 操作时使用的。该区域只在 64 位系统中起作用,因为只有在 64 位系统中才会专门为 32 位设备提供专门的 DMA 区域。
- ZONE_NORMAL:这个区域的物理页都可以直接映射到内核中的虚拟内存,由于是线性映射,内核可以直接进行访问。
- ZONE_HIGHMEM:这个区域包含的物理页就是我们说的高端内存,内核不能直接访问这些物理页,这些物理页需要动态映射进内核虚拟内存空间中(非线性映射)。该区域只在 32 位系统中才会存在,因为 64 位系统中的内核虚拟内存空间太大了(128T),都可以进行直接映射。
以上这些物理内存区域的划分定义在 /include/linux/mmzone.h 文件中:
|
|
大家可能注意到内核中定义的 zone_type 除了上边为大家介绍的四个物理内存区域,又多出了两个区域:ZONE_MOVABLE 和 ZONE_DEVICE。
ZONE_DEVICE 是为支持热插拔设备而分配的非易失性内存( Non Volatile Memory ),也可用于内核崩溃时保存相关的调试信息。
ZONE_MOVABLE 是内核定义的一个虚拟内存区域,该区域中的物理页可以来自于上边介绍的几种真实的物理区域。该区域中的页全部都是可以迁移的,主要是为了防止内存碎片和支持内存的热插拔。
既然有了这些实际的物理内存区域,那么内核为什么又要划分出一个 ZONE_MOVABLE 这样的虚拟内存区域呢 ?
因为随着系统的运行会伴随着不同大小的物理内存页的分配和释放,这种内存不规则的分配释放随着系统的长时间运行就会导致内存碎片,内存碎片会使得系统在明明有足够内存的情况下,依然无法为进程分配合适的内存。

如上图所示,假如现在系统一共有 16 个物理内存页,当前系统只是分配了 3 个物理页,那么在当前系统中还剩余 13 个物理内存页的情况下,如果内核想要分配 8 个连续的物理页的话,就会由于内存碎片的存在导致分配失败。(只能分配最多 4 个连续的物理页)
内核中请求分配的物理页面数只能是 2 的次幂!!
如果这些物理页处于 ZONE_MOVABLE 区域,它们就可以被迁移,内核可以通过迁移页面来避免内存碎片的问题:
内核通过迁移页面来规整内存,这样就可以避免内存碎片,从而得到一大片连续的物理内存,以满足内核对大块连续内存分配的请求。所以这就是内核需要根据物理页面是否能够迁移的特性,而划分出 ZONE_MOVABLE 区域的目的。
到这里,我们已经清楚了 NUMA 节点中物理内存区域的划分,下面我们继续回到 struct pglist_data 结构中看下内核如何在 NUMA 节点中组织这些划分出来的内存区域:
|
|
nr_zones 用于统计 NUMA 节点内包含的物理内存区域个数,不是每个 NUMA 节点都会包含以上介绍的所有物理内存区域,NUMA 节点之间所包含的物理内存区域个数是不一样的。
事实上只有第一个 NUMA 节点可以包含所有的物理内存区域,其它的节点并不能包含所有的区域类型,因为有些内存区域比如:ZONE_DMA,ZONE_DMA32 必须从物理内存的起点开始。这些在物理内存开始的区域可能已经被划分到第一个 NUMA 节点了,后面的物理内存才会被依次划分给接下来的 NUMA 节点。因此后面的 NUMA 节点并不会包含 ZONE_DMA,ZONE_DMA32 区域。
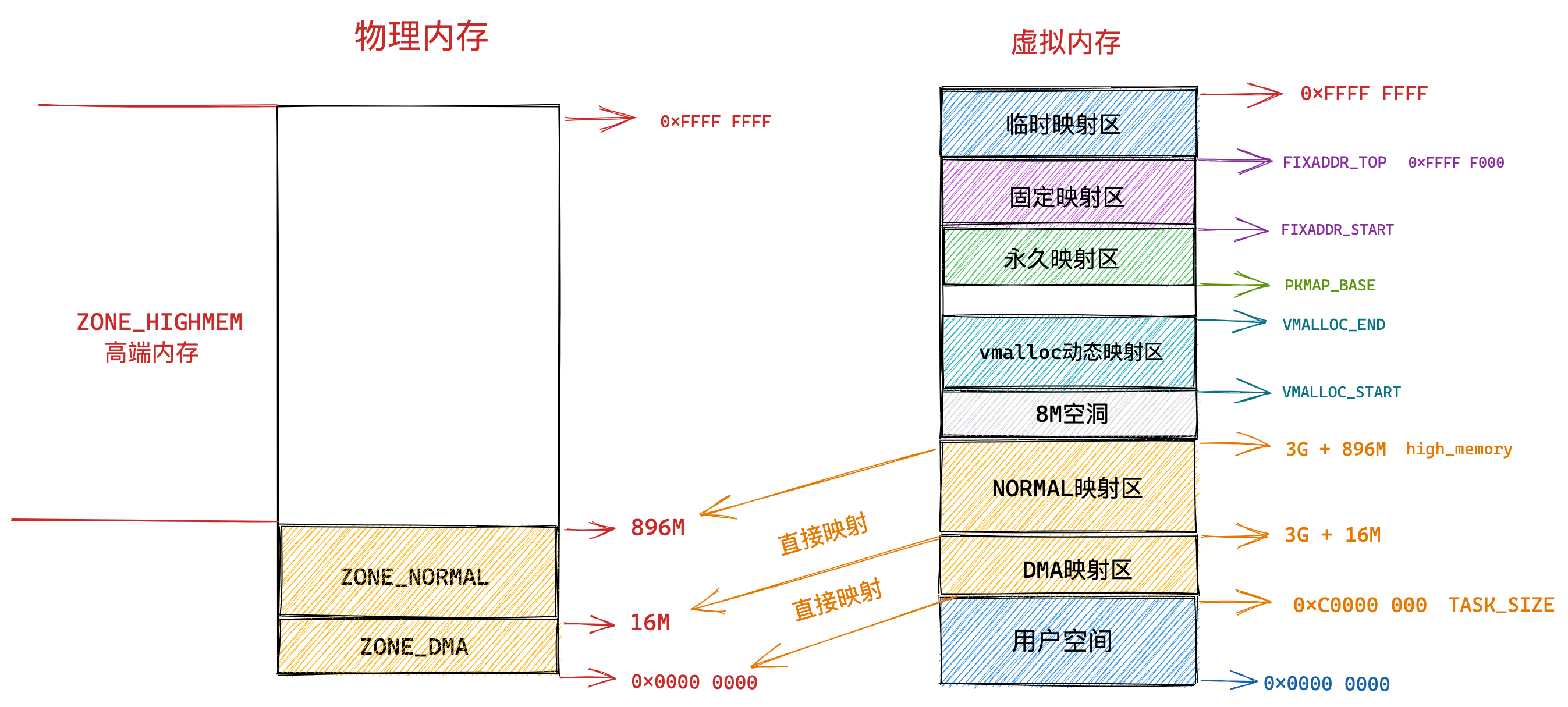
ZONE_NORMAL、ZONE_HIGHMEM 和 ZONE_MOVABLE 是可以出现在所有 NUMA 节点上的。
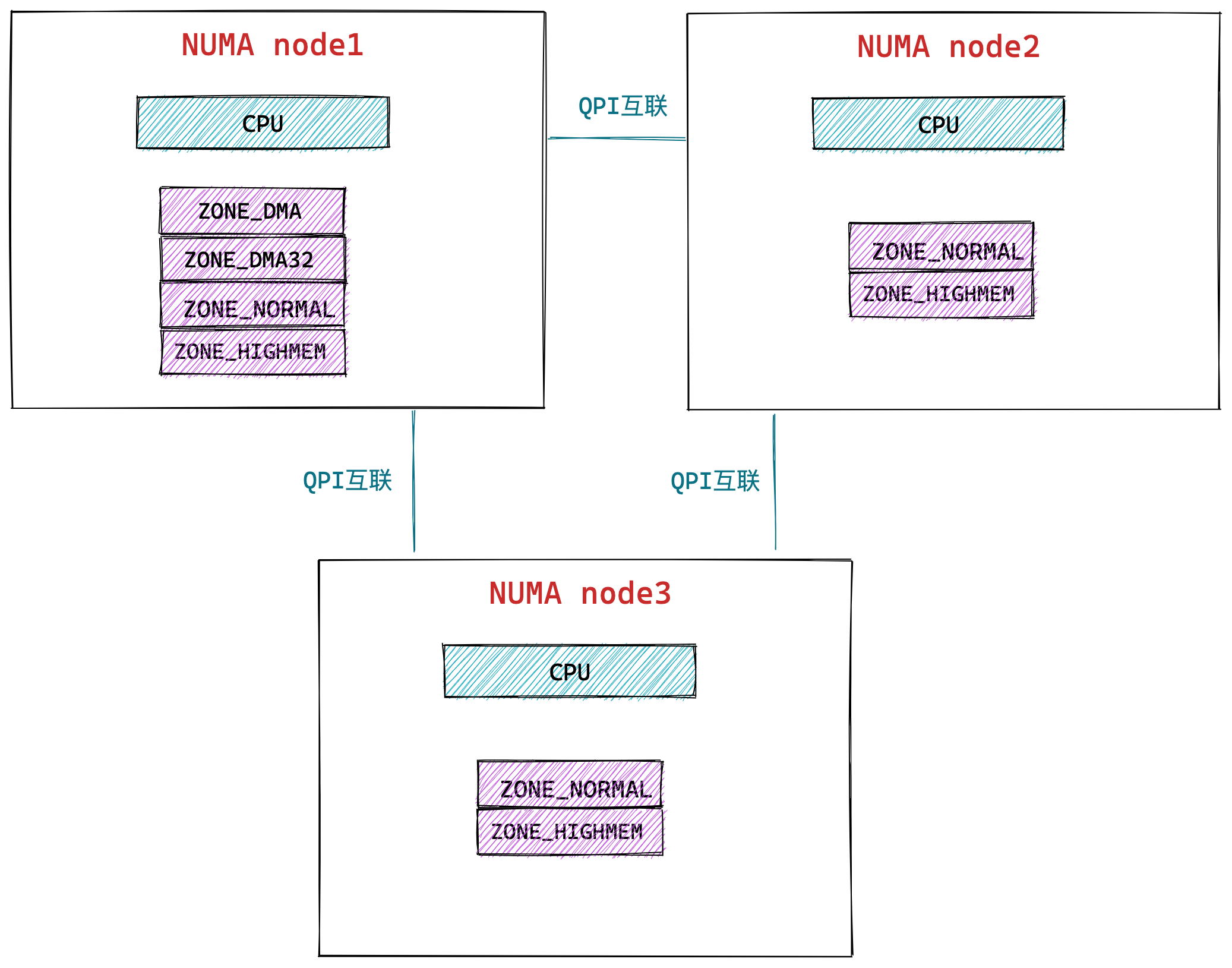
node_zones[MAX_NR_ZONES] 数组包含了 NUMA 节点中的所有物理内存区域,物理内存区域在内核中的数据结构是 struct zone 。
node_zonelists[MAX_ZONELISTS] 是 struct zonelist 类型的数组,它包含了备用 NUMA 节点和这些备用节点中的物理内存区域。备用节点是按照访问距离的远近,依次排列在 node_zonelists 数组中,数组第一个备用节点是访问距离最近的,这样当本节点内存不足时,可以从备用 NUMA 节点中分配内存。
各个 NUMA 节点之间的内存分配情况我们可以通过前边介绍的
numastat命令查看。
NUMA 节点中的内存规整与回收
内存可以说是计算机系统中最为宝贵的资源了,再怎么多也不够用,当系统运行时间长了之后,难免会遇到内存紧张的时候,这时候就需要内核将那些不经常使用的内存页面回收起来,或者将那些可以迁移的页面进行内存规整,从而可以腾出连续的物理内存页面供内核分配。
内核会为每个 NUMA 节点分配一个 kswapd 进程用于回收不经常使用的页面,还会为每个 NUMA 节点分配一个 kcompactd 进程用于内存的规整避免内存碎片。
|
|
NUMA 节点描述符 struct pglist_data 结构中的 struct task_struct *kswapd 属性用于指向内核为 NUMA 节点分配的 kswapd 进程。
kswapd_wait 用于 kswapd 进程周期性回收页面时使用到的等待队列。
同理 struct task_struct *kcompactd 用于指向内核为 NUMA 节点分配的 kcompactd 进程。
kcompactd_wait 用于 kcompactd 进程周期性规整内存时使用到的等待队列。
本小节我主要为大家介绍 NUMA 节点的数据结构 struct pglist_data。详细的内存回收会在本文后面的章节单独介绍。
NUMA 节点的状态 node_states
如果系统中的 NUMA 节点多于一个,内核会维护一个位图 node_states,用于维护各个 NUMA 节点的状态信息。
如果系统中只有一个 NUMA 节点,则没有节点位图。
节点位图以及节点的状态掩码值定义在 /include/linux/nodemask.h 文件中:
|
|
节点的状态可通过以下掩码表示:
|
|
N_POSSIBLE 表示 NUMA 节点在某个时刻可以变为 online 状态,N_ONLINE 表示 NUMA 节点当前的状态为 online 状态。
我们在本文《2.3.1 物理内存热插拔》小节中提到,在稀疏内存模型中,NUMA 节点的状态可以在系统运行的过程中随时切换 online ,offline 的状态,用来支持内存的热插拔。
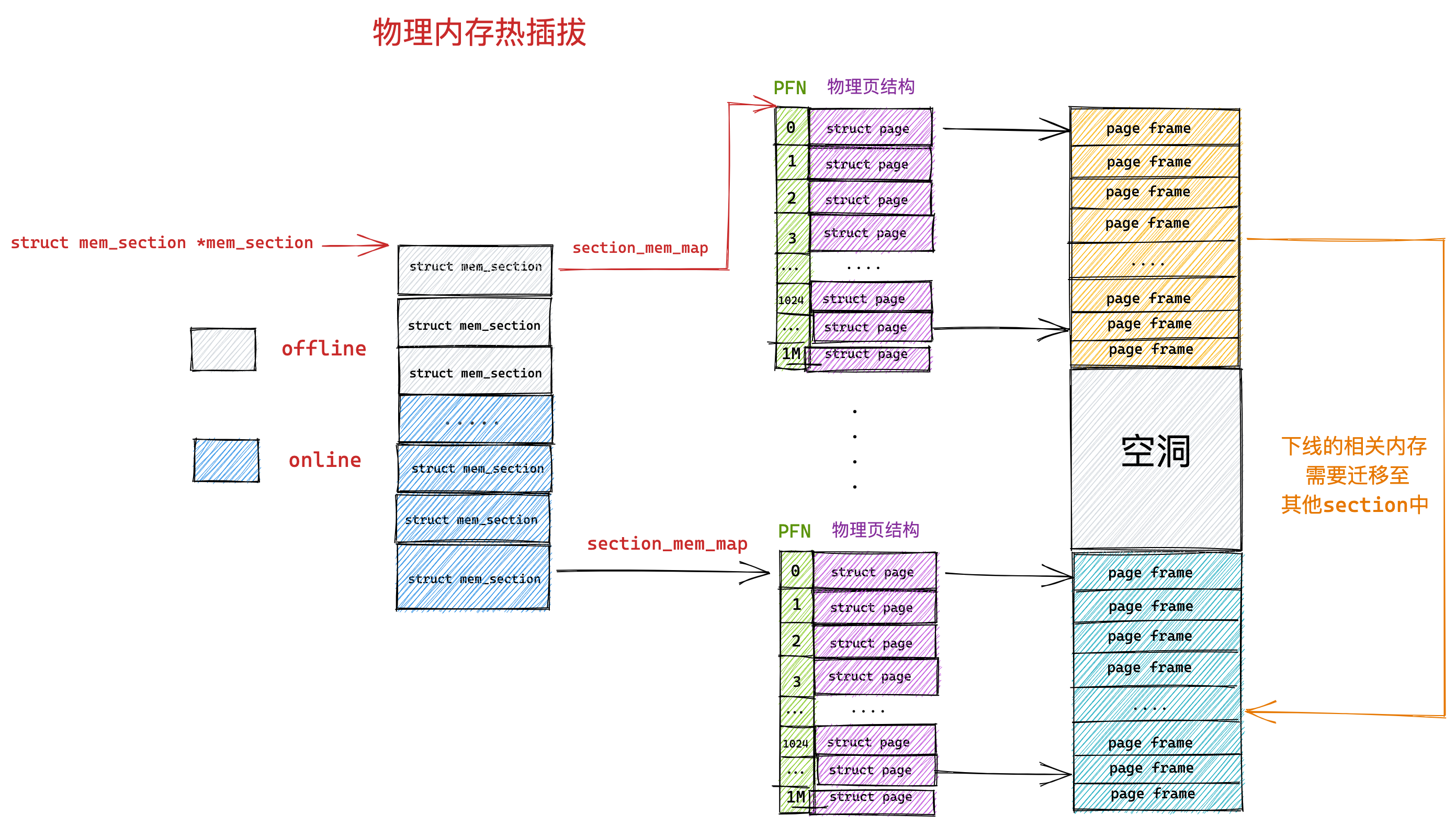
N_NORMAL_MEMORY 表示节点没有高端内存,只有 ZONE_NORMAL 内存区域。
N_HIGH_MEMORY 表示节点有 ZONE_NORMAL 内存区域或者有 ZONE_HIGHMEM 内存区域。
N_MEMORY 表示节点有 ZONE_NORMAL,ZONE_HIGHMEM,ZONE_MOVABLE 内存区域。
N_CPU 表示节点包含一个或多个 CPU。
此外内核还提供了两个辅助函数用于设置或者清除指定节点的特定状态:
|
|
内核提供了 for_each_node_state 宏用于迭代处于特定状态的所有 NUMA 节点。
|
|
比如:for_each_online_node 用于迭代所有 online 的 NUMA 节点:
|
|
内核如何管理 NUMA 节点中的物理内存区域
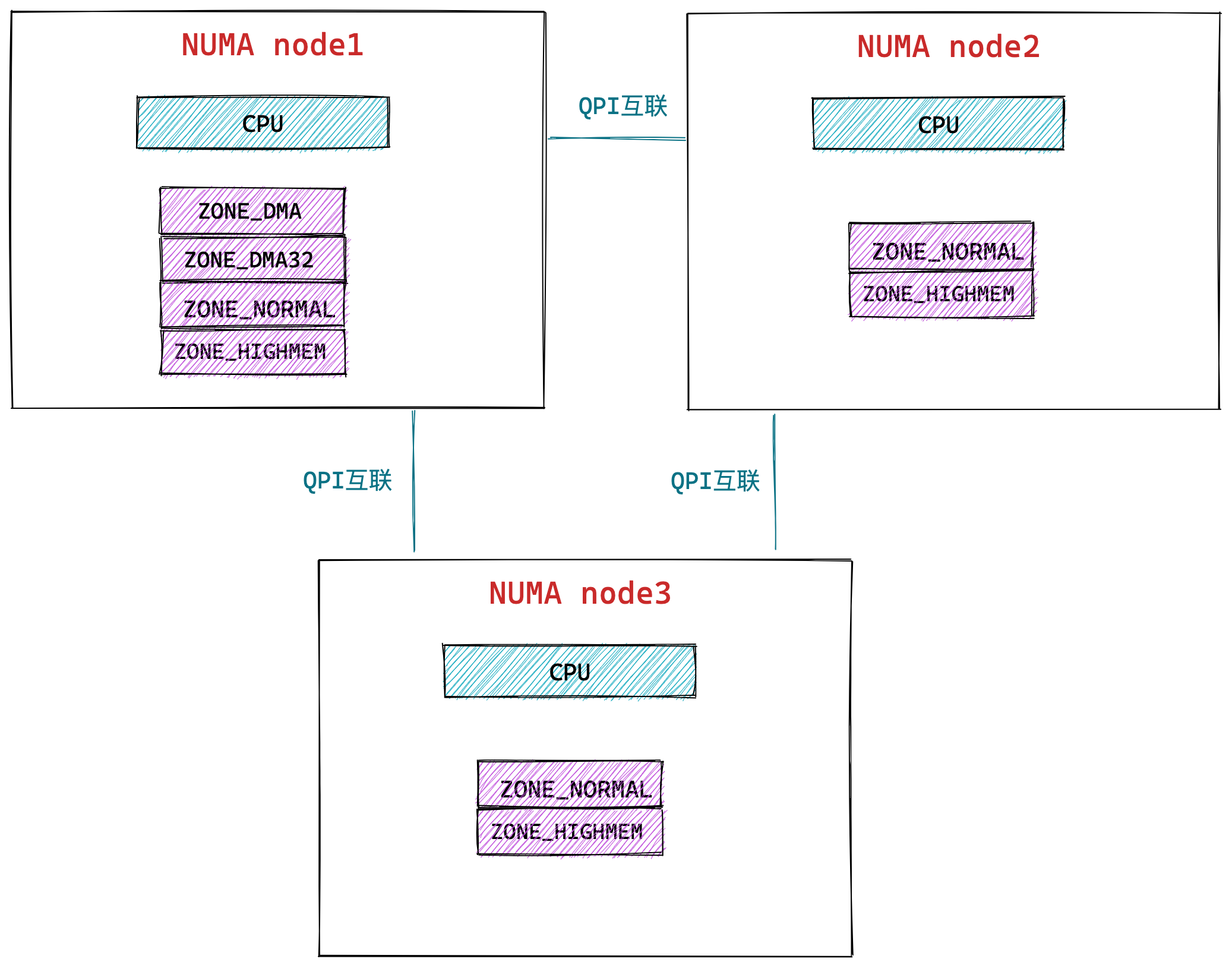
在前边《4.3 NUMA 节点物理内存区域的划分》小节的介绍中,由于实际的计算机体系结构受到硬件方面的制约,间接限制了页框的使用方式。于是内核会根据各个物理内存区域的功能不同,将 NUMA 节点内的物理内存划分为:ZONE_DMA,ZONE_DMA32,ZONE_NORMAL,ZONE_HIGHMEM 这几个物理内存区域。
ZONE_MOVABLE 区域是内核从逻辑上的划分,区域中的物理页面来自于上述几个内存区域,目的是避免内存碎片和支持内存热插拔(前边我已经介绍过了)。
我们可以通过 cat /proc/zoneinfo | grep Node 命令来查看 NUMA 节点中内存区域的分布情况:

我使用的服务器是 64 位,所以不包含 ZONE_HIGHMEM 区域。
通过 cat /proc/zoneinfo 命令来查看系统中各个 NUMA 节点中的各个内存区域的内存使用情况:
下图中我们以 NUMA Node 0 中的 ZONE_NORMAL 区域为例说明,大家只需要浏览一个大概,图中每个字段的含义我会在本小节的后面一一为大家介绍~~~
内核中用于描述和管理 NUMA 节点中的物理内存区域的结构体是 struct zone,上图中显示的 ZONE_NORMAL 区域中,物理内存使用统计的相关数据均来自于 struct zone 结构体,我们先来看一下内核对 struct zone 结构体的整体布局情况:
|
|
由于 struct zone 结构体在内核中是一个访问非常频繁的结构体,在多处理器系统中,会有不同的 CPU 同时大量频繁的访问 struct zone 结构体中的不同字段。
因此内核对 struct zone 结构体的设计是相当考究的,将这些频繁访问的字段信息归类为 4 个部分,并通过 ZONE_PADDING 来分割。
目的是通过 ZONE_PADDING 来填充字节,将这四个部分,分别填充到不同的 CPU 高速缓存行(cache line)中,使得它们各自独占 cache line,提高访问性能。
根据前边物理内存区域划分的相关内容介绍,我们知道内核会把 NUMA 节点中的物理内存区域顶多划分为 ZONE_DMA,ZONE_DMA32,ZONE_NORMAL,ZONE_HIGHMEM 这几个物理内存区域。因此 struct zone 的实例在内核中会相对比较少,通过 ZONE_PADDING 填充字节,带来的 struct zone 结构体实例内存占用增加是可以忽略不计的。
在结构体的最后内核还是用了 ____cacheline_internodealigned_in_smp 编译器关键字来实现最优的高速缓存行对齐方式。
关于 CPU 高速缓存行对齐的详细内容,感兴趣的同学可以回看下我之前的文章 《一文聊透对象在JVM中的内存布局,以及内存对齐和压缩指针的原理及应用》 (opens new window)。
我为了使大家能够更好地理解内核如何使用 struct zone 结构体来描述内存区域,从而把结构体中的字段按照一定的层次结构重新排列介绍,这并不是原生的字段对齐方式,这一点需要大家注意!!!
|
|
struct zone 是会被内核频繁访问的一个结构体,在多核处理器中,多个 CPU 会并发访问 struct zone,为了防止并发访问,内核使用了一把 spinlock_t lock 自旋锁来防止并发错误以及不一致。
name 属性会根据该内存区域的类型不同保存内存区域的名称,比如:Normal ,DMA,HighMem 等。
前边我们介绍 NUMA 节点的描述符 struct pglist_data 的时候提到,pglist_data 通过 struct zone 类型的数组 node_zones 将 NUMA 节点中划分的物理内存区域连接起来。
|
|
这些物理内存区域也会通过 struct zone 中的 zone_pgdat 指向自己所属的 NUMA 节点。
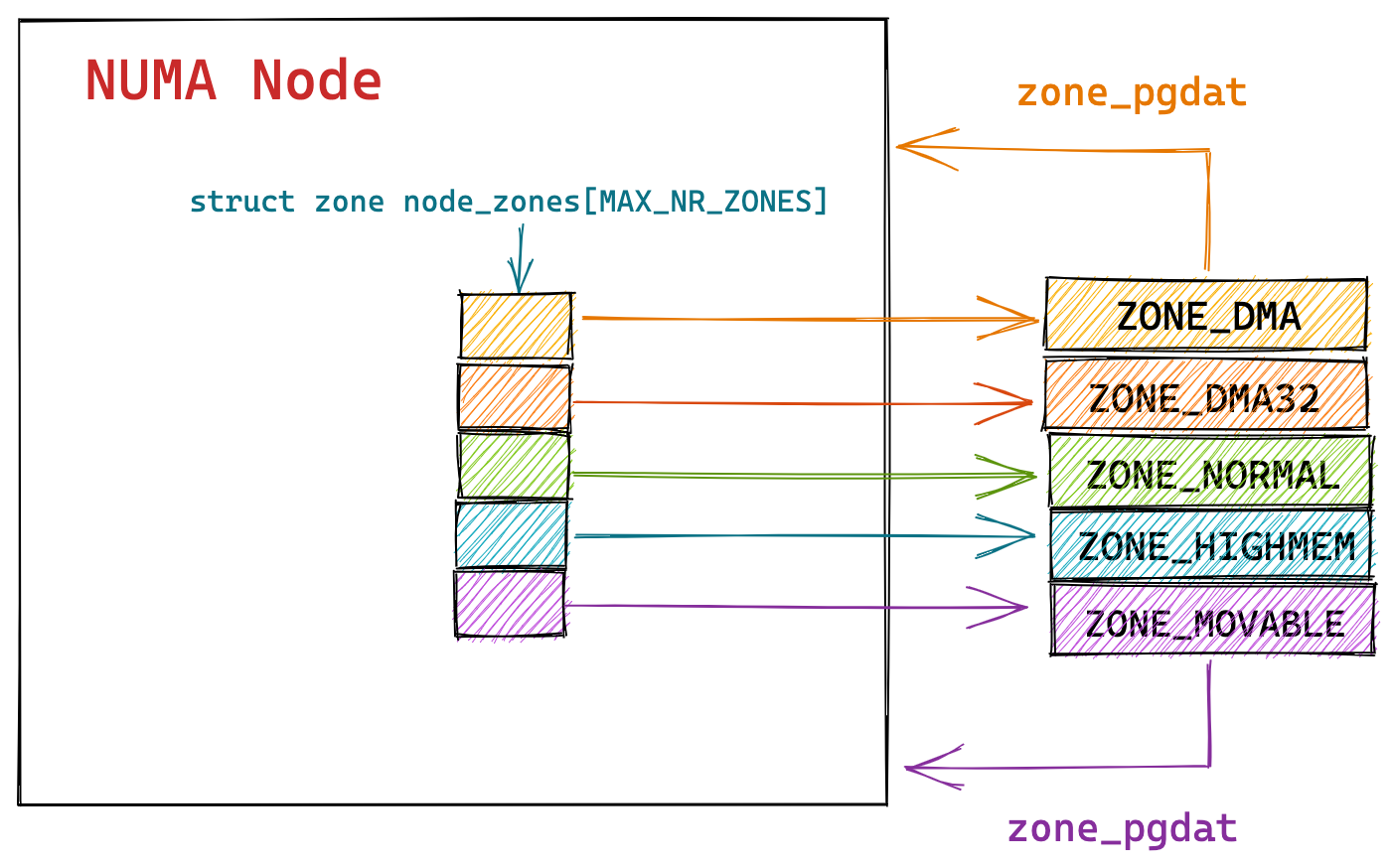
NUMA 节点 struct pglist_data 结构中的 node_start_pfn 指向 NUMA 节点内第一个物理页的 PFN。同理物理内存区域 struct zone 结构中的 zone_start_pfn 指向的是该内存区域内所管理的第一个物理页面 PFN 。
后面的属性也和 NUMA 节点对应的字段含义一样,比如:spanned_pages 表示该内存区域内所有的物理页总数(包含内存空洞),通过 spanned_pages = zone_end_pfn - zone_start_pfn 计算得到。
present_pages 则表示该内存区域内所有实际可用的物理页面总数(不包含内存空洞),通过 present_pages = spanned_pages - absent_pages(pages in holes) 计算得到。
在 NUMA 架构下,物理内存被划分成了一个一个的内存节点(NUMA 节点),在每个 NUMA 节点内部又将其所管理的物理内存按照功能不同划分成了不同的内存区域,每个内存区域管理一片用于具体功能的物理内存,而内核会为每一个内存区域分配一个伙伴系统用于管理该内存区域下物理内存的分配和释放。
物理内存在内核中管理的层级关系为:
None -> Zone -> page
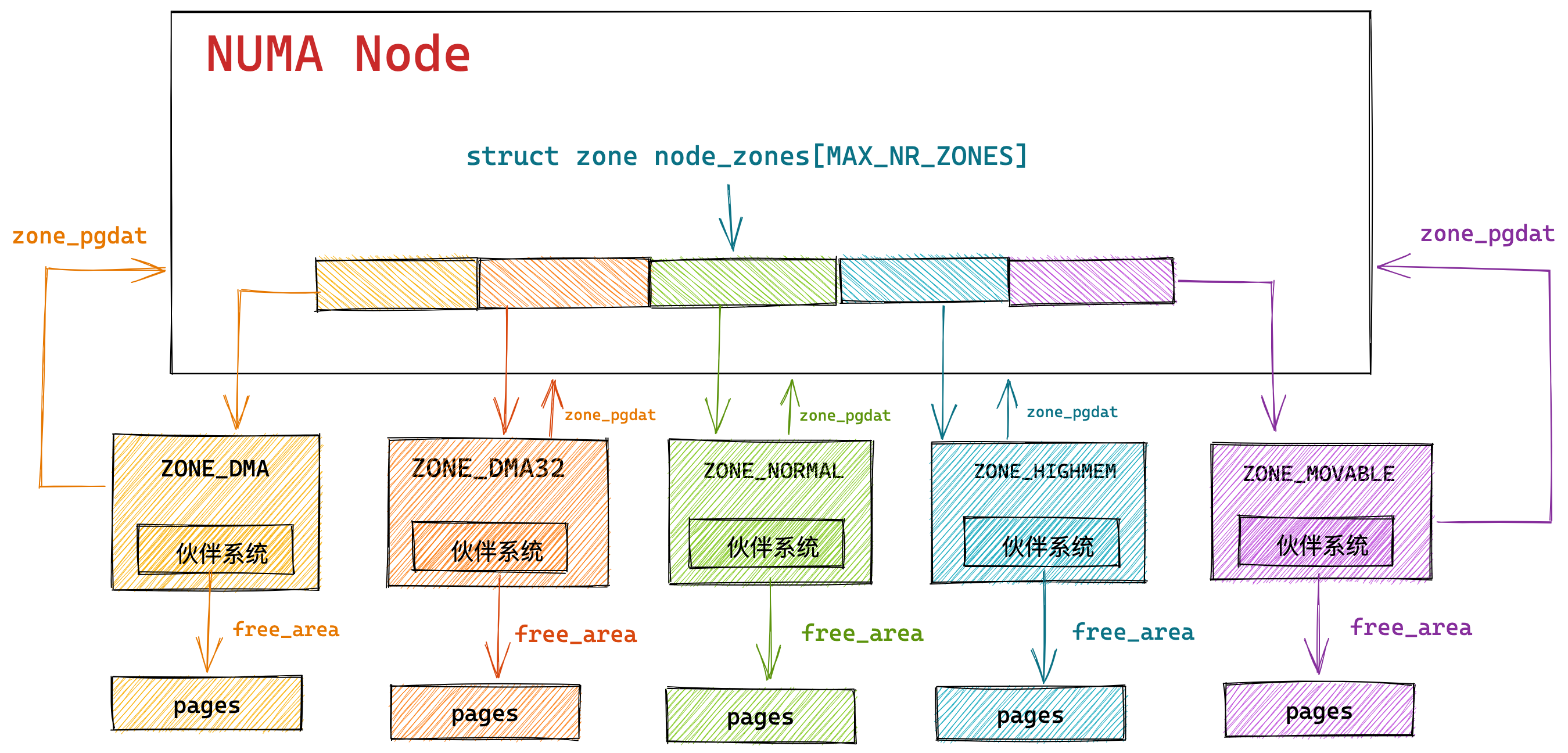
struct zone 结构中的 managed_pages 用于表示该内存区域内被伙伴系统所管理的物理页数量。
数组 free_area[MAX_ORDER] 是伙伴系统的核心数据结构,我会在后面的系列文章中详细为大家介绍伙伴系统的实现。
vm_stat 维护了该内存区域物理内存的使用统计信息,前边介绍的 cat /proc/zoneinfo命令的输出数据就来源于这个 vm_stat。
物理内存区域中的预留内存
除了前边介绍的关于物理内存区域的这些基本信息之外,每个物理内存区域 struct zone 还为操作系统预留了一部分内存,这部分预留的物理内存用于内核的一些核心操作,这些操作无论如何是不允许内存分配失败的。
什么意思呢?内核中关于内存分配的场景无外乎有两种方式:
- 当进程请求内核分配内存时,如果此时内存比较充裕,那么进程的请求会被立刻满足,如果此时内存已经比较紧张,内核就需要将一部分不经常使用的内存进行回收,从而腾出一部分内存满足进程的内存分配的请求,在这个回收内存的过程中,进程会一直阻塞等待。
- 另一种内存分配场景,进程是不允许阻塞的,内存分配的请求必须马上得到满足,比如执行中断处理程序或者执行持有自旋锁等临界区内的代码时,进程就不允许睡眠,因为中断程序无法被重新调度。这时就需要内核提前为这些核心操作预留一部分内存,当内存紧张时,可以使用这部分预留的内存给这些操作分配。
|
|
nr_reserved_highatomic 表示的是该内存区域内预留内存的大小,范围为 128 到 65536 KB 之间。
lowmem_reserve 数组则是用于规定每个内存区域必须为自己保留的物理页数量,防止更高位的内存区域对自己的内存空间进行过多的侵占挤压。
那么什么是高位内存区域 ?什么是低位内存区域 ? 高位内存区域为什么会对低位内存区域进行侵占挤压呢 ?
因为物理内存区域比如前边介绍的 ZONE_DMA,ZONE_DMA32,ZONE_NORMAL,ZONE_HIGHMEM 这些都是针对物理内存进行的划分,所谓的低位内存区域和高位内存区域其实还是按照物理内存地址从低到高进行排列布局:
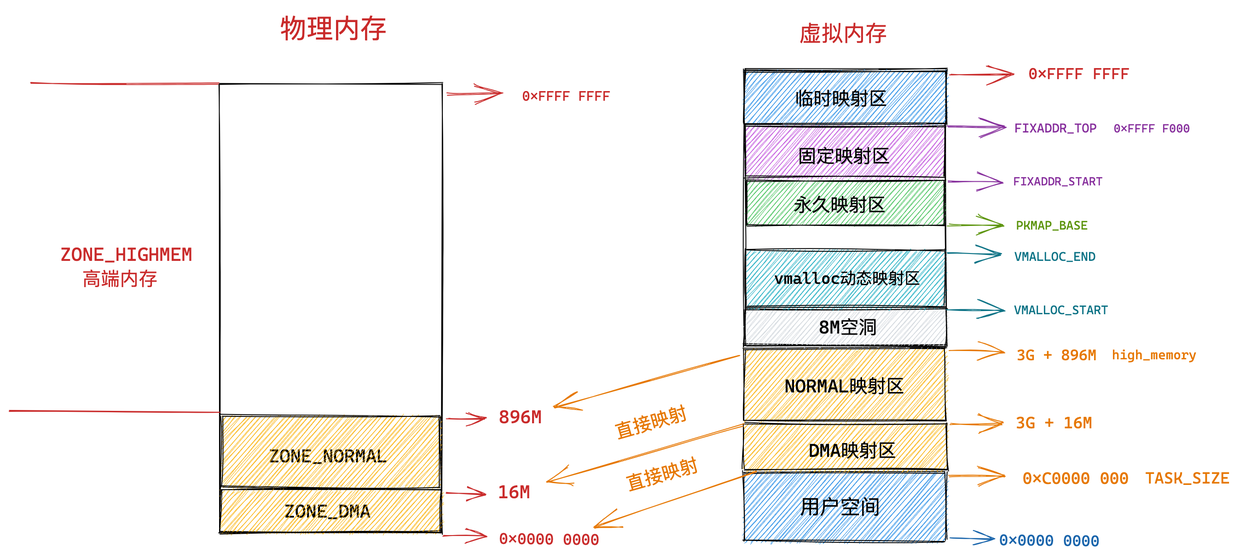
根据物理内存地址的高低,低位内存区域到高位内存区域的顺序依次是:ZONE_DMA,ZONE_DMA32,ZONE_NORMAL,ZONE_HIGHMEM。
高位内存区域为什么会对低位内存区域进行挤压呢 ?
一些用于特定功能的物理内存必须从特定的内存区域中进行分配,比如外设的 DMA 控制器就必须从 ZONE_DMA 或者 ZONE_DMA32 中分配内存。
但是一些用于常规用途的物理内存则可以从多个物理内存区域中进行分配,当 ZONE_HIGHMEM 区域中的内存不足时,内核可以从 ZONE_NORMAL 进行内存分配,ZONE_NORMAL 区域内存不足时可以进一步降级到 ZONE_DMA 区域进行分配。
而低位内存区域中的内存总是宝贵的,内核肯定希望这些用于常规用途的物理内存从常规内存区域中进行分配,这样能够节省 ZONE_DMA 区域中的物理内存保证 DMA 操作的内存使用需求,但是如果内存很紧张了,高位内存区域中的物理内存不够用了,那么内核就会去占用挤压其他内存区域中的物理内存从而满足内存分配的需求。
但是内核又不会允许高位内存区域对低位内存区域的无限制挤压占用,因为毕竟低位内存区域有它特定的用途,所以每个内存区域会给自己预留一定的内存,防止被高位内存区域挤压占用。而每个内存区域为自己预留的这部分内存就存储在 lowmem_reserve 数组中。
每个内存区域是按照一定的比例来计算自己的预留内存的,这个比例我们可以通过 cat /proc/sys/vm/lowmem_reserve_ratio 命令查看:

从左到右分别代表了 ZONE_DMA,ZONE_DMA32,ZONE_NORMAL,ZONE_MOVABLE,ZONE_DEVICE 物理内存区域的预留内存比例。
我使用的服务器是 64 位,所以没有 ZONE_HIGHMEM 区域。
那么每个内存区域如何根据各自的 lowmem_reserve_ratio 来计算各自区域中的预留内存大小呢?
为了让大家更好的理解,下面我们以 ZONE_DMA,ZONE_NORMAL,ZONE_HIGHMEM 这三个物理内存区域举例,它们的 lowmem_reserve_ratio 分别为 256,32,0。它们的大小分别是:8M,64M,256M,按照每页大小 4K 计算它们区域里包含的物理页个数分别为:2048, 16384, 65536。
| lowmem_reserve_ratio | 内存区域大小 | 物理内存页个数 | |
|---|---|---|---|
| ZONE_DMA | 256 | 8M | 2048 |
| ZONE_NORMAL | 32 | 64M | 16384 |
| ZONE_HIGHMEM | 0 | 256M | 65536 |
- ZONE_DMA 为防止被 ZONE_NORMAL 挤压侵占,而为自己预留的物理内存页为:
16384 / 256 = 64。 - ZONE_DMA 为防止被 ZONE_HIGHMEM 挤压侵占而为自己预留的物理内存页为:
(65536 + 16384) / 256 = 320。 - ZONE_NORMAL 为防止被 ZONE_HIGHMEM 挤压侵占而为自己预留的物理内存页为:
65536 / 32 = 2048。
各个内存区域为防止被高位内存区域过度挤压占用,而为自己预留的内存大小,我们可以通过前边 cat /proc/zoneinfo 命令来查看,输出信息的 protection:则表示各个内存区域预留内存大小。
此外我们还可以通过 sysctl对内核参数 lowmem_reserve_ratio 进行动态调整,这样内核会根据新的 lowmem_reserve_ratio 动态重新计算各个内存区域的预留内存大小。
前面介绍的物理内存区域内被伙伴系统所管理的物理页数量 managed_pages 的计算方式就通过 present_pages 减去这些预留的物理内存页 reserved_pages 得到的。
调整内核参数的多种方法,我在《从 Linux 内核角度探秘 JDK NIO 文件读写本质》 (opens new window)一文中的 “13.6 脏页回写参数的相关配置方式” 小节中已经详细介绍过了,感兴趣的同学可以在回看下。
物理内存区域中的水位线
内存资源是系统中最宝贵的系统资源,是有限的。当内存资源紧张的时候,系统的应对方法无非就是三种:
- 产生 OOM,内核直接将系统中占用大量内存的进程,将 OOM 优先级最高的进程干掉,释放出这个进程占用的内存供其他更需要的进程分配使用。
- 内存回收,将不经常使用到的内存回收,腾挪出来的内存供更需要的进程分配使用。
- 内存规整,将可迁移的物理页面进行迁移规整,消除内存碎片。从而获得更大的一片连续物理内存空间供进程分配。
我们都知道,内核将物理内存划分成一页一页的单位进行管理(每页 4K 大小)。内存回收的单位也是按页来的。在内核中,物理内存页有两种类型,针对这两种类型的物理内存页,内核会有不同的回收机制。
第一种就是文件页,所谓文件页就是其物理内存页中的数据来自于磁盘中的文件,当我们进行文件读取的时候,内核会根据局部性原理将读取的磁盘数据缓存在 page cache 中,page cache 里存放的就是文件页。当进程再次读取读文件页中的数据时,内核直接会从 page cache 中获取并拷贝给进程,省去了读取磁盘的开销。
对于文件页的回收通常会比较简单,因为文件页中的数据来自于磁盘,所以当回收文件页的时候直接回收就可以了,当进程再次读取文件页时,大不了再从磁盘中重新读取就是了。
但是当进程已经对文件页进行修改过但还没来得及同步回磁盘,此时文件页就是脏页,不能直接进行回收,需要先将脏页回写到磁盘中才能进行回收。
我们可以在进程中通过 fsync() 系统调用将指定文件的所有脏页同步回写到磁盘,同时内核也会根据一定的条件唤醒专门用于回写脏页的 pflush 内核线程。
关于文件页相关的详细内容,感兴趣的同学可以回看下我的这篇文章 《从 Linux 内核角度探秘 JDK NIO 文件读写本质》 (opens new window)。
而另外一种物理页类型是匿名页,所谓匿名页就是它背后并没有一个磁盘中的文件作为数据来源,匿名页中的数据都是通过进程运行过程中产生的,比如我们应用程序中动态分配的堆内存。
当内存资源紧张需要对不经常使用的那些匿名页进行回收时,因为匿名页的背后没有一个磁盘中的文件做依托,所以匿名页不能像文件页那样直接回收,无论匿名页是不是脏页,都需要先将匿名页中的数据先保存在磁盘空间中,然后在对匿名页进行回收。
并把释放出来的这部分内存分配给更需要的进程使用,当进程再次访问这块内存时,在重新把之前匿名页中的数据从磁盘空间中读取到内存就可以了,而这块磁盘空间可以是单独的一片磁盘分区(Swap 分区)或者是一个特殊的文件(Swap 文件)。匿名页的回收机制就是我们经常看到的 Swap 机制。
所谓的页面换出就是在 Swap 机制下,当内存资源紧张时,内核就会把不经常使用的这些匿名页中的数据写入到 Swap 分区或者 Swap 文件中。从而释放这些数据所占用的内存空间。
所谓的页面换入就是当进程再次访问那些被换出的数据时,内核会重新将这些数据从 Swap 分区或者 Swap 文件中读取到内存中来。
综上所述,物理内存区域中的内存回收分为文件页回收(通过 pflush 内核线程)和匿名页回收(通过 kswapd 内核进程)。Swap 机制主要针对的是匿名页回收。
那么当内存紧张的时候,内核到底是该回收文件页呢?还是该回收匿名页呢?
事实上 Linux 提供了一个 swappiness 的内核选项,我们可以通过 cat /proc/sys/vm/swappiness 命令查看,swappiness 选项的取值范围为 0 到 100,默认为 60。
swappiness 用于表示 Swap 机制的积极程度,数值越大,Swap 的积极程度越高,内核越倾向于回收匿名页。数值越小,Swap 的积极程度越低。内核就越倾向于回收文件页。
注意: swappiness 只是表示 Swap 积极的程度,当内存非常紧张的时候,即使将 swappiness 设置为 0 ,也还是会发生 Swap 的。
那么到底什么时候内存才算是紧张的?紧张到什么程度才开始 Swap 呢?这一切都需要一个量化的标准,于是就有了本小节的主题 —— 物理内存区域中的水位线。
内核会为每个 NUMA 节点中的每个物理内存区域定制三条用于指示内存容量的水位线,分别是:WMARK_MIN(页最小阈值), WMARK_LOW (页低阈值),WMARK_HIGH(页高阈值)。
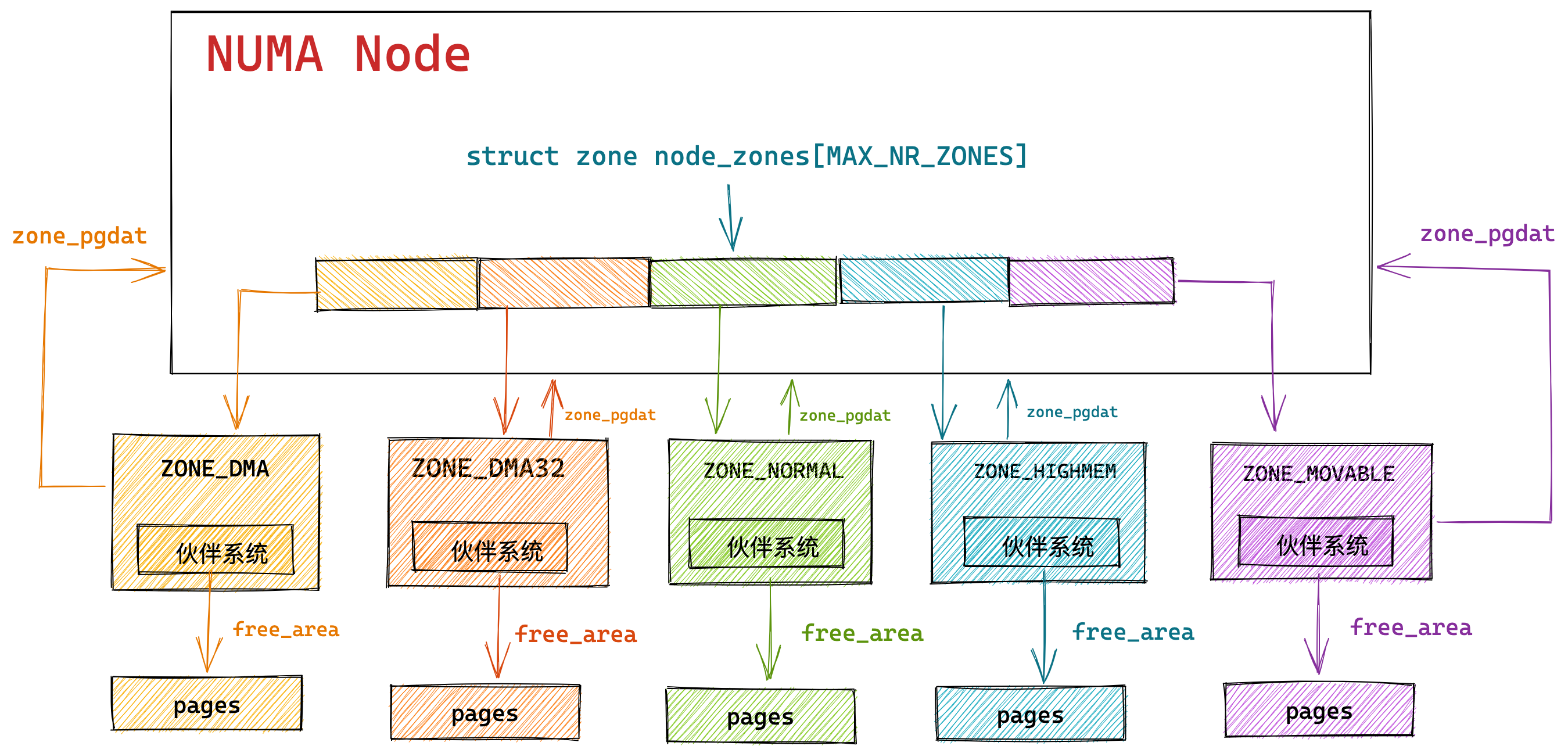
这三条水位线定义在 /include/linux/mmzone.h 文件中:
|
|
这三条水位线对应的 watermark 数值存储在每个物理内存区域 struct zone 结构中的 _watermark[NR_WMARK] 数组中。
|
|
注意:下面提到的物理内存区域的剩余内存是需要刨去上小节介绍的 lowmem_reserve 预留内存大小。
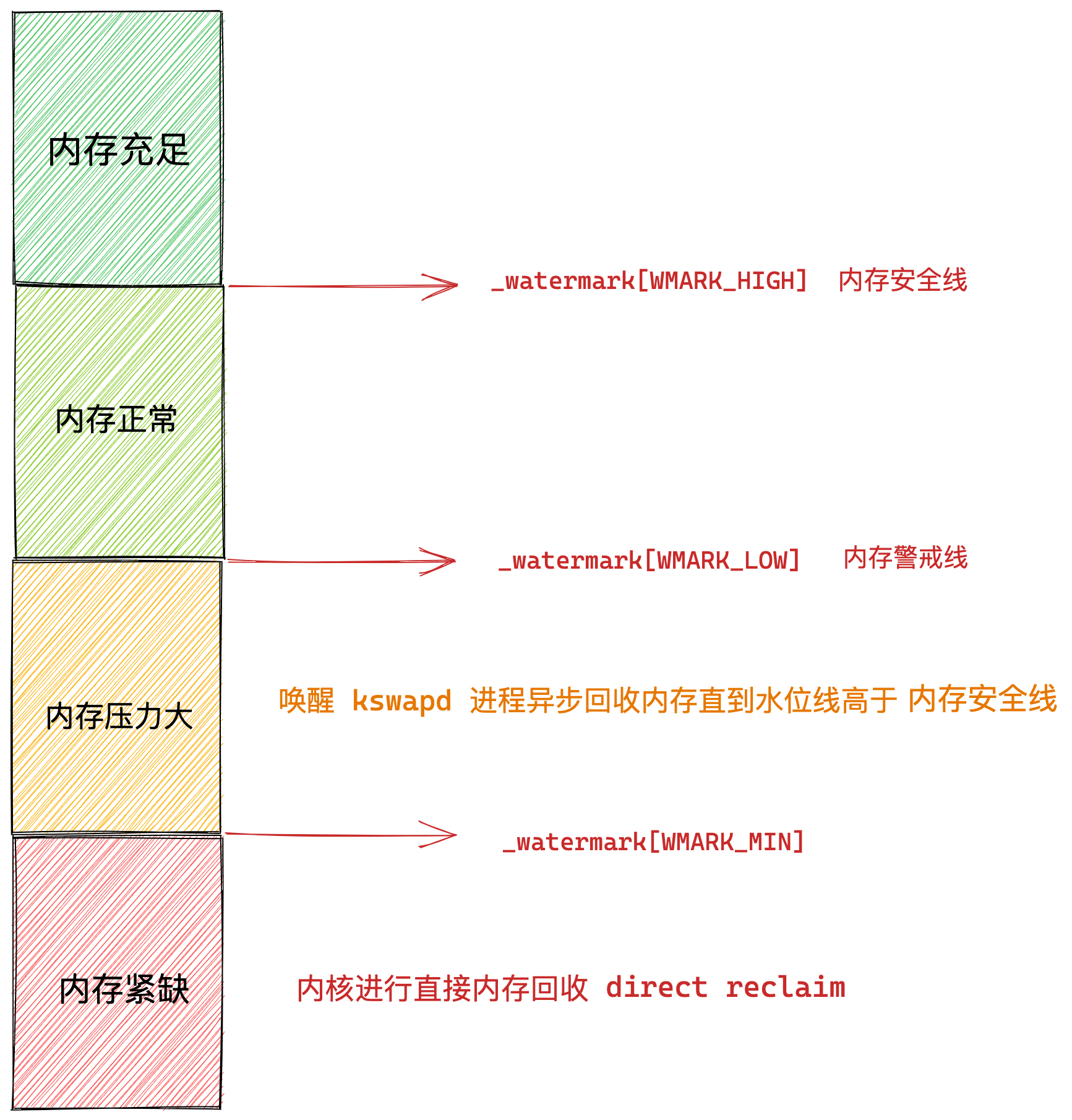
- 当该物理内存区域的剩余内存容量高于 _watermark[WMARK_HIGH] 时,说明此时该物理内存区域中的内存容量非常充足,内存分配完全没有压力。
- 当剩余内存容量在 _watermark[WMARK_LOW] 与_watermark[WMARK_HIGH] 之间时,说明此时内存有一定的消耗但是还可以接受,能够继续满足进程的内存分配需求。
- 当剩余内容容量在 _watermark[WMARK_MIN] 与 _watermark[WMARK_LOW] 之间时,说明此时内存容量已经有点危险了,内存分配面临一定的压力,但是还可以满足进程的内存分配要求,当给进程分配完内存之后,就会唤醒 kswapd 进程开始内存回收,直到剩余内存高于 _watermark[WMARK_HIGH] 为止。
在这种情况下,进程的内存分配会触发内存回收,但请求进程本身不会被阻塞,由内核的 kswapd 进程异步回收内存。
- 当剩余内容容量低于 _watermark[WMARK_MIN] 时,说明此时的内容容量已经非常危险了,如果进程在这时请求内存分配,内核就会进行直接内存回收,这时请求进程会同步阻塞等待,直到内存回收完毕。
位于 _watermark[WMARK_MIN] 以下的内存容量是预留给内核在紧急情况下使用的,这部分内存就是我们在 《5.1 物理内存区域中的预留内存》小节中介绍的预留内存 nr_reserved_highatomic。
我们可以通过 cat /proc/zoneinfo 命令来查看不同 NUMA 节点中不同内存区域中的水位线:
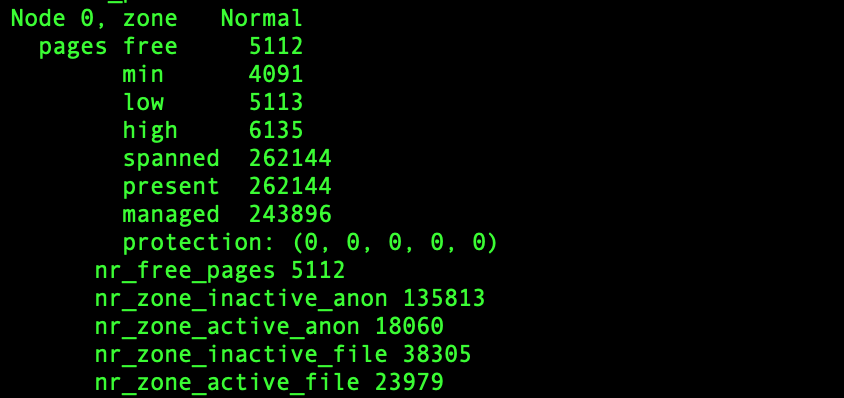
其中大部分字段的含义我已经在前面的章节中为大家介绍过了,下面我们只介绍和本小节内容相关的字段含义:
- free 就是该物理内存区域内剩余的内存页数,它的值和后面的 nr_free_pages 相同。
- min、low、high 就是上面提到的三条内存水位线:_watermark[WMARK_MIN],_watermark[WMARK_LOW] ,_watermark[WMARK_HIGH]。
- nr_zone_active_anon 和 nr_zone_inactive_anon 分别是该内存区域内活跃和非活跃的匿名页数量。
- nr_zone_active_file 和 nr_zone_inactive_file 分别是该内存区域内活跃和非活跃的文件页数量。
水位线的计算
在上小节中我们介绍了内核通过对物理内存区域设置内存水位线来决定内存回收的时机,那么这三条内存水位线的值具体是多少,内核中是根据什么计算出来的呢?
事实上 WMARK_MIN,WMARK_LOW ,WMARK_HIGH 这三个水位线的数值是通过内核参数 /proc/sys/vm/min_free_kbytes 为基准分别计算出来的,用户也可以通过 sysctl 来动态设置这个内核参数。
内核参数 min_free_kbytes 的单位为 KB 。

通常情况下 WMARK_LOW 的值是 WMARK_MIN 的 1.25 倍,WMARK_HIGH 的值是 WMARK_LOW 的 1.5 倍。而 WMARK_MIN 的数值就是由这个内核参数 min_free_kbytes 来决定的。
下面我们就来看下内核中关于 min_free_kbytes 的计算方式:
min_free_kbytes 的计算逻辑
以下计算逻辑是针对 64 位系统中内存区域水位线的计算,在 64 位系统中没有高端内存 ZONE_HIGHMEM 区域。
min_free_kbytes 的计算逻辑定义在内核文件 /mm/page_alloc.c 的 init_per_zone_wmark_min 方法中,用于计算最小水位线 WMARK_MIN 的数值也就是这里的 min_free_kbytes (单位为 KB)。 水位线的单位是物理内存页的数量。
|
|
首先我们需要先计算出当前 NUMA 节点中所有低位内存区域(除高端内存之外)中内存总容量之和。也即是说 lowmem_kbytes 的值为: ZONE_DMA 区域中 managed_pages + ZONE_DMA32 区域中 managed_pages + ZONE_NORMAL 区域中 managed_pages 。
lowmem_kbytes 的计算逻辑在 nr_free_zone_pages 方法中:
|
|
nr_free_zone_pages 方法上面的注释大家可能看的有点蒙,这里需要为大家解释一下,nr_free_zone_pages 方法的计算逻辑本意是给定一个 zone index (方法参数 offset),计算范围为:这个给定 zone 下面的所有低位内存区域。
nr_free_zone_pages 方法会计算这些低位内存区域内在 high watermark 水位线之上的内存容量( managed_pages - high_pages )之和。作为该方法的返回值。
但此时我们正准备计算这些水位线,水位线还没有值,所以此时这个方法的语义就是计算低位内存区域内被伙伴系统所管理的内存容量( managed_pages )之和。也就是我们想要的 lowmem_kbytes。
接下来在 init_per_zone_wmark_min 方法中会对 lowmem_kbytes * 16 进行开平方得到 new_min_free_kbytes。

如果计算出的 new_min_free_kbytes 大于用户设置的内核参数值 /proc/sys/vm/min_free_kbytes ,那么最终 min_free_kbytes 就是 new_min_free_kbytes。如果小于用户设定的值,那么就采用用户指定的 min_free_kbytes 。
min_free_kbytes 的取值范围限定在 128 到 65536 KB 之间。
随后内核会根据这个 min_free_kbytes 在 setup_per_zone_wmarks() 方法中计算出该物理内存区域的三条水位线。
最后在 setup_per_zone_lowmem_reserve() 方法中计算内存区域的预留内存大小,防止被高位内存区域过度挤压占用。该方法的逻辑就是我们在《5.1 物理内存区域中的预留内存》小节中提到的内容。
setup_per_zone_wmarks 计算水位线
这里我们依然不会考虑高端内存区域 ZONE_HIGHMEM。
物理内存区域内的三条水位线:WMARK_MIN,WMARK_LOW,WMARK_HIGH 的最终计算逻辑是在 __setup_per_zone_wmarks 方法中完成的:
|
|
在 for_each_zone 循环内依次遍历 NUMA 节点中的所有内存区域 zone,计算每个内存区域 zone 里的内存水位线。其中计算 WMARK_MIN 水位线的核心逻辑封装在 do_div 方法中,在 do_div 方法中会先计算每个 zone 内存容量之间的比例,然后根据这个比例去从 min_free_kbytes 中划分出对应 zone 的 WMARK_MIN 水位线来。
比如:当前 NUMA 节点中有两个 zone :ZONE_DMA 和 ZONE_NORMAL,内存容量大小分别是:100 M 和 800 M。那么 ZONE_DMA 与 ZONE_NORMAL 之间的比例就是 1 :8。
根据这个比例,ZONE_DMA 区域里的 WMARK_MIN 水位线就是:min_free_kbytes * 1 / 8 。ZONE_NORMAL 区域里的 WMARK_MIN 水位线就是:min_free_kbytes * 7 / 8。
计算出了 WMARK_MIN 的值,那么接下来 WMARK_LOW, WMARK_HIGH 的值也就好办了,它们都是基于 WMARK_MIN 计算出来的。
WMARK_LOW 的值是 WMARK_MIN 的 1.25 倍,WMARK_HIGH 的值是 WMARK_LOW 的 1.5 倍。
此外,大家可能对下面这段代码比较有疑问?
|
|
这段代码主要是通过内核参数 watermark_scale_factor 来调节水位线:WMARK_MIN,WMARK_LOW,WMARK_HIGH 之间的间距,那么为什么要调整水位线之间的间距大小呢?
watermark_scale_factor 调整水位线的间距
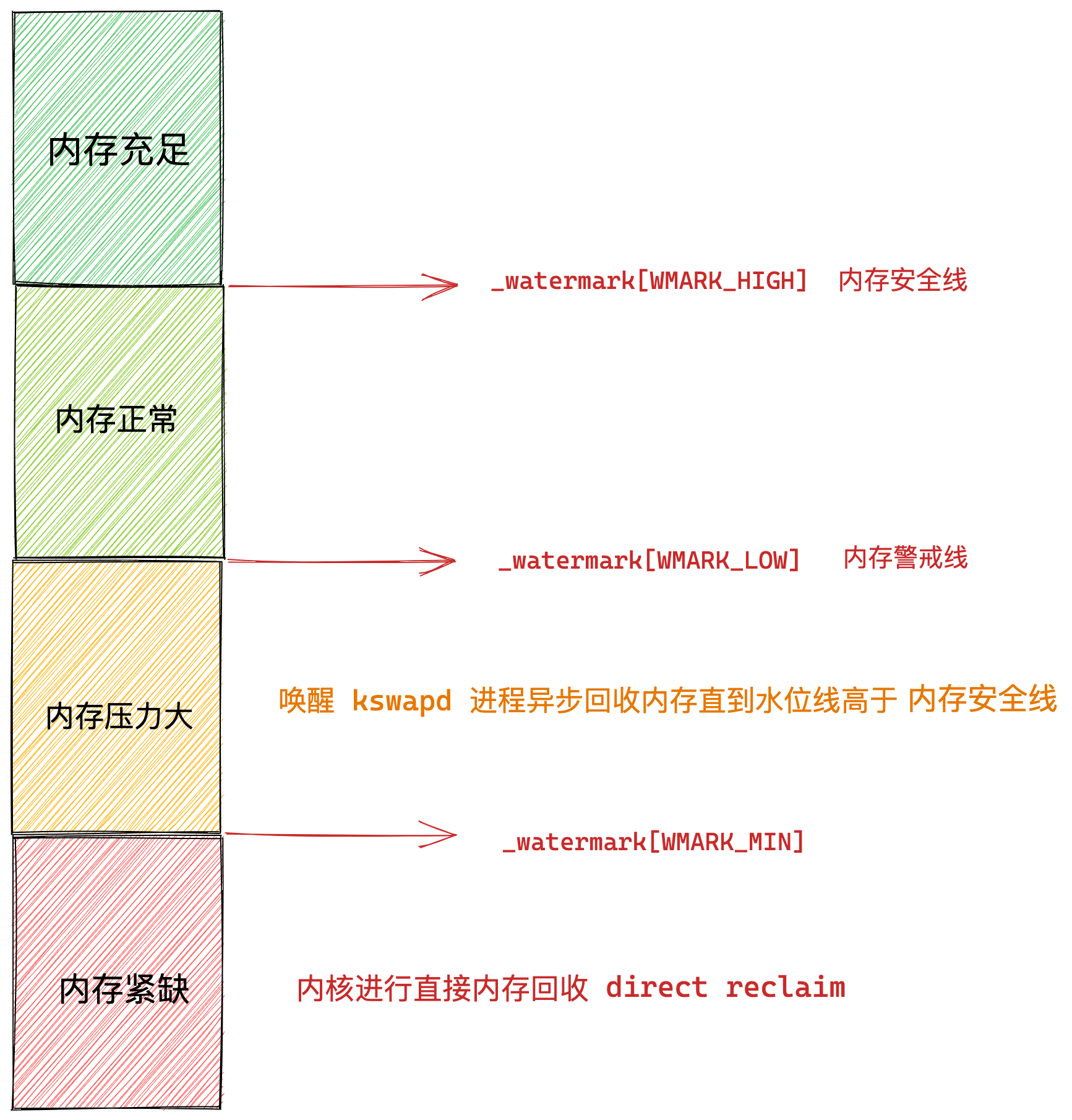
为了避免内核的直接内存回收 direct reclaim 阻塞进程影响系统的性能,所以我们需要尽量保持内存区域中的剩余内存容量尽量在 WMARK_MIN 水位线之上,但是有一些极端情况,比如突然遇到网络流量增大,需要短时间内申请大量的内存来存放网络请求数据,此时 kswapd 回收内存的速度可能赶不上内存分配的速度,从而造成直接内存回收 direct reclaim,影响系统性能。
在内存分配过程中,剩余内存容量处于 WMARK_MIN 与 WMARK_LOW 水位线之间会唤醒 kswapd 进程来回收内存,直到内存容量恢复到 WMARK_HIGH 水位线之上。
剩余内存容量低于 WMARK_MIN 水位线时就会触发直接内存回收 direct reclaim。
而剩余内存容量高于 WMARK_LOW 水位线又不会唤醒 kswapd 进程,因此 kswapd 进程活动的关键范围在 WMARK_MIN 与 WMARK_LOW 之间,而为了应对这种突发的网络流量暴增,我们需要保证 kswapd 进程活动的范围大一些,这样内核就能够时刻进行内存回收使得剩余内存容量较长时间的保持在 WMARK_HIGH 水位线之上。
这样一来就要求 WMARK_MIN 与 WMARK_LOW 水位线之间的间距不能太小,因为 WMARK_LOW 水位线之上就不会唤醒 kswapd 进程了。
因此内核引入了 /proc/sys/vm/watermark_scale_factor 参数来调节水位线之间的间距。该内核参数默认值为 10,最大值为 3000。

那么如何使用 watermark_scale_factor 参数调整水位线之间的间距呢?
水位线间距计算公式:(watermark_scale_factor / 10000) * managed_pages 。
|
|
在内核中水位线间距计算逻辑是:(WMARK_MIN / 4) 与 (zone_managed_pages * watermark_scale_factor / 10000) 之间较大的那个值。
用户可以通过 sysctl 来动态调整 watermark_scale_factor 参数,内核会动态重新计算水位线之间的间距,使得 WMARK_MIN 与 WMARK_LOW 之间留有足够的缓冲余地,使得 kswapd 能够有时间回收足够的内存,从而解决直接内存回收导致的性能抖动问题。
物理内存区域中的冷热页
之前我在《一文聊透对象在JVM中的内存布局,以及内存对齐和压缩指针的原理及应用》 (opens new window)一文中为大家介绍 CPU 的高速缓存时曾提到过,根据摩尔定律:芯片中的晶体管数量每隔 18 个月就会翻一番。导致 CPU 的性能和处理速度变得越来越快,而提升 CPU 的运行速度比提升内存的运行速度要容易和便宜的多,所以就导致了 CPU 与内存之间的速度差距越来越大。
CPU 与 内存之间的速度差异到底有多大呢? 我们知道寄存器是离 CPU 最近的,CPU 在访问寄存器的时候速度近乎于 0 个时钟周期,访问速度最快,基本没有时延。而访问内存则需要 50 - 200 个时钟周期。
所以为了弥补 CPU 与内存之间巨大的速度差异,提高CPU的处理效率和吞吐,于是我们引入了 L1 , L2 , L3 高速缓存集成到 CPU 中。CPU 访问高速缓存仅需要用到 1 - 30 个时钟周期,CPU 中的高速缓存是对内存热点数据的一个缓存。
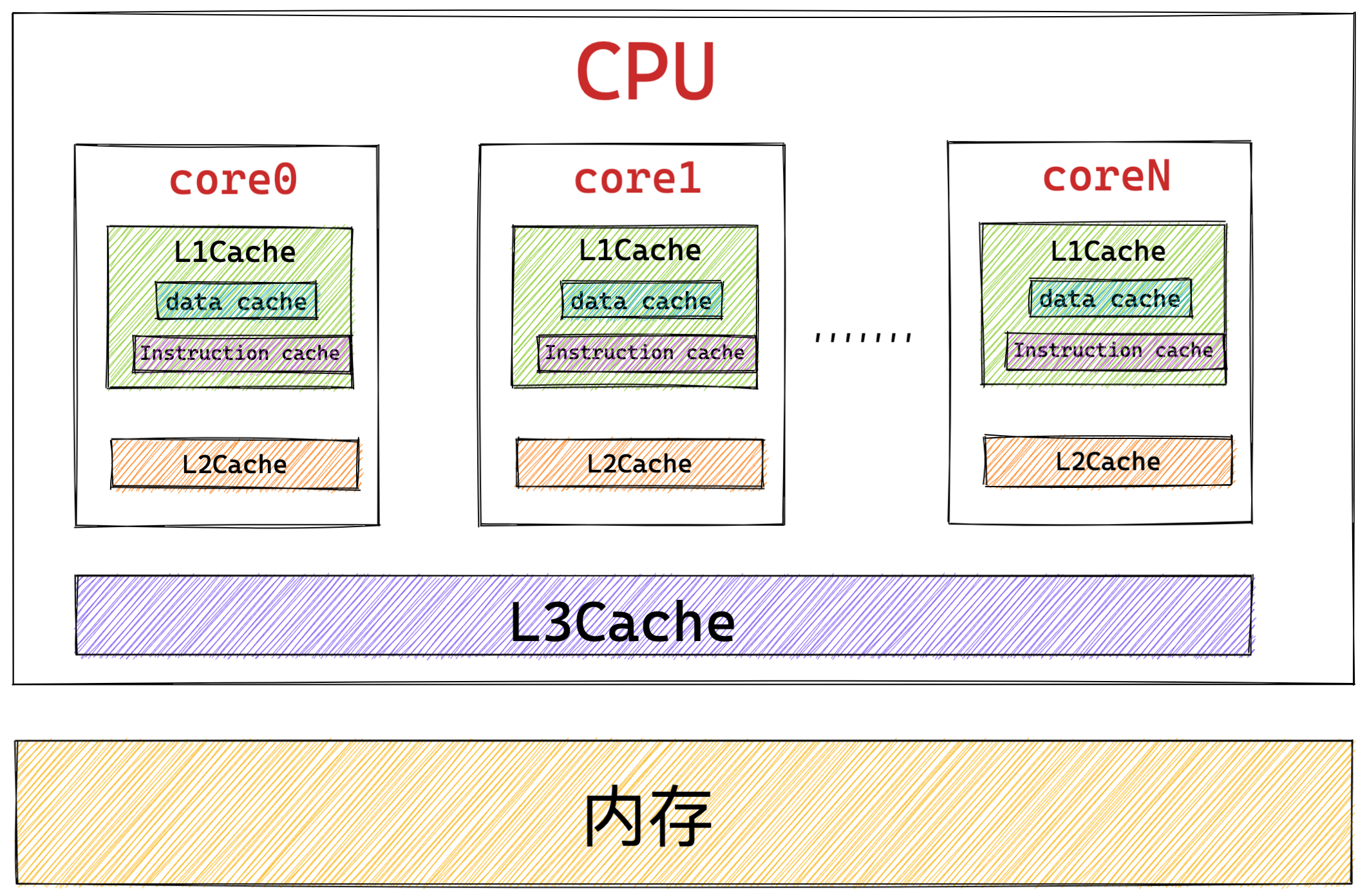
CPU 访问高速缓存的速度比访问内存的速度快大约10倍,引入高速缓存的目的在于消除CPU与内存之间的速度差距,CPU 用高速缓存来用来存放内存中的热点数据。
另外我们根据程序的时间局部性原理可以知道,内存的数据一旦被访问,那么它很有可能在短期内被再次访问,如果我们把经常访问的物理内存页缓存在 CPU 的高速缓存中,那么当进程再次访问的时候就会直接命中 CPU 的高速缓存,避免了进一步对内存的访问,极大提升了应用程序的性能。
程序局部性原理表现为:时间局部性和空间局部性。时间局部性是指如果程序中的某条指令一旦执行,则不久之后该指令可能再次被执行;如果某块数据被访问,则不久之后该数据可能再次被访问。空间局部性是指一旦程序访问了某个存储单元,则不久之后,其附近的存储单元也将被访问。
本文我们的主题是 Linux 物理内存的管理,那么在 NUMA 内存架构下,这些 NUMA 节点中的物理内存区域 zone 管理的这些物理内存页,哪些是在 CPU 的高速缓存中?哪些又不在 CPU 的高速缓存中呢?内核如何来管理这些加载进 CPU 高速缓存中的物理内存页呢?
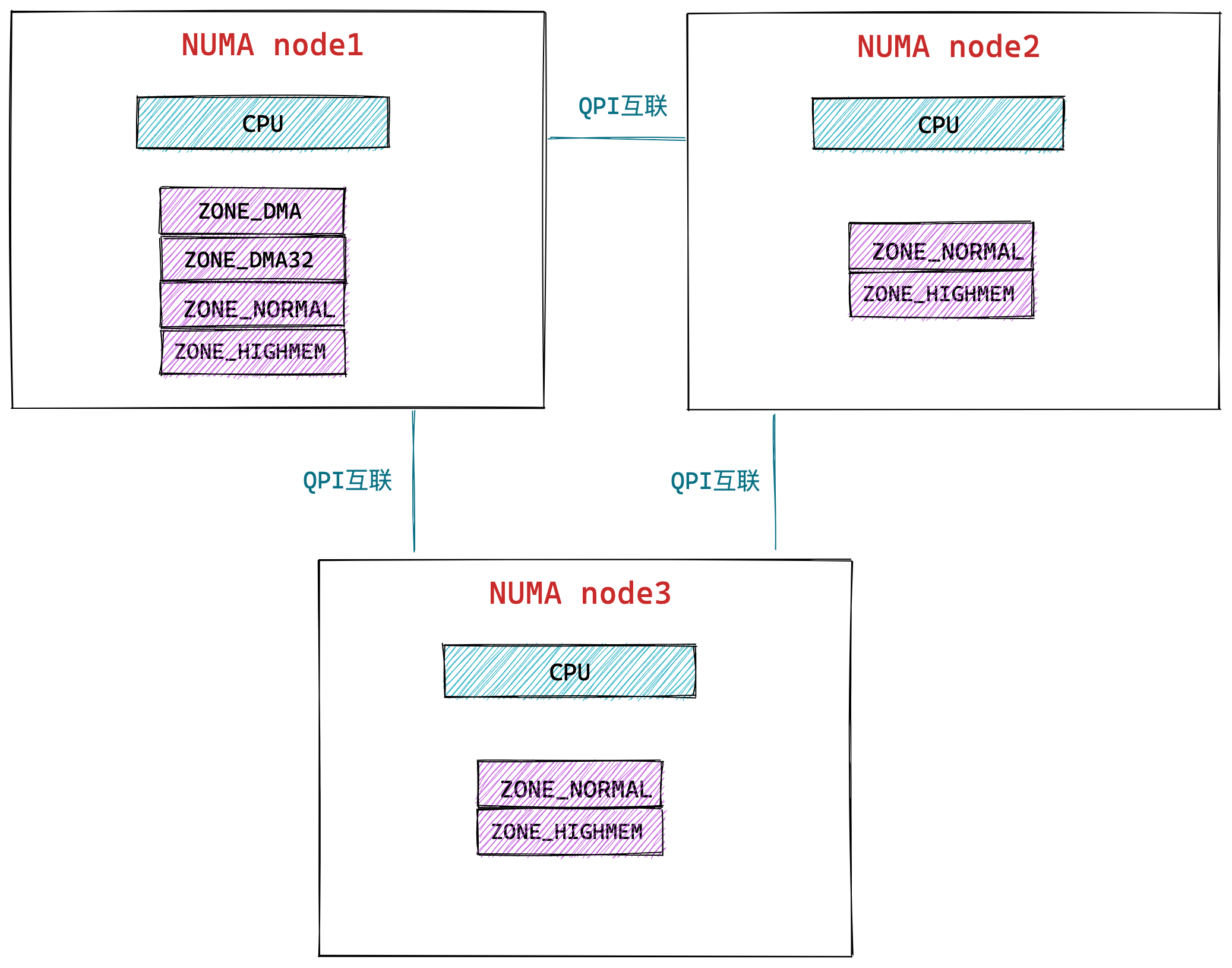
本小节标题中所谓的热页就是已经加载进 CPU 高速缓存中的物理内存页,所谓的冷页就是还未加载进 CPU 高速缓存中的物理内存页,冷页是热页的后备选项。
我先以内核版本 2.6.25 之前的冷热页相关的管理逻辑为大家讲解,因为这个版本的逻辑比较直观,大家更容易理解。在这个基础之上,我会在介绍内核 5.0 版本对于冷热页管理的逻辑,差别不是很大。
|
|
在 2.6.25 版本之前的内核源码中,物理内存区域 struct zone 包含了一个 struct per_cpu_pageset 类型的数组 pageset。其中内核关于冷热页的管理全部封装在 struct per_cpu_pageset 结构中。
因为每个 CPU 都有自己独立的高速缓存,所以每个 CPU 对应一个 per_cpu_pageset 结构,pageset 数组容量 NR_CPUS 是一个可以在编译期间配置的宏常数,表示内核可以支持的最大 CPU个数,注意该值并不是系统实际存在的 CPU 数量。
在 NUMA 内存架构下,每个物理内存区域都是属于一个特定的 NUMA 节点,NUMA 节点中包含了一个或者多个 CPU,NUMA 节点中的每个内存区域会关联到一个特定的 CPU 上,但 struct zone 结构中的 pageset 数组包含的是系统中所有 CPU 的高速缓存页。
因为虽然一个内存区域关联到了 NUMA 节点中的一个特定 CPU 上,但是其他CPU 依然可以访问该内存区域中的物理内存页,因此其他 CPU 上的高速缓存仍然可以包含该内存区域中的物理内存页。
每个 CPU 都可以访问系统中的所有物理内存页,尽管访问速度不同(这在前边我们介绍 NUMA 架构的时候已经介绍过),因此特定的物理内存区域 struct zone 不仅要考虑到所属 NUMA 节点中相关的 CPU,还需要照顾到系统中的其他 CPU。
在表示每个 CPU 高速缓存结构 struct per_cpu_pageset 中有一个 struct per_cpu_pages 类型的数组 pcp,容量为 2。 数组 pcp 索引 0 表示该内存区域加载进 CPU 高速缓存的热页集合,索引 1 表示该内存区域中还未加载进 CPU 高速缓存的冷页集合。
|
|
struct per_cpu_pages 结构则是最终用于管理 CPU 高速缓存中的热页,冷页集合的数据结构:
|
|
- int count :表示集合中包含的物理页数量,如果该结构是热页集合,则表示加载进 CPU 高速缓存中的物理页面个数。
- struct list_head list :该 list 是一个双向链表,保存了当前 CPU 的热页或者冷页。
- int batch:每次批量向 CPU 高速缓存填充或者释放的物理页面个数。
- int high:如果集合中页面的数量 count 值超过了 high 的值,那么表示 list 中的页面太多了,内核会从高速缓存中释放 batch 个页面到物理内存区域中的伙伴系统中。
- int low : 在之前更老的版本中,per_cpu_pages 结构还定义了一个 low 下限值,如果 count 低于 low 的值,那么内核会从伙伴系统中申请 batch 个页面填充至当前 CPU 的高速缓存中。之后的版本中取消了 low ,内核对容量过低的页面集合并没有显示的使用水位值 low,当列表中没有其他成员时,内核会重新填充高速缓存。
以上则是内核版本 2.6.25 之前管理 CPU 高速缓存冷热页的相关数据结构,我们看到在 2.6.25 之前,内核是使用两个 per_cpu_pages 结构来分别管理冷页和热页集合的
后来内核开发人员通过测试发现,用两个列表来管理冷热页,并不会比用一个列表集中管理冷热页带来任何的实质性好处,因此在内核版本 2.6.25 之后,将冷页和热页的管理合并在了一个列表中,热页放在列表的头部,冷页放在列表的尾部。
在内核 5.0 的版本中, struct zone 结构中去掉了原来使用 struct per_cpu_pageset 数,因为 struct per_cpu_pageset 结构中分别管理了冷页和热页。
|
|
直接使用 struct per_cpu_pages 结构的链表来集中管理系统中所有 CPU 高速缓存冷热页。
|
|
前面我们提到,内核为了最大程度的防止内存碎片,将物理内存页面按照是否可迁移的特性分为了多种迁移类型:可迁移,可回收,不可迁移。在 struct per_cpu_pages 结构中,每一种迁移类型都会对应一个冷热页链表。
内核如何描述物理内存页
经过前边几个小节的介绍,我想大家现在应该对 Linux 内核整个内存管理框架有了一个总体上的认识。
如上图所示,在 NUMA 架构下内存被划分成了一个一个的内存节点(NUMA Node),在每个 NUMA 节点中,内核又根据节点内物理内存的功能用途不同,将 NUMA 节点内的物理内存划分为四个物理内存区域分别是:ZONE_DMA,ZONE_DMA32,ZONE_NORMAL,ZONE_HIGHMEM。其中 ZONE_MOVABLE 区域是逻辑上的划分,主要是为了防止内存碎片和支持内存的热插拔。
物理内存区域中管理的就是物理内存页( Linux 内存管理的最小单位),前面我们介绍的内核对物理内存的换入,换出,回收,内存映射等操作的单位就是页。内核为每一个物理内存区域分配了一个伙伴系统,用于管理该物理内存区域下所有物理内存页面的分配和释放。
Linux 默认支持的物理内存页大小为 4KB,在 64 位体系结构中还可以支持 8KB,有的处理器还可以支持 4MB,支持物理地址扩展 PAE 机制的处理器上还可以支持 2MB。
那么 Linux 为什么会默认采用 4KB 作为标准物理内存页的大小呢 ?
首先关于物理页面的大小,Linux 规定必须是 2 的整数次幂,因为 2 的整数次幂可以将一些数学运算转换为移位操作,比如乘除运算可以通过移位操作来实现,这样效率更高。
那么系统支持 4KB,8KB,2MB,4MB 等大小的物理页面,它们都是 2 的整数次幂,为啥偏偏要选 4KB 呢?
因为前面提到,在内存紧张的时候,内核会将不经常使用到的物理页面进行换入换出等操作,还有在内存与文件映射的场景下,都会涉及到与磁盘的交互,数据在磁盘中组织形式也是根据一个磁盘块一个磁盘块来管理的,4kB 和 4MB 都是磁盘块大小的整数倍,但在大多数情况下,内存与磁盘之间传输小块数据时会更加的高效,所以综上所述内核会采用 4KB 作为默认物理内存页大小。
假设我们有 4G 大小的物理内存,每个物理内存页大小为 4K,那么这 4G 的物理内存会被内核划分为 1M 个物理内存页,内核使用一个 struct page 的结构体来描述物理内存页,而每个 struct page 结构体占用内存大小为 40 字节,那么内核就需要用额外的 40 * 1M = 40M 的内存大小来描述物理内存页。
对于 4G 物理内存而言,这额外的 40M 内存占比相对较小,这个代价勉强可以接受,但是对内存锱铢必较的内核来说,还是会尽最大努力想尽一切办法来控制 struct page 结构体的大小。
因为对于 4G 的物理内存来说,内核就需要使用 1M 个物理页面来管理,1M 个物理页的数量已经是非常庞大的了,因此在后续的内核迭代中,对于 struct page 结构的任何微小改动,都可能导致用于管理物理内存页的 struct page 实例所需要的内存暴涨。
回想一下我们经历过的很多复杂业务系统,由于业务逻辑已经非常复杂,在加上业务版本日积月累的迭代,整个业务系统已经变得异常复杂,在这种类型的业务系统中,我们经常会使用一个非常庞大的类来包装全量的业务响应信息用以应对各种复杂的场景,但是这个类已经包含了太多太多的业务字段了,而且这些业务字段在有的场景中会用到,在有的场景中又不会用到,后面还可能继续临时增加很多字段。系统的维护就这样变得越来越困难。
相比上面业务系统开发中随意地增加改动类中的字段,在内核中肯定是不会允许这样的行为发生的。struct page 结构是内核中访问最为频繁的一个结构体,就好比是 Linux 世界里最繁华的地段,在这个最繁华的地段租间房子,那租金可谓是相当的高,同样的道理,内核在 struct page 结构体中增加一个字段的代价也是非常之大,该结构体中每个字段中的每个比特,内核用的都是淋漓尽致。
但是 struct page 结构同样会面临很多复杂的场景,结构体中的某些字段在某些场景下有用,而在另外的场景下却没有用,而内核又不可能像业务系统开发那样随意地为 struct page 结构增加字段,那么内核该如何应对这种情况呢?
下面我们即将会看到 struct page 结构体里包含了大量的 union 结构,而 union 结构在 C 语言中被用于同一块内存根据不同场景保存不同类型数据的一种方式。内核之所以在 struct page 结构中使用 union,是因为一个物理内存页面在内核中的使用场景和使用方式是多种多样的。在这多种场景下,利用 union 尽最大可能使 struct page 的内存占用保持在一个较低的水平。
struct page 结构可谓是内核中最为繁杂的一个结构体,应用在内核中的各种功能场景下,在本小节中一一解释清楚各个字段的含义是不现实的,下面我只会列举 struct page 中最为常用的几个字段,剩下的字段我会在后续相关文章中专门介绍。
|
|
下面我就来为大家介绍下 struct page 结构在不同场景下的使用方式:
第一种使用方式是内核直接分配使用一整页的物理内存,在《5.2 物理内存区域中的水位线》小节中我们提到,内核中的物理内存页有两种类型,分别用于不同的场景:
- 一种是匿名页,匿名页背后并没有一个磁盘中的文件作为数据来源,匿名页中的数据都是通过进程运行过程中产生的,匿名页直接和进程虚拟地址空间建立映射供进程使用。
- 另外一种是文件页,文件页中的数据来自于磁盘中的文件,文件页需要先关联一个磁盘中的文件,然后再和进程虚拟地址空间建立映射供进程使用,使得进程可以通过操作虚拟内存实现对文件的操作,这就是我们常说的内存文件映射。
|
|
我们首先来介绍下 struct page 结构中的 struct address_space *mapping 字段。提到 struct address_space 结构,如果大家之前看过我 《从 Linux 内核角度探秘 JDK NIO 文件读写本质》 (opens new window)这篇文章的话,一定不会对 struct address_space 感到陌生。
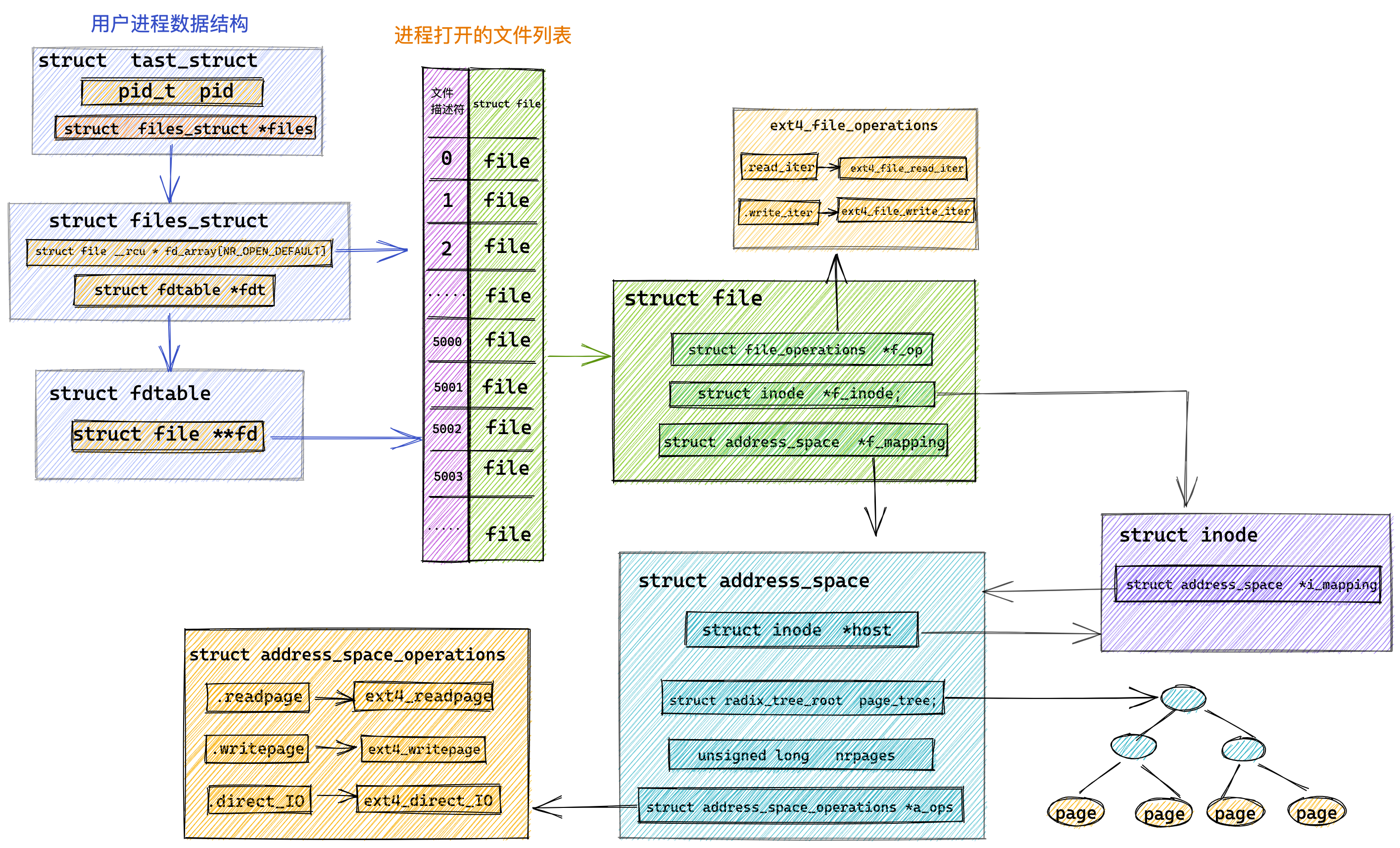
在内核中每个文件都会有一个属于自己的 page cache(页高速缓存),页高速缓存在内核中的结构体就是这个 struct address_space。它被文件的 inode 所持有。
如果当前物理内存页 struct page 是一个文件页的话,那么 mapping 指针的最低位会被设置为 0 ,指向该内存页关联文件的 struct address_space(页高速缓存),pgoff_t index 字段表示该内存页 page 在页高速缓存 page cache 中的 index 索引。内核会利用这个 index 字段从 page cache 中查找该物理内存页,
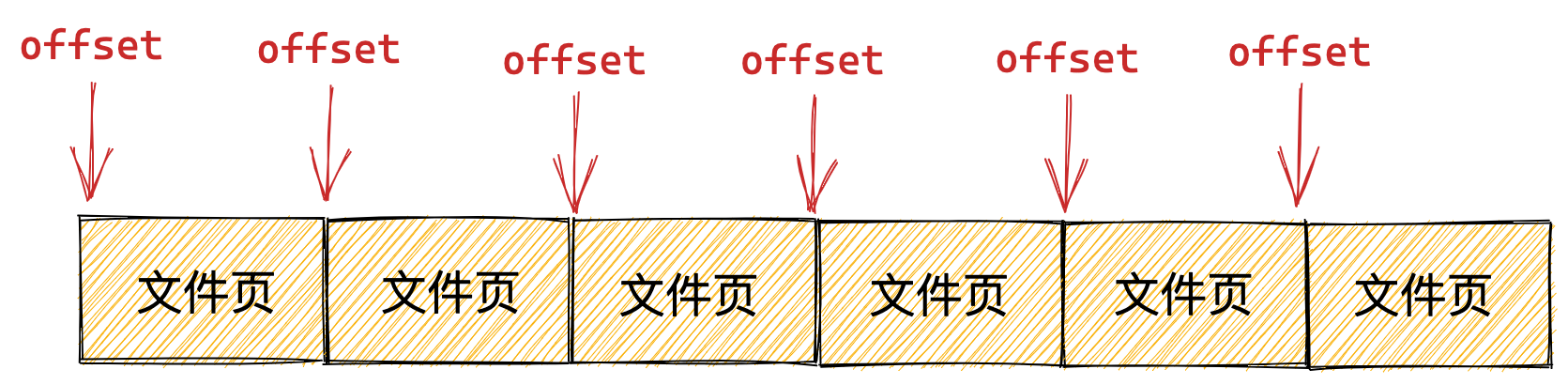
同时该 pgoff_t index 字段也表示该内存页中的文件数据在文件内部的偏移 offset。偏移单位为 page size。
对相关查找细节感兴趣的同学可以在回看下我 《从 Linux 内核角度探秘 JDK NIO 文件读写本质》 (opens new window)文章中的《8. page cache 中查找缓存页》小节。
如果当前物理内存页 struct page 是一个匿名页的话,那么 mapping 指针的最低位会被设置为 1 , 指向该匿名页在进程虚拟内存空间中的匿名映射区域 struct anon_vma 结构(每个匿名页对应唯一的 anon_vma 结构),用于物理内存到虚拟内存的反向映射。
匿名页的反向映射
我们通常所说的内存映射是正向映射,即从虚拟内存到物理内存的映射。而反向映射则是从物理内存到虚拟内存的映射,用于当某个物理内存页需要进行回收或迁移时,此时需要去找到这个物理页被映射到了哪些进程的虚拟地址空间中,并断开它们之间的映射。
在没有反向映射的机制前,需要去遍历所有进程的虚拟地址空间中的映射页表,这个效率显然是很低下的。有了反向映射机制之后内核就可以直接找到该物理内存页到所有进程映射的虚拟地址空间 VMA ,并从 VMA 使用的进程页表中取消映射,
谈到 VMA 大家一定不会感到陌生,VMA 相关的内容我在 《深入理解 Linux 虚拟内存管理》 (opens new window)这篇文章中详细的介绍过。
如下图所示,进程的虚拟内存空间在内核中使用 struct mm_struct 结构表示,进程的虚拟内存空间包含了一段一段的虚拟内存区域 VMA,比如我们经常接触到的堆,栈。内核中使用 struct vm_area_struct 结构来描述这些虚拟内存区域。
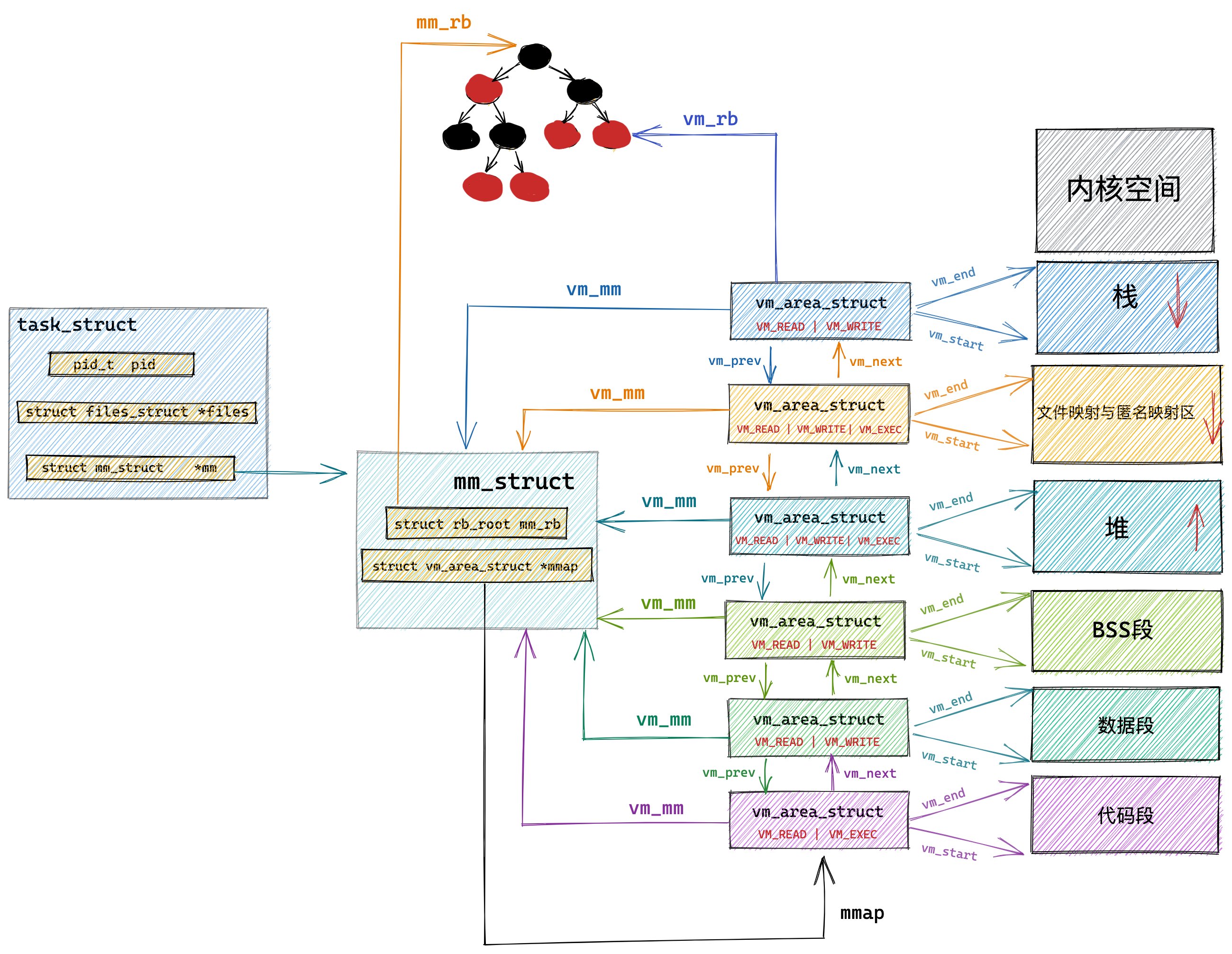
这里我只列举出 struct vm_area_struct 结构中与匿名页反向映射相关的字段属性:
|
|
这里大家可能会感到好奇,既然内核中有了 struct vm_area_struct 结构来描述虚拟内存区域,那不管是文件页也好,还是匿名页也好,都可以使用 struct vm_area_struct 结构体来进行描述,这里为什么有会出现 struct anon_vma 结构和 struct anon_vma_chain 结构?这两个结构到底是干嘛的?如何利用它俩来完成匿名内存页的反向映射呢?
根据前几篇文章的内容我们知道,进程利用 fork 系统调用创建子进程的时候,内核会将父进程的虚拟内存空间相关的内容拷贝到子进程的虚拟内存空间中,此时子进程的虚拟内存空间和父进程的虚拟内存空间是一模一样的,其中虚拟内存空间中映射的物理内存页也是一样的,在内核中都是同一份,在父进程和子进程之间共享(包括 anon_vma 和 anon_vma_chain)。
当进程在向内核申请内存的时候,内核首先会为进程申请的这块内存创建初始化一段虚拟内存区域 struct vm_area_struct 结构,但是并不会为其分配真正的物理内存。
当进程开始访问这段虚拟内存时,内核会产生缺页中断,在缺页中断处理函数中才会去真正的分配物理内存(这时才会为子进程创建自己的 anon_vma 和 anon_vma_chain),并建立虚拟内存与物理内存之间的映射关系(正向映射)。
|
|
这里我们主要关注 do_anonymous_page 函数,正是在这里内核完成了 struct anon_vma 结构和 struct anon_vma_chain 结构的创建以及相关匿名页反向映射数据结构的相互关联。
|
|
在 do_anonymous_page 匿名页缺页处理函数中会为 struct vm_area_struct 结构创建匿名页相关的 struct anon_vma 结构和 struct anon_vma_chain 结构。
并在 anon_vma_prepare 函数中实现 anon_vma 和 anon_vma_chain 之间的关联 ,随后调用 alloc_zeroed_user_highpage_movable 从伙伴系统中获取物理内存页 struct page,并在 page_add_new_anon_rmap 函数中完成 struct page 与 anon_vma 的关联(这里正是反向映射关系建立的关键)
在介绍匿名页反向映射源码实现之前,我先来为大家介绍一下相关的两个重要数据结构 struct anon_vma 和 struct anon_vma_chain,方便大家理解为何 struct page 与 anon_vma 关联起来就能实现反向映射?
前面我们提到,匿名页的反向映射关键就是建立物理内存页 struct page 与进程虚拟内存空间 VMA 之间的映射关系。
匿名页的 struct page 中的 mapping 指针指向的是 struct anon_vma 结构。
|
|
只要我们实现了 anon_vma 与 vm_area_struct 之间的关联,那么 page 到 vm_area_struct 之间的映射就建立起来了,struct anon_vma_chain 结构做的事情就是建立 anon_vma 与 vm_area_struct 之间的关联关系。
|
|
struct anon_vma_chain 结构通过其中的 vma 指针和 anon_vma 指针将相关的匿名页与其映射的进程虚拟内存空间关联了起来。
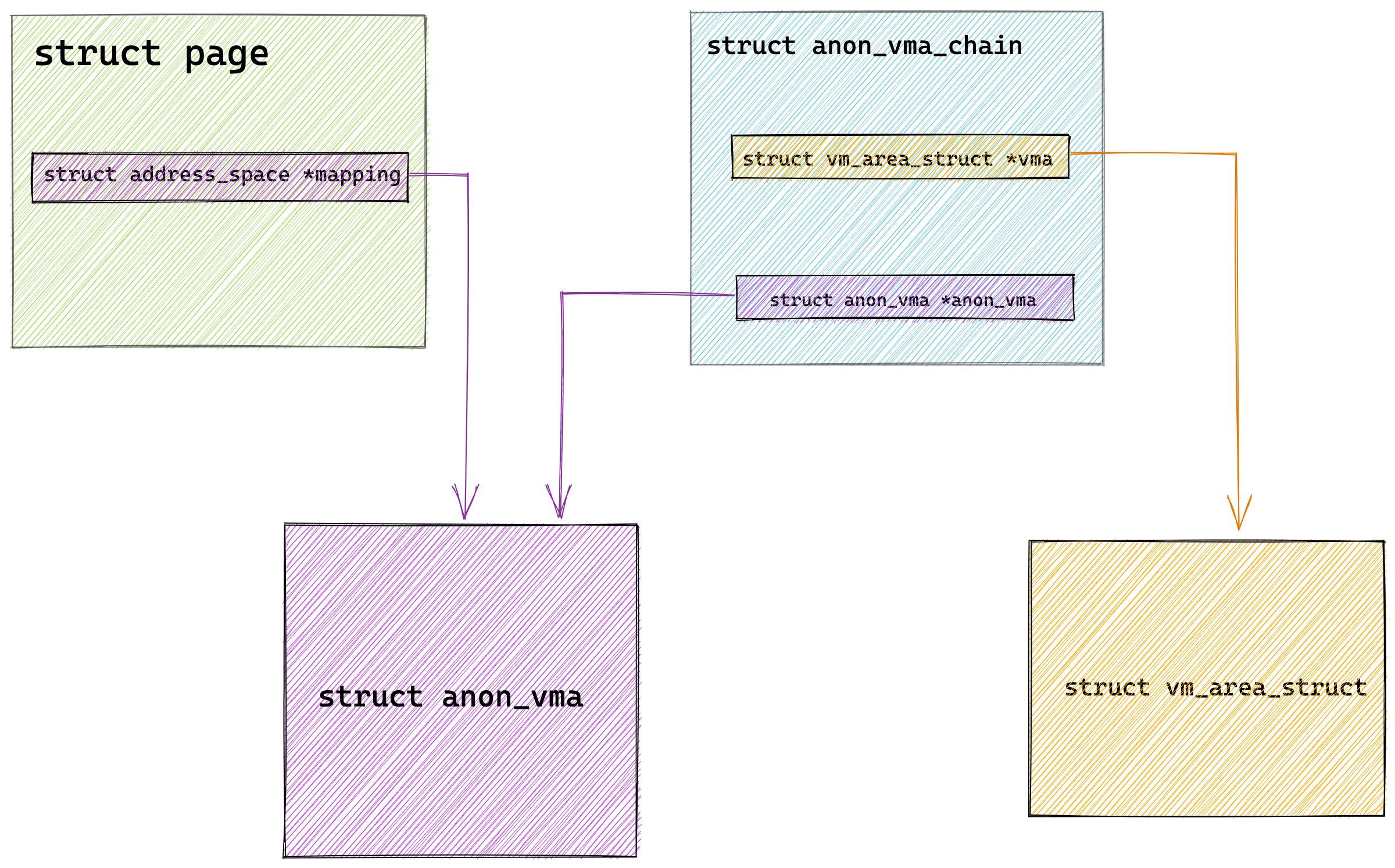
从目前来看匿名页 struct page 算是与 anon_vma 建立了关系,又通过 anon_vma_chain 将 anon_vma 与 vm_area_struct 建立了关系。那么就剩下最后一道关系需要打通了,就是如何通过 anon_vma 找到 anon_vma_chain 进而找到 vm_area_struct 呢?这就需要我们将 anon_vma 与 anon_vma_chain 之间的关系也打通。
我们知道每个匿名页对应唯一的 anon_vma 结构,但是一个匿名物理页可以映射到不同进程的虚拟内存空间中,每个进程的虚拟内存空间都是独立的,也就是说不同的进程就会有不同的 VMA。
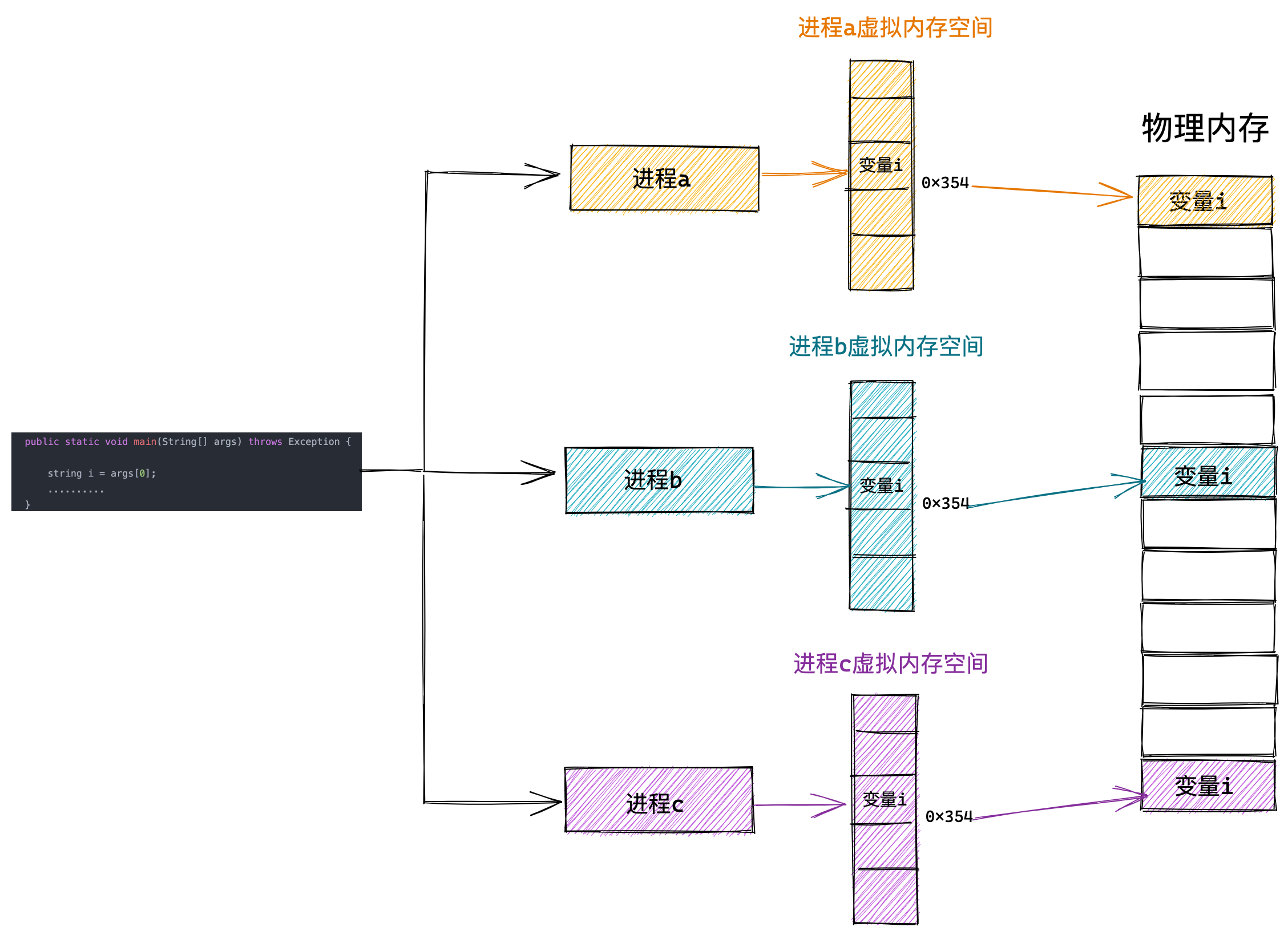
不同的 VMA 意味着同一个匿名页 anon_vma 就会对应多个 anon_vma_chain。那么如何通过一个 anon_vma 找到和他关联的所有 anon_vma_chain 呢?找到了这些 anon_vma_chain 也就意味着 struct page 找到了与它关联的所有进程虚拟内存空间 VMA。
我们看看能不能从 struct anon_vma 结构中寻找一下线索:
|
|
我们重点来看 struct anon_vma 结构中的 rb_root 字段,struct anon_vma 结构中管理了一颗红黑树,这颗红黑树上管理的全部都是与该 anon_vma 关联的 anon_vma_chain。我们可以通过 struct page 中的 mapping 指针找到 anon_vma,然后遍历 anon_vma 中的这颗红黑树 rb_root ,从而找到与其关联的所有 anon_vma_chain。
|
|
struct anon_vma_chain 结构中的 rb 字段表示其在对应 anon_vma 管理的红黑树中的节点。
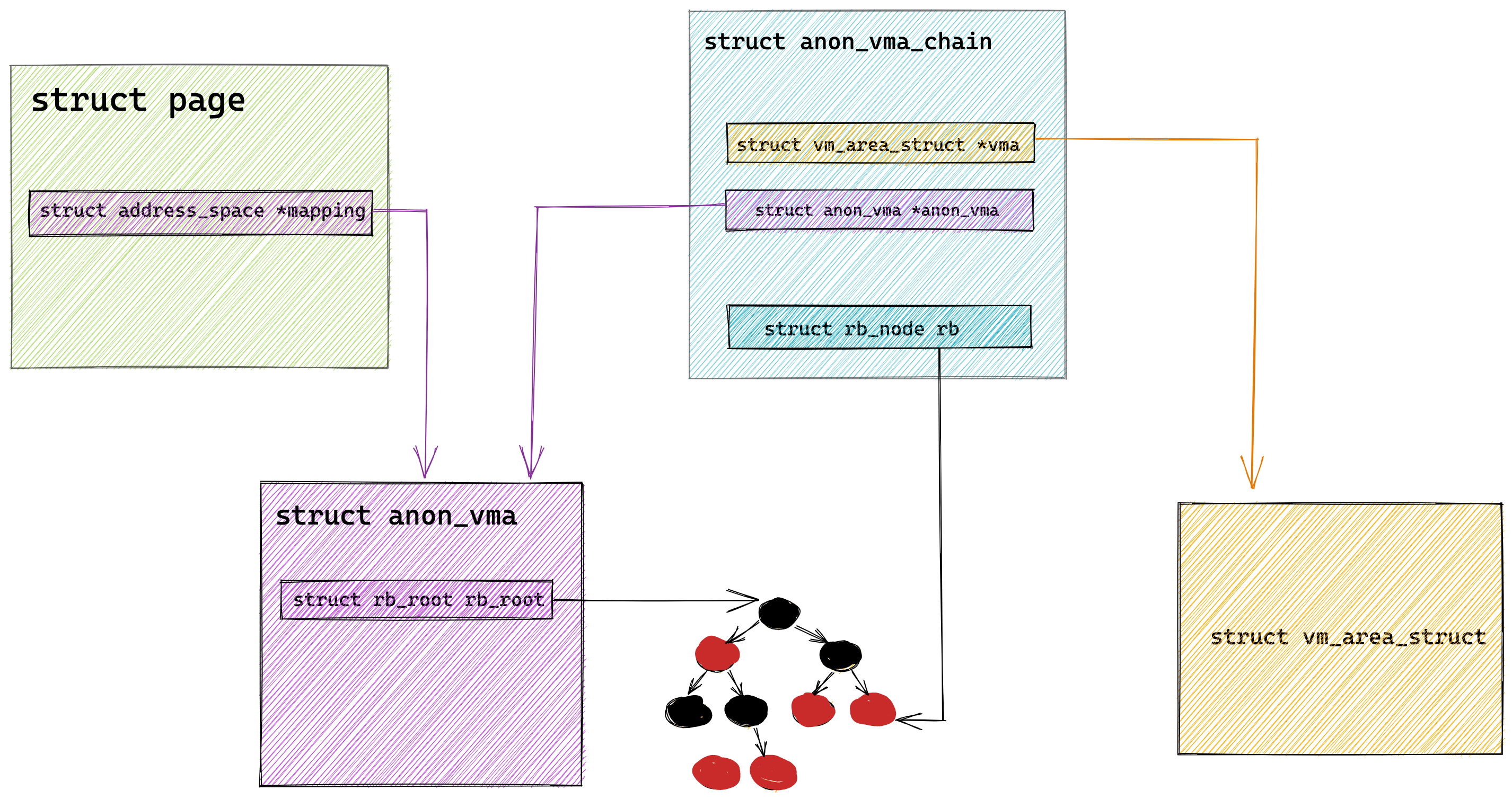
到目前为止,物理内存页 page 到与其映射的进程虚拟内存空间 VMA,这样一种一对多的映射关系现在就算建立起来了。
而 vm_area_struct 表示的只是进程虚拟内存空间中的一段虚拟内存区域,这块虚拟内存区域中可能会包含多个匿名页,所以 VMA 与物理内存页 page 也是有一对多的映射关系存在。而这个映射关系在哪里保存呢?
大家注意 struct anon_vma_chain 结构中还有一个列表结构 same_vma,从这个名字上我们很容易就能猜到这个列表 same_vma 中存储的 anon_vma_chain 对应的 VMA 全都是一样的,而列表元素 anon_vma_chain 中的 anon_vma 却是不一样的。内核用这样一个链表结构 same_vma 存储了进程相应虚拟内存区域 VMA 中所包含的所有匿名页。
struct vm_area_struct 结构中的 struct list_head anon_vma_chain 指向的也是这个列表 same_vma。
|
|
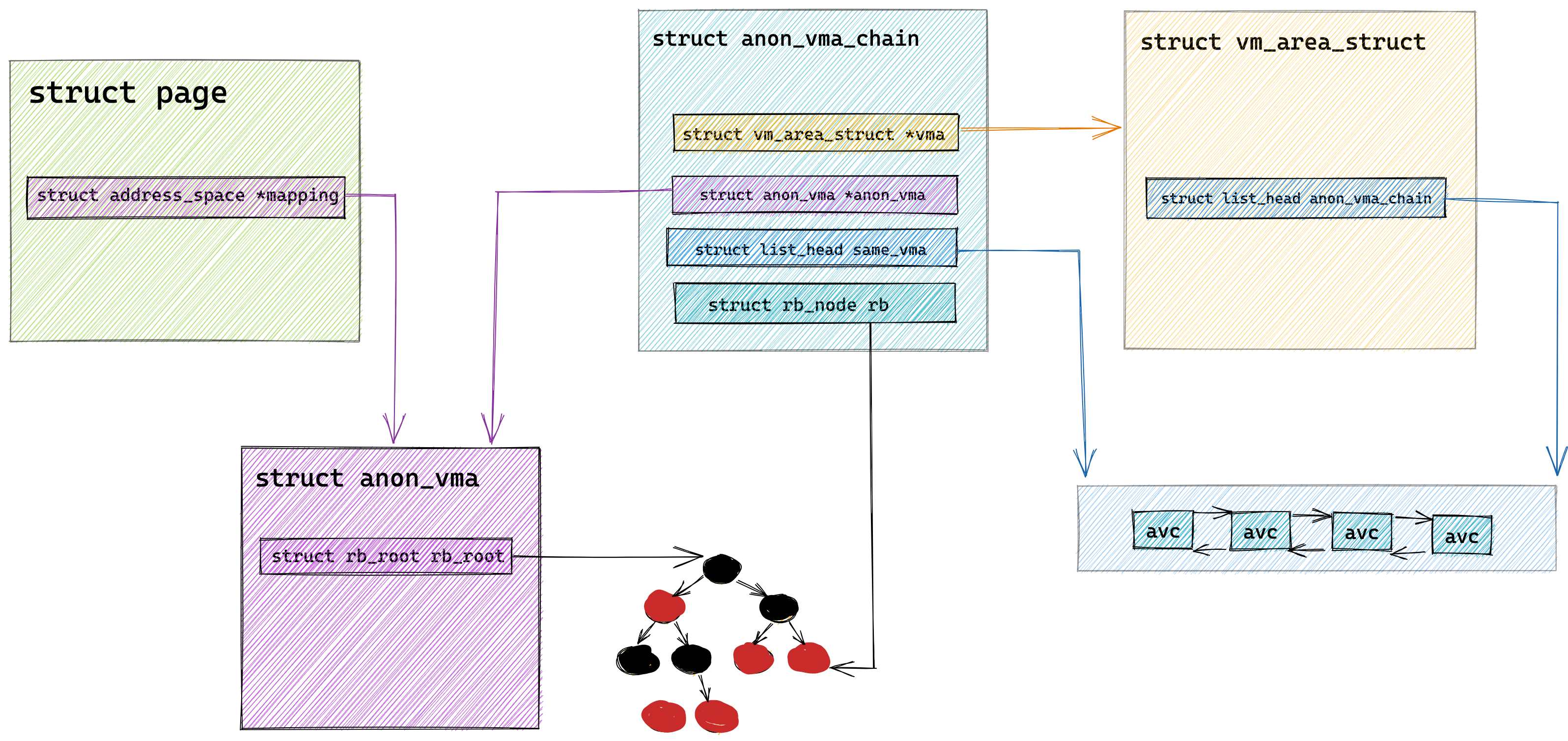
现在整个匿名页到进程虚拟内存空间的反向映射链路关系,我就为大家梳理清楚了,下面我们接着回到 do_anonymous_page 函数中,来一一验证上述映射逻辑:
|
|
在 do_anonymous_page 中首先会调用 anon_vma_prepare 方法来为匿名页创建 anon_vma 实例和 anon_vma_chain 实例,并建立它们之间的关联关系。
|
|
anon_vma_prepare 方法中调用 anon_vma_chain_link 方法来建立 anon_vma,anon_vma_chain,vm_area_struct 三者之间的关联关系:
|
|
到现在为止还缺关键的最后一步,就是打通匿名内存页 page 到 vm_area_struct 之间的关系,首先我们就需要调用 alloc_zeroed_user_highpage_movable 方法从伙伴系统中申请一个匿名页。当获取到 page 实例之后,通过 page_add_new_anon_rmap 最终建立起 page 到 vm_area_struct 的整条反向映射链路。
|
|
现在让我们再次回到本小节 《6.1 匿名页的反向映射》的开始,再来看这段话,是不是感到非常清晰了呢~~
如果当前物理内存页 struct page 是一个匿名页的话,那么 mapping 指针的最低位会被设置为
1, 指向该匿名页在进程虚拟内存空间中的匿名映射区域 struct anon_vma 结构(每个匿名页对应唯一的 anon_vma 结构),用于物理内存到虚拟内存的反向映射。
如果当前物理内存页 struct page 是一个文件页的话,那么 mapping 指针的最低位会被设置为
0,指向该内存页关联文件的 struct address_space(页高速缓存)。pgoff_t index 字段表示该内存页 page 在页高速缓存中的 index 索引,也表示该内存页中的文件数据在文件内部的偏移 offset。偏移单位为 page size。
struct page 结构中的 struct address_space *mapping 指针的最低位如何置 1 ,又如何置 0 呢?关键在下面这条语句:
|
|
anon_vma 指针加上 PAGE_MAPPING_ANON ,并转换为 address_space 指针,这样可确保 address_space 指针的低位为 1 表示匿名页。
address_space 指针在转换为 anon_vma 指针的时候可通过如下语句实现:
|
|
PAGE_MAPPING_ANON 常量定义在内核 /include/linux/page-flags.h 文件中:
|
|
而对于文件页来说,page 结构的 mapping 指针最低位本来就是 0 ,因为 address_space 类型的指针实现总是对齐至 sizeof(long),因此在 Linux 支持的所有计算机上,指向 address_space 实例的指针最低位总是为 0 。
内核可以通过这个技巧直接检查 page 结构中的 mapping 指针的最低位来判断该物理内存页到底是匿名页还是文件页。
前面说了文件页的 page 结构的 index 属性表示该内存页 page 在磁盘文件中的偏移 offset ,偏移单位为 page size 。
那匿名页的 page 结构中的 index 属性表示什么呢?我们接着来看 linear_page_index 函数:
|
|
逻辑很简单,就是表示匿名页在对应进程虚拟内存区域 VMA 中的偏移。
在本小节最后,还有一个与反向映射相关的重要属性就是 page 结构中的 _mapcount。
|
|
经过本小节详细的介绍,我想大家现在已经猜到 _mapcount 字段的含义了,我们知道一个物理内存页可以映射到多个进程的虚拟内存空间中,比如:共享内存映射,父子进程的创建等。page 与 VMA 是一对多的关系,这里的 _mapcount 就表示该物理页映射到了多少个进程的虚拟内存空间中。
内存页回收相关属性
我们接着来看 struct page 中剩下的其他属性,我们知道物理内存页在内核中分为匿名页和文件页,在《5.2 物理内存区域中的水位线》小节中,我还提到过两个重要的链表分别为:active 链表和 inactive 链表。
其中 active 链表用来存放访问非常频繁的内存页(热页), inactive 链表用来存放访问不怎么频繁的内存页(冷页),当内存紧张的时候,内核就会优先将 inactive 链表中的内存页置换出去。
内核在回收内存的时候,这两个列表中的回收优先级为:inactive 链表尾部 > inactive 链表头部 > active 链表尾部 > active 链表头部。
我们可以通过 cat /proc/zoneinfo 命令来查看不同 NUMA 节点中不同内存区域中的 active 链表和 inactive 链表中物理内存页的个数:
- nr_zone_active_anon 和 nr_zone_inactive_anon 分别是该内存区域内活跃和非活跃的匿名页数量。
- nr_zone_active_file 和 nr_zone_inactive_file 分别是该内存区域内活跃和非活跃的文件页数量。
为什么会有 active 链表和 inactive 链表?
内存回收的关键是如何实现一个高效的页面替换算法 PFRA (Page Frame Replacement Algorithm) ,提到页面替换算法大家可能立马会想到 LRU (Least-Recently-Used) 算法。LRU 算法的核心思想就是那些最近最少使用的页面,在未来的一段时间内可能也不会再次被使用,所以在内存紧张的时候,会优先将这些最近最少使用的页面置换出去。在这种情况下其实一个 active 链表就可以满足我们的需求。
但是这里会有一个严重的问题,LRU 算法更多的是在时间维度上的考量,突出最近最少使用,但是它并没有考量到使用频率的影响,假设有这样一种状况,就是一个页面被疯狂频繁的使用,毫无疑问它肯定是一个热页,但是这个页面最近的一次访问时间离现在稍微久了一点点,此时进来大量的页面,这些页面的特点是只会使用一两次,以后将再也不会用到。
在这种情况下,根据 LRU 的语义这个之前频繁地被疯狂访问的页面就会被置换出去了(本来应该将这些大量一次性访问的页面置换出去的),当这个页面在不久之后要被访问时,此时已经不在内存中了,还需要在重新置换进来,造成性能的损耗。这种现象也叫 Page Thrashing(页面颠簸)。
因此,内核为了将页面使用频率这个重要的考量因素加入进来,于是就引入了 active 链表和 inactive 链表。工作原理如下:
- 首先 inactive 链表的尾部存放的是访问频率最低并且最少访问的页面,在内存紧张的时候,这些页面被置换出去的优先级是最大的。
- 对于文件页来说,当它被第一次读取的时候,内核会将它放置在 inactive 链表的头部,如果它继续被访问,则会提升至 active 链表的尾部。如果它没有继续被访问,则会随着新文件页的进入,内核会将它慢慢的推到 inactive 链表的尾部,如果此时再次被访问则会直接被提升到 active 链表的头部。大家可以看出此时页面的使用频率这个因素已经被考量了进来。
- 对于匿名页来说,当它被第一次读取的时候,内核会直接将它放置在 active 链表的尾部,注意不是 inactive 链表的头部,这里和文件页不同。因为匿名页的换出 Swap Out 成本会更大,内核会对匿名页更加优待。当匿名页再次被访问的时候就会被被提升到 active 链表的头部。
- 当遇到内存紧张的情况需要换页时,内核会从 active 链表的尾部开始扫描,将一定量的页面降级到 inactive 链表头部,这样一来原来位于 inactive 链表尾部的页面就会被置换出去。
内核在回收内存的时候,这两个列表中的回收优先级为:inactive 链表尾部 > inactive 链表头部 > active 链表尾部 > active 链表头部。
为什么会把 active 链表和 inactive 链表分成两类,一类是匿名页,一类是文件页?
在本文 《5.2 物理内存区域中的水位线》小节中,我为大家介绍了一个叫做 swappiness 的内核参数, 我们可以通过 cat /proc/sys/vm/swappiness 命令查看,swappiness 选项的取值范围为 0 到 100,默认为 60。
swappiness 用于表示 Swap 机制的积极程度,数值越大,Swap 的积极程度,越高越倾向于回收匿名页。数值越小,Swap 的积极程度越低,越倾向于回收文件页。
因为回收匿名页和回收文件页的代价是不一样的,回收匿名页代价会更高一点,所以引入 swappiness 来控制内核回收的倾向。
注意: swappiness 只是表示 Swap 积极的程度,当内存非常紧张的时候,即使将 swappiness 设置为 0 ,也还是会发生 Swap 的。
假设我们现在只有 active 链表和 inactive 链表,不对这两个链表进行匿名页和文件页的归类,在需要页面置换的时候,内核会先从 active 链表尾部开始扫描,当 swappiness 被设置为 0 时,内核只会置换文件页,不会置换匿名页。
由于 active 链表和 inactive 链表没有进行物理页面类型的归类,所以链表中既会有匿名页也会有文件页,如果链表中有大量的匿名页的话,内核就会不断的跳过这些匿名页去寻找文件页,并将文件页替换出去,这样从性能上来说肯定是低效的。
因此内核将 active 链表和 inactive 链表按照匿名页和文件页进行了归类,当 swappiness 被设置为 0 时,内核只需要去 nr_zone_active_file 和 nr_zone_inactive_file 链表中扫描即可,提升了性能。
其实除了以上我介绍的四种 LRU 链表(匿名页的 active 链表,inactive 链表和文件页的active 链表, inactive 链表)之外,内核还有一种链表,比如进程可以通过 mlock() 等系统调用把内存页锁定在内存里,保证该内存页无论如何不会被置换出去,比如出于安全或者性能的考虑,页面中可能会包含一些敏感的信息不想被 swap 到磁盘上导致泄密,或者一些频繁访问的内存页必须一直贮存在内存中。
当这些被锁定在内存中的页面很多时,内核在扫描 active 链表的时候也不得不跳过这些页面,所以内核又将这些被锁定的页面单独拎出来放在一个独立的链表中。
现在我为大家介绍五种用于存放 page 的链表,内核会根据不同的情况将一个物理页放置在这五种链表其中一个上。那么对于物理页的 struct page 结构中就需要有一个属性用来标识该物理页究竟被内核放置在哪个链表上。
|
|
struct list_head lru 属性就是用来指向物理页被放置在了哪个链表上。
atomic_t _refcount 属性用来记录内核中引用该物理页的次数,表示该物理页的活跃程度。
物理内存页属性和状态的标志位 flag
|
|
在本文 《2.3 SPARSEMEM 稀疏内存模型》小节中,我们提到,内核为了能够更灵活地管理粒度更小的连续物理内存,于是就此引入了 SPARSEMEM 稀疏内存模型。
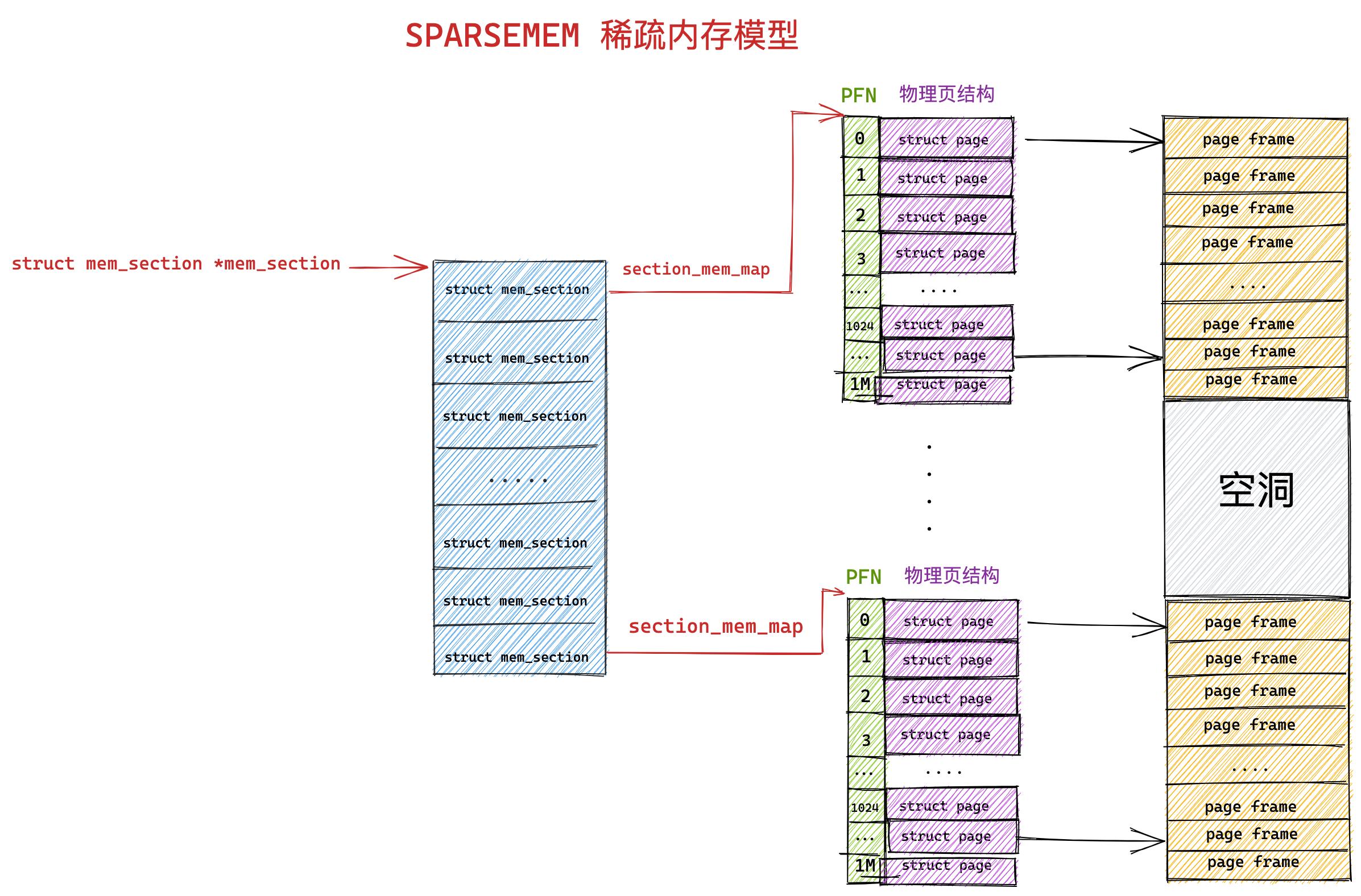
SPARSEMEM 稀疏内存模型的核心思想就是提供对粒度更小的连续内存块进行精细的管理,用于管理连续内存块的单元被称作 section 。内核中用于描述 section 的数据结构是 struct mem_section。
由于 section 被用作管理小粒度的连续内存块,这些小的连续物理内存在 section 中也是通过数组的方式被组织管理(图中 struct page 类型的数组)。
每个 struct mem_section 结构体中有一个 section_mem_map 指针用于指向连续内存的 page 数组。而所有的 mem_section 也会被存放在一个全局的数组 mem_section 中。
那么给定一个具体的 struct page,在稀疏内存模型中内核如何定位到这个物理内存页到底属于哪个 mem_section 呢 ?这是第一个问题~~
我在《5. 内核如何管理 NUMA 节点中的物理内存区域》小节中讲到了内存的架构,在 NUMA 架构下,物理内存被划分成了一个一个的内存节点(NUMA 节点),在每个 NUMA 节点内部又将其所管理的物理内存按照功能不同划分成了不同的内存区域 zone,每个内存区域管理一片用于特定具体功能的物理内存 page。
物理内存在内核中管理的层级关系为:None -> Zone -> page
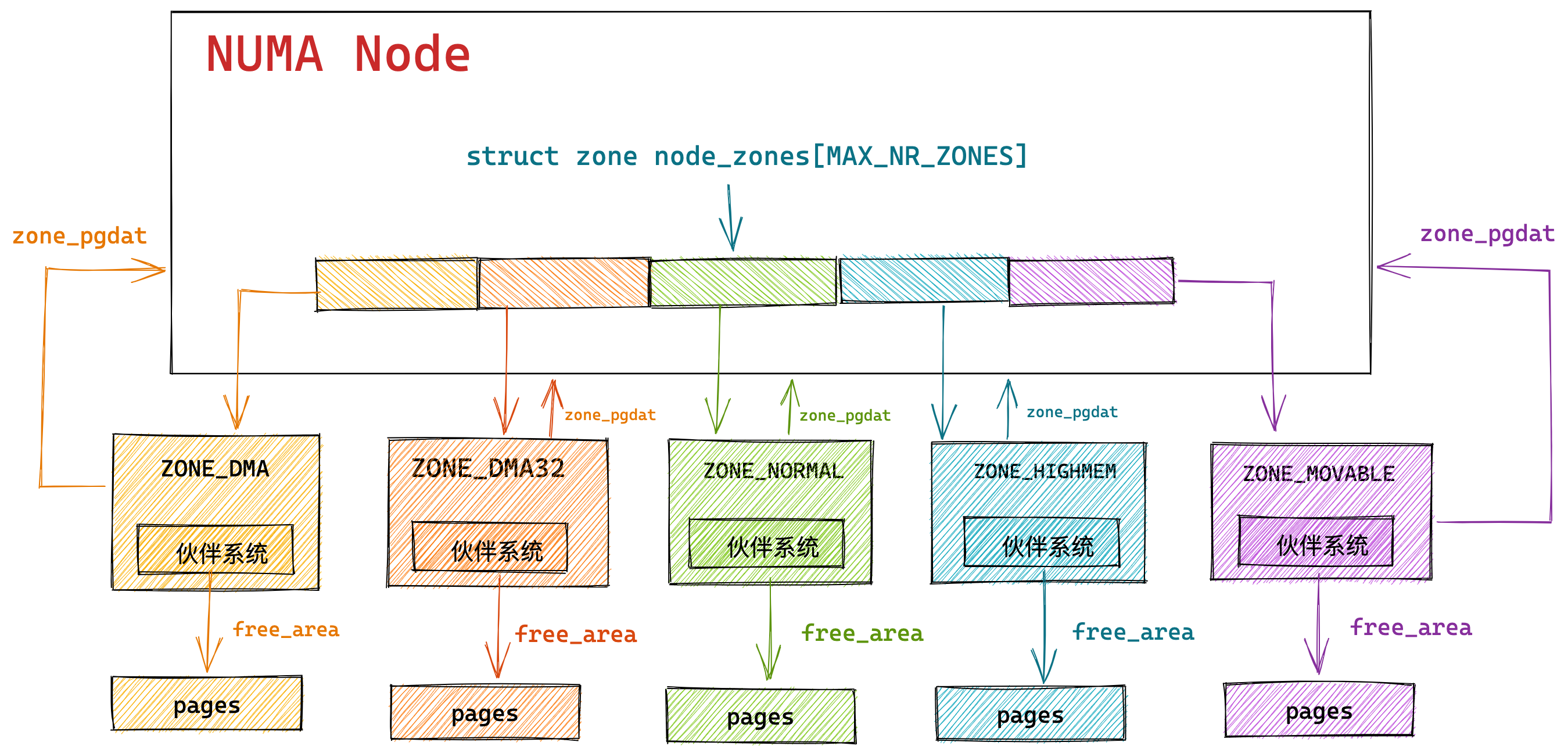
那么在 NUMA 架构下,给定一个具体的 struct page,内核又该如何确定该物理内存页究竟属于哪个 NUMA 节点,属于哪块内存区域 zone 呢? 这是第二个问题。
关于以上我提出的两个问题所需要的定位信息全部存储在 struct page 结构中的 flags 字段中。前边我们提到,struct page 是 Linux 世界里最繁华的地段,这里的地价非常昂贵,所以 page 结构中这些字段里的每一个比特内核都会物尽其用。
|
|
因此这个 unsigned long 类型的 flags 字段中不仅包含上面提到的定位信息还会包括物理内存页的一些属性和标志位。flags 字段的高 8 位用来表示 struct page 的定位信息,剩余低位表示特定的标志位。
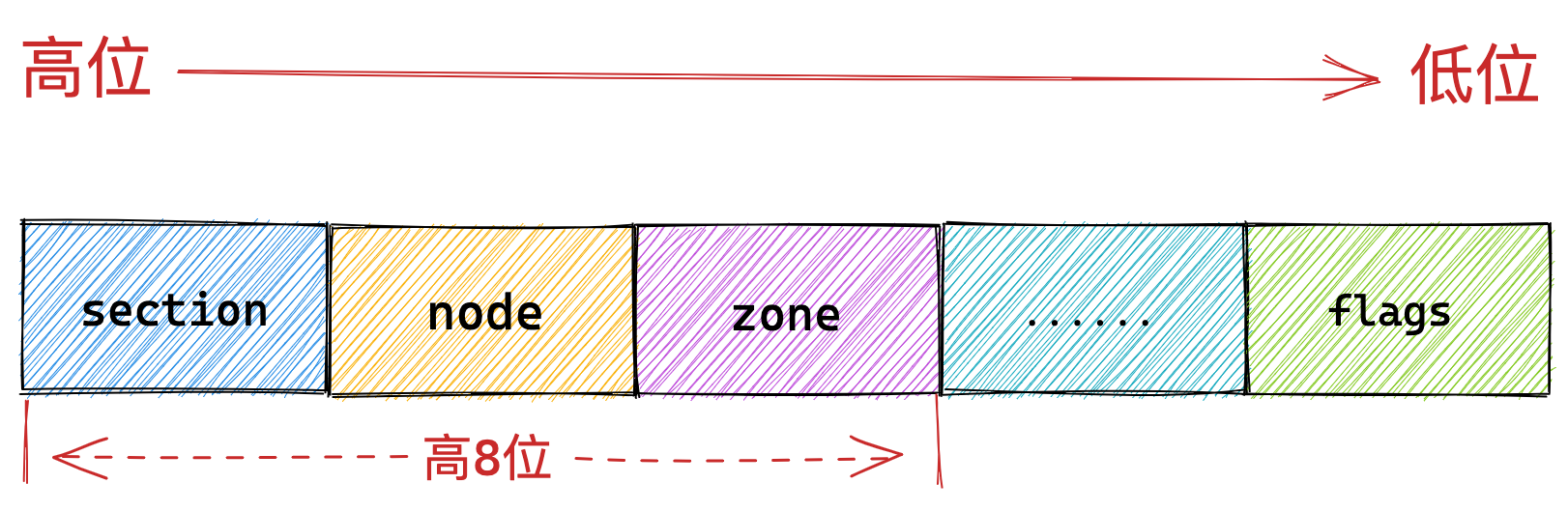
struct page 与其所属上层结构转换的相应函数定义在 /include/linux/mm.h 文件中:
|
|
在我们介绍完了 flags 字段中高位存储的位置定位信息之后,接下来就该来介绍下在低位比特中表示的物理内存页的那些标志位~~
物理内存页的这些标志位定义在内核 /include/linux/page-flags.h文件中:
|
|
- PG_locked 表示该物理页面已经被锁定,如果该标志位置位,说明有使用者正在操作该 page , 则内核的其他部分不允许访问该页, 这可以防止内存管理出现竞态条件,例如:在从硬盘读取数据到 page 时。
- PG_mlocked 表示该物理内存页被进程通过 mlock 系统调用锁定常驻在内存中,不会被置换出去。
- PG_referenced 表示该物理页面刚刚被访问过。
- PG_active 表示该物理页位于 active list 链表中。PG_referenced 和 PG_active 共同控制了系统使用该内存页的活跃程度,在内存回收的时候这两个信息非常重要。
- PG_uptodate 表示该物理页的数据已经从块设备中读取到内存中,并且期间没有出错。
- PG_readahead 当进程在顺序访问文件的时候,内核会预读若干相邻的文件页数据到 page 中,物理页 page 结构设置了该标志位,表示它是一个正在被内核预读的页。相关详细内容可回看我之前的这篇文章 《从 Linux 内核角度探秘 JDK NIO 文件读写本质》(opens new window)
- PG_dirty 物理内存页的脏页标识,表示该物理内存页中的数据已经被进程修改,但还没有同步会磁盘中。我在 《从 Linux 内核角度探秘 JDK NIO 文件读写本质》 (opens new window)一文中也详细介绍过。
- PG_lru 表示该物理内存页现在被放置在哪个 lru 链表上,比如:是在 active list 链表中 ? 还是在 inactive list 链表中 ?
- PG_highmem 表示该物理内存页是在高端内存中。
- PG_writeback 表示该物理内存页正在被内核的 pdflush 线程回写到磁盘中。详情可回看文章《从 Linux 内核角度探秘 JDK NIO 文件读写本质》 (opens new window)。
- PG_slab 表示该物理内存页属于 slab 分配器所管理的一部分。
- PG_swapcache 表示该物理内存页处于 swap cache 中。 struct page 中的 private 指针这时指向 swap_entry_t 。
- PG_reclaim 表示该物理内存页已经被内核选中即将要进行回收。
- PG_buddy 表示该物理内存页是空闲的并且被伙伴系统所管理。
- PG_compound 表示物理内存页属于复合页的其中一部分。
- PG_private 标志被置位的时候表示该 struct page 结构中的 private 指针指向了具体的对象。不同场景指向的对象不同。
除此之外内核还定义了一些标准宏,用来检查某个物理内存页 page 是否设置了特定的标志位,以及对这些标志位的操作,这些宏在内核中的实现都是原子的,命名格式如下:
- PageXXX(page):检查 page 是否设置了 PG_XXX 标志位
- SetPageXXX(page):设置 page 的 PG_XXX 标志位
- ClearPageXXX(page):清除 page 的 PG_XXX 标志位
- TestSetPageXXX(page):设置 page 的 PG_XXX 标志位,并返回原值
另外在很多情况下,内核通常需要等待物理页 page 的某个状态改变,才能继续恢复工作,内核提供了如下两个辅助函数,来实现在特定状态的阻塞等待:
|
|
当物理页面在锁定的状态下,进程调用了 wait_on_page_locked 函数,那么进程就会阻塞等待知道页面解锁。
当物理页面正在被内核回写到磁盘的过程中,进程调用了 wait_on_page_writeback 函数就会进入阻塞状态直到脏页数据被回写到磁盘之后被唤醒。
复合页 compound_page 相关属性
我们都知道 Linux 管理内存的最小单位是 page,每个 page 描述 4K 大小的物理内存,但在一些对于内存敏感的使用场景中,用户往往期望使用一些巨型大页。
巨型大页就是通过两个或者多个物理上连续的内存页 page 组装成的一个比普通内存页 page 更大的页,
因为这些巨型页要比普通的 4K 内存页要大很多,所以遇到缺页中断的情况就会相对减少,由于减少了缺页中断所以性能会更高。
另外,由于巨型页比普通页要大,所以巨型页需要的页表项要比普通页要少,页表项里保存了虚拟内存地址与物理内存地址的映射关系,当 CPU 访问内存的时候需要频繁通过 MMU 访问页表项获取物理内存地址,由于要频繁访问,所以页表项一般会缓存在 TLB 中,因为巨型页需要的页表项较少,所以节约了 TLB 的空间同时降低了 TLB 缓存 MISS 的概率,从而加速了内存访问。
还有一个使用巨型页受益场景就是,当一个内存占用很大的进程(比如 Redis)通过 fork 系统调用创建子进程的时候,会拷贝父进程的相关资源,其中就包括父进程的页表,由于巨型页使用的页表项少,所以拷贝的时候性能会提升不少。
以上就是巨型页存在的原因以及使用的场景,但是在 Linux 内存管理架构中都是统一通过 struct page 来管理内存,而巨型大页却是通过两个或者多个物理上连续的内存页 page 组装成的一个比普通内存页 page 更大的页,那么巨型页的管理与普通页的管理如何统一呢?
这就引出了本小节的主题—–复合页 compound_page,下面我们就来看下 Linux 如果通过统一的 struct page 结构来描述这些巨型页(compound_page):
虽然巨型页(compound_page)是由多个物理上连续的普通 page 组成的,但是在内核的视角里它还是被当做一个特殊内存页来看待。
下图所示,是由 4 个连续的普通内存页 page 组成的一个 compound_page:
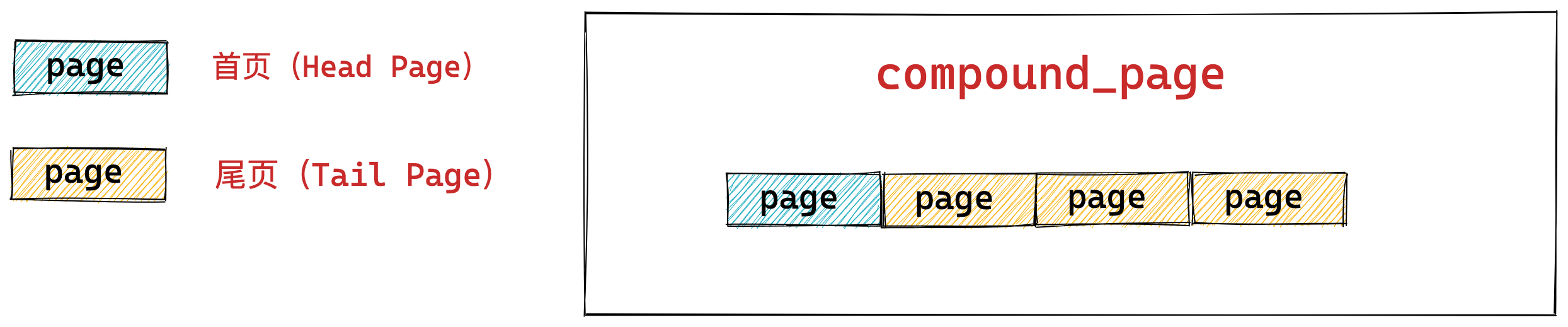
组成复合页的第一个 page 我们称之为首页(Head Page),其余的均称之为尾页(Tail Page)。
我们来看一下 struct page 中关于描述 compound_page 的相关字段:
|
|
首页对应的 struct page 结构里的 flags 会被设置为 PG_head,表示这是复合页的第一页。
另外首页中还保存关于复合页的一些额外信息,比如用于释放复合页的析构函数会保存在首页 struct page 结构里的 compound_dtor 字段中,复合页的分配阶 order 会保存在首页中的 compound_order 中,以及用于指示复合页的引用计数 compound_pincount,以及复合页的反向映射个数(该复合页被多少个进程的页表所映射)compound_mapcount 均在首页中保存。
复合页中的所有尾页都会通过其对应的 struct page 结构中的 compound_head 指向首页,这样通过首页和尾页就组装成了一个完整的复合页 compound_page 。
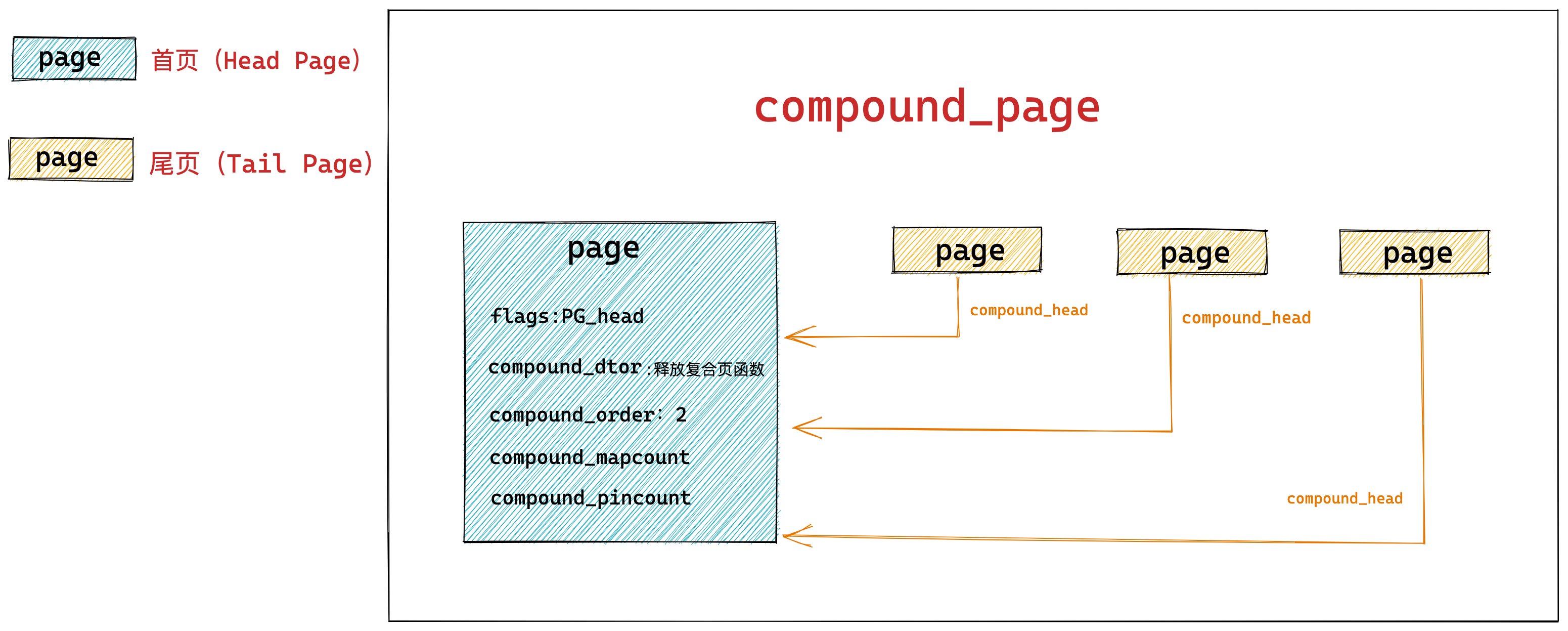
Slab 对象池相关属性
本小节只是对 slab 的一个简单介绍,大家有个大概的印象就可以了,后面我会有一篇专门的文章为大家详细介绍 slab 的相关实现细节,到时候还会在重新详细介绍 struct page 中的相关属性。
内核中对内存页的分配使用有两种方式,一种是一页一页的分配使用,这种以页为单位的分配方式内核会向相应内存区域 zone 里的伙伴系统申请以及释放。
另一种方式就是只分配小块的内存,不需要一下分配一页的内存,比如前边章节中提到的 struct page ,anon_vma_chain ,anon_vma ,vm_area_struct 结构实例的分配,这些结构通常就是几十个字节大小,并不需要按页来分配。
为了满足类似这种小内存分配的需要,Linux 内核使用 slab allocator 分配器来分配,slab 就好比一个对象池,内核中的数据结构对象都对应于一个 slab 对象池,用于分配这些固定类型对象所需要的内存。
它的基本原理是从伙伴系统中申请一整页内存,然后划分成多个大小相等的小块内存被 slab 所管理。这样一来 slab 就和物理内存页 page 发生了关联,由于 slab 管理的单元是物理内存页 page 内进一步划分出来的小块内存,所以当 page 被分配给相应 slab 结构之后,struct page 里也会存放 slab 相关的一些管理数据。
|
|
- struct list_head slab_list :slab 的管理结构中有众多用于管理 page 的链表,比如:完全空闲的 page 链表,完全分配的 page 链表,部分分配的 page 链表,slab_list 用于指定当前 page 位于 slab 中的哪个具体链表上。
- struct page *next : 当 page 位于 slab 结构中的某个管理链表上时,next 指针用于指向链表中的下一个 page。
- int pages : 表示 slab 中总共拥有的 page 个数。
- int pobjects : 表示 slab 中拥有的特定类型的对象个数。
- struct kmem_cache *slab_cache : 用于指向当前 page 所属的 slab 管理结构,通过 slab_cache 将 page 和 slab 关联起来。
- void *freelist : 指向 page 中的第一个未分配出去的空闲对象,前面介绍过,slab 向伙伴系统申请一个或者多个 page,并将一整页 page 划分出多个大小相等的内存块,用于存储特定类型的对象。
- void *s_mem : 指向 page 中的第一个对象。
- unsigned inuse : 表示 slab 中已经被分配出去的对象个数,当该值为 0 时,表示 slab 中所管理的对象全都是空闲的,当所有的空闲对象达到一定数目,该 slab 就会被伙伴系统回收掉。
- unsigned objects : slab 中所有的对象个数。
- unsigned frozen : 当前内存页 page 被 slab 放置在 CPU 本地缓存列表中,frozen = 1,否则 frozen = 0 。
总结
到这里,关于 Linux 物理内存管理的相关内容我就为大家介绍完了,本文的内容比较多,尤其是物理内存页反向映射相关的内容比较复杂,涉及到的关联关系比较多,现在我在带大家总结一下本文的主要内容,方便大家复习回顾:
在本文的开始,我首先从 CPU 角度为大家介绍了三种物理内存模型:FLATMEM 平坦内存模型,DISCONTIGMEM 非连续内存模型,SPARSEMEM 稀疏内存模型。
随后我又接着介绍了两种物理内存架构:一致性内存访问 UMA 架构,非一致性内存访问 NUMA 架构。
在这个基础之上,又按照内核对物理内存的组织管理层次,分别介绍了 Node 节点,物理内存区域 zone 等相关内核结构。它们的层次如下图所示:
在把握了物理内存的总体架构之后,又引出了众多细节性的内容,比如:物理内存区域的管理与划分,物理内存区域中的预留内存,物理内存区域中的水位线及其计算方式,物理内存区域中的冷热页。
最后,我详细介绍了内核如何通过 struct page 结构来描述物理内存页,其中匿名页反向映射的内容比较复杂,需要大家多多梳理回顾一下。
进程管理
进程、线程基础知识
先来看看一则小故事
我们写好的一行行代码,为了让其工作起来,我们还得把它送进城(进程)里,那既然进了城里,那肯定不能胡作非为了。
城里人有城里人的规矩,城中有个专门管辖你们的城管(操作系统),人家让你休息就休息,让你工作就工作,毕竟摊位不多,每个人都要占这个摊位来工作,城里要工作的人多着去了。
所以城管为了公平起见,它使用一种策略(调度)方式,给每个人一个固定的工作时间(时间片),时间到了就会通知你去休息而换另外一个人上场工作。
另外,在休息时候你也不能偷懒,要记住工作到哪了,不然下次到你工作了,你忘记工作到哪了,那还怎么继续?
有的人,可能还进入了县城(线程)工作,这里相对轻松一些,在休息的时候,要记住的东西相对较少,而且还能共享城里的资源。
“哎哟,难道本文内容是进程和线程?”
可以,聪明的你猜出来了,也不枉费我瞎编乱造的故事了。
进程和线程对于写代码的我们,真的天天见、日日见了,但见的多不代表你就熟悉它们,比如简单问你一句,你知道它们的工作原理和区别吗?
不知道没关系,今天就要跟大家讨论操作系统的进程和线程。
TIP
先强调一下,我们本篇讲的主要都是操作系统理论知识,偏大学计算机专业课上的那种,并不是讲解 Linux 或 Windows 操作系统的实现方式,所以大家要区别一下。
想让了解 Linux 或 Windows 操作系统的具体实现,得去看这些操作系统的实现原理或者源码书籍。
进程
我们编写的代码只是一个存储在硬盘的静态文件,通过编译后就会生成二进制可执行文件,当我们运行这个可执行文件后,它会被装载到内存中,接着 CPU 会执行程序中的每一条指令,那么这个运行中的程序,就被称为「进程」(Process)。
现在我们考虑有一个会读取硬盘文件数据的程序被执行了,那么当运行到读取文件的指令时,就会去从硬盘读取数据,但是硬盘的读写速度是非常慢的,那么在这个时候,如果 CPU 傻傻的等硬盘返回数据的话,那 CPU 的利用率是非常低的。
做个类比,你去煮开水时,你会傻傻的等水壶烧开吗?很明显,小孩也不会傻等。我们可以在水壶烧开之前去做其他事情。当水壶烧开了,我们自然就会听到“嘀嘀嘀”的声音,于是再把烧开的水倒入到水杯里就好了。
所以,当进程要从硬盘读取数据时,CPU 不需要阻塞等待数据的返回,而是去执行另外的进程。当硬盘数据返回时,CPU 会收到个中断,于是 CPU 再继续运行这个进程。
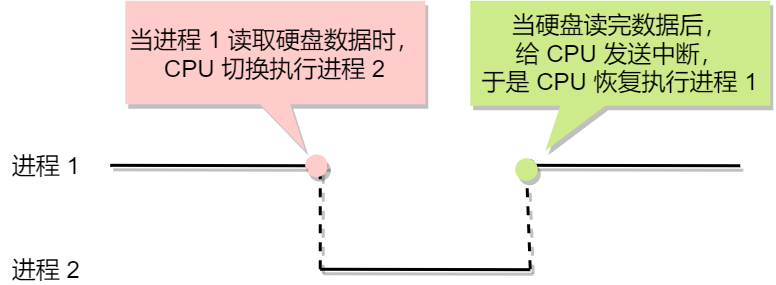
这种多个程序、交替执行的思想,就有 CPU 管理多个进程的初步想法。
对于一个支持多进程的系统,CPU 会从一个进程快速切换至另一个进程,其间每个进程各运行几十或几百个毫秒。
虽然单核的 CPU 在某一个瞬间,只能运行一个进程。但在 1 秒钟期间,它可能会运行多个进程,这样就产生并行的错觉,实际上这是并发。
并发和并行有什么区别?
一图胜千言。
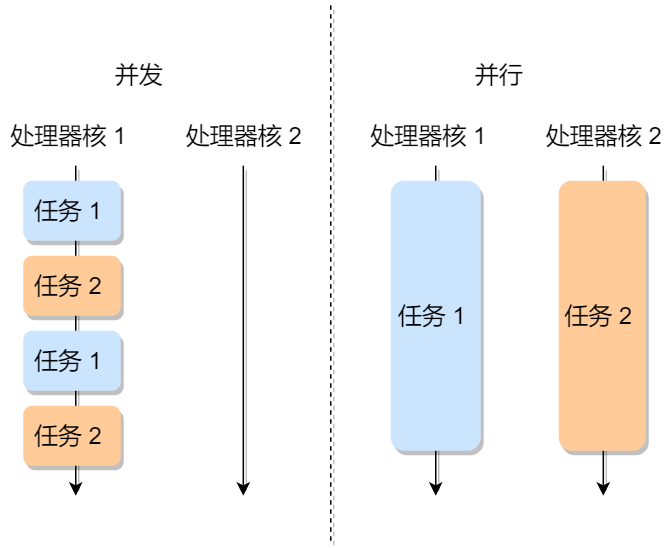
进程与程序的关系的类比
到了晚饭时间,一对小情侣肚子都咕咕叫了,于是男生见机行事,就想给女生做晚饭,所以他就在网上找了辣子鸡的菜谱,接着买了一些鸡肉、辣椒、香料等材料,然后边看边学边做这道菜。
突然,女生说她想喝可乐,那么男生只好把做菜的事情暂停一下,并在手机菜谱标记做到哪一个步骤,把状态信息记录了下来。
然后男生听从女生的指令,跑去下楼买了一瓶冰可乐后,又回到厨房继续做菜。
这体现了,CPU 可以从一个进程(做菜)切换到另外一个进程(买可乐),在切换前必须要记录当前进程中运行的状态信息,以备下次切换回来的时候可以恢复执行。
所以,可以发现进程有着「运行 - 暂停 - 运行」的活动规律。
进程的状态
在上面,我们知道了进程有着「运行 - 暂停 - 运行」的活动规律。一般说来,一个进程并不是自始至终连续不停地运行的,它与并发执行中的其他进程的执行是相互制约的。
它有时处于运行状态,有时又由于某种原因而暂停运行处于等待状态,当使它暂停的原因消失后,它又进入准备运行状态。
所以,在一个进程的活动期间至少具备三种基本状态,即运行状态、就绪状态、阻塞状态。
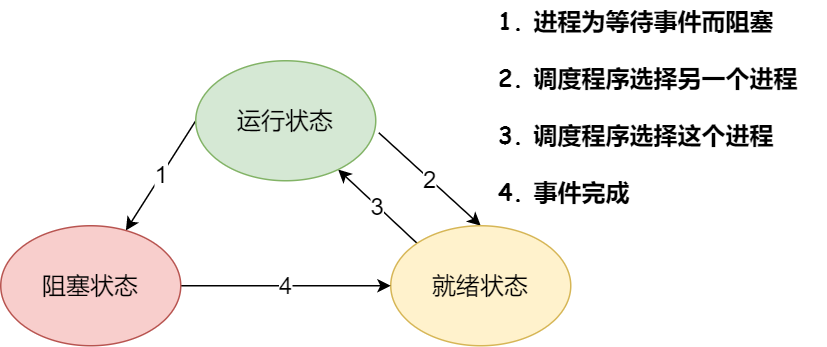
上图中各个状态的意义:
- 运行状态(Running):该时刻进程占用 CPU;
- 就绪状态(Ready):可运行,由于其他进程处于运行状态而暂时停止运行;
- 阻塞状态(Blocked):该进程正在等待某一事件发生(如等待输入/输出操作的完成)而暂时停止运行,这时,即使给它CPU控制权,它也无法运行;
当然,进程还有另外两个基本状态:
- 创建状态(new):进程正在被创建时的状态;
- 结束状态(Exit):进程正在从系统中消失时的状态;
于是,一个完整的进程状态的变迁如下图:
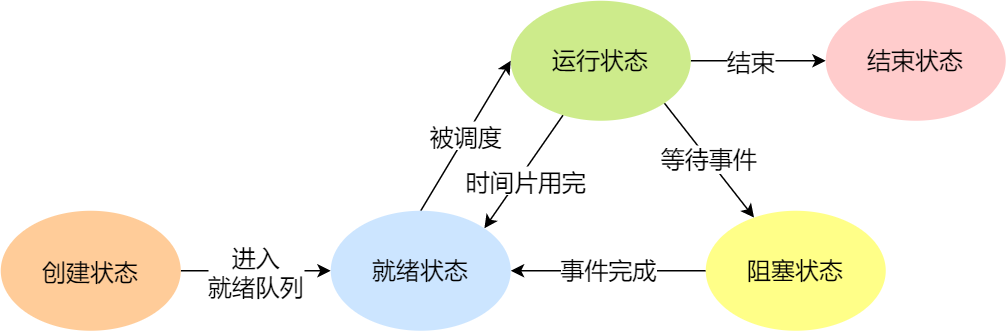
再来详细说明一下进程的状态变迁:
- NULL -> 创建状态:一个新进程被创建时的第一个状态;
- 创建状态 -> 就绪状态:当进程被创建完成并初始化后,一切就绪准备运行时,变为就绪状态,这个过程是很快的;
- 就绪态 -> 运行状态:处于就绪状态的进程被操作系统的进程调度器选中后,就分配给 CPU 正式运行该进程;
- 运行状态 -> 结束状态:当进程已经运行完成或出错时,会被操作系统作结束状态处理;
- 运行状态 -> 就绪状态:处于运行状态的进程在运行过程中,由于分配给它的运行时间片用完,操作系统会把该进程变为就绪态,接着从就绪态选中另外一个进程运行;
- 运行状态 -> 阻塞状态:当进程请求某个事件且必须等待时,例如请求 I/O 事件;
- 阻塞状态 -> 就绪状态:当进程要等待的事件完成时,它从阻塞状态变到就绪状态;
如果有大量处于阻塞状态的进程,进程可能会占用着物理内存空间,显然不是我们所希望的,毕竟物理内存空间是有限的,被阻塞状态的进程占用着物理内存就一种浪费物理内存的行为。
所以,在虚拟内存管理的操作系统中,通常会把阻塞状态的进程的物理内存空间换出到硬盘,等需要再次运行的时候,再从硬盘换入到物理内存。
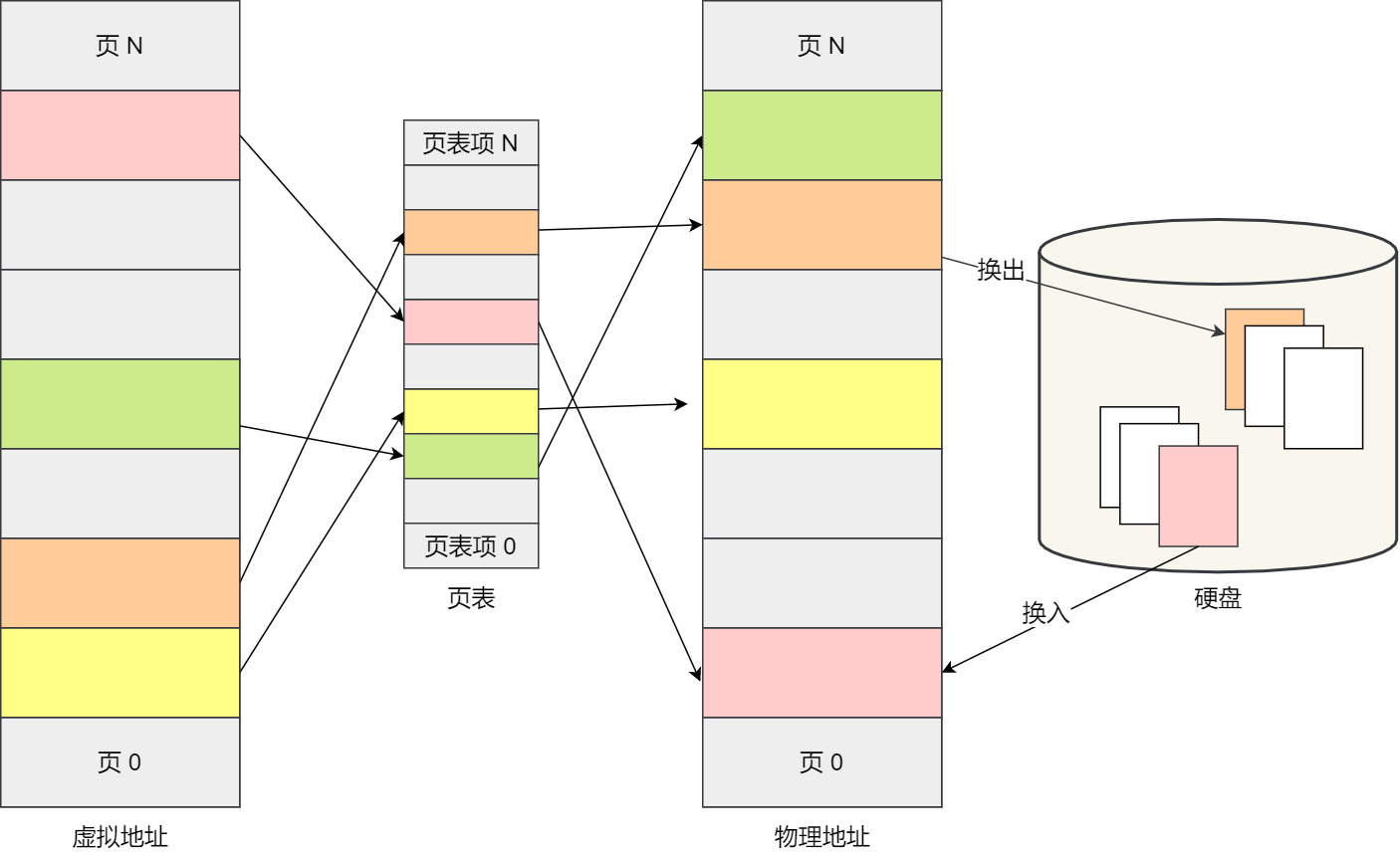
那么,就需要一个新的状态,来描述进程没有占用实际的物理内存空间的情况,这个状态就是挂起状态。这跟阻塞状态是不一样,阻塞状态是等待某个事件的返回。
另外,挂起状态可以分为两种:
- 阻塞挂起状态:进程在外存(硬盘)并等待某个事件的出现;
- 就绪挂起状态:进程在外存(硬盘),但只要进入内存,即刻立刻运行;
这两种挂起状态加上前面的五种状态,就变成了七种状态变迁(留给我的颜色不多了),见如下图:
导致进程挂起的原因不只是因为进程所使用的内存空间不在物理内存,还包括如下情况:
- 通过 sleep 让进程间歇性挂起,其工作原理是设置一个定时器,到期后唤醒进程。
- 用户希望挂起一个程序的执行,比如在 Linux 中用
Ctrl+Z挂起进程;
进程的控制结构
在操作系统中,是用进程控制块(process control block,PCB)数据结构来描述进程的。
那 PCB 是什么呢?
PCB 是进程存在的唯一标识,这意味着一个进程的存在,必然会有一个 PCB,如果进程消失了,那么 PCB 也会随之消失。
PCB 具体包含什么信息呢?
进程描述信息:
- 进程标识符:标识各个进程,每个进程都有一个并且唯一的标识符;
- 用户标识符:进程归属的用户,用户标识符主要为共享和保护服务;
进程控制和管理信息:
- 进程当前状态,如 new、ready、running、waiting 或 blocked 等;
- 进程优先级:进程抢占 CPU 时的优先级;
资源分配清单:
- 有关内存地址空间或虚拟地址空间的信息,所打开文件的列表和所使用的 I/O 设备信息。
CPU 相关信息:
- CPU 中各个寄存器的值,当进程被切换时,CPU 的状态信息都会被保存在相应的 PCB 中,以便进程重新执行时,能从断点处继续执行。
可见,PCB 包含信息还是比较多的。
每个 PCB 是如何组织的呢?
通常是通过链表的方式进行组织,把具有相同状态的进程链在一起,组成各种队列。比如:
- 将所有处于就绪状态的进程链在一起,称为就绪队列;
- 把所有因等待某事件而处于等待状态的进程链在一起就组成各种阻塞队列;
- 另外,对于运行队列在单核 CPU 系统中则只有一个运行指针了,因为单核 CPU 在某个时间,只能运行一个程序。
那么,就绪队列和阻塞队列链表的组织形式如下图:
除了链接的组织方式,还有索引方式,它的工作原理:将同一状态的进程组织在一个索引表中,索引表项指向相应的 PCB,不同状态对应不同的索引表。
一般会选择链表,因为可能面临进程创建,销毁等调度导致进程状态发生变化,所以链表能够更加灵活的插入和删除。
进程的控制
我们熟知了进程的状态变迁和进程的数据结构 PCB 后,再来看看进程的创建、终止、阻塞、唤醒的过程,这些过程也就是进程的控制。
01 创建进程
操作系统允许一个进程创建另一个进程,而且允许子进程继承父进程所拥有的资源。
创建进程的过程如下:
- 申请一个空白的 PCB,并向 PCB 中填写一些控制和管理进程的信息,比如进程的唯一标识等;
- 为该进程分配运行时所必需的资源,比如内存资源;
- 将 PCB 插入到就绪队列,等待被调度运行;
02 终止进程
进程可以有 3 种终止方式:正常结束、异常结束以及外界干预(信号 kill 掉)。
当子进程被终止时,其在父进程处继承的资源应当还给父进程。而当父进程被终止时,该父进程的子进程就变为孤儿进程,会被 1 号进程收养,并由 1 号进程对它们完成状态收集工作。
终止进程的过程如下:
- 查找需要终止的进程的 PCB;
- 如果处于执行状态,则立即终止该进程的执行,然后将 CPU 资源分配给其他进程;
- 如果其还有子进程,则应将该进程的子进程交给 1 号进程接管;
- 将该进程所拥有的全部资源都归还给操作系统;
- 将其从 PCB 所在队列中删除;
03 阻塞进程
当进程需要等待某一事件完成时,它可以调用阻塞语句把自己阻塞等待。而一旦被阻塞等待,它只能由另一个进程唤醒。
阻塞进程的过程如下:
- 找到将要被阻塞进程标识号对应的 PCB;
- 如果该进程为运行状态,则保护其现场,将其状态转为阻塞状态,停止运行;
- 将该 PCB 插入到阻塞队列中去;
04 唤醒进程
进程由「运行」转变为「阻塞」状态是由于进程必须等待某一事件的完成,所以处于阻塞状态的进程是绝对不可能叫醒自己的。
如果某进程正在等待 I/O 事件,需由别的进程发消息给它,则只有当该进程所期待的事件出现时,才由发现者进程用唤醒语句叫醒它。
唤醒进程的过程如下:
- 在该事件的阻塞队列中找到相应进程的 PCB;
- 将其从阻塞队列中移出,并置其状态为就绪状态;
- 把该 PCB 插入到就绪队列中,等待调度程序调度;
进程的阻塞和唤醒是一对功能相反的语句,如果某个进程调用了阻塞语句,则必有一个与之对应的唤醒语句。
进程的上下文切换
各个进程之间是共享 CPU 资源的,在不同的时候进程之间需要切换,让不同的进程可以在 CPU 执行,那么这个一个进程切换到另一个进程运行,称为进程的上下文切换。
在详细说进程上下文切换前,我们先来看看 CPU 上下文切换
大多数操作系统都是多任务,通常支持大于 CPU 数量的任务同时运行。实际上,这些任务并不是同时运行的,只是因为系统在很短的时间内,让各个任务分别在 CPU 运行,于是就造成同时运行的错觉。
任务是交给 CPU 运行的,那么在每个任务运行前,CPU 需要知道任务从哪里加载,又从哪里开始运行。
所以,操作系统需要事先帮 CPU 设置好 CPU 寄存器和程序计数器。
CPU 寄存器是 CPU 内部一个容量小,但是速度极快的内存(缓存)。我举个例子,寄存器像是你的口袋,内存像你的书包,硬盘则是你家里的柜子,如果你的东西存放到口袋,那肯定是比你从书包或家里柜子取出来要快的多。
再来,程序计数器则是用来存储 CPU 正在执行的指令位置、或者即将执行的下一条指令位置。
所以说,CPU 寄存器和程序计数是 CPU 在运行任何任务前,所必须依赖的环境,这些环境就叫做 CPU 上下文。
既然知道了什么是 CPU 上下文,那理解 CPU 上下文切换就不难了。
CPU 上下文切换就是先把前一个任务的 CPU 上下文(CPU 寄存器和程序计数器)保存起来,然后加载新任务的上下文到这些寄存器和程序计数器,最后再跳转到程序计数器所指的新位置,运行新任务。
系统内核会存储保持下来的上下文信息,当此任务再次被分配给 CPU 运行时,CPU 会重新加载这些上下文,这样就能保证任务原来的状态不受影响,让任务看起来还是连续运行。
上面说到所谓的「任务」,主要包含进程、线程和中断。所以,可以根据任务的不同,把 CPU 上下文切换分成:进程上下文切换、线程上下文切换和中断上下文切换。
进程的上下文切换到底是切换什么呢?
进程是由内核管理和调度的,所以进程的切换只能发生在内核态。
所以,进程的上下文切换不仅包含了虚拟内存、栈、全局变量等用户空间的资源,还包括了内核堆栈、寄存器等内核空间的资源。
通常,会把交换的信息保存在进程的 PCB,当要运行另外一个进程的时候,我们需要从这个进程的 PCB 取出上下文,然后恢复到 CPU 中,这使得这个进程可以继续执行,如下图所示:
大家需要注意,进程的上下文开销是很关键的,我们希望它的开销越小越好,这样可以使得进程可以把更多时间花费在执行程序上,而不是耗费在上下文切换。
发生进程上下文切换有哪些场景?
- 为了保证所有进程可以得到公平调度,CPU 时间被划分为一段段的时间片,这些时间片再被轮流分配给各个进程。这样,当某个进程的时间片耗尽了,进程就从运行状态变为就绪状态,系统从就绪队列选择另外一个进程运行;
- 进程在系统资源不足(比如内存不足)时,要等到资源满足后才可以运行,这个时候进程也会被挂起,并由系统调度其他进程运行;
- 当进程通过睡眠函数 sleep 这样的方法将自己主动挂起时,自然也会重新调度;
- 当有优先级更高的进程运行时,为了保证高优先级进程的运行,当前进程会被挂起,由高优先级进程来运行;
- 发生硬件中断时,CPU 上的进程会被中断挂起,转而执行内核中的中断服务程序;
以上,就是发生进程上下文切换的常见场景了。
线程
在早期的操作系统中都是以进程作为独立运行的基本单位,直到后面,计算机科学家们又提出了更小的能独立运行的基本单位,也就是线程。
为什么使用线程?
我们举个例子,假设你要编写一个视频播放器软件,那么该软件功能的核心模块有三个:
- 从视频文件当中读取数据;
- 对读取的数据进行解压缩;
- 把解压缩后的视频数据播放出来;
对于单进程的实现方式,我想大家都会是以下这个方式:
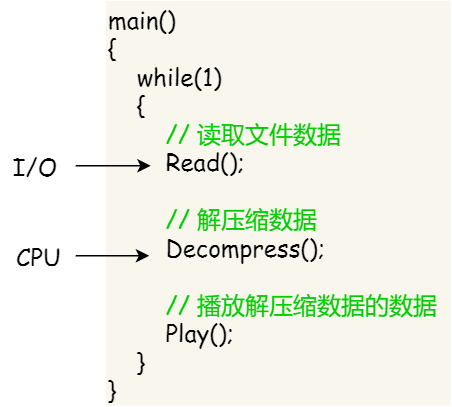
对于单进程的这种方式,存在以下问题:
- 播放出来的画面和声音会不连贯,因为当 CPU 能力不够强的时候,
Read的时候可能进程就等在这了,这样就会导致等半天才进行数据解压和播放; - 各个函数之间不是并发执行,影响资源的使用效率;
那改进成多进程的方式:

对于多进程的这种方式,依然会存在问题:
- 进程之间如何通信,共享数据?
- 维护进程的系统开销较大,如创建进程时,分配资源、建立 PCB;终止进程时,回收资源、撤销 PCB;进程切换时,保存当前进程的状态信息;
那到底如何解决呢?需要有一种新的实体,满足以下特性:
- 实体之间可以并发运行;
- 实体之间共享相同的地址空间;
这个新的实体,就是线程( *Thread* ),线程之间可以并发运行且共享相同的地址空间。
什么是线程?
线程是进程当中的一条执行流程。
同一个进程内多个线程之间可以共享代码段、数据段、打开的文件等资源,但每个线程各自都有一套独立的寄存器和栈,这样可以确保线程的控制流是相对独立的。
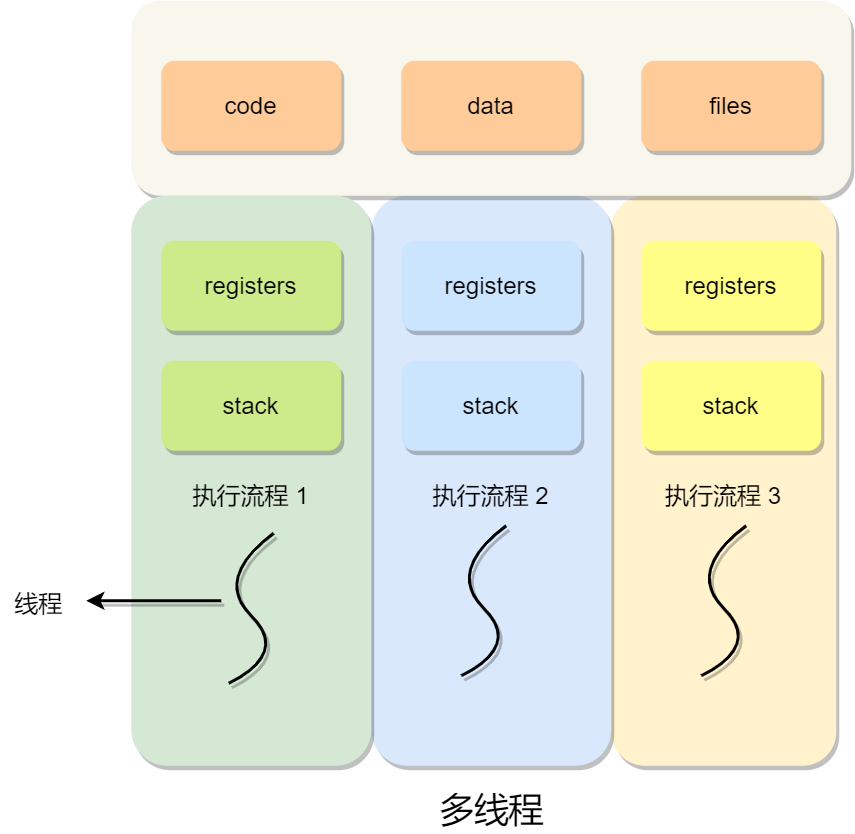
线程的优缺点?
线程的优点:
- 一个进程中可以同时存在多个线程;
- 各个线程之间可以并发执行;
- 各个线程之间可以共享地址空间和文件等资源;
线程的缺点:
- 当进程中的一个线程崩溃时,会导致其所属进程的所有线程崩溃(这里是针对 C/C++ 语言,Java语言中的线程奔溃不会造成进程崩溃,具体分析原因可以看这篇:线程崩溃了,进程也会崩溃吗? (opens new window))。
举个例子,对于游戏的用户设计,则不应该使用多线程的方式,否则一个用户挂了,会影响其他同个进程的线程。
线程与进程的比较
线程与进程的比较如下:
- 进程是资源(包括内存、打开的文件等)分配的单位,线程是 CPU 调度的单位;
- 进程拥有一个完整的资源平台,而线程只独享必不可少的资源,如寄存器和栈;
- 线程同样具有就绪、阻塞、执行三种基本状态,同样具有状态之间的转换关系;
- 线程能减少并发执行的时间和空间开销;
对于,线程相比进程能减少开销,体现在:
- 线程的创建时间比进程快,因为进程在创建的过程中,还需要资源管理信息,比如内存管理信息、文件管理信息,而线程在创建的过程中,不会涉及这些资源管理信息,而是共享它们;
- 线程的终止时间比进程快,因为线程释放的资源相比进程少很多;
- 同一个进程内的线程切换比进程切换快,因为线程具有相同的地址空间(虚拟内存共享),这意味着同一个进程的线程都具有同一个页表,那么在切换的时候不需要切换页表。而对于进程之间的切换,切换的时候要把页表给切换掉,而页表的切换过程开销是比较大的;
- 由于同一进程的各线程间共享内存和文件资源,那么在线程之间数据传递的时候,就不需要经过内核了,这就使得线程之间的数据交互效率更高了;
所以,不管是时间效率,还是空间效率线程比进程都要高。
线程的上下文切换
在前面我们知道了,线程与进程最大的区别在于:线程是调度的基本单位,而进程则是资源拥有的基本单位。
所以,所谓操作系统的任务调度,实际上的调度对象是线程,而进程只是给线程提供了虚拟内存、全局变量等资源。
对于线程和进程,我们可以这么理解:
- 当进程只有一个线程时,可以认为进程就等于线程;
- 当进程拥有多个线程时,这些线程会共享相同的虚拟内存和全局变量等资源,这些资源在上下文切换时是不需要修改的;
另外,线程也有自己的私有数据,比如栈和寄存器等,这些在上下文切换时也是需要保存的。
线程上下文切换的是什么?
这还得看线程是不是属于同一个进程:
- 当两个线程不是属于同一个进程,则切换的过程就跟进程上下文切换一样;
- 当两个线程是属于同一个进程,因为虚拟内存是共享的,所以在切换时,虚拟内存这些资源就保持不动,只需要切换线程的私有数据、寄存器等不共享的数据;
所以,线程的上下文切换相比进程,开销要小很多。
线程的实现
主要有三种线程的实现方式:
- 用户线程(*User Thread*):在用户空间实现的线程,不是由内核管理的线程,是由用户态的线程库来完成线程的管理;
- 内核线程(*Kernel Thread*):在内核中实现的线程,是由内核管理的线程;
- 轻量级进程(*LightWeight Process*):在内核中来支持用户线程;
那么,这还需要考虑一个问题,用户线程和内核线程的对应关系。
首先,第一种关系是多对一的关系,也就是多个用户线程对应同一个内核线程:
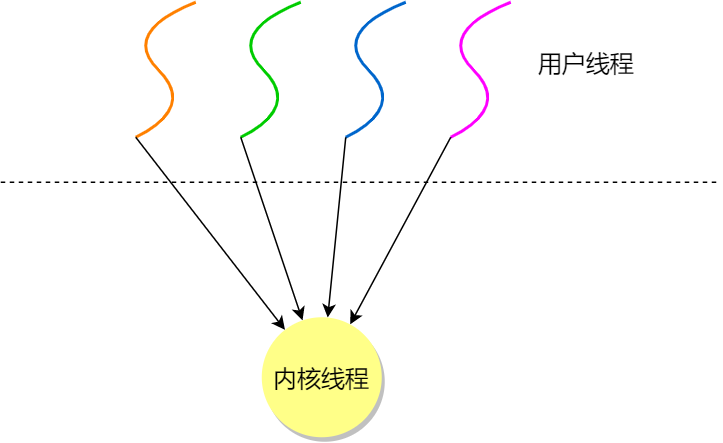
第二种是一对一的关系,也就是一个用户线程对应一个内核线程:
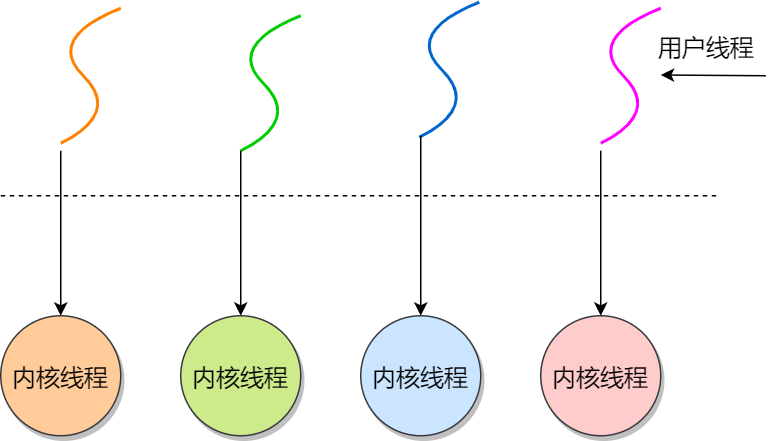
第三种是多对多的关系,也就是多个用户线程对应到多个内核线程:
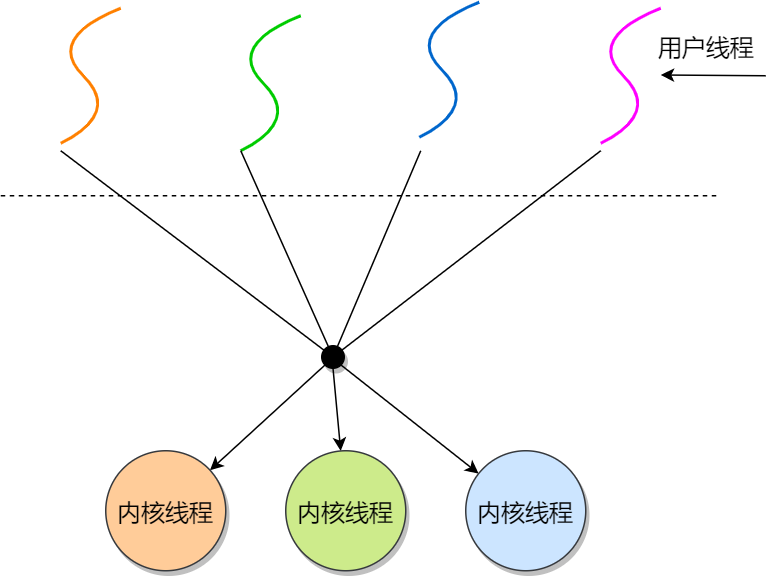
用户线程如何理解?存在什么优势和缺陷?
用户线程是基于用户态的线程管理库来实现的,那么线程控制块(*Thread Control Block, TCB*) 也是在库里面来实现的,对于操作系统而言是看不到这个 TCB 的,它只能看到整个进程的 PCB。
所以,用户线程的整个线程管理和调度,操作系统是不直接参与的,而是由用户级线程库函数来完成线程的管理,包括线程的创建、终止、同步和调度等。
用户级线程的模型,也就类似前面提到的多对一的关系,即多个用户线程对应同一个内核线程,如下图所示:
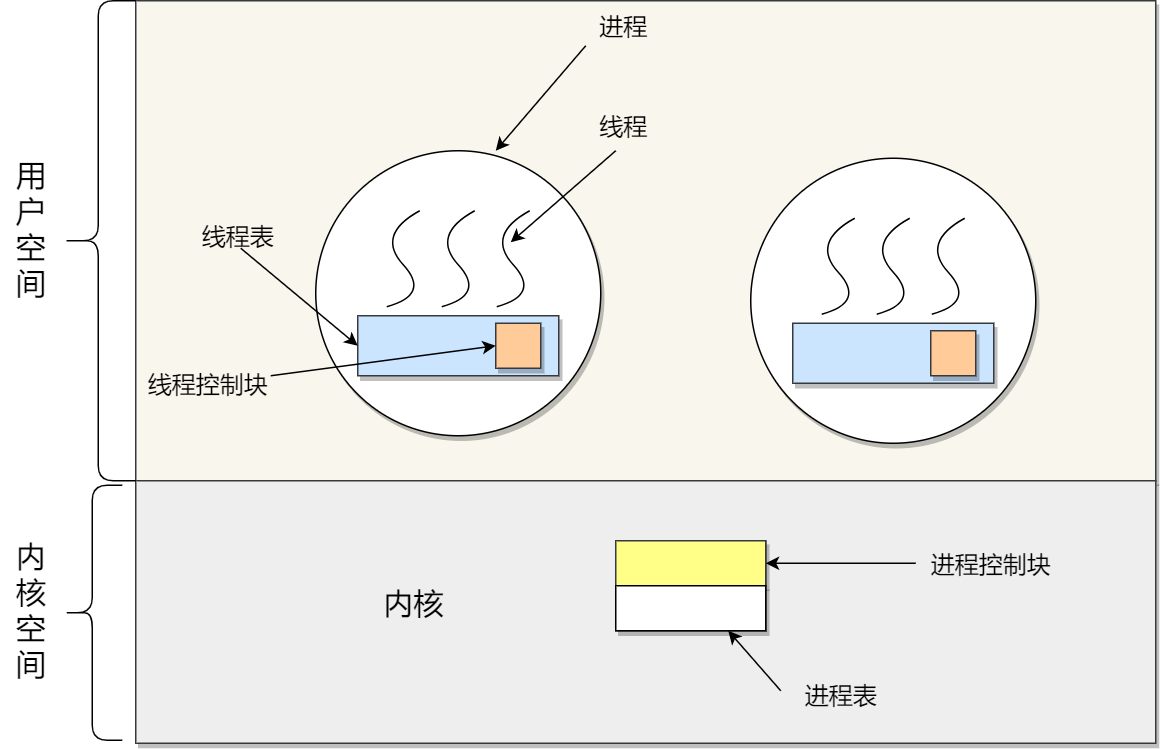
用户线程的优点:
- 每个进程都需要有它私有的线程控制块(TCB)列表,用来跟踪记录它各个线程状态信息(PC、栈指针、寄存器),TCB 由用户级线程库函数来维护,可用于不支持线程技术的操作系统;
- 用户线程的切换也是由线程库函数来完成的,无需用户态与内核态的切换,所以速度特别快;
用户线程的缺点:
- 由于操作系统不参与线程的调度,如果一个线程发起了系统调用而阻塞,那进程所包含的用户线程都不能执行了。
- 当一个线程开始运行后,除非它主动地交出 CPU 的使用权,否则它所在的进程当中的其他线程无法运行,因为用户态的线程没法打断当前运行中的线程,它没有这个特权,只有操作系统才有,但是用户线程不是由操作系统管理的。
- 由于时间片分配给进程,故与其他进程比,在多线程执行时,每个线程得到的时间片较少,执行会比较慢;
以上,就是用户线程的优缺点了。
那内核线程如何理解?存在什么优势和缺陷?
内核线程是由操作系统管理的,线程对应的 TCB 自然是放在操作系统里的,这样线程的创建、终止和管理都是由操作系统负责。
内核线程的模型,也就类似前面提到的一对一的关系,即一个用户线程对应一个内核线程,如下图所示:
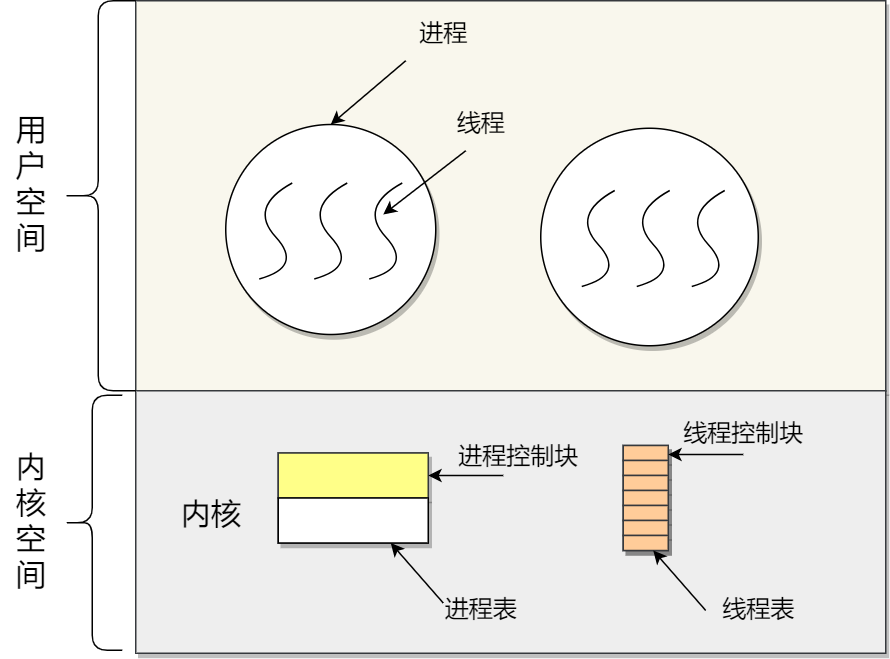
内核线程的优点:
- 在一个进程当中,如果某个内核线程发起系统调用而被阻塞,并不会影响其他内核线程的运行;
- 分配给线程,多线程的进程获得更多的 CPU 运行时间;
内核线程的缺点:
- 在支持内核线程的操作系统中,由内核来维护进程和线程的上下文信息,如 PCB 和 TCB;
- 线程的创建、终止和切换都是通过系统调用的方式来进行,因此对于系统来说,系统开销比较大;
以上,就是内核线程的优缺点了。
最后的轻量级进程如何理解?
轻量级进程(*Light-weight process,LWP*)是内核支持的用户线程,一个进程可有一个或多个 LWP,每个 LWP 是跟内核线程一对一映射的,也就是 LWP 都是由一个内核线程支持,而且 LWP 是由内核管理并像普通进程一样被调度。
在大多数系统中,LWP与普通进程的区别也在于它只有一个最小的执行上下文和调度程序所需的统计信息。一般来说,一个进程代表程序的一个实例,而 LWP 代表程序的执行线程,因为一个执行线程不像进程那样需要那么多状态信息,所以 LWP 也不带有这样的信息。
在 LWP 之上也是可以使用用户线程的,那么 LWP 与用户线程的对应关系就有三种:
1 : 1,即一个 LWP 对应 一个用户线程;N : 1,即一个 LWP 对应多个用户线程;M : N,即多个 LWP 对应多个用户线程;
接下来针对上面这三种对应关系说明它们优缺点。先看下图的 LWP 模型:
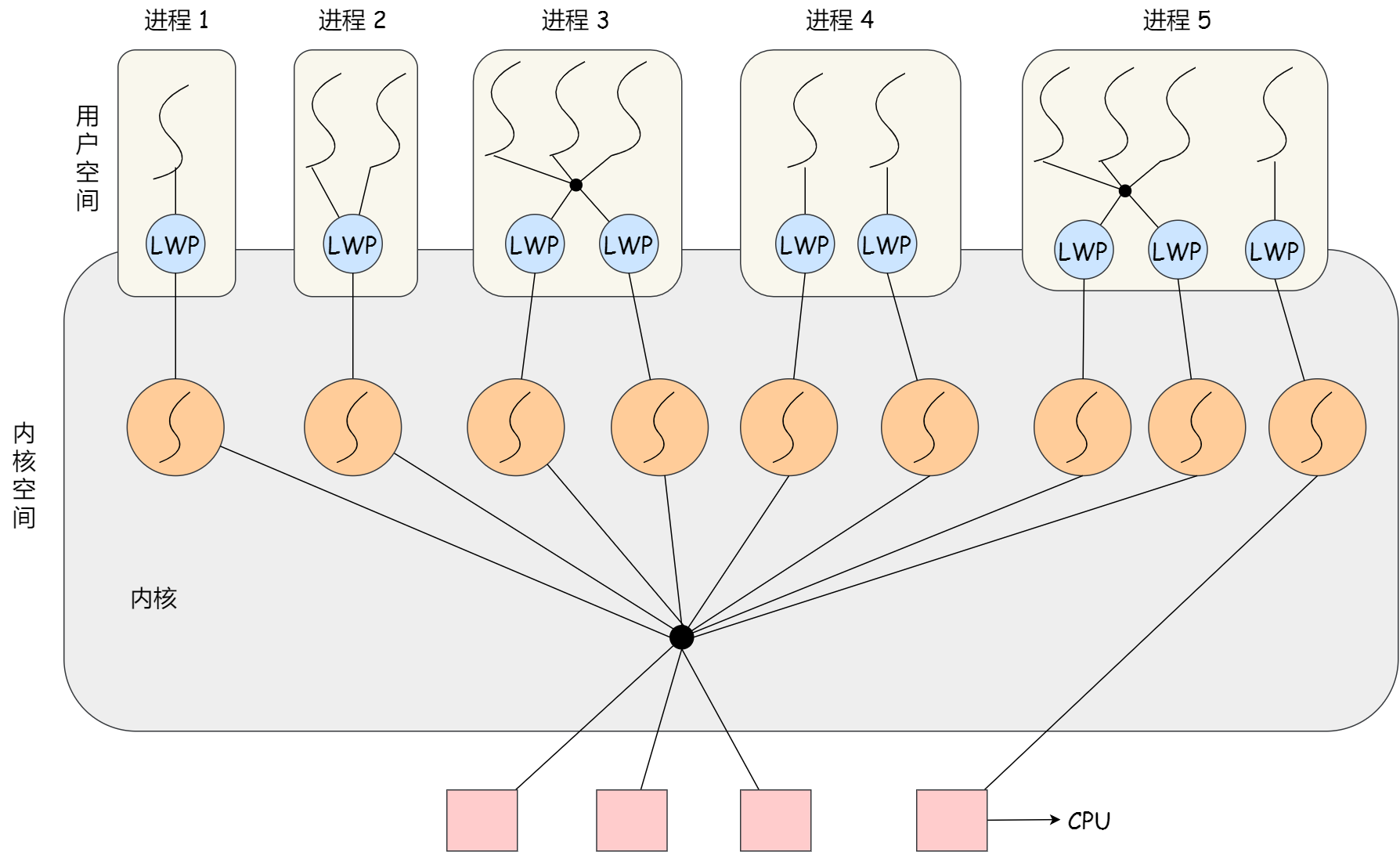
1 : 1 模式
一个线程对应到一个 LWP 再对应到一个内核线程,如上图的进程 4,属于此模型。
- 优点:实现并行,当一个 LWP 阻塞,不会影响其他 LWP;
- 缺点:每一个用户线程,就产生一个内核线程,创建线程的开销较大。
N : 1 模式
多个用户线程对应一个 LWP 再对应一个内核线程,如上图的进程 2,线程管理是在用户空间完成的,此模式中用户的线程对操作系统不可见。
- 优点:用户线程要开几个都没问题,且上下文切换发生用户空间,切换的效率较高;
- 缺点:一个用户线程如果阻塞了,则整个进程都将会阻塞,另外在多核 CPU 中,是没办法充分利用 CPU 的。
M : N 模式
根据前面的两个模型混搭一起,就形成 M:N 模型,该模型提供了两级控制,首先多个用户线程对应到多个 LWP,LWP 再一一对应到内核线程,如上图的进程 3。
- 优点:综合了前两种优点,大部分的线程上下文发生在用户空间,且多个线程又可以充分利用多核 CPU 的资源。
组合模式
如上图的进程 5,此进程结合 1:1 模型和 M:N 模型。开发人员可以针对不同的应用特点调节内核线程的数目来达到物理并行性和逻辑并行性的最佳方案。
调度
进程都希望自己能够占用 CPU 进行工作,那么这涉及到前面说过的进程上下文切换。
一旦操作系统把进程切换到运行状态,也就意味着该进程占用着 CPU 在执行,但是当操作系统把进程切换到其他状态时,那就不能在 CPU 中执行了,于是操作系统会选择下一个要运行的进程。
选择一个进程运行这一功能是在操作系统中完成的,通常称为调度程序(scheduler)。
那到底什么时候调度进程,或以什么原则来调度进程呢?
TIP
我知道很多人会问,线程不是操作系统的调度单位吗?为什么这里参与调度的是进程?
先提前说明,这里的进程指只有主线程的进程,所以调度主线程就等于调度了整个进程。
那为什么干脆不直接取名线程调度?主要是操作系统相关书籍,都是用进程调度这个名字,所以我也沿用了这个名字。
调度时机
在进程的生命周期中,当进程从一个运行状态到另外一状态变化的时候,其实会触发一次调度。
比如,以下状态的变化都会触发操作系统的调度:
- 从就绪态 -> 运行态:当进程被创建时,会进入到就绪队列,操作系统会从就绪队列选择一个进程运行;
- 从运行态 -> 阻塞态:当进程发生 I/O 事件而阻塞时,操作系统必须选择另外一个进程运行;
- 从运行态 -> 结束态:当进程退出结束后,操作系统得从就绪队列选择另外一个进程运行;
因为,这些状态变化的时候,操作系统需要考虑是否要让新的进程给 CPU 运行,或者是否让当前进程从 CPU 上退出来而换另一个进程运行。
另外,如果硬件时钟提供某个频率的周期性中断,那么可以根据如何处理时钟中断 ,把调度算法分为两类:
- 非抢占式调度算法挑选一个进程,然后让该进程运行直到被阻塞,或者直到该进程退出,才会调用另外一个进程,也就是说不会理时钟中断这个事情。
- 抢占式调度算法挑选一个进程,然后让该进程只运行某段时间,如果在该时段结束时,该进程仍然在运行时,则会把它挂起,接着调度程序从就绪队列挑选另外一个进程。这种抢占式调度处理,需要在时间间隔的末端发生时钟中断,以便把 CPU 控制返回给调度程序进行调度,也就是常说的时间片机制。
调度原则
原则一:如果运行的程序,发生了 I/O 事件的请求,那 CPU 使用率必然会很低,因为此时进程在阻塞等待硬盘的数据返回。这样的过程,势必会造成 CPU 突然的空闲。所以,为了提高 CPU 利用率,在这种发送 I/O 事件致使 CPU 空闲的情况下,调度程序需要从就绪队列中选择一个进程来运行。
原则二:有的程序执行某个任务花费的时间会比较长,如果这个程序一直占用着 CPU,会造成系统吞吐量(CPU 在单位时间内完成的进程数量)的降低。所以,要提高系统的吞吐率,调度程序要权衡长任务和短任务进程的运行完成数量。
原则三:从进程开始到结束的过程中,实际上是包含两个时间,分别是进程运行时间和进程等待时间,这两个时间总和就称为周转时间。进程的周转时间越小越好,如果进程的等待时间很长而运行时间很短,那周转时间就很长,这不是我们所期望的,调度程序应该避免这种情况发生。
原则四:处于就绪队列的进程,也不能等太久,当然希望这个等待的时间越短越好,这样可以使得进程更快的在 CPU 中执行。所以,就绪队列中进程的等待时间也是调度程序所需要考虑的原则。
原则五:对于鼠标、键盘这种交互式比较强的应用,我们当然希望它的响应时间越快越好,否则就会影响用户体验了。所以,对于交互式比较强的应用,响应时间也是调度程序需要考虑的原则。
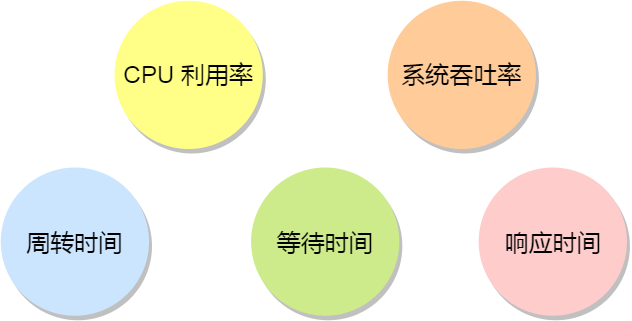
针对上面的五种调度原则,总结成如下:
- CPU 利用率:调度程序应确保 CPU 是始终匆忙的状态,这可提高 CPU 的利用率;
- 系统吞吐量:吞吐量表示的是单位时间内 CPU 完成进程的数量,长作业的进程会占用较长的 CPU 资源,因此会降低吞吐量,相反,短作业的进程会提升系统吞吐量;
- 周转时间:周转时间是进程运行+阻塞时间+等待时间的总和,一个进程的周转时间越小越好;
- 等待时间:这个等待时间不是阻塞状态的时间,而是进程处于就绪队列的时间,等待的时间越长,用户越不满意;
- 响应时间:用户提交请求到系统第一次产生响应所花费的时间,在交互式系统中,响应时间是衡量调度算法好坏的主要标准。
说白了,这么多调度原则,目的就是要使得进程要「快」。
调度算法
不同的调度算法适用的场景也是不同的。
接下来,说说在单核 CPU 系统中常见的调度算法。
01 先来先服务调度算法
最简单的一个调度算法,就是非抢占式的先来先服务(*First Come First Serve, FCFS*)算法了。

顾名思义,先来后到,每次从就绪队列选择最先进入队列的进程,然后一直运行,直到进程退出或被阻塞,才会继续从队列中选择第一个进程接着运行。
这似乎很公平,但是当一个长作业先运行了,那么后面的短作业等待的时间就会很长,不利于短作业。
FCFS 对长作业有利,适用于 CPU 繁忙型作业的系统,而不适用于 I/O 繁忙型作业的系统。
02 最短作业优先调度算法
最短作业优先(*Shortest Job First, SJF*)调度算法同样也是顾名思义,它会优先选择运行时间最短的进程来运行,这有助于提高系统的吞吐量。
这显然对长作业不利,很容易造成一种极端现象。
比如,一个长作业在就绪队列等待运行,而这个就绪队列有非常多的短作业,那么就会使得长作业不断的往后推,周转时间变长,致使长作业长期不会被运行。
03 高响应比优先调度算法
前面的「先来先服务调度算法」和「最短作业优先调度算法」都没有很好的权衡短作业和长作业。
那么,高响应比优先 (*Highest Response Ratio Next, HRRN*)调度算法主要是权衡了短作业和长作业。
每次进行进程调度时,先计算「响应比优先级」,然后把「响应比优先级」最高的进程投入运行,「响应比优先级」的计算公式:

从上面的公式,可以发现:
- 如果两个进程的「等待时间」相同时,「要求的服务时间」越短,「响应比」就越高,这样短作业的进程容易被选中运行;
- 如果两个进程「要求的服务时间」相同时,「等待时间」越长,「响应比」就越高,这就兼顾到了长作业进程,因为进程的响应比可以随时间等待的增加而提高,当其等待时间足够长时,其响应比便可以升到很高,从而获得运行的机会;
TIP
很多人问怎么才能知道一个进程要求服务的时间?这不是不可预知的吗?
对的,这是不可预估的。所以,高响应比优先调度算法是「理想型」的调度算法,现实中是实现不了的。
04 时间片轮转调度算法
最古老、最简单、最公平且使用最广的算法就是时间片轮转(*Round Robin, RR*)调度算法。
每个进程被分配一个时间段,称为时间片(*Quantum*),即允许该进程在该时间段中运行。
- 如果时间片用完,进程还在运行,那么将会把此进程从 CPU 释放出来,并把 CPU 分配给另外一个进程;
- 如果该进程在时间片结束前阻塞或结束,则 CPU 立即进行切换;
另外,时间片的长度就是一个很关键的点:
- 如果时间片设得太短会导致过多的进程上下文切换,降低了 CPU 效率;
- 如果设得太长又可能引起对短作业进程的响应时间变长。将
一般来说,时间片设为 20ms~50ms 通常是一个比较合理的折中值。
05 最高优先级调度算法
前面的「时间片轮转算法」做了个假设,即让所有的进程同等重要,也不偏袒谁,大家的运行时间都一样。
但是,对于多用户计算机系统就有不同的看法了,它们希望调度是有优先级的,即希望调度程序能从就绪队列中选择最高优先级的进程进行运行,这称为最高优先级(*Highest Priority First,HPF*)调度算法。
进程的优先级可以分为,静态优先级和动态优先级:
- 静态优先级:创建进程时候,就已经确定了优先级了,然后整个运行时间优先级都不会变化;
- 动态优先级:根据进程的动态变化调整优先级,比如如果进程运行时间增加,则降低其优先级,如果进程等待时间(就绪队列的等待时间)增加,则升高其优先级,也就是随着时间的推移增加等待进程的优先级。
该算法也有两种处理优先级高的方法,非抢占式和抢占式:
- 非抢占式:当就绪队列中出现优先级高的进程,运行完当前进程,再选择优先级高的进程。
- 抢占式:当就绪队列中出现优先级高的进程,当前进程挂起,调度优先级高的进程运行。
但是依然有缺点,可能会导致低优先级的进程永远不会运行。
06 多级反馈队列调度算法
多级反馈队列(*Multilevel Feedback Queue*)调度算法是「时间片轮转算法」和「最高优先级算法」的综合和发展。
顾名思义:
- 「多级」表示有多个队列,每个队列优先级从高到低,同时优先级越高时间片越短。
- 「反馈」表示如果有新的进程加入优先级高的队列时,立刻停止当前正在运行的进程,转而去运行优先级高的队列;
来看看,它是如何工作的:
- 设置了多个队列,赋予每个队列不同的优先级,每个队列优先级从高到低,同时优先级越高时间片越短;
- 新的进程会被放入到第一级队列的末尾,按先来先服务的原则排队等待被调度,如果在第一级队列规定的时间片没运行完成,则将其转入到第二级队列的末尾,以此类推,直至完成;
- 当较高优先级的队列为空,才调度较低优先级的队列中的进程运行。如果进程运行时,有新进程进入较高优先级的队列,则停止当前运行的进程并将其移入到原队列末尾,接着让较高优先级的进程运行;
可以发现,对于短作业可能可以在第一级队列很快被处理完。对于长作业,如果在第一级队列处理不完,可以移入下次队列等待被执行,虽然等待的时间变长了,但是运行时间也变更长了,所以该算法很好的兼顾了长短作业,同时有较好的响应时间。
看的迷迷糊糊?那我拿去银行办业务的例子,把上面的调度算法串起来,你还不懂,你锤我!
办理业务的客户相当于进程,银行窗口工作人员相当于 CPU。
现在,假设这个银行只有一个窗口(单核 CPU ),那么工作人员一次只能处理一个业务。
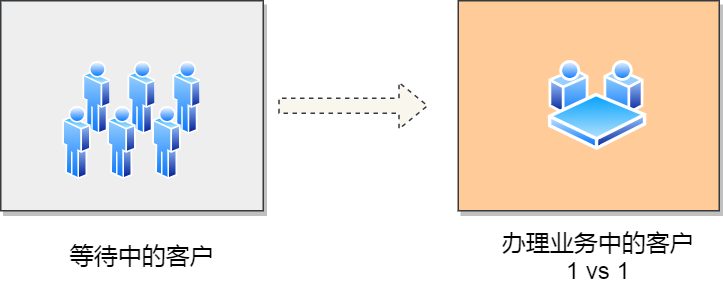
那么最简单的处理方式,就是先来的先处理,后面来的就乖乖排队,这就是先来先服务(*FCFS*)调度算法。但是万一先来的这位老哥是来贷款的,这一谈就好几个小时,一直占用着窗口,这样后面的人只能干等,或许后面的人只是想简单的取个钱,几分钟就能搞定,却因为前面老哥办长业务而要等几个小时,你说气不气人?
有客户抱怨了,那我们就要改进,我们干脆优先给那些几分钟就能搞定的人办理业务,这就是短作业优先(*SJF*)调度算法。听起来不错,但是依然还是有个极端情况,万一办理短业务的人非常的多,这会导致长业务的人一直得不到服务,万一这个长业务是个大客户,那不就捡了芝麻丢了西瓜
那就公平起见,现在窗口工作人员规定,每个人我只处理 10 分钟。如果 10 分钟之内处理完,就马上换下一个人。如果没处理完,依然换下一个人,但是客户自己得记住办理到哪个步骤了。这个也就是时间片轮转(*RR*)调度算法。但是如果时间片设置过短,那么就会造成大量的上下文切换,增大了系统开销。如果时间片过长,相当于退化成 FCFS 算法了。
既然公平也可能存在问题,那银行就对客户分等级,分为普通客户、VIP 客户、SVIP 客户。只要高优先级的客户一来,就第一时间处理这个客户,这就是最高优先级(*HPF*)调度算法。但依然也会有极端的问题,万一当天来的全是高级客户,那普通客户不是没有被服务的机会,不把普通客户当人是吗?那我们把优先级改成动态的,如果客户办理业务时间增加,则降低其优先级,如果客户等待时间增加,则升高其优先级。
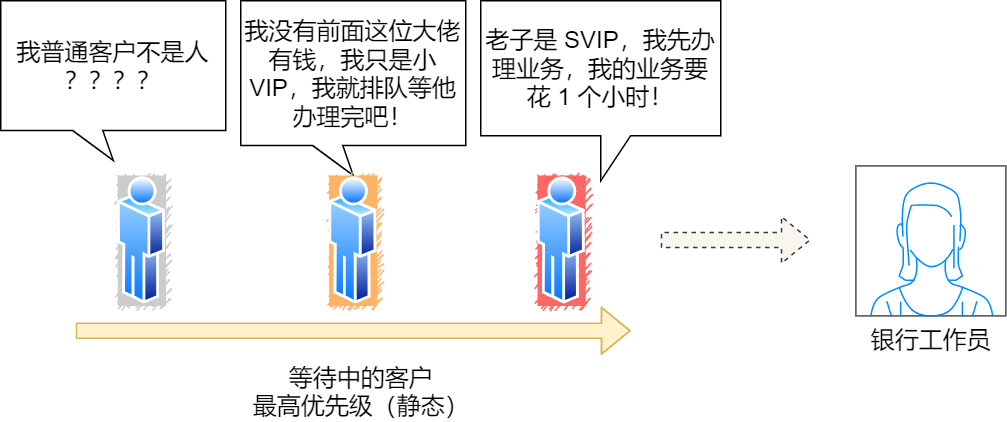
那有没有兼顾到公平和效率的方式呢?这里介绍一种算法,考虑的还算充分的,多级反馈队列(*MFQ*)调度算法,它是时间片轮转算法和优先级算法的综合和发展。它的工作方式:
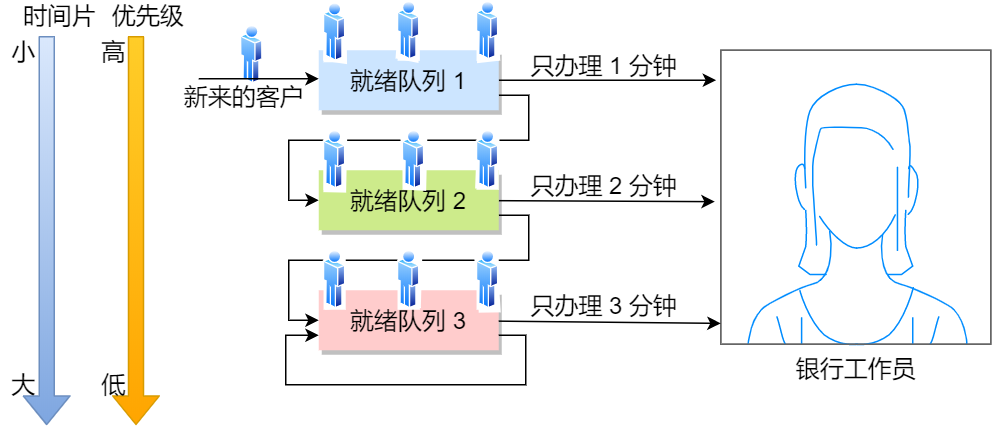
- 银行设置了多个排队(就绪)队列,每个队列都有不同的优先级,各个队列优先级从高到低,同时每个队列执行时间片的长度也不同,优先级越高的时间片越短。
- 新客户(进程)来了,先进入第一级队列的末尾,按先来先服务原则排队等待被叫号(运行)。如果时间片用完客户的业务还没办理完成,则让客户进入到下一级队列的末尾,以此类推,直至客户业务办理完成。
- 当第一级队列没人排队时,就会叫号二级队列的客户。如果客户办理业务过程中,有新的客户加入到较高优先级的队列,那么此时办理中的客户需要停止办理,回到原队列的末尾等待再次叫号,因为要把窗口让给刚进入较高优先级队列的客户。
可以发现,对于要办理短业务的客户来说,可以很快的轮到并解决。对于要办理长业务的客户,一下子解决不了,就可以放到下一个队列,虽然等待的时间稍微变长了,但是轮到自己的办理时间也变长了,也可以接受,不会造成极端的现象,可以说是综合上面几种算法的优点。
进程间有哪些通信方式?
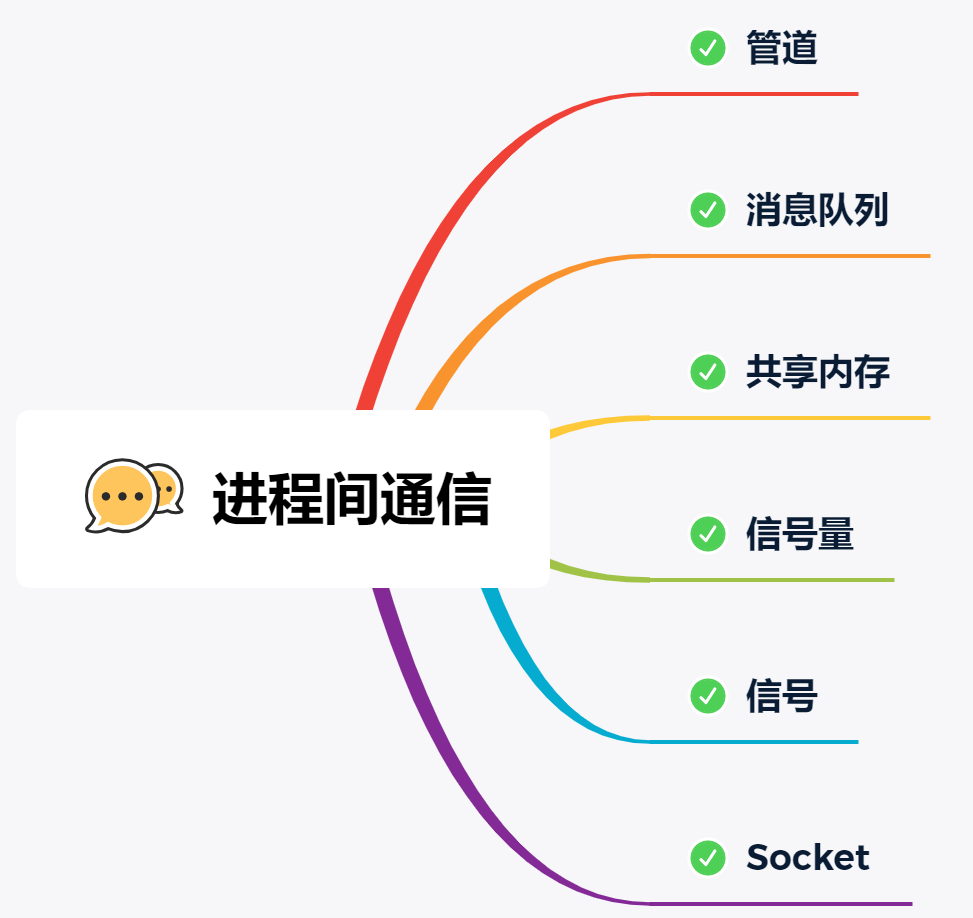
每个进程的用户地址空间都是独立的,一般而言是不能互相访问的,但内核空间是每个进程都共享的,所以进程之间要通信必须通过内核。
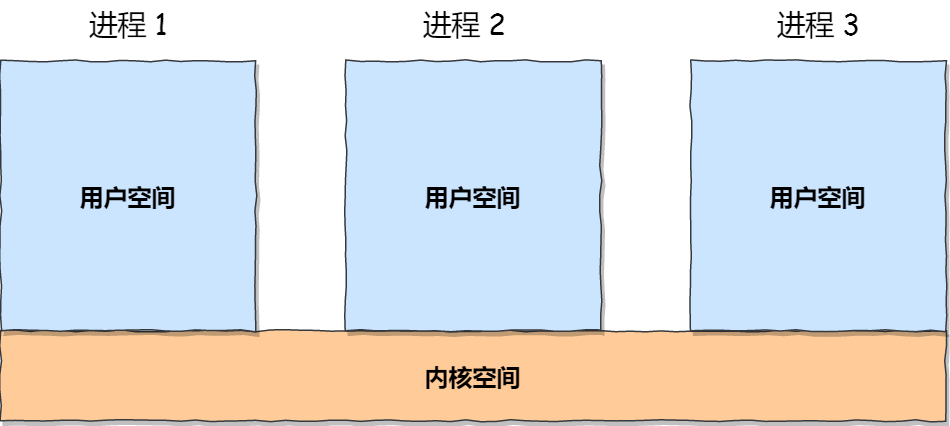
Linux 内核提供了不少进程间通信的机制,我们来一起瞧瞧有哪些?
管道
如果你学过 Linux 命令,那你肯定很熟悉「|」这个竖线。
|
|
上面命令行里的「|」竖线就是一个管道,它的功能是将前一个命令(ps auxf)的输出,作为后一个命令(grep mysql)的输入,从这功能描述,可以看出管道传输数据是单向的,如果想相互通信,我们需要创建两个管道才行。
同时,我们得知上面这种管道是没有名字,所以「|」表示的管道称为匿名管道,用完了就销毁。
管道还有另外一个类型是命名管道,也被叫做 FIFO,因为数据是先进先出的传输方式。
在使用命名管道前,先需要通过 mkfifo 命令来创建,并且指定管道名字:
|
|
myPipe 就是这个管道的名称,基于 Linux 一切皆文件的理念,所以管道也是以文件的方式存在,我们可以用 ls 看一下,这个文件的类型是 p,也就是 pipe(管道) 的意思:
|
|
接下来,我们往 myPipe 这个管道写入数据:
|
|
你操作了后,你会发现命令执行后就停在这了,这是因为管道里的内容没有被读取,只有当管道里的数据被读完后,命令才可以正常退出。
于是,我们执行另外一个命令来读取这个管道里的数据:
|
|
可以看到,管道里的内容被读取出来了,并打印在了终端上,另外一方面,echo 那个命令也正常退出了。
我们可以看出,管道这种通信方式效率低,不适合进程间频繁地交换数据。当然,它的好处,自然就是简单,同时也我们很容易得知管道里的数据已经被另一个进程读取了。
那管道如何创建呢,背后原理是什么?
匿名管道的创建,需要通过下面这个系统调用:
|
|
这里表示创建一个匿名管道,并返回了两个描述符,一个是管道的读取端描述符 fd[0],另一个是管道的写入端描述符 fd[1]。注意,这个匿名管道是特殊的文件,只存在于内存,不存于文件系统中。
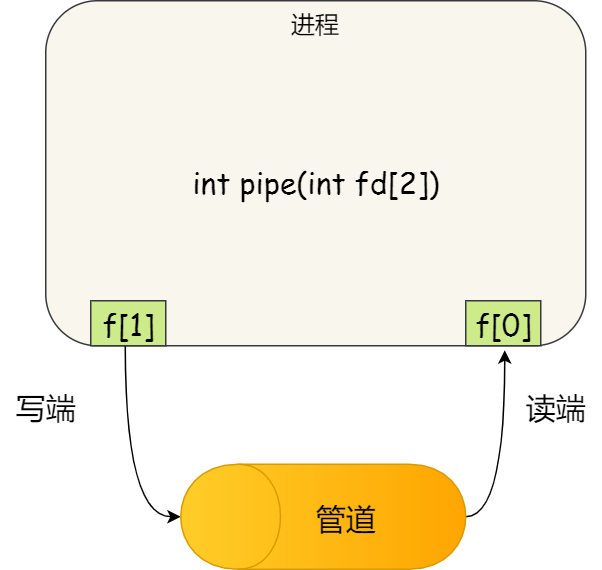
其实,所谓的管道,就是内核里面的一串缓存。从管道的一段写入的数据,实际上是缓存在内核中的,另一端读取,也就是从内核中读取这段数据。另外,管道传输的数据是无格式的流且大小受限。
看到这,你可能会有疑问了,这两个描述符都是在一个进程里面,并没有起到进程间通信的作用,怎么样才能使得管道是跨过两个进程的呢?
我们可以使用 fork 创建子进程,创建的子进程会复制父进程的文件描述符,这样就做到了两个进程各有两个「 fd[0] 与 fd[1]」,两个进程就可以通过各自的 fd 写入和读取同一个管道文件实现跨进程通信了。
管道只能一端写入,另一端读出,所以上面这种模式容易造成混乱,因为父进程和子进程都可以同时写入,也都可以读出。那么,为了避免这种情况,通常的做法是:
- 父进程关闭读取的 fd[0],只保留写入的 fd[1];
- 子进程关闭写入的 fd[1],只保留读取的 fd[0];
所以说如果需要双向通信,则应该创建两个管道。
到这里,我们仅仅解析了使用管道进行父进程与子进程之间的通信,但是在我们 shell 里面并不是这样的。
在 shell 里面执行 A | B命令的时候,A 进程和 B 进程都是 shell 创建出来的子进程,A 和 B 之间不存在父子关系,它俩的父进程都是 shell。
所以说,在 shell 里通过「|」匿名管道将多个命令连接在一起,实际上也就是创建了多个子进程,那么在我们编写 shell 脚本时,能使用一个管道搞定的事情,就不要多用一个管道,这样可以减少创建子进程的系统开销。
我们可以得知,对于匿名管道,它的通信范围是存在父子关系的进程。因为管道没有实体,也就是没有管道文件,只能通过 fork 来复制父进程 fd 文件描述符,来达到通信的目的。
另外,对于命名管道,它可以在不相关的进程间也能相互通信。因为命令管道,提前创建了一个类型为管道的设备文件,在进程里只要使用这个设备文件,就可以相互通信。
不管是匿名管道还是命名管道,进程写入的数据都是缓存在内核中,另一个进程读取数据时候自然也是从内核中获取,同时通信数据都遵循先进先出原则,不支持 lseek 之类的文件定位操作。
消息队列
前面说到管道的通信方式是效率低的,因此管道不适合进程间频繁地交换数据。
对于这个问题,消息队列的通信模式就可以解决。比如,A 进程要给 B 进程发送消息,A 进程把数据放在对应的消息队列后就可以正常返回了,B 进程需要的时候再去读取数据就可以了。同理,B 进程要给 A 进程发送消息也是如此。
再来,消息队列是保存在内核中的消息链表,在发送数据时,会分成一个一个独立的数据单元,也就是消息体(数据块),消息体是用户自定义的数据类型,消息的发送方和接收方要约定好消息体的数据类型,所以每个消息体都是固定大小的存储块,不像管道是无格式的字节流数据。如果进程从消息队列中读取了消息体,内核就会把这个消息体删除。
消息队列生命周期随内核,如果没有释放消息队列或者没有关闭操作系统,消息队列会一直存在,而前面提到的匿名管道的生命周期,是随进程的创建而建立,随进程的结束而销毁。
消息这种模型,两个进程之间的通信就像平时发邮件一样,你来一封,我回一封,可以频繁沟通了。
但邮件的通信方式存在不足的地方有两点,一是通信不及时,二是附件也有大小限制,这同样也是消息队列通信不足的点。
消息队列不适合比较大数据的传输,因为在内核中每个消息体都有一个最大长度的限制,同时所有队列所包含的全部消息体的总长度也是有上限。在 Linux 内核中,会有两个宏定义 MSGMAX 和 MSGMNB,它们以字节为单位,分别定义了一条消息的最大长度和一个队列的最大长度。
消息队列通信过程中,存在用户态与内核态之间的数据拷贝开销,因为进程写入数据到内核中的消息队列时,会发生从用户态拷贝数据到内核态的过程,同理另一进程读取内核中的消息数据时,会发生从内核态拷贝数据到用户态的过程。
共享内存
消息队列的读取和写入的过程,都会有发生用户态与内核态之间的消息拷贝过程。那共享内存的方式,就很好的解决了这一问题。
现代操作系统,对于内存管理,采用的是虚拟内存技术,也就是每个进程都有自己独立的虚拟内存空间,不同进程的虚拟内存映射到不同的物理内存中。所以,即使进程 A 和 进程 B 的虚拟地址是一样的,其实访问的是不同的物理内存地址,对于数据的增删查改互不影响。
共享内存的机制,就是拿出一块虚拟地址空间来,映射到相同的物理内存中。这样这个进程写入的东西,另外一个进程马上就能看到了,都不需要拷贝来拷贝去,传来传去,大大提高了进程间通信的速度。
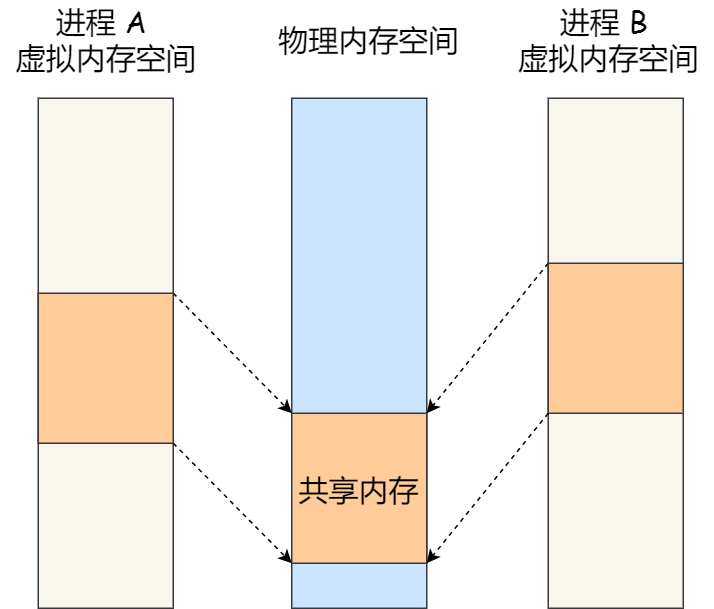
信号量
用了共享内存通信方式,带来新的问题,那就是如果多个进程同时修改同一个共享内存,很有可能就冲突了。例如两个进程都同时写一个地址,那先写的那个进程会发现内容被别人覆盖了。
为了防止多进程竞争共享资源,而造成的数据错乱,所以需要保护机制,使得共享的资源,在任意时刻只能被一个进程访问。正好,信号量就实现了这一保护机制。
信号量其实是一个整型的计数器,主要用于实现进程间的互斥与同步,而不是用于缓存进程间通信的数据。
信号量表示资源的数量,控制信号量的方式有两种原子操作:
- 一个是 P 操作,这个操作会把信号量减去 1,相减后如果信号量 < 0,则表明资源已被占用,进程需阻塞等待;相减后如果信号量 >= 0,则表明还有资源可使用,进程可正常继续执行。
- 另一个是 V 操作,这个操作会把信号量加上 1,相加后如果信号量 <= 0,则表明当前有阻塞中的进程,于是会将该进程唤醒运行;相加后如果信号量 > 0,则表明当前没有阻塞中的进程;
P 操作是用在进入共享资源之前,V 操作是用在离开共享资源之后,这两个操作是必须成对出现的。
接下来,举个例子,如果要使得两个进程互斥访问共享内存,我们可以初始化信号量为 1。
具体的过程如下:
- 进程 A 在访问共享内存前,先执行了 P 操作,由于信号量的初始值为 1,故在进程 A 执行 P 操作后信号量变为 0,表示共享资源可用,于是进程 A 就可以访问共享内存。
- 若此时,进程 B 也想访问共享内存,执行了 P 操作,结果信号量变为了 -1,这就意味着临界资源已被占用,因此进程 B 被阻塞。
- 直到进程 A 访问完共享内存,才会执行 V 操作,使得信号量恢复为 0,接着就会唤醒阻塞中的线程 B,使得进程 B 可以访问共享内存,最后完成共享内存的访问后,执行 V 操作,使信号量恢复到初始值 1。
可以发现,信号初始化为 1,就代表着是互斥信号量,它可以保证共享内存在任何时刻只有一个进程在访问,这就很好的保护了共享内存。
另外,在多进程里,每个进程并不一定是顺序执行的,它们基本是以各自独立的、不可预知的速度向前推进,但有时候我们又希望多个进程能密切合作,以实现一个共同的任务。
例如,进程 A 是负责生产数据,而进程 B 是负责读取数据,这两个进程是相互合作、相互依赖的,进程 A 必须先生产了数据,进程 B 才能读取到数据,所以执行是有前后顺序的。
那么这时候,就可以用信号量来实现多进程同步的方式,我们可以初始化信号量为 0。
具体过程:
- 如果进程 B 比进程 A 先执行了,那么执行到 P 操作时,由于信号量初始值为 0,故信号量会变为 -1,表示进程 A 还没生产数据,于是进程 B 就阻塞等待;
- 接着,当进程 A 生产完数据后,执行了 V 操作,就会使得信号量变为 0,于是就会唤醒阻塞在 P 操作的进程 B;
- 最后,进程 B 被唤醒后,意味着进程 A 已经生产了数据,于是进程 B 就可以正常读取数据了。
可以发现,信号初始化为 0,就代表着是同步信号量,它可以保证进程 A 应在进程 B 之前执行。
信号
上面说的进程间通信,都是常规状态下的工作模式。对于异常情况下的工作模式,就需要用「信号」的方式来通知进程。
信号跟信号量虽然名字相似度 66.66%,但两者用途完全不一样,就好像 Java 和 JavaScript 的区别。
在 Linux 操作系统中, 为了响应各种各样的事件,提供了几十种信号,分别代表不同的意义。我们可以通过 kill -l 命令,查看所有的信号:
|
|
运行在 shell 终端的进程,我们可以通过键盘输入某些组合键的时候,给进程发送信号。例如
- Ctrl+C 产生
SIGINT信号,表示终止该进程; - Ctrl+Z 产生
SIGTSTP信号,表示停止该进程,但还未结束;
如果进程在后台运行,可以通过 kill 命令的方式给进程发送信号,但前提需要知道运行中的进程 PID 号,例如:
- kill -9 1050 ,表示给 PID 为 1050 的进程发送
SIGKILL信号,用来立即结束该进程;
所以,信号事件的来源主要有硬件来源(如键盘 Cltr+C )和软件来源(如 kill 命令)。
信号是进程间通信机制中唯一的异步通信机制,因为可以在任何时候发送信号给某一进程,一旦有信号产生,我们就有下面这几种,用户进程对信号的处理方式。
1.执行默认操作。Linux 对每种信号都规定了默认操作,例如,上面列表中的 SIGTERM 信号,就是终止进程的意思。
2.捕捉信号。我们可以为信号定义一个信号处理函数。当信号发生时,我们就执行相应的信号处理函数。
3.忽略信号。当我们不希望处理某些信号的时候,就可以忽略该信号,不做任何处理。有两个信号是应用进程无法捕捉和忽略的,即 SIGKILL 和 SEGSTOP,它们用于在任何时候中断或结束某一进程。
Socket
前面提到的管道、消息队列、共享内存、信号量和信号都是在同一台主机上进行进程间通信,那要想跨网络与不同主机上的进程之间通信,就需要 Socket 通信了。
实际上,Socket 通信不仅可以跨网络与不同主机的进程间通信,还可以在同主机上进程间通信。
我们来看看创建 socket 的系统调用:
|
|
三个参数分别代表:
- domain 参数用来指定协议族,比如 AF_INET 用于 IPV4、AF_INET6 用于 IPV6、AF_LOCAL/AF_UNIX 用于本机;
- type 参数用来指定通信特性,比如 SOCK_STREAM 表示的是字节流,对应 TCP、SOCK_DGRAM 表示的是数据报,对应 UDP、SOCK_RAW 表示的是原始套接字;
- protocal 参数原本是用来指定通信协议的,但现在基本废弃。因为协议已经通过前面两个参数指定完成,protocol 目前一般写成 0 即可;
根据创建 socket 类型的不同,通信的方式也就不同:
- 实现 TCP 字节流通信: socket 类型是 AF_INET 和 SOCK_STREAM;
- 实现 UDP 数据报通信:socket 类型是 AF_INET 和 SOCK_DGRAM;
- 实现本地进程间通信: 「本地字节流 socket 」类型是 AF_LOCAL 和 SOCK_STREAM,「本地数据报 socket 」类型是 AF_LOCAL 和 SOCK_DGRAM。另外,AF_UNIX 和 AF_LOCAL 是等价的,所以 AF_UNIX 也属于本地 socket;
接下来,简单说一下这三种通信的编程模式。
针对 TCP 协议通信的 socket 编程模型
- 服务端和客户端初始化
socket,得到文件描述符; - 服务端调用
bind,将绑定在 IP 地址和端口; - 服务端调用
listen,进行监听; - 服务端调用
accept,等待客户端连接; - 客户端调用
connect,向服务器端的地址和端口发起连接请求; - 服务端
accept返回用于传输的socket的文件描述符; - 客户端调用
write写入数据;服务端调用read读取数据; - 客户端断开连接时,会调用
close,那么服务端read读取数据的时候,就会读取到了EOF,待处理完数据后,服务端调用close,表示连接关闭。
这里需要注意的是,服务端调用 accept 时,连接成功了会返回一个已完成连接的 socket,后续用来传输数据。
所以,监听的 socket 和真正用来传送数据的 socket,是「两个」 socket,一个叫作监听 socket,一个叫作已完成连接 socket。
成功连接建立之后,双方开始通过 read 和 write 函数来读写数据,就像往一个文件流里面写东西一样。
针对 UDP 协议通信的 socket 编程模型
UDP 是没有连接的,所以不需要三次握手,也就不需要像 TCP 调用 listen 和 connect,但是 UDP 的交互仍然需要 IP 地址和端口号,因此也需要 bind。
对于 UDP 来说,不需要要维护连接,那么也就没有所谓的发送方和接收方,甚至都不存在客户端和服务端的概念,只要有一个 socket 多台机器就可以任意通信,因此每一个 UDP 的 socket 都需要 bind。
另外,每次通信时,调用 sendto 和 recvfrom,都要传入目标主机的 IP 地址和端口。
针对本地进程间通信的 socket 编程模型
本地 socket 被用于在同一台主机上进程间通信的场景:
- 本地 socket 的编程接口和 IPv4 、IPv6 套接字编程接口是一致的,可以支持「字节流」和「数据报」两种协议;
- 本地 socket 的实现效率大大高于 IPv4 和 IPv6 的字节流、数据报 socket 实现;
对于本地字节流 socket,其 socket 类型是 AF_LOCAL 和 SOCK_STREAM。
对于本地数据报 socket,其 socket 类型是 AF_LOCAL 和 SOCK_DGRAM。
本地字节流 socket 和 本地数据报 socket 在 bind 的时候,不像 TCP 和 UDP 要绑定 IP 地址和端口,而是绑定一个本地文件,这也就是它们之间的最大区别。
总结
由于每个进程的用户空间都是独立的,不能相互访问,这时就需要借助内核空间来实现进程间通信,原因很简单,每个进程都是共享一个内核空间。
Linux 内核提供了不少进程间通信的方式,其中最简单的方式就是管道,管道分为「匿名管道」和「命名管道」。
匿名管道顾名思义,它没有名字标识,匿名管道是特殊文件只存在于内存,没有存在于文件系统中,shell 命令中的「|」竖线就是匿名管道,通信的数据是无格式的流并且大小受限,通信的方式是单向的,数据只能在一个方向上流动,如果要双向通信,需要创建两个管道,再来匿名管道是只能用于存在父子关系的进程间通信,匿名管道的生命周期随着进程创建而建立,随着进程终止而消失。
命名管道突破了匿名管道只能在亲缘关系进程间的通信限制,因为使用命名管道的前提,需要在文件系统创建一个类型为 p 的设备文件,那么毫无关系的进程就可以通过这个设备文件进行通信。另外,不管是匿名管道还是命名管道,进程写入的数据都是缓存在内核中,另一个进程读取数据时候自然也是从内核中获取,同时通信数据都遵循先进先出原则,不支持 lseek 之类的文件定位操作。
消息队列克服了管道通信的数据是无格式的字节流的问题,消息队列实际上是保存在内核的「消息链表」,消息队列的消息体是可以用户自定义的数据类型,发送数据时,会被分成一个一个独立的消息体,当然接收数据时,也要与发送方发送的消息体的数据类型保持一致,这样才能保证读取的数据是正确的。消息队列通信的速度不是最及时的,毕竟每次数据的写入和读取都需要经过用户态与内核态之间的拷贝过程。
共享内存可以解决消息队列通信中用户态与内核态之间数据拷贝过程带来的开销,它直接分配一个共享空间,每个进程都可以直接访问,就像访问进程自己的空间一样快捷方便,不需要陷入内核态或者系统调用,大大提高了通信的速度,享有最快的进程间通信方式之名。但是便捷高效的共享内存通信,带来新的问题,多进程竞争同个共享资源会造成数据的错乱。
那么,就需要信号量来保护共享资源,以确保任何时刻只能有一个进程访问共享资源,这种方式就是互斥访问。信号量不仅可以实现访问的互斥性,还可以实现进程间的同步,信号量其实是一个计数器,表示的是资源个数,其值可以通过两个原子操作来控制,分别是 P 操作和 V 操作。
与信号量名字很相似的叫信号,它俩名字虽然相似,但功能一点儿都不一样。信号是异步通信机制,信号可以在应用进程和内核之间直接交互,内核也可以利用信号来通知用户空间的进程发生了哪些系统事件,信号事件的来源主要有硬件来源(如键盘 Cltr+C )和软件来源(如 kill 命令),一旦有信号发生,进程有三种方式响应信号 1. 执行默认操作、2. 捕捉信号、3. 忽略信号。有两个信号是应用进程无法捕捉和忽略的,即 SIGKILL 和 SIGSTOP,这是为了方便我们能在任何时候结束或停止某个进程。
前面说到的通信机制,都是工作于同一台主机,如果要与不同主机的进程间通信,那么就需要 Socket 通信了。Socket 实际上不仅用于不同的主机进程间通信,还可以用于本地主机进程间通信,可根据创建 Socket 的类型不同,分为三种常见的通信方式,一个是基于 TCP 协议的通信方式,一个是基于 UDP 协议的通信方式,一个是本地进程间通信方式。
以上,就是进程间通信的主要机制了。你可能会问了,那线程通信间的方式呢?
同个进程下的线程之间都是共享进程的资源,只要是共享变量都可以做到线程间通信,比如全局变量,所以对于线程间关注的不是通信方式,而是关注多线程竞争共享资源的问题,信号量也同样可以在线程间实现互斥与同步:
- 互斥的方式,可保证任意时刻只有一个线程访问共享资源;
- 同步的方式,可保证线程 A 应在线程 B 之前执行;
多线程冲突了怎么办?
对于共享资源,如果没有上锁,在多线程的环境里,那么就可能会发生翻车现场。
接下来,用 30+ 张图,带大家走进操作系统中避免多线程资源竞争的互斥、同步的方法。
竞争与协作
在单核 CPU 系统里,为了实现多个程序同时运行的假象,操作系统通常以时间片调度的方式,让每个进程执行每次执行一个时间片,时间片用完了,就切换下一个进程运行,由于这个时间片的时间很短,于是就造成了「并发」的现象。
另外,操作系统也为每个进程创建巨大、私有的虚拟内存的假象,这种地址空间的抽象让每个程序好像拥有自己的内存,而实际上操作系统在背后秘密地让多个地址空间「复用」物理内存或者磁盘。
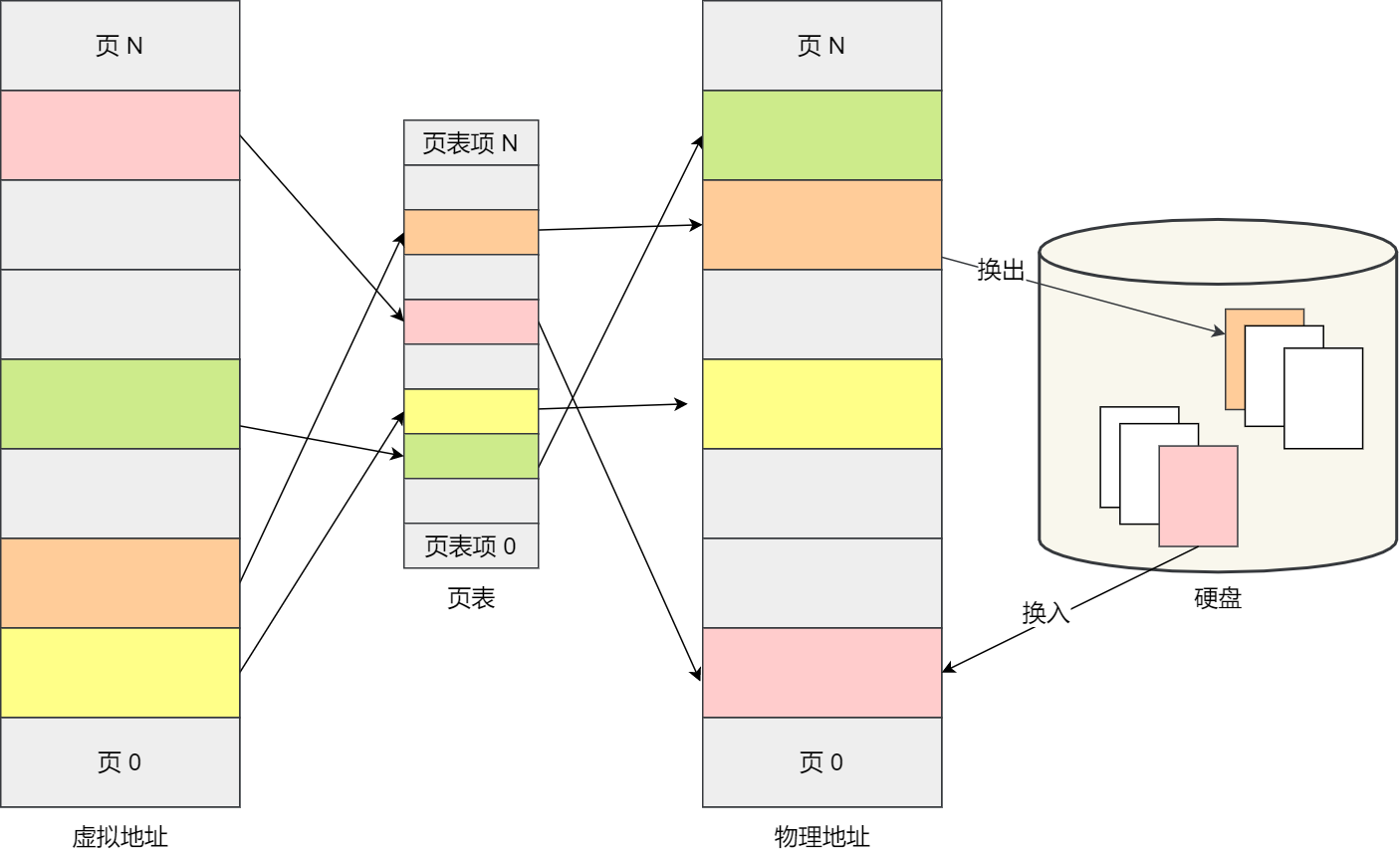
如果一个程序只有一个执行流程,也代表它是单线程的。当然一个程序可以有多个执行流程,也就是所谓的多线程程序,线程是调度的基本单位,进程则是资源分配的基本单位。
所以,线程之间是可以共享进程的资源,比如代码段、堆空间、数据段、打开的文件等资源,但每个线程都有自己独立的栈空间。
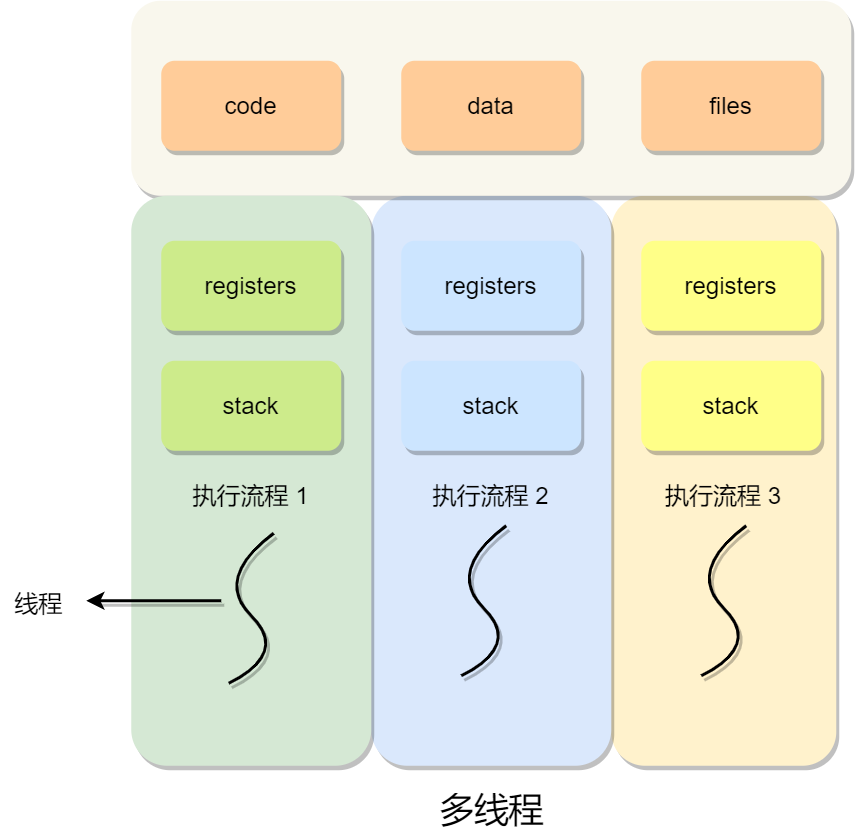
那么问题就来了,多个线程如果竞争共享资源,如果不采取有效的措施,则会造成共享数据的混乱。
我们做个小实验,创建两个线程,它们分别对共享变量 i 自增 1 执行 10000 次,如下代码(虽然说是 C++ 代码,但是没学过 C++ 的同学也是看到懂的):
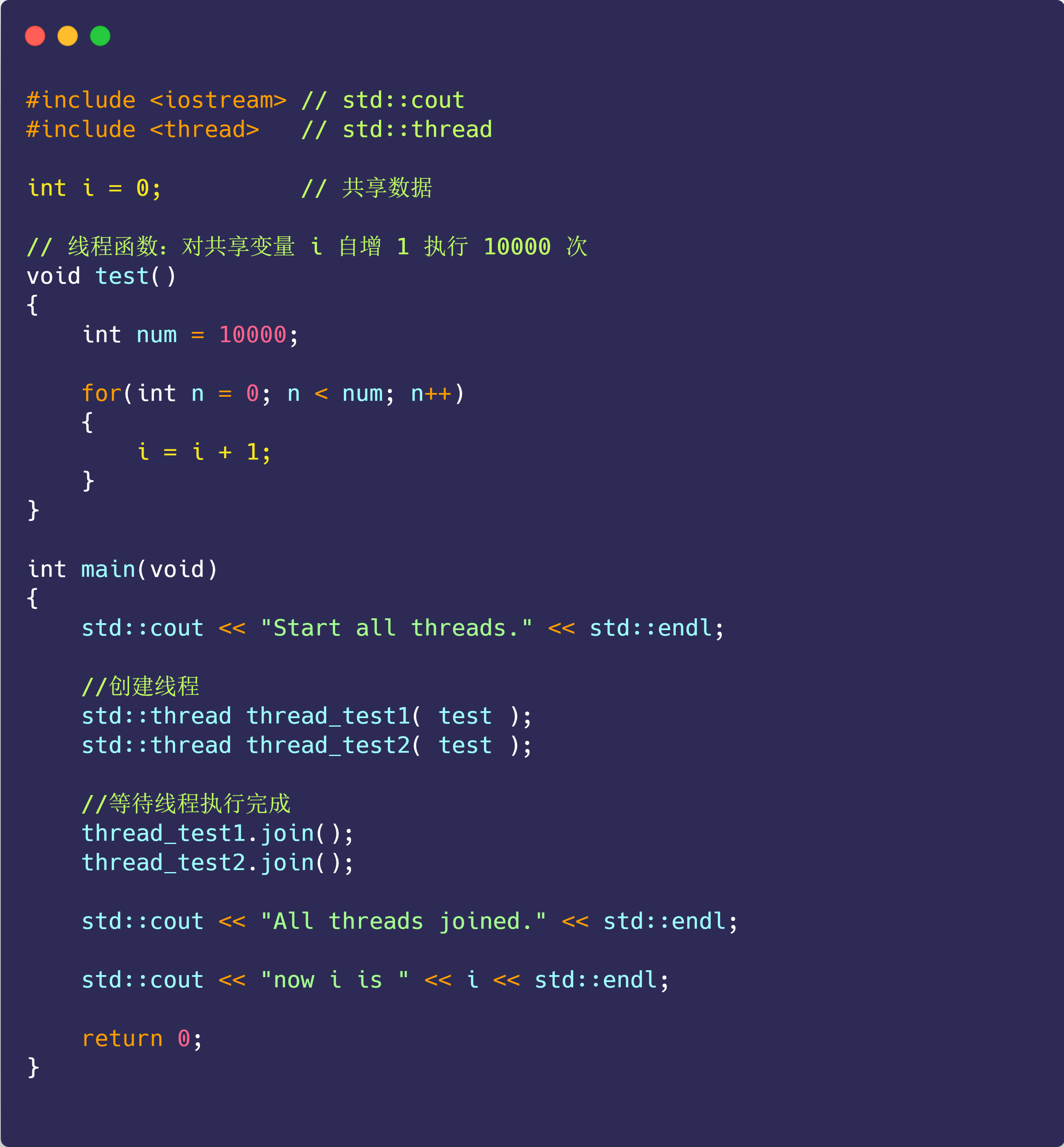
按理来说,i 变量最后的值应该是 20000,但很不幸,并不是如此。我们对上面的程序执行一下:

运行了两次,发现出现了 i 值的结果是 15173,也会出现 20000 的 i 值结果。
每次运行不但会产生错误,而且得到不同的结果。在计算机里是不能容忍的,虽然是小概率出现的错误,但是小概率事件它一定是会发生的,「墨菲定律」大家都懂吧。
为什么会发生这种情况?
为了理解为什么会发生这种情况,我们必须了解编译器为更新计数器 i 变量生成的代码序列,也就是要了解汇编指令的执行顺序。
在这个例子中,我们只是想给 i 加上数字 1,那么它对应的汇编指令执行过程是这样的:
可以发现,只是单纯给 i 加上数字 1,在 CPU 运行的时候,实际上要执行 3 条指令。
设想我们的线程 1 进入这个代码区域,它将 i 的值(假设此时是 50 )从内存加载到它的寄存器中,然后它向寄存器加 1,此时在寄存器中的 i 值是 51。
现在,一件不幸的事情发生了:时钟中断发生。因此,操作系统将当前正在运行的线程的状态保存到线程的线程控制块 TCB。
现在更糟的事情发生了,线程 2 被调度运行,并进入同一段代码。它也执行了第一条指令,从内存获取 i 值并将其放入到寄存器中,此时内存中 i 的值仍为 50,因此线程 2 寄存器中的 i 值也是 50。假设线程 2 执行接下来的两条指令,将寄存器中的 i 值 + 1,然后将寄存器中的 i 值保存到内存中,于是此时全局变量 i 值是 51。
最后,又发生一次上下文切换,线程 1 恢复执行。还记得它已经执行了两条汇编指令,现在准备执行最后一条指令。回忆一下, 线程 1 寄存器中的 i 值是51,因此,执行最后一条指令后,将值保存到内存,全局变量 i 的值再次被设置为 51。
简单来说,增加 i (值为 50 )的代码被运行两次,按理来说,最后的 i 值应该是 52,但是由于不可控的调度,导致最后 i 值却是 51。
针对上面线程 1 和线程 2 的执行过程,我画了一张流程图,会更明确一些:

互斥的概念
上面展示的情况称为竞争条件(*race condition*),当多线程相互竞争操作共享变量时,由于运气不好,即在执行过程中发生了上下文切换,我们得到了错误的结果,事实上,每次运行都可能得到不同的结果,因此输出的结果存在不确定性(*indeterminate*)。
由于多线程执行操作共享变量的这段代码可能会导致竞争状态,因此我们将此段代码称为临界区(*critical section*),它是访问共享资源的代码片段,一定不能给多线程同时执行。
我们希望这段代码是互斥(*mutualexclusion*)的,也就说保证一个线程在临界区执行时,其他线程应该被阻止进入临界区,说白了,就是这段代码执行过程中,最多只能出现一个线程。
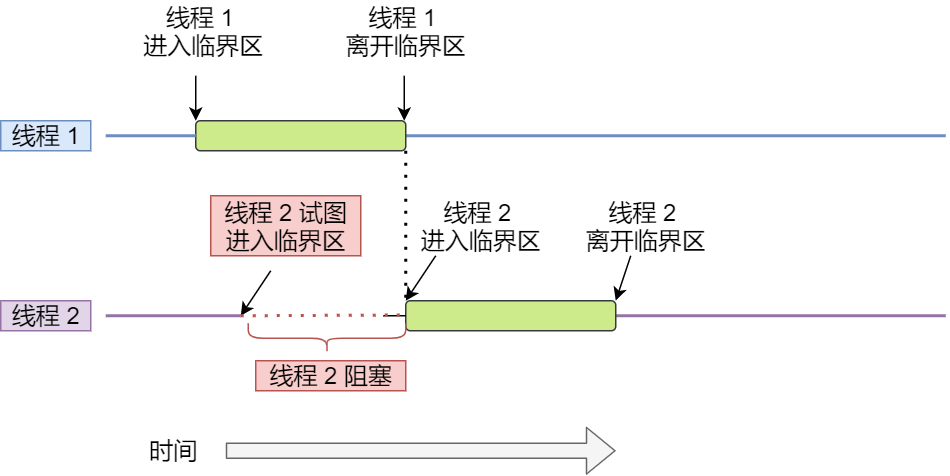
另外,说一下互斥也并不是只针对多线程。在多进程竞争共享资源的时候,也同样是可以使用互斥的方式来避免资源竞争造成的资源混乱。
同步的概念
互斥解决了并发进程/线程对临界区的使用问题。这种基于临界区控制的交互作用是比较简单的,只要一个进程/线程进入了临界区,其他试图想进入临界区的进程/线程都会被阻塞着,直到第一个进程/线程离开了临界区。
我们都知道在多线程里,每个线程并不一定是顺序执行的,它们基本是以各自独立的、不可预知的速度向前推进,但有时候我们又希望多个线程能密切合作,以实现一个共同的任务。
例子,线程 1 是负责读入数据的,而线程 2 是负责处理数据的,这两个线程是相互合作、相互依赖的。线程 2 在没有收到线程 1 的唤醒通知时,就会一直阻塞等待,当线程 1 读完数据需要把数据传给线程 2 时,线程 1 会唤醒线程 2,并把数据交给线程 2 处理。
所谓同步,就是并发进程/线程在一些关键点上可能需要互相等待与互通消息,这种相互制约的等待与互通信息称为进程/线程同步。
举个生活的同步例子,你肚子饿了想要吃饭,你叫妈妈早点做菜,妈妈听到后就开始做菜,但是在妈妈没有做完饭之前,你必须阻塞等待,等妈妈做完饭后,自然会通知你,接着你吃饭的事情就可以进行了。
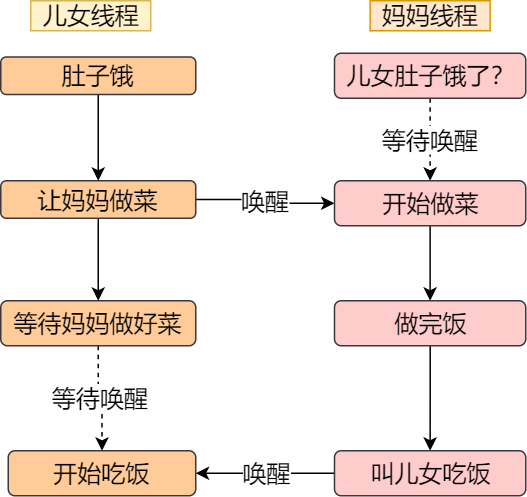
注意,同步与互斥是两种不同的概念:
- 同步就好比:「操作 A 应在操作 B 之前执行」,「操作 C 必须在操作 A 和操作 B 都完成之后才能执行」等;
- 互斥就好比:「操作 A 和操作 B 不能在同一时刻执行」;
互斥与同步的实现和使用
在进程/线程并发执行的过程中,进程/线程之间存在协作的关系,例如有互斥、同步的关系。
为了实现进程/线程间正确的协作,操作系统必须提供实现进程协作的措施和方法,主要的方法有两种:
- 锁:加锁、解锁操作;
- 信号量:P、V 操作;
这两个都可以方便地实现进程/线程互斥,而信号量比锁的功能更强一些,它还可以方便地实现进程/线程同步。
锁
使用加锁操作和解锁操作可以解决并发线程/进程的互斥问题。
任何想进入临界区的线程,必须先执行加锁操作。若加锁操作顺利通过,则线程可进入临界区;在完成对临界资源的访问后再执行解锁操作,以释放该临界资源。
根据锁的实现不同,可以分为「忙等待锁」和「无忙等待锁」。
我们先来看看「忙等待锁」的实现
在说明「忙等待锁」的实现之前,先介绍现代 CPU 体系结构提供的特殊原子操作指令 —— 测试和置位(*Test-and-Set*)指令。
如果用 C 代码表示 Test-and-Set 指令,形式如下:

测试并设置指令做了下述事情:
- 把
old_ptr更新为new的新值 - 返回
old_ptr的旧值;
当然,关键是这些代码是原子执行。因为既可以测试旧值,又可以设置新值,所以我们把这条指令叫作「测试并设置」。
那什么是原子操作呢?原子操作就是要么全部执行,要么都不执行,不能出现执行到一半的中间状态
我们可以运用 Test-and-Set 指令来实现「忙等待锁」,代码如下:

我们来确保理解为什么这个锁能工作:
- 第一个场景是,首先假设一个线程在运行,调用
lock(),没有其他线程持有锁,所以flag是 0。当调用TestAndSet(flag, 1)方法,返回 0,线程会跳出 while 循环,获取锁。同时也会原子的设置 flag 为1,标志锁已经被持有。当线程离开临界区,调用unlock()将flag清理为 0。 - 第二种场景是,当某一个线程已经持有锁(即
flag为1)。本线程调用lock(),然后调用TestAndSet(flag, 1),这一次返回 1。只要另一个线程一直持有锁,TestAndSet()会重复返回 1,本线程会一直忙等。当flag终于被改为 0,本线程会调用TestAndSet(),返回 0 并且原子地设置为 1,从而获得锁,进入临界区。
很明显,当获取不到锁时,线程就会一直 while 循环,不做任何事情,所以就被称为「忙等待锁」,也被称为自旋锁(*spin lock*)。
这是最简单的一种锁,一直自旋,利用 CPU 周期,直到锁可用。在单处理器上,需要抢占式的调度器(即不断通过时钟中断一个线程,运行其他线程)。否则,自旋锁在单 CPU 上无法使用,因为一个自旋的线程永远不会放弃 CPU。
再来看看「无等待锁」的实现
无等待锁顾明思议就是获取不到锁的时候,不用自旋。
既然不想自旋,那当没获取到锁的时候,就把当前线程放入到锁的等待队列,然后执行调度程序,把 CPU 让给其他线程执行。
本次只是提出了两种简单锁的实现方式。当然,在具体操作系统实现中,会更复杂,但也离不开本例子两个基本元素。
如果你想要对锁的更进一步理解,推荐大家可以看《操作系统导论》第 28 章锁的内容,这本书在「微信读书」就可以免费看。
信号量
信号量是操作系统提供的一种协调共享资源访问的方法。
通常信号量表示资源的数量,对应的变量是一个整型(sem)变量。
另外,还有两个原子操作的系统调用函数来控制信号量的,分别是:
- P 操作:将
sem减1,相减后,如果sem < 0,则进程/线程进入阻塞等待,否则继续,表明 P 操作可能会阻塞; - V 操作:将
sem加1,相加后,如果sem <= 0,唤醒一个等待中的进程/线程,表明 V 操作不会阻塞;
TIP
很多人问,V 操作 中 sem <= 0 的判断是不是写反了?
没写反,我举个例子,如果 sem = 1,有三个线程进行了 P 操作:
- 第一个线程 P 操作后,sem = 0;
- 第二个线程 P 操作后,sem = -1;
- 第三个线程 P 操作后,sem = -2;
这时,第一个线程执行 V 操作后, sem 是 -1,因为 sem <= 0,所以要唤醒第二或第三个线程。
P 操作是用在进入临界区之前,V 操作是用在离开临界区之后,这两个操作是必须成对出现的。
举个类比,2 个资源的信号量,相当于 2 条火车轨道,PV 操作如下图过程:
操作系统是如何实现 PV 操作的呢?
信号量数据结构与 PV 操作的算法描述如下图:

PV 操作的函数是由操作系统管理和实现的,所以操作系统已经使得执行 PV 函数时是具有原子性的。
PV 操作如何使用的呢?
信号量不仅可以实现临界区的互斥访问控制,还可以线程间的事件同步。
我们先来说说如何使用信号量实现临界区的互斥访问。
为每类共享资源设置一个信号量 s,其初值为 1,表示该临界资源未被占用。
只要把进入临界区的操作置于 P(s) 和 V(s) 之间,即可实现进程/线程互斥:
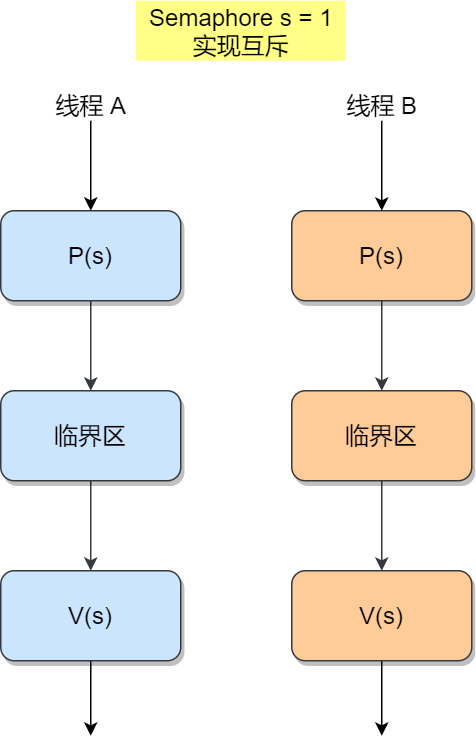
此时,任何想进入临界区的线程,必先在互斥信号量上执行 P 操作,在完成对临界资源的访问后再执行 V 操作。由于互斥信号量的初始值为 1,故在第一个线程执行 P 操作后 s 值变为 0,表示临界资源为空闲,可分配给该线程,使之进入临界区。
若此时又有第二个线程想进入临界区,也应先执行 P 操作,结果使 s 变为负值,这就意味着临界资源已被占用,因此,第二个线程被阻塞。
并且,直到第一个线程执行 V 操作,释放临界资源而恢复 s 值为 0 后,才唤醒第二个线程,使之进入临界区,待它完成临界资源的访问后,又执行 V 操作,使 s 恢复到初始值 1。
对于两个并发线程,互斥信号量的值仅取 1、0 和 -1 三个值,分别表示:
- 如果互斥信号量为 1,表示没有线程进入临界区;
- 如果互斥信号量为 0,表示有一个线程进入临界区;
- 如果互斥信号量为 -1,表示一个线程进入临界区,另一个线程等待进入。
通过互斥信号量的方式,就能保证临界区任何时刻只有一个线程在执行,就达到了互斥的效果。
再来,我们说说如何使用信号量实现事件同步。
同步的方式是设置一个信号量,其初值为 0。
我们把前面的「吃饭-做饭」同步的例子,用代码的方式实现一下:

妈妈一开始询问儿子要不要做饭时,执行的是 P(s1) ,相当于询问儿子需不需要吃饭,由于 s1 初始值为 0,此时 s1 变成 -1,表明儿子不需要吃饭,所以妈妈线程就进入等待状态。
当儿子肚子饿时,执行了 V(s1),使得 s1 信号量从 -1 变成 0,表明此时儿子需要吃饭了,于是就唤醒了阻塞中的妈妈线程,妈妈线程就开始做饭。
接着,儿子线程执行了 P(s2),相当于询问妈妈饭做完了吗,由于 s2 初始值是 0,则此时 s2 变成 -1,说明妈妈还没做完饭,儿子线程就等待状态。
最后,妈妈终于做完饭了,于是执行 V(s2),s2 信号量从 -1 变回了 0,于是就唤醒等待中的儿子线程,唤醒后,儿子线程就可以进行吃饭了。
生产者-消费者问题

生产者-消费者问题描述:
- 生产者在生成数据后,放在一个缓冲区中;
- 消费者从缓冲区取出数据处理;
- 任何时刻,只能有一个生产者或消费者可以访问缓冲区;
我们对问题分析可以得出:
- 任何时刻只能有一个线程操作缓冲区,说明操作缓冲区是临界代码,需要互斥;
- 缓冲区空时,消费者必须等待生产者生成数据;缓冲区满时,生产者必须等待消费者取出数据。说明生产者和消费者需要同步。
那么我们需要三个信号量,分别是:
- 互斥信号量
mutex:用于互斥访问缓冲区,初始化值为 1; - 资源信号量
fullBuffers:用于消费者询问缓冲区是否有数据,有数据则读取数据,初始化值为 0(表明缓冲区一开始为空); - 资源信号量
emptyBuffers:用于生产者询问缓冲区是否有空位,有空位则生成数据,初始化值为 n (缓冲区大小);
具体的实现代码:

如果消费者线程一开始执行 P(fullBuffers),由于信号量 fullBuffers 初始值为 0,则此时 fullBuffers 的值从 0 变为 -1,说明缓冲区里没有数据,消费者只能等待。
接着,轮到生产者执行 P(emptyBuffers),表示减少 1 个空槽,如果当前没有其他生产者线程在临界区执行代码,那么该生产者线程就可以把数据放到缓冲区,放完后,执行 V(fullBuffers) ,信号量 fullBuffers 从 -1 变成 0,表明有「消费者」线程正在阻塞等待数据,于是阻塞等待的消费者线程会被唤醒。
消费者线程被唤醒后,如果此时没有其他消费者线程在读数据,那么就可以直接进入临界区,从缓冲区读取数据。最后,离开临界区后,把空槽的个数 + 1。
经典同步问题
哲学家就餐问题
当初我在校招的时候,面试官也问过「哲学家就餐」这道题目,我当时听的一脸懵逼,无论面试官怎么讲述这个问题,我也始终没听懂,就莫名其妙的说这个问题会「死锁」。
当然,我这回答槽透了,所以当场 game over,残酷又悲惨故事,就不多说了,反正当时菜就是菜。
时至今日,看我来图解这道题。
先来看看哲学家就餐的问题描述:
5个老大哥哲学家,闲着没事做,围绕着一张圆桌吃面;- 巧就巧在,这个桌子只有
5支叉子,每两个哲学家之间放一支叉子; - 哲学家围在一起先思考,思考中途饿了就会想进餐;
- 奇葩的是,这些哲学家要两支叉子才愿意吃面,也就是需要拿到左右两边的叉子才进餐;
- 吃完后,会把两支叉子放回原处,继续思考;
那么问题来了,如何保证哲 学家们的动作有序进行,而不会出现有人永远拿不到叉子呢?
方案一
我们用信号量的方式,也就是 PV 操作来尝试解决它,代码如下:

上面的程序,好似很自然。拿起叉子用 P 操作,代表有叉子就直接用,没有叉子时就等待其他哲学家放回叉子。
不过,这种解法存在一个极端的问题:假设五位哲学家同时拿起左边的叉子,桌面上就没有叉子了, 这样就没有人能够拿到他们右边的叉子,也就说每一位哲学家都会在 P(fork[(i + 1) % N ]) 这条语句阻塞了,很明显这发生了死锁的现象。
方案二
既然「方案一」会发生同时竞争左边叉子导致死锁的现象,那么我们就在拿叉子前,加个互斥信号量,代码如下:

上面程序中的互斥信号量的作用就在于,只要有一个哲学家进入了「临界区」,也就是准备要拿叉子时,其他哲学家都不能动,只有这位哲学家用完叉子了,才能轮到下一个哲学家进餐。
方案二虽然能让哲学家们按顺序吃饭,但是每次进餐只能有一位哲学家,而桌面上是有 5 把叉子,按道理是能可以有两个哲学家同时进餐的,所以从效率角度上,这不是最好的解决方案。
方案三
那既然方案二使用互斥信号量,会导致只能允许一个哲学家就餐,那么我们就不用它。
另外,方案一的问题在于,会出现所有哲学家同时拿左边刀叉的可能性,那我们就避免哲学家可以同时拿左边的刀叉,采用分支结构,根据哲学家的编号的不同,而采取不同的动作。
即让偶数编号的哲学家「先拿左边的叉子后拿右边的叉子」,奇数编号的哲学家「先拿右边的叉子后拿左边的叉子」。
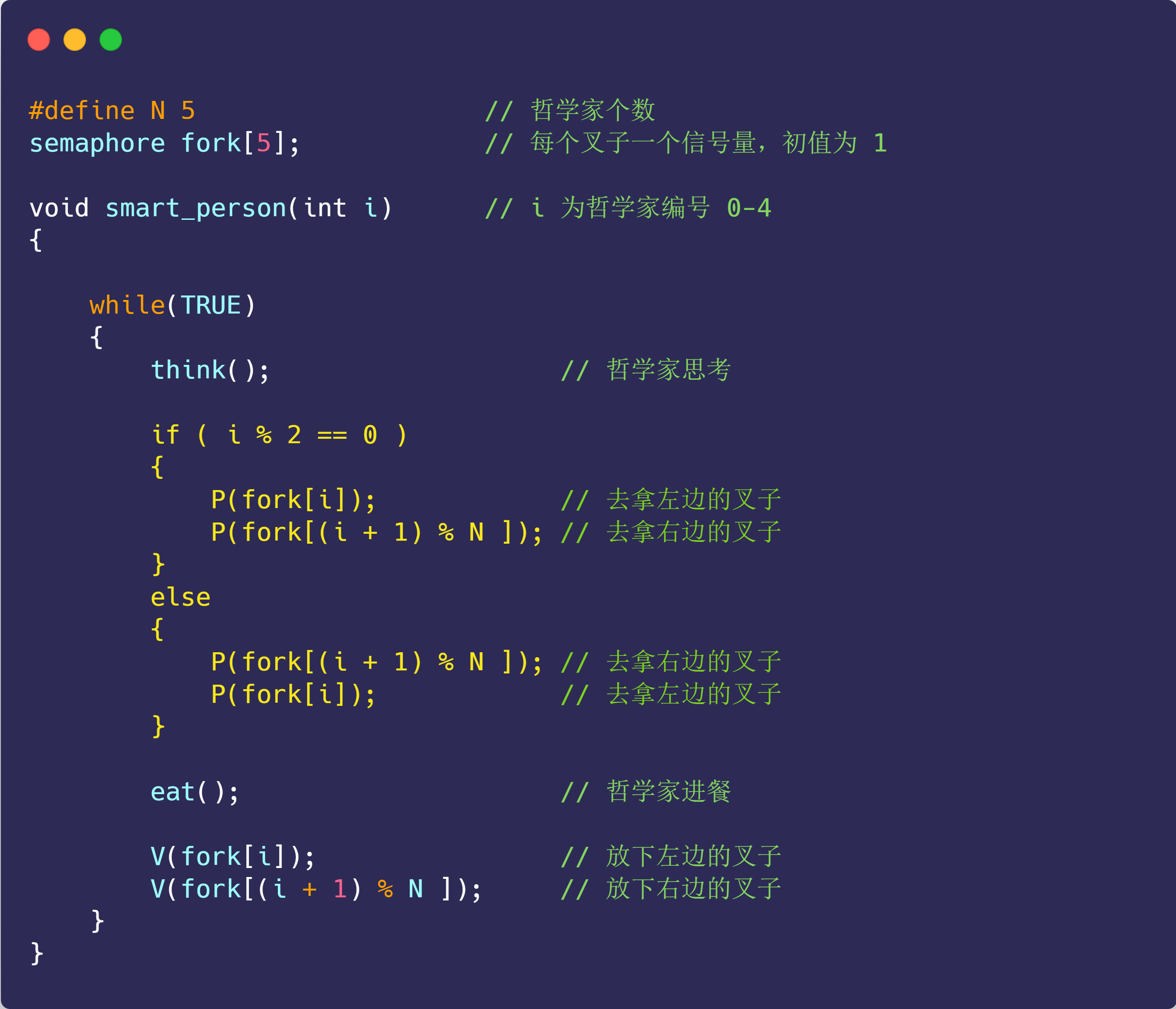
上面的程序,在 P 操作时,根据哲学家的编号不同,拿起左右两边叉子的顺序不同。另外,V 操作是不需要分支的,因为 V 操作是不会阻塞的。
方案三即不会出现死锁,也可以两人同时进餐。
方案四
在这里再提出另外一种可行的解决方案,我们用一个数组 state 来记录每一位哲学家的三个状态,分别是在进餐状态、思考状态、饥饿状态(正在试图拿叉子)。
那么,一个哲学家只有在两个邻居都没有进餐时,才可以进入进餐状态。
第 i 个哲学家的左邻右舍,则由宏 LEFT 和 RIGHT 定义:
- LEFT : ( i + 5 - 1 ) % 5
- RIGHT : ( i + 1 ) % 5
比如 i 为 2,则 LEFT 为 1,RIGHT 为 3。
具体代码实现如下:
上面的程序使用了一个信号量数组,每个信号量对应一位哲学家,这样在所需的叉子被占用时,想进餐的哲学家就被阻塞。
注意,每个进程/线程将 smart_person 函数作为主代码运行,而其他 take_forks、put_forks 和 test 只是普通的函数,而非单独的进程/线程。
方案四同样不会出现死锁,也可以两人同时进餐。
读者-写者问题
前面的「哲学家进餐问题」对于互斥访问有限的竞争问题(如 I/O 设备)一类的建模过程十分有用。
另外,还有个著名的问题是「读者-写者」,它为数据库访问建立了一个模型。
读者只会读取数据,不会修改数据,而写者即可以读也可以修改数据。
读者-写者的问题描述:
- 「读-读」允许:同一时刻,允许多个读者同时读
- 「读-写」互斥:没有写者时读者才能读,没有读者时写者才能写
- 「写-写」互斥:没有其他写者时,写者才能写
接下来,提出几个解决方案来分析分析。
方案一
使用信号量的方式来尝试解决:
- 信号量
wMutex:控制写操作的互斥信号量,初始值为 1 ; - 读者计数
rCount:正在进行读操作的读者个数,初始化为 0; - 信号量
rCountMutex:控制对 rCount 读者计数器的互斥修改,初始值为 1;
接下来看看代码的实现:

上面的这种实现,是读者优先的策略,因为只要有读者正在读的状态,后来的读者都可以直接进入,如果读者持续不断进入,则写者会处于饥饿状态。
方案二
那既然有读者优先策略,自然也有写者优先策略:
- 只要有写者准备要写入,写者应尽快执行写操作,后来的读者就必须阻塞;
- 如果有写者持续不断写入,则读者就处于饥饿;
在方案一的基础上新增如下变量:
- 信号量
rMutex:控制读者进入的互斥信号量,初始值为 1; - 信号量
wDataMutex:控制写者写操作的互斥信号量,初始值为 1; - 写者计数
wCount:记录写者数量,初始值为 0; - 信号量
wCountMutex:控制 wCount 互斥修改,初始值为 1;
具体实现如下代码:
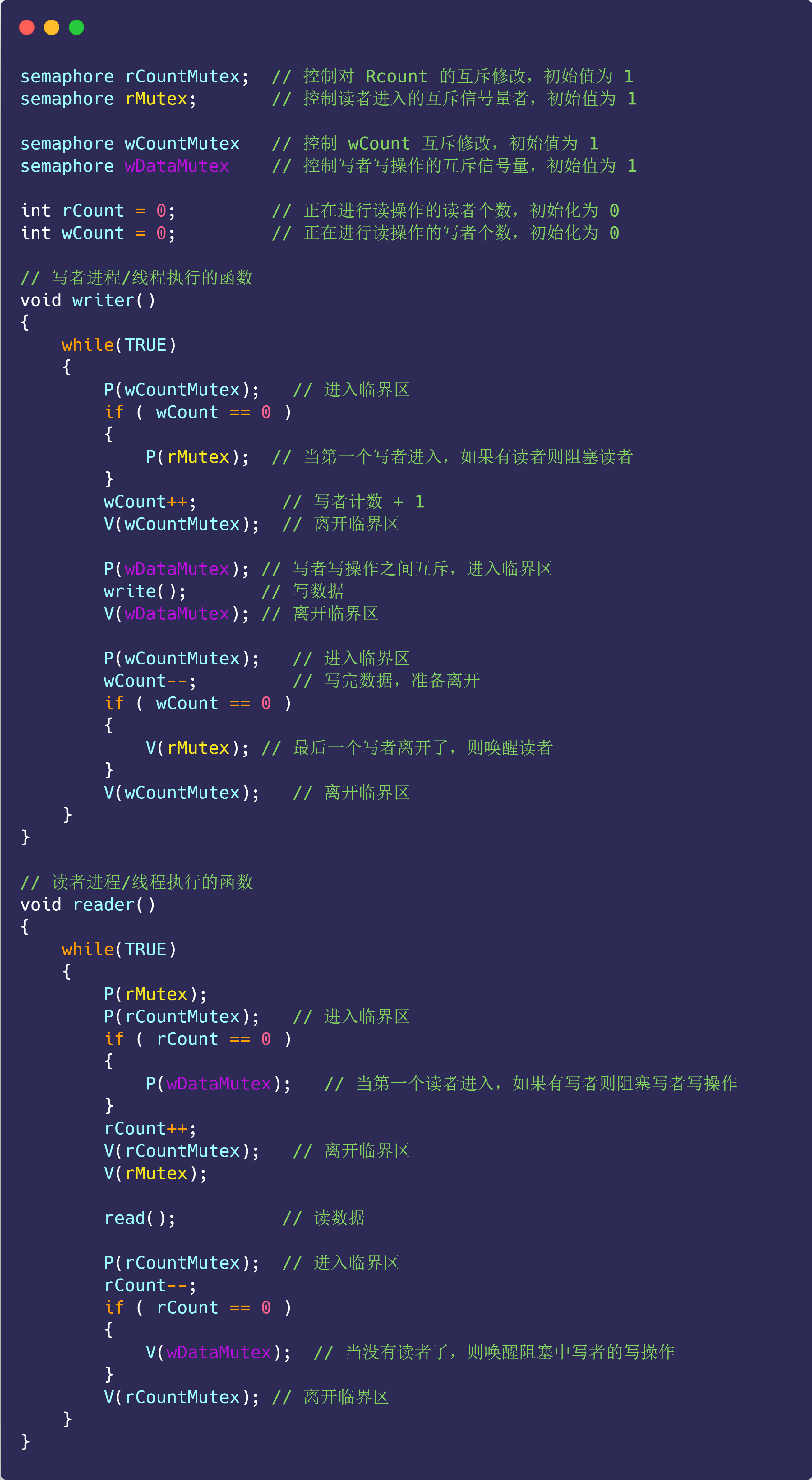
注意,这里 rMutex 的作用,开始有多个读者读数据,它们全部进入读者队列,此时来了一个写者,执行了 P(rMutex) 之后,后续的读者由于阻塞在 rMutex 上,都不能再进入读者队列,而写者到来,则可以全部进入写者队列,因此保证了写者优先。
同时,第一个写者执行了 P(rMutex) 之后,也不能马上开始写,必须等到所有进入读者队列的读者都执行完读操作,通过 V(wDataMutex) 唤醒写者的写操作。
方案三
既然读者优先策略和写者优先策略都会造成饥饿的现象,那么我们就来实现一下公平策略。
公平策略:
- 优先级相同;
- 写者、读者互斥访问;
- 只能一个写者访问临界区;
- 可以有多个读者同时访问临界资源;
具体代码实现:
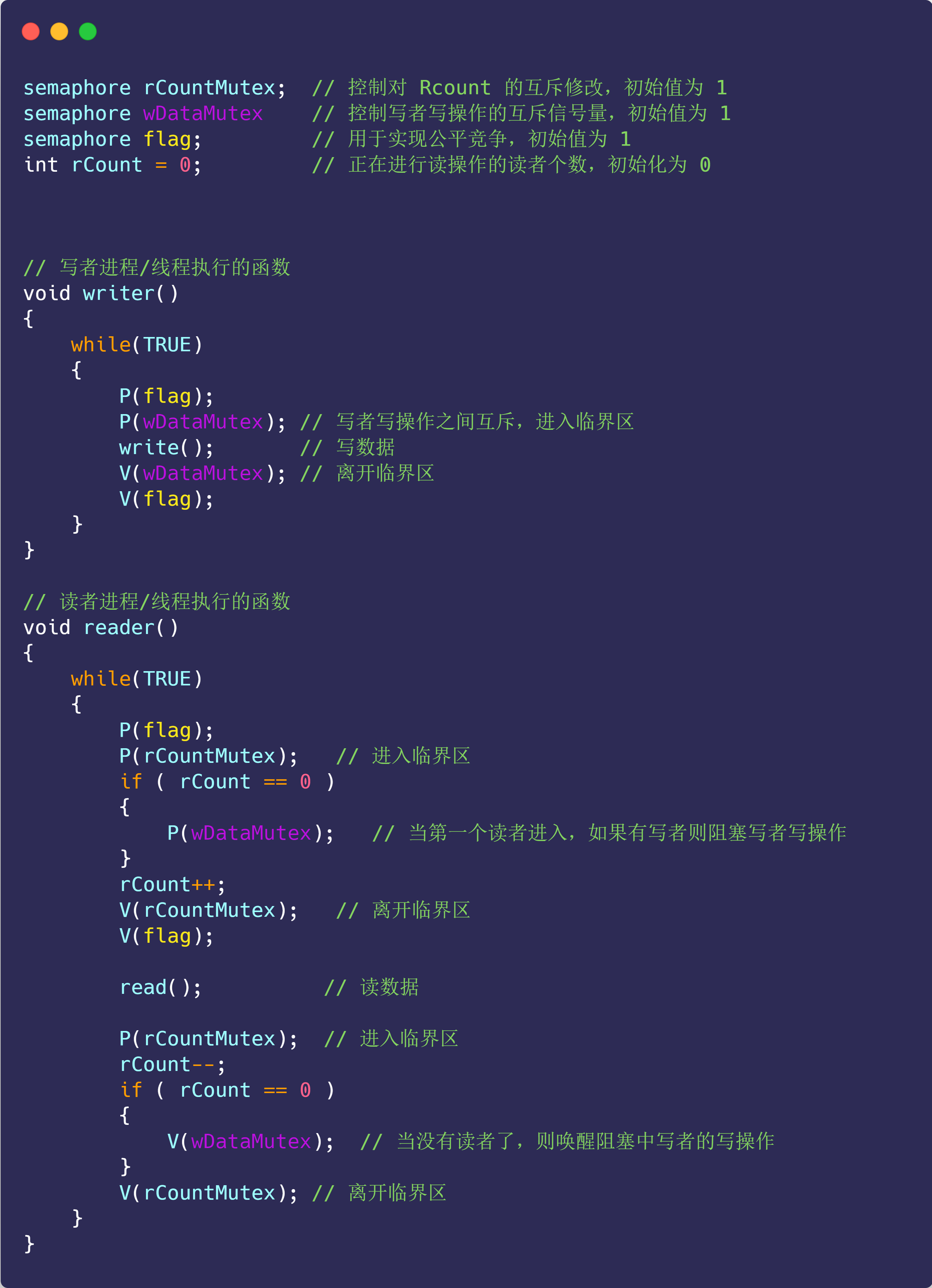
看完代码不知你是否有这样的疑问,为什么加了一个信号量 flag,就实现了公平竞争?
对比方案一的读者优先策略,可以发现,读者优先中只要后续有读者到达,读者就可以进入读者队列, 而写者必须等待,直到没有读者到达。
没有读者到达会导致读者队列为空,即 rCount==0,此时写者才可以进入临界区执行写操作。
而这里 flag 的作用就是阻止读者的这种特殊权限(特殊权限是只要读者到达,就可以进入读者队列)。
比如:开始来了一些读者读数据,它们全部进入读者队列,此时来了一个写者,执行 P(falg) 操作,使得后续到来的读者都阻塞在 flag 上,不能进入读者队列,这会使得读者队列逐渐为空,即 rCount 减为 0。
这个写者也不能立马开始写(因为此时读者队列不为空),会阻塞在信号量 wDataMutex 上,读者队列中的读者全部读取结束后,最后一个读者进程执行 V(wDataMutex),唤醒刚才的写者,写者则继续开始进行写操作。
怎么避免死锁?
面试过程中,死锁也是高频的考点,因为如果线上环境真多发生了死锁,那真的出大事了。
这次,我们就来系统地聊聊死锁的问题。
- 死锁的概念;
- 模拟死锁问题的产生;
- 利用工具排查死锁问题;
- 避免死锁问题的发生;
死锁的概念
在多线程编程中,我们为了防止多线程竞争共享资源而导致数据错乱,都会在操作共享资源之前加上互斥锁,只有成功获得到锁的线程,才能操作共享资源,获取不到锁的线程就只能等待,直到锁被释放。
那么,当两个线程为了保护两个不同的共享资源而使用了两个互斥锁,那么这两个互斥锁应用不当的时候,可能会造成两个线程都在等待对方释放锁,在没有外力的作用下,这些线程会一直相互等待,就没办法继续运行,这种情况就是发生了死锁。
举个例子,小林拿了小美房间的钥匙,而小林在自己的房间里,小美拿了小林房间的钥匙,而小美也在自己的房间里。如果小林要从自己的房间里出去,必须拿到小美手中的钥匙,但是小美要出去,又必须拿到小林手中的钥匙,这就形成了死锁。
死锁只有同时满足以下四个条件才会发生:
- 互斥条件;
- 持有并等待条件;
- 不可剥夺条件;
- 环路等待条件;
互斥条件
互斥条件是指多个线程不能同时使用同一个资源。
比如下图,如果线程 A 已经持有的资源,不能再同时被线程 B 持有,如果线程 B 请求获取线程 A 已经占用的资源,那线程 B 只能等待,直到线程 A 释放了资源。
持有并等待条件
持有并等待条件是指,当线程 A 已经持有了资源 1,又想申请资源 2,而资源 2 已经被线程 C 持有了,所以线程 A 就会处于等待状态,但是线程 A 在等待资源 2 的同时并不会释放自己已经持有的资源 1。
不可剥夺条件
不可剥夺条件是指,当线程已经持有了资源 ,在自己使用完之前不能被其他线程获取,线程 B 如果也想使用此资源,则只能在线程 A 使用完并释放后才能获取。
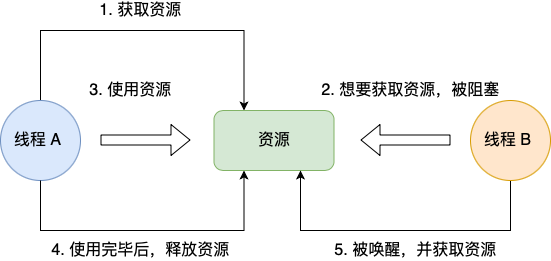
环路等待条件
环路等待条件指的是,在死锁发生的时候,两个线程获取资源的顺序构成了环形链。
比如,线程 A 已经持有资源 2,而想请求资源 1, 线程 B 已经获取了资源 1,而想请求资源 2,这就形成资源请求等待的环形图。
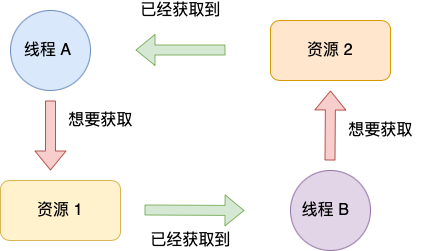
模拟死锁问题的产生
Talk is cheap. Show me the code.
下面,我们用代码来模拟死锁问题的产生。
首先,我们先创建 2 个线程,分别为线程 A 和 线程 B,然后有两个互斥锁,分别是 mutex_A 和 mutex_B,代码如下:
|
|
接下来,我们看下线程 A 函数做了什么。
|
|
可以看到,线程 A 函数的过程:
- 先获取互斥锁 A,然后睡眠 1 秒;
- 再获取互斥锁 B,然后释放互斥锁 B;
- 最后释放互斥锁 A;
|
|
可以看到,线程 B 函数的过程:
- 先获取互斥锁 B,然后睡眠 1 秒;
- 再获取互斥锁 A,然后释放互斥锁 A;
- 最后释放互斥锁 B;
然后,我们运行这个程序,运行结果如下:
|
|
可以看到线程 B 在等待互斥锁 A 的释放,线程 A 在等待互斥锁 B 的释放,双方都在等待对方资源的释放,很明显,产生了死锁问题。
利用工具排查死锁问题
如果你想排查你的 Java 程序是否死锁,则可以使用 jstack 工具,它是 jdk 自带的线程堆栈分析工具。
由于小林的死锁代码例子是 C 写的,在 Linux 下,我们可以使用 pstack + gdb 工具来定位死锁问题。
pstack 命令可以显示每个线程的栈跟踪信息(函数调用过程),它的使用方式也很简单,只需要 pstack <pid> 就可以了。
那么,在定位死锁问题时,我们可以多次执行 pstack 命令查看线程的函数调用过程,多次对比结果,确认哪几个线程一直没有变化,且是因为在等待锁,那么大概率是由于死锁问题导致的。
我用 pstack 输出了我前面模拟死锁问题的进程的所有线程的情况,我多次执行命令后,其结果都一样,如下:
|
|
可以看到,Thread 2 和 Thread 3 一直阻塞获取锁(pthread_mutex_lock)的过程,而且 pstack 多次输出信息都没有变化,那么可能大概率发生了死锁。
但是,还不能够确认这两个线程是在互相等待对方的锁的释放,因为我们看不到它们是等在哪个锁对象,于是我们可以使用 gdb 工具进一步确认。
整个 gdb 调试过程,如下:
|
|
我来解释下,上面的调试过程:
- 通过
info thread打印了所有的线程信息,可以看到有 3 个线程,一个是主线程(LWP 87746),另外两个都是我们自己创建的线程(LWP 87747 和 87748); - 通过
thread 2,将切换到第 2 个线程(LWP 87748); - 通过
bt,打印线程的调用栈信息,可以看到有 threadB_proc 函数,说明这个是线程 B 函数,也就说 LWP 87748 是线程 B; - 通过
frame 3,打印调用栈中的第三个帧的信息,可以看到线程 B 函数,在获取互斥锁 A 的时候阻塞了; - 通过
p mutex_A,打印互斥锁 A 对象信息,可以看到它被 LWP 为 87747(线程 A) 的线程持有着; - 通过
p mutex_B,打印互斥锁 B 对象信息,可以看到他被 LWP 为 87748 (线程 B) 的线程持有着;
因为线程 B 在等待线程 A 所持有的 mutex_A, 而同时线程 A 又在等待线程 B 所拥有的mutex_B, 所以可以断定该程序发生了死锁。
避免死锁问题的发生
前面我们提到,产生死锁的四个必要条件是:互斥条件、持有并等待条件、不可剥夺条件、环路等待条件。
那么避免死锁问题就只需要破环其中一个条件就可以,最常见的并且可行的就是使用资源有序分配法,来破环环路等待条件。
那什么是资源有序分配法呢?
线程 A 和 线程 B 获取资源的顺序要一样,当线程 A 是先尝试获取资源 A,然后尝试获取资源 B 的时候,线程 B 同样也是先尝试获取资源 A,然后尝试获取资源 B。也就是说,线程 A 和 线程 B 总是以相同的顺序申请自己想要的资源。
我们使用资源有序分配法的方式来修改前面发生死锁的代码,我们可以不改动线程 A 的代码。
我们先要清楚线程 A 获取资源的顺序,它是先获取互斥锁 A,然后获取互斥锁 B。
所以我们只需将线程 B 改成以相同顺序的获取资源,就可以打破死锁了。
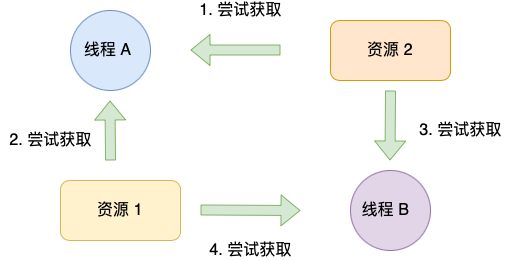
线程 B 函数改进后的代码如下:
|
|
执行结果如下,可以看,没有发生死锁。
|
|
总结
简单来说,死锁问题的产生是由两个或者以上线程并行执行的时候,争夺资源而互相等待造成的。
死锁只有同时满足互斥、持有并等待、不可剥夺、环路等待这四个条件的时候才会发生。
所以要避免死锁问题,就是要破坏其中一个条件即可,最常用的方法就是使用资源有序分配法来破坏环路等待条件。
什么是悲观锁、乐观锁?
在编程世界里,「锁」是五花八门,多种多样,每种锁的加锁开销以及应用场景也可能会不同。
如何用好锁,也是程序员的基本素养之一了。
高并发的场景下,如果选对了合适的锁,则会大大提高系统的性能,否则性能会降低。
所以,知道各种锁的开销,以及应用场景是很有必要的。
接下来,就谈一谈常见的这几种锁:
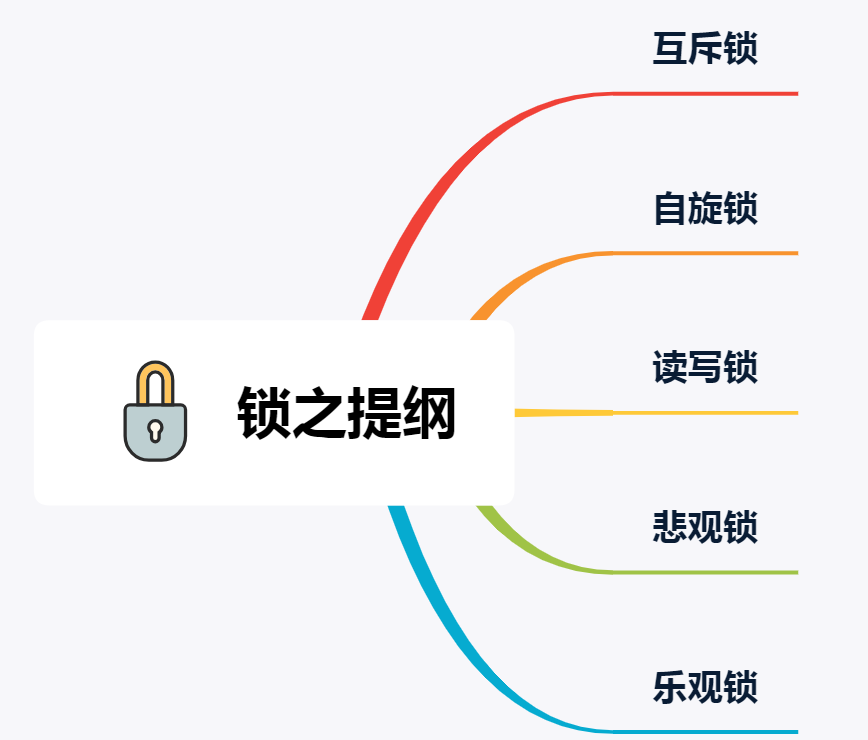
多线程访问共享资源的时候,避免不了资源竞争而导致数据错乱的问题,所以我们通常为了解决这一问题,都会在访问共享资源之前加锁。
最常用的就是互斥锁,当然还有很多种不同的锁,比如自旋锁、读写锁、乐观锁等,不同种类的锁自然适用于不同的场景。
如果选择了错误的锁,那么在一些高并发的场景下,可能会降低系统的性能,这样用户体验就会非常差了。
所以,为了选择合适的锁,我们不仅需要清楚知道加锁的成本开销有多大,还需要分析业务场景中访问的共享资源的方式,再来还要考虑并发访问共享资源时的冲突概率。
对症下药,才能减少锁对高并发性能的影响。
那接下来,针对不同的应用场景,谈一谈「互斥锁、自旋锁、读写锁、乐观锁、悲观锁」的选择和使用。
互斥锁与自旋锁
最底层的两种就是会「互斥锁和自旋锁」,有很多高级的锁都是基于它们实现的,你可以认为它们是各种锁的地基,所以我们必须清楚它俩之间的区别和应用。
加锁的目的就是保证共享资源在任意时间里,只有一个线程访问,这样就可以避免多线程导致共享数据错乱的问题。
当已经有一个线程加锁后,其他线程加锁则就会失败,互斥锁和自旋锁对于加锁失败后的处理方式是不一样的:
- 互斥锁加锁失败后,线程会释放 CPU ,给其他线程;
- 自旋锁加锁失败后,线程会忙等待,直到它拿到锁;
互斥锁是一种「独占锁」,比如当线程 A 加锁成功后,此时互斥锁已经被线程 A 独占了,只要线程 A 没有释放手中的锁,线程 B 加锁就会失败,于是就会释放 CPU 让给其他线程,既然线程 B 释放掉了 CPU,自然线程 B 加锁的代码就会被阻塞。
对于互斥锁加锁失败而阻塞的现象,是由操作系统内核实现的。当加锁失败时,内核会将线程置为「睡眠」状态,等到锁被释放后,内核会在合适的时机唤醒线程,当这个线程成功获取到锁后,于是就可以继续执行。如下图:
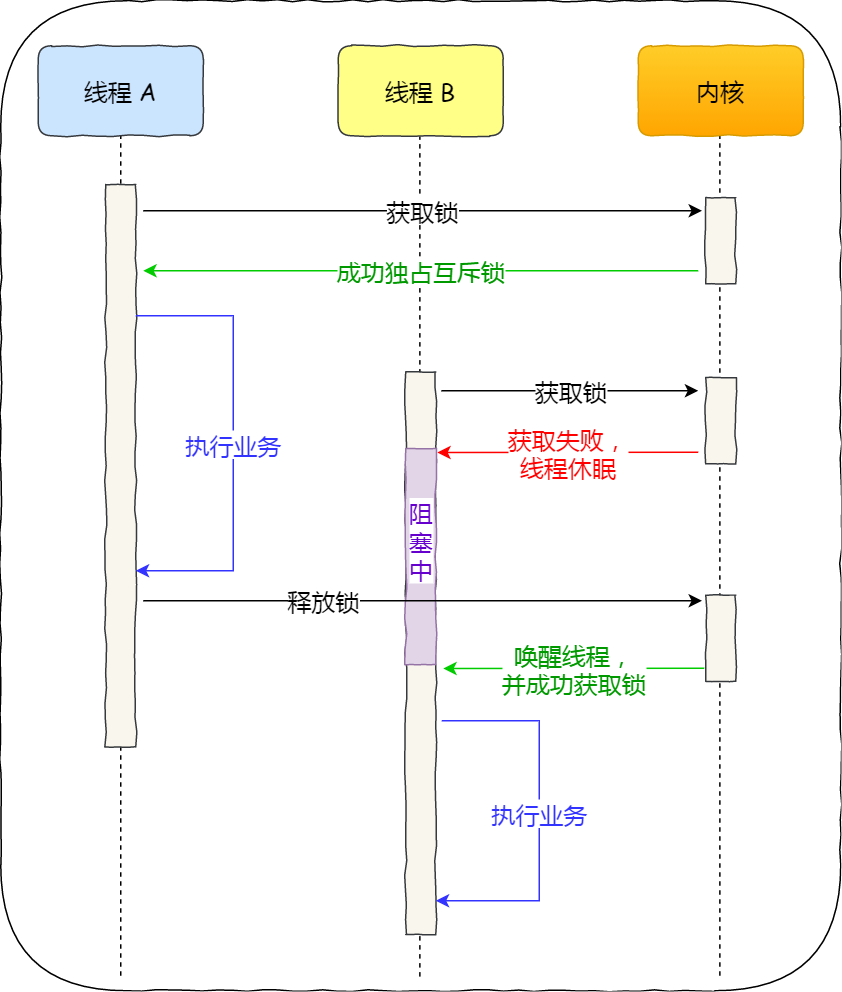
所以,互斥锁加锁失败时,会从用户态陷入到内核态,让内核帮我们切换线程,虽然简化了使用锁的难度,但是存在一定的性能开销成本。
那这个开销成本是什么呢?会有两次线程上下文切换的成本:
- 当线程加锁失败时,内核会把线程的状态从「运行」状态设置为「睡眠」状态,然后把 CPU 切换给其他线程运行;
- 接着,当锁被释放时,之前「睡眠」状态的线程会变为「就绪」状态,然后内核会在合适的时间,把 CPU 切换给该线程运行。
线程的上下文切换的是什么?当两个线程是属于同一个进程,因为虚拟内存是共享的,所以在切换时,虚拟内存这些资源就保持不动,只需要切换线程的私有数据、寄存器等不共享的数据。
上下切换的耗时有大佬统计过,大概在几十纳秒到几微秒之间,如果你锁住的代码执行时间比较短,那可能上下文切换的时间都比你锁住的代码执行时间还要长。
所以,如果你能确定被锁住的代码执行时间很短,就不应该用互斥锁,而应该选用自旋锁,否则使用互斥锁。
自旋锁是通过 CPU 提供的 CAS 函数(Compare And Swap),在「用户态」完成加锁和解锁操作,不会主动产生线程上下文切换,所以相比互斥锁来说,会快一些,开销也小一些。
一般加锁的过程,包含两个步骤:
- 第一步,查看锁的状态,如果锁是空闲的,则执行第二步;
- 第二步,将锁设置为当前线程持有;
CAS 函数就把这两个步骤合并成一条硬件级指令,形成原子指令,这样就保证了这两个步骤是不可分割的,要么一次性执行完两个步骤,要么两个步骤都不执行。
比如,设锁为变量 lock,整数 0 表示锁是空闲状态,整数 pid 表示线程 ID,那么 CAS(lock, 0, pid) 就表示自旋锁的加锁操作,CAS(lock, pid, 0) 则表示解锁操作。
使用自旋锁的时候,当发生多线程竞争锁的情况,加锁失败的线程会「忙等待」,直到它拿到锁。这里的「忙等待」可以用 while 循环等待实现,不过最好是使用 CPU 提供的 PAUSE 指令来实现「忙等待」,因为可以减少循环等待时的耗电量。
自旋锁是最比较简单的一种锁,一直自旋,利用 CPU 周期,直到锁可用。需要注意,在单核 CPU 上,需要抢占式的调度器(即不断通过时钟中断一个线程,运行其他线程)。否则,自旋锁在单 CPU 上无法使用,因为一个自旋的线程永远不会放弃 CPU。
自旋锁开销少,在多核系统下一般不会主动产生线程切换,适合异步、协程等在用户态切换请求的编程方式,但如果被锁住的代码执行时间过长,自旋的线程会长时间占用 CPU 资源,所以自旋的时间和被锁住的代码执行的时间是成「正比」的关系,我们需要清楚的知道这一点。
自旋锁与互斥锁使用层面比较相似,但实现层面上完全不同:当加锁失败时,互斥锁用「线程切换」来应对,自旋锁则用「忙等待」来应对。
它俩是锁的最基本处理方式,更高级的锁都会选择其中一个来实现,比如读写锁既可以选择互斥锁实现,也可以基于自旋锁实现。
读写锁
读写锁从字面意思我们也可以知道,它由「读锁」和「写锁」两部分构成,如果只读取共享资源用「读锁」加锁,如果要修改共享资源则用「写锁」加锁。
所以,读写锁适用于能明确区分读操作和写操作的场景。
读写锁的工作原理是:
- 当「写锁」没有被线程持有时,多个线程能够并发地持有读锁,这大大提高了共享资源的访问效率,因为「读锁」是用于读取共享资源的场景,所以多个线程同时持有读锁也不会破坏共享资源的数据。
- 但是,一旦「写锁」被线程持有后,读线程的获取读锁的操作会被阻塞,而且其他写线程的获取写锁的操作也会被阻塞。
所以说,写锁是独占锁,因为任何时刻只能有一个线程持有写锁,类似互斥锁和自旋锁,而读锁是共享锁,因为读锁可以被多个线程同时持有。
知道了读写锁的工作原理后,我们可以发现,读写锁在读多写少的场景,能发挥出优势。
另外,根据实现的不同,读写锁可以分为「读优先锁」和「写优先锁」。
读优先锁期望的是,读锁能被更多的线程持有,以便提高读线程的并发性,它的工作方式是:当读线程 A 先持有了读锁,写线程 B 在获取写锁的时候,会被阻塞,并且在阻塞过程中,后续来的读线程 C 仍然可以成功获取读锁,最后直到读线程 A 和 C 释放读锁后,写线程 B 才可以成功获取写锁。如下图:
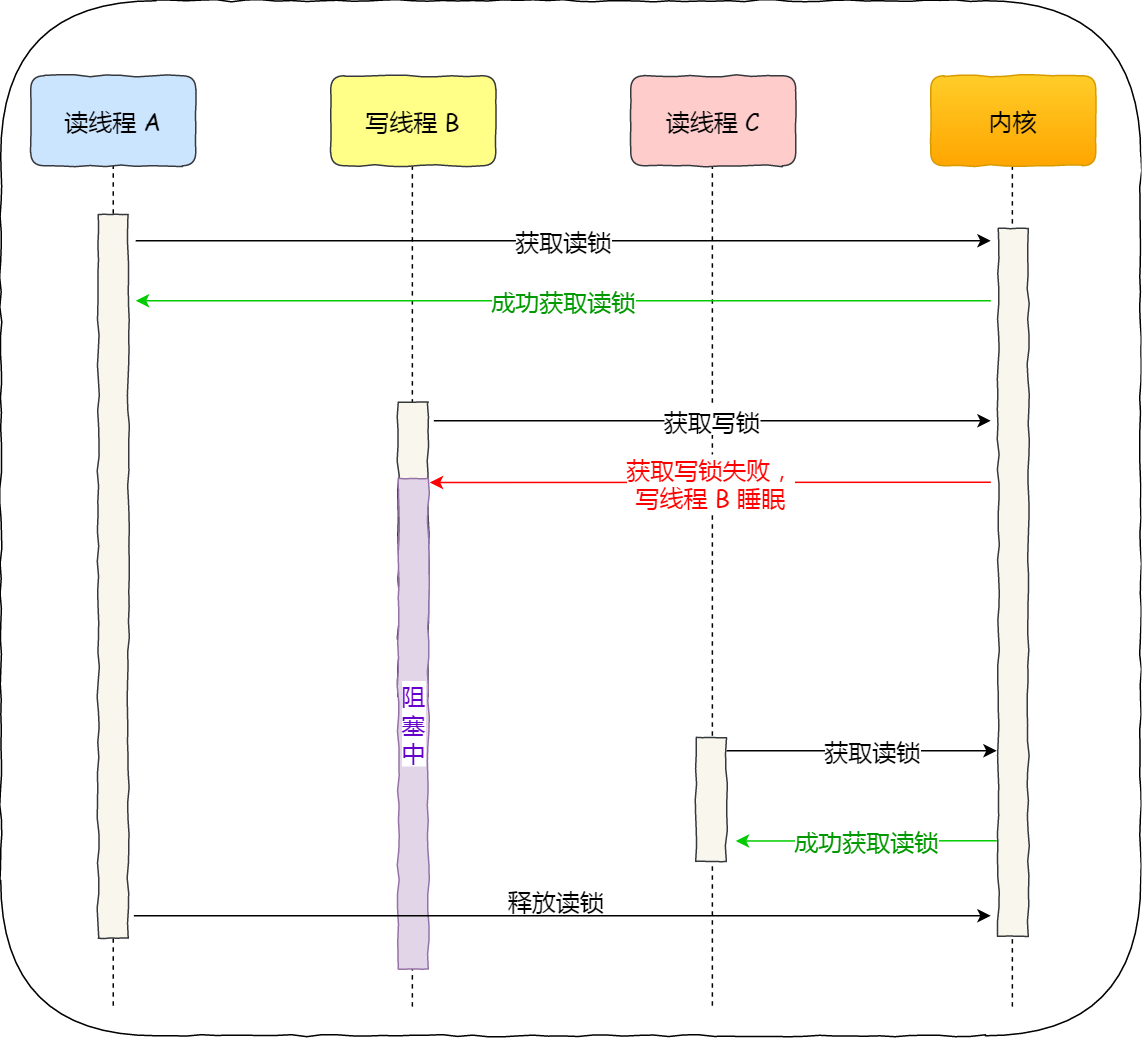
而「写优先锁」是优先服务写线程,其工作方式是:当读线程 A 先持有了读锁,写线程 B 在获取写锁的时候,会被阻塞,并且在阻塞过程中,后续来的读线程 C 获取读锁时会失败,于是读线程 C 将被阻塞在获取读锁的操作,这样只要读线程 A 释放读锁后,写线程 B 就可以成功获取写锁。如下图:
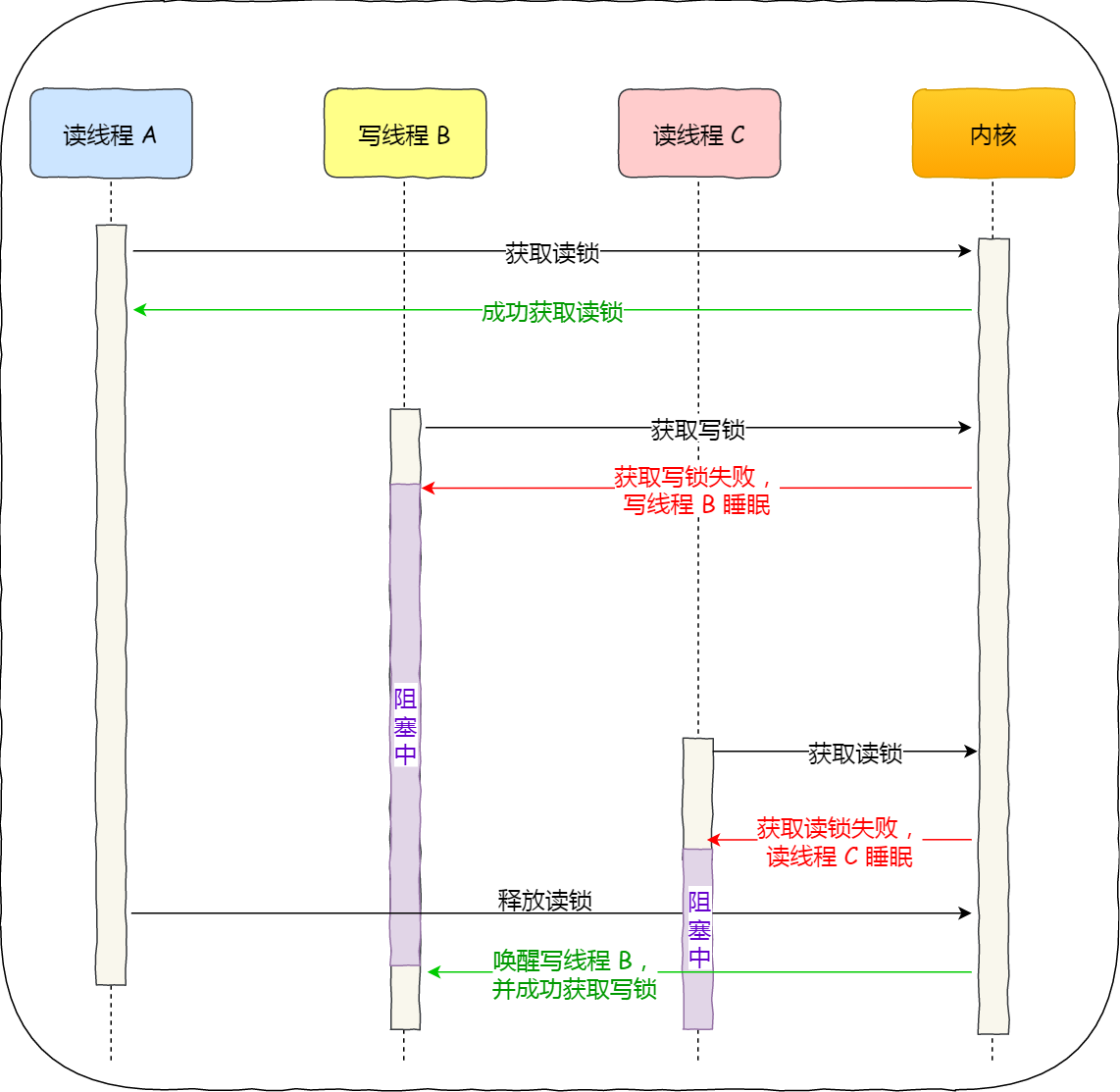
读优先锁对于读线程并发性更好,但也不是没有问题。我们试想一下,如果一直有读线程获取读锁,那么写线程将永远获取不到写锁,这就造成了写线程「饥饿」的现象。
写优先锁可以保证写线程不会饿死,但是如果一直有写线程获取写锁,读线程也会被「饿死」。
既然不管优先读锁还是写锁,对方可能会出现饿死问题,那么我们就不偏袒任何一方,搞个「公平读写锁」。
公平读写锁比较简单的一种方式是:用队列把获取锁的线程排队,不管是写线程还是读线程都按照先进先出的原则加锁即可,这样读线程仍然可以并发,也不会出现「饥饿」的现象。
互斥锁和自旋锁都是最基本的锁,读写锁可以根据场景来选择这两种锁其中的一个进行实现。
乐观锁与悲观锁
前面提到的互斥锁、自旋锁、读写锁,都是属于悲观锁。
悲观锁做事比较悲观,它认为多线程同时修改共享资源的概率比较高,于是很容易出现冲突,所以访问共享资源前,先要上锁。
那相反的,如果多线程同时修改共享资源的概率比较低,就可以采用乐观锁。
乐观锁做事比较乐观,它假定冲突的概率很低,它的工作方式是:先修改完共享资源,再验证这段时间内有没有发生冲突,如果没有其他线程在修改资源,那么操作完成,如果发现有其他线程已经修改过这个资源,就放弃本次操作。
放弃后如何重试,这跟业务场景息息相关,虽然重试的成本很高,但是冲突的概率足够低的话,还是可以接受的。
可见,乐观锁的心态是,不管三七二十一,先改了资源再说。另外,你会发现乐观锁全程并没有加锁,所以它也叫无锁编程。
这里举一个场景例子:在线文档。
我们都知道在线文档可以同时多人编辑的,如果使用了悲观锁,那么只要有一个用户正在编辑文档,此时其他用户就无法打开相同的文档了,这用户体验当然不好了。
那实现多人同时编辑,实际上是用了乐观锁,它允许多个用户打开同一个文档进行编辑,编辑完提交之后才验证修改的内容是否有冲突。
怎么样才算发生冲突?这里举个例子,比如用户 A 先在浏览器编辑文档,之后用户 B 在浏览器也打开了相同的文档进行编辑,但是用户 B 比用户 A 提交早,这一过程用户 A 是不知道的,当 A 提交修改完的内容时,那么 A 和 B 之间并行修改的地方就会发生冲突。
服务端要怎么验证是否冲突了呢?通常方案如下:
- 由于发生冲突的概率比较低,所以先让用户编辑文档,但是浏览器在下载文档时会记录下服务端返回的文档版本号;
- 当用户提交修改时,发给服务端的请求会带上原始文档版本号,服务器收到后将它与当前版本号进行比较,如果版本号不一致则提交失败,如果版本号一致则修改成功,然后服务端版本号更新到最新的版本号。
实际上,我们常见的 SVN 和 Git 也是用了乐观锁的思想,先让用户编辑代码,然后提交的时候,通过版本号来判断是否产生了冲突,发生了冲突的地方,需要我们自己修改后,再重新提交。
乐观锁虽然去除了加锁解锁的操作,但是一旦发生冲突,重试的成本非常高,所以只有在冲突概率非常低,且加锁成本非常高的场景时,才考虑使用乐观锁。
总结
开发过程中,最常见的就是互斥锁的了,互斥锁加锁失败时,会用「线程切换」来应对,当加锁失败的线程再次加锁成功后的这一过程,会有两次线程上下文切换的成本,性能损耗比较大。
如果我们明确知道被锁住的代码的执行时间很短,那我们应该选择开销比较小的自旋锁,因为自旋锁加锁失败时,并不会主动产生线程切换,而是一直忙等待,直到获取到锁,那么如果被锁住的代码执行时间很短,那这个忙等待的时间相对应也很短。
如果能区分读操作和写操作的场景,那读写锁就更合适了,它允许多个读线程可以同时持有读锁,提高了读的并发性。根据偏袒读方还是写方,可以分为读优先锁和写优先锁,读优先锁并发性很强,但是写线程会被饿死,而写优先锁会优先服务写线程,读线程也可能会被饿死,那为了避免饥饿的问题,于是就有了公平读写锁,它是用队列把请求锁的线程排队,并保证先入先出的原则来对线程加锁,这样便保证了某种线程不会被饿死,通用性也更好点。
互斥锁和自旋锁都是最基本的锁,读写锁可以根据场景来选择这两种锁其中的一个进行实现。
另外,互斥锁、自旋锁、读写锁都属于悲观锁,悲观锁认为并发访问共享资源时,冲突概率可能非常高,所以在访问共享资源前,都需要先加锁。
相反的,如果并发访问共享资源时,冲突概率非常低的话,就可以使用乐观锁,它的工作方式是,在访问共享资源时,不用先加锁,修改完共享资源后,再验证这段时间内有没有发生冲突,如果没有其他线程在修改资源,那么操作完成,如果发现有其他线程已经修改过这个资源,就放弃本次操作。
但是,一旦冲突概率上升,就不适合使用乐观锁了,因为它解决冲突的重试成本非常高。
不管使用的哪种锁,我们的加锁的代码范围应该尽可能的小,也就是加锁的粒度要小,这样执行速度会比较快。再来,使用上了合适的锁,就会快上加快了。
读者问答
CAS 不是乐观锁吗,为什么基于 CAS 实现的自旋锁是悲观锁?
乐观锁是先修改同步资源,再验证有没有发生冲突。
悲观锁是修改共享数据前,都要先加锁,防止竞争。
CAS 是乐观锁没错,但是 CAS 和自旋锁不同之处,自旋锁基于 CAS 加了while 或者睡眠 CPU 的操作而产生自旋的效果,加锁失败会忙等待直到拿到锁,自旋锁是要需要事先拿到锁才能修改数据的,所以算悲观锁。
一个进程最多可以创健多少个线程?
昨天有位读者问了我这么个问题:

大致意思就是,他看了一个面经,说虚拟内存是 2G 大小,然后他看了我的图解系统 PDF 里说虚拟内存是 4G,然后他就懵逼了。
其实他看这个面经很有问题,没有说明是什么操作系统,以及是多少位操作系统。
因为不同的操作系统和不同位数的操作系统,虚拟内存可能是不一样多。
Windows 系统我不了解,我就说说 Linux 系统。
在 Linux 操作系统中,虚拟地址空间的内部又被分为内核空间和用户空间两部分,不同位数的系统,地址 空间的范围也不同。比如最常⻅的 32 位和 64 位系统,如下所示:
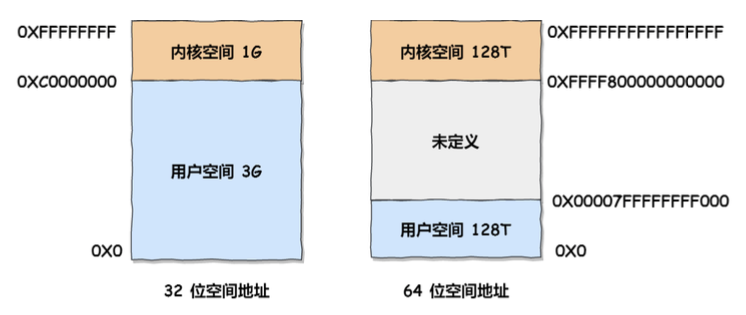
通过这里可以看出:
- 32 位系统的内核空间占用 1G ,位于最高处,剩下的 3G 是用户空间;
- 64 位系统的内核空间和用户空间都是 128T ,分别占据整个内存空间的最高和最低处,剩下的中间部分是未定义的。
接着,来看看读者那个面经题目:一个进程最多可以创建多少个线程?
这个问题跟两个东西有关系:
- 进程的虚拟内存空间上限,因为创建一个线程,操作系统需要为其分配一个栈空间,如果线程数量越多,所需的栈空间就要越大,那么虚拟内存就会占用的越多。
- 系统参数限制,虽然 Linux 并没有内核参数来控制单个进程创建的最大线程个数,但是有系统级别的参数来控制整个系统的最大线程个数。
我们先看看,在进程里创建一个线程需要消耗多少虚拟内存大小?
我们可以执行 ulimit -a 这条命令,查看进程创建线程时默认分配的栈空间大小,比如我这台服务器默认分配给线程的栈空间大小为 8M。
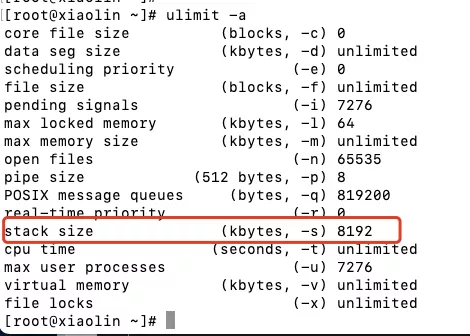
在前面我们知道,在 32 位 Linux 系统里,一个进程的虚拟空间是 4G,内核分走了1G,留给用户用的只有 3G。
那么假设创建一个线程需要占用 10M 虚拟内存,总共有 3G 虚拟内存可以使用。于是我们可以算出,最多可以创建差不多 300 个(3G/10M)左右的线程。
如果你想自己做个实验,你可以找台 32 位的 Linux 系统运行下面这个代码:
由于我手上没有 32 位的系统,我这里贴一个网上别人做的测试结果:

如果想使得进程创建上千个线程,那么我们可以调整创建线程时分配的栈空间大小,比如调整为 512k:
|
|
说完 32 位系统的情况,我们来看看 64 位系统里,一个进程能创建多少线程呢?
我的测试服务器的配置:
- 64 位系统;
- 2G 物理内存;
- 单核 CPU。
64 位系统意味着用户空间的虚拟内存最大值是 128T,这个数值是很大的,如果按创建一个线程需占用 10M 栈空间的情况来算,那么理论上可以创建 128T/10M 个线程,也就是 1000多万个线程,有点魔幻!
所以按 64 位系统的虚拟内存大小,理论上可以创建无数个线程。
事实上,肯定创建不了那么多线程,除了虚拟内存的限制,还有系统的限制。
比如下面这三个内核参数的大小,都会影响创建线程的上限:
- /proc/sys/kernel/threads-max,表示系统支持的最大线程数,默认值是
14553; - /proc/sys/kernel/pid_max,表示系统全局的 PID 号数值的限制,每一个进程或线程都有 ID,ID 的值超过这个数,进程或线程就会创建失败,默认值是
32768; - /proc/sys/vm/max_map_count,表示限制一个进程可以拥有的VMA(虚拟内存区域)的数量,具体什么意思我也没搞清楚,反正如果它的值很小,也会导致创建线程失败,默认值是
65530。
那接下针对我的测试服务器的配置,看下一个进程最多能创建多少个线程呢?
我在这台服务器跑了前面的程序,其结果如下:
可以看到,创建了 14374 个线程后,就无法在创建了,而且报错是因为资源的限制。
前面我提到的 threads-max 内核参数,它是限制系统里最大线程数,默认值是 14553。
我们可以运行那个测试线程数的程序后,看下当前系统的线程数是多少,可以通过 top -H 查看。

左上角的 Threads 的数量显示是 14553,与 threads-max 内核参数的值相同,所以我们可以认为是因为这个参数导致无法继续创建线程。
那么,我们可以把 threads-max 参数设置成 99999:
|
|
设置完 threads-max 参数后,我们重新跑测试线程数的程序,运行后结果如下图:
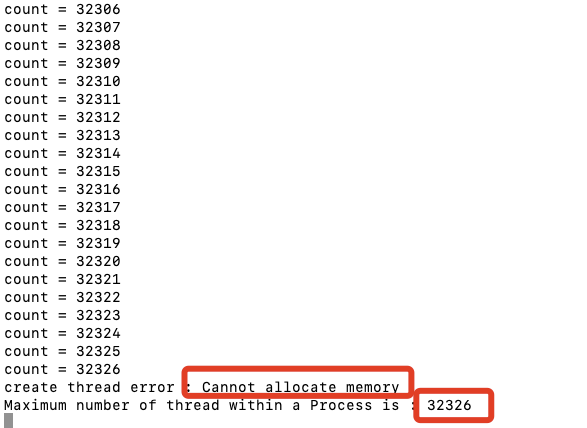
可以看到,当进程创建了 32326 个线程后,就无法继续创建里,且报错是无法继续申请内存。
此时的上限个数很接近 pid_max 内核参数的默认值(32768),那么我们可以尝试将这个参数设置为 99999:
|
|
设置完 pid_max 参数后,继续跑测试线程数的程序,运行后结果创建线程的个数还是一样卡在了 32768 了。
当时我也挺疑惑的,明明 pid_max 已经调整大后,为什么线程个数还是上不去呢?
后面经过查阅资料发现,max_map_count 这个内核参数也是需要调大的,但是它的数值与最大线程数之间有什么关系,我也不太明白,只是知道它的值是会限制创建线程个数的上限。
然后,我把 max_map_count 内核参数也设置成后 99999:
|
|
继续跑测试线程数的程序,结果如下图:

当创建差不多 5 万个线程后,我的服务器就卡住不动了,CPU 都已经被占满了,毕竟这个是单核 CPU,所以现在是 CPU 的瓶颈了。
我只有这台服务器,如果你们有性能更强的服务器来测试的话,有兴趣的小伙伴可以去测试下。
接下来,我们换个思路测试下,把创建线程时分配的栈空间调大,比如调大为 100M,在大就会创建线程失败。
|
|
设置完后,跑测试线程的程序,其结果如下:
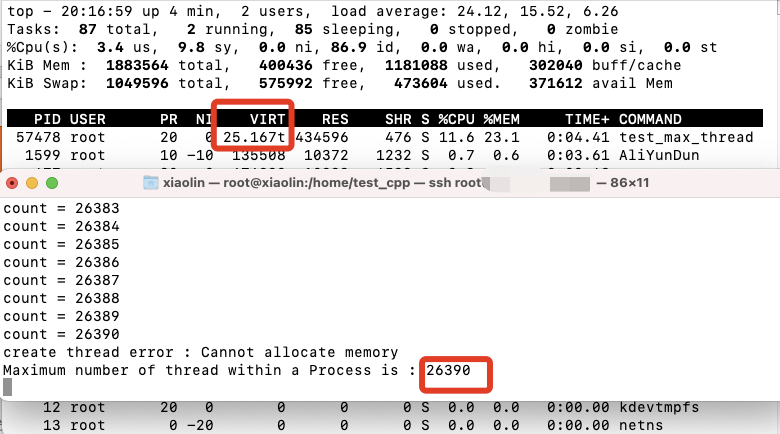
总共创建了 26390 个线程,然后就无法继续创建了,而且该进程的虚拟内存空间已经高达 25T,要知道这台服务器的物理内存才 2G。
为什么物理内存只有 2G,进程的虚拟内存却可以使用 25T 呢?
因为虚拟内存并不是全部都映射到物理内存的,程序是有局部性的特性,也就是某一个时间只会执行部分代码,所以只需要映射这部分程序就好。
你可以从上面那个 top 的截图看到,虽然进程虚拟空间很大,但是物理内存(RES)只有使用了 400 多M。
好了,简单总结下:
- 32 位系统,用户态的虚拟空间只有 3G,如果创建线程时分配的栈空间是 10M,那么一个进程最多只能创建 300 个左右的线程。
- 64 位系统,用户态的虚拟空间大到有 128T,理论上不会受虚拟内存大小的限制,而会受系统的参数或性能限制。
线程崩溃了,进程也会崩溃吗?
之前分享这篇文章的时候:进程和线程基础知识全家桶,30 张图一套带走 (opens new window),提到说线程的一个缺点:

很多同学就好奇,为什么 C/C++ 语言里,线程崩溃后,进程也会崩溃,而 Java 语言里却不会呢?
刚好看到朋友(公众号:码海 (opens new window))写了一篇:「美团面试题:为什么线程崩溃崩溃不会导致 JVM 崩溃?」
我觉得写的很好,所以分享给大家一起拜读拜读,本文分以下几节来探讨:
- 线程崩溃,进程一定会崩溃吗
- 进程是如何崩溃的-信号机制简介
- 为什么在 JVM 中线程崩溃不会导致 JVM 进程崩溃
- openJDK 源码解析
线程崩溃,进程一定会崩溃吗
一般来说如果线程是因为非法访问内存引起的崩溃,那么进程肯定会崩溃,为什么系统要让进程崩溃呢,这主要是因为在进程中,各个线程的地址空间是共享的,既然是共享,那么某个线程对地址的非法访问就会导致内存的不确定性,进而可能会影响到其他线程,这种操作是危险的,操作系统会认为这很可能导致一系列严重的后果,于是干脆让整个进程崩溃
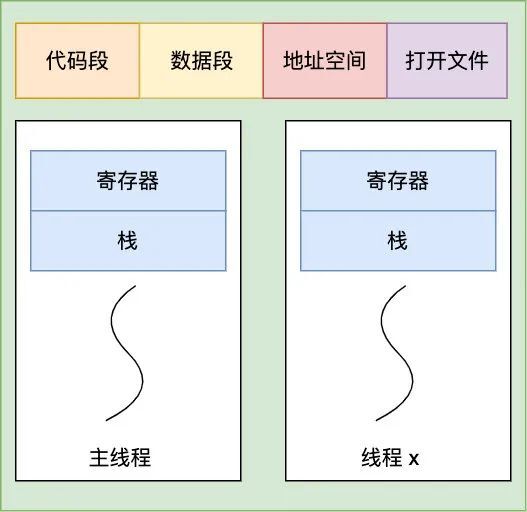
线程共享代码段,数据段,地址空间,文件非法访问内存有以下几种情况,我们以 C 语言举例来看看。
1、针对只读内存写入数据
|
|
2、访问了进程没有权限访问的地址空间(比如内核空间)
|
|
在 32 位虚拟地址空间中,p 指向的是内核空间,显然不具有写入权限,所以上述赋值操作会导致崩溃
3、访问了不存在的内存,比如:
|
|
以上错误都是访问内存时的错误,所以统一会报 Segment Fault 错误(即段错误),这些都会导致进程崩溃
进程是如何崩溃的-信号机制简介
那么线程崩溃后,进程是如何崩溃的呢,这背后的机制到底是怎样的,答案是信号。
大家想想要干掉一个正在运行的进程是不是经常用 kill -9 pid 这样的命令,这里的 kill 其实就是给指定 pid 发送终止信号的意思,其中的 9 就是信号。
其实信号有很多类型的,在 Linux 中可以通过 kill -l查看所有可用的信号:
当然了发 kill 信号必须具有一定的权限,否则任意进程都可以通过发信号来终止其他进程,那显然是不合理的,实际上 kill 执行的是系统调用,将控制权转移给了内核(操作系统),由内核来给指定的进程发送信号
那么发个信号进程怎么就崩溃了呢,这背后的原理到底是怎样的?
其背后的机制如下
- CPU 执行正常的进程指令
- 调用 kill 系统调用向进程发送信号
- 进程收到操作系统发的信号,CPU 暂停当前程序运行,并将控制权转交给操作系统
- 调用 kill 系统调用向进程发送信号(假设为 11,即 SIGSEGV,一般非法访问内存报的都是这个错误)
- 操作系统根据情况执行相应的信号处理程序(函数),一般执行完信号处理程序逻辑后会让进程退出
注意上面的第五步,如果进程没有注册自己的信号处理函数,那么操作系统会执行默认的信号处理程序(一般最后会让进程退出),但如果注册了,则会执行自己的信号处理函数,这样的话就给了进程一个垂死挣扎的机会,它收到 kill 信号后,可以调用 exit() 来退出,但也可以使用 sigsetjmp,siglongjmp 这两个函数来恢复进程的执行
|
|
如代码所示:注册信号处理函数后,当收到 SIGSEGV 信号后,先执行相关的逻辑再退出
另外当进程接收信号之后也可以不定义自己的信号处理函数,而是选择忽略信号,如下
|
|
也就是说虽然给进程发送了 kill 信号,但如果进程自己定义了信号处理函数或者无视信号就有机会逃出生天,当然了 kill -9 命令例外,不管进程是否定义了信号处理函数,都会马上被干掉。
说到这大家是否想起了一道经典面试题:如何让正在运行的 Java 工程的优雅停机?
通过上面的介绍大家不难发现,其实是 JVM 自己定义了信号处理函数,这样当发送 kill pid 命令(默认会传 15 也就是 SIGTERM)后,JVM 就可以在信号处理函数中执行一些资源清理之后再调用 exit 退出。
这种场景显然不能用 kill -9,不然一下把进程干掉了资源就来不及清除了。
为什么线程崩溃不会导致 JVM 进程崩溃
现在我们再来看看开头这个问题,相信你多少会心中有数,想想看在 Java 中有哪些是常见的由于非法访问内存而产生的 Exception 或 error 呢,常见的是大家熟悉的 StackoverflowError 或者 NPE(NullPointerException),NPE 我们都了解,属于是访问了不存在的内存。
但为什么栈溢出(Stackoverflow)也属于非法访问内存呢,这得简单聊一下进程的虚拟空间,也就是前面提到的共享地址空间。
现代操作系统为了保护进程之间不受影响,所以使用了虚拟地址空间来隔离进程,进程的寻址都是针对虚拟地址,每个进程的虚拟空间都是一样的,而线程会共用进程的地址空间。
以 32 位虚拟空间,进程的虚拟空间分布如下:
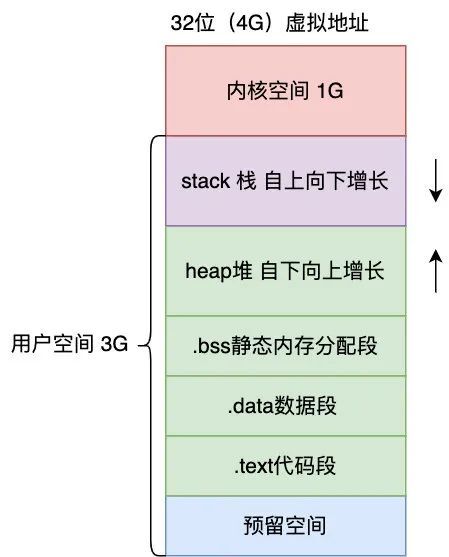
那么 stackoverflow 是怎么发生的呢?
进程每调用一个函数,都会分配一个栈桢,然后在栈桢里会分配函数里定义的各种局部变量。
假设现在调用了一个无限递归的函数,那就会持续分配栈帧,但 stack 的大小是有限的(Linux 中默认为 8 M,可以通过 ulimit -a 查看),如果无限递归很快栈就会分配完了,此时再调用函数试图分配超出栈的大小内存,就会发生段错误,也就是 stackoverflowError。
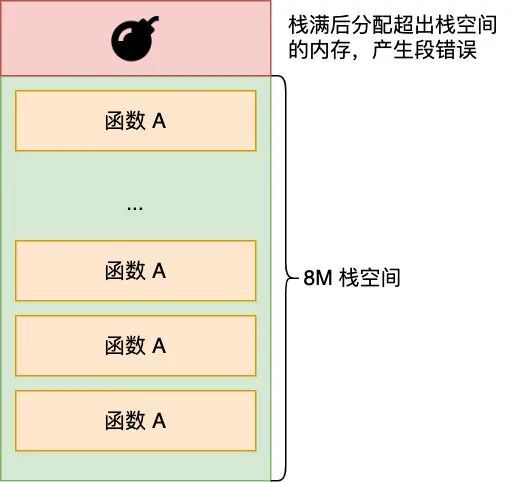
好了,现在我们知道了 StackoverflowError 怎么产生的。
那问题来了,既然 StackoverflowError 或者 NPE 都属于非法访问内存, JVM 为什么不会崩溃呢?
有了上一节的铺垫,相信你不难回答,其实就是因为 JVM 自定义了自己的信号处理函数,拦截了 SIGSEGV 信号,针对这两者不让它们崩溃。
怎么证明这个推测呢,我们来看下 JVM 的源码来一探究竟
openJDK 源码解析
HotSpot 虚拟机目前使用范围最广的 Java 虚拟机,据 R 大所述, Oracle JDK 与 OpenJDK 里的 JVM 都是 HotSpot VM,从源码层面说,两者基本上是同一个东西。
OpenJDK 是开源的,所以我们主要研究下 Java 8 的 OpenJDK 即可,地址如下:https://github.com/AdoptOpenJDK/openjdk-jdk8u (opens new window),有兴趣的可以下载来看看。
我们只要研究 Linux 下的 JVM,为了便于说明,也方便大家查阅,我把其中关于信号处理的关键流程整理了下(忽略其中的次要代码)。
可以看到,在启动 JVM 的时候,也设置了信号处理函数,收到 SIGSEGV,SIGPIPE 等信号后最终会调用 JVM_handle_linux_signal 这个自定义信号处理函数,再来看下这个函数的主要逻辑。
|
|
从以上代码我们可以知道以下信息:
- 发生 stackoverflow 还有空指针错误,确实都发送了 SIGSEGV,只是虚拟机不选择退出,而是自己内部作了额外的处理,其实是恢复了线程的执行,并抛出 StackoverflowError 和 NPE,这就是为什么 JVM 不会崩溃且我们能捕获这两个错误/异常的原因
- 如果针对 SIGSEGV 等信号,在以上的函数中 JVM 没有做额外的处理,那么最终会走到 report_and_die 这个方法,这个方法主要做的事情是生成 hs_err_pid_xxx.log crash 文件(记录了一些堆栈信息或错误),然后退出
至此我相信大家明白了为什么发生了 StackoverflowError 和 NPE 这两个非法访问内存的错误,JVM 却没有崩溃。
原因其实就是虚拟机内部定义了信号处理函数,而在信号处理函数中对这两者做了额外的处理以让 JVM 不崩溃,另一方面也可以看出如果 JVM 不对信号做额外的处理,最后会自己退出并产生 crash 文件 hs_err_pid_xxx.log(可以通过 -XX:ErrorFile=/var/*log*/hs_err.log 这样的方式指定),这个文件记录了虚拟机崩溃的重要原因。
所以也可以说,虚拟机是否崩溃只要看它是否会产生此崩溃日志文件
总结
正常情况下,操作系统为了保证系统安全,所以针对非法内存访问会发送一个 SIGSEGV 信号,而操作系统一般会调用默认的信号处理函数(一般会让相关的进程崩溃)。
但如果进程觉得"罪不致死",那么它也可以选择自定义一个信号处理函数,这样的话它就可以做一些自定义的逻辑,比如记录 crash 信息等有意义的事。
回过头来看为什么虚拟机会针对 StackoverflowError 和 NullPointerException 做额外处理让线程恢复呢,针对 stackoverflow 其实它采用了一种栈回溯的方法保证线程可以一直执行下去,而捕获空指针错误主要是这个错误实在太普遍了。
为了这一个很常见的错误而让 JVM 崩溃那线上的 JVM 要宕机多少次,所以出于工程健壮性的考虑,与其直接让 JVM 崩溃倒不如让线程起死回生,并且将这两个错误/异常抛给用户来处理。
调度算法
进程调度/页面置换/磁盘调度算法
最近,我偷偷潜伏在各大技术群,因为秋招在即,看到不少小伙伴分享的大厂面经。
然后发现,操作系统的知识点考察还是比较多的,大厂就是大厂,就爱问基础知识。其中,关于操作系统的「调度算法」考察也算比较频繁。
所以,我这边总结了操作系统的三大调度机制,分别是「进程调度/页面置换/磁盘调度算法」,供大家复习,希望大家在秋招能斩获自己心意的 offer。
进程调度算法
进程调度算法也称 CPU 调度算法,毕竟进程是由 CPU 调度的。
当 CPU 空闲时,操作系统就选择内存中的某个「就绪状态」的进程,并给其分配 CPU。
什么时候会发生 CPU 调度呢?通常有以下情况:
- 当进程从运行状态转到等待状态;
- 当进程从运行状态转到就绪状态;
- 当进程从等待状态转到就绪状态;
- 当进程从运行状态转到终止状态;
其中发生在 1 和 4 两种情况下的调度称为「非抢占式调度」,2 和 3 两种情况下发生的调度称为「抢占式调度」。
非抢占式的意思就是,当进程正在运行时,它就会一直运行,直到该进程完成或发生某个事件而被阻塞时,才会把 CPU 让给其他进程。
而抢占式调度,顾名思义就是进程正在运行的时,可以被打断,使其把 CPU 让给其他进程。那抢占的原则一般有三种,分别是时间片原则、优先权原则、短作业优先原则。
你可能会好奇为什么第 3 种情况也会发生 CPU 调度呢?假设有一个进程是处于等待状态的,但是它的优先级比较高,如果该进程等待的事件发生了,它就会转到就绪状态,一旦它转到就绪状态,如果我们的调度算法是以优先级来进行调度的,那么它就会立马抢占正在运行的进程,所以这个时候就会发生 CPU 调度。
那第 2 种状态通常是时间片到的情况,因为时间片到了就会发生中断,于是就会抢占正在运行的进程,从而占用 CPU。
调度算法影响的是等待时间(进程在就绪队列中等待调度的时间总和),而不能影响进程正在使用 CPU 的时间和 I/O 时间。
接下来,说说常见的调度算法:
- 先来先服务调度算法
- 最短作业优先调度算法
- 高响应比优先调度算法
- 时间片轮转调度算法
- 最高优先级调度算法
- 多级反馈队列调度算法
先来先服务调度算法
最简单的一个调度算法,就是非抢占式的先来先服务(*First Come First Severd, FCFS*)算法了。
顾名思义,先来后到,每次从就绪队列选择最先进入队列的进程,然后一直运行,直到进程退出或被阻塞,才会继续从队列中选择第一个进程接着运行。
这似乎很公平,但是当一个长作业先运行了,那么后面的短作业等待的时间就会很长,不利于短作业。
FCFS 对长作业有利,适用于 CPU 繁忙型作业的系统,而不适用于 I/O 繁忙型作业的系统。
最短作业优先调度算法
最短作业优先(*Shortest Job First, SJF*)调度算法同样也是顾名思义,它会优先选择运行时间最短的进程来运行,这有助于提高系统的吞吐量。
这显然对长作业不利,很容易造成一种极端现象。
比如,一个长作业在就绪队列等待运行,而这个就绪队列有非常多的短作业,那么就会使得长作业不断的往后推,周转时间变长,致使长作业长期不会被运行。
高响应比优先调度算法
前面的「先来先服务调度算法」和「最短作业优先调度算法」都没有很好的权衡短作业和长作业。
那么,高响应比优先 (*Highest Response Ratio Next, HRRN*)调度算法主要是权衡了短作业和长作业。
每次进行进程调度时,先计算「响应比优先级」,然后把「响应比优先级」最高的进程投入运行,「响应比优先级」的计算公式:
从上面的公式,可以发现:
- 如果两个进程的「等待时间」相同时,「要求的服务时间」越短,「响应比」就越高,这样短作业的进程容易被选中运行;
- 如果两个进程「要求的服务时间」相同时,「等待时间」越长,「响应比」就越高,这就兼顾到了长作业进程,因为进程的响应比可以随时间等待的增加而提高,当其等待时间足够长时,其响应比便可以升到很高,从而获得运行的机会;
时间片轮转调度算法
最古老、最简单、最公平且使用最广的算法就是时间片轮转(*Round Robin, RR*)调度算法。
每个进程被分配一个时间段,称为时间片(*Quantum*),即允许该进程在该时间段中运行。
- 如果时间片用完,进程还在运行,那么将会把此进程从 CPU 释放出来,并把 CPU 分配另外一个进程;
- 如果该进程在时间片结束前阻塞或结束,则 CPU 立即进行切换;
另外,时间片的长度就是一个很关键的点:
- 如果时间片设得太短会导致过多的进程上下文切换,降低了 CPU 效率;
- 如果设得太长又可能引起对短作业进程的响应时间变长。
通常时间片设为 20ms~50ms 通常是一个比较合理的折中值。
最高优先级调度算法
前面的「时间片轮转算法」做了个假设,即让所有的进程同等重要,也不偏袒谁,大家的运行时间都一样。
但是,对于多用户计算机系统就有不同的看法了,它们希望调度是有优先级的,即希望调度程序能从就绪队列中选择最高优先级的进程进行运行,这称为最高优先级(*Highest Priority First,HPF*)调度算法。
进程的优先级可以分为,静态优先级或动态优先级:
- 静态优先级:创建进程时候,就已经确定了优先级了,然后整个运行时间优先级都不会变化;
- 动态优先级:根据进程的动态变化调整优先级,比如如果进程运行时间增加,则降低其优先级,如果进程等待时间(就绪队列的等待时间)增加,则升高其优先级,也就是随着时间的推移增加等待进程的优先级。
该算法也有两种处理优先级高的方法,非抢占式和抢占式:
- 非抢占式:当就绪队列中出现优先级高的进程,运行完当前进程,再选择优先级高的进程。
- 抢占式:当就绪队列中出现优先级高的进程,当前进程挂起,调度优先级高的进程运行。
但是依然有缺点,可能会导致低优先级的进程永远不会运行。
多级反馈队列调度算法
多级反馈队列(*Multilevel Feedback Queue*)调度算法是「时间片轮转算法」和「最高优先级算法」的综合和发展。
顾名思义:
- 「多级」表示有多个队列,每个队列优先级从高到低,同时优先级越高时间片越短。
- 「反馈」表示如果有新的进程加入优先级高的队列时,立刻停止当前正在运行的进程,转而去运行优先级高的队列;
来看看,它是如何工作的:
- 设置了多个队列,赋予每个队列不同的优先级,每个队列优先级从高到低,同时优先级越高时间片越短;
- 新的进程会被放入到第一级队列的末尾,按先来先服务的原则排队等待被调度,如果在第一级队列规定的时间片没运行完成,则将其转入到第二级队列的末尾,以此类推,直至完成;
- 当较高优先级的队列为空,才调度较低优先级的队列中的进程运行。如果进程运行时,有新进程进入较高优先级的队列,则停止当前运行的进程并将其移入到原队列末尾,接着让较高优先级的进程运行;
可以发现,对于短作业可能可以在第一级队列很快被处理完。对于长作业,如果在第一级队列处理不完,可以移入下次队列等待被执行,虽然等待的时间变长了,但是运行时间也会更长了,所以该算法很好的兼顾了长短作业,同时有较好的响应时间。
内存页面置换算法
在了解内存页面置换算法前,我们得先谈一下缺页异常(缺页中断)。
当 CPU 访问的页面不在物理内存时,便会产生一个缺页中断,请求操作系统将所缺页调入到物理内存。那它与一般中断的主要区别在于:
- 缺页中断在指令执行「期间」产生和处理中断信号,而一般中断在一条指令执行「完成」后检查和处理中断信号。
- 缺页中断返回到该指令的开始重新执行「该指令」,而一般中断返回回到该指令的「下一个指令」执行。
我们来看一下缺页中断的处理流程,如下图:
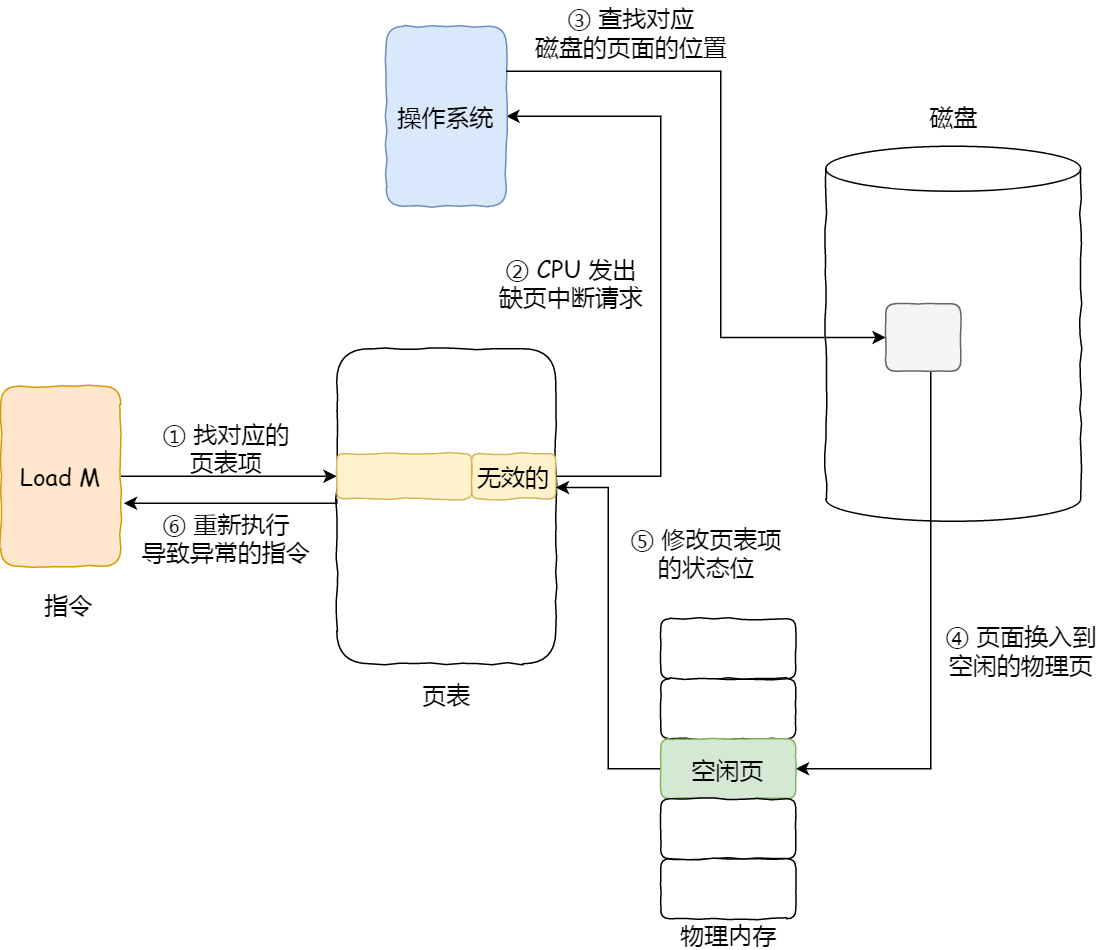
- 在 CPU 里访问一条 Load M 指令,然后 CPU 会去找 M 所对应的页表项。
- 如果该页表项的状态位是「有效的」,那 CPU 就可以直接去访问物理内存了,如果状态位是「无效的」,则 CPU 则会发送缺页中断请求。
- 操作系统收到了缺页中断,则会执行缺页中断处理函数,先会查找该页面在磁盘中的页面的位置。
- 找到磁盘中对应的页面后,需要把该页面换入到物理内存中,但是在换入前,需要在物理内存中找空闲页,如果找到空闲页,就把页面换入到物理内存中。
- 页面从磁盘换入到物理内存完成后,则把页表项中的状态位修改为「有效的」。
- 最后,CPU 重新执行导致缺页异常的指令。
上面所说的过程,第 4 步是能在物理内存找到空闲页的情况,那如果找不到呢?
找不到空闲页的话,就说明此时内存已满了,这时候,就需要「页面置换算法」选择一个物理页,如果该物理页有被修改过(脏页),则把它换出到磁盘,然后把该被置换出去的页表项的状态改成「无效的」,最后把正在访问的页面装入到这个物理页中。
这里提一下,页表项通常有如下图的字段:

那其中:
- 状态位:用于表示该页是否有效,也就是说是否在物理内存中,供程序访问时参考。
- 访问字段:用于记录该页在一段时间被访问的次数,供页面置换算法选择出页面时参考。
- 修改位:表示该页在调入内存后是否有被修改过,由于内存中的每一页都在磁盘上保留一份副本,因此,如果没有修改,在置换该页时就不需要将该页写回到磁盘上,以减少系统的开销;如果已经被修改,则将该页重写到磁盘上,以保证磁盘中所保留的始终是最新的副本。
- 硬盘地址:用于指出该页在硬盘上的地址,通常是物理块号,供调入该页时使用。
这里我整理了虚拟内存的管理整个流程,你可以从下面这张图看到:
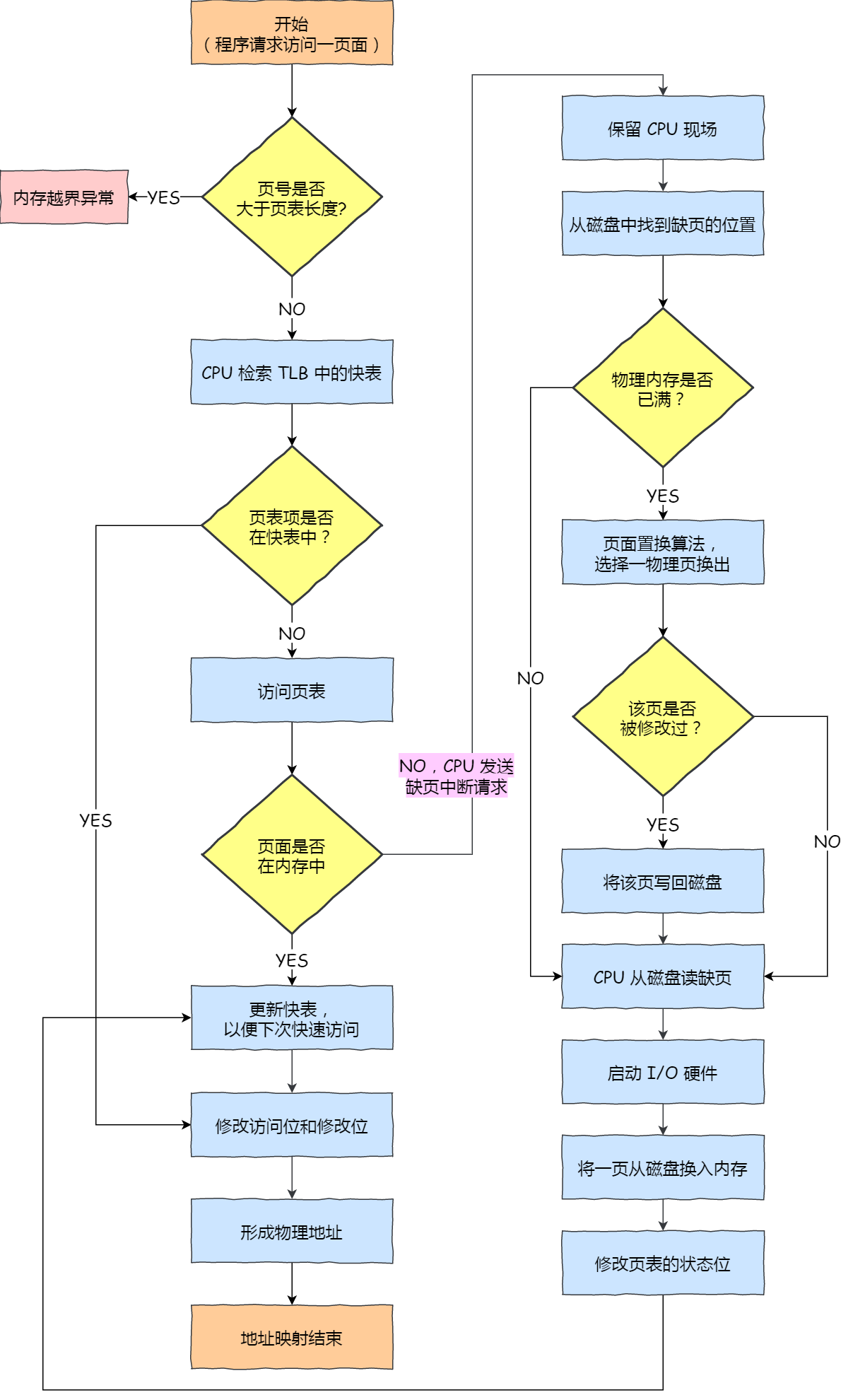
所以,页面置换算法的功能是,当出现缺页异常,需调入新页面而内存已满时,选择被置换的物理页面,也就是说选择一个物理页面换出到磁盘,然后把需要访问的页面换入到物理页。
那其算法目标则是,尽可能减少页面的换入换出的次数,常见的页面置换算法有如下几种:
- 最佳页面置换算法(OPT)
- 先进先出置换算法(FIFO)
- 最近最久未使用的置换算法(LRU)
- 时钟页面置换算法(Lock)
- 最不常用置换算法(LFU)
最佳页面置换算法
最佳页面置换算法基本思路是,置换在「未来」最长时间不访问的页面。
所以,该算法实现需要计算内存中每个逻辑页面的「下一次」访问时间,然后比较,选择未来最长时间不访问的页面。
我们举个例子,假设一开始有 3 个空闲的物理页,然后有请求的页面序列,那它的置换过程如下图:
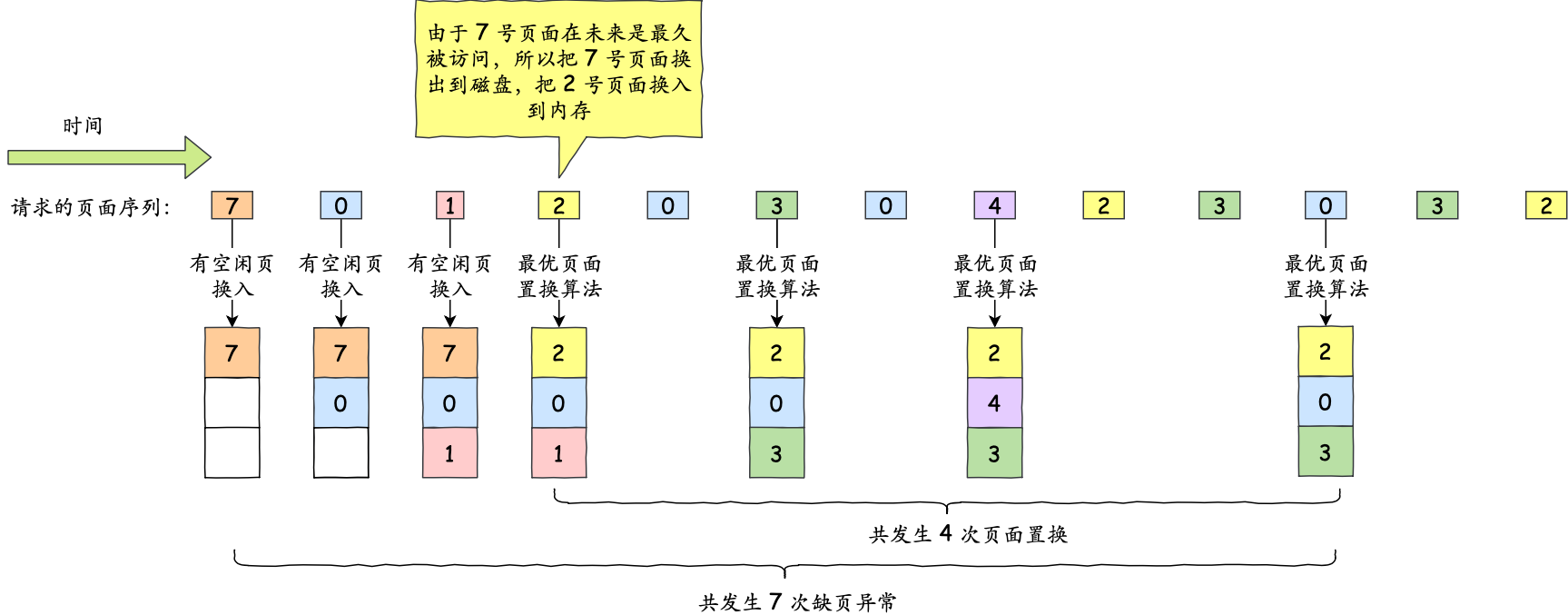
在这个请求的页面序列中,缺页共发生了 7 次(空闲页换入 3 次 + 最优页面置换 4 次),页面置换共发生了 4 次。
这很理想,但是实际系统中无法实现,因为程序访问页面时是动态的,我们是无法预知每个页面在「下一次」访问前的等待时间。
所以,最佳页面置换算法作用是为了衡量你的算法的效率,你的算法效率越接近该算法的效率,那么说明你的算法是高效的。
先进先出置换算法
既然我们无法预知页面在下一次访问前所需的等待时间,那我们可以选择在内存驻留时间很长的页面进行中置换,这个就是「先进先出置换」算法的思想。
还是以前面的请求的页面序列作为例子,假设使用先进先出置换算法,则过程如下图:
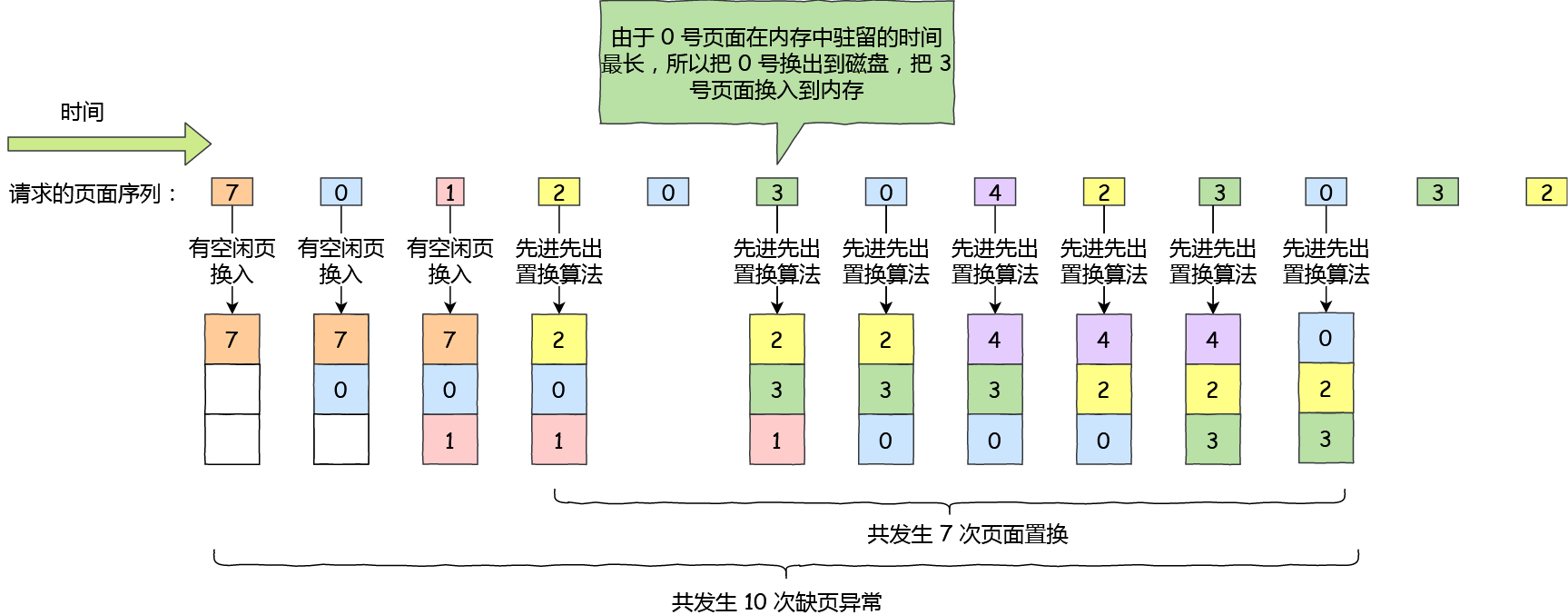
在这个请求的页面序列中,缺页共发生了 10 次,页面置换共发生了 7 次,跟最佳页面置换算法比较起来,性能明显差了很多。
最近最久未使用的置换算法
最近最久未使用(LRU)的置换算法的基本思路是,发生缺页时,选择最长时间没有被访问的页面进行置换,也就是说,该算法假设已经很久没有使用的页面很有可能在未来较长的一段时间内仍然不会被使用。
这种算法近似最优置换算法,最优置换算法是通过「未来」的使用情况来推测要淘汰的页面,而 LRU 则是通过「历史」的使用情况来推测要淘汰的页面。
还是以前面的请求的页面序列作为例子,假设使用最近最久未使用的置换算法,则过程如下图:
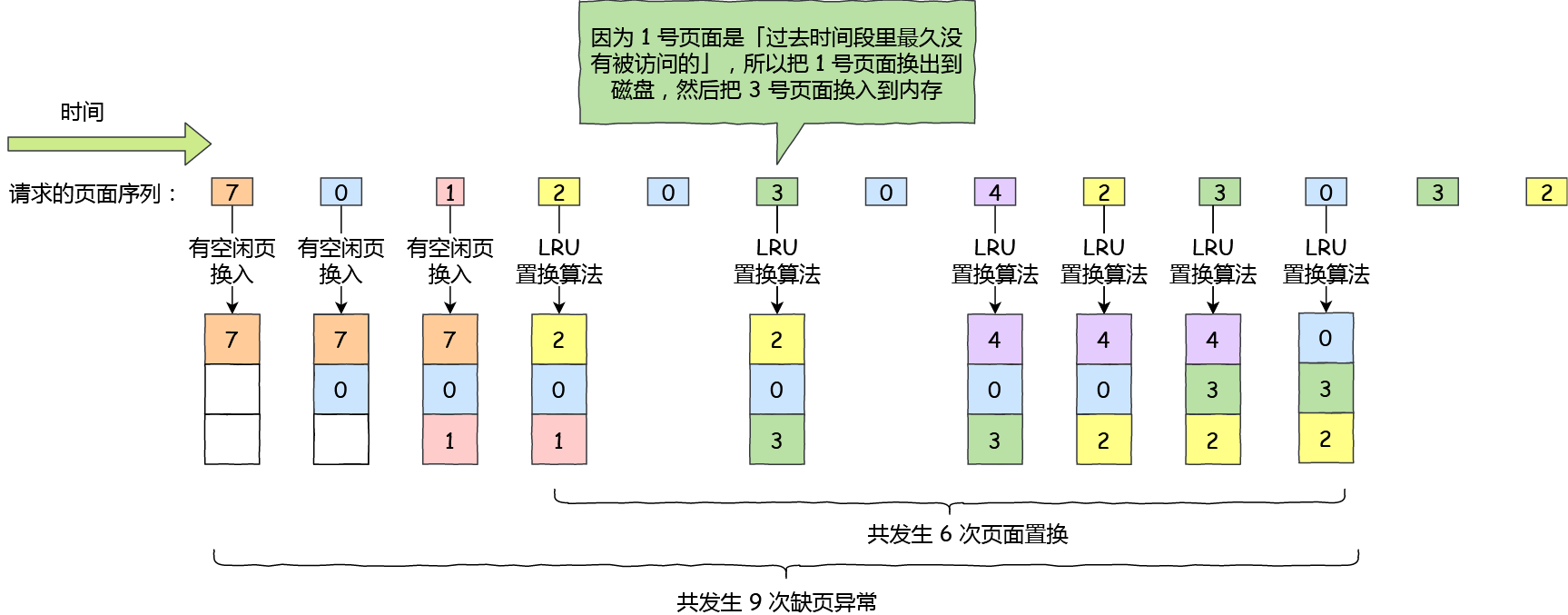
在这个请求的页面序列中,缺页共发生了 9 次,页面置换共发生了 6 次,跟先进先出置换算法比较起来,性能提高了一些。
虽然 LRU 在理论上是可以实现的,但代价很高。为了完全实现 LRU,需要在内存中维护一个所有页面的链表,最近最多使用的页面在表头,最近最少使用的页面在表尾。
困难的是,在每次访问内存时都必须要更新「整个链表」。在链表中找到一个页面,删除它,然后把它移动到表头是一个非常费时的操作。
所以,LRU 虽然看上去不错,但是由于开销比较大,实际应用中比较少使用。
时钟页面置换算法
那有没有一种即能优化置换的次数,也能方便实现的算法呢?
时钟页面置换算法就可以两者兼得,它跟 LRU 近似,又是对 FIFO 的一种改进。
该算法的思路是,把所有的页面都保存在一个类似钟面的「环形链表」中,一个表针指向最老的页面。
当发生缺页中断时,算法首先检查表针指向的页面:
- 如果它的访问位是 0 就淘汰该页面,并把新的页面插入这个位置,然后把表针前移一个位置;
- 如果访问位是 1 就清除访问位,并把表针前移一个位置,重复这个过程直到找到了一个访问位为 0 的页面为止;
我画了一副时钟页面置换算法的工作流程图,你可以在下方看到:
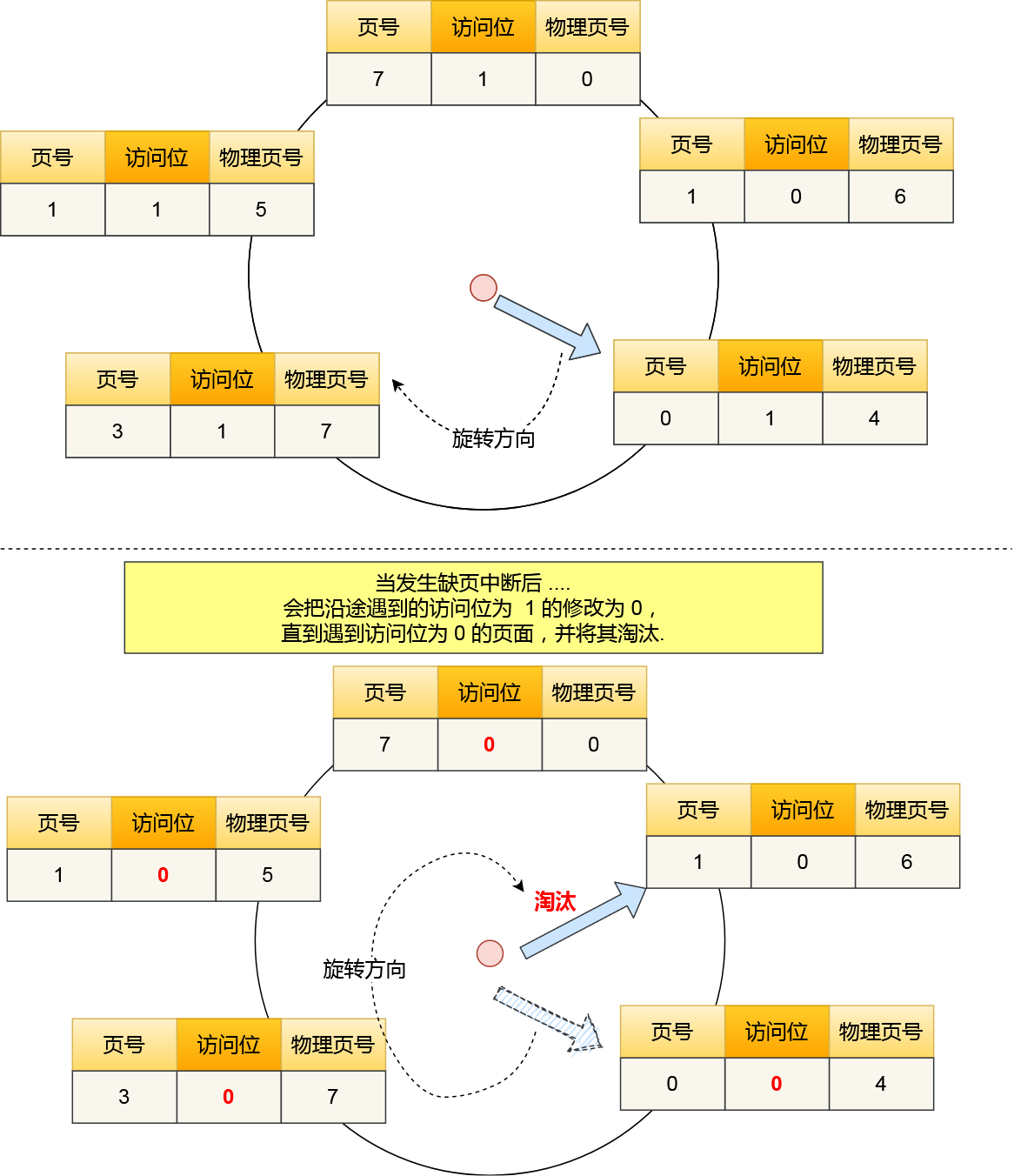
了解了这个算法的工作方式,就明白为什么它被称为时钟(Clock)算法了。
最不常用算法
最不常用(LFU)算法,这名字听起来很调皮,但是它的意思不是指这个算法不常用,而是当发生缺页中断时,选择「访问次数」最少的那个页面,并将其淘汰。
它的实现方式是,对每个页面设置一个「访问计数器」,每当一个页面被访问时,该页面的访问计数器就累加 1。在发生缺页中断时,淘汰计数器值最小的那个页面。
看起来很简单,每个页面加一个计数器就可以实现了,但是在操作系统中实现的时候,我们需要考虑效率和硬件成本的。
要增加一个计数器来实现,这个硬件成本是比较高的,另外如果要对这个计数器查找哪个页面访问次数最小,查找链表本身,如果链表长度很大,是非常耗时的,效率不高。
但还有个问题,LFU 算法只考虑了频率问题,没考虑时间的问题,比如有些页面在过去时间里访问的频率很高,但是现在已经没有访问了,而当前频繁访问的页面由于没有这些页面访问的次数高,在发生缺页中断时,就会可能会误伤当前刚开始频繁访问,但访问次数还不高的页面。
那这个问题的解决的办法还是有的,可以定期减少访问的次数,比如当发生时间中断时,把过去时间访问的页面的访问次数除以 2,也就说,随着时间的流失,以前的高访问次数的页面会慢慢减少,相当于加大了被置换的概率。
磁盘调度算法
我们来看看磁盘的结构,如下图:
常见的机械磁盘是上图左边的样子,中间圆的部分是磁盘的盘片,一般会有多个盘片,每个盘面都有自己的磁头。右边的图就是一个盘片的结构,盘片中的每一层分为多个磁道,每个磁道分多个扇区,每个扇区是 512 字节。那么,多个具有相同编号的磁道形成一个圆柱,称之为磁盘的柱面,如上图里中间的样子。
磁盘调度算法的目的很简单,就是为了提高磁盘的访问性能,一般是通过优化磁盘的访问请求顺序来做到的。
寻道的时间是磁盘访问最耗时的部分,如果请求顺序优化的得当,必然可以节省一些不必要的寻道时间,从而提高磁盘的访问性能。
假设有下面一个请求序列,每个数字代表磁道的位置:
98,183,37,122,14,124,65,67
初始磁头当前的位置是在第 53 磁道。
接下来,分别对以上的序列,作为每个调度算法的例子,那常见的磁盘调度算法有:
- 先来先服务算法
- 最短寻道时间优先算法
- 扫描算法
- 循环扫描算法
- LOOK 与 C-LOOK 算法
先来先服务
先来先服务(First-Come,First-Served,FCFS),顾名思义,先到来的请求,先被服务。
那按照这个序列的话:
98,183,37,122,14,124,65,67
那么,磁盘的写入顺序是从左到右,如下图:
先来先服务算法总共移动了 640 个磁道的距离,这么一看这种算法,比较简单粗暴,但是如果大量进程竞争使用磁盘,请求访问的磁道可能会很分散,那先来先服务算法在性能上就会显得很差,因为寻道时间过长。
最短寻道时间优先
最短寻道时间优先(Shortest Seek First,SSF)算法的工作方式是,优先选择从当前磁头位置所需寻道时间最短的请求,还是以这个序列为例子:
98,183,37,122,14,124,65,67
那么,那么根据距离磁头( 53 位置)最近的请求的算法,具体的请求则会是下列从左到右的顺序:
65,67,37,14,98,122,124,183
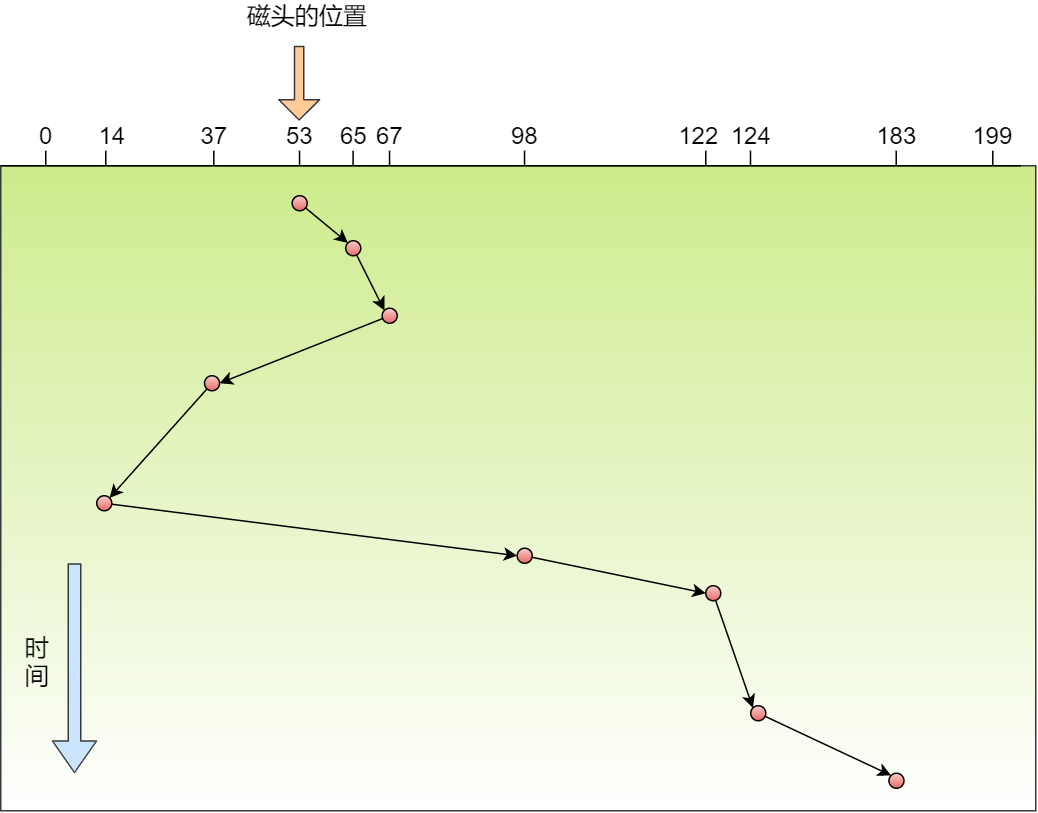
磁头移动的总距离是 236 磁道,相比先来先服务性能提高了不少。
但这个算法可能存在某些请求的饥饿,因为本次例子我们是静态的序列,看不出问题,假设是一个动态的请求,如果后续来的请求都是小于 183 磁道的,那么 183 磁道可能永远不会被响应,于是就产生了饥饿现象,这里产生饥饿的原因是磁头在一小块区域来回移动。
扫描算法
最短寻道时间优先算法会产生饥饿的原因在于:磁头有可能再一个小区域内来回得移动。
为了防止这个问题,可以规定:磁头在一个方向上移动,访问所有未完成的请求,直到磁头到达该方向上的最后的磁道,才调换方向,这就是扫描(*Scan*)算法。
这种算法也叫做电梯算法,比如电梯保持按一个方向移动,直到在那个方向上没有请求为止,然后改变方向。
还是以这个序列为例子,磁头的初始位置是 53:
98,183,37,122,14,124,65,67
那么,假设扫描调度算先朝磁道号减少的方向移动,具体请求则会是下列从左到右的顺序:
37,14,0,65,67,98,122,124,183
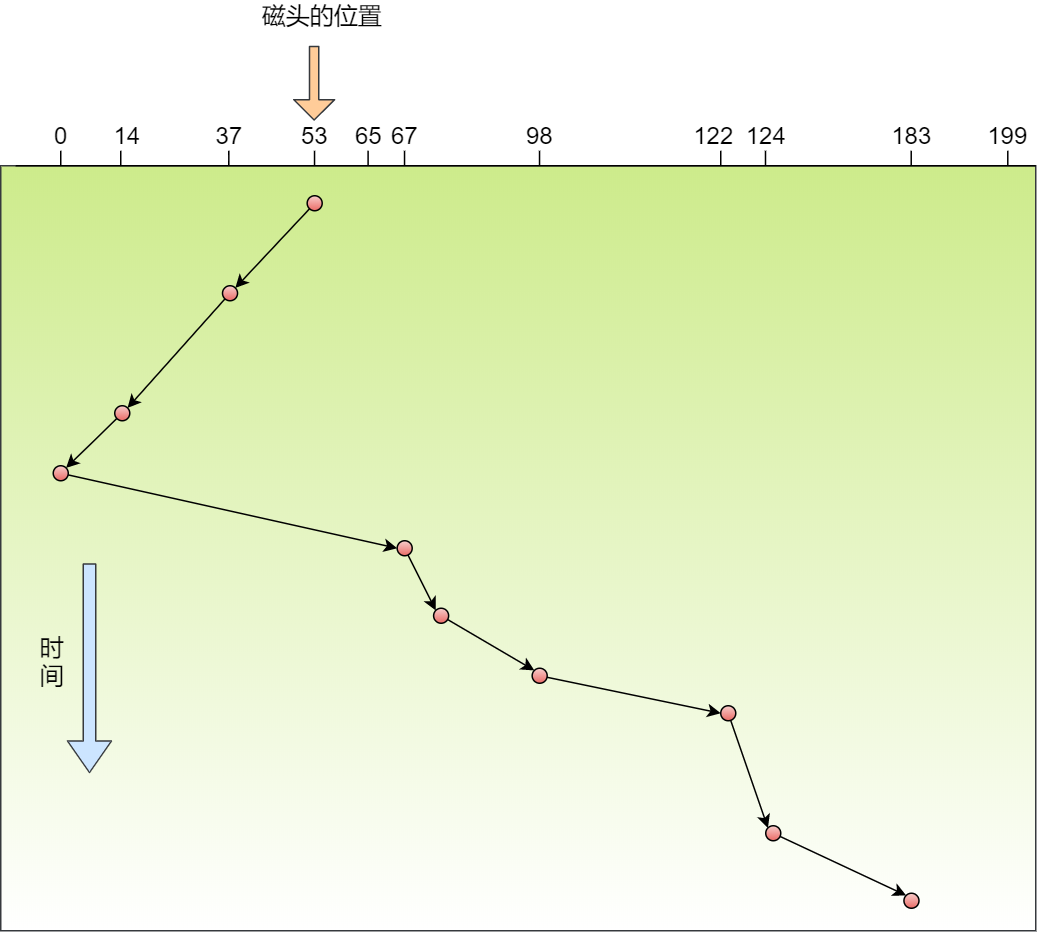
磁头先响应左边的请求,直到到达最左端( 0 磁道)后,才开始反向移动,响应右边的请求。
扫描调度算法性能较好,不会产生饥饿现象,但是存在这样的问题,中间部分的磁道会比较占便宜,中间部分相比其他部分响应的频率会比较多,也就是说每个磁道的响应频率存在差异。
循环扫描算法
扫描算法使得每个磁道响应的频率存在差异,那么要优化这个问题的话,可以总是按相同的方向进行扫描,使得每个磁道的响应频率基本一致。
循环扫描(Circular Scan, CSCAN )规定:只有磁头朝某个特定方向移动时,才处理磁道访问请求,而返回时直接快速移动至最靠边缘的磁道,也就是复位磁头,这个过程是很快的,并且返回中途不处理任何请求,该算法的特点,就是磁道只响应一个方向上的请求。
还是以这个序列为例子,磁头的初始位置是 53:
98,183,37,122,14,124,65,67
那么,假设循环扫描调度算先朝磁道增加的方向移动,具体请求会是下列从左到右的顺序:
65,67,98,122,124,183,199,0,14,37
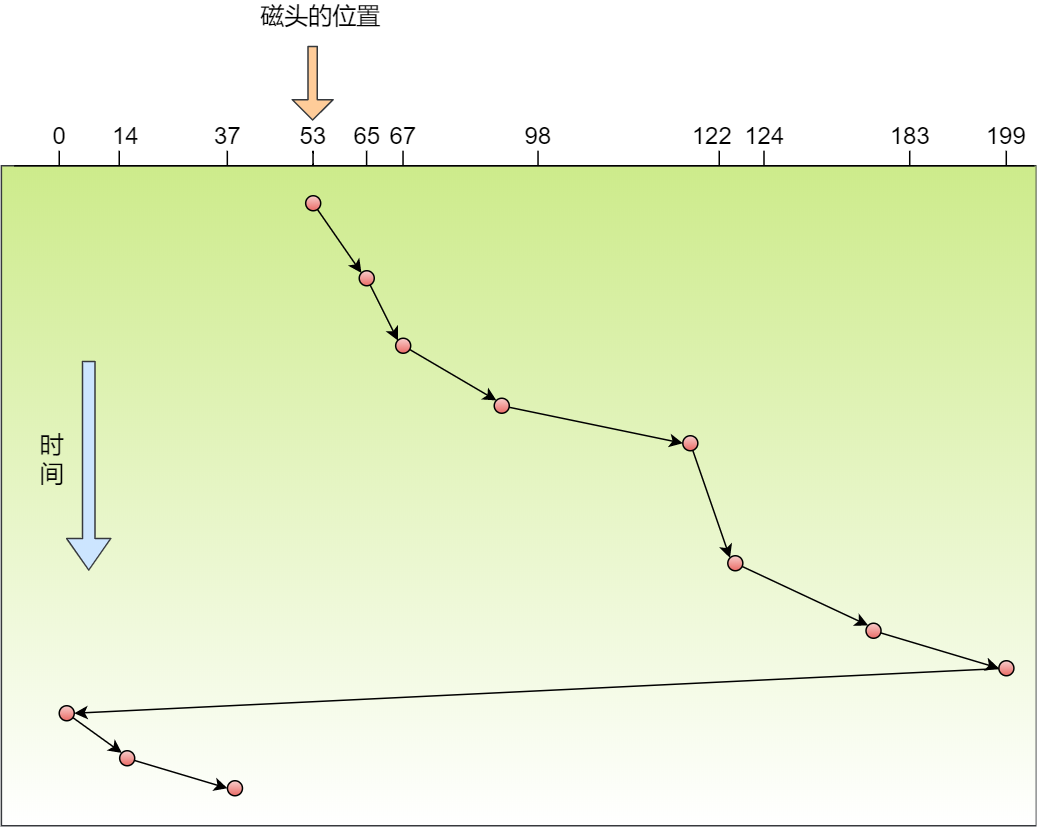
磁头先响应了右边的请求,直到碰到了最右端的磁道 199,就立即回到磁盘的开始处(磁道 0),但这个返回的途中是不响应任何请求的,直到到达最开始的磁道后,才继续顺序响应右边的请求。
循环扫描算法相比于扫描算法,对于各个位置磁道响应频率相对比较平均。
LOOK 与 C-LOOK算法
我们前面说到的扫描算法和循环扫描算法,都是磁头移动到磁盘「最始端或最末端」才开始调换方向。
那这其实是可以优化的,优化的思路就是磁头在移动到「最远的请求」位置,然后立即反向移动。
那针对 SCAN 算法的优化则叫 LOOK 算法,它的工作方式,磁头在每个方向上仅仅移动到最远的请求位置,然后立即反向移动,而不需要移动到磁盘的最始端或最末端,反向移动的途中会响应请求。
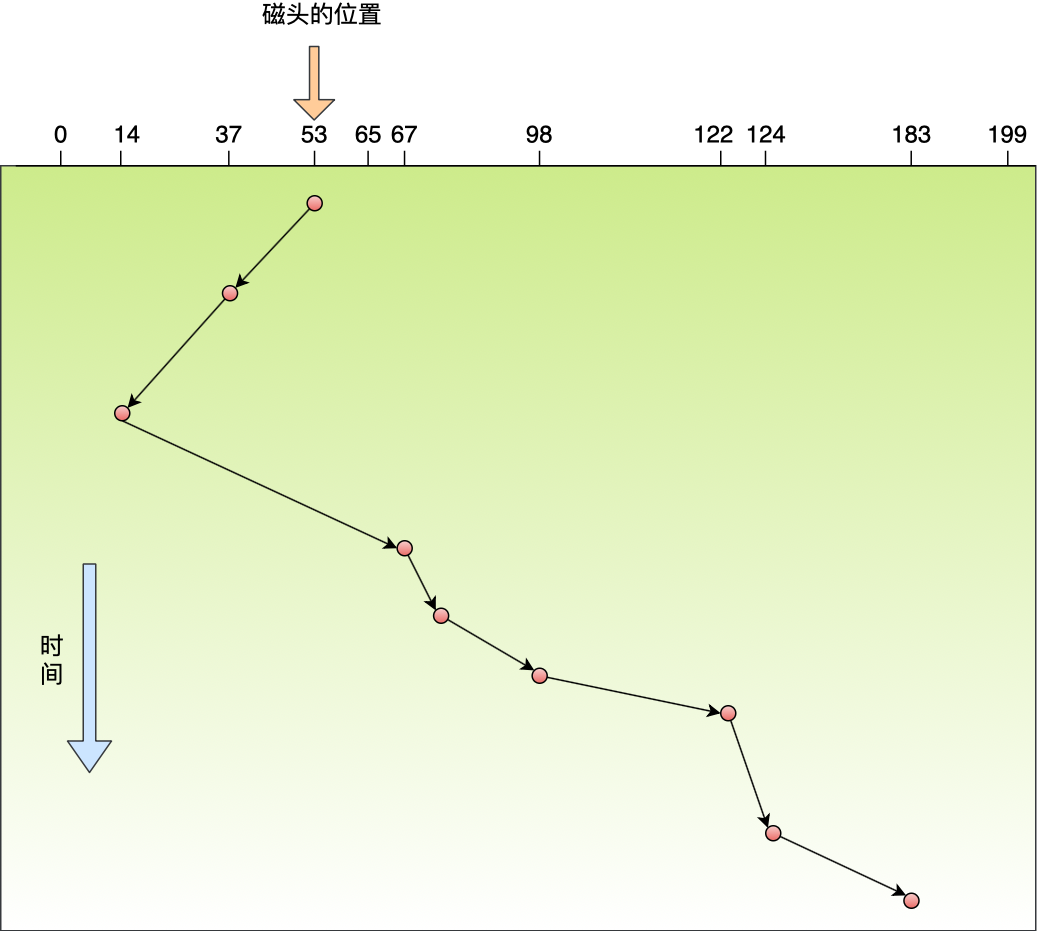
而针 C-SCAN 算法的优化则叫 C-LOOK,它的工作方式,磁头在每个方向上仅仅移动到最远的请求位置,然后立即反向移动,而不需要移动到磁盘的最始端或最末端,反向移动的途中不会响应请求。
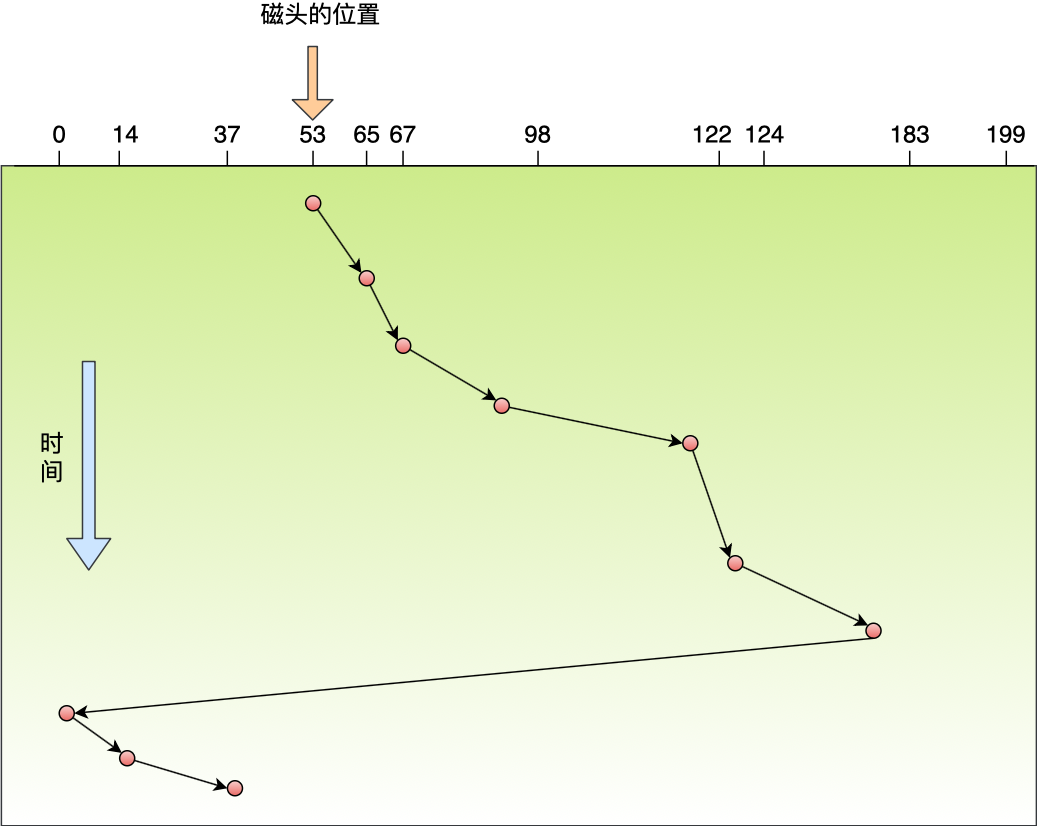
文件系统
文件系统全家桶
不多 BB,直接上「硬菜」。
文件系统的基本组成
文件系统是操作系统中负责管理持久数据的子系统,说简单点,就是负责把用户的文件存到磁盘硬件中,因为即使计算机断电了,磁盘里的数据并不会丢失,所以可以持久化的保存文件。
文件系统的基本数据单位是文件,它的目的是对磁盘上的文件进行组织管理,那组织的方式不同,就会形成不同的文件系统。
Linux 最经典的一句话是:「一切皆文件」,不仅普通的文件和目录,就连块设备、管道、socket 等,也都是统一交给文件系统管理的。
Linux 文件系统会为每个文件分配两个数据结构:索引节点(*index node*)和目录项(*directory entry*),它们主要用来记录文件的元信息和目录层次结构。
- 索引节点,也就是 inode,用来记录文件的元信息,比如 inode 编号、文件大小、访问权限、创建时间、修改时间、数据在磁盘的位置等等。索引节点是文件的唯一标识,它们之间一一对应,也同样都会被存储在硬盘中,所以索引节点同样占用磁盘空间。
- 目录项,也就是 dentry,用来记录文件的名字、索引节点指针以及与其他目录项的层级关联关系。多个目录项关联起来,就会形成目录结构,但它与索引节点不同的是,目录项是由内核维护的一个数据结构,不存放于磁盘,而是缓存在内存。
由于索引节点唯一标识一个文件,而目录项记录着文件的名字,所以目录项和索引节点的关系是多对一,也就是说,一个文件可以有多个别名。比如,硬链接的实现就是多个目录项中的索引节点指向同一个文件。
注意,目录也是文件,也是用索引节点唯一标识,和普通文件不同的是,普通文件在磁盘里面保存的是文件数据,而目录文件在磁盘里面保存子目录或文件。
目录项和目录是一个东西吗?
虽然名字很相近,但是它们不是一个东西,目录是个文件,持久化存储在磁盘,而目录项是内核一个数据结构,缓存在内存。
如果查询目录频繁从磁盘读,效率会很低,所以内核会把已经读过的目录用目录项这个数据结构缓存在内存,下次再次读到相同的目录时,只需从内存读就可以,大大提高了文件系统的效率。
注意,目录项这个数据结构不只是表示目录,也是可以表示文件的。
那文件数据是如何存储在磁盘的呢?
磁盘读写的最小单位是扇区,扇区的大小只有 512B 大小,很明显,如果每次读写都以这么小为单位,那这读写的效率会非常低。
所以,文件系统把多个扇区组成了一个逻辑块,每次读写的最小单位就是逻辑块(数据块),Linux 中的逻辑块大小为 4KB,也就是一次性读写 8 个扇区,这将大大提高了磁盘的读写的效率。
以上就是索引节点、目录项以及文件数据的关系,下面这个图就很好的展示了它们之间的关系:
索引节点是存储在硬盘上的数据,那么为了加速文件的访问,通常会把索引节点加载到内存中。
另外,磁盘进行格式化的时候,会被分成三个存储区域,分别是超级块、索引节点区和数据块区。
- 超级块,用来存储文件系统的详细信息,比如块个数、块大小、空闲块等等。
- 索引节点区,用来存储索引节点;
- 数据块区,用来存储文件或目录数据;
我们不可能把超级块和索引节点区全部加载到内存,这样内存肯定撑不住,所以只有当需要使用的时候,才将其加载进内存,它们加载进内存的时机是不同的:
- 超级块:当文件系统挂载时进入内存;
- 索引节点区:当文件被访问时进入内存;
虚拟文件系统
文件系统的种类众多,而操作系统希望对用户提供一个统一的接口,于是在用户层与文件系统层引入了中间层,这个中间层就称为虚拟文件系统(*Virtual File System,VFS*)。
VFS 定义了一组所有文件系统都支持的数据结构和标准接口,这样程序员不需要了解文件系统的工作原理,只需要了解 VFS 提供的统一接口即可。
在 Linux 文件系统中,用户空间、系统调用、虚拟文件系统、缓存、文件系统以及存储之间的关系如下图:
Linux 支持的文件系统也不少,根据存储位置的不同,可以把文件系统分为三类:
- 磁盘的文件系统,它是直接把数据存储在磁盘中,比如 Ext 2/3/4、XFS 等都是这类文件系统。
- 内存的文件系统,这类文件系统的数据不是存储在硬盘的,而是占用内存空间,我们经常用到的
/proc和/sys文件系统都属于这一类,读写这类文件,实际上是读写内核中相关的数据。 - 网络的文件系统,用来访问其他计算机主机数据的文件系统,比如 NFS、SMB 等等。
文件系统首先要先挂载到某个目录才可以正常使用,比如 Linux 系统在启动时,会把文件系统挂载到根目录。
文件的使用
我们从用户角度来看文件的话,就是我们要怎么使用文件?首先,我们得通过系统调用来打开一个文件。

|
|
上面简单的代码是读取一个文件的过程:
- 首先用
open系统调用打开文件,open的参数中包含文件的路径名和文件名。 - 使用
write写数据,其中write使用open所返回的文件描述符,并不使用文件名作为参数。 - 使用完文件后,要用
close系统调用关闭文件,避免资源的泄露。
我们打开了一个文件后,操作系统会跟踪进程打开的所有文件,所谓的跟踪呢,就是操作系统为每个进程维护一个打开文件表,文件表里的每一项代表「文件描述符」,所以说文件描述符是打开文件的标识。
操作系统在打开文件表中维护着打开文件的状态和信息:
- 文件指针:系统跟踪上次读写位置作为当前文件位置指针,这种指针对打开文件的某个进程来说是唯一的;
- 文件打开计数器:文件关闭时,操作系统必须重用其打开文件表条目,否则表内空间不够用。因为多个进程可能打开同一个文件,所以系统在删除打开文件条目之前,必须等待最后一个进程关闭文件,该计数器跟踪打开和关闭的数量,当该计数为 0 时,系统关闭文件,删除该条目;
- 文件磁盘位置:绝大多数文件操作都要求系统修改文件数据,该信息保存在内存中,以免每个操作都从磁盘中读取;
- 访问权限:每个进程打开文件都需要有一个访问模式(创建、只读、读写、添加等),该信息保存在进程的打开文件表中,以便操作系统能允许或拒绝之后的 I/O 请求;
在用户视角里,文件就是一个持久化的数据结构,但操作系统并不会关心你想存在磁盘上的任何的数据结构,操作系统的视角是如何把文件数据和磁盘块对应起来。
所以,用户和操作系统对文件的读写操作是有差异的,用户习惯以字节的方式读写文件,而操作系统则是以数据块来读写文件,那屏蔽掉这种差异的工作就是文件系统了。
我们来分别看一下,读文件和写文件的过程:
- 当用户进程从文件读取 1 个字节大小的数据时,文件系统则需要获取字节所在的数据块,再返回数据块对应的用户进程所需的数据部分。
- 当用户进程把 1 个字节大小的数据写进文件时,文件系统则找到需要写入数据的数据块的位置,然后修改数据块中对应的部分,最后再把数据块写回磁盘。
所以说,文件系统的基本操作单位是数据块。
文件的存储
文件的数据是要存储在硬盘上面的,数据在磁盘上的存放方式,就像程序在内存中存放的方式那样,有以下两种:
- 连续空间存放方式
- 非连续空间存放方式
其中,非连续空间存放方式又可以分为「链表方式」和「索引方式」。
不同的存储方式,有各自的特点,重点是要分析它们的存储效率和读写性能,接下来分别对每种存储方式说一下。
连续空间存放方式
连续空间存放方式顾名思义,文件存放在磁盘「连续的」物理空间中。这种模式下,文件的数据都是紧密相连,读写效率很高,因为一次磁盘寻道就可以读出整个文件。
使用连续存放的方式有一个前提,必须先知道一个文件的大小,这样文件系统才会根据文件的大小在磁盘上找到一块连续的空间分配给文件。
所以,文件头里需要指定「起始块的位置」和「长度」,有了这两个信息就可以很好的表示文件存放方式是一块连续的磁盘空间。
注意,此处说的文件头,就类似于 Linux 的 inode。
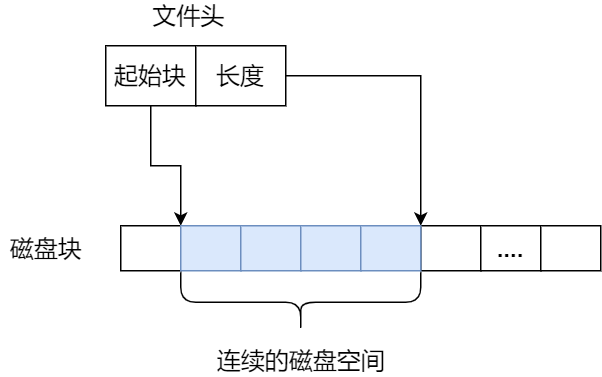
连续空间存放的方式虽然读写效率高,但是有「磁盘空间碎片」和「文件长度不易扩展」的缺陷。
如下图,如果文件 B 被删除,磁盘上就留下一块空缺,这时,如果新来的文件小于其中的一个空缺,我们就可以将其放在相应空缺里。但如果该文件的大小大于所有的空缺,但却小于空缺大小之和,则虽然磁盘上有足够的空缺,但该文件还是不能存放。当然了,我们可以通过将现有文件进行挪动来腾出空间以容纳新的文件,但是这个在磁盘挪动文件是非常耗时,所以这种方式不太现实。
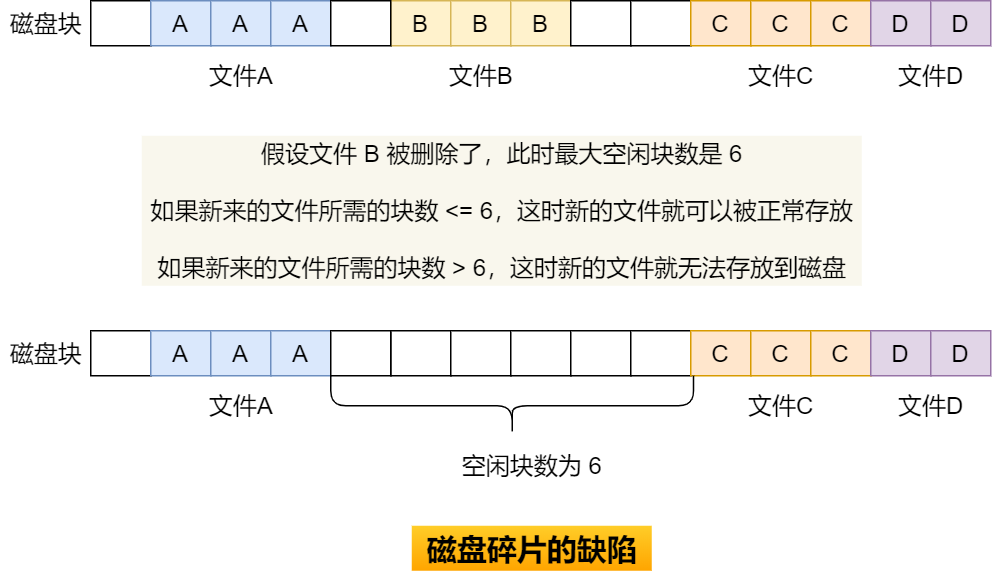
另外一个缺陷是文件长度扩展不方便,例如上图中的文件 A 要想扩大一下,需要更多的磁盘空间,唯一的办法就只能是挪动的方式,前面也说了,这种方式效率是非常低的。
那么有没有更好的方式来解决上面的问题呢?答案当然有,既然连续空间存放的方式不太行,那么我们就改变存放的方式,使用非连续空间存放方式来解决这些缺陷。
非连续空间存放方式
非连续空间存放方式分为「链表方式」和「索引方式」。
我们先来看看链表的方式。
链表的方式存放是离散的,不用连续的,于是就可以消除磁盘碎片,可大大提高磁盘空间的利用率,同时文件的长度可以动态扩展。根据实现的方式的不同,链表可分为「隐式链表」和「显式链接」两种形式。
文件要以「隐式链表」的方式存放的话,实现的方式是文件头要包含「第一块」和「最后一块」的位置,并且每个数据块里面留出一个指针空间,用来存放下一个数据块的位置,这样一个数据块连着一个数据块,从链头开始就可以顺着指针找到所有的数据块,所以存放的方式可以是不连续的。
隐式链表的存放方式的缺点在于无法直接访问数据块,只能通过指针顺序访问文件,以及数据块指针消耗了一定的存储空间。隐式链接分配的稳定性较差,系统在运行过程中由于软件或者硬件错误导致链表中的指针丢失或损坏,会导致文件数据的丢失。
如果取出每个磁盘块的指针,把它放在内存的一个表中,就可以解决上述隐式链表的两个不足。那么,这种实现方式是「显式链接」,它指把用于链接文件各数据块的指针,显式地存放在内存的一张链接表中,该表在整个磁盘仅设置一张,每个表项中存放链接指针,指向下一个数据块号。
对于显式链接的工作方式,我们举个例子,文件 A 依次使用了磁盘块 4、7、2、10 和 12 ,文件 B 依次使用了磁盘块 6、3、11 和 14 。利用下图中的表,可以从第 4 块开始,顺着链走到最后,找到文件 A 的全部磁盘块。同样,从第 6 块开始,顺着链走到最后,也能够找出文件 B 的全部磁盘块。最后,这两个链都以一个不属于有效磁盘编号的特殊标记(如 -1 )结束。内存中的这样一个表格称为文件分配表(*File Allocation Table,FAT*)。
由于查找记录的过程是在内存中进行的,因而不仅显著地提高了检索速度,而且大大减少了访问磁盘的次数。但也正是整个表都存放在内存中的关系,它的主要的缺点是不适用于大磁盘。
比如,对于 200GB 的磁盘和 1KB 大小的块,这张表需要有 2 亿项,每一项对应于这 2 亿个磁盘块中的一个块,每项如果需要 4 个字节,那这张表要占用 800MB 内存,很显然 FAT 方案对于大磁盘而言不太合适。
接下来,我们来看看索引的方式。
链表的方式解决了连续分配的磁盘碎片和文件动态扩展的问题,但是不能有效支持直接访问(FAT除外),索引的方式可以解决这个问题。
索引的实现是为每个文件创建一个「索引数据块」,里面存放的是指向文件数据块的指针列表,说白了就像书的目录一样,要找哪个章节的内容,看目录查就可以。
另外,文件头需要包含指向「索引数据块」的指针,这样就可以通过文件头知道索引数据块的位置,再通过索引数据块里的索引信息找到对应的数据块。
创建文件时,索引块的所有指针都设为空。当首次写入第 i 块时,先从空闲空间中取得一个块,再将其地址写到索引块的第 i 个条目。
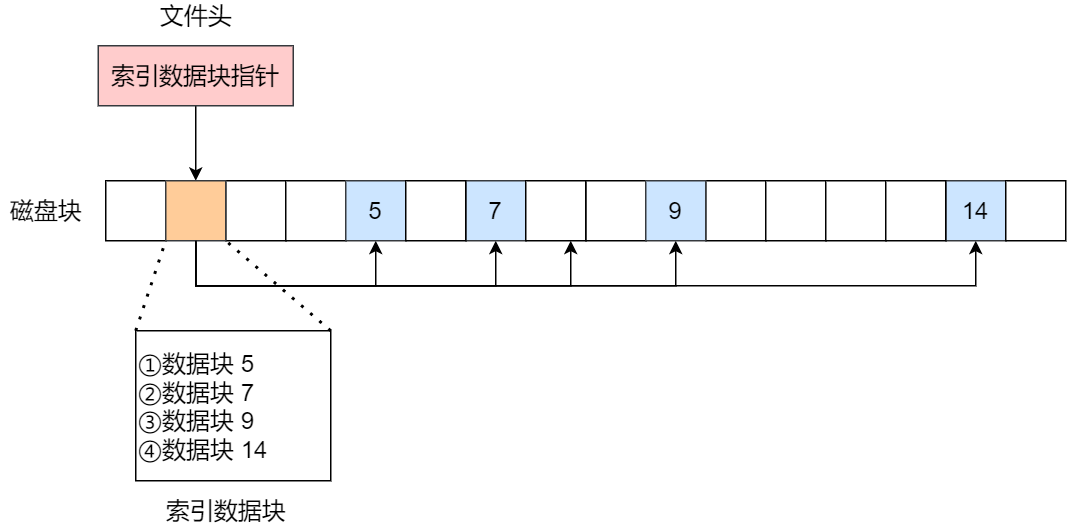
索引的方式优点在于:
- 文件的创建、增大、缩小很方便;
- 不会有碎片的问题;
- 支持顺序读写和随机读写;
由于索引数据也是存放在磁盘块的,如果文件很小,明明只需一块就可以存放的下,但还是需要额外分配一块来存放索引数据,所以缺陷之一就是存储索引带来的开销。
如果文件很大,大到一个索引数据块放不下索引信息,这时又要如何处理大文件的存放呢?我们可以通过组合的方式,来处理大文件的存。
先来看看链表 + 索引的组合,这种组合称为「链式索引块」,它的实现方式是在索引数据块留出一个存放下一个索引数据块的指针,于是当一个索引数据块的索引信息用完了,就可以通过指针的方式,找到下一个索引数据块的信息。那这种方式也会出现前面提到的链表方式的问题,万一某个指针损坏了,后面的数据也就会无法读取了。
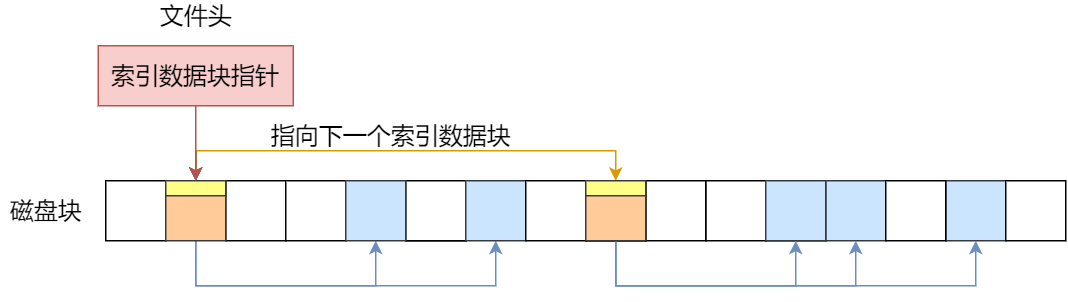
还有另外一种组合方式是索引 + 索引的方式,这种组合称为「多级索引块」,实现方式是通过一个索引块来存放多个索引数据块,一层套一层索引,像极了俄罗斯套娃是吧。
Unix 文件的实现方式
我们先把前面提到的文件实现方式,做个比较:
那早期 Unix 文件系统是组合了前面的文件存放方式的优点,如下图:
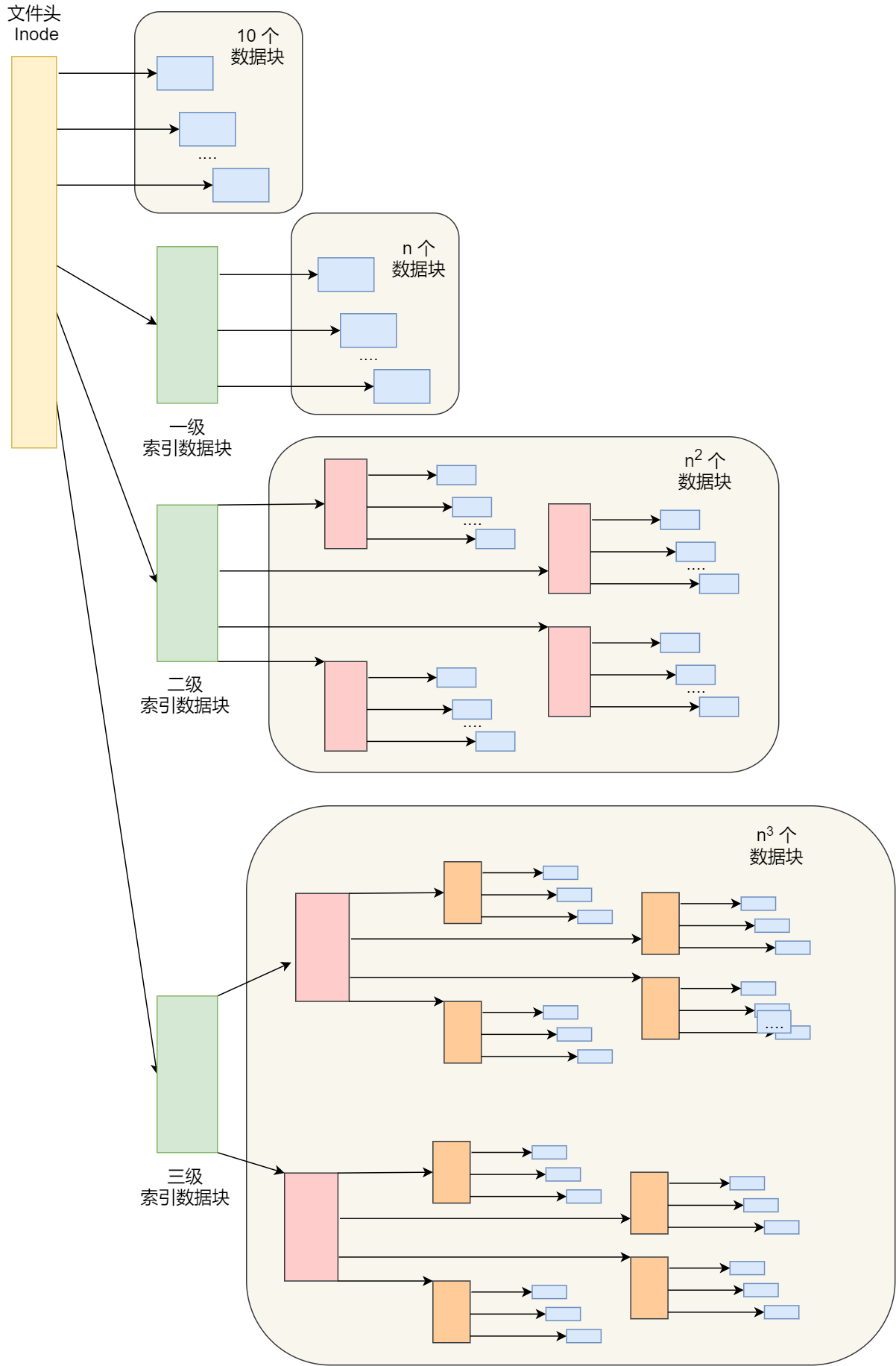
它是根据文件的大小,存放的方式会有所变化:
- 如果存放文件所需的数据块小于 10 块,则采用直接查找的方式;
- 如果存放文件所需的数据块超过 10 块,则采用一级间接索引方式;
- 如果前面两种方式都不够存放大文件,则采用二级间接索引方式;
- 如果二级间接索引也不够存放大文件,这采用三级间接索引方式;
那么,文件头(Inode)就需要包含 13 个指针:
- 10 个指向数据块的指针;
- 第 11 个指向索引块的指针;
- 第 12 个指向二级索引块的指针;
- 第 13 个指向三级索引块的指针;
所以,这种方式能很灵活地支持小文件和大文件的存放:
- 对于小文件使用直接查找的方式可减少索引数据块的开销;
- 对于大文件则以多级索引的方式来支持,所以大文件在访问数据块时需要大量查询;
这个方案就用在了 Linux Ext 2/3 文件系统里,虽然解决大文件的存储,但是对于大文件的访问,需要大量的查询,效率比较低。
为了解决这个问题,Ext 4 做了一定的改变,具体怎么解决的,本文就不展开了。
空闲空间管理
前面说到的文件的存储是针对已经被占用的数据块组织和管理,接下来的问题是,如果我要保存一个数据块,我应该放在硬盘上的哪个位置呢?难道需要将所有的块扫描一遍,找个空的地方随便放吗?
那这种方式效率就太低了,所以针对磁盘的空闲空间也是要引入管理的机制,接下来介绍几种常见的方法:
- 空闲表法
- 空闲链表法
- 位图法
空闲表法
空闲表法就是为所有空闲空间建立一张表,表内容包括空闲区的第一个块号和该空闲区的块个数,注意,这个方式是连续分配的。如下图:

当请求分配磁盘空间时,系统依次扫描空闲表里的内容,直到找到一个合适的空闲区域为止。当用户撤销一个文件时,系统回收文件空间。这时,也需顺序扫描空闲表,寻找一个空闲表条目并将释放空间的第一个物理块号及它占用的块数填到这个条目中。
这种方法仅当有少量的空闲区时才有较好的效果。因为,如果存储空间中有着大量的小的空闲区,则空闲表变得很大,这样查询效率会很低。另外,这种分配技术适用于建立连续文件。
空闲链表法
我们也可以使用「链表」的方式来管理空闲空间,每一个空闲块里有一个指针指向下一个空闲块,这样也能很方便的找到空闲块并管理起来。如下图:
当创建文件需要一块或几块时,就从链头上依次取下一块或几块。反之,当回收空间时,把这些空闲块依次接到链头上。
这种技术只要在主存中保存一个指针,令它指向第一个空闲块。其特点是简单,但不能随机访问,工作效率低,因为每当在链上增加或移动空闲块时需要做很多 I/O 操作,同时数据块的指针消耗了一定的存储空间。
空闲表法和空闲链表法都不适合用于大型文件系统,因为这会使空闲表或空闲链表太大。
位图法
位图是利用二进制的一位来表示磁盘中一个盘块的使用情况,磁盘上所有的盘块都有一个二进制位与之对应。
当值为 0 时,表示对应的盘块空闲,值为 1 时,表示对应的盘块已分配。它形式如下:
|
|
在 Linux 文件系统就采用了位图的方式来管理空闲空间,不仅用于数据空闲块的管理,还用于 inode 空闲块的管理,因为 inode 也是存储在磁盘的,自然也要有对其管理。
文件系统的结构
前面提到 Linux 是用位图的方式管理空闲空间,用户在创建一个新文件时,Linux 内核会通过 inode 的位图找到空闲可用的 inode,并进行分配。要存储数据时,会通过块的位图找到空闲的块,并分配,但仔细计算一下还是有问题的。
数据块的位图是放在磁盘块里的,假设是放在一个块里,一个块 4K,每位表示一个数据块,共可以表示 4 * 1024 * 8 = 2^15 个空闲块,由于 1 个数据块是 4K 大小,那么最大可以表示的空间为 2^15 * 4 * 1024 = 2^27 个 byte,也就是 128M。
也就是说按照上面的结构,如果采用「一个块的位图 + 一系列的块」,外加「一个块的 inode 的位图 + 一系列的 inode 的结构」能表示的最大空间也就 128M,这太少了,现在很多文件都比这个大。
在 Linux 文件系统,把这个结构称为一个块组,那么有 N 多的块组,就能够表示 N 大的文件。
下图给出了 Linux Ext2 整个文件系统的结构和块组的内容,文件系统都由大量块组组成,在硬盘上相继排布:
最前面的第一个块是引导块,在系统启动时用于启用引导,接着后面就是一个一个连续的块组了,块组的内容如下:
- 超级块,包含的是文件系统的重要信息,比如 inode 总个数、块总个数、每个块组的 inode 个数、每个块组的块个数等等。
- 块组描述符,包含文件系统中各个块组的状态,比如块组中空闲块和 inode 的数目等,每个块组都包含了文件系统中「所有块组的组描述符信息」。
- 数据位图和 inode 位图, 用于表示对应的数据块或 inode 是空闲的,还是被使用中。
- inode 列表,包含了块组中所有的 inode,inode 用于保存文件系统中与各个文件和目录相关的所有元数据。
- 数据块,包含文件的有用数据。
你可以会发现每个块组里有很多重复的信息,比如超级块和块组描述符表,这两个都是全局信息,而且非常的重要,这么做是有两个原因:
- 如果系统崩溃破坏了超级块或块组描述符,有关文件系统结构和内容的所有信息都会丢失。如果有冗余的副本,该信息是可能恢复的。
- 通过使文件和管理数据尽可能接近,减少了磁头寻道和旋转,这可以提高文件系统的性能。
不过,Ext2 的后续版本采用了稀疏技术。该做法是,超级块和块组描述符表不再存储到文件系统的每个块组中,而是只写入到块组 0、块组 1 和其他 ID 可以表示为 3、 5、7 的幂的块组中。
目录的存储
在前面,我们知道了一个普通文件是如何存储的,但还有一个特殊的文件,经常用到的目录,它是如何保存的呢?
基于 Linux 一切皆文件的设计思想,目录其实也是个文件,你甚至可以通过 vim 打开它,它也有 inode,inode 里面也是指向一些块。
和普通文件不同的是,普通文件的块里面保存的是文件数据,而目录文件的块里面保存的是目录里面一项一项的文件信息。
在目录文件的块中,最简单的保存格式就是列表,就是一项一项地将目录下的文件信息(如文件名、文件 inode、文件类型等)列在表里。
列表中每一项就代表该目录下的文件的文件名和对应的 inode,通过这个 inode,就可以找到真正的文件。
通常,第一项是「.」,表示当前目录,第二项是「..」,表示上一级目录,接下来就是一项一项的文件名和 inode。
如果一个目录有超级多的文件,我们要想在这个目录下找文件,按照列表一项一项的找,效率就不高了。
于是,保存目录的格式改成哈希表,对文件名进行哈希计算,把哈希值保存起来,如果我们要查找一个目录下面的文件名,可以通过名称取哈希。如果哈希能够匹配上,就说明这个文件的信息在相应的块里面。
Linux 系统的 ext 文件系统就是采用了哈希表,来保存目录的内容,这种方法的优点是查找非常迅速,插入和删除也较简单,不过需要一些预备措施来避免哈希冲突。
目录查询是通过在磁盘上反复搜索完成,需要不断地进行 I/O 操作,开销较大。所以,为了减少 I/O 操作,把当前使用的文件目录缓存在内存,以后要使用该文件时只要在内存中操作,从而降低了磁盘操作次数,提高了文件系统的访问速度。
软链接和硬链接
有时候我们希望给某个文件取个别名,那么在 Linux 中可以通过硬链接(*Hard Link*) 和软链接(*Symbolic Link*) 的方式来实现,它们都是比较特殊的文件,但是实现方式也是不相同的。
硬链接是多个目录项中的「索引节点」指向一个文件,也就是指向同一个 inode,但是 inode 是不可能跨越文件系统的,每个文件系统都有各自的 inode 数据结构和列表,所以硬链接是不可用于跨文件系统的。由于多个目录项都是指向一个 inode,那么只有删除文件的所有硬链接以及源文件时,系统才会彻底删除该文件。
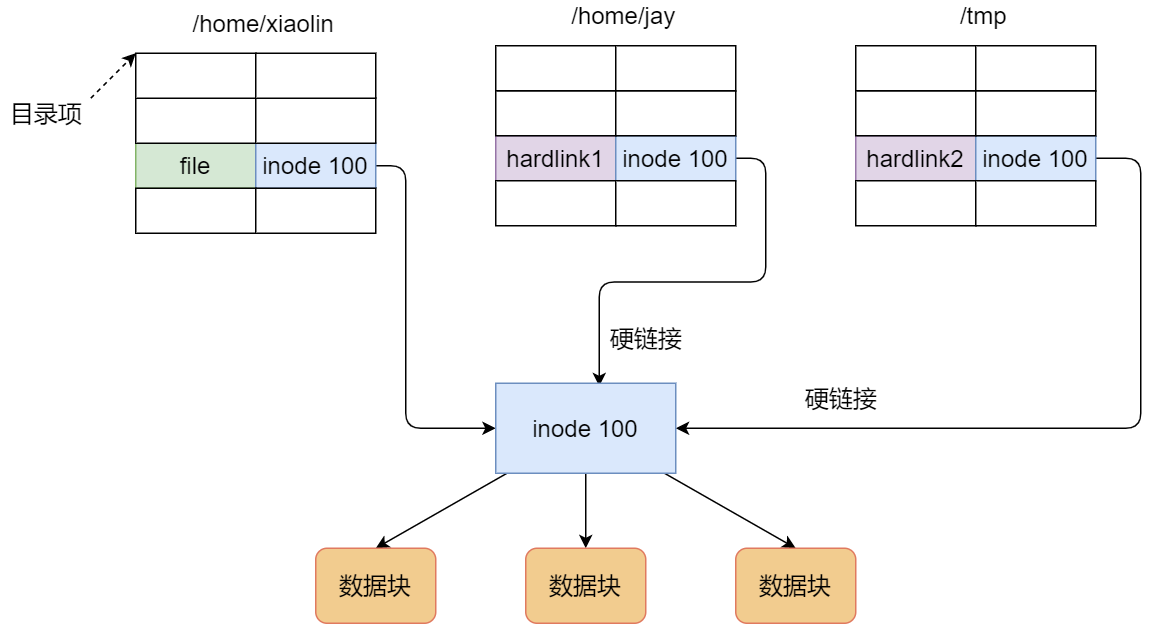
软链接相当于重新创建一个文件,这个文件有独立的 inode,但是这个文件的内容是另外一个文件的路径,所以访问软链接的时候,实际上相当于访问到了另外一个文件,所以软链接是可以跨文件系统的,甚至目标文件被删除了,链接文件还是在的,只不过指向的文件找不到了而已。
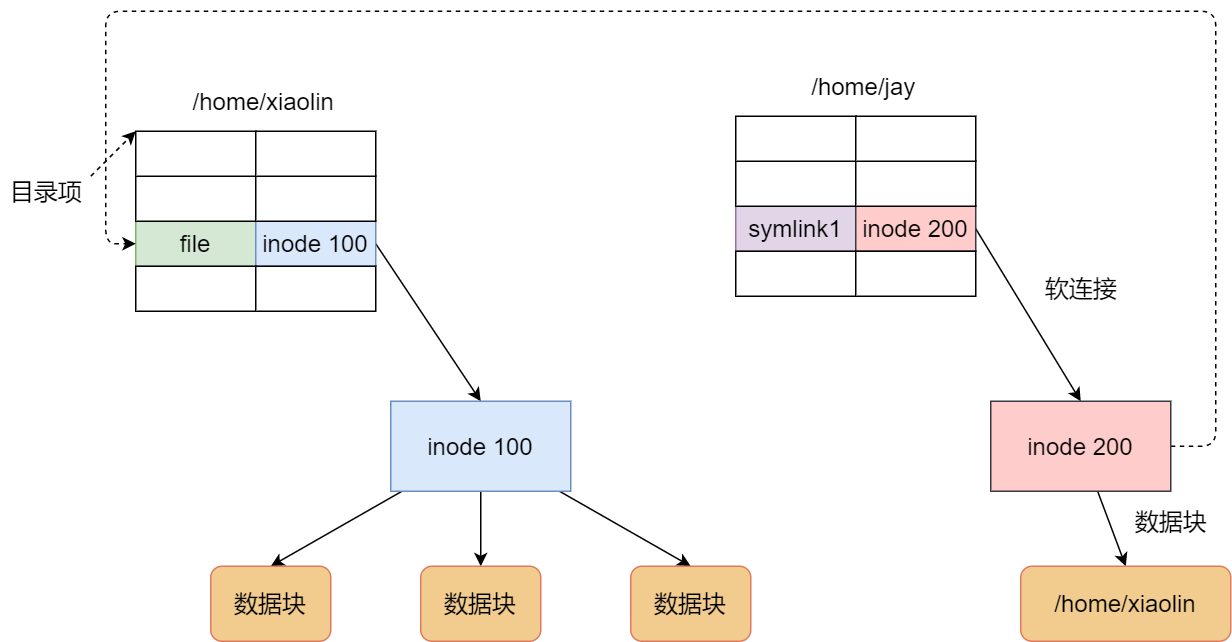
文件 I/O
文件的读写方式各有千秋,对于文件的 I/O 分类也非常多,常见的有
- 缓冲与非缓冲 I/O
- 直接与非直接 I/O
- 阻塞与非阻塞 I/O VS 同步与异步 I/O
接下来,分别对这些分类讨论讨论。
缓冲与非缓冲 I/O
文件操作的标准库是可以实现数据的缓存,那么根据「是否利用标准库缓冲」,可以把文件 I/O 分为缓冲 I/O 和非缓冲 I/O:
- 缓冲 I/O,利用的是标准库的缓存实现文件的加速访问,而标准库再通过系统调用访问文件。
- 非缓冲 I/O,直接通过系统调用访问文件,不经过标准库缓存。
这里所说的「缓冲」特指标准库内部实现的缓冲。
比方说,很多程序遇到换行时才真正输出,而换行前的内容,其实就是被标准库暂时缓存了起来,这样做的目的是,减少系统调用的次数,毕竟系统调用是有 CPU 上下文切换的开销的。
直接与非直接 I/O
我们都知道磁盘 I/O 是非常慢的,所以 Linux 内核为了减少磁盘 I/O 次数,在系统调用后,会把用户数据拷贝到内核中缓存起来,这个内核缓存空间也就是「页缓存」,只有当缓存满足某些条件的时候,才发起磁盘 I/O 的请求。
那么,根据「是否利用操作系统的缓存」,可以把文件 I/O 分为直接 I/O 与非直接 I/O:
- 直接 I/O,不会发生内核缓存和用户程序之间数据复制,而是直接经过文件系统访问磁盘。
- 非直接 I/O,读操作时,数据从内核缓存中拷贝给用户程序,写操作时,数据从用户程序拷贝给内核缓存,再由内核决定什么时候写入数据到磁盘。
如果你在使用文件操作类的系统调用函数时,指定了 O_DIRECT 标志,则表示使用直接 I/O。如果没有设置过,默认使用的是非直接 I/O。
如果用了非直接 I/O 进行写数据操作,内核什么情况下才会把缓存数据写入到磁盘?
以下几种场景会触发内核缓存的数据写入磁盘:
- 在调用
write的最后,当发现内核缓存的数据太多的时候,内核会把数据写到磁盘上; - 用户主动调用
sync,内核缓存会刷到磁盘上; - 当内存十分紧张,无法再分配页面时,也会把内核缓存的数据刷到磁盘上;
- 内核缓存的数据的缓存时间超过某个时间时,也会把数据刷到磁盘上;
阻塞与非阻塞 I/O VS 同步与异步 I/O
为什么把阻塞 / 非阻塞与同步与异步放一起说的呢?因为它们确实非常相似,也非常容易混淆,不过它们之间的关系还是有点微妙的。
先来看看阻塞 I/O,当用户程序执行 read ,线程会被阻塞,一直等到内核数据准备好,并把数据从内核缓冲区拷贝到应用程序的缓冲区中,当拷贝过程完成,read 才会返回。
注意,阻塞等待的是「内核数据准备好」和「数据从内核态拷贝到用户态」这两个过程。过程如下图:
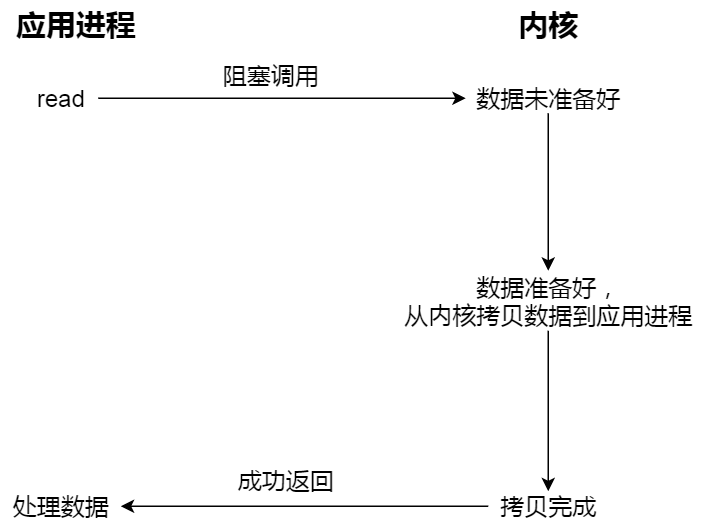
知道了阻塞 I/O ,来看看非阻塞 I/O,非阻塞的 read 请求在数据未准备好的情况下立即返回,可以继续往下执行,此时应用程序不断轮询内核,直到数据准备好,内核将数据拷贝到应用程序缓冲区,read 调用才可以获取到结果。过程如下图:
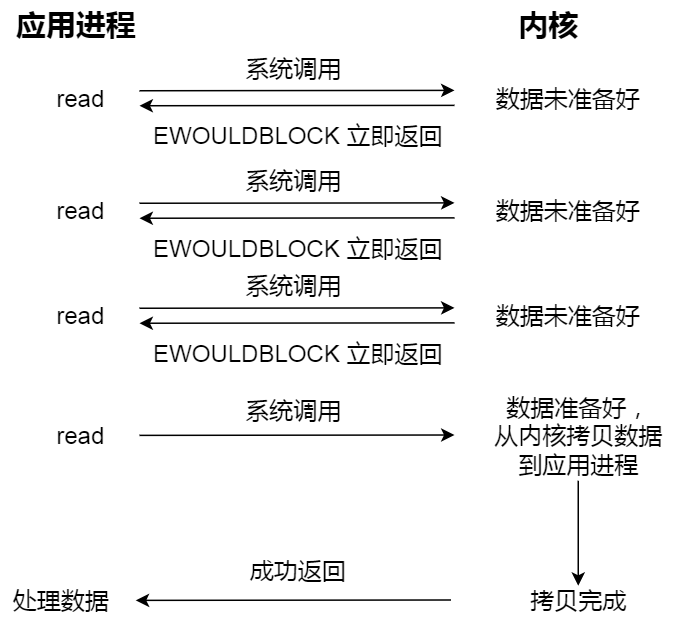
注意,这里最后一次 read 调用,获取数据的过程,是一个同步的过程,是需要等待的过程。这里的同步指的是内核态的数据拷贝到用户程序的缓存区这个过程。
举个例子,访问管道或 socket 时,如果设置了 O_NONBLOCK 标志,那么就表示使用的是非阻塞 I/O 的方式访问,而不做任何设置的话,默认是阻塞 I/O。
应用程序每次轮询内核的 I/O 是否准备好,感觉有点傻乎乎,因为轮询的过程中,应用程序啥也做不了,只是在循环。
为了解决这种傻乎乎轮询方式,于是 I/O 多路复用技术就出来了,如 select、poll,它是通过 I/O 事件分发,当内核数据准备好时,再以事件通知应用程序进行操作。
这个做法大大改善了 CPU 的利用率,因为当调用了 I/O 多路复用接口,如果没有事件发生,那么当前线程就会发生阻塞,这时 CPU 会切换其他线程执行任务,等内核发现有事件到来的时候,会唤醒阻塞在 I/O 多路复用接口的线程,然后用户可以进行后续的事件处理。
整个流程要比阻塞 IO 要复杂,似乎也更浪费性能。但 I/O 多路复用接口最大的优势在于,用户可以在一个线程内同时处理多个 socket 的 IO 请求(参见:I/O 多路复用:select/poll/epoll (opens new window))。用户可以注册多个 socket,然后不断地调用 I/O 多路复用接口读取被激活的 socket,即可达到在同一个线程内同时处理多个 IO 请求的目的。而在同步阻塞模型中,必须通过多线程的方式才能达到这个目的。
下图是使用 select I/O 多路复用过程。注意,read 获取数据的过程(数据从内核态拷贝到用户态的过程),也是一个同步的过程,需要等待:
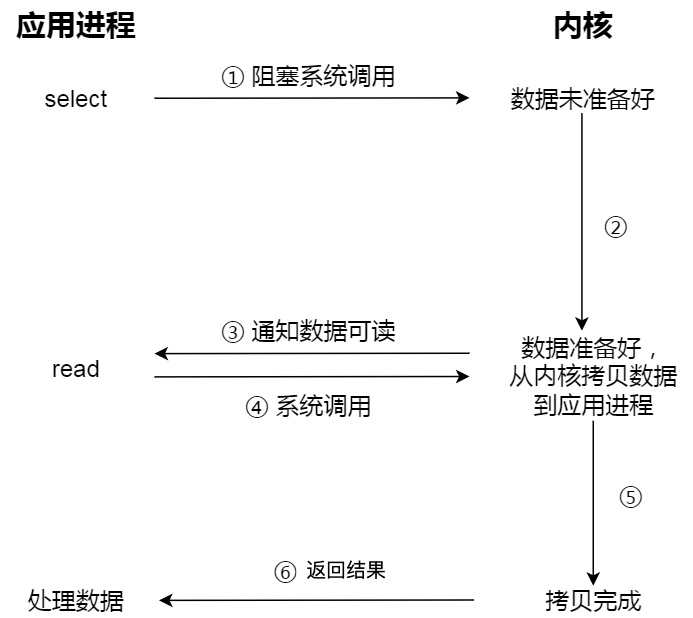
实际上,无论是阻塞 I/O、非阻塞 I/O,还是基于非阻塞 I/O 的多路复用都是同步调用。因为它们在 read 调用时,内核将数据从内核空间拷贝到应用程序空间,过程都是需要等待的,也就是说这个过程是同步的,如果内核实现的拷贝效率不高,read 调用就会在这个同步过程中等待比较长的时间。
而真正的异步 I/O 是「内核数据准备好」和「数据从内核态拷贝到用户态」这两个过程都不用等待。
当我们发起 aio_read 之后,就立即返回,内核自动将数据从内核空间拷贝到应用程序空间,这个拷贝过程同样是异步的,内核自动完成的,和前面的同步操作不一样,应用程序并不需要主动发起拷贝动作。过程如下图:
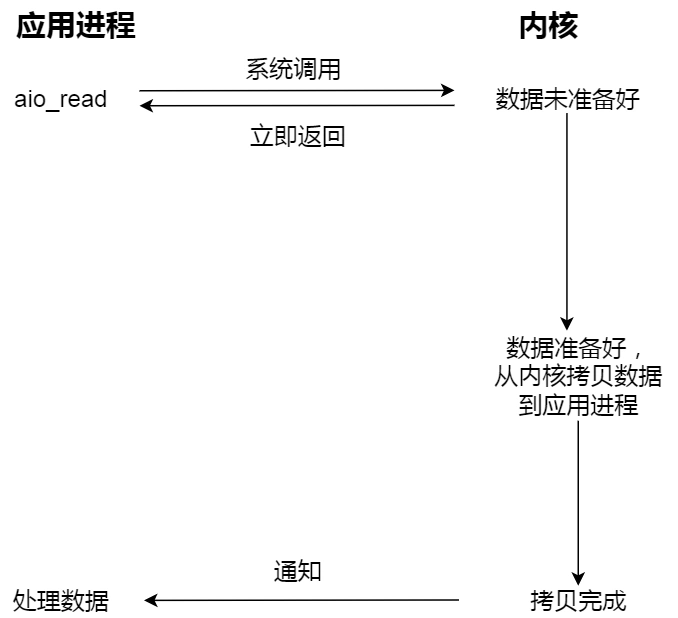
下面这张图,总结了以上几种 I/O 模型:

在前面我们知道了,I/O 是分为两个过程的:
- 数据准备的过程
- 数据从内核空间拷贝到用户进程缓冲区的过程
阻塞 I/O 会阻塞在「过程 1 」和「过程 2」,而非阻塞 I/O 和基于非阻塞 I/O 的多路复用只会阻塞在「过程 2」,所以这三个都可以认为是同步 I/O。
异步 I/O 则不同,「过程 1 」和「过程 2 」都不会阻塞。
用故事去理解这几种 I/O 模型
举个你去饭堂吃饭的例子,你好比用户程序,饭堂好比操作系统。
阻塞 I/O 好比,你去饭堂吃饭,但是饭堂的菜还没做好,然后你就一直在那里等啊等,等了好长一段时间终于等到饭堂阿姨把菜端了出来(数据准备的过程),但是你还得继续等阿姨把菜(内核空间)打到你的饭盒里(用户空间),经历完这两个过程,你才可以离开。
非阻塞 I/O 好比,你去了饭堂,问阿姨菜做好了没有,阿姨告诉你没,你就离开了,过几十分钟,你又来饭堂问阿姨,阿姨说做好了,于是阿姨帮你把菜打到你的饭盒里,这个过程你是得等待的。
基于非阻塞的 I/O 多路复用好比,你去饭堂吃饭,发现有一排窗口,饭堂阿姨告诉你这些窗口都还没做好菜,等做好了再通知你,于是等啊等(select 调用中),过了一会阿姨通知你菜做好了,但是不知道哪个窗口的菜做好了,你自己看吧。于是你只能一个一个窗口去确认,后面发现 5 号窗口菜做好了,于是你让 5 号窗口的阿姨帮你打菜到饭盒里,这个打菜的过程你是要等待的,虽然时间不长。打完菜后,你自然就可以离开了。
异步 I/O 好比,你让饭堂阿姨将菜做好并把菜打到饭盒里后,把饭盒送到你面前,整个过程你都不需要任何等待。
进程写文件时,进程发生了崩溃,已写入的数据会丢失吗?
前几天,有位读者问了我这么个问题:
大概就是,进程写文件(使用缓冲 IO)过程中,写一半的时候,进程发生了崩溃,已写入的数据会丢失吗?
答案,是不会的。
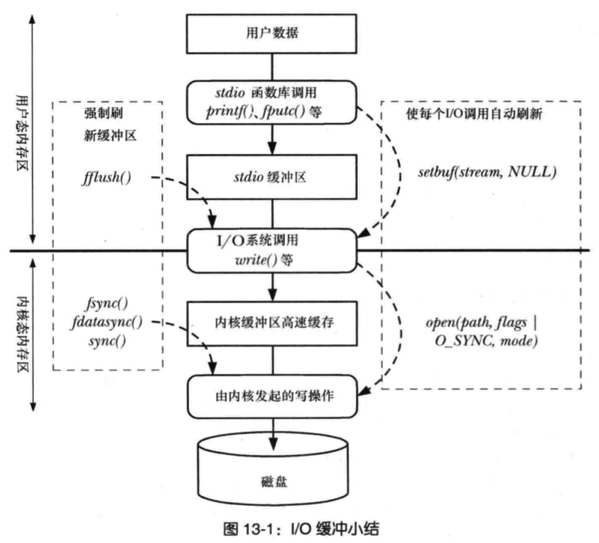
因为进程在执行 write (使用缓冲 IO)系统调用的时候,实际上是将文件数据写到了内核的 page cache,它是文件系统中用于缓存文件数据的缓冲,所以即使进程崩溃了,文件数据还是保留在内核的 page cache,我们读数据的时候,也是从内核的 page cache 读取,因此还是依然读的进程崩溃前写入的数据。
内核会找个合适的时机,将 page cache 中的数据持久化到磁盘。但是如果 page cache 里的文件数据,在持久化到磁盘化到磁盘之前,系统发生了崩溃,那这部分数据就会丢失了。
当然, 我们也可以在程序里调用 fsync 函数,在写文文件的时候,立刻将文件数据持久化到磁盘,这样就可以解决系统崩溃导致的文件数据丢失的问题。
我在网上看到一篇介绍 page cache 很好的文章, 分享给大家一起学习。
作者:spongecaptain
原文地址:[Linux 的 Page Cache(opens new window)](https://spongecaptain.cool/SimpleClearFileIO/1. page cache.html)
Page Cache
Page Cache 是什么?
为了理解 Page Cache,我们不妨先看一下 Linux 的文件 I/O 系统,如下图所示:
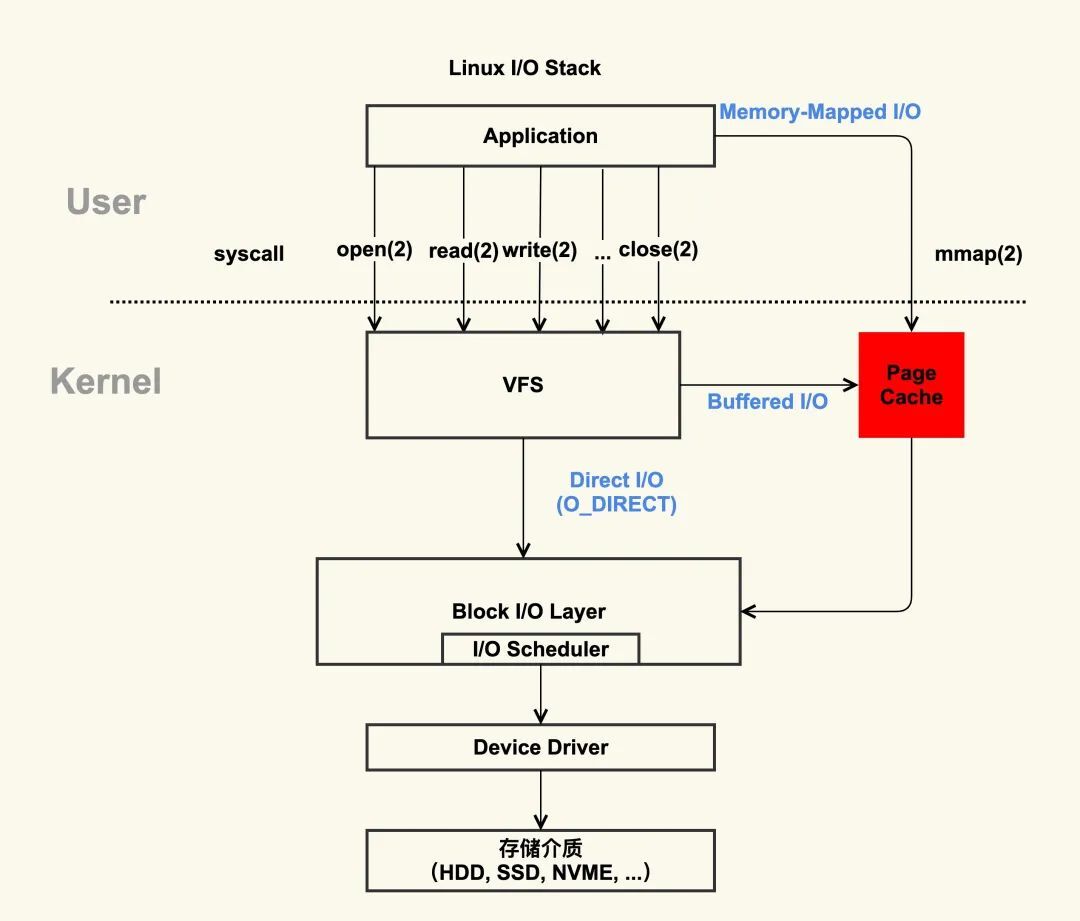
上图中,红色部分为 Page Cache。可见 Page Cache 的本质是由 Linux 内核管理的内存区域。我们通过 mmap 以及 buffered I/O 将文件读取到内存空间实际上都是读取到 Page Cache 中。
如何查看系统的 Page Cache?
通过读取 /proc/meminfo 文件,能够实时获取系统内存情况:
|
|
根据上面的数据,你可以简单得出这样的公式(等式两边之和都是 112696 KB):
|
|
两边等式都是 Page Cache,即:
|
|
通过阅读下面的小节,就能够理解为什么 SwapCached 与 Buffers 也是 Page Cache 的一部分。
page 与 Page Cache
page 是内存管理分配的基本单位, Page Cache 由多个 page 构成。page 在操作系统中通常为 4KB 大小(32bits/64bits),而 Page Cache 的大小则为 4KB 的整数倍。
另一方面,并不是所有 page 都被组织为 Page Cache。
Linux 系统上供用户可访问的内存分为两个类型,即:
- File-backed pages:文件备份页也就是 Page Cache 中的 page,对应于磁盘上的若干数据块;对于这些页最大的问题是脏页回盘;
- Anonymous pages:匿名页不对应磁盘上的任何磁盘数据块,它们是进程的运行是内存空间(例如方法栈、局部变量表等属性);
为什么 Linux 不把 Page Cache 称为 block cache,这不是更好吗?
这是因为从磁盘中加载到内存的数据不仅仅放在 Page Cache 中,还放在 buffer cache 中。
例如通过 Direct I/O 技术的磁盘文件就不会进入 Page Cache 中。当然,这个问题也有 Linux 历史设计的原因,毕竟这只是一个称呼,含义随着 Linux 系统的演进也逐渐不同。
下面比较一下 File-backed pages 与 Anonymous pages 在 Swap 机制下的性能。
内存是一种珍惜资源,当内存不够用时,内存管理单元(Memory Mangament Unit)需要提供调度算法来回收相关内存空间。内存空间回收的方式通常就是 swap,即交换到持久化存储设备上。
File-backed pages(Page Cache)的内存回收代价较低。Page Cache 通常对应于一个文件上的若干顺序块,因此可以通过顺序 I/O 的方式落盘。另一方面,如果 Page Cache 上没有进行写操作(所谓的没有脏页),甚至不会将 Page Cache 回盘,因为数据的内容完全可以通过再次读取磁盘文件得到。
Page Cache 的主要难点在于脏页回盘,这个内容会在后面进行详细说明。
Anonymous pages 的内存回收代价较高。这是因为 Anonymous pages 通常随机地写入持久化交换设备。另一方面,无论是否有写操作,为了确保数据不丢失,Anonymous pages 在 swap 时必须持久化到磁盘。
Swap 与缺页中断
Swap 机制指的是当物理内存不够用,内存管理单元(Memory Mangament Unit,MMU)需要提供调度算法来回收相关内存空间,然后将清理出来的内存空间给当前内存申请方。
Swap 机制存在的本质原因是 Linux 系统提供了虚拟内存管理机制,每一个进程认为其独占内存空间,因此所有进程的内存空间之和远远大于物理内存。所有进程的内存空间之和超过物理内存的部分就需要交换到磁盘上。
操作系统以 page 为单位管理内存,当进程发现需要访问的数据不在内存时,操作系统可能会将数据以页的方式加载到内存中。上述过程被称为缺页中断,当操作系统发生缺页中断时,就会通过系统调用将 page 再次读到内存中。
但主内存的空间是有限的,当主内存中不包含可以使用的空间时,操作系统会从选择合适的物理内存页驱逐回磁盘,为新的内存页让出位置,选择待驱逐页的过程在操作系统中叫做页面替换(Page Replacement),替换操作又会触发 swap 机制。
如果物理内存足够大,那么可能不需要 Swap 机制,但是 Swap 在这种情况下还是有一定优势:对于有发生内存泄漏几率的应用程序(进程),Swap 交换分区更是重要,这可以确保内存泄露不至于导致物理内存不够用,最终导致系统崩溃。但内存泄露会引起频繁的 swap,此时非常影响操作系统的性能。
Linux 通过一个 swappiness 参数来控制 Swap 机制:这个参数值可为 0-100,控制系统 swap 的优先级:
- 高数值:较高频率的 swap,进程不活跃时主动将其转换出物理内存。
- 低数值:较低频率的 swap,这可以确保交互式不因为内存空间频繁地交换到磁盘而提高响应延迟。
最后,为什么 SwapCached 也是 Page Cache 的一部分?
这是因为当匿名页(Inactive(anon) 以及 Active(anon))先被交换(swap out)到磁盘上后,然后再加载回(swap in)内存中,由于读入到内存后原来的 Swap File 还在,所以 SwapCached 也可以认为是 File-backed page,即属于 Page Cache。这个过程如下图所示。
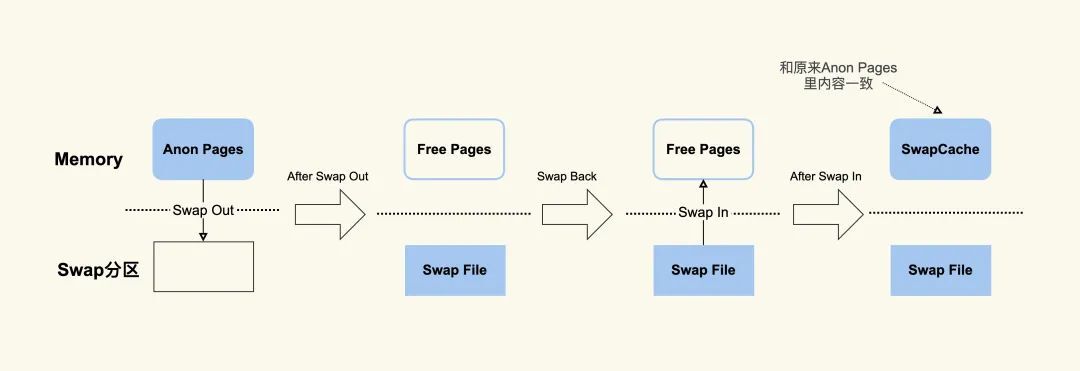
Page Cache 与 buffer cache
执行 free 命令,注意到会有两列名为 buffers 和 cached,也有一行名为 “-/+ buffers/cache”。
|
|
其中,cached 列表示当前的页缓存(Page Cache)占用量,buffers 列表示当前的块缓存(buffer cache)占用量。
用一句话来解释:Page Cache 用于缓存文件的页数据,buffer cache 用于缓存块设备(如磁盘)的块数据。
- 页是逻辑上的概念,因此 Page Cache 是与文件系统同级的;
- 块是物理上的概念,因此 buffer cache 是与块设备驱动程序同级的。
Page Cache 与 buffer cache 的共同目的都是加速数据 I/O:
- 写数据时首先写到缓存,将写入的页标记为 dirty,然后向外部存储 flush,也就是缓存写机制中的 write-back(另一种是 write-through,Linux 默认情况下不采用);
- 读数据时首先读取缓存,如果未命中,再去外部存储读取,并且将读取来的数据也加入缓存。操作系统总是积极地将所有空闲内存都用作 Page Cache 和 buffer cache,当内存不够用时也会用 LRU 等算法淘汰缓存页。
在 Linux 2.4 版本的内核之前,Page Cache 与 buffer cache 是完全分离的。但是,块设备大多是磁盘,磁盘上的数据又大多通过文件系统来组织,这种设计导致很多数据被缓存了两次,浪费内存。
所以在 2.4 版本内核之后,两块缓存近似融合在了一起:如果一个文件的页加载到了 Page Cache,那么同时 buffer cache 只需要维护块指向页的指针就可以了。只有那些没有文件表示的块,或者绕过了文件系统直接操作(如dd命令)的块,才会真正放到 buffer cache 里。
因此,我们现在提起 Page Cache,基本上都同时指 Page Cache 和 buffer cache 两者,本文之后也不再区分,直接统称为 Page Cache。
下图近似地示出 32-bit Linux 系统中可能的一种 Page Cache 结构,其中 block size 大小为 1KB,page size 大小为 4KB。
Page Cache 中的每个文件都是一棵基数树(radix tree,本质上是多叉搜索树),树的每个节点都是一个页。根据文件内的偏移量就可以快速定位到所在的页,如下图所示。关于基数树的原理可以参见英文维基,这里就不细说了。
Page Cache 与预读
操作系统为基于 Page Cache 的读缓存机制提供预读机制(PAGE_READAHEAD),一个例子是:
- 用户线程仅仅请求读取磁盘上文件 A 的 offset 为 0-3KB 范围内的数据,由于磁盘的基本读写单位为 block(4KB),于是操作系统至少会读 0-4KB 的内容,这恰好可以在一个 page 中装下。
- 但是操作系统出于局部性原理会选择将磁盘块 offset [4KB,8KB)、[8KB,12KB) 以及 [12KB,16KB) 都加载到内存,于是额外在内存中申请了 3 个 page;
下图代表了操作系统的预读机制:
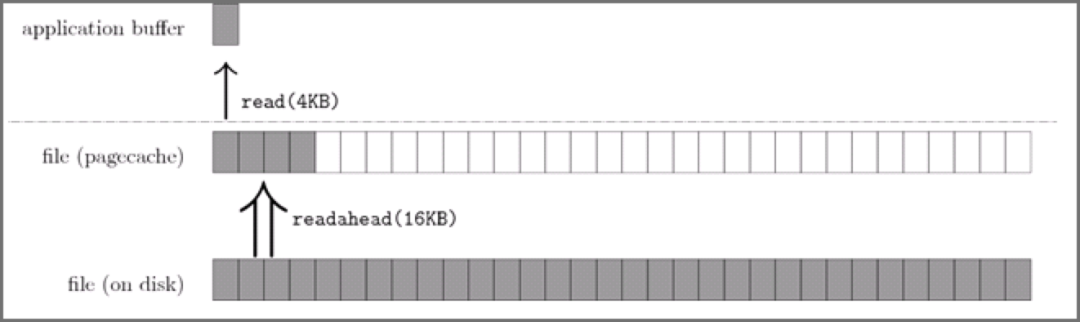
上图中,应用程序利用 read 系统调动读取 4KB 数据,实际上内核使用 readahead 机制完成了 16KB 数据的读取。
Page Cache 与文件持久化的一致性&可靠性
现代 Linux 的 Page Cache 正如其名,是对磁盘上 page(页)的内存缓存,同时可以用于读/写操作。
任何系统引入缓存,就会引发一致性问题:内存中的数据与磁盘中的数据不一致,例如常见后端架构中的 Redis 缓存与 MySQL 数据库就存在一致性问题。
Linux 提供多种机制来保证数据一致性,但无论是单机上的内存与磁盘一致性,还是分布式组件中节点 1 与节点 2 、节点 3 的数据一致性问题,理解的关键是 trade-off:吞吐量与数据一致性保证是一对矛盾。
首先,需要我们理解一下文件的数据。文件 = 数据 + 元数据。元数据用来描述文件的各种属性,也必须存储在磁盘上。因此,我们说保证文件一致性其实包含了两个方面:数据一致+元数据一致。
文件的元数据包括:文件大小、创建时间、访问时间、属主属组等信息。
我们考虑如下一致性问题:如果发生写操作并且对应的数据在 Page Cache 中,那么写操作就会直接作用于 Page Cache 中,此时如果数据还没刷新到磁盘,那么内存中的数据就领先于磁盘,此时对应 page 就被称为 Dirty page。
当前 Linux 下以两种方式实现文件一致性:
- Write Through(写穿):向用户层提供特定接口,应用程序可主动调用接口来保证文件一致性;
- Write back(写回):系统中存在定期任务(表现形式为内核线程),周期性地同步文件系统中文件脏数据块,这是默认的 Linux 一致性方案;
上述两种方式最终都依赖于系统调用,主要分为如下三种系统调用:
| 方法 | 含义 |
|---|---|
| fsync(intfd) | fsync(fd):将 fd 代表的文件的脏数据和脏元数据全部刷新至磁盘中。 |
| fdatasync(int fd) | fdatasync(fd):将 fd 代表的文件的脏数据刷新至磁盘,同时对必要的元数据刷新至磁盘中,这里所说的必要的概念是指:对接下来访问文件有关键作用的信息,如文件大小,而文件修改时间等不属于必要信息 |
| sync() | sync():则是对系统中所有的脏的文件数据元数据刷新至磁盘中 |
上述三种系统调用可以分别由用户进程与内核进程发起。下面我们研究一下内核线程的相关特性。
- 创建的针对回写任务的内核线程数由系统中持久存储设备决定,为每个存储设备创建单独的刷新线程;
- 关于多线程的架构问题,Linux 内核采取了 Lighthttp 的做法,即系统中存在一个管理线程和多个刷新线程(每个持久存储设备对应一个刷新线程)。管理线程监控设备上的脏页面情况,若设备一段时间内没有产生脏页面,就销毁设备上的刷新线程;若监测到设备上有脏页面需要回写且尚未为该设备创建刷新线程,那么创建刷新线程处理脏页面回写。而刷新线程的任务较为单调,只负责将设备中的脏页面回写至持久存储设备中。
- 刷新线程刷新设备上脏页面大致设计如下:
- 每个设备保存脏文件链表,保存的是该设备上存储的脏文件的 inode 节点。所谓的回写文件脏页面即回写该 inode 链表上的某些文件的脏页面;
- 系统中存在多个回写时机,第一是应用程序主动调用回写接口(fsync,fdatasync 以及 sync 等),第二管理线程周期性地唤醒设备上的回写线程进行回写,第三是某些应用程序/内核任务发现内存不足时要回收部分缓存页面而事先进行脏页面回写,设计一个统一的框架来管理这些回写任务非常有必要。
Write Through 与 Write back 在持久化的可靠性上有所不同:
- Write Through 以牺牲系统 I/O 吞吐量作为代价,向上层应用确保一旦写入,数据就已经落盘,不会丢失;
- Write back 在系统发生宕机的情况下无法确保数据已经落盘,因此存在数据丢失的问题。不过,在程序挂了,例如被 kill -9,Page Cache 中的数据操作系统还是会确保落盘;
Page Cache 的优劣势
Page Cache 的优势
1.加快数据访问
如果数据能够在内存中进行缓存,那么下一次访问就不需要通过磁盘 I/O 了,直接命中内存缓存即可。
由于内存访问比磁盘访问快很多,因此加快数据访问是 Page Cache 的一大优势。
2.减少 I/O 次数,提高系统磁盘 I/O 吞吐量
得益于 Page Cache 的缓存以及预读能力,而程序又往往符合局部性原理,因此通过一次 I/O 将多个 page 装入 Page Cache 能够减少磁盘 I/O 次数, 进而提高系统磁盘 I/O 吞吐量。
Page Cache 的劣势
page cache 也有其劣势,最直接的缺点是需要占用额外物理内存空间,物理内存在比较紧俏的时候可能会导致频繁的 swap 操作,最终导致系统的磁盘 I/O 负载的上升。
Page Cache 的另一个缺陷是对应用层并没有提供很好的管理 API,几乎是透明管理。应用层即使想优化 Page Cache 的使用策略也很难进行。因此一些应用选择在用户空间实现自己的 page 管理,而不使用 page cache,例如 MySQL InnoDB 存储引擎以 16KB 的页进行管理。
Page Cache 最后一个缺陷是在某些应用场景下比 Direct I/O 多一次磁盘读 I/O 以及磁盘写 I/O。
Direct I/O 即直接 I/O。其名字中的”直接”二字用于区分使用 page cache 机制的缓存 I/O。
- 缓存文件 I/O:用户空间要读写一个文件并不直接与磁盘交互,而是中间夹了一层缓存,即 page cache;
- 直接文件 I/O:用户空间读取的文件直接与磁盘交互,没有中间 page cache 层;
“直接”在这里还有另一层语义:其他所有技术中,数据至少需要在内核空间存储一份,但是在 Direct I/O 技术中,数据直接存储在用户空间中,绕过了内核。
Direct I/O 模式如下图所示:
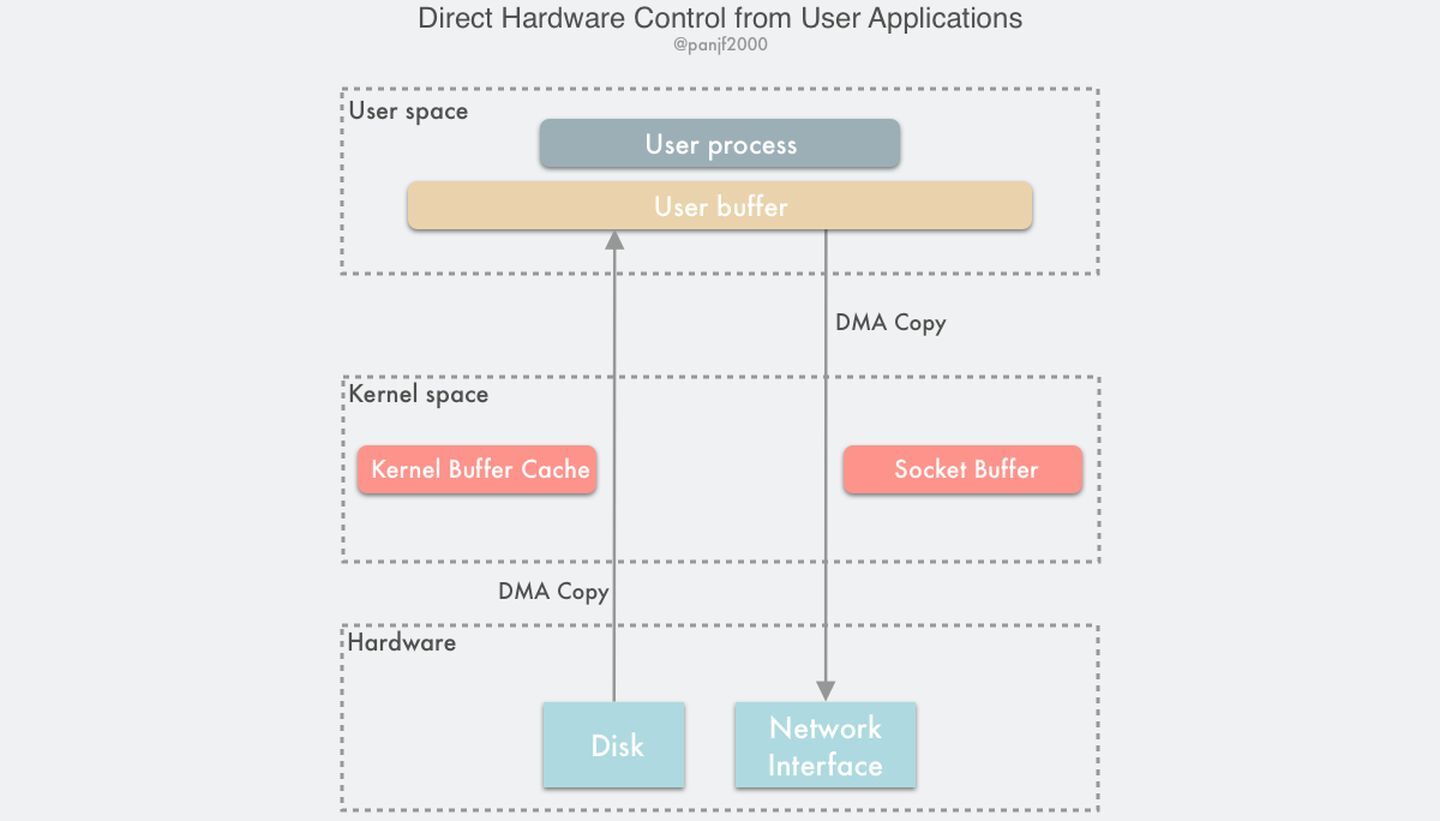
此时用户空间直接通过 DMA 的方式与磁盘以及网卡进行数据拷贝。
Direct I/O 的读写非常有特点:
- Write 操作:由于其不使用 page cache,所以其进行写文件,如果返回成功,数据就真的落盘了(不考虑磁盘自带的缓存);
- Read 操作:由于其不使用 page cache,每次读操作是真的从磁盘中读取,不会从文件系统的缓存中读取。
参考资料
- Linux内核技术实战课(opens new window)
- Reconsidering swapping(opens new window)
- 访问局部性(opens new window)
- [DMA 与零拷贝技术(opens new window)](https://spongecaptain.cool/SimpleClearFileIO/2. DMA 与零拷贝技术.html)
设备管理
键盘敲入A字母时,操作系统期间发生了什么?
键盘可以说是我们最常使用的输入硬件设备了,但身为程序员的你,你知道「键盘敲入A 字母时,操作系统期间发生了什么吗」?
那要想知道这个发生的过程,我们得先了解了解「操作系统是如何管理多种多样的的输入输出设备」的,等了解完这个后,我们再来看看这个问题,你就会发现问题已经被迎刃而解了。
设备控制器
我们的电脑设备可以接非常多的输入输出设备,比如键盘、鼠标、显示器、网卡、硬盘、打印机、音响等等,每个设备的用法和功能都不同,那操作系统是如何把这些输入输出设备统一管理的呢?
为了屏蔽设备之间的差异,每个设备都有一个叫设备控制器(*Device Control*) 的组件,比如硬盘有硬盘控制器、显示器有视频控制器等。
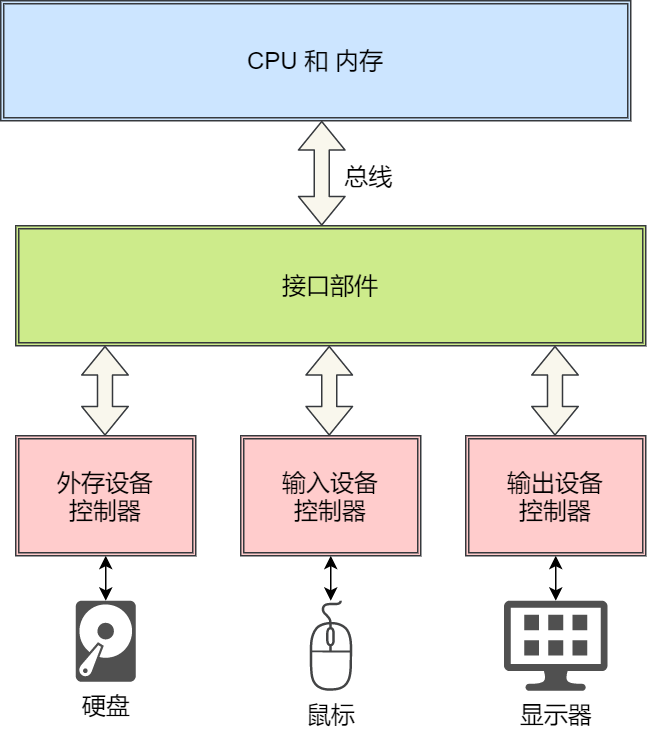
因为这些控制器都很清楚的知道对应设备的用法和功能,所以 CPU 是通过设备控制器来和设备打交道的。
设备控制器里有芯片,它可执行自己的逻辑,也有自己的寄存器,用来与 CPU 进行通信,比如:
- 通过写入这些寄存器,操作系统可以命令设备发送数据、接收数据、开启或关闭,或者执行某些其他操作。
- 通过读取这些寄存器,操作系统可以了解设备的状态,是否准备好接收一个新的命令等。
实际上,控制器是有三类寄存器,它们分别是状态寄存器(*Status Register*)、 命令寄存器(*Command Register*)**以及**数据寄存器(*Data Register*),如下图:
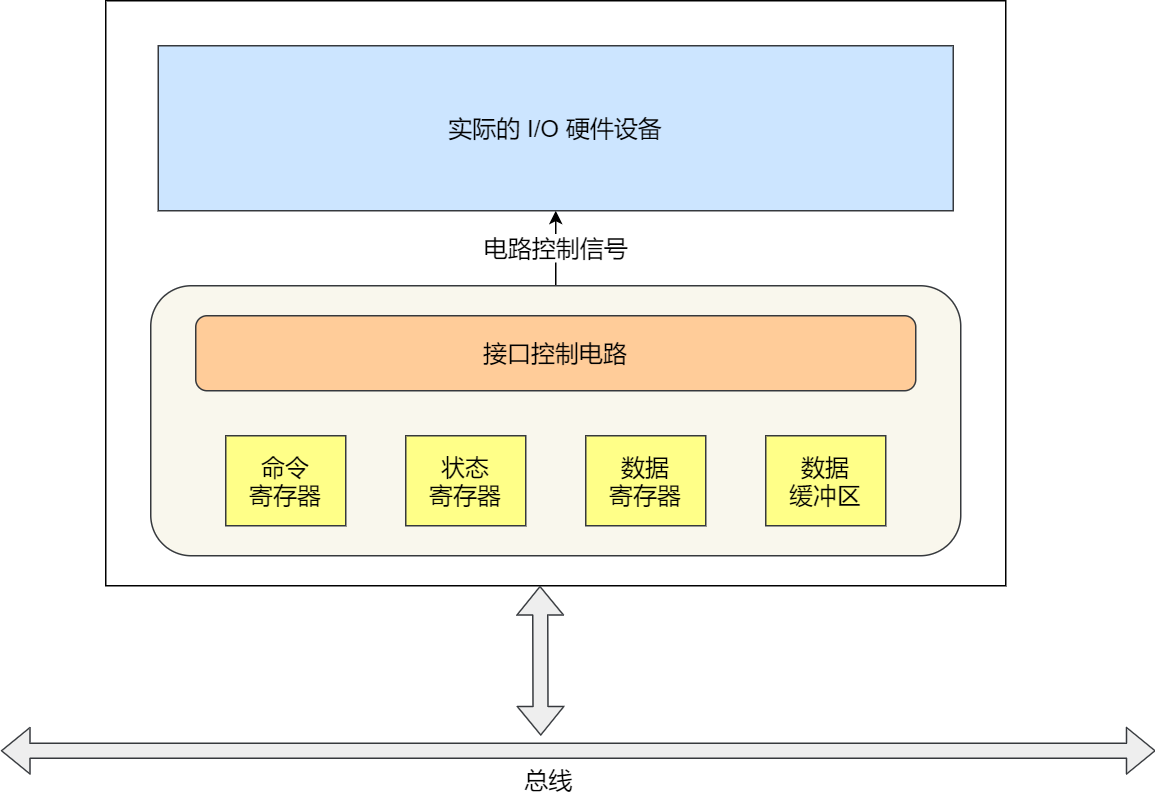
这三个寄存器的作用:
- 数据寄存器,CPU 向 I/O 设备写入需要传输的数据,比如要打印的内容是「Hello」,CPU 就要先发送一个 H 字符给到对应的 I/O 设备。
- 命令寄存器,CPU 发送一个命令,告诉 I/O 设备,要进行输入/输出操作,于是就会交给 I/O 设备去工作,任务完成后,会把状态寄存器里面的状态标记为完成。
- 状态寄存器,目的是告诉 CPU ,现在已经在工作或工作已经完成,如果已经在工作状态,CPU 再发送数据或者命令过来,都是没有用的,直到前面的工作已经完成,状态寄存标记成已完成,CPU 才能发送下一个字符和命令。
CPU 通过读写设备控制器中的寄存器控制设备,这可比 CPU 直接控制输入输出设备,要方便和标准很多。
另外, 输入输出设备可分为两大类 :块设备(*Block Device*)**和**字符设备(*Character Device*)。
- 块设备,把数据存储在固定大小的块中,每个块有自己的地址,硬盘、USB 是常见的块设备。
- 字符设备,以字符为单位发送或接收一个字符流,字符设备是不可寻址的,也没有任何寻道操作,鼠标是常见的字符设备。
块设备通常传输的数据量会非常大,于是控制器设立了一个可读写的数据缓冲区。
- CPU 写入数据到控制器的缓冲区时,当缓冲区的数据囤够了一部分,才会发给设备。
- CPU 从控制器的缓冲区读取数据时,也需要缓冲区囤够了一部分,才拷贝到内存。
这样做是为了,减少对设备的频繁操作。
那 CPU 是如何与设备的控制寄存器和数据缓冲区进行通信的?存在两个方法:
- 端口 I/O,每个控制寄存器被分配一个 I/O 端口,可以通过特殊的汇编指令操作这些寄存器,比如
in/out类似的指令。 - 内存映射 I/O,将所有控制寄存器映射到内存空间中,这样就可以像读写内存一样读写数据缓冲区。
I/O 控制方式
在前面我知道,每种设备都有一个设备控制器,控制器相当于一个小 CPU,它可以自己处理一些事情,但有个问题是,当 CPU 给设备发送了一个指令,让设备控制器去读设备的数据,它读完的时候,要怎么通知 CPU 呢?
控制器的寄存器一般会有状态标记位,用来标识输入或输出操作是否完成。于是,我们想到第一种轮询等待的方法,让 CPU 一直查寄存器的状态,直到状态标记为完成,很明显,这种方式非常的傻瓜,它会占用 CPU 的全部时间。
那我们就想到第二种方法 —— 中断,通知操作系统数据已经准备好了。我们一般会有一个硬件的中断控制器,当设备完成任务后触发中断到中断控制器,中断控制器就通知 CPU,一个中断产生了,CPU 需要停下当前手里的事情来处理中断。
另外,中断有两种,一种软中断,例如代码调用 INT 指令触发,一种是硬件中断,就是硬件通过中断控制器触发的。
但中断的方式对于频繁读写数据的磁盘,并不友好,这样 CPU 容易经常被打断,会占用 CPU 大量的时间。对于这一类设备的问题的解决方法是使用 DMA(*Direct Memory Access*) 功能,它可以使得设备在 CPU 不参与的情况下,能够自行完成把设备 I/O 数据放入到内存。那要实现 DMA 功能要有 「DMA 控制器」硬件的支持。
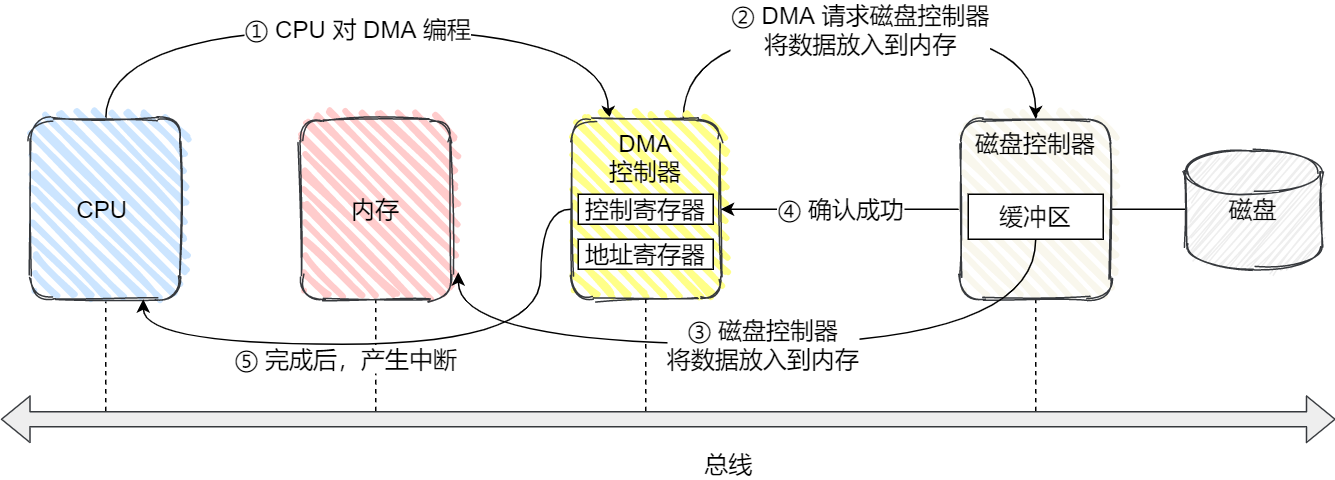
DMA 的工作方式如下:
- CPU 需对 DMA 控制器下发指令,告诉它想读取多少数据,读完的数据放在内存的某个地方就可以了;
- 接下来,DMA 控制器会向磁盘控制器发出指令,通知它从磁盘读数据到其内部的缓冲区中,接着磁盘控制器将缓冲区的数据传输到内存;
- 当磁盘控制器把数据传输到内存的操作完成后,磁盘控制器在总线上发出一个确认成功的信号到 DMA 控制器;
- DMA 控制器收到信号后,DMA 控制器发中断通知 CPU 指令完成,CPU 就可以直接用内存里面现成的数据了;
可以看到, CPU 当要读取磁盘数据的时候,只需给 DMA 控制器发送指令,然后返回去做其他事情,当磁盘数据拷贝到内存后,DMA 控制机器通过中断的方式,告诉 CPU 数据已经准备好了,可以从内存读数据了。仅仅在传送开始和结束时需要 CPU 干预。
设备驱动程序
虽然设备控制器屏蔽了设备的众多细节,但每种设备的控制器的寄存器、缓冲区等使用模式都是不同的,所以为了屏蔽「设备控制器」的差异,引入了设备驱动程序。
设备控制器不属于操作系统范畴,它是属于硬件,而设备驱动程序属于操作系统的一部分,操作系统的内核代码可以像本地调用代码一样使用设备驱动程序的接口,而设备驱动程序是面向设备控制器的代码,它发出操控设备控制器的指令后,才可以操作设备控制器。
不同的设备控制器虽然功能不同,但是设备驱动程序会提供统一的接口给操作系统,这样不同的设备驱动程序,就可以以相同的方式接入操作系统。如下图:
前面提到了不少关于中断的事情,设备完成了事情,则会发送中断来通知操作系统。那操作系统就需要有一个地方来处理这个中断,这个地方也就是在设备驱动程序里,它会及时响应控制器发来的中断请求,并根据这个中断的类型调用响应的中断处理程序进行处理。
通常,设备驱动程序初始化的时候,要先注册一个该设备的中断处理函数。
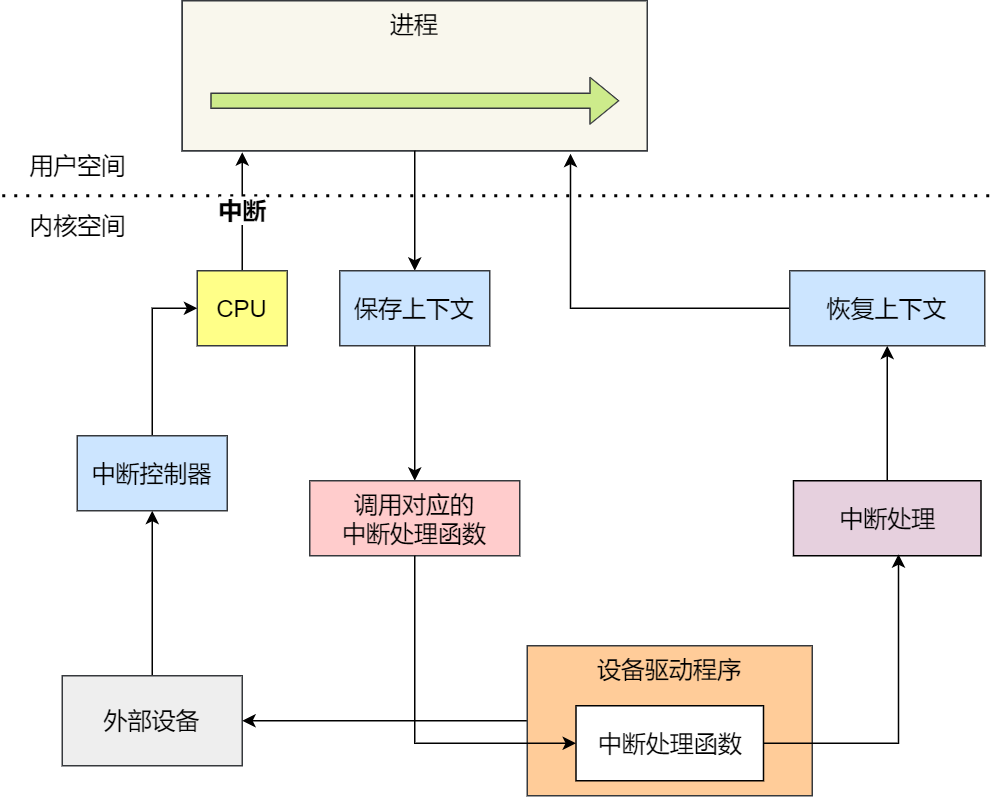
我们来看看,中断处理程序的处理流程:
- 在 I/O 时,设备控制器如果已经准备好数据,则会通过中断控制器向 CPU 发送中断请求;
- 保护被中断进程的 CPU 上下文;
- 转入相应的设备中断处理函数;
- 进行中断处理;
- 恢复被中断进程的上下文;
通用块层
对于块设备,为了减少不同块设备的差异带来的影响,Linux 通过一个统一的通用块层,来管理不同的块设备。
通用块层是处于文件系统和磁盘驱动中间的一个块设备抽象层,它主要有两个功能:
- 第一个功能,向上为文件系统和应用程序,提供访问块设备的标准接口,向下把各种不同的磁盘设备抽象为统一的块设备,并在内核层面,提供一个框架来管理这些设备的驱动程序;
- 第二功能,通用层还会给文件系统和应用程序发来的 I/O 请求排队,接着会对队列重新排序、请求合并等方式,也就是 I/O 调度,主要目的是为了提高磁盘读写的效率。
Linux 内存支持 5 种 I/O 调度算法,分别是:
- 没有调度算法
- 先入先出调度算法
- 完全公平调度算法
- 优先级调度
- 最终期限调度算法
第一种,没有调度算法,是的,你没听错,它不对文件系统和应用程序的 I/O 做任何处理,这种算法常用在虚拟机 I/O 中,此时磁盘 I/O 调度算法交由物理机系统负责。
第二种,先入先出调度算法,这是最简单的 I/O 调度算法,先进入 I/O 调度队列的 I/O 请求先发生。
第三种,完全公平调度算法,大部分系统都把这个算法作为默认的 I/O 调度器,它为每个进程维护了一个 I/O 调度队列,并按照时间片来均匀分布每个进程的 I/O 请求。
第四种,优先级调度算法,顾名思义,优先级高的 I/O 请求先发生, 它适用于运行大量进程的系统,像是桌面环境、多媒体应用等。
第五种,最终期限调度算法,分别为读、写请求创建了不同的 I/O 队列,这样可以提高机械磁盘的吞吐量,并确保达到最终期限的请求被优先处理,适用于在 I/O 压力比较大的场景,比如数据库等。
存储系统 I/O 软件分层
前面说到了不少东西,设备、设备控制器、驱动程序、通用块层,现在再结合文件系统原理,我们来看看 Linux 存储系统的 I/O 软件分层。
可以把 Linux 存储系统的 I/O 由上到下可以分为三个层次,分别是文件系统层、通用块层、设备层。他们整个的层次关系如下图:
这三个层次的作用是:
- 文件系统层,包括虚拟文件系统和其他文件系统的具体实现,它向上为应用程序统一提供了标准的文件访问接口,向下会通过通用块层来存储和管理磁盘数据。
- 通用块层,包括块设备的 I/O 队列和 I/O 调度器,它会对文件系统的 I/O 请求进行排队,再通过 I/O 调度器,选择一个 I/O 发给下一层的设备层。
- 设备层,包括硬件设备、设备控制器和驱动程序,负责最终物理设备的 I/O 操作。
有了文件系统接口之后,不但可以通过文件系统的命令行操作设备,也可以通过应用程序,调用 read、write 函数,就像读写文件一样操作设备,所以说设备在 Linux 下,也只是一个特殊的文件。
但是,除了读写操作,还需要有检查特定于设备的功能和属性。于是,需要 ioctl 接口,它表示输入输出控制接口,是用于配置和修改特定设备属性的通用接口。
另外,存储系统的 I/O 是整个系统最慢的一个环节,所以 Linux 提供了不少缓存机制来提高 I/O 的效率。
- 为了提高文件访问的效率,会使用页缓存、索引节点缓存、目录项缓存等多种缓存机制,目的是为了减少对块设备的直接调用。
- 为了提高块设备的访问效率, 会使用缓冲区,来缓存块设备的数据。
键盘敲入字母时,期间发生了什么?
看完前面的内容,相信你对输入输出设备的管理有了一定的认识,那接下来就从操作系统的角度回答开头的问题「键盘敲入字母时,操作系统期间发生了什么?」
我们先来看看 CPU 的硬件架构图:
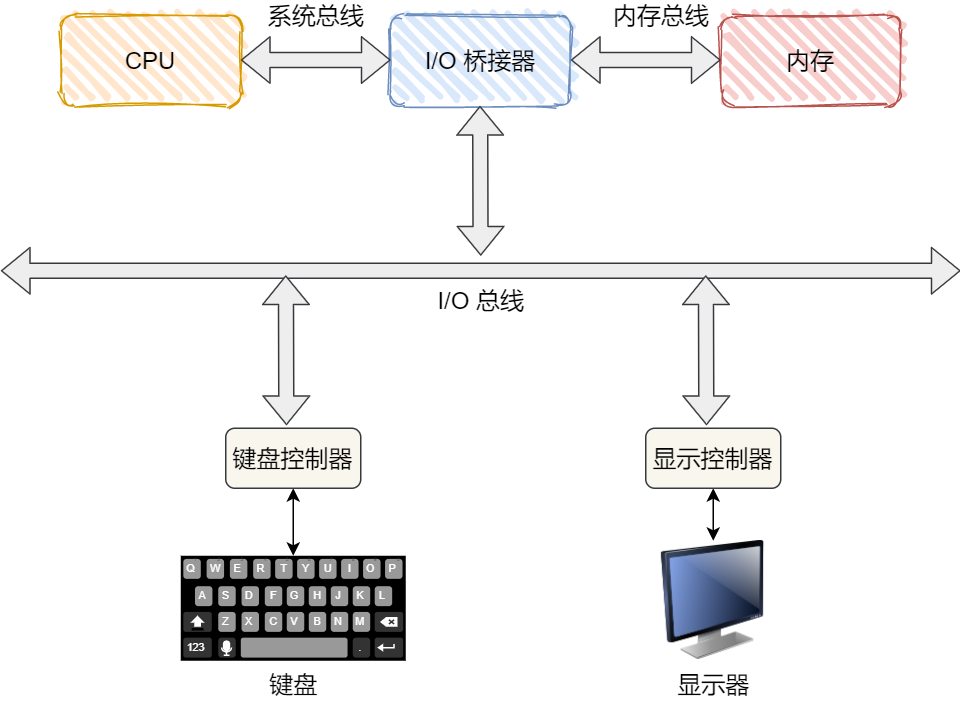
CPU 里面的内存接口,直接和系统总线通信,然后系统总线再接入一个 I/O 桥接器,这个 I/O 桥接器,另一边接入了内存总线,使得 CPU 和内存通信。再另一边,又接入了一个 I/O 总线,用来连接 I/O 设备,比如键盘、显示器等。
那当用户输入了键盘字符,键盘控制器就会产生扫描码数据,并将其缓冲在键盘控制器的寄存器中,紧接着键盘控制器通过总线给 CPU 发送中断请求。
CPU 收到中断请求后,操作系统会保存被中断进程的 CPU 上下文,然后调用键盘的中断处理程序。
键盘的中断处理程序是在键盘驱动程序初始化时注册的,那键盘中断处理函数的功能就是从键盘控制器的寄存器的缓冲区读取扫描码,再根据扫描码找到用户在键盘输入的字符,如果输入的字符是显示字符,那就会把扫描码翻译成对应显示字符的 ASCII 码,比如用户在键盘输入的是字母 A,是显示字符,于是就会把扫描码翻译成 A 字符的 ASCII 码。
得到了显示字符的 ASCII 码后,就会把 ASCII 码放到「读缓冲区队列」,接下来就是要把显示字符显示屏幕了,显示设备的驱动程序会定时从「读缓冲区队列」读取数据放到「写缓冲区队列」,最后把「写缓冲区队列」的数据一个一个写入到显示设备的控制器的寄存器中的数据缓冲区,最后将这些数据显示在屏幕里。
显示出结果后,恢复被中断进程的上下文。
网络系统
什么是零拷贝?
磁盘可以说是计算机系统最慢的硬件之一,读写速度相差内存 10 倍以上,所以针对优化磁盘的技术非常的多,比如零拷贝、直接 I/O、异步 I/O 等等,这些优化的目的就是为了提高系统的吞吐量,另外操作系统内核中的磁盘高速缓存区,可以有效的减少磁盘的访问次数。
这次,我们就以「文件传输」作为切入点,来分析 I/O 工作方式,以及如何优化传输文件的性能。
为什么要有 DMA 技术?
在没有 DMA 技术前,I/O 的过程是这样的:
- CPU 发出对应的指令给磁盘控制器,然后返回;
- 磁盘控制器收到指令后,于是就开始准备数据,会把数据放入到磁盘控制器的内部缓冲区中,然后产生一个中断;
- CPU 收到中断信号后,停下手头的工作,接着把磁盘控制器的缓冲区的数据一次一个字节地读进自己的寄存器,然后再把寄存器里的数据写入到内存,而在数据传输的期间 CPU 是无法执行其他任务的。
为了方便你理解,我画了一副图:
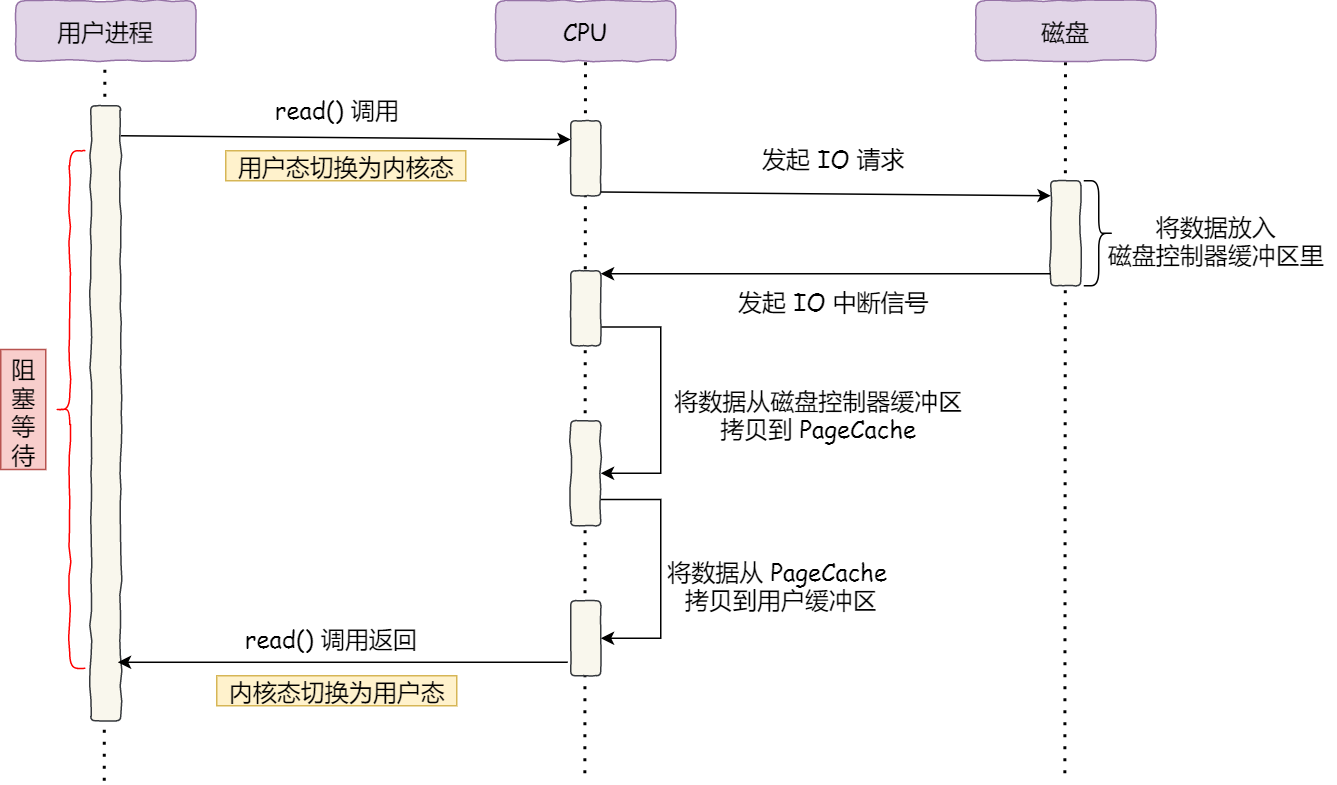
可以看到,整个数据的传输过程,都要需要 CPU 亲自参与搬运数据的过程,而且这个过程,CPU 是不能做其他事情的。
简单的搬运几个字符数据那没问题,但是如果我们用千兆网卡或者硬盘传输大量数据的时候,都用 CPU 来搬运的话,肯定忙不过来。
计算机科学家们发现了事情的严重性后,于是就发明了 DMA 技术,也就是直接内存访问(*Direct Memory Access*) 技术。
什么是 DMA 技术?简单理解就是,在进行 I/O 设备和内存的数据传输的时候,数据搬运的工作全部交给 DMA 控制器,而 CPU 不再参与任何与数据搬运相关的事情,这样 CPU 就可以去处理别的事务。
那使用 DMA 控制器进行数据传输的过程究竟是什么样的呢?下面我们来具体看看。
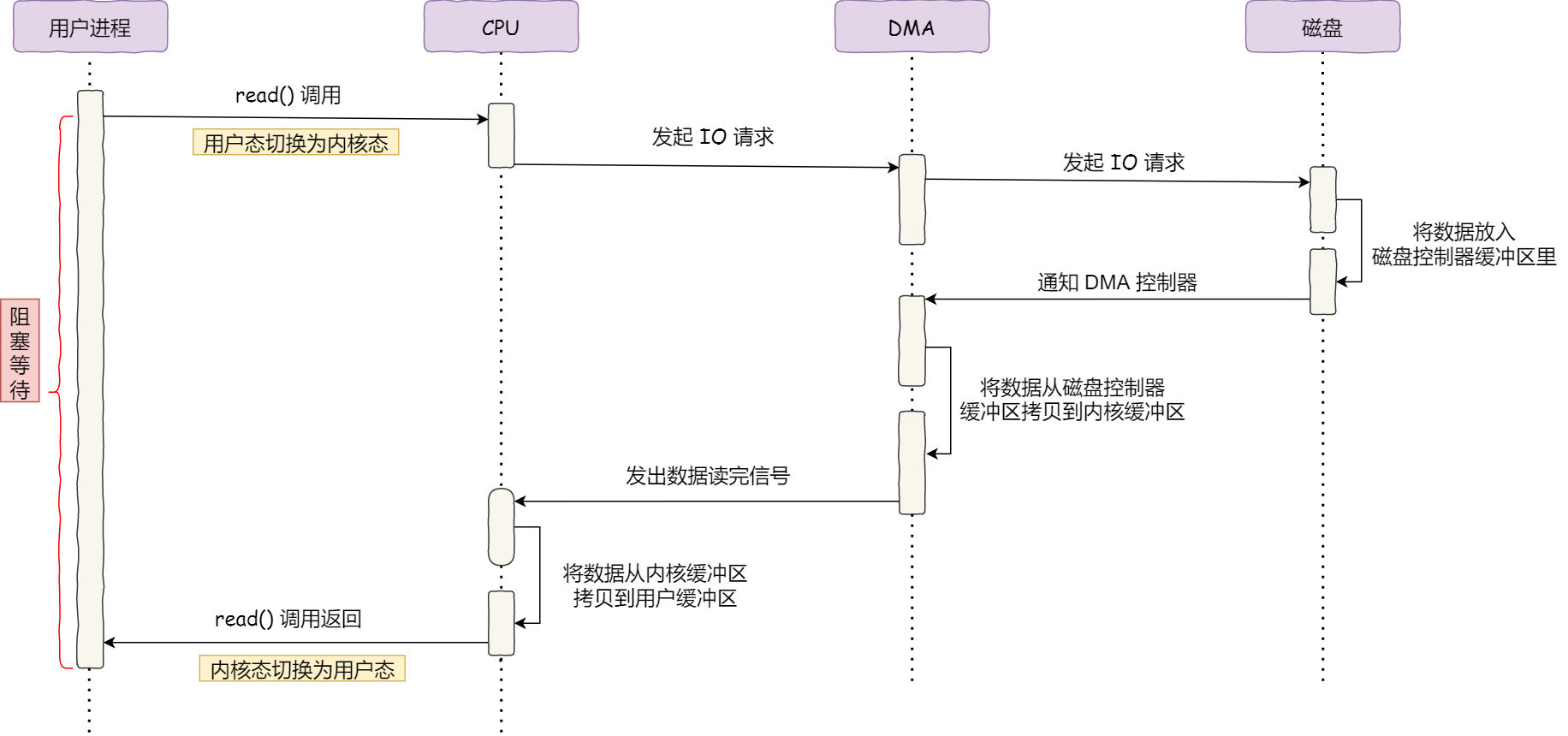
具体过程:
- 用户进程调用 read 方法,向操作系统发出 I/O 请求,请求读取数据到自己的内存缓冲区中,进程进入阻塞状态;
- 操作系统收到请求后,进一步将 I/O 请求发送 DMA,然后让 CPU 执行其他任务;
- DMA 进一步将 I/O 请求发送给磁盘;
- 磁盘收到 DMA 的 I/O 请求,把数据从磁盘读取到磁盘控制器的缓冲区中,当磁盘控制器的缓冲区被读满后,向 DMA 发起中断信号,告知自己缓冲区已满;
- DMA 收到磁盘的信号,将磁盘控制器缓冲区中的数据拷贝到内核缓冲区中,此时不占用 CPU,CPU 可以执行其他任务;
- 当 DMA 读取了足够多的数据,就会发送中断信号给 CPU;
- CPU 收到 DMA 的信号,知道数据已经准备好,于是将数据从内核拷贝到用户空间,系统调用返回;
可以看到, CPU 不再参与「将数据从磁盘控制器缓冲区搬运到内核空间」的工作,这部分工作全程由 DMA 完成。但是 CPU 在这个过程中也是必不可少的,因为传输什么数据,从哪里传输到哪里,都需要 CPU 来告诉 DMA 控制器。
早期 DMA 只存在在主板上,如今由于 I/O 设备越来越多,数据传输的需求也不尽相同,所以每个 I/O 设备里面都有自己的 DMA 控制器。
传统的文件传输有多糟糕?
如果服务端要提供文件传输的功能,我们能想到的最简单的方式是:将磁盘上的文件读取出来,然后通过网络协议发送给客户端。
传统 I/O 的工作方式是,数据读取和写入是从用户空间到内核空间来回复制,而内核空间的数据是通过操作系统层面的 I/O 接口从磁盘读取或写入。
代码通常如下,一般会需要两个系统调用:
|
|
代码很简单,虽然就两行代码,但是这里面发生了不少的事情。
首先,期间共发生了 4 次用户态与内核态的上下文切换,因为发生了两次系统调用,一次是 read() ,一次是 write(),每次系统调用都得先从用户态切换到内核态,等内核完成任务后,再从内核态切换回用户态。
上下文切换到成本并不小,一次切换需要耗时几十纳秒到几微秒,虽然时间看上去很短,但是在高并发的场景下,这类时间容易被累积和放大,从而影响系统的性能。
其次,还发生了 4 次数据拷贝,其中两次是 DMA 的拷贝,另外两次则是通过 CPU 拷贝的,下面说一下这个过程:
- 第一次拷贝,把磁盘上的数据拷贝到操作系统内核的缓冲区里,这个拷贝的过程是通过 DMA 搬运的。
- 第二次拷贝,把内核缓冲区的数据拷贝到用户的缓冲区里,于是我们应用程序就可以使用这部分数据了,这个拷贝到过程是由 CPU 完成的。
- 第三次拷贝,把刚才拷贝到用户的缓冲区里的数据,再拷贝到内核的 socket 的缓冲区里,这个过程依然还是由 CPU 搬运的。
- 第四次拷贝,把内核的 socket 缓冲区里的数据,拷贝到网卡的缓冲区里,这个过程又是由 DMA 搬运的。
我们回过头看这个文件传输的过程,我们只是搬运一份数据,结果却搬运了 4 次,过多的数据拷贝无疑会消耗 CPU 资源,大大降低了系统性能。
这种简单又传统的文件传输方式,存在冗余的上文切换和数据拷贝,在高并发系统里是非常糟糕的,多了很多不必要的开销,会严重影响系统性能。
所以,要想提高文件传输的性能,就需要减少「用户态与内核态的上下文切换」和「内存拷贝」的次数。
如何优化文件传输的性能?
先来看看,如何减少「用户态与内核态的上下文切换」的次数呢?
读取磁盘数据的时候,之所以要发生上下文切换,这是因为用户空间没有权限操作磁盘或网卡,内核的权限最高,这些操作设备的过程都需要交由操作系统内核来完成,所以一般要通过内核去完成某些任务的时候,就需要使用操作系统提供的系统调用函数。
而一次系统调用必然会发生 2 次上下文切换:首先从用户态切换到内核态,当内核执行完任务后,再切换回用户态交由进程代码执行。
所以,要想减少上下文切换到次数,就要减少系统调用的次数。
再来看看,如何减少「数据拷贝」的次数?
在前面我们知道了,传统的文件传输方式会历经 4 次数据拷贝,而且这里面,「从内核的读缓冲区拷贝到用户的缓冲区里,再从用户的缓冲区里拷贝到 socket 的缓冲区里」,这个过程是没有必要的。
因为文件传输的应用场景中,在用户空间我们并不会对数据「再加工」,所以数据实际上可以不用搬运到用户空间,因此用户的缓冲区是没有必要存在的。
如何实现零拷贝?
零拷贝技术实现的方式通常有 2 种:
- mmap + write
- sendfile
下面就谈一谈,它们是如何减少「上下文切换」和「数据拷贝」的次数。
mmap + write
在前面我们知道,read() 系统调用的过程中会把内核缓冲区的数据拷贝到用户的缓冲区里,于是为了减少这一步开销,我们可以用 mmap() 替换 read() 系统调用函数。
|
|
mmap() 系统调用函数会直接把内核缓冲区里的数据「映射」到用户空间,这样,操作系统内核与用户空间就不需要再进行任何的数据拷贝操作。
具体过程如下:
- 应用进程调用了
mmap()后,DMA 会把磁盘的数据拷贝到内核的缓冲区里。接着,应用进程跟操作系统内核「共享」这个缓冲区; - 应用进程再调用
write(),操作系统直接将内核缓冲区的数据拷贝到 socket 缓冲区中,这一切都发生在内核态,由 CPU 来搬运数据; - 最后,把内核的 socket 缓冲区里的数据,拷贝到网卡的缓冲区里,这个过程是由 DMA 搬运的。
我们可以得知,通过使用 mmap() 来代替 read(), 可以减少一次数据拷贝的过程。
但这还不是最理想的零拷贝,因为仍然需要通过 CPU 把内核缓冲区的数据拷贝到 socket 缓冲区里,而且仍然需要 4 次上下文切换,因为系统调用还是 2 次。
sendfile
在 Linux 内核版本 2.1 中,提供了一个专门发送文件的系统调用函数 sendfile(),函数形式如下:
|
|
它的前两个参数分别是目的端和源端的文件描述符,后面两个参数是源端的偏移量和复制数据的长度,返回值是实际复制数据的长度。
首先,它可以替代前面的 read() 和 write() 这两个系统调用,这样就可以减少一次系统调用,也就减少了 2 次上下文切换的开销。
其次,该系统调用,可以直接把内核缓冲区里的数据拷贝到 socket 缓冲区里,不再拷贝到用户态,这样就只有 2 次上下文切换,和 3 次数据拷贝。如下图:
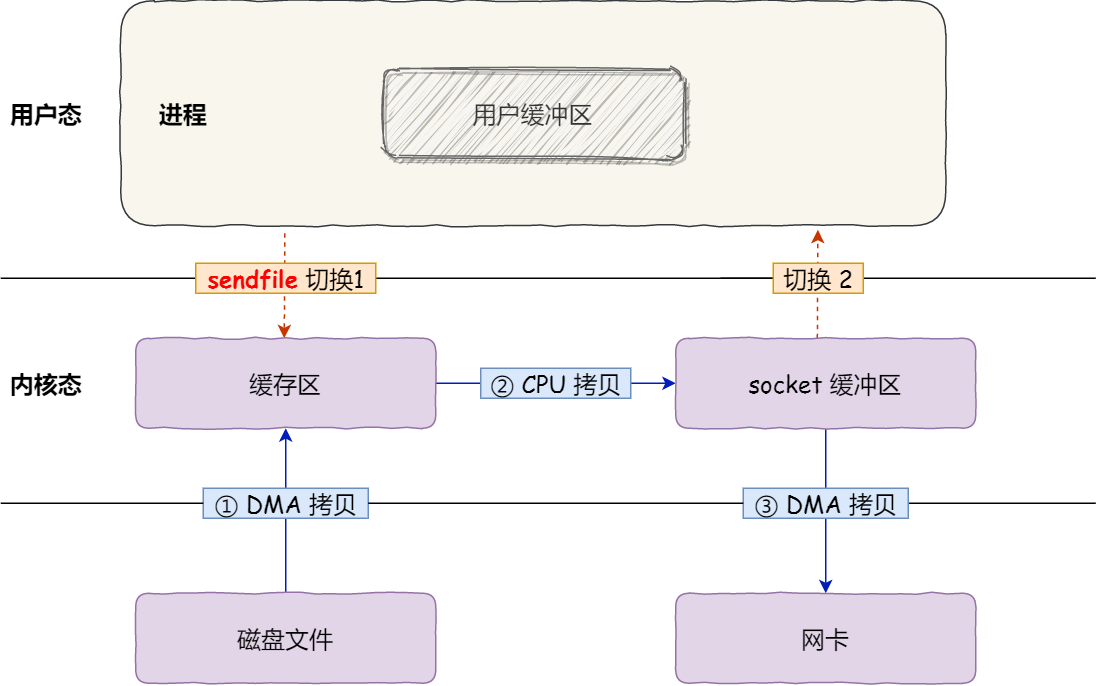
但是这还不是真正的零拷贝技术,如果网卡支持 SG-DMA(The Scatter-Gather Direct Memory Access)技术(和普通的 DMA 有所不同),我们可以进一步减少通过 CPU 把内核缓冲区里的数据拷贝到 socket 缓冲区的过程。
你可以在你的 Linux 系统通过下面这个命令,查看网卡是否支持 scatter-gather 特性:
|
|
于是,从 Linux 内核 2.4 版本开始起,对于支持网卡支持 SG-DMA 技术的情况下, sendfile() 系统调用的过程发生了点变化,具体过程如下:
- 第一步,通过 DMA 将磁盘上的数据拷贝到内核缓冲区里;
- 第二步,缓冲区描述符和数据长度传到 socket 缓冲区,这样网卡的 SG-DMA 控制器就可以直接将内核缓存中的数据拷贝到网卡的缓冲区里,此过程不需要将数据从操作系统内核缓冲区拷贝到 socket 缓冲区中,这样就减少了一次数据拷贝;
所以,这个过程之中,只进行了 2 次数据拷贝,如下图:
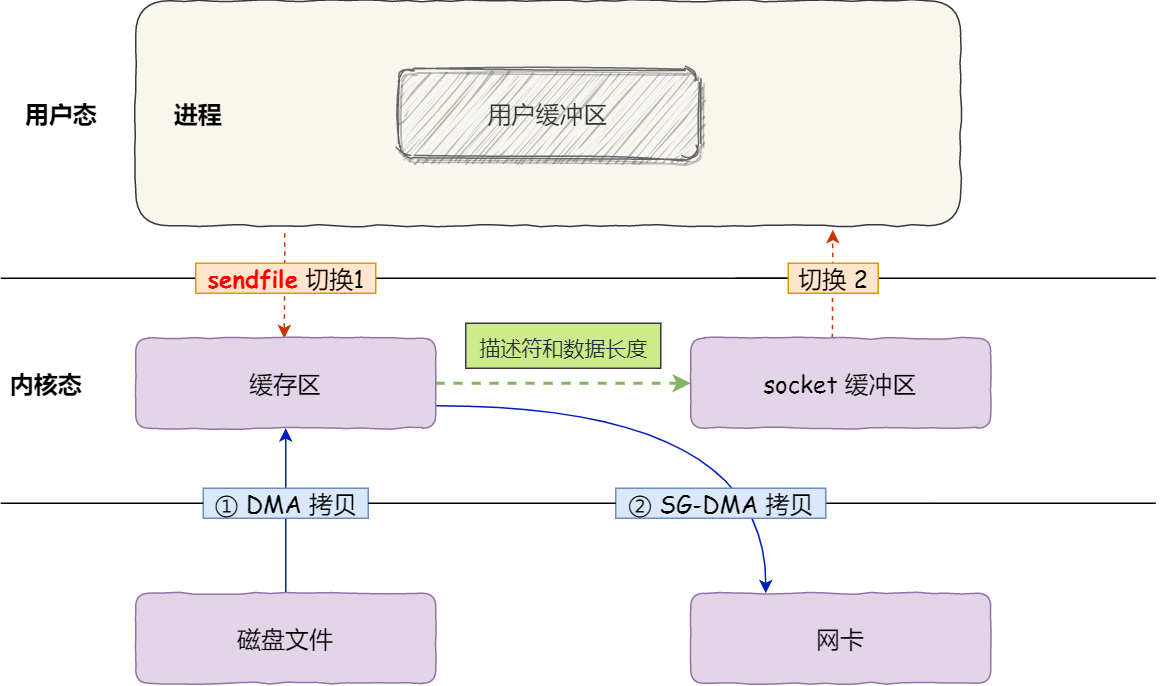
这就是所谓的零拷贝(*Zero-copy*)技术,因为我们没有在内存层面去拷贝数据,也就是说全程没有通过 CPU 来搬运数据,所有的数据都是通过 DMA 来进行传输的。。
零拷贝技术的文件传输方式相比传统文件传输的方式,减少了 2 次上下文切换和数据拷贝次数,只需要 2 次上下文切换和数据拷贝次数,就可以完成文件的传输,而且 2 次的数据拷贝过程,都不需要通过 CPU,2 次都是由 DMA 来搬运。
所以,总体来看,零拷贝技术可以把文件传输的性能提高至少一倍以上。
使用零拷贝技术的项目
事实上,Kafka 这个开源项目,就利用了「零拷贝」技术,从而大幅提升了 I/O 的吞吐率,这也是 Kafka 在处理海量数据为什么这么快的原因之一。
如果你追溯 Kafka 文件传输的代码,你会发现,最终它调用了 Java NIO 库里的 transferTo 方法:
|
|
如果 Linux 系统支持 sendfile() 系统调用,那么 transferTo() 实际上最后就会使用到 sendfile() 系统调用函数。
曾经有大佬专门写过程序测试过,在同样的硬件条件下,传统文件传输和零拷拷贝文件传输的性能差异,你可以看到下面这张测试数据图,使用了零拷贝能够缩短 65% 的时间,大幅度提升了机器传输数据的吞吐量。
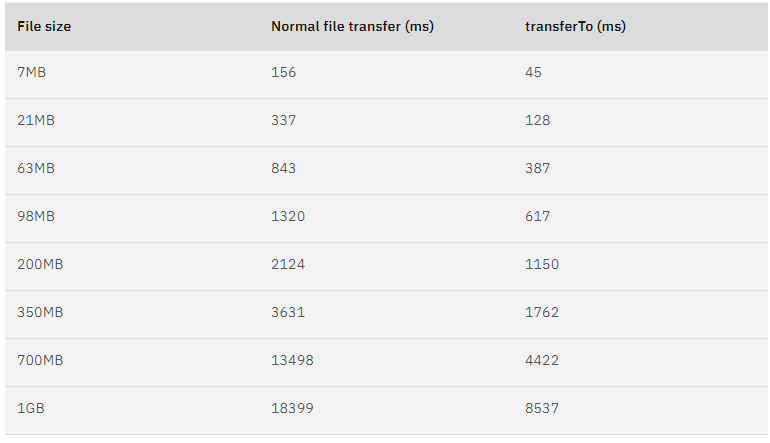
另外,Nginx 也支持零拷贝技术,一般默认是开启零拷贝技术,这样有利于提高文件传输的效率,是否开启零拷贝技术的配置如下:
|
|
sendfile 配置的具体意思:
- 设置为 on 表示,使用零拷贝技术来传输文件:sendfile ,这样只需要 2 次上下文切换,和 2 次数据拷贝。
- 设置为 off 表示,使用传统的文件传输技术:read + write,这时就需要 4 次上下文切换,和 4 次数据拷贝。
当然,要使用 sendfile,Linux 内核版本必须要 2.1 以上的版本。
PageCache 有什么作用?
回顾前面说道文件传输过程,其中第一步都是先需要先把磁盘文件数据拷贝「内核缓冲区」里,这个「内核缓冲区」实际上是磁盘高速缓存(*PageCache*)。
由于零拷贝使用了 PageCache 技术,可以使得零拷贝进一步提升了性能,我们接下来看看 PageCache 是如何做到这一点的。
读写磁盘相比读写内存的速度慢太多了,所以我们应该想办法把「读写磁盘」替换成「读写内存」。于是,我们会通过 DMA 把磁盘里的数据搬运到内存里,这样就可以用读内存替换读磁盘。
但是,内存空间远比磁盘要小,内存注定只能拷贝磁盘里的一小部分数据。
那问题来了,选择哪些磁盘数据拷贝到内存呢?
我们都知道程序运行的时候,具有「局部性」,所以通常,刚被访问的数据在短时间内再次被访问的概率很高,于是我们可以用 PageCache 来缓存最近被访问的数据,当空间不足时淘汰最久未被访问的缓存。
所以,读磁盘数据的时候,优先在 PageCache 找,如果数据存在则可以直接返回;如果没有,则从磁盘中读取,然后缓存 PageCache 中。
还有一点,读取磁盘数据的时候,需要找到数据所在的位置,但是对于机械磁盘来说,就是通过磁头旋转到数据所在的扇区,再开始「顺序」读取数据,但是旋转磁头这个物理动作是非常耗时的,为了降低它的影响,PageCache 使用了「预读功能」。
比如,假设 read 方法每次只会读 32 KB 的字节,虽然 read 刚开始只会读 0 ~ 32 KB 的字节,但内核会把其后面的 32~64 KB 也读取到 PageCache,这样后面读取 32~64 KB 的成本就很低,如果在 32~64 KB 淘汰出 PageCache 前,进程读取到它了,收益就非常大。
所以,PageCache 的优点主要是两个:
- 缓存最近被访问的数据;
- 预读功能;
这两个做法,将大大提高读写磁盘的性能。
但是,在传输大文件(GB 级别的文件)的时候,PageCache 会不起作用,那就白白浪费 DMA 多做的一次数据拷贝,造成性能的降低,即使使用了 PageCache 的零拷贝也会损失性能
这是因为如果你有很多 GB 级别文件需要传输,每当用户访问这些大文件的时候,内核就会把它们载入 PageCache 中,于是 PageCache 空间很快被这些大文件占满。
另外,由于文件太大,可能某些部分的文件数据被再次访问的概率比较低,这样就会带来 2 个问题:
- PageCache 由于长时间被大文件占据,其他「热点」的小文件可能就无法充分使用到 PageCache,于是这样磁盘读写的性能就会下降了;
- PageCache 中的大文件数据,由于没有享受到缓存带来的好处,但却耗费 DMA 多拷贝到 PageCache 一次;
所以,针对大文件的传输,不应该使用 PageCache,也就是说不应该使用零拷贝技术,因为可能由于 PageCache 被大文件占据,而导致「热点」小文件无法利用到 PageCache,这样在高并发的环境下,会带来严重的性能问题。
大文件传输用什么方式实现?
那针对大文件的传输,我们应该使用什么方式呢?
我们先来看看最初的例子,当调用 read 方法读取文件时,进程实际上会阻塞在 read 方法调用,因为要等待磁盘数据的返回,如下图:
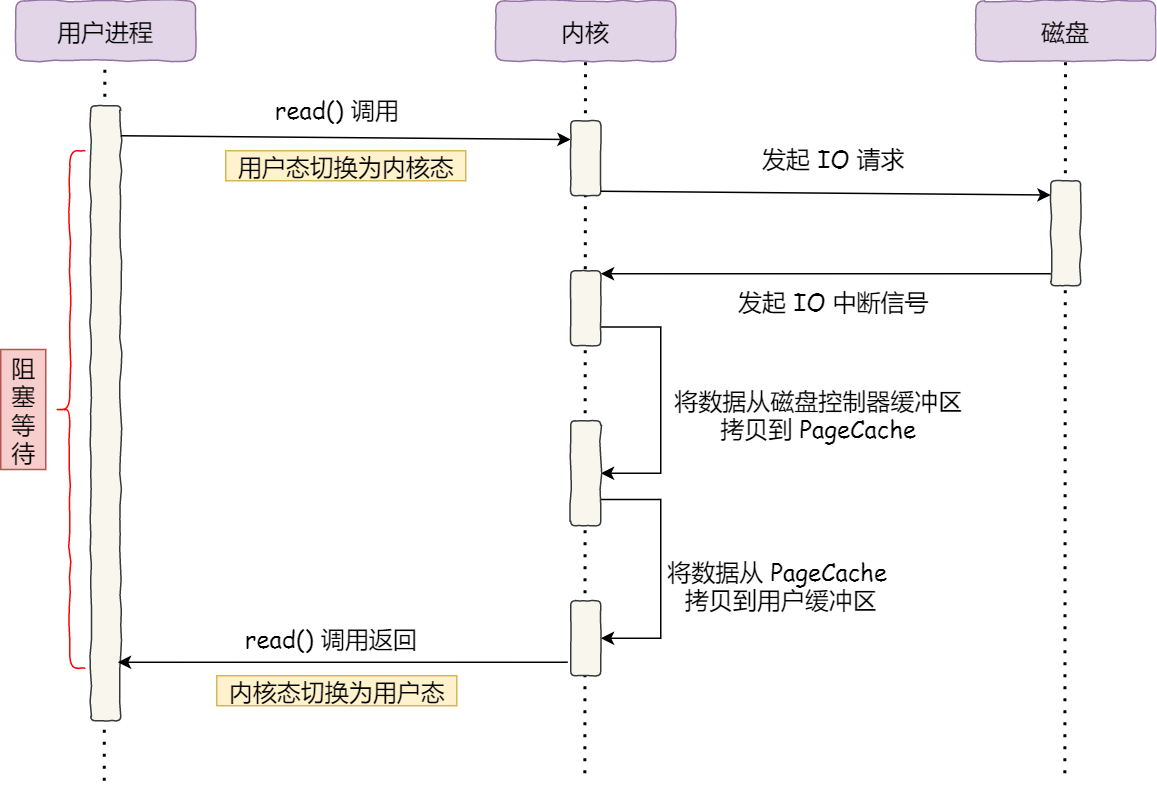
具体过程:
- 当调用 read 方法时,会阻塞着,此时内核会向磁盘发起 I/O 请求,磁盘收到请求后,便会寻址,当磁盘数据准备好后,就会向内核发起 I/O 中断,告知内核磁盘数据已经准备好;
- 内核收到 I/O 中断后,就将数据从磁盘控制器缓冲区拷贝到 PageCache 里;
- 最后,内核再把 PageCache 中的数据拷贝到用户缓冲区,于是 read 调用就正常返回了。
对于阻塞的问题,可以用异步 I/O 来解决,它工作方式如下图:
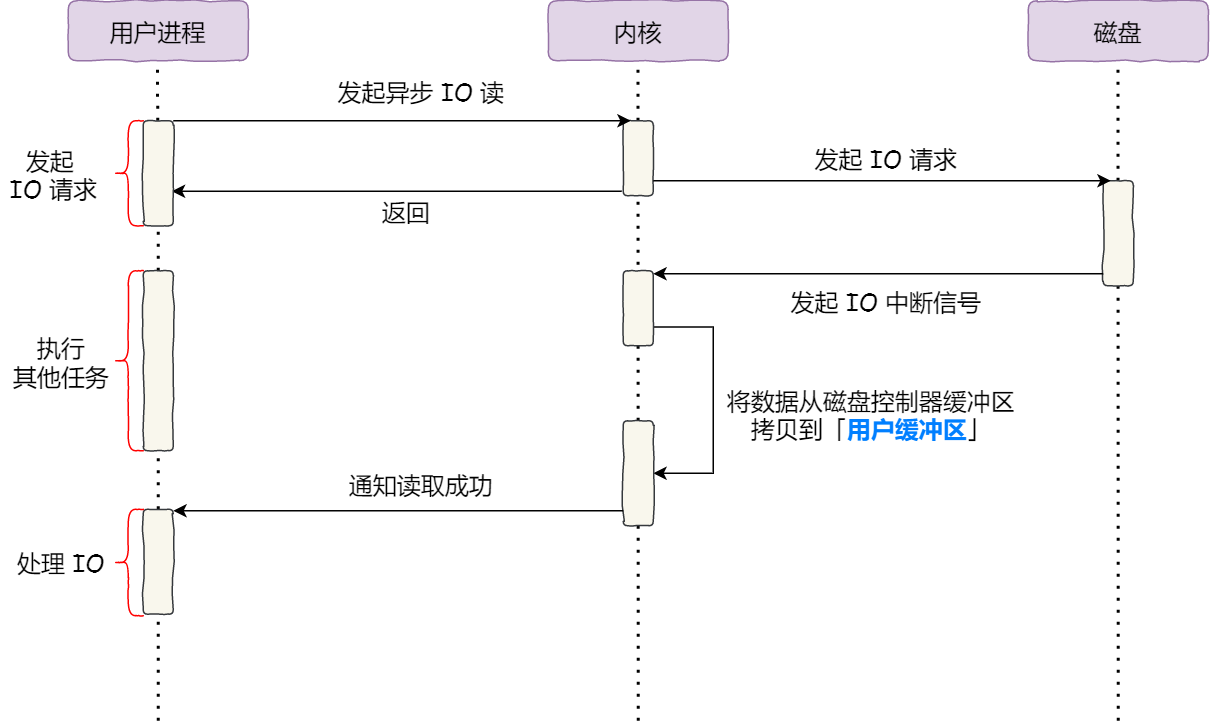
它把读操作分为两部分:
- 前半部分,内核向磁盘发起读请求,但是可以不等待数据就位就可以返回,于是进程此时可以处理其他任务;
- 后半部分,当内核将磁盘中的数据拷贝到进程缓冲区后,进程将接收到内核的通知,再去处理数据;
而且,我们可以发现,异步 I/O 并没有涉及到 PageCache,所以使用异步 I/O 就意味着要绕开 PageCache。
绕开 PageCache 的 I/O 叫直接 I/O,使用 PageCache 的 I/O 则叫缓存 I/O。通常,对于磁盘,异步 I/O 只支持直接 I/O。
前面也提到,大文件的传输不应该使用 PageCache,因为可能由于 PageCache 被大文件占据,而导致「热点」小文件无法利用到 PageCache。
于是,在高并发的场景下,针对大文件的传输的方式,应该使用「异步 I/O + 直接 I/O」来替代零拷贝技术。
直接 I/O 应用场景常见的两种:
- 应用程序已经实现了磁盘数据的缓存,那么可以不需要 PageCache 再次缓存,减少额外的性能损耗。在 MySQL 数据库中,可以通过参数设置开启直接 I/O,默认是不开启;
- 传输大文件的时候,由于大文件难以命中 PageCache 缓存,而且会占满 PageCache 导致「热点」文件无法充分利用缓存,从而增大了性能开销,因此,这时应该使用直接 I/O。
另外,由于直接 I/O 绕过了 PageCache,就无法享受内核的这两点的优化:
- 内核的 I/O 调度算法会缓存尽可能多的 I/O 请求在 PageCache 中,最后「合并」成一个更大的 I/O 请求再发给磁盘,这样做是为了减少磁盘的寻址操作;
- 内核也会「预读」后续的 I/O 请求放在 PageCache 中,一样是为了减少对磁盘的操作;
于是,传输大文件的时候,使用「异步 I/O + 直接 I/O」了,就可以无阻塞地读取文件了。
所以,传输文件的时候,我们要根据文件的大小来使用不同的方式:
- 传输大文件的时候,使用「异步 I/O + 直接 I/O」;
- 传输小文件的时候,则使用「零拷贝技术」;
在 nginx 中,我们可以用如下配置,来根据文件的大小来使用不同的方式:
|
|
当文件大小大于 directio 值后,使用「异步 I/O + 直接 I/O」,否则使用「零拷贝技术」。
总结
早期 I/O 操作,内存与磁盘的数据传输的工作都是由 CPU 完成的,而此时 CPU 不能执行其他任务,会特别浪费 CPU 资源。
于是,为了解决这一问题,DMA 技术就出现了,每个 I/O 设备都有自己的 DMA 控制器,通过这个 DMA 控制器,CPU 只需要告诉 DMA 控制器,我们要传输什么数据,从哪里来,到哪里去,就可以放心离开了。后续的实际数据传输工作,都会由 DMA 控制器来完成,CPU 不需要参与数据传输的工作。
传统 IO 的工作方式,从硬盘读取数据,然后再通过网卡向外发送,我们需要进行 4 上下文切换,和 4 次数据拷贝,其中 2 次数据拷贝发生在内存里的缓冲区和对应的硬件设备之间,这个是由 DMA 完成,另外 2 次则发生在内核态和用户态之间,这个数据搬移工作是由 CPU 完成的。
为了提高文件传输的性能,于是就出现了零拷贝技术,它通过一次系统调用(sendfile 方法)合并了磁盘读取与网络发送两个操作,降低了上下文切换次数。另外,拷贝数据都是发生在内核中的,天然就降低了数据拷贝的次数。
Kafka 和 Nginx 都有实现零拷贝技术,这将大大提高文件传输的性能。
零拷贝技术是基于 PageCache 的,PageCache 会缓存最近访问的数据,提升了访问缓存数据的性能,同时,为了解决机械硬盘寻址慢的问题,它还协助 I/O 调度算法实现了 IO 合并与预读,这也是顺序读比随机读性能好的原因。这些优势,进一步提升了零拷贝的性能。
需要注意的是,零拷贝技术是不允许进程对文件内容作进一步的加工的,比如压缩数据再发送。
另外,当传输大文件时,不能使用零拷贝,因为可能由于 PageCache 被大文件占据,而导致「热点」小文件无法利用到 PageCache,并且大文件的缓存命中率不高,这时就需要使用「异步 IO + 直接 IO 」的方式。
在 Nginx 里,可以通过配置,设定一个文件大小阈值,针对大文件使用异步 IO 和直接 IO,而对小文件使用零拷贝。
l/O多路复用:select/poll/epoll
我们以最简单 socket 网络模型,一步一步的到 I/O 多路复用。
但我不会具体细节说到每个系统调用的参数,这方面书上肯定比我说的详细。
好了,发车!
最基本的 Socket 模型
要想客户端和服务器能在网络中通信,那必须得使用 Socket 编程,它是进程间通信里比较特别的方式,特别之处在于它是可以跨主机间通信。
Socket 的中文名叫作插口,咋一看还挺迷惑的。事实上,双方要进行网络通信前,各自得创建一个 Socket,这相当于客户端和服务器都开了一个“口子”,双方读取和发送数据的时候,都通过这个“口子”。这样一看,是不是觉得很像弄了一根网线,一头插在客户端,一头插在服务端,然后进行通信。
创建 Socket 的时候,可以指定网络层使用的是 IPv4 还是 IPv6,传输层使用的是 TCP 还是 UDP。
UDP 的 Socket 编程相对简单些,这里我们只介绍基于 TCP 的 Socket 编程。
服务器的程序要先跑起来,然后等待客户端的连接和数据,我们先来看看服务端的 Socket 编程过程是怎样的。
服务端首先调用 socket() 函数,创建网络协议为 IPv4,以及传输协议为 TCP 的 Socket ,接着调用 bind() 函数,给这个 Socket 绑定一个 IP 地址和端口,绑定这两个的目的是什么?
- 绑定端口的目的:当内核收到 TCP 报文,通过 TCP 头里面的端口号,来找到我们的应用程序,然后把数据传递给我们。
- 绑定 IP 地址的目的:一台机器是可以有多个网卡的,每个网卡都有对应的 IP 地址,当绑定一个网卡时,内核在收到该网卡上的包,才会发给我们;
绑定完 IP 地址和端口后,就可以调用 listen() 函数进行监听,此时对应 TCP 状态图中的 listen,如果我们要判定服务器中一个网络程序有没有启动,可以通过 netstat 命令查看对应的端口号是否有被监听。
服务端进入了监听状态后,通过调用 accept() 函数,来从内核获取客户端的连接,如果没有客户端连接,则会阻塞等待客户端连接的到来。
那客户端是怎么发起连接的呢?客户端在创建好 Socket 后,调用 connect() 函数发起连接,该函数的参数要指明服务端的 IP 地址和端口号,然后万众期待的 TCP 三次握手就开始了。
在 TCP 连接的过程中,服务器的内核实际上为每个 Socket 维护了两个队列:
- 一个是「还没完全建立」连接的队列,称为 TCP 半连接队列,这个队列都是没有完成三次握手的连接,此时服务端处于
syn_rcvd的状态; - 一个是「已经建立」连接的队列,称为 TCP 全连接队列,这个队列都是完成了三次握手的连接,此时服务端处于
established状态;
当 TCP 全连接队列不为空后,服务端的 accept() 函数,就会从内核中的 TCP 全连接队列里拿出一个已经完成连接的 Socket 返回应用程序,后续数据传输都用这个 Socket。
注意,监听的 Socket 和真正用来传数据的 Socket 是两个:
- 一个叫作监听 Socket;
- 一个叫作已连接 Socket;
连接建立后,客户端和服务端就开始相互传输数据了,双方都可以通过 read() 和 write() 函数来读写数据。
至此, TCP 协议的 Socket 程序的调用过程就结束了,整个过程如下图:
看到这,不知道你有没有觉得读写 Socket 的方式,好像读写文件一样。
是的,基于 Linux 一切皆文件的理念,在内核中 Socket 也是以「文件」的形式存在的,也是有对应的文件描述符。
PS : 下面会说到内核里的数据结构,不感兴趣的可以跳过这一部分,不会对后续的内容有影响。
文件描述符的作用是什么?每一个进程都有一个数据结构 task_struct,该结构体里有一个指向「文件描述符数组」的成员指针。该数组里列出这个进程打开的所有文件的文件描述符。数组的下标是文件描述符,是一个整数,而数组的内容是一个指针,指向内核中所有打开的文件的列表,也就是说内核可以通过文件描述符找到对应打开的文件。
然后每个文件都有一个 inode,Socket 文件的 inode 指向了内核中的 Socket 结构,在这个结构体里有两个队列,分别是发送队列和接收队列,这个两个队列里面保存的是一个个 struct sk_buff,用链表的组织形式串起来。
sk_buff 可以表示各个层的数据包,在应用层数据包叫 data,在 TCP 层我们称为 segment,在 IP 层我们叫 packet,在数据链路层称为 frame。
你可能会好奇,为什么全部数据包只用一个结构体来描述呢?协议栈采用的是分层结构,上层向下层传递数据时需要增加包头,下层向上层数据时又需要去掉包头,如果每一层都用一个结构体,那在层之间传递数据的时候,就要发生多次拷贝,这将大大降低 CPU 效率。
于是,为了在层级之间传递数据时,不发生拷贝,只用 sk_buff 一个结构体来描述所有的网络包,那它是如何做到的呢?是通过调整 sk_buff 中 data 的指针,比如:
- 当接收报文时,从网卡驱动开始,通过协议栈层层往上传送数据报,通过增加 skb->data 的值,来逐步剥离协议首部。
- 当要发送报文时,创建 sk_buff 结构体,数据缓存区的头部预留足够的空间,用来填充各层首部,在经过各下层协议时,通过减少 skb->data 的值来增加协议首部。
你可以从下面这张图看到,当发送报文时,data 指针的移动过程。
如何服务更多的用户?
前面提到的 TCP Socket 调用流程是最简单、最基本的,它基本只能一对一通信,因为使用的是同步阻塞的方式,当服务端在还没处理完一个客户端的网络 I/O 时,或者 读写操作发生阻塞时,其他客户端是无法与服务端连接的。
可如果我们服务器只能服务一个客户,那这样就太浪费资源了,于是我们要改进这个网络 I/O 模型,以支持更多的客户端。
在改进网络 I/O 模型前,我先来提一个问题,你知道服务器单机理论最大能连接多少个客户端?
相信你知道 TCP 连接是由四元组唯一确认的,这个四元组就是:本机IP, 本机端口, 对端IP, 对端端口。
服务器作为服务方,通常会在本地固定监听一个端口,等待客户端的连接。因此服务器的本地 IP 和端口是固定的,于是对于服务端 TCP 连接的四元组只有对端 IP 和端口是会变化的,所以最大 TCP 连接数 = 客户端 IP 数×客户端端口数。
对于 IPv4,客户端的 IP 数最多为 2 的 32 次方,客户端的端口数最多为 2 的 16 次方,也就是服务端单机最大 TCP 连接数约为 2 的 48 次方。
这个理论值相当“丰满”,但是服务器肯定承载不了那么大的连接数,主要会受两个方面的限制:
- 文件描述符,Socket 实际上是一个文件,也就会对应一个文件描述符。在 Linux 下,单个进程打开的文件描述符数是有限制的,没有经过修改的值一般都是 1024,不过我们可以通过 ulimit 增大文件描述符的数目;
- 系统内存,每个 TCP 连接在内核中都有对应的数据结构,意味着每个连接都是会占用一定内存的;
那如果服务器的内存只有 2 GB,网卡是千兆的,能支持并发 1 万请求吗?
并发 1 万请求,也就是经典的 C10K 问题 ,C 是 Client 单词首字母缩写,C10K 就是单机同时处理 1 万个请求的问题。
从硬件资源角度看,对于 2GB 内存千兆网卡的服务器,如果每个请求处理占用不到 200KB 的内存和 100Kbit 的网络带宽就可以满足并发 1 万个请求。
不过,要想真正实现 C10K 的服务器,要考虑的地方在于服务器的网络 I/O 模型,效率低的模型,会加重系统开销,从而会离 C10K 的目标越来越远。
多进程模型
基于最原始的阻塞网络 I/O, 如果服务器要支持多个客户端,其中比较传统的方式,就是使用多进程模型,也就是为每个客户端分配一个进程来处理请求。
服务器的主进程负责监听客户的连接,一旦与客户端连接完成,accept() 函数就会返回一个「已连接 Socket」,这时就通过 fork() 函数创建一个子进程,实际上就把父进程所有相关的东西都复制一份,包括文件描述符、内存地址空间、程序计数器、执行的代码等。
这两个进程刚复制完的时候,几乎一模一样。不过,会根据返回值来区分是父进程还是子进程,如果返回值是 0,则是子进程;如果返回值是其他的整数,就是父进程。
正因为子进程会复制父进程的文件描述符,于是就可以直接使用「已连接 Socket 」和客户端通信了,
可以发现,子进程不需要关心「监听 Socket」,只需要关心「已连接 Socket」;父进程则相反,将客户服务交给子进程来处理,因此父进程不需要关心「已连接 Socket」,只需要关心「监听 Socket」。
下面这张图描述了从连接请求到连接建立,父进程创建生子进程为客户服务。
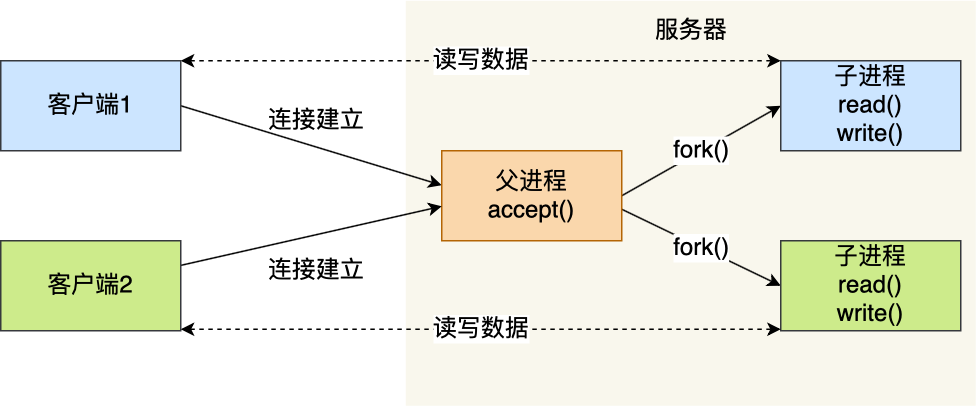
另外,当「子进程」退出时,实际上内核里还会保留该进程的一些信息,也是会占用内存的,如果不做好“回收”工作,就会变成僵尸进程,随着僵尸进程越多,会慢慢耗尽我们的系统资源。
因此,父进程要“善后”好自己的孩子,怎么善后呢?那么有两种方式可以在子进程退出后回收资源,分别是调用 wait() 和 waitpid() 函数。
这种用多个进程来应付多个客户端的方式,在应对 100 个客户端还是可行的,但是当客户端数量高达一万时,肯定扛不住的,因为每产生一个进程,必会占据一定的系统资源,而且进程间上下文切换的“包袱”是很重的,性能会大打折扣。
进程的上下文切换不仅包含了虚拟内存、栈、全局变量等用户空间的资源,还包括了内核堆栈、寄存器等内核空间的资源。
多线程模型
既然进程间上下文切换的“包袱”很重,那我们就搞个比较轻量级的模型来应对多用户的请求 —— 多线程模型。
线程是运行在进程中的一个“逻辑流”,单进程中可以运行多个线程,同进程里的线程可以共享进程的部分资源,比如文件描述符列表、进程空间、代码、全局数据、堆、共享库等,这些共享资源在上下文切换时不需要切换,而只需要切换线程的私有数据、寄存器等不共享的数据,因此同一个进程下的线程上下文切换的开销要比进程小得多。
当服务器与客户端 TCP 完成连接后,通过 pthread_create() 函数创建线程,然后将「已连接 Socket」的文件描述符传递给线程函数,接着在线程里和客户端进行通信,从而达到并发处理的目的。
如果每来一个连接就创建一个线程,线程运行完后,还得操作系统还得销毁线程,虽说线程切换的上写文开销不大,但是如果频繁创建和销毁线程,系统开销也是不小的。
那么,我们可以使用线程池的方式来避免线程的频繁创建和销毁,所谓的线程池,就是提前创建若干个线程,这样当由新连接建立时,将这个已连接的 Socket 放入到一个队列里,然后线程池里的线程负责从队列中取出「已连接 Socket 」进行处理。
需要注意的是,这个队列是全局的,每个线程都会操作,为了避免多线程竞争,线程在操作这个队列前要加锁。
上面基于进程或者线程模型的,其实还是有问题的。新到来一个 TCP 连接,就需要分配一个进程或者线程,那么如果要达到 C10K,意味着要一台机器维护 1 万个连接,相当于要维护 1 万个进程/线程,操作系统就算死扛也是扛不住的。
I/O 多路复用
既然为每个请求分配一个进程/线程的方式不合适,那有没有可能只使用一个进程来维护多个 Socket 呢?答案是有的,那就是 I/O 多路复用技术。
一个进程虽然任一时刻只能处理一个请求,但是处理每个请求的事件时,耗时控制在 1 毫秒以内,这样 1 秒内就可以处理上千个请求,把时间拉长来看,多个请求复用了一个进程,这就是多路复用,这种思想很类似一个 CPU 并发多个进程,所以也叫做时分多路复用。
我们熟悉的 select/poll/epoll 内核提供给用户态的多路复用系统调用,进程可以通过一个系统调用函数从内核中获取多个事件。
select/poll/epoll 是如何获取网络事件的呢?在获取事件时,先把所有连接(文件描述符)传给内核,再由内核返回产生了事件的连接,然后在用户态中再处理这些连接对应的请求即可。
select/poll/epoll 这是三个多路复用接口,都能实现 C10K 吗?接下来,我们分别说说它们。
select/poll
select 实现多路复用的方式是,将已连接的 Socket 都放到一个文件描述符集合,然后调用 select 函数将文件描述符集合拷贝到内核里,让内核来检查是否有网络事件产生,检查的方式很粗暴,就是通过遍历文件描述符集合的方式,当检查到有事件产生后,将此 Socket 标记为可读或可写, 接着再把整个文件描述符集合拷贝回用户态里,然后用户态还需要再通过遍历的方法找到可读或可写的 Socket,然后再对其处理。
所以,对于 select 这种方式,需要进行 2 次「遍历」文件描述符集合,一次是在内核态里,一个次是在用户态里 ,而且还会发生 2 次「拷贝」文件描述符集合,先从用户空间传入内核空间,由内核修改后,再传出到用户空间中。
select 使用固定长度的 BitsMap,表示文件描述符集合,而且所支持的文件描述符的个数是有限制的,在 Linux 系统中,由内核中的 FD_SETSIZE 限制, 默认最大值为 1024,只能监听 0~1023 的文件描述符。
poll 不再用 BitsMap 来存储所关注的文件描述符,取而代之用动态数组,以链表形式来组织,突破了 select 的文件描述符个数限制,当然还会受到系统文件描述符限制。
但是 poll 和 select 并没有太大的本质区别,都是使用「线性结构」存储进程关注的 Socket 集合,因此都需要遍历文件描述符集合来找到可读或可写的 Socket,时间复杂度为 O(n),而且也需要在用户态与内核态之间拷贝文件描述符集合,这种方式随着并发数上来,性能的损耗会呈指数级增长。
epoll
先复习下 epoll 的用法。如下的代码中,先用epoll_create 创建一个 epoll对象 epfd,再通过 epoll_ctl 将需要监视的 socket 添加到epfd中,最后调用 epoll_wait 等待数据。
|
|
epoll 通过两个方面,很好解决了 select/poll 的问题。
第一点,epoll 在内核里使用红黑树来跟踪进程所有待检测的文件描述字,把需要监控的 socket 通过 epoll_ctl() 函数加入内核中的红黑树里,红黑树是个高效的数据结构,增删改一般时间复杂度是 O(logn)。而 select/poll 内核里没有类似 epoll 红黑树这种保存所有待检测的 socket 的数据结构,所以 select/poll 每次操作时都传入整个 socket 集合给内核,而 epoll 因为在内核维护了红黑树,可以保存所有待检测的 socket ,所以只需要传入一个待检测的 socket,减少了内核和用户空间大量的数据拷贝和内存分配。
第二点, epoll 使用事件驱动的机制,内核里维护了一个链表来记录就绪事件,当某个 socket 有事件发生时,通过回调函数内核会将其加入到这个就绪事件列表中,当用户调用 epoll_wait() 函数时,只会返回有事件发生的文件描述符的个数,不需要像 select/poll 那样轮询扫描整个 socket 集合,大大提高了检测的效率。
从下图你可以看到 epoll 相关的接口作用:
epoll 的方式即使监听的 Socket 数量越多的时候,效率不会大幅度降低,能够同时监听的 Socket 的数目也非常的多了,上限就为系统定义的进程打开的最大文件描述符个数。因而,epoll 被称为解决 C10K 问题的利器。
插个题外话,网上文章不少说,epoll_wait 返回时,对于就绪的事件,epoll 使用的是共享内存的方式,即用户态和内核态都指向了就绪链表,所以就避免了内存拷贝消耗。
这是错的!看过 epoll 内核源码的都知道,压根就没有使用共享内存这个玩意。你可以从下面这份代码看到, epoll_wait 实现的内核代码中调用了 __put_user 函数,这个函数就是将数据从内核拷贝到用户空间。

好了,这个题外话就说到这了,我们继续!
边缘触发和水平触发
epoll 支持两种事件触发模式,分别是边缘触发(*edge-triggered,ET*)**和**水平触发(*level-triggered,LT*)。
这两个术语还挺抽象的,其实它们的区别还是很好理解的。
- 使用边缘触发模式时,当被监控的 Socket 描述符上有可读事件发生时,服务器端只会从 epoll_wait 中苏醒一次,即使进程没有调用 read 函数从内核读取数据,也依然只苏醒一次,因此我们程序要保证一次性将内核缓冲区的数据读取完;
- 使用水平触发模式时,当被监控的 Socket 上有可读事件发生时,服务器端不断地从 epoll_wait 中苏醒,直到内核缓冲区数据被 read 函数读完才结束,目的是告诉我们有数据需要读取;
举个例子,你的快递被放到了一个快递箱里,如果快递箱只会通过短信通知你一次,即使你一直没有去取,它也不会再发送第二条短信提醒你,这个方式就是边缘触发;如果快递箱发现你的快递没有被取出,它就会不停地发短信通知你,直到你取出了快递,它才消停,这个就是水平触发的方式。
这就是两者的区别,水平触发的意思是只要满足事件的条件,比如内核中有数据需要读,就一直不断地把这个事件传递给用户;而边缘触发的意思是只有第一次满足条件的时候才触发,之后就不会再传递同样的事件了。
如果使用水平触发模式,当内核通知文件描述符可读写时,接下来还可以继续去检测它的状态,看它是否依然可读或可写。所以在收到通知后,没必要一次执行尽可能多的读写操作。
如果使用边缘触发模式,I/O 事件发生时只会通知一次,而且我们不知道到底能读写多少数据,所以在收到通知后应尽可能地读写数据,以免错失读写的机会。因此,我们会循环从文件描述符读写数据,那么如果文件描述符是阻塞的,没有数据可读写时,进程会阻塞在读写函数那里,程序就没办法继续往下执行。所以,边缘触发模式一般和非阻塞 I/O 搭配使用,程序会一直执行 I/O 操作,直到系统调用(如 read 和 write)返回错误,错误类型为 EAGAIN 或 EWOULDBLOCK。
一般来说,边缘触发的效率比水平触发的效率要高,因为边缘触发可以减少 epoll_wait 的系统调用次数,系统调用也是有一定的开销的的,毕竟也存在上下文的切换。
select/poll 只有水平触发模式,epoll 默认的触发模式是水平触发,但是可以根据应用场景设置为边缘触发模式。
另外,使用 I/O 多路复用时,最好搭配非阻塞 I/O 一起使用,Linux 手册关于 select 的内容中有如下说明:
Under Linux, select() may report a socket file descriptor as “ready for reading”, while nevertheless a subsequent read blocks. This could for example happen when data has arrived but upon examination has wrong checksum and is discarded. There may be other circumstances in which a file descriptor is spuriously reported as ready. Thus it may be safer to use O_NONBLOCK on sockets that should not block.
我谷歌翻译的结果:
在Linux下,select() 可能会将一个 socket 文件描述符报告为 “准备读取”,而后续的读取块却没有。例如,当数据已经到达,但经检查后发现有错误的校验和而被丢弃时,就会发生这种情况。也有可能在其他情况下,文件描述符被错误地报告为就绪。因此,在不应该阻塞的 socket 上使用 O_NONBLOCK 可能更安全。
简单点理解,就是多路复用 API 返回的事件并不一定可读写的,如果使用阻塞 I/O, 那么在调用 read/write 时则会发生程序阻塞,因此最好搭配非阻塞 I/O,以便应对极少数的特殊情况。
总结
最基础的 TCP 的 Socket 编程,它是阻塞 I/O 模型,基本上只能一对一通信,那为了服务更多的客户端,我们需要改进网络 I/O 模型。
比较传统的方式是使用多进程/线程模型,每来一个客户端连接,就分配一个进程/线程,然后后续的读写都在对应的进程/线程,这种方式处理 100 个客户端没问题,但是当客户端增大到 10000 个时,10000 个进程/线程的调度、上下文切换以及它们占用的内存,都会成为瓶颈。
为了解决上面这个问题,就出现了 I/O 的多路复用,可以只在一个进程里处理多个文件的 I/O,Linux 下有三种提供 I/O 多路复用的 API,分别是:select、poll、epoll。
select 和 poll 并没有本质区别,它们内部都是使用「线性结构」来存储进程关注的 Socket 集合。
在使用的时候,首先需要把关注的 Socket 集合通过 select/poll 系统调用从用户态拷贝到内核态,然后由内核检测事件,当有网络事件产生时,内核需要遍历进程关注 Socket 集合,找到对应的 Socket,并设置其状态为可读/可写,然后把整个 Socket 集合从内核态拷贝到用户态,用户态还要继续遍历整个 Socket 集合找到可读/可写的 Socket,然后对其处理。
很明显发现,select 和 poll 的缺陷在于,当客户端越多,也就是 Socket 集合越大,Socket 集合的遍历和拷贝会带来很大的开销,因此也很难应对 C10K。
epoll 是解决 C10K 问题的利器,通过两个方面解决了 select/poll 的问题。
- epoll 在内核里使用「红黑树」来关注进程所有待检测的 Socket,红黑树是个高效的数据结构,增删改一般时间复杂度是 O(logn),通过对这棵黑红树的管理,不需要像 select/poll 在每次操作时都传入整个 Socket 集合,减少了内核和用户空间大量的数据拷贝和内存分配。
- epoll 使用事件驱动的机制,内核里维护了一个「链表」来记录就绪事件,只将有事件发生的 Socket 集合传递给应用程序,不需要像 select/poll 那样轮询扫描整个集合(包含有和无事件的 Socket ),大大提高了检测的效率。
而且,epoll 支持边缘触发和水平触发的方式,而 select/poll 只支持水平触发,一般而言,边缘触发的方式会比水平触发的效率高。
高性能网络模式:Reactor和Proactor
这次就来图解 Reactor 和 Proactor 这两个高性能网络模式。
别小看这两个东西,特别是 Reactor 模式,市面上常见的开源软件很多都采用了这个方案,比如 Redis、Nginx、Netty 等等,所以学好这个模式设计的思想,不仅有助于我们理解很多开源软件,而且也能在面试时吹逼。
发车!
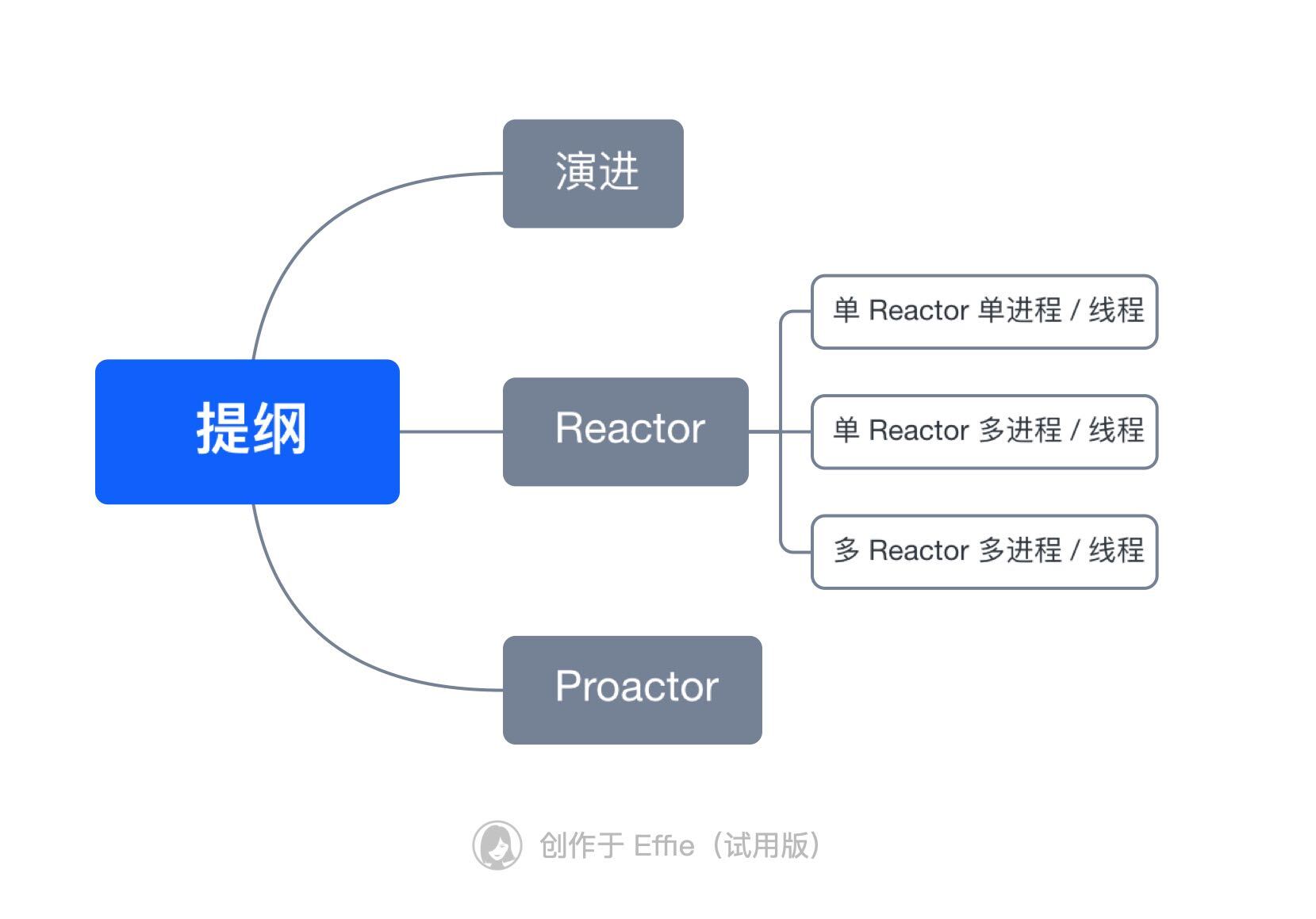
演进
如果要让服务器服务多个客户端,那么最直接的方式就是为每一条连接创建线程。
其实创建进程也是可以的,原理是一样的,进程和线程的区别在于线程比较轻量级些,线程的创建和线程间切换的成本要小些,为了描述简述,后面都以线程为例。
处理完业务逻辑后,随着连接关闭后线程也同样要销毁了,但是这样不停地创建和销毁线程,不仅会带来性能开销,也会造成浪费资源,而且如果要连接几万条连接,创建几万个线程去应对也是不现实的。
要这么解决这个问题呢?我们可以使用「资源复用」的方式。
也就是不用再为每个连接创建线程,而是创建一个「线程池」,将连接分配给线程,然后一个线程可以处理多个连接的业务。
不过,这样又引来一个新的问题,线程怎样才能高效地处理多个连接的业务?
当一个连接对应一个线程时,线程一般采用「read -> 业务处理 -> send」的处理流程,如果当前连接没有数据可读,那么线程会阻塞在 read 操作上( socket 默认情况是阻塞 I/O),不过这种阻塞方式并不影响其他线程。
但是引入了线程池,那么一个线程要处理多个连接的业务,线程在处理某个连接的 read 操作时,如果遇到没有数据可读,就会发生阻塞,那么线程就没办法继续处理其他连接的业务。
要解决这一个问题,最简单的方式就是将 socket 改成非阻塞,然后线程不断地轮询调用 read 操作来判断是否有数据,这种方式虽然该能够解决阻塞的问题,但是解决的方式比较粗暴,因为轮询是要消耗 CPU 的,而且随着一个 线程处理的连接越多,轮询的效率就会越低。
上面的问题在于,线程并不知道当前连接是否有数据可读,从而需要每次通过 read 去试探。
那有没有办法在只有当连接上有数据的时候,线程才去发起读请求呢?答案是有的,实现这一技术的就是 I/O 多路复用。
I/O 多路复用技术会用一个系统调用函数来监听我们所有关心的连接,也就说可以在一个监控线程里面监控很多的连接。
我们熟悉的 select/poll/epoll 就是内核提供给用户态的多路复用系统调用,线程可以通过一个系统调用函数从内核中获取多个事件。
PS:如果想知道 select/poll/epoll 的区别,可以看看小林之前写的这篇文章:这次答应我,一举拿下 I/O 多路复用!(opens new window)
select/poll/epoll 是如何获取网络事件的呢?
在获取事件时,先把我们要关心的连接传给内核,再由内核检测:
- 如果没有事件发生,线程只需阻塞在这个系统调用,而无需像前面的线程池方案那样轮训调用 read 操作来判断是否有数据。
- 如果有事件发生,内核会返回产生了事件的连接,线程就会从阻塞状态返回,然后在用户态中再处理这些连接对应的业务即可。
当下开源软件能做到网络高性能的原因就是 I/O 多路复用吗?
是的,基本是基于 I/O 多路复用,用过 I/O 多路复用接口写网络程序的同学,肯定知道是面向过程的方式写代码的,这样的开发的效率不高。
于是,大佬们基于面向对象的思想,对 I/O 多路复用作了一层封装,让使用者不用考虑底层网络 API 的细节,只需要关注应用代码的编写。
大佬们还为这种模式取了个让人第一时间难以理解的名字:Reactor 模式。
Reactor 翻译过来的意思是「反应堆」,可能大家会联想到物理学里的核反应堆,实际上并不是的这个意思。
这里的反应指的是「对事件反应」,也就是来了一个事件,Reactor 就有相对应的反应/响应。
事实上,Reactor 模式也叫 Dispatcher 模式,我觉得这个名字更贴合该模式的含义,即 I/O 多路复用监听事件,收到事件后,根据事件类型分配(Dispatch)给某个进程 / 线程。
Reactor 模式主要由 Reactor 和处理资源池这两个核心部分组成,它俩负责的事情如下:
- Reactor 负责监听和分发事件,事件类型包含连接事件、读写事件;
- 处理资源池负责处理事件,如 read -> 业务逻辑 -> send;
Reactor 模式是灵活多变的,可以应对不同的业务场景,灵活在于:
- Reactor 的数量可以只有一个,也可以有多个;
- 处理资源池可以是单个进程 / 线程,也可以是多个进程 /线程;
将上面的两个因素排列组设一下,理论上就可以有 4 种方案选择:
- 单 Reactor 单进程 / 线程;
- 单 Reactor 多进程 / 线程;
- 多 Reactor 单进程 / 线程;
- 多 Reactor 多进程 / 线程;
其中,「多 Reactor 单进程 / 线程」实现方案相比「单 Reactor 单进程 / 线程」方案,不仅复杂而且也没有性能优势,因此实际中并没有应用。
剩下的 3 个方案都是比较经典的,且都有应用在实际的项目中:
- 单 Reactor 单进程 / 线程;
- 单 Reactor 多线程 / 进程;
- 多 Reactor 多进程 / 线程;
方案具体使用进程还是线程,要看使用的编程语言以及平台有关:
- Java 语言一般使用线程,比如 Netty;
- C 语言使用进程和线程都可以,例如 Nginx 使用的是进程,Memcache 使用的是线程。
接下来,分别介绍这三个经典的 Reactor 方案。
Reactor
单 Reactor 单进程 / 线程
一般来说,C 语言实现的是「单 Reactor *单进程*」的方案,因为 C 语编写完的程序,运行后就是一个独立的进程,不需要在进程中再创建线程。
而 Java 语言实现的是「单 Reactor *单线程*」的方案,因为 Java 程序是跑在 Java 虚拟机这个进程上面的,虚拟机中有很多线程,我们写的 Java 程序只是其中的一个线程而已。
我们来看看「单 Reactor 单进程」的方案示意图:
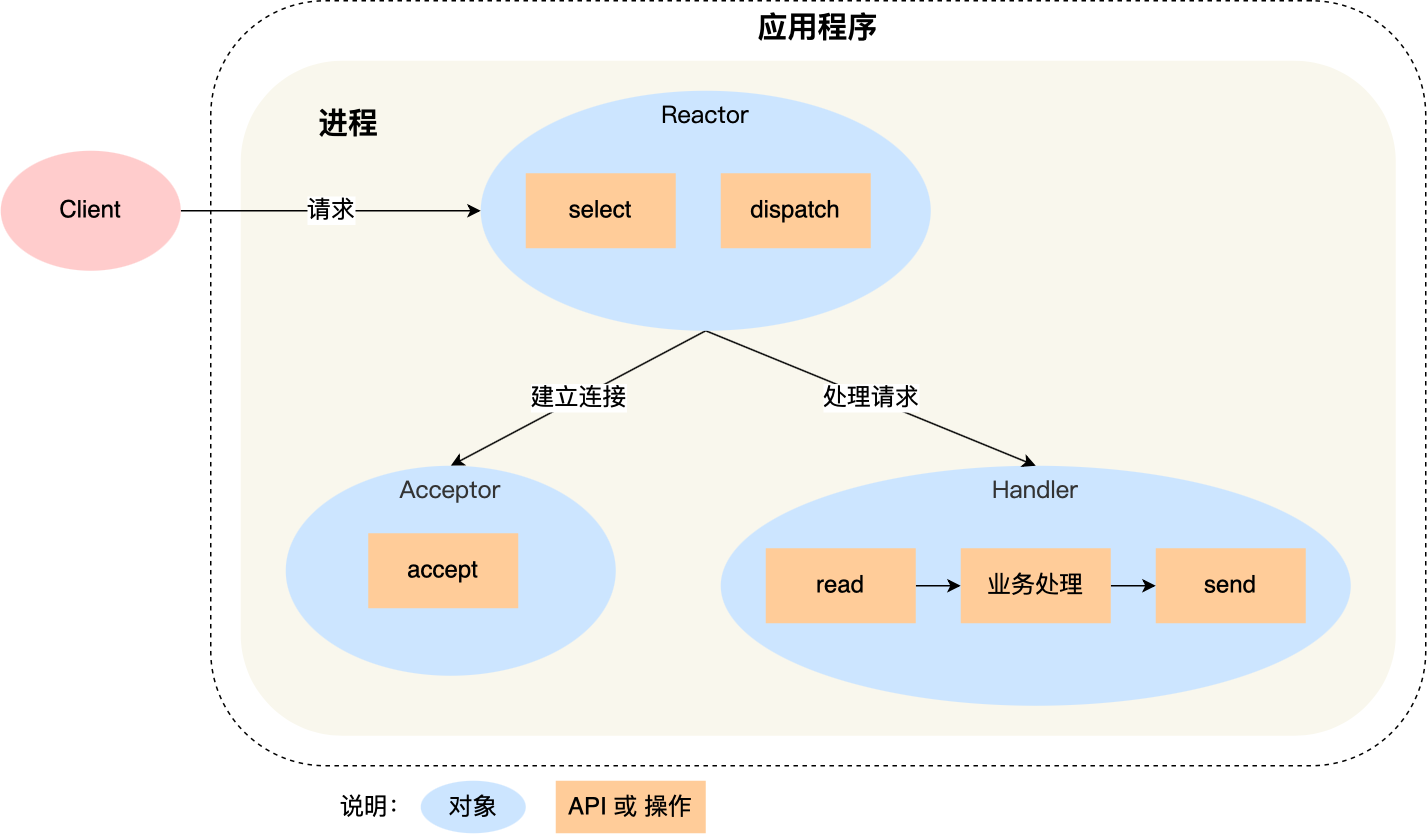
可以看到进程里有 Reactor、Acceptor、Handler 这三个对象:
- Reactor 对象的作用是监听和分发事件;
- Acceptor 对象的作用是获取连接;
- Handler 对象的作用是处理业务;
对象里的 select、accept、read、send 是系统调用函数,dispatch 和 「业务处理」是需要完成的操作,其中 dispatch 是分发事件操作。
接下来,介绍下「单 Reactor 单进程」这个方案:
- Reactor 对象通过 select (IO 多路复用接口) 监听事件,收到事件后通过 dispatch 进行分发,具体分发给 Acceptor 对象还是 Handler 对象,还要看收到的事件类型;
- 如果是连接建立的事件,则交由 Acceptor 对象进行处理,Acceptor 对象会通过 accept 方法 获取连接,并创建一个 Handler 对象来处理后续的响应事件;
- 如果不是连接建立事件, 则交由当前连接对应的 Handler 对象来进行响应;
- Handler 对象通过 read -> 业务处理 -> send 的流程来完成完整的业务流程。
单 Reactor 单进程的方案因为全部工作都在同一个进程内完成,所以实现起来比较简单,不需要考虑进程间通信,也不用担心多进程竞争。
但是,这种方案存在 2 个缺点:
- 第一个缺点,因为只有一个进程,无法充分利用 多核 CPU 的性能;
- 第二个缺点,Handler 对象在业务处理时,整个进程是无法处理其他连接的事件的,如果业务处理耗时比较长,那么就造成响应的延迟;
所以,单 Reactor 单进程的方案不适用计算机密集型的场景,只适用于业务处理非常快速的场景。
Redis 是由 C 语言实现的,在 Redis 6.0 版本之前采用的正是「单 Reactor 单进程」的方案,因为 Redis 业务处理主要是在内存中完成,操作的速度是很快的,性能瓶颈不在 CPU 上,所以 Redis 对于命令的处理是单进程的方案。
单 Reactor 多线程 / 多进程
如果要克服「单 Reactor 单线程 / 进程」方案的缺点,那么就需要引入多线程 / 多进程,这样就产生了单 Reactor 多线程 / 多进程的方案。
闻其名不如看其图,先来看看「单 Reactor 多线程」方案的示意图如下:
详细说一下这个方案:
- Reactor 对象通过 select (IO 多路复用接口) 监听事件,收到事件后通过 dispatch 进行分发,具体分发给 Acceptor 对象还是 Handler 对象,还要看收到的事件类型;
- 如果是连接建立的事件,则交由 Acceptor 对象进行处理,Acceptor 对象会通过 accept 方法 获取连接,并创建一个 Handler 对象来处理后续的响应事件;
- 如果不是连接建立事件, 则交由当前连接对应的 Handler 对象来进行响应;
上面的三个步骤和单 Reactor 单线程方案是一样的,接下来的步骤就开始不一样了:
- Handler 对象不再负责业务处理,只负责数据的接收和发送,Handler 对象通过 read 读取到数据后,会将数据发给子线程里的 Processor 对象进行业务处理;
- 子线程里的 Processor 对象就进行业务处理,处理完后,将结果发给主线程中的 Handler 对象,接着由 Handler 通过 send 方法将响应结果发送给 client;
单 Reator 多线程的方案优势在于能够充分利用多核 CPU 的能,那既然引入多线程,那么自然就带来了多线程竞争资源的问题。
例如,子线程完成业务处理后,要把结果传递给主线程的 Handler 进行发送,这里涉及共享数据的竞争。
要避免多线程由于竞争共享资源而导致数据错乱的问题,就需要在操作共享资源前加上互斥锁,以保证任意时间里只有一个线程在操作共享资源,待该线程操作完释放互斥锁后,其他线程才有机会操作共享数据。
聊完单 Reactor 多线程的方案,接着来看看单 Reactor 多进程的方案。
事实上,单 Reactor 多进程相比单 Reactor 多线程实现起来很麻烦,主要因为要考虑子进程 <-> 父进程的双向通信,并且父进程还得知道子进程要将数据发送给哪个客户端。
而多线程间可以共享数据,虽然要额外考虑并发问题,但是这远比进程间通信的复杂度低得多,因此实际应用中也看不到单 Reactor 多进程的模式。
另外,「单 Reactor」的模式还有个问题,因为一个 Reactor 对象承担所有事件的监听和响应,而且只在主线程中运行,在面对瞬间高并发的场景时,容易成为性能的瓶颈的地方。
多 Reactor 多进程 / 线程
要解决「单 Reactor」的问题,就是将「单 Reactor」实现成「多 Reactor」,这样就产生了第 多 Reactor 多进程 / 线程的方案。
老规矩,闻其名不如看其图。多 Reactor 多进程 / 线程方案的示意图如下(以线程为例):
方案详细说明如下:
- 主线程中的 MainReactor 对象通过 select 监控连接建立事件,收到事件后通过 Acceptor 对象中的 accept 获取连接,将新的连接分配给某个子线程;
- 子线程中的 SubReactor 对象将 MainReactor 对象分配的连接加入 select 继续进行监听,并创建一个 Handler 用于处理连接的响应事件。
- 如果有新的事件发生时,SubReactor 对象会调用当前连接对应的 Handler 对象来进行响应。
- Handler 对象通过 read -> 业务处理 -> send 的流程来完成完整的业务流程。
多 Reactor 多线程的方案虽然看起来复杂的,但是实际实现时比单 Reactor 多线程的方案要简单的多,原因如下:
- 主线程和子线程分工明确,主线程只负责接收新连接,子线程负责完成后续的业务处理。
- 主线程和子线程的交互很简单,主线程只需要把新连接传给子线程,子线程无须返回数据,直接就可以在子线程将处理结果发送给客户端。
大名鼎鼎的两个开源软件 Netty 和 Memcache 都采用了「多 Reactor 多线程」的方案。
采用了「多 Reactor 多进程」方案的开源软件是 Nginx,不过方案与标准的多 Reactor 多进程有些差异。
具体差异表现在主进程中仅仅用来初始化 socket,并没有创建 mainReactor 来 accept 连接,而是由子进程的 Reactor 来 accept 连接,通过锁来控制一次只有一个子进程进行 accept(防止出现惊群现象),子进程 accept 新连接后就放到自己的 Reactor 进行处理,不会再分配给其他子进程。
Proactor
前面提到的 Reactor 是非阻塞同步网络模式,而 Proactor 是异步网络模式。
这里先给大家复习下阻塞、非阻塞、同步、异步 I/O 的概念。
先来看看阻塞 I/O,当用户程序执行 read ,线程会被阻塞,一直等到内核数据准备好,并把数据从内核缓冲区拷贝到应用程序的缓冲区中,当拷贝过程完成,read 才会返回。
注意,阻塞等待的是「内核数据准备好」和「数据从内核态拷贝到用户态」这两个过程。过程如下图:
知道了阻塞 I/O ,来看看非阻塞 I/O,非阻塞的 read 请求在数据未准备好的情况下立即返回,可以继续往下执行,此时应用程序不断轮询内核,直到数据准备好,内核将数据拷贝到应用程序缓冲区,read 调用才可以获取到结果。过程如下图:
注意,这里最后一次 read 调用,获取数据的过程,是一个同步的过程,是需要等待的过程。这里的同步指的是内核态的数据拷贝到用户程序的缓存区这个过程。
举个例子,如果 socket 设置了 O_NONBLOCK 标志,那么就表示使用的是非阻塞 I/O 的方式访问,而不做任何设置的话,默认是阻塞 I/O。
因此,无论 read 和 send 是阻塞 I/O,还是非阻塞 I/O 都是同步调用。因为在 read 调用时,内核将数据从内核空间拷贝到用户空间的过程都是需要等待的,也就是说这个过程是同步的,如果内核实现的拷贝效率不高,read 调用就会在这个同步过程中等待比较长的时间。
而真正的异步 I/O 是「内核数据准备好」和「数据从内核态拷贝到用户态」这两个过程都不用等待。
当我们发起 aio_read (异步 I/O) 之后,就立即返回,内核自动将数据从内核空间拷贝到用户空间,这个拷贝过程同样是异步的,内核自动完成的,和前面的同步操作不一样,应用程序并不需要主动发起拷贝动作。过程如下图:
举个你去饭堂吃饭的例子,你好比应用程序,饭堂好比操作系统。
阻塞 I/O 好比,你去饭堂吃饭,但是饭堂的菜还没做好,然后你就一直在那里等啊等,等了好长一段时间终于等到饭堂阿姨把菜端了出来(数据准备的过程),但是你还得继续等阿姨把菜(内核空间)打到你的饭盒里(用户空间),经历完这两个过程,你才可以离开。
非阻塞 I/O 好比,你去了饭堂,问阿姨菜做好了没有,阿姨告诉你没,你就离开了,过几十分钟,你又来饭堂问阿姨,阿姨说做好了,于是阿姨帮你把菜打到你的饭盒里,这个过程你是得等待的。
异步 I/O 好比,你让饭堂阿姨将菜做好并把菜打到饭盒里后,把饭盒送到你面前,整个过程你都不需要任何等待。
很明显,异步 I/O 比同步 I/O 性能更好,因为异步 I/O 在「内核数据准备好」和「数据从内核空间拷贝到用户空间」这两个过程都不用等待。
Proactor 正是采用了异步 I/O 技术,所以被称为异步网络模型。
现在我们再来理解 Reactor 和 Proactor 的区别,就比较清晰了。
- Reactor 是非阻塞同步网络模式,感知的是就绪可读写事件。在每次感知到有事件发生(比如可读就绪事件)后,就需要应用进程主动调用 read 方法来完成数据的读取,也就是要应用进程主动将 socket 接收缓存中的数据读到应用进程内存中,这个过程是同步的,读取完数据后应用进程才能处理数据。
- Proactor 是异步网络模式, 感知的是已完成的读写事件。在发起异步读写请求时,需要传入数据缓冲区的地址(用来存放结果数据)等信息,这样系统内核才可以自动帮我们把数据的读写工作完成,这里的读写工作全程由操作系统来做,并不需要像 Reactor 那样还需要应用进程主动发起 read/write 来读写数据,操作系统完成读写工作后,就会通知应用进程直接处理数据。
因此,Reactor 可以理解为「来了事件操作系统通知应用进程,让应用进程来处理」,而 Proactor 可以理解为「来了事件操作系统来处理,处理完再通知应用进程」。这里的「事件」就是有新连接、有数据可读、有数据可写的这些 I/O 事件这里的「处理」包含从驱动读取到内核以及从内核读取到用户空间。
举个实际生活中的例子,Reactor 模式就是快递员在楼下,给你打电话告诉你快递到你家小区了,你需要自己下楼来拿快递。而在 Proactor 模式下,快递员直接将快递送到你家门口,然后通知你。
无论是 Reactor,还是 Proactor,都是一种基于「事件分发」的网络编程模式,区别在于 Reactor 模式是基于「待完成」的 I/O 事件,而 Proactor 模式则是基于「已完成」的 I/O 事件。
接下来,一起看看 Proactor 模式的示意图:
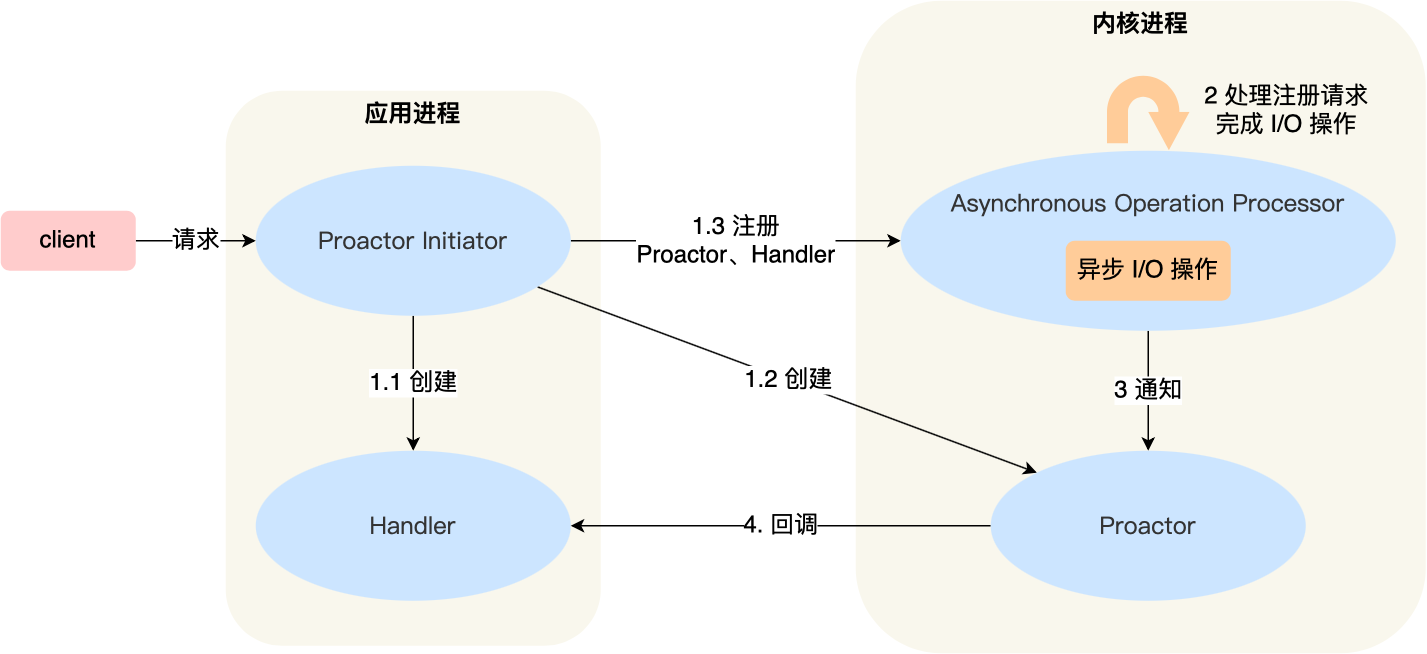
介绍一下 Proactor 模式的工作流程:
- Proactor Initiator 负责创建 Proactor 和 Handler 对象,并将 Proactor 和 Handler 都通过 Asynchronous Operation Processor 注册到内核;
- Asynchronous Operation Processor 负责处理注册请求,并处理 I/O 操作;
- Asynchronous Operation Processor 完成 I/O 操作后通知 Proactor;
- Proactor 根据不同的事件类型回调不同的 Handler 进行业务处理;
- Handler 完成业务处理;
可惜的是,在 Linux 下的异步 I/O 是不完善的, aio 系列函数是由 POSIX 定义的异步操作接口,不是真正的操作系统级别支持的,而是在用户空间模拟出来的异步,并且仅仅支持基于本地文件的 aio 异步操作,网络编程中的 socket 是不支持的,这也使得基于 Linux 的高性能网络程序都是使用 Reactor 方案。
而 Windows 里实现了一套完整的支持 socket 的异步编程接口,这套接口就是 IOCP,是由操作系统级别实现的异步 I/O,真正意义上异步 I/O,因此在 Windows 里实现高性能网络程序可以使用效率更高的 Proactor 方案。
总结
常见的 Reactor 实现方案有三种。
第一种方案单 Reactor 单进程 / 线程,不用考虑进程间通信以及数据同步的问题,因此实现起来比较简单,这种方案的缺陷在于无法充分利用多核 CPU,而且处理业务逻辑的时间不能太长,否则会延迟响应,所以不适用于计算机密集型的场景,适用于业务处理快速的场景,比如 Redis(6.0之前 ) 采用的是单 Reactor 单进程的方案。
第二种方案单 Reactor 多线程,通过多线程的方式解决了方案一的缺陷,但它离高并发还差一点距离,差在只有一个 Reactor 对象来承担所有事件的监听和响应,而且只在主线程中运行,在面对瞬间高并发的场景时,容易成为性能的瓶颈的地方。
第三种方案多 Reactor 多进程 / 线程,通过多个 Reactor 来解决了方案二的缺陷,主 Reactor 只负责监听事件,响应事件的工作交给了从 Reactor,Netty 和 Memcache 都采用了「多 Reactor 多线程」的方案,Nginx 则采用了类似于 「多 Reactor 多进程」的方案。
Reactor 可以理解为「来了事件操作系统通知应用进程,让应用进程来处理」,而 Proactor 可以理解为「来了事件操作系统来处理,处理完再通知应用进程」。
因此,真正的大杀器还是 Proactor,它是采用异步 I/O 实现的异步网络模型,感知的是已完成的读写事件,而不需要像 Reactor 感知到事件后,还需要调用 read 来从内核中获取数据。
不过,无论是 Reactor,还是 Proactor,都是一种基于「事件分发」的网络编程模式,区别在于 Reactor 模式是基于「待完成」的 I/O 事件,而 Proactor 模式则是基于「已完成」的 I/O 事件。
什么是一致性哈希?
在逛牛客网的面经的时候,发现有位同学在面微信的时候,被问到这个问题:

第一个问题就是:一致性哈希是什么,使用场景,解决了什么问题?
这个问题还挺有意思的,所以今天就来聊聊这个。
发车!
如何分配请求?
大多数网站背后肯定不是只有一台服务器提供服务,因为单机的并发量和数据量都是有限的,所以都会用多台服务器构成集群来对外提供服务。
但是问题来了,现在有那么多个节点(后面统称服务器为节点,因为少一个字),要如何分配客户端的请求呢?
其实这个问题就是「负载均衡问题」。解决负载均衡问题的算法很多,不同的负载均衡算法,对应的就是不同的分配策略,适应的业务场景也不同。
最简单的方式,引入一个中间的负载均衡层,让它将外界的请求「轮流」的转发给内部的集群。比如集群有 3 个节点,外界请求有 3 个,那么每个节点都会处理 1 个请求,达到了分配请求的目的。
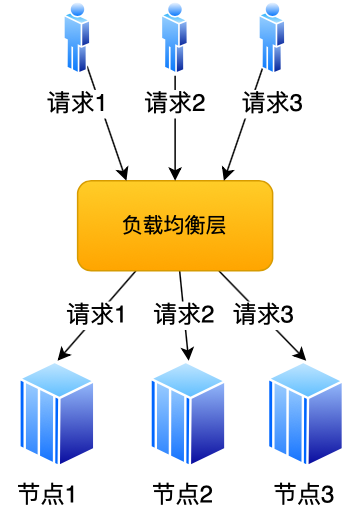
考虑到每个节点的硬件配置有所区别,我们可以引入权重值,将硬件配置更好的节点的权重值设高,然后根据各个节点的权重值,按照一定比重分配在不同的节点上,让硬件配置更好的节点承担更多的请求,这种算法叫做加权轮询。
加权轮询算法使用场景是建立在每个节点存储的数据都是相同的前提。所以,每次读数据的请求,访问任意一个节点都能得到结果。
但是,加权轮询算法是无法应对「分布式系统(数据分片的系统)」的,因为分布式系统中,每个节点存储的数据是不同的。
当我们想提高系统的容量,就会将数据水平切分到不同的节点来存储,也就是将数据分布到了不同的节点。比如一个分布式 KV(key-valu) 缓存系统,某个 key 应该到哪个或者哪些节点上获得,应该是确定的,不是说任意访问一个节点都可以得到缓存结果的。
因此,我们要想一个能应对分布式系统的负载均衡算法。
使用哈希算法有什么问题?
有的同学可能很快就想到了:哈希算法。因为对同一个关键字进行哈希计算,每次计算都是相同的值,这样就可以将某个 key 确定到一个节点了,可以满足分布式系统的负载均衡需求。
哈希算法最简单的做法就是进行取模运算,比如分布式系统中有 3 个节点,基于 hash(key) % 3 公式对数据进行了映射。
如果客户端要获取指定 key 的数据,通过下面的公式可以定位节点:
|
|
如果经过上面这个公式计算后得到的值是 0,就说明该 key 需要去第一个节点获取。
但是有一个很致命的问题,如果节点数量发生了变化,也就是在对系统做扩容或者缩容时,必须迁移改变了映射关系的数据,否则会出现查询不到数据的问题。
举个例子,假设我们有一个由 A、B、C 三个节点组成分布式 KV 缓存系统,基于计算公式 hash(key) % 3 将数据进行了映射,每个节点存储了不同的数据:

现在有 3 个查询 key 的请求,分别查询 key-01,key-02,key-03 的数据,这三个 key 分别经过 hash() 函数计算后的值为 hash( key-01) = 6、hash( key-02) = 7、hash(key-03) = 8,然后再对这些值进行取模运算。
通过这样的哈希算法,每个 key 都可以定位到对应的节点。
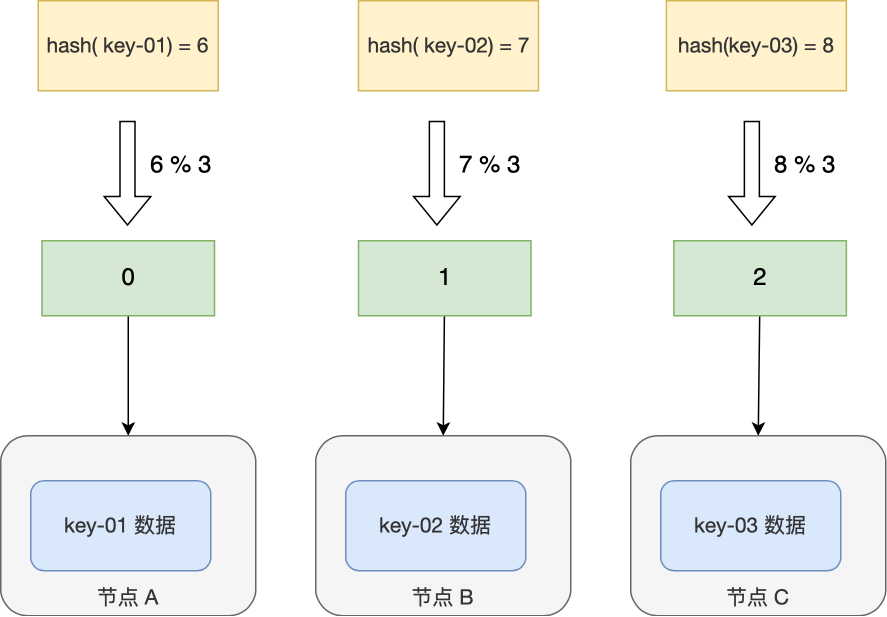
当 3 个节点不能满足业务需求了,这时我们增加了一个节点,节点的数量从 3 变化为 4,意味取模哈希函数中基数的变化,这样会导致大部分映射关系改变,如下图:
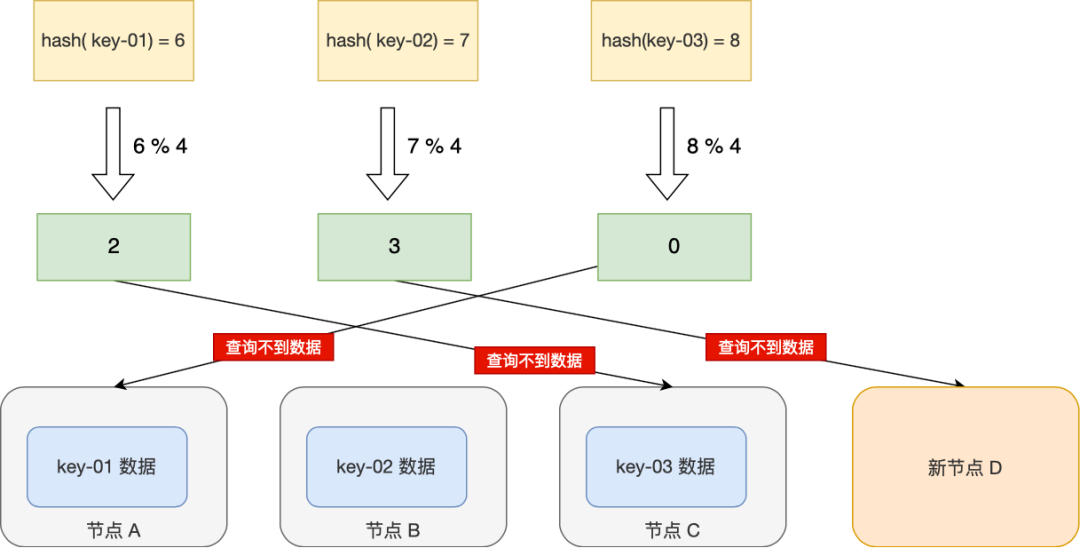
比如,之前的 hash(key-01) % 3 = 0,就变成了 hash(key-01) % 4 = 2,查询 key-01 数据时,寻址到了节点 C,而 key-01 的数据是存储在节点 A 上的,不是在节点 C,所以会查询不到数据。
同样的道理,如果我们对分布式系统进行缩容,比如移除一个节点,也会因为取模哈希函数中基数的变化,可能出现查询不到数据的问题。
要解决这个问题的办法,就需要我们进行迁移数据,比如节点的数量从 3 变化为 4 时,要基于新的计算公式 hash(key) % 4 ,重新对数据和节点做映射。
假设总数据条数为 M,哈希算法在面对节点数量变化时,最坏情况下所有数据都需要迁移,所以它的数据迁移规模是 O(M),这样数据的迁移成本太高了。
所以,我们应该要重新想一个新的算法,来避免分布式系统在扩容或者缩容时,发生过多的数据迁移。
使用一致性哈希算法有什么问题?
一致性哈希算法就很好地解决了分布式系统在扩容或者缩容时,发生过多的数据迁移的问题。
一致哈希算法也用了取模运算,但与哈希算法不同的是,哈希算法是对节点的数量进行取模运算,而一致哈希算法是对 2^32 进行取模运算,是一个固定的值。
我们可以把一致哈希算法是对 2^32 进行取模运算的结果值组织成一个圆环,就像钟表一样,钟表的圆可以理解成由 60 个点组成的圆,而此处我们把这个圆想象成由 2^32 个点组成的圆,这个圆环被称为哈希环,如下图:

一致性哈希要进行两步哈希:
- 第一步:对存储节点进行哈希计算,也就是对存储节点做哈希映射,比如根据节点的 IP 地址进行哈希;
- 第二步:当对数据进行存储或访问时,对数据进行哈希映射;
所以,一致性哈希是指将「存储节点」和「数据」都映射到一个首尾相连的哈希环上。
问题来了,对「数据」进行哈希映射得到一个结果要怎么找到存储该数据的节点呢?
答案是,映射的结果值往顺时针的方向的找到第一个节点,就是存储该数据的节点。
举个例子,有 3 个节点经过哈希计算,映射到了如下图的位置:
接着,对要查询的 key-01 进行哈希计算,确定此 key-01 映射在哈希环的位置,然后从这个位置往顺时针的方向找到第一个节点,就是存储该 key-01 数据的节点。
比如,下图中的 key-01 映射的位置,往顺时针的方向找到第一个节点就是节点 A。
所以,当需要对指定 key 的值进行读写的时候,要通过下面 2 步进行寻址:
- 首先,对 key 进行哈希计算,确定此 key 在环上的位置;
- 然后,从这个位置沿着顺时针方向走,遇到的第一节点就是存储 key 的节点。
知道了一致哈希寻址的方式,我们来看看,如果增加一个节点或者减少一个节点会发生大量的数据迁移吗?
假设节点数量从 3 增加到了 4,新的节点 D 经过哈希计算后映射到了下图中的位置:
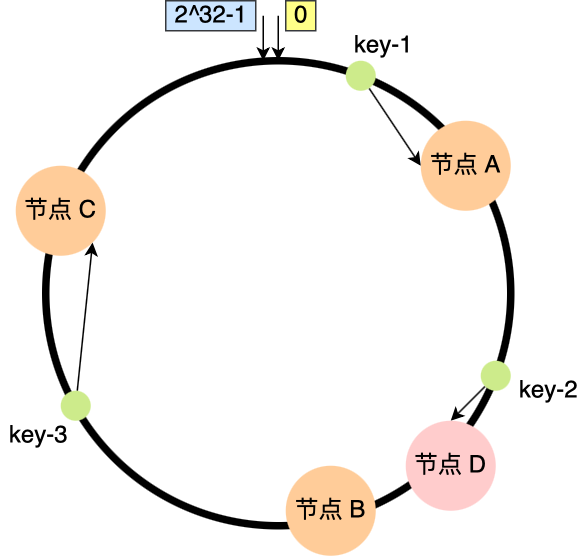
你可以看到,key-01、key-03 都不受影响,只有 key-02 需要被迁移节点 D。
假设节点数量从 3 减少到了 2,比如将节点 A 移除:
你可以看到,key-02 和 key-03 不会受到影响,只有 key-01 需要被迁移节点 B。
因此,在一致哈希算法中,如果增加或者移除一个节点,仅影响该节点在哈希环上顺时针相邻的后继节点,其它数据也不会受到影响。
上面这些图中 3 个节点映射在哈希环还是比较分散的,所以看起来请求都会「均衡」到每个节点。
但是一致性哈希算法并不保证节点能够在哈希环上分布均匀,这样就会带来一个问题,会有大量的请求集中在一个节点上。
比如,下图中 3 个节点的映射位置都在哈希环的右半边:
这时候有一半以上的数据的寻址都会找节点 A,也就是访问请求主要集中的节点 A 上,这肯定不行的呀,说好的负载均衡呢,这种情况一点都不均衡。
另外,在这种节点分布不均匀的情况下,进行容灾与扩容时,哈希环上的相邻节点容易受到过大影响,容易发生雪崩式的连锁反应。
比如,上图中如果节点 A 被移除了,当节点 A 宕机后,根据一致性哈希算法的规则,其上数据应该全部迁移到相邻的节点 B 上,这样,节点 B 的数据量、访问量都会迅速增加很多倍,一旦新增的压力超过了节点 B 的处理能力上限,就会导致节点 B 崩溃,进而形成雪崩式的连锁反应。
所以,一致性哈希算法虽然减少了数据迁移量,但是存在节点分布不均匀的问题。
如何通过虚拟节点提高均衡度?
要想解决节点能在哈希环上分配不均匀的问题,就是要有大量的节点,节点数越多,哈希环上的节点分布的就越均匀。
但问题是,实际中我们没有那么多节点。所以这个时候我们就加入虚拟节点,也就是对一个真实节点做多个副本。
具体做法是,不再将真实节点映射到哈希环上,而是将虚拟节点映射到哈希环上,并将虚拟节点映射到实际节点,所以这里有「两层」映射关系。
比如对每个节点分别设置 3 个虚拟节点:
- 对节点 A 加上编号来作为虚拟节点:A-01、A-02、A-03
- 对节点 B 加上编号来作为虚拟节点:B-01、B-02、B-03
- 对节点 C 加上编号来作为虚拟节点:C-01、C-02、C-03
引入虚拟节点后,原本哈希环上只有 3 个节点的情况,就会变成有 9 个虚拟节点映射到哈希环上,哈希环上的节点数量多了 3 倍。
你可以看到,节点数量多了后,节点在哈希环上的分布就相对均匀了。这时候,如果有访问请求寻址到「A-01」这个虚拟节点,接着再通过「A-01」虚拟节点找到真实节点 A,这样请求就能访问到真实节点 A 了。
上面为了方便你理解,每个真实节点仅包含 3 个虚拟节点,这样能起到的均衡效果其实很有限。而在实际的工程中,虚拟节点的数量会大很多,比如 Nginx 的一致性哈希算法,每个权重为 1 的真实节点就含有160 个虚拟节点。
另外,虚拟节点除了会提高节点的均衡度,还会提高系统的稳定性。当节点变化时,会有不同的节点共同分担系统的变化,因此稳定性更高。
比如,当某个节点被移除时,对应该节点的多个虚拟节点均会移除,而这些虚拟节点按顺时针方向的下一个虚拟节点,可能会对应不同的真实节点,即这些不同的真实节点共同分担了节点变化导致的压力。
而且,有了虚拟节点后,还可以为硬件配置更好的节点增加权重,比如对权重更高的节点增加更多的虚拟节点即可。
因此,带虚拟节点的一致性哈希方法不仅适合硬件配置不同的节点的场景,而且适合节点规模会发生变化的场景。
总结
不同的负载均衡算法适用的业务场景也不同的。
轮询这类的策略只能适用与每个节点的数据都是相同的场景,访问任意节点都能请求到数据。但是不适用分布式系统,因为分布式系统意味着数据水平切分到了不同的节点上,访问数据的时候,一定要寻址存储该数据的节点。
哈希算法虽然能建立数据和节点的映射关系,但是每次在节点数量发生变化的时候,最坏情况下所有数据都需要迁移,这样太麻烦了,所以不适用节点数量变化的场景。
为了减少迁移的数据量,就出现了一致性哈希算法。
一致性哈希是指将「存储节点」和「数据」都映射到一个首尾相连的哈希环上,如果增加或者移除一个节点,仅影响该节点在哈希环上顺时针相邻的后继节点,其它数据也不会受到影响。
但是一致性哈希算法不能够均匀的分布节点,会出现大量请求都集中在一个节点的情况,在这种情况下进行容灾与扩容时,容易出现雪崩的连锁反应。
为了解决一致性哈希算法不能够均匀的分布节点的问题,就需要引入虚拟节点,对一个真实节点做多个副本。不再将真实节点映射到哈希环上,而是将虚拟节点映射到哈希环上,并将虚拟节点映射到实际节点,所以这里有「两层」映射关系。
引入虚拟节点后,可以会提高节点的均衡度,还会提高系统的稳定性。所以,带虚拟节点的一致性哈希方法不仅适合硬件配置不同的节点的场景,而且适合节点规模会发生变化的场景。
Linux命令
如何查看网络的性能指标?
Linux 网络协议栈是根据 TCP/IP 模型来实现的,TCP/IP 模型由应用层、传输层、网络层和网络接口层,共四层组成,每一层都有各自的职责。
应用程序要发送数据包时,通常是通过 socket 接口,于是就会发生系统调用,把应用层的数据拷贝到内核里的 socket 层,接着由网络协议栈从上到下逐层处理后,最后才会送到网卡发送出去。
而对于接收网络包时,同样也要经过网络协议逐层处理,不过处理的方向与发送数据时是相反的,也就是从下到上的逐层处理,最后才送到应用程序。
网络的速度往往跟用户体验是挂钩的,那我们又该用什么指标来衡量 Linux 的网络性能呢?以及如何分析网络问题呢?
这次,我们就来说这些。
性能指标有哪些?
通常是以 4 个指标来衡量网络的性能,分别是带宽、延时、吞吐率、PPS(Packet Per Second),它们表示的意义如下:
- 带宽,表示链路的最大传输速率,单位是 b/s (比特 / 秒),带宽越大,其传输能力就越强。
- 延时,表示请求数据包发送后,收到对端响应,所需要的时间延迟。不同的场景有着不同的含义,比如可以表示建立 TCP 连接所需的时间延迟,或一个数据包往返所需的时间延迟。
- 吞吐率,表示单位时间内成功传输的数据量,单位是 b/s(比特 / 秒)或者 B/s(字节 / 秒),吞吐受带宽限制,带宽越大,吞吐率的上限才可能越高。
- PPS,全称是 Packet Per Second(包 / 秒),表示以网络包为单位的传输速率,一般用来评估系统对于网络的转发能力。
当然,除了以上这四种基本的指标,还有一些其他常用的性能指标,比如:
- 网络的可用性,表示网络能否正常通信;
- 并发连接数,表示 TCP 连接数量;
- 丢包率,表示所丢失数据包数量占所发送数据组的比率;
- 重传率,表示重传网络包的比例;
你可能会问了,如何观测这些性能指标呢?不急,继续往下看。
网络配置如何看?
要想知道网络的配置和状态,我们可以使用 ifconfig 或者 ip 命令来查看。
这两个命令功能都差不多,不过它们属于不同的软件包,ifconfig 属于 net-tools 软件包,ip 属于 iproute2 软件包,我的印象中 net-tools 软件包没有人继续维护了,而 iproute2 软件包是有开发者依然在维护,所以更推荐你使用 ip 工具。
学以致用,那就来使用这两个命令,来查看网口 eth0 的配置等信息:
虽然这两个命令输出的格式不尽相同,但是输出的内容基本相同,比如都包含了 IP 地址、子网掩码、MAC 地址、网关地址、MTU 大小、网口的状态以及网络包收发的统计信息,下面就来说说这些信息,它们都与网络性能有一定的关系。
第一,网口的连接状态标志。其实也就是表示对应的网口是否连接到交换机或路由器等设备,如果 ifconfig 输出中看到有 RUNNING,或者 ip 输出中有 LOWER_UP,则说明物理网络是连通的,如果看不到,则表示网口没有接网线。
第二,MTU 大小。默认值是 1500 字节,其作用主要是限制网络包的大小,如果 IP 层有一个数据报要传,而且网络包的长度比链路层的 MTU 还大,那么 IP 层就需要进行分片,即把数据报分成若干片,这样每一片就都小于 MTU。事实上,每个网络的链路层 MTU 可能会不一样,所以你可能需要调大或者调小 MTU 的数值。
第三,网口的 IP 地址、子网掩码、MAC 地址、网关地址。这些信息必须要配置正确,网络功能才能正常工作。
第四,网络包收发的统计信息。通常有网络收发的字节数、包数、错误数以及丢包情况的信息,如果 TX(发送) 和 RX(接收) 部分中 errors、dropped、overruns、carrier 以及 collisions 等指标不为 0 时,则说明网络发送或者接收出问题了,这些出错统计信息的指标意义如下:
- errors 表示发生错误的数据包数,比如校验错误、帧同步错误等;
- dropped 表示丢弃的数据包数,即数据包已经收到了 Ring Buffer(这个缓冲区是在内核内存中,更具体一点是在网卡驱动程序里),但因为系统内存不足等原因而发生的丢包;
- overruns 表示超限数据包数,即网络接收/发送速度过快,导致 Ring Buffer 中的数据包来不及处理,而导致的丢包,因为过多的数据包挤压在 Ring Buffer,这样 Ring Buffer 很容易就溢出了;
- carrier 表示发生 carrirer 错误的数据包数,比如双工模式不匹配、物理电缆出现问题等;
- collisions 表示冲突、碰撞数据包数;
ifconfig 和 ip 命令只显示的是网口的配置以及收发数据包的统计信息,而看不到协议栈里的信息,那接下来就来看看如何查看协议栈里的信息。
socket 信息如何查看?
我们可以使用 netstat 或者 ss,这两个命令查看 socket、网络协议栈、网口以及路由表的信息。
虽然 netstat 与 ss 命令查看的信息都差不多,但是如果在生产环境中要查看这类信息的时候,尽量不要使用 netstat 命令,因为它的性能不好,在系统比较繁忙的情况下,如果频繁使用 netstat 命令则会对性能的开销雪上加霜,所以更推荐你使用性能更好的 ss 命令。
从下面这张图,你可以看到这两个命令的输出内容:
可以发现,输出的内容都差不多, 比如都包含了 socket 的状态(State)、接收队列(Recv-Q)、发送队列(Send-Q)、本地地址(Local Address)、远端地址(Foreign Address)、进程 PID 和进程名称(PID/Program name)等。
接收队列(Recv-Q)和发送队列(Send-Q)比较特殊,在不同的 socket 状态。它们表示的含义是不同的。
当 socket 状态处于 Established时:
- Recv-Q 表示 socket 缓冲区中还没有被应用程序读取的字节数;
- Send-Q 表示 socket 缓冲区中还没有被远端主机确认的字节数;
而当 socket 状态处于 Listen 时:
- Recv-Q 表示全连接队列的长度;
- Send-Q 表示全连接队列的最大长度;
在 TCP 三次握手过程中,当服务器收到客户端的 SYN 包后,内核会把该连接存储到半连接队列,然后再向客户端发送 SYN+ACK 包,接着客户端会返回 ACK,服务端收到第三次握手的 ACK 后,内核会把连接从半连接队列移除,然后创建新的完全的连接,并将其增加到全连接队列 ,等待进程调用 accept() 函数时把连接取出来。
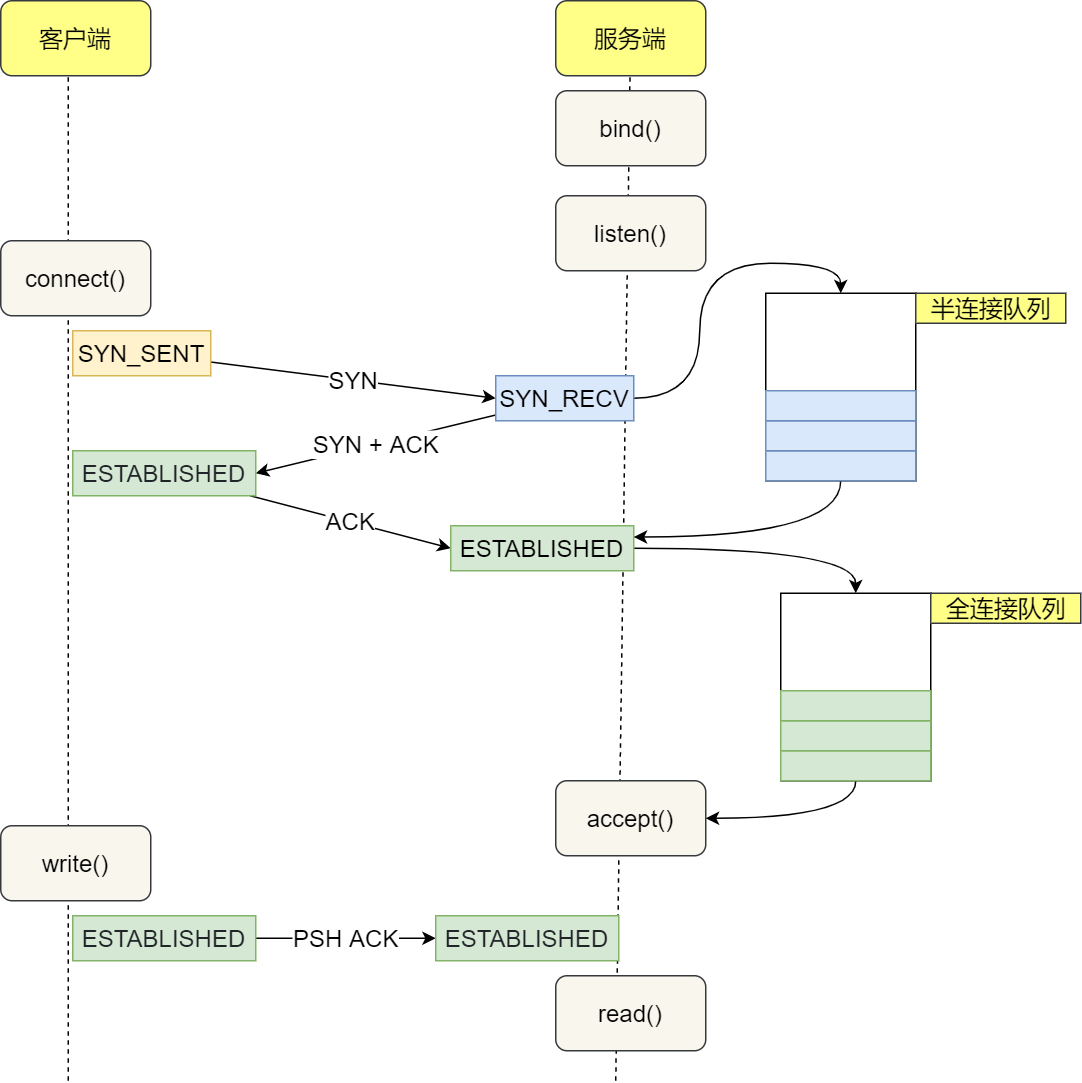
也就说,全连接队列指的是服务器与客户端完了 TCP 三次握手后,还没有被 accept() 系统调用取走连接的队列。
那对于协议栈的统计信息,依然还是使用 netstat 或 ss,它们查看统计信息的命令如下:

ss 命令输出的统计信息相比 netsat 比较少,ss 只显示已经连接(estab)、关闭(closed)、孤儿(orphaned) socket 等简要统计。
而 netstat 则有更详细的网络协议栈信息,比如上面显示了 TCP 协议的主动连接(active connections openings)、被动连接(passive connection openings)、失败重试(failed connection attempts)、发送(segments send out)和接收(segments received)的分段数量等各种信息。
网络吞吐率和 PPS 如何查看?
可以使用 sar 命令当前网络的吞吐率和 PPS,用法是给 sar 增加 -n 参数就可以查看网络的统计信息,比如
- sar -n DEV,显示网口的统计数据;
- sar -n EDEV,显示关于网络错误的统计数据;
- sar -n TCP,显示 TCP 的统计数据
比如,我通过 sar 命令获取了网口的统计信息:
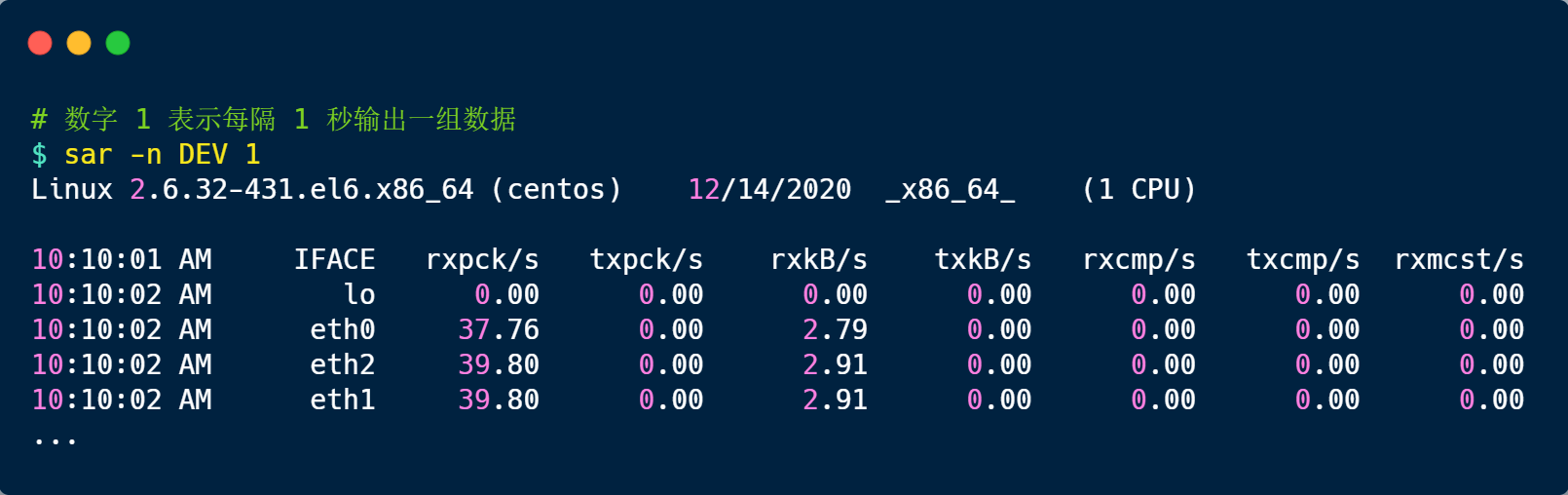
它们的含义:
rxpck/s和txpck/s分别是接收和发送的 PPS,单位为包 / 秒。rxkB/s和txkB/s分别是接收和发送的吞吐率,单位是 KB/ 秒。rxcmp/s和txcmp/s分别是接收和发送的压缩数据包数,单位是包 / 秒。
对于带宽,我们可以使用 ethtool 命令来查询,它的单位通常是 Gb/s 或者 Mb/s,不过注意这里小写字母 b ,表示比特而不是字节。我们通常提到的千兆网卡、万兆网卡等,单位也都是比特(bit)。如下你可以看到, eth0 网卡就是一个千兆网卡:
|
|
连通性和延时如何查看?
要测试本机与远程主机的连通性和延时,通常是使用 ping 命令,它是基于 ICMP 协议的,工作在网络层。
比如,如果要测试本机到 192.168.12.20 IP 地址的连通性和延时:
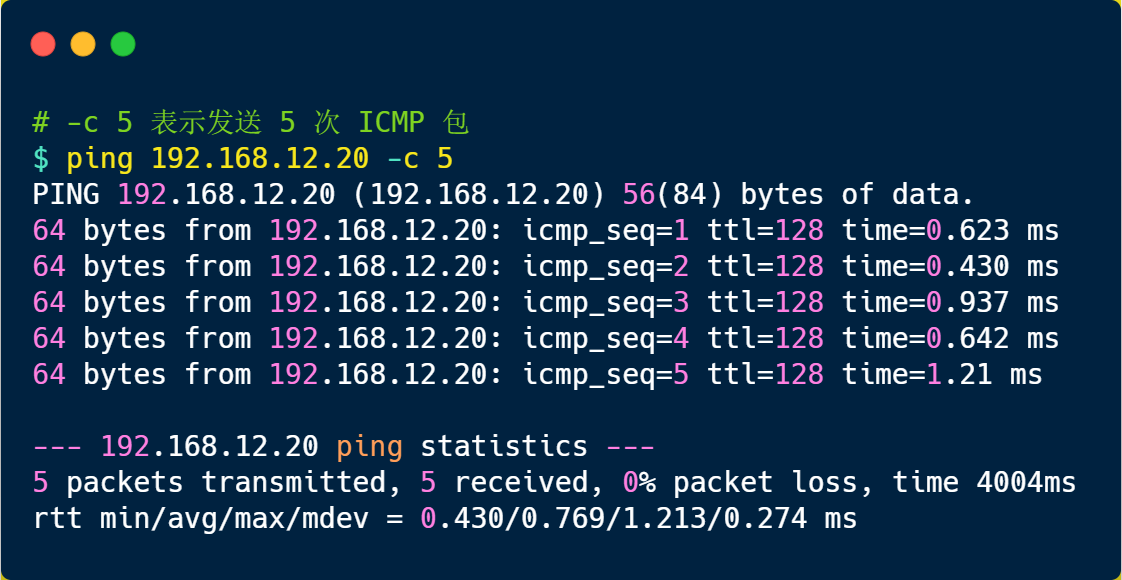
显示的内容主要包含 icmp_seq(ICMP 序列号)、TTL(生存时间,或者跳数)以及 time (往返延时),而且最后会汇总本次测试的情况,如果网络没有丢包,packet loss 的百分比就是 0。
不过,需要注意的是,ping 不通服务器并不代表 HTTP 请求也不通,因为有的服务器的防火墙是会禁用 ICMP 协议的。
如何从日志分析PV、UV?
很多时候,我们观察程序是否如期运行,或者是否有错误,最直接的方式就是看运行日志,当然要想从日志快速查到我们想要的信息,前提是程序打印的日志要精炼、精准。
但日志涵盖的信息远不止于此,比如对于 nginx 的 access.log 日志,我们可以根据日志信息分析用户行为。
什么用户行为呢?比如分析出哪个页面访问次数(PV)最多,访问人数(UV)最多,以及哪天访问量最多,哪个请求访问最多等等。
这次,将用一个大概几万条记录的 nginx 日志文件作为案例,一起来看看如何分析出「用户信息」。
别急着开始
当我们要分析日志的时候,先用 ls -lh 命令查看日志文件的大小,如果日志文件大小非常大,最好不要在线上环境做。
比如我下面这个日志就 6.5M,不算大,在线上环境分析问题不大。

如果日志文件数据量太大,你直接一个 cat 命令一执行,是会影响线上环境,加重服务器的负载,严重的话,可能导致服务器无响应。
当发现日志很大的时候,我们可以使用 scp 命令将文件传输到闲置的服务器再分析,scp 命令使用方式如下图:
慎用 cat
大家都知道 cat 命令是用来查看文件内容的,但是日志文件数据量有多少,它就读多少,很显然不适用大文件。
对于大文件,我们应该养成好习惯,用 less 命令去读文件里的内容,因为 less 并不会加载整个文件,而是按需加载,先是输出一小页的内容,当你要往下看的时候,才会继续加载。
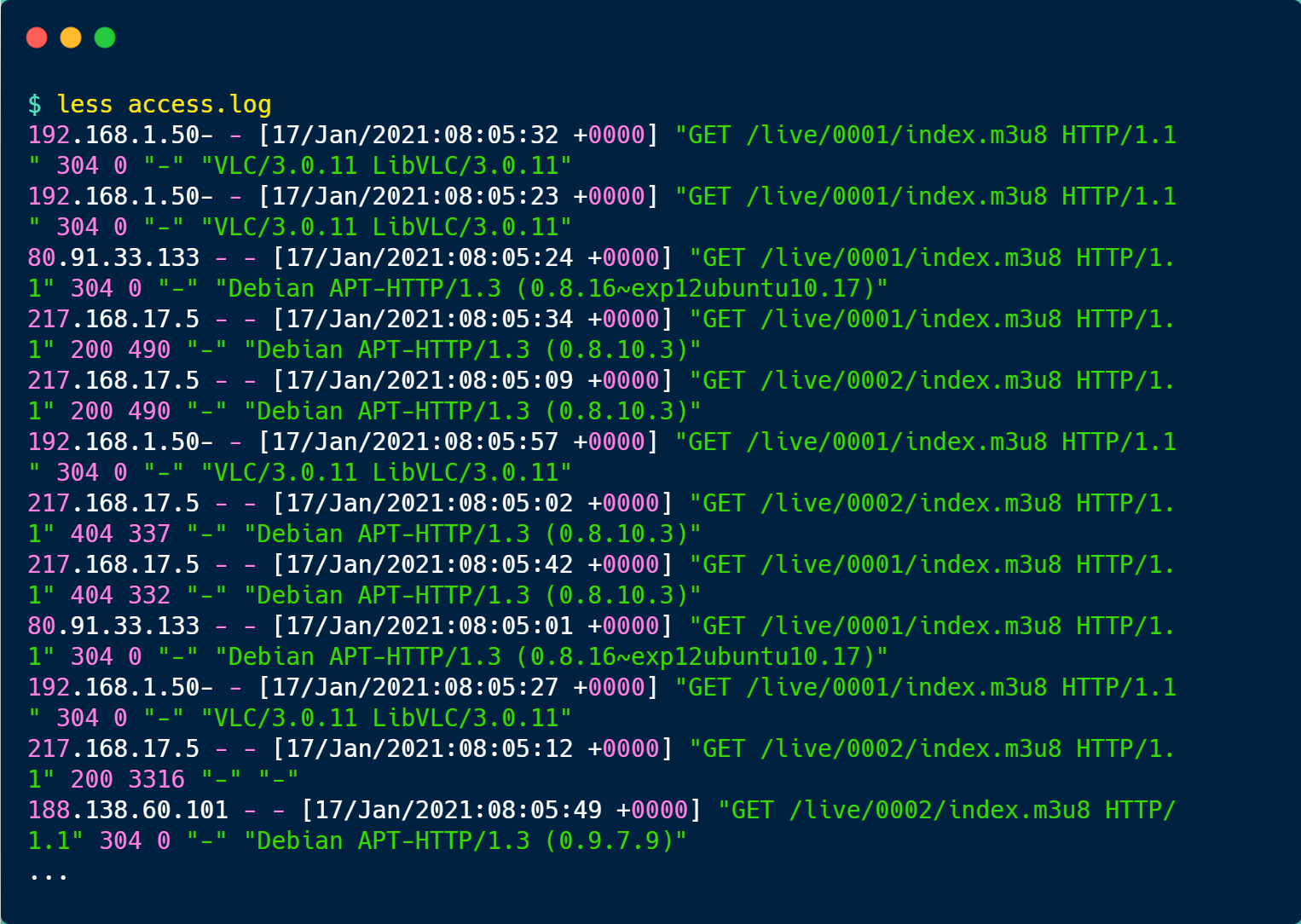
可以发现,nginx 的 access.log 日志每一行是一次用户访问的记录,从左到右分别包含如下信息:
- 客户端的 IP 地址;
- 访问时间;
- HTTP 请求的方法、路径、协议版本、协议版本、返回的状态码;
- User Agent,一般是客户端使用的操作系统以及版本、浏览器及版本等;
不过,有时候我们想看日志最新部分的内容,可以使用 tail 命令,比如当你想查看倒数 5 行的内容,你可以使用这样的命令:
如果你想实时看日志打印的内容,你可以使用 tail -f 命令,这样你看日志的时候,就会是阻塞状态,有新日志输出的时候,就会实时显示出来。
PV 分析
PV 的全称叫 Page View,用户访问一个页面就是一次 PV,比如大多数博客平台,点击一次页面,阅读量就加 1,所以说 PV 的数量并不代表真实的用户数量,只是个点击量。
对于 nginx 的 access.log 日志文件来说,分析 PV 还是比较容易的,既然日志里的内容是访问记录,那有多少条日志记录就有多少 PV。
我们直接使用 wc -l 命令,就可以查看整体的 PV 了,如下图一共有 49903 条 PV。

PV 分组
nginx 的 access.log 日志文件有访问时间的信息,因此我们可以根据访问时间进行分组,比如按天分组,查看每天的总 PV,这样可以得到更加直观的数据。
要按时间分组,首先我们先「访问时间」过滤出来,这里可以使用 awk 命令来处理,awk 是一个处理文本的利器。
awk 命令默认是以「空格」为分隔符,由于访问时间在日志里的第 4 列,因此可以使用 awk '{print $4}' access.log 命令把访问时间的信息过滤出来,结果如下:

上面的信息还包含了时分秒,如果只想显示年月日的信息,可以使用 awk 的 substr 函数,从第 2 个字符开始,截取 11 个字符。
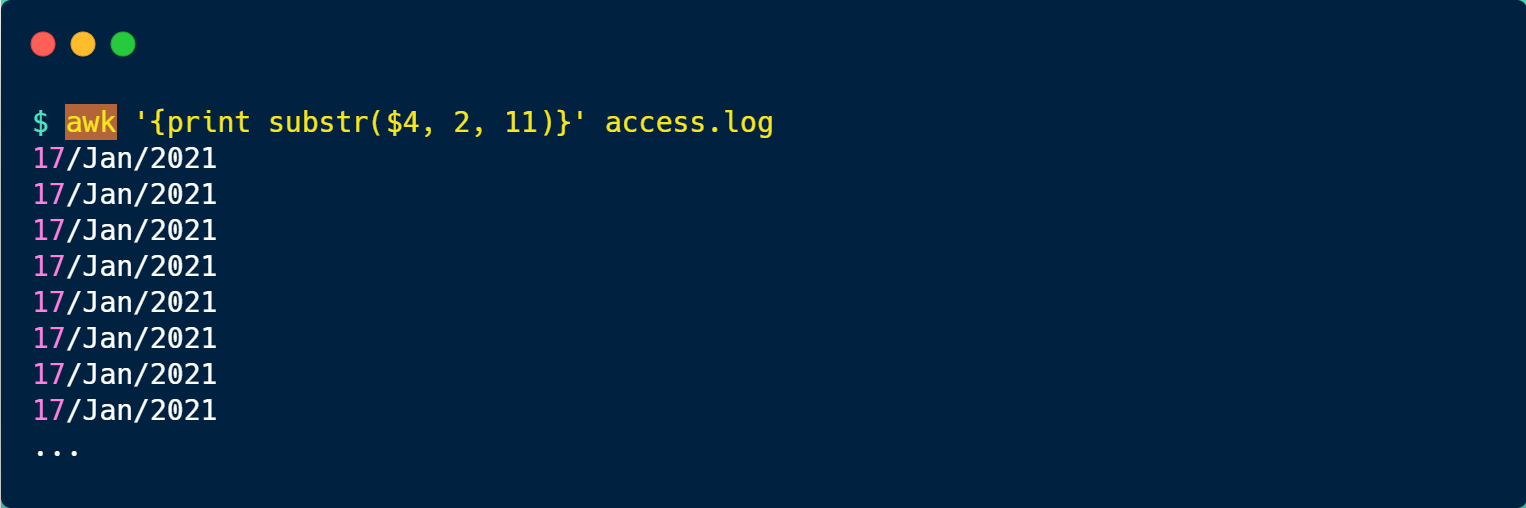
接着,我们可以使用 sort 对日期进行排序,然后使用 uniq -c 进行统计,于是按天分组的 PV 就出来了。
可以看到,每天的 PV 量大概在 2000-2800:
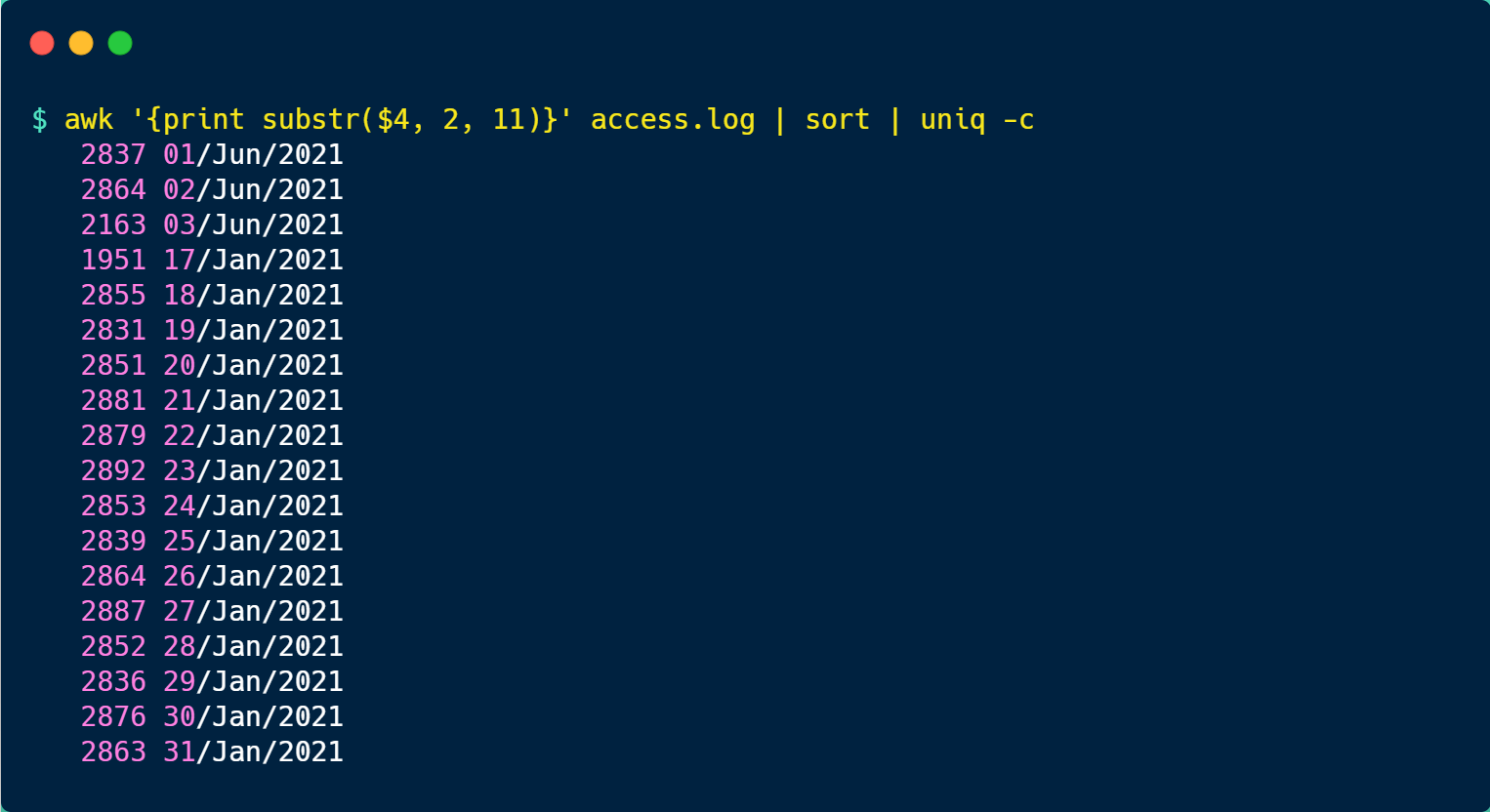
注意,使用 uniq -c 命令前,先要进行 sort 排序,因为 uniq 去重的原理是比较相邻的行,然后除去第二行和该行的后续副本,因此在使用 uniq 命令之前,请使用 sort 命令使所有重复行相邻。
UV 分析
UV 的全称是 Uniq Visitor,它代表访问人数,比如公众号的阅读量就是以 UV 统计的,不管单个用户点击了多少次,最终只算 1 次阅读量。
access.log 日志里虽然没有用户的身份信息,但是我们可以用「客户端 IP 地址」来近似统计 UV。

该命令的输出结果是 2589,也就说明 UV 的量为 2589。上图中,从左到右的命令意思如下:
awk '{print $1}' access.log,取日志的第 1 列内容,客户端的 IP 地址正是第 1 列;sort,对信息排序;uniq,去除重复的记录;wc -l,查看记录条数;
UV 分组
假设我们按天来分组分析每天的 UV 数量,这种情况就稍微比较复杂,需要比较多的命令来实现。
既然要按天统计 UV,那就得把「日期 + IP地址」过滤出来,并去重,命令如下:
具体分析如下:
- 第一次
awk是将第 4 列的日期和第 1 列的客户端 IP 地址过滤出来,并用空格拼接起来; - 然后
sort对第一次 awk 输出的内容进行排序; - 接着用
uniq去除重复的记录,也就说日期 +IP 相同的行就只保留一个;
上面只是把 UV 的数据列了出来,但是并没有统计出次数。
如果需要对当天的 UV 统计,在上面的命令再拼接 awk '{uv[$1]++;next}END{for (ip in uv) print ip, uv[ip]}' 命令就可以了,结果如下图:
awk 本身是「逐行」进行处理的,当执行完一行后,我们可以用 next 关键字来告诉 awk 跳转到下一行,把下一行作为输入。
对每一行输入,awk 会根据第 1 列的字符串(也就是日期)进行累加,这样相同日期的 ip 地址,就会累加起来,作为当天的 uv 数量。
之后的 END 关键字代表一个触发器,就是当前面的输入全部完成后,才会执行 END {} 中的语句,END 的语句是通过 foreach 遍历 uv 中所有的 key,打印出按天分组的 uv 数量。
终端分析
nginx 的 access.log 日志最末尾关于 User Agent 的信息,主要是客户端访问服务器使用的工具,可能是手机、浏览器等。
因此,我们可以利用这一信息来分析有哪些终端访问了服务器。
User Agent 的信息在日志里的第 12 列,因此我们先使用 awk 过滤出第 12 列的内容后,进行 sort 排序,再用 uniq -c 去重并统计,最后再使用 sort -rn(r 表示逆向排序, n 表示按数值排序) 对统计的结果排序,结果如下图:
分析 TOP3 的请求
access.log 日志中,第 7 列是客户端请求的路径,先使用 awk 过滤出第 7 列的内容后,进行 sort 排序,再用 uniq -c 去重并统计,然后再使用 sort -rn 对统计的结果排序,最后使用 head -n 3 分析 TOP3 的请求,结果如下图:
