编译命令
go run
go run命令直接编译和执行源码中的main函数,但是并不会留下任何可执行文件(可执行文件被放在临时文件中执行,执行结束后将被自动删除)。go run命令后可以添加参数。
来到HelloGo.go文件的目录下,执行如下命令:
go build
go build命令会将源码编译为可执行文件,默认将编译该目录下的所有的源码。也可以在命令后添加多个文件名,go build命令将编译这些源码,输出可执行文件。
同样来到HelloGo.go文件的目录下,执行如下命令,其中-o选项用于指定生成的可执行文件的文件名:
1
|
go build -o HelloGo HelloGo.go
|
或者
都将在当前目录下生成一个HelloGo的可执行文件。
基本语法
变量的声明与初始化
var是Go语言中声明变量的关键字。Go语言在声明变量时,会自动把变量对应的内存区域进行初始化操作,每个变量会被初始化为其类型的默认值。即变量一经声明,则被初始化为其类型的默认值。变量声明样式如下所示:
在Go语言中,每一个声明的变量都必须被使用,否则会编译不通过。即变量一经声明,则必须使用。
变量初始化样式:
类型推导
Go语言提供了类型推导的语法糖,可精简变量初始化为以下样式:
类型推导的语法糖省略了声明变量的关键字var和类型属性T
除了类型推导的语法糖特性,Go语言还提供了多重赋值和匿名变量的语法糖特性。
多重赋值
多重赋值特性可以轻松实现变量变换任务,不需要借助第三方变量。如下所示:
1
2
3
|
a := 1
b := 2
b, a =a, b
|
匿名变量
通过在不需要变量声明的地方使用_来代替变量名,我们就可以忽略部分不需要的左值。匿名变量不占用命名空间,不会分配内存。匿名变量与匿名变量之间也不会因为多次声明而无法使用。具体例子如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
package main
import "fmt"
// 返回一个人的姓和名
func getName() (string, string){
return "王", "小二" // Go语言支持函数多返回值
}
func main() {
surname,_ := getName() // 使用匿名变量
_, personalName := getName() // 使用匿名变量
fmt.Printf("My surname is %v and my personal name is %v", surname, personalName)
}
|
原生数据类型
基本数据类型:整型、浮点数、布尔型、字符串型等。
整型
整型中主要有两大类,分别是:
- 按照整型的长度划分:
int8、int16、int32、int64
- 按照有无符号划分:
uint8、uint16、uint32、uint64
除此之外,Go语言还提供了平台自匹配长度的**int类型和uint类型**。(常用)
整型类型之间可以相互转换,高长度类型向低长度类型转换时仅保留高长度类型的低位值。
浮点型
浮点型主要有两种:
float32:单精度,存储占用4个字节,也即4*8=32位,其中1位用来符号,8位用来指数,剩下的23位表示尾数float64:双精度,存储占用8个字节,也即8*8=64位,其中1位用来符号,11位用来指数,剩下的52位表示尾数(常用)
float32和float64之间可以进行类型转换,但需要注意精度损失。
布尔型
true和false。不能与整型进行强转,也无法参与数值运算。
字符串型
在Go语言中,字符串是基本类型,它基于UTF-8编码实现。在遍历字符串型时,我们需要区分byte和rune。
分别以byte和rune方式遍历字符串:
1
2
3
|
f := "Golang编程"
fmt.Printf("byte len of f is %v\n", len(f))
fmt.Printf("rune len of f is %v\n", utf8.RuneCountInString(f))
|
上述例子的输出为:
1
2
|
byte len of f is 12
rune len of f is 8
|
第一种方式,统计的是字节的长度。由于中文字符在UTF-8中占用了3个字节,所以使用len方法获得的中文字符长度为6个字节。
第二种方式,统计的是字符的长度。
在本质上,byte和rune的底层类型分别为uint8和int32。由于int32能够表达更多的值,可以更容易处理Unicode字符,所以rune能够处理一切的字符,而byte仅仅局限与处理ASCII字符。
Golang限定字符或者字符串一共有三种引号:
- 单引号,表示
byte类型或rune类型,对应uint8和int32类型,默认是rune类型。byte用来强调数据是raw data,而不是数字;而rune用来表示Unicode的code point。
- 双引号,才是字符串,实际上是字符数组。可以用索引号访问某字节,也可以用
len()函数来获取字符串所占的字节长度。
- 反引号,表示字符串字面量,但不支持任何转义序列。字面量 raw literal string 的意思是,你定义时写的啥样,它就啥样,你有换行,它就换行。你写转义字符,它也就展示转义字符
指针
在C/C++语言中,指针直接操作内存的特性使得C/C++具备极高的性能,开发人员通过它直接操作和管理大块内存数据。但与此同时,指针偏移、运算和内存释放可能引发的错误也让指针编程饱受诟病。
Go语言限制了指针类型的偏移和运算能力,使得指针类型具备了指针高效访问的特性,但又不会发生指针偏移,避免了非法修改敏感数据的问题。同时Go语言中提供的自动垃圾回收机制,也减少了指针占用内存回收的复杂性。
在Go语言中,指针包含以下三个概念:
在程序运行过程中,每一个变量的值都保存在内存中,变量对应的内存有其特定的地址。假设某一个变量的类型为T,在Go语言中,我们可以通过取址符号&获取该变量对应内存的地址,生成该变量对应的指针。此时**,指针的值即变量的内存地址**,指针类型即*T,称为T的指针类型,*代表指针。
Go语言也提供根据指针获取变量值的取指操作*,通过取值操作*可以获取指针对应变量的值和对变量进行赋值操作。具体代码如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
func main() {
str := "Golang is Good!"
// 获取 str 的指针
strPrt := &str
fmt.Printf("str type is %T, value is %v, address is %p\n", str, str, &str)
fmt.Printf("strPtr type is %T, and value is %v\n", strPrt, strPrt)
// 获取指针对应变量的值
newStr := *strPrt
fmt.Printf("newStr type is %T, value is %v, and address is %p\n", newStr, newStr, &newStr)
// 通过指针对变量进行赋值
*strPrt = "Java is Good too!"
fmt.Printf("newStr type is %T, value is %v, and address is %p\n", newStr, newStr, &newStr)
fmt.Printf("str type is %T, value is %v, address is %p\n", str, str, &str)
}
|
输出的结果为:
1
2
3
4
5
|
str type is string, value is Golang is Good!, address is 0xc00004a250
strPtr type is *string, and value is 0xc00004a250
newStr type is string, value is Golang is Good!, and address is 0xc00004a280
newStr type is string, value is Golang is Good!, and address is 0xc00004a280
str type is string, value is Java is Good too!, address is 0xc00004a250
|
在上述代码中,我们通过strPtr指针获取str的值赋予给newStr变量。
可以观察到str和newStr是两个不同的变量,它们对应的内存不一样,赋值过程中发生了值拷贝。
值拷贝会创建新的内存空间,然后将原有变量的值复制到新的内存空间中,形成两个独立的变量。通过指针修改str变量的值并不会影响到newStr,因为这两个变量对应的内存地址不一样。
除了使用&对变量进行取址操作创建指针,还可以使用new函数直接分配内存,并返回指向内存的指针,此时内存中的值会被初始化为类型的默认值。如下例所示:
1
2
3
4
|
// 通过new函数创建一个*string指针
str := new(string)
// 通过指针对变量进行赋值
*str = "Golang is Good!"
|
在Go语言的flag包中,命令行参数一般以指针返回。
常量
变量的值在运行时可变,而常量的值在声明之后不允许变化。通过const关键字可以声明常量。如下例所示:
类型推导
Go语言的类型推导省略常量声明时的类型T和同时声明多个常量。如下例所示:
1
2
3
4
5
6
7
|
// 省略类型T
const name = 表达式
// 同时声明多个常量
const (
name1 = 表达式1
name2 = 表达式2
)
|
类型别名
Go语言提供了类型别名的语法特性。类型别名本质上与原类型是属于同一个类型的,它相当于原类型T的一个别称。定义一个类型别名的样式如下:
类型定义
类型定义会创建一个新的类型,新建的类型将具备原类型T的特性。类型定义的样式如下:
通过一个例子理解类型别名和类型定义之间的区别:
1
2
3
4
5
6
7
8
9
10
11
|
type aliasInt = int // 定义一个类型别名
type myInt int // 定义一个新的类型
func main() {
var alias aliasInt
fmt.Printf("alias value is %v, type is %T\n", alias, alias)
var myint myInt
fmt.Printf("myint value is %v, type is %T\n", myint, myint)
}
|
输出结果为:
1
2
|
alias value is 0, type is int
myint value is 0, type is main.myInt
|
从输出结果中,我们可以看到通过类型别名aliasInt声明的alias变量还是int型,而重新定义的myInt属于新的类型,但是通过它声明的变量myint和alias一样都为0。
分支与循环控制
Go语言的分支控制与其他语言相似,但是更为简略,简单的表达样式如下:
1
2
3
4
5
6
7
|
if expression1 {
branch1
} else if expression2 {
branch2
} else {
branch3
}
|
Go语言中规定与if匹配的{必须与if和表达式位于同一行,同样的,else也必须与上一个分支的}位于同一行,否则会发生编译错误。表达式两边可以省略()。
Go语言还提供了switch语句对大量的值和表达式进行判断。
- 为了避免人为错误,
switch中的每一个case都是独立的代码块,不需要通过break跳出switch选择体。
- 如果需要继续执行接下来的
case判断,需要添加fallthrough关键字对上下两个case进行连接。
- 除了支持数值常量,Go语言的
switch还能对字符串 、表达式等复杂情况进行处理。
一个简单的例子如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
|
// 根据人名分配工作
name := "小红"
switch name {
case "小明":
fmt.Println("扫地")
case "小红":
fmt.Println("擦黑板")
case "小刚":
fmt.Println("倒垃圾")
default:
fmt.Println("没人干活")
}
|
在上面的例子中,每一个case都是字符串样式,且无需通过break控制跳出。
如果我们需要在case中判断表达式,在这种情况下switch后面不需要指定判断变量,这种形式就和if-else类似。如下例所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
// 根据分数判断成绩程度
score := 90
switch {
case score < 100 && score >= 90:
fmt.Println("优秀")
case score < 90 && score >= 80:
fmt.Println("良好")
case score < 80 && score >= 60:
fmt.Println("及格")
case score < 60:
fmt.Println("不及格")
default:
fmt.Println("分数错误")
}
|
Go语言的循环体仅提供了for关键字,没有其他语言中提供的while或者do-while形式。基本样式如下:
1
2
3
|
for init; condition; end {
//循环体代码
}
|
这其中,初始语句、条件表达式、结束语句都可以不写。如果三者都缺省,这将变成一个无限循环语句,可以通过break关键字跳出循环体,或者使用continue关键字继续下一个循环。
Go中常用的容器
- 当我们在程序中操作大量同类型变量时,为了方便数据的存储和操作,我们需要借助容器的力量。
- Go语言中以标准库的方式提供了常用的容器实现,主要有固定大小的数组、可以动态扩容的切片、双向列表以及**
key-value方式存储的字典**等。
数组
数组是一段存储固定类型固定长度的连续内存空间,它的大小在声明时就已经固定。数组的声明样式如下所示:
size必须在静态编译时就确定其大小,不能动态指定T表示数组成员的类型,可为任意类型
在Go语言,可以在声明时使用初始化列表对数组进行初始化,也可以通过下标对数据成员进行访问和赋值。如下所示:
1
2
3
4
5
6
7
8
9
10
11
|
var classMates1 [3]string
// 通过下标为数组成员赋值
classMates1[0] = "小明"
classMates1[1] = "小红"
classMates1[2] = "小李"
fmt.Println(classMates1)
// 通过下标访问数组成员
fmt.Println("The No.1 student is " + classMates1[0])
// 通过初始化列表声明并初始化数组
classMates2 := [...]string{"小明", "小红", "小李"}
fmt.Println(classMates2)
|
输出结果为:
1
2
3
|
[小明 小红 小李]
The No.1 student is 小明
[小明 小红 小李]
|
- 使用初始化列表初始化数组时,需要注意
[]内的数组大小需要和{}内的数组成员的数量一致。
- 上述例子中,我们使用了
...让编译器为我们根据{}内成员的数量确定数组的大小。
除此之外,我们还可以使用指针操作数组。如下例所示:
1
2
3
4
5
|
classMates3 := new([3]string)
classMates3[0] = "小明"
classMates3[1] = "小红"
classMates3[2] = "小李"
fmt.Println(*classMates3)
|
输出结果为:
- 在上述代码中,我们通过
new函数申请了[3]string的内存空间并初始化,返回其对应的指针。
- 需要注意的是,该指针无法支持偏移和运算,这是Go语言对指针类型的限制。
- 我们可以通过指针直接操作数组,这与C语言中的指针功能无异。
new和make的区别:
- make 只能用来分配及初始化类型为 slice、map、chan 的数据。new 可以分配任意类型的数据;
- new 分配返回的是指针,即类型 *Type。make 返回引用,即 Type;
- new 分配的空间被清零。make 分配空间后,会进行初始化;
数组指针和指针数组
数组指针:
1
2
3
4
5
6
7
8
|
func main() {
arr := [5]string{"1", "2", "3", "4", "5"}
var arrP *[5]string // 声明一个数组指针arrP
arrP = &arr
fmt.Println(arr, arrP)
}
//运行结果:
//[1 2 3 4 5] &[1 2 3 4 5]
|
指针数组:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
func main() {
str1 := "1"
str2 := "2"
str3 := "3"
str4 := "4"
str5 := "5"
// 声明并初始化一个指针数组arrPP,数组内存放的是指针(地址)
arrPP := [5]*string{&str1, &str2, &str3, &str4, &str5}
*arrPP[2] = "333"
fmt.Println(str3)
}
//运行结果:
//333
|
切片
- 切片是对数组的一个连续片段的引用,它是一个容量可变的序列。
- 我们可以简单将切片理解为动态数组,它的内部结构包括底层数组指针、大小和容量,它通过指针引用底层数组,把对数据的读写操作限定在指定的区域内。
切片的结构体由三部分组成:
array:指向底层存储数据数组的指针len:指当前切片的长度,即成员数量cap:指当前切片的容量,它总是大于等于len
从原生数组中生成切片
我们可以从原有数组中生成一个切片,生成的切片指针即指向原数组。生成的样式如下:
1
|
slice := source[begin:end]
|
source表示生成切片的原有数组begin表示切片的开始位置,end表示切片的结束位置,- 不包含
end索引指向的原有数组成员,即左闭右开。
具体例子如下所示:
1
2
3
4
5
6
7
8
9
10
|
sourceArray := [...]int{1,2,3}
slice := sourceArray[0:1]
fmt.Printf("slice value is %v\n", slice)
fmt.Printf("slice len is %v\n", len(slice))
fmt.Printf("slice cap is %v\n", cap(slice))
slice[0] = 4
fmt.Printf("slice value is %v\n", slice)
fmt.Printf("sourceArray value is %v\n", sourceArray)
|
输出的结果为:
1
2
3
4
5
|
slice value is [1]
slice len is 1
slice cap is 3
slice value is [4]
sourceArray value is [4 2 3]
|
- 因为切片作为指向原有数组的引用,对切片修改就是对原数组进行修改
动态创建切片
通过make函数动态创建切片,在创建过程中指定切片的长度和容量。样式如下所示:
T即切片中的成员类型size为当前切片具备的长度cap为当前切片预分配的长度,即切片的容量
例子如下所示:
1
2
3
4
|
slice = make([]int, 2, 4)
fmt.Printf("slice value is %v\n", slice)
fmt.Printf("slice len is %v\n", len(slice))
fmt.Printf("slice cap is %v\n", cap(slice))
|
输出的结果为:
1
2
3
|
slice value is [0 0]
slice len is 2
slice cap is 4
|
从上述输出可以看出make函数创建的新切片中的成员都被初始化为类型的初始值。
声明新的切片
直接声明新的切片类似于数组的初始化,但是不需要指定其大小,否则就变成了数组。样式如下所示:
此时声明的切片并没有分配内存,我们可以在声明切片的同时对其进行初始化,如下例所示:
1
2
3
4
|
ex := []int{1, 2, 3}
fmt.Printf("ex value is %v\n", ex)
fmt.Printf("ex len is %v\n", len(ex))
fmt.Printf("ex cap is %v\n", cap(ex))
|
输出的结果为:
1
2
3
|
ex value is [1 2 3]
ex len is 3
ex cap is 3
|
向切片添加元素
- Go语言中提供了
append内建函数用于动态向切片添加元素,它将返回新的切片。
- 如果当前切片的容量可以容纳更多的元素,即
len小于cap,添加操作将在切片指向的原有数组上进行,这将会覆盖掉原有数组的值。
- 如果当前切片的容量不足以容纳更多的元素,那么切片将会进行扩容。
- 扩容的具体过程为:申请一个新的连续内存空间,空间大小一般为原有容量的两倍,然后将原来数组中的数据复制到新的数组中,同时将切片中的指针指向新的数组,最后将新的元素添加到新的数组中。
通过下例演示切片的动态扩容:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
arr1 := [...]int{1,2,3,4}
arr2 := [...]int{1,2,3,4}
sli1 := arr1[0:2] // 长度为2,容量为4
sli2 := arr2[2:4] // 长度为2,容量为2
fmt.Printf("sli1 pointer is %p, len is %v, cap is %v, value is %v\n", &sli1, len(sli1), cap(sli1), sli1)
fmt.Printf("sli2 pointer is %p, len is %v, cap is %v, value is %v\n", &sli2, len(sli2), cap(sli2), sli2)
newSli1 := append(sli1, 5)
fmt.Printf("newSli1 pointer is %p, len is %v, cap is %v, value is %v\n", &newSli1, len(newSli1), cap(newSli1), newSli1)
fmt.Printf("source arr1 become %v\n", arr1)
newSli2 := append(sli2, 5)
fmt.Printf("newSli2 pointer is %p, len is %v, cap is %v, value is %v\n", &newSli2, len(newSli2), cap(newSli2), newSli2)
fmt.Printf("source arr2 become %v\n", arr2)
|
上例的输出结果为:
1
2
3
4
5
6
|
sli1 pointer is 0xc000004078, len is 2, cap is 4, value is [1 2]
sli2 pointer is 0xc000004090, len is 2, cap is 2, value is [3 4]
newSli1 pointer is 0xc0000040d8, len is 3, cap is 4, value is [1 2 5]
source arr1 become [1 2 5 4]
newSli2 pointer is 0xc000004108, len is 3, cap is 4, value is [3 4 5]
source arr2 become [1 2 3 4]
|
- 通过上面的例子,我们可以发现,容量足够的
sli1直接将append添加的新元素覆盖到原有数组arr1中。而容量不够的sli2进行了扩容操作,申请了新的底层数组,不在原数组的基础上进行操作。在实际使用的过程要记住这两种的区别。
如果原有数组可以添加新的元素,但切片自身的容量已经饱和,此时进行append操作,同样会进行扩容,申请新的内存空间。如下例所示:
1
2
3
4
5
6
7
8
|
arr3 := [...]int{1,2,3,4}
sli3 := arr3[0:2:2] // 长度为2,容量为2
fmt.Printf("sli3 pointer is %p, len is %v, cap is %v, value is %v\n", &sli3, len(sli3), cap(sli3), sli3)
newSli3 := append(sli3,5)
fmt.Printf("newSli3 pointer is %p, len is %v, cap is %v, value is %v\n", &newSli3, len(newSli3), cap(newSli3), newSli3)
fmt.Printf("source arr3 become %v\n", arr3)
|
对应的输出结果为:
1
2
3
|
sli3 pointer is 0xc000004138, len is 2, cap is 2, value is [1 2]
newSli3 pointer is 0xc000004168, len is 3, cap is 4, value is [1 2 5]
source arr3 become [1 2 3 4]
|
- 在上述代码中,我们指定了创建切片的第三个参数
cap。这里的cap不是切片容量,切片容量是cap-begin。
为了方便切片的数据快速复制到另一个切片中,Go语言提供了内建的copy函数。它的使用样式如下:
1
|
copy(destSli, srcSli []T)
|
它的返回结果为实际发生复制的元素个数。
作为函数参数传递
在Go语言中,切片(slice)是一个引用类型,但它包含三个部分:指向底层数组(array)的指针、长度(len)和容量(cap)。将切片作为参数传递给函数时,实际上传递的是指向这个切片的指针及其长度和容量信息的副本,但它们指向的是相同的底层数组。
这意味着,如果在函数内部修改切片的内容(例如,通过索引访问或修改切片内的元素),那么这些修改会影响到原始切片。但是,如果改变了切片本身的长度或其他元数据,那么这些改变不会影响到原始切片,因为改变的是切片元数据的副本。
1
2
3
4
|
func modifySlice(s []int) {
s[0] = 100 // 修改切片中的元素
s = append(s, 200) // 改变切片本身,原始切片不受影响
}
|
列表
Go语言中的列表即双向链表,它适合于存储需要经常进行元素插入和删除操作的元素集合。
列表的初始化样式如下所示:
1
2
3
4
|
// 方法一
var name list.List
// 方法二
name := list.New()
|
- 方法一直接声明初始化列表,方法二使用
container/list包中的New函数初始化列表,返回列表对应的指针。
- 可以注意到,列表没有限制其内保存成员的类型,即任意类型的成员都可以同时存在列表中。
演示列表的插入、删除和遍历操作:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
tmpList := list.New()
// 尾插
for i := 1; i <= 10; i++ {
tmpList.PushBack(i)
}
// 头插
first := tmpList.PushFront(0)
// 删除
tmpList.Remove(first)
// 遍历
for l := tmpList.Front(); l != nil; l = l.Next() {
fmt.Print(l.Value, " ")
}
|
字典
Go语言中的字典用于存储键值对,其中每一个键都会映射到一个值。其内部通过散列表的方式实现。定义的样式如下所示:
1
|
name := make(map[keyType]valueType)
|
通过一个简单的例子演示map使用方式:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
classMates1 := make(map[int]string)
// 添加映射关系
classMates1[0] = "小明"
classMates1[1] = "小红"
classMates1[2] = "小张"
fmt.Printf("id %v is %v\n", 1, classMates1[1])
// 在声明时初始化数据
classMates2 := map[int]string{
0 : "小明",
1 : "小红",
2 : "小张",
}
fmt.Printf("id %v is %v\n", 3, classMates2[3])
|
- 如上代码所示,我们可以使用
make函数为map分配内存空间后,再为map一一添加键值对映射关系。
- 也可以直接在声明时通过类
JSON格式添加键值对映射关系 。
- 在
map中可以通过键直接查询对应的值,如果不存在这样的键,将会返回值类型的默认值。
可以采用以下方式查询某个键是否存在于map中:
1
|
mate,ok := classMates2[1]
|
如果键存在于map中,布尔型ok将会是true。mate为对应的值。
容器遍历
下例通过for-range遍历数组、切片、字典
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
// 数组的遍历
nums := [...]int{1, 2, 3, 4, 5, 6, 7, 8}
for k, v := range nums {
// k为下标,v为对应的值
fmt.Println(k, v, " ")
}
fmt.Println()
// 切片的遍历
slis := []int{1, 2, 3, 4, 5, 6, 7, 8}
for k, v := range slis {
// k为下标,v为对应的值
fmt.Println(k, v, " ")
}
fmt.Println()
// 字典的遍历
tmpMap := map[int]string{
0: "小明",
1: "小红",
2: "小张",
}
for k, v := range tmpMap {
// k为键值,v为对应值
fmt.Println(k, v, " ")
}
|
- 可以将不需要的键或值改为匿名变量
- 列表的遍历比较特殊,需要配合
Front函数获取列表的头元素,再使用其Next函数依次往下遍历,具体代码可见上面列表部分的举例。
特别注意:在for-range遍历过程中,键和值是值拷贝,对它们修改不会影响容器内成员变化。
函数与接口
函数声明和参数传递
Go语言中函数声明包括函数名、参数列表和返回参数列表。具体样式如下所示:
1
2
3
|
func name(params)(return params) {
function body
}
|
- 函数以
func作为标识,函数名可以由字母、数字、下划线组成,但第一位不能是数字
- 在同一包内,函数名不可重名
- 一个函数如果希望被包外代码访问,函数名的首字母需要为大写
- 参数列表中的每个参数由参数变量名和参数类型组成,它们将作为函数的局部变量被使用
- 在参数列表中,多个参数之间通过逗号分隔
- 如果相邻的参数的类型相同,那么可以只在最后参数列表最后写上参数类型
Go语言中函数不仅支持多返回值,还支持对返回值进行命名,此时返回参数列表与参数列表类似,如下例所示:
1
2
3
4
5
|
func div(dividend, divisor int)(quotient, remainder int) {
quotient = dividend/divisor
remainder = dividend%divisor
return
}
|
- 在上面的正整数除法的函数中,我们对返回值分别命名为
quotient和remainder,于是可以直接在函数体内对它们进行赋值。
- 需要注意的是,在使用命名返回值的函数中,在函数结束前我们需要显式使用
return语句进行返回
- 命名返回值和非命名返回值不能混合使用,两种形式只能二选一,否则会出现编译错误
Go语言中函数参数的传递方式是值传递,但可以在参数中使用指针或者引用来减少复制时产生的性能损耗。
匿名函数
- 匿名函数是一种没有函数名,只有函数体的函数,即定义即使用
- 匿名函数只有在被调用的时候才会被初始化
- 匿名函数一般被当作一种类型赋值给函数类型的变量,经常被用作回调函数
Go语言的匿名函数的声明样式如下所示:
1
2
3
|
func(params)(return params){
function body
}
|
我们可以在匿名函数声明之后,在其后加上调用的参数列表,即可对匿名函数进行调用,如下例所示:
1
2
3
|
func (name string) {
fmt.Println("My name is ",name)
}("wyatt")
|
还可以将匿名函数赋值给函数类型的变量,用于多次调用或者求值,如下例所示:
1
2
3
4
5
|
currentTime := func() {
fmt.Println(time.Now())
}
// 调用匿名函数
currentTime()
|
匿名函数一个比较常用的场景是用作回调函数。如下例所示,定义一个函数proc():它接受string和匿名函数的参数输入,然后使用匿名函数对string进行处理。
1
2
3
4
5
6
7
8
9
10
11
12
13
|
func proc(input string, processor func(str string)) {
// 调用匿名函数
processor(input)
}
func main() {
proc("王小二", func(str string) {
for _, v := range str {
fmt.Printf("%c\n", v)
}
})
}
|
- 匿名函数作为参数传入函数
proc(),赋值给函数类型参数processor
- 在函数
proc()中作为回调函数用于对传入的字符串进行处理
- 可以根据自己的需要传递不同的匿名函数实现对字符串不同的处理操作
不定项参数
1
2
3
4
5
6
7
8
9
10
|
func main(){
mo(999,"1","2","3","4")
}
func mo(data1 int, data2 ...string){
fmt.Println(data1, data2)
}
//运行结果:
//999 [1 2 3 4]
//可以看到 第二个是切片类型 可以用for range遍历
|
将一个切片作为参数传入:
1
2
3
4
5
6
7
8
9
10
|
func main(){
ar := []string{"1", "2", "3"}
mo(999,ar...) //将一个切片作为参数传入
}
func mo(data1 int, data2 ...string){
fmt.Println(data1, data2)
}
//运行结果:
//999 [1 2 3 ]
|
自执行函数
- 不需要名字的函数,只需要执行一次即可
- 可以用作定时
1
2
3
4
5
6
7
|
func main() {
(func() {
fmt.Println("我是自执行函数")
})()
}
//运行结果:
//我是自执行函数
|
闭包函数
- 函数里面嵌套一个函数,最后返回里面的函数
- Go 语言支持匿名函数,可作为闭包。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
func main() {
//调用方式1
f1 := mo1() //f1是一个函数类型的变量
f1()
f2 := mo2()
f2(1)
//调用方式2
mo1()()
mo2()(1)
}
//闭包函数1不需要入参
func mo1() func() {
return func() {
fmt.Println("我是闭包函数")
}
}
//闭包函数2需要入参
func mo2() func(int) {
return func(num int) {
fmt.Println("我是闭包函数", num)
}
}
//运行结果:
//我是闭包函数
//我是闭包函数 1
//我是闭包函数
//我是闭包函数 1
|
全局变量的特点:常驻内存、污染全局
局部变量的特点:不常驻内存、不污染全局
闭包:常驻内存、不污染全局
- 闭包是指有权访问另一个函数作用域中的变量的函数
- 创建闭包的常见的方式就是在一个函数内部创建另一个函数,通过另一个函数访问这个函数的局部变量
注意:由于闭包里作用域返回的局部变量资源不会被立刻销毁回收,所以可能会占用更多的内存。过度使用闭包会导致性能下降,建议在非常有必要的时候才使用闭包
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
func adder1() func() int {
i := 10
return func() int {
return i + 1
}
}
func adder2() func(int) int {
i := 10
return func(y int) int {
i += y
return i
}
}
func main() {
fn := adder1()
fmt.Println(fn())
fmt.Println(fn())
fmt.Println(fn())
fn2 := adder2()
fmt.Println(fn2(10))
fmt.Println(fn2(10))
fmt.Println(fn2(10))
}
// 运行结果
11
11
11
20
30
40
|
延迟函数
Go语言中的defer语句会将其后面跟随的语句进行延迟处理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
func main() {
defer mo()
fmt.Println("1")
fmt.Println("2")
fmt.Println("3")
}
func mo() {
fmt.Println("我是延迟函数,我想最先执行,但却总是最后被执行")
}
//运行结果:
//1
//2
//3
//我是延迟函数,我想最先执行,但却总是最后被执行
|
在defer归属的函数即将返回时,将延迟处理的语句按defer定义的逆序进行执行,也就是说,先被defer的语句最后被执行,最后被defer的语句,最先被执行
1
2
3
4
5
6
7
8
9
10
11
12
13
|
func main() {
fmt.Println("开始")
defer fmt.Println("1")
defer fmt.Println("2")
defer fmt.Println("3")
fmt.Println("结束")
}
// 运行结果
开始
结束
3
2
1
|
defer执行时机
在Go语言的函数中return语句在底层并不是原子操作,它分为给返回值赋值和RET指令两步。而defer语句执行的时机就在返回值赋值操作后,RET指令执行前。具体如下图所示:
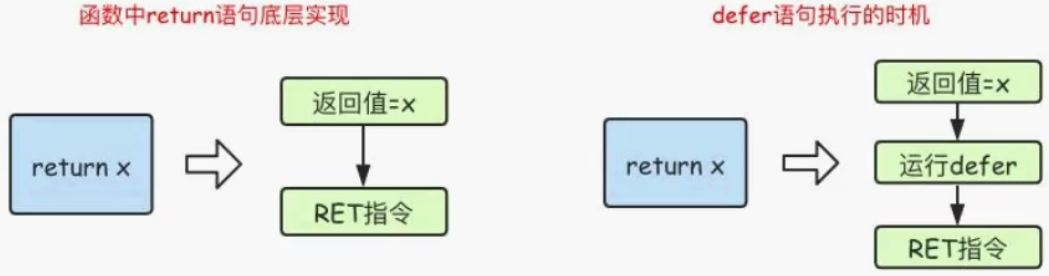
defer在命名返回值和匿名返回值函数中表现不一样
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
// 匿名返回值
func f1() int {
a := 0
defer func() {
a++
}()
return a
}
// 命名返回值
func f2() (a int) {
defer func() {
a++
}() // 注意:若defer后若使用匿名函数,必须是匿名自执行函数
return a
}
func main() {
fmt.Println(f1())
fmt.Println(f2())
}
// 运行结果
0
1
|
defer在注册要延迟执行的函数时,该函数所有的参数就需要确定其值
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
func calc(index string, a, b int) int {
ret := a + b
fmt.Println(index, a, b, ret)
return ret
}
func main() {
x := 1
y := 2
defer calc("AA", x, calc("A", x, y))
x = 10
defer calc("BB", x, calc("B", x, y))
y = 20
}
// 结果
A 1 2 3
B 10 2 12
BB 10 12 22
AA 1 3 4
// 分析
注册顺序:
defer calc("AA", x, calc("A", x, y)) calc("A", x, y):A 1 2 3
defer calc("BB", x, calc("B", x, y)) calc("B", x, y):B 10 2 12
执行顺序:
defer calc("BB", x, calc("B", x, y)) BB 10 12 22
defer calc("AA", x, calc("A", x, y)) AA 1 3 4
|
指针传参
1
2
3
4
5
6
7
8
9
10
11
|
func main() {
str1 := "我没变"
pointFunc(str1)
fmt.Println(str1)
}
func pointFunc(str1 string) {
str1 = "我变了"
}
//运行结果:
//我没变
|
1
2
3
4
5
6
7
8
9
10
11
|
func main() {
str1 := "我没变"
pointFunc(&str1)
fmt.Println(str1)
}
func pointFunc(str1 *string) {
*str1 = "我变了"
}
//运行结果:
//我变了
|
错误处理
Go 语言中目前可以使用 panic/recover 模式来处理错误
panic 可以在任何地方引发,但 recover 只在defer调用的函数中有效
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
func fn(a, b int) {
defer func() {
err := recover()
if err != nil {
fmt.Println("err:", err)
}
}()
fmt.Println(a / b)
}
func main() {
fn(10, 0)
fn(10, 2)
}
// 运行结果
err: runtime error: integer divide by zero
5
|
另一个用法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
func readFile(filename string) error {
if filename == "main.go" {
return nil
} else {
return errors.New("读取文件失败")
}
}
func myFn() {
defer func() {
if err := recover(); err != nil {
fmt.Println("出现err:", err)
}
}()
err := readFile("xxx.go")
if err != nil {
panic(err)
}
}
func main() {
myFn()
fmt.Println("继续执行...")
}
// 结果
出现err: 读取文件失败
继续执行...
|
结构体
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
func main() {
var person1 Person //声明方式1
person2 := Person{ //声明方式2
}
person3 := new(Person) //声明方式3
fmt.Println(person1)
fmt.Println(person2)
fmt.Println(person3) //返回地址
fmt.Println(*person3)
}
//运行结果:
//{ 0 false []}
//{ 0 false []}
//&{ 0 false []}
//{ 0 false []}
|
方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
func (p *Person) playGame1(gameName string) (reStr string) {
reStr = p.Name + "正在玩" + gameName
p.Name = "Mr.Wang"
return reStr
}
func main() {
person1 := Person{
Name: "wyatt",
Age: 21,
Sex: true,
Hobby: []string{"Code", "Game"},
}
retStr := person1.playGame("lol")
fmt.Println(retStr)
fmt.Println(person1)
}
//运行结果:
//wyatt正在玩lol
//{Mr.Wang 21 true [Code Game]}
|
- 普通传参,不会改变原来结构体的值,与上面的唯一区别是:去掉了方法声明中的
*
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
func (p Person) playGame1(gameName string) (reStr string) {
reStr = p.Name + "正在玩" + gameName
p.Name = "Mr.Wang"
return reStr
}
func main() {
person1 := Person{
Name: "wyatt",
Age: 21,
Sex: true,
Hobby: []string{"Code", "Game"},
}
retStr := person1.playGame("lol")
fmt.Println(retStr)
fmt.Println(person1)
}
//运行结果:
//wyatt正在玩lol
//{wyatt 21 true [Code Game]}
|
结构体嵌套:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
type Person struct {
Name string
Age int
Sex bool
Hobby []string
MyHome Home
}
type Home struct {
home string
}
func (h Home) open() {
fmt.Println("open", h.home)
}
func main() {
person1 := Person{
Name: "wyatt",
Age: 21,
Sex: true,
Hobby: []string{"Code", "Game"},
MyHome: Home{"Xi'An"},
}
person1.MyHome.open()
}
//运行结果:
//open Xi'An
|
结构体与JSON序列化
GolangJSON序列化是指把结构体数据转化成JSON格式的字符串,GolangJSON的反序列化是指把JSON数据转化成Golang中的结构体对象,Golang中的序列化和反序列化主要通过"encoding/json"包中的json.Marshal()和json.Unmarshal()方法实现
注意:由于golang中结构体的私有属性不能被外部包访问,所以定义与json(反)序列化的结构体属性首字母要大写
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
type Student struct {
ID int
Gender string
Name string
Sno string
}
func main() {
var s1 = Student{
ID: 1,
Gender: "男",
Name: "李四",
Sno: "s0001",
}
fmt.Printf("%#v\n", s1)
jsonByte, err := json.Marshal(s1)
if err != nil {
fmt.Println(err)
}
jsonStr := string(jsonByte)
fmt.Println(jsonStr)
}
// 输出
main.Student{ID:1, Gender:"男", Name:"李四", Sno:"s0001"}
{"ID":1,"Gender":"男","Name":"李四","Sno":"s0001"}
|
Json字符串转换成结构体对象
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
type Student struct {
ID int
Gender string
Name string
Sno string
}
func main() {
var jsonStr = `{"ID":1,"Gender":"男","Name":"李四","Sno":"s0001"}`
// 定义一个Student实例
var student Student
err := json.Unmarshal([]byte(jsonStr), &student)
if err != nil {
fmt.Printf("unmarshalerr=%v\n", err)
}
fmt.Printf("反序列化后student=%#v\nstudent.Name=%v\n", student, student.Name)
}
// 输出
反序列化后student=main.Student{ID:1, Gender:"男", Name:"李四", Sno:"s0001"}
student.Name=李四
|
结构体标签Tag
Tag 是结构体的元信息,可以在运行的时候通过反射的机制读取出来。Tag 在结构体字段的后方定义,由一对反引号包裹起来,具体的格式如下:
key1:"value1" key2:"value2"
结构体 tag 由一个或多个键值对组成。键与值使用冒号分隔,值用双引号括起来。同一个结构体字段可以设置多个键值对 tag,不同的键值对之间使用空格分隔
注意事项: 为结构体编写 Tag 时,必须严格遵守键值对的规则。结构体标签的解析代码的容错能力很差,一旦格式写错,编译和运行时都不会提示任何错误,通过反射也无法正确取值。例如不要在 key 和 value 之间添加空格
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
type Student struct {
ID int `json:"id"` //通过指定 tag 实现 json 序列化该字段时的 key
Gender string `json:"gender"`
Name string
Sno string
}
func main() {
var s1 = Student{
ID: 1,
Gender: "男",
Name: "李四",
Sno: "s0001",
}
fmt.Printf("%#v\n", s1)
jsonByte, _ := json.Marshal(s1)
jsonStr := string(jsonByte)
fmt.Println(jsonStr)
}
// 输出
main.Student{ID:1, Gender:"男", Name:"李四", Sno:"s0001"}
{"id":1,"gender":"男","Name":"李四","Sno":"s0001"}
|
接口
- 接口是一些方法的集合,需要结构体去实现这些方法,从而实现接口
- 一个结构体实现多个接口
- 接口与接口间可以通过嵌套创造出新的接口
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
type Animal interface {
Eat()
Run()
}
type Cat struct {
Name string
Sex bool
}
func (c Cat) Eat() {
fmt.Println(c.Name, "开始吃")
}
func (c Cat) Run() {
fmt.Println(c.Name, "开始跑")
}
func main() {
// go中接口就是一个数据类型
var a Animal
c := Cat{
Name: "Tom",
Sex: false,
}
// 表示c实现了接口Animal的两个方法
a = c
// 可以用接口调用到原始实例的方法
a.Eat()
a.Run()
//简写
//var a Animal
//a := Cat{
// Name: "Tom",
// Sex: false,
//}
//a.Eat()
//a.Run()
}
//运行结果:
//Tom 开始吃
//Tom 开始跑
|
泛型
- 可以用空接口实现泛型:可以作为入参类型声明,传入任意类型参数;可以作为map的值类型;可以作为切片值类型
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
func main() {
c := Cat{
Name: "Tom",
Sex: false,
}
MyFunc(1)
MyFunc([]string{"a", "b"})
MyFunc(c)
}
func MyFunc(a interface{}) {
fmt.Println(a)
}
//运行结果:
//1
//[a b]
//{Tom false}
|
类型断言
一个接口的值(简称接口值)是由一个具体类型和具体类型的值两部分组成的。这两部分分别称为接口的动态类型和动态值。 如果想要判断空接口中值的类型,就可以使用类型断言,其语法格式:
- x : 表示类型为
interface{}的变量
- T : 表示断言 x 可能的类型
该语法返回两个参数,第一个参数是 x 转化为 T 类型后的变量,第二个值是一个布尔值,若为 true 则表示断言成功,为 false 则表示断言失败
1
2
3
4
5
6
7
8
9
10
11
|
func main() {
var x interface{}
x = "Hello golang"
if v, ok := x.(string); ok {
fmt.Println(v)
} else {
fmt.Println("类型断言失败")
}
}
// 输出
Hello golang
|
上面的示例中如果要断言多次就需要写多个 if 判断,这个时候可以使用 switch 语句来实现:
注意:类型.(type)只能结合 switch 语句使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
func main() {
justifyType("1")
justifyType(1)
justifyType(true)
justifyType([]int{1, 2, 3})
}
func justifyType(x interface{}) {
switch v := x.(type) {
case string:
fmt.Printf("x is a string,value is %v\n", v)
case int:
fmt.Printf("x is a int is %v\n", v)
case bool:
fmt.Printf("x is a bool is %v\n", v)
default:
fmt.Println("unsupported type!")
}
}
// 输出
x is a string,value is 1
x is a int is 1
x is a bool is true
unsupported type!
|
因为空接口可以存储任意类型值的特点,所以空接口在 Go 语言中的使用十分广泛
断言:把一个接口类型指定为它原始的类型,并且可以调用原始类型的属性和方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
type User struct {
Name string
Age int
Sex bool
}
// SayName 是User的方法
func (u User) SayName() {
fmt.Println("My name is", u.Name)
}
func main() {
u := User{
Name: "wyatt",
Age: 21,
Sex: true,
}
MyFunc(u)
}
// MyFunc 用空接口作为入参类型
func MyFunc(v interface{}) {
// 明确v接口是User
v.(User).SayName()
}
|
- 进一步拓展:根据
interfaceName.(type)获取传入的接口类型采取不同的操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
type User struct {
Name string
Age int
Sex bool
}
type Student struct {
User
}
func main() {
u := User{
Name: "wyatt",
Age: 21,
Sex: true,
}
s := Student{User{}}
MyFunc(u)
MyFunc(s)
}
// MyFunc 用空接口作为入参类型
func MyFunc(v interface{}) {
switch v.(type) {
case User:
fmt.Println("I'm User")
case Student:
fmt.Println("I'm Student")
}
}
//运行结果
//I'm User
//I'm Student
|
关于接口需要注意的是:只有当有两个或两个以上的具体类型必须以相同的方式进行处理时才需要定义接口。不要为了写接口而写接口,那样只会增加不必要的抽象,导致不必要的运行时损耗。
解耦合
- 接口作为一个规范:必须要实现一个接口的全部方法,才能调用该接口的某个方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
var V Animal //声明一个全局变量
func main() {
c := Cat{
Name: "Tom",
Sex: false,
}
MyFunc(c) //函数内实例化接口
V.Run() //通过接口调用方法
}
func MyFunc(a Animal) {
V = a
}
//运行结果:
//Tom 开始跑
|
并发
goroutine:可以让程序中的某个函数可以单独拿出来,跑到一边去执行,跟主程序没有任何的阻碍关系channel:可以让跑到一边去执行的函数和主程序或另一个跑到一边去执行的函数进行通信的东西
goroutine
- 在调用一个函数的前面加上
go就是goroutine,它会让方法异步执行,相当于协程
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
func main() {
go Run()
// 让主程序睡1s再停止,防止结束太快,看不到协程打印信息
time.Sleep(1 * time.Second)
//另一种验证协程异步执行的方式
//for i := 0; i < 10; i++ {
// fmt.Println(i)
//}
}
func Run() {
fmt.Println("跑起来了协程")
}
//运行结果:
//跑起来了协程
|
协程管理器
主线程执行完毕后即使协程没有执行完毕,程序也会退出,例如下面代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
func test1() {
for i := 0; i < 10; i++ {
fmt.Println("test1() hello,world-", i)
time.Sleep(time.Second)
}
}
func test2() {
for i := 0; i < 10; i++ {
fmt.Println("test2() hello,world-", i)
time.Sleep(time.Second * 2)
}
}
func main() {
go test1() //开启了一个协程
go test2() //开启了一个协程
fmt.Println("主线程退出...")
}
// 输出
主线程退出...
|
sync.WaitGroup 可以实现主线程等待协程执行完毕
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
var wg sync.WaitGroup
func test1() {
for i := 0; i < 10; i++ {
fmt.Println("test1() hello,world-", i)
time.Sleep(time.Second)
}
wg.Done() // 协程计数器-1
}
func test2() {
for i := 0; i < 10; i++ {
fmt.Println("test2() hello,world-", i)
time.Sleep(time.Second * 2)
}
wg.Done() // 协程计数器-1
}
func main() {
wg.Add(1) // 协程计数器+1
go test1() //开启了一个协程
wg.Add(1) // 协程计数器+1
go test2() //开启了一个协程
wg.Wait() // 主线程等待协程执行完毕
fmt.Println("主线程退出...")
}
// 输出
test2() hello,world- 0
test1() hello,world- 0
...
test1() hello,world- 9
...
test2() hello,world- 9
主线程退出...
|
channel
channel是goroutine之间沟通的桥梁- Golang 的并发模型是 CSP(Communicating Sequential Processes),提倡通过通信共享内存而不是通过共享内存而实现通信。
- Go 语言中的管道(channel)是一种特殊的类型。管道像一个传送带或者队列,总是遵循**先入先出(First In First Out)**的规则,保证收发数据的顺序。每一个管道都是一个具体类型的导管,也就是声明 channel 的时候需要为其指定元素
创建 chan
管道需要使用 make 函数初始化之后才能使用
chan操作
管道有发送(send)、接收(receive)和关闭(close)三种操作。发送和接收都使用<-符号。
- 发送(将数据放在管道内)
1
|
ch <- 10 // 把 10 发送到 ch 中
|
- 接收(从管道内取值)
1
2
|
x := <- ch // 从 ch 中接收值并赋值给变量 x
<-ch // 从 ch 中接收值,忽略结果
|
- 关闭管道
只有在通知接收方 goroutine 所有的数据都发送完毕的时候才需要关闭管道。管道是可以被垃圾回收机制回收的,它和关闭文件是不一样的,在结束操作之后关闭文件是必须要做的,但关闭管道不是必须的
关闭后的管道有以下特点:
- 对一个关闭的管道再发送值就会导致 panic
- 对一个关闭的管道进行接收会一直获取值直到管道为空。
- 对一个关闭的并且没有值的管道执行接收操作会得到对应类型的零值
- 关闭一个已经关闭的管道会导致 panic
注意:遍历时,在写入完成后一定要先close掉chan再for range遍历,不然会报错;使用for循环遍历管道时可以不关闭
1
2
3
4
5
6
7
8
9
10
11
12
|
func main() {
c1 := make(chan int, 5)
c1 <- 1
c1 <- 2
c1 <- 3
c1 <- 4
c1 <- 5
close(c1)
for i := range c1 {
fmt.Println(i)
}
}
|
定义chan
- 定义chan分为五种:有缓冲、无缓冲、可读、可取、可读可取
- 有的时候会将管道作为参数在多个任务函数间传递,很多时候在不同的任务函数中使用管道都会对其进行限制,比如限制管道在函数中只能发送或只能接收
有缓冲、无缓冲、可读可取
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
func main() {
// 1.定义有缓冲的chan(可读可取)
c1 := make(chan int, 1)
c1 <- 1 //往缓冲区存个1
fmt.Println(<-c1) //从缓冲区取出1打印
// 2.定义无缓冲的chan(可读可取)
c2 := make(chan int)
go func() { //协程+匿名自执行函数
c2 <- 1 //存
}()
fmt.Println(<-c2) //取
}
//运行结果:
//1
//1
|
- 有无缓冲区别:通过打断点,DEBUG查看执行过程发现,有缓冲时主程序执行时发现要取,会去执行协程,一次存够,然后回主程序去取;无缓冲时主程序执行时发现要取,会去执行协程,存一次,然后回主程序取一次,再去执行协程,存一次,然后再回主程序取一次
1
2
3
4
5
6
7
8
9
10
11
12
|
func main() {
c1 := make(chan int, 10)
go func() { //协程+自执行函数
for i := 0; i < 10; i++ {
c1 <- i //存
}
}()
for i := 0; i < 10; i++ {
fmt.Println(<-c1) //取
}
}
|
- 进一步探究,将缓冲区缩小,可以发现:主程序执行时发现要取,会去执行协程,一次存满缓冲区,然后回主程序去取一个,此时缓冲区会空出一个,此时又会去执行协程,存一个,然后回主程序去取一个……
可读、可取
1
2
3
4
5
6
7
8
9
|
func main() {
c1 := make(chan int, 5)
// 1.只能读的chan
var readc <-chan int = c1
// 2.只能写的chan
var writec chan<- int = c1
writec <- 1
fmt.Println(<-readc)
}
|
协程与主程序通信
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
func main() {
c1 := make(chan int, 5)
var readc <-chan int = c1
var writec chan<- int = c1
go SetChan(writec)
GetChan(readc)
}
func SetChan(writec chan<- int) {
for i := 0; i < 10; i++ {
writec <- i
}
}
func GetChan(readc <-chan int) {
for i := 0; i < 10; i++ {
fmt.Printf("在主程序中获取协程中的数据:%d\n", <-readc)
}
}
//运行结果:
//在主程序中获取协程中的数据:0
//在主程序中获取协程中的数据:1
//......
|
select多路复用
在某些场景下需要同时从多个通道接收数据。这个时候就可以用到 golang 中提供的 select 多路复用。
通常情况通道在接收数据时,如果没有数据可以接收将会发生阻塞。
Go 内置了 select 关键字,可以同时响应多个管道的操作。
select 的使用类似于 switch 语句,它有一系列 case 分支和一个默认的分支。每个 case 会对应一个管道的通信(接收或发送)过程。select 会一直等待,直到某个 case 的通信操作完成时,就会执行 case 分支对应的语句。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
func main() {
//1.定义一个int管道,容量为 10
intChan := make(chan int, 10)
for i := 0; i < 10; i++ {
intChan <- i
}
//2.定义一个string管道,容量为 5
stringChan := make(chan string, 5)
for i := 0; i < 5; i++ {
stringChan <- "hello" + fmt.Sprintf("%d", i)
}
for {
select {
case v := <-intChan:
fmt.Printf("从 intChan 读取的数据%d\n", v)
case v := <-stringChan:
fmt.Printf("从 stringChan 读取的数据%s\n", v)
default:
fmt.Printf("数据获取完毕\n")
return // 跳出循环,注意退出
}
}
}
// 输出
从 stringChan 读取的数据hello0
...
从 intChan 读取的数据9
数据获取完毕
|
互斥锁
互斥锁是传统并发编程中对共享资源进行访问控制的主要手段,它由标准库sync中的Mutex结构体类型表示。sync.Mutex类型只有两个公开的指针方法,Lock和Unlock。Lock锁定当前的共享资源,Unlock进行解锁
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
var count = 0
var wg sync.WaitGroup
var mutex sync.Mutex
func test() {
mutex.Lock() // 加锁
count++
fmt.Println("the count is:", count)
time.Sleep(time.Millisecond)
mutex.Unlock() // 解锁
wg.Done()
}
func main() {
for r := 0; r < 100; r++ {
wg.Add(1)
go test()
}
wg.Wait()
}
|
互斥锁的本质是当一个goroutine访问的时候,其他goroutine都不能访问。这样在资源同步,避免竞争的同时也降低了程序的并发性能。程序由原来的并行执行变成了串行执行。
另外一种锁,叫做读写锁。 读写锁可以让多个读操作并发,同时读取,但是对于写操作是完全互斥的。也就是说,当一个 goroutine 进行写操作的时候,其他 goroutine 既不能进行读操作,也不能进行写操作。
GO中的读写锁由结构体类型sync.RWMutex表示。此类型的方法集合中包含两对方法: 一组是对写操作的锁定和解锁,简称“写锁定”和“写解锁”:
1
2
|
func (*RWMutex)Lock()
func (*RWMutex)Unlock()
|
另一组表示对读操作的锁定和解锁,简称为“读锁定”与“读解锁”:
1
2
|
func (*RWMutex)RLock()
func (*RWMutex)RUnlock()
|
反射
- 官方说法:在编译时不知道类型的情况下,可更新变量、运行时查看值、调用方法以及直接对他们的布局进行操作的机制,称为反射。
- 通俗一点就是:可以知道本数据的原始数据类型和数据内容,方法等、并且可以进行一定操作
- 我们通过接口或者其他的方式接收到了类型不固定的数据的时候需要写太多的swatch case断言代码,此时代码不灵活且通用性差,反射这时候就可以无视类型,改变原数据结构中的数据
- 包名:
reflect
reflect.TypeOf():动态获取输入参数中的值的类型reflect.TypeOf().Name():获取类型名称reflect.TypeOf().Kind():获取类型种类
- 对于自定义类型,类型是
main.myInt、类型名称为myInt、类型种类为int
- 对于结构体,类型是
main.Person、类型名称为Person、类型种类为struct
- 对于
*int指针,类型是*int、类型名称为空、类型种类为ptr
- 对于数组,类型是
[3]int、类型名称为为空、类型种类为array
- 对于切片,类型是
[]int、类型名称为为空、类型种类为slice
reflect.ValueOf():获取输入参数接口中的数据的值reflect.ValueOf().Fidle(int):用来获取结构体属性值reflect.ValueOf().FieldByIndex([]int{0,1}):从结构体中按层级取值reflect.ValueOf().FieldByName(name):从结构体中按属性名取值reflect.ValueOf().Elem():获取原始数据并操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
func main() {
u := User{
Name: "wyatt",
Age: 21,
Sex: true,
}
MyFunc(u)
}
// MyFunc 用空接口作为入参类型
func MyFunc(inter interface{}) {
fmt.Println(reflect.TypeOf(inter))
fmt.Println(reflect.ValueOf(inter))
fmt.Println(reflect.ValueOf(inter).Field(0))
}
//运行结果:
//main.User
//{wyatt 21 true}
//wyatt
|
判断传入的类型是否是我们想要的类型:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
func main() {
u := User{
Name: "wyatt",
Age: 21,
Sex: true,
}
MyFunc(u)
MyFunc(6)
MyFunc("Hello")
}
// MyFunc 用空接口作为入参类型
func MyFunc(inter interface{}) {
if reflect.TypeOf(inter).Kind() == reflect.Struct {
fmt.Println("I'm Struct")
}
if reflect.TypeOf(inter).Kind() == reflect.String {
fmt.Println("I'm String")
}
if reflect.TypeOf(inter).Kind() == reflect.Int {
fmt.Println("I'm Int")
}
}
//运行结果:
//I'm Struct
//I'm Int
//I'm String
|
通过反射修改内容:
- 想要在函数中通过反射修改变量的值,需要注意函数参数传递的是值拷贝,必须传递变量地址才能修改变量值
- 反射中使用专有的
Elem()方法来获取指针对应的值
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
func main() {
u := User{
Name: "wyatt",
Age: 21,
Sex: true,
}
fmt.Println(u)
MyFunc(&u) //要修改源数据,需要传入地址
fmt.Println(u)
}
// MyFunc 用空接口作为入参类型
func MyFunc(inter interface{}) {
reflect.ValueOf(inter).Elem().FieldByName("Name").SetString("Mr.Wang")
}
//运行结果
//{wyatt 21 true}
//{Mr.Wang 21 true}
|
通过反射调用方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
func (u User) SayName() {
fmt.Println("My name is", u.Name)
}
func main() {
u := User{
Name: "wyatt",
Age: 21,
Sex: true,
}
MyFunc(u)
}
// MyFunc 用空接口作为入参类型
func MyFunc(inter interface{}) {
reflect.ValueOf(inter).Method(0).Call([]reflect.Value{})
}
|
常用包
包(package)是多个 Go 源码的集合,是一种高级的代码复用方案,Go 语言为我们提供了很多内置包,如 fmt、strconv、strings、sort、errors、time、encoding/json、os、io 等。
Golang 中的包可以分为三种:
- 系统内置包: Golang 提供的内置包,引入后可以直接使用,如 fmt、strconv、strings、sort、errors、time、encoding/json、os、io 等
- 自定义包:开发者自己写的包
- 第三方包:属于自定义包的一种,需要下载安装到本地后才可以使用
init()初始化函数
在 Go 语言程序执行时导入包语句会自动触发包内部init()函数的调用。需要注意的是:init()函数没有参数也没有返回值。init()函数在程序运行时自动被调用执行,不能在代码中主动调用它。 包初始化执行的顺序如下图所示:

Go 语言包会从 main 包开始检查其导入的所有包,每个包中又可能导入了其他的包。Go 编译器由此构建出一个树状的包引用关系,再根据引用顺序决定编译顺序,依次编译这些包的代码。 在运行时,被最后导入的包会最先初始化并调用其init()函数, 如下图示

初始化项目:
下载并清除未使用的包:
time包
时间和日期是编程中经常会用到的,在 golang 中time包提供了时间的显示和测量用的函数
可以通过time.Now()函数获取当前的时间对象,然后获取时间对象的年月日时分秒等信息。示例代码如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
func main() {
timeObj := time.Now() //获取当前时间
fmt.Printf("current time:%v\n", timeObj)
year := timeObj.Year() //年
month := timeObj.Month() //月
day := timeObj.Day() //日
hour := timeObj.Hour() //小时
minute := timeObj.Minute() //分钟
second := timeObj.Second() //秒
fmt.Printf("%d-%02d-%02d %02d:%02d:%02d\n", year, month, day, hour, minute, second)
}
// 输出
current time:2024-09-15 23:06:33.9575285 +0800 CST m=+0.002649101
2024-09-15 23:06:33
|
注意:%02d中的中的 2 表示宽度,如果整数不够 2 列就补上 0
也可以用Format方法格式化输出日期字符串
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
func main() {
timeObj := time.Now()
// 格式化的模板为 Go 的出生时间2006年1月2号15点04分(记忆口诀为:2006 1 2 3 4)
// 写成15就是 24 小时制
fmt.Println(timeObj.Format("2006-01-02 15:04:05"))
// 写成03就是 12 小时制
fmt.Println(timeObj.Format("2006-01-02 03:04:05"))
fmt.Println(timeObj.Format("2006/01/02 15:04"))
fmt.Println(timeObj.Format("15:04 2006/01/02"))
fmt.Println(timeObj.Format("2006/01/02"))
}
// 输出
2024-09-15 23:07:08
2024-09-15 11:07:08
2024/09/15 23:07
23:07 2024/09/15
2024/09/15
|
时间戳是自 1970 年 1 月 1 日(08:00:00GMT)至当前时间的总毫秒数。它也被称为 Unix 时间戳(UnixTimestamp), 基于时间对象获取时间戳的示例代码如下:
1
2
3
4
5
6
7
8
9
10
|
func main() {
timeObj := time.Now() //获取当前时间
timestamp1 := timeObj.Unix() //毫秒时间戳
timestamp2 := timeObj.UnixNano() //纳秒时间戳
fmt.Printf("current timestamp1:%v\n", timestamp1)
fmt.Printf("current timestamp2:%v\n", timestamp2)
}
// 输出
current timestamp1:1726413198
current timestamp2:1726413198057647200
|
使用time.Unix()函数可以将时间戳转为时间格式,再使用Format把时间格式化成日期
1
2
3
4
5
6
7
8
9
|
func unixToTime(timestamp int64) {
timeObj := time.Unix(timestamp, 0) //将时间戳转为时间格式
fmt.Println(timeObj.Format("2006-01-02 15:04:05"))
}
func main() {
unixToTime(1726413198)
}
// 输出
2024-09-15 23:13:18
|
日期字符串转换成时间戳
1
2
3
4
5
6
7
8
|
func main() {
t1 := "2024-09-15 23:13:18" // 时间字符串
timeTemplate := "2006-01-02 15:04:05" //模板
timeObj, _ := time.ParseInLocation(timeTemplate, t1, time.Local)
fmt.Println(timeObj.Unix())
}
// 输出
1726413198
|
time.Duration是time包定义的一个类型,它代表两个时间点之间经过的时间,以纳秒为单位。time.Duration表示一段时间间隔,可表示的最长时间段大约 290 年。 time包中定义的时间间隔类型的常量如下:
1
2
3
4
5
6
7
8
|
const (
Nanosecond Duration = 1
Microsecond = 1000 * Nanosecond
Millisecond = 1000 * Microsecond
Second = 1000 * Millisecond
Minute = 60 * Second
Hour = 60 * Minut
)
|
使用时间间隔
1
2
3
4
5
6
7
|
func main() {
fmt.Println(time.Millisecond)
fmt.Println(time.Second)
}
// 输出
1ms
1s
|
在日常的编码过程中可能会遇到要求时间+时间间隔的需求,Go 语言的时间对象有提供 Add 方法,例如求一个小时之后的时间:
1
2
3
4
5
6
7
8
9
|
func main() {
timeObj := time.Now()
fmt.Println(timeObj)
timeObj = timeObj.Add(time.Hour) // 当前时间加 1 小时后的时间
fmt.Println(timeObj)
}
// 输出
2024-09-15 23:31:35.3763716 +0800 CST m=+0.004018501
2024-09-16 00:31:35.3763716 +0800 CST m=+3600.004018501
|
此外还有
Sub:求两个时间之间的差值Equal:判断两个时间是否相同Before、After:判断两个时间先后
可以使用time.NewTicker(时间间隔)来设置定时器
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
func main() {
ticker := time.NewTicker(time.Second) //定义一个 1 秒间隔的定时器
n := 5
// 执行五次
for t := range ticker.C {
fmt.Println(t) //每秒都会执行的任务
n--
if n == 0 {
ticker.Stop() //终止定时器继续执行
break
}
}
}
// 输出
2024-09-15 23:38:23.7271471 +0800 CST m=+1.013951101
2024-09-15 23:38:24.7315988 +0800 CST m=+2.018402801
2024-09-15 23:38:25.7221984 +0800 CST m=+3.009002401
2024-09-15 23:38:26.7214733 +0800 CST m=+4.008277301
2024-09-15 23:38:27.7187273 +0800 CST m=+5.005531301
|
也可以使用time.Sleep(time.Second)来实现定时器
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
// 每隔(休眠)一秒打印一次
func main() {
fmt.Println("aaa")
time.Sleep(time.Second)
fmt.Println("aaa2")
time.Sleep(time.Second)
fmt.Println("aaa3")
time.Sleep(time.Second)
fmt.Println("aaa4")
}
// 输出
aaa
aaa2
aaa3
aaa4
|
context包
引例:启动协程,通过chan,主进程控制子协程并传参
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
func main() {
message := make(chan int) //与协程通信信息
flag := make(chan bool) //结束标志
go son(flag, message)
for i := 0; i < 10; i++ {
message <- i //往msg通道写
}
flag <- true //往flag通道写
time.Sleep(time.Second) //等待1s
fmt.Println("主进程结束")
}
func son(flag chan bool, msg chan int) {
//Tick()函数等待d时长,时间到后,将等待时间写入到channel中并返回这个只读channel
t := time.Tick(time.Second) //等待1s
for _ = range t {
select {
case m := <-msg: //从msg通道读
fmt.Printf("接收到值:%d\n", m)
case <-flag:
fmt.Println("子协程结束")
return
}
}
}
//运行结果:每隔1s打印1行
//接收到值:0
//......
//接收到值:9
//子协程结束
//主进程结束
|
- context包:
context的作用就是在不同的goroutine之间同步请求特定的数据、取消信号以及处理请求的截止日期
WithCancel:创建一个带有Clear()关闭函数的ctxWithDeadline:创建一个带有超时时间点的ctxWithTimeout:创建一个有超时时间的ctxWithValue:创建一个携带了参数的ctxContext基础接口:
Deadline()Done()Err()Value()
TODO:不确定是否使用上下文的时候使用,返回emptyCtxBackground:确定使用上下文的时候使用,返回emptyCtx
用ctx改写上面的程序:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
func main() {
message := make(chan int) //与协程通信信息
//flag := make(chan bool) //结束标志
ctx, clear := context.WithCancel(context.Background())
go son(ctx, message)
for i := 0; i < 10; i++ {
message <- i //往msg通道写
}
//flag <- true //往flag通道写
clear()
time.Sleep(time.Second) //等待1s
fmt.Println("主进程结束")
}
func son(ctx context.Context, msg chan int) {
//Tick()函数等待d时长,时间到后,将等待时间写入到channel中并返回这个只读channel
t := time.Tick(time.Second) //等待1s
for _ = range t {
select {
case m := <-msg: //从msg通道读
fmt.Printf("接收到值:%d\n", m)
case <-ctx.Done():
fmt.Println("子协程结束")
return
}
}
}
//运行结果:每隔1s打印1行
//接收到值:0
//......
//接收到值:9
//子协程结束
//主进程结束
|
用WithValue传参:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
func main() {
message := make(chan int) //与协程通信信息
//flag := make(chan bool) //结束标志
ctx := context.WithValue(context.Background(), "name", "wyatt")
ctx, clear := context.WithCancel(ctx)
//ctx, clear := context.WithCancel(context.Background())
go son(ctx, message)
for i := 0; i < 10; i++ {
message <- i //往msg通道写
}
//flag <- true //往flag通道写
clear()
time.Sleep(time.Second) //等待1s
fmt.Println("主进程结束")
}
func son(ctx context.Context, msg chan int) {
//Tick()函数等待d时长,时间到后,将等待时间写入到channel中并返回这个只读channel
t := time.Tick(time.Second) //等待1s
for _ = range t {
select {
case m := <-msg: //从msg通道读
fmt.Printf("接收到值:%d\n", m)
case <-ctx.Done():
fmt.Println("子协程结束", ctx.Value("name"))
return
}
}
}
//运行结果:每隔1s打印1行
//接收到值:0
//......
//接收到值:9
//子协程结束 wyatt
//主进程结束
|
用WithDeadline创建一个带有超时时间点的ctx,超时自动结束
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
func main() {
message := make(chan int) //与协程通信信息
//flag := make(chan bool) //结束标志
//ctx := context.WithValue(context.Background(), "name", "wyatt")
//ctx, clear := context.WithCancel(ctx)
//ctx, clear := context.WithCancel(context.Background())
ctx, clear := context.WithDeadline(context.Background(), time.Now().Add(time.Second*8))
go son(ctx, message)
for i := 0; i < 10; i++ {
message <- i //往msg通道写
}
//flag <- true //往flag通道写
defer clear()
time.Sleep(time.Second) //等待1s
fmt.Println("主进程结束")
}
func son(ctx context.Context, msg chan int) {
//Tick()函数等待d时长,时间到后,将等待时间写入到channel中并返回这个只读channel
t := time.Tick(time.Second) //等待1s
for _ = range t {
select {
case m := <-msg: //从msg通道读
fmt.Printf("接收到值:%d\n", m)
case <-ctx.Done():
fmt.Println("子协程结束")
return
}
}
}
//运行结果:每隔1s打印1行
//接收到值:0
//......
//接收到值:7
//子协程结束
|
用WithTimeout创建一个有超时时间的ctx,超时自动结束
1
|
ctx, clear := context.WithTimeout(context.Background(), time.Second*4)
|
sync包
互斥锁:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
func main() {
l := &sync.Mutex{}
go lockFun(l)
go lockFun(l)
go lockFun(l)
for {
}
}
func lockFun(lock *sync.Mutex) {
lock.Lock() //加互斥锁
fmt.Println("这是个共享设备,同时只能被一个进程访问")
time.Sleep(1 * time.Second)
lock.Unlock() //解互斥锁
}
//运行结果:不是同时打印的,只有上一个锁解了,下一个才能执行
//这是个共享设备,同时只能被一个进程访问
//这是个共享设备,同时只能被一个进程访问
//这是个共享设备,同时只能被一个进程访问
|
读写锁:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
func main() {
l := &sync.RWMutex{}
go lockFun(l)
go lockFun(l)
go readLockFun(l)
go readLockFun(l)
go readLockFun(l)
go readLockFun(l)
for {
}
}
func lockFun(lock *sync.RWMutex) {
lock.Lock() //加互斥锁
fmt.Println("这是个共享设备,同时只能被一个进程访问")
time.Sleep(1 * time.Second)
lock.Unlock() //解互斥锁
}
func readLockFun(lock *sync.RWMutex) {
lock.RLock() //加读锁
fmt.Println("可以共享读")
time.Sleep(1 * time.Second)
lock.RUnlock() //解读锁
}
//运行结果:共享读是同时打印的,因为读取的时候不会阻塞
//这是个共享设备,同时只能被一个进程访问
//可以共享读
//可以共享读
//可以共享读
//可以共享读
//这是个共享设备,同时只能被一个进程访问
|
Once.Do():这个方法无论被调用多少次,只会执行一次
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
func main() {
o := &sync.Once{}
for i := 0; i < 10; i++ {
o.Do(func() {
fmt.Println(i)
})
}
for i := 0; i < 10; i++ {
o.Do(func() {
fmt.Println(i)
})
}
for i := 0; i < 10; i++ {
o.Do(func() {
fmt.Println(i)
})
}
}
//运行结果:
//0
|
WaitGroup:
Add(delta int):设定需要Done多少次Done():Done一次+1Wait():在到达Done的次数前一直阻塞
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
func main() {
wg := &sync.WaitGroup{}
wg.Add(2)
go func() {
time.Sleep(3 * time.Second)
wg.Done()
fmt.Println("等了3s")
}()
go func() {
time.Sleep(6 * time.Second)
wg.Done()
fmt.Println("等了6s")
}()
wg.Wait()
fmt.Println("over")
}
//运行结果:
//等了3s
//等了6s
//over
|
Map:一个并发字典,可以同时读写字典
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
func main() {
m := &sync.Map{}
go func() {
for {
m.Store(1, 1) //存
}
}()
go func() {
for {
fmt.Println(m.Load(1)) //取
}
}()
time.Sleep(100)
}
//运行结果:
//1 true
//1 true
//......
|
Pool:并发池,每次取出的数随机
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
func main() {
p := &sync.Pool{}
p.Put(1) //存
p.Put(2) //存
p.Put(3) //存
p.Put(4) //存
p.Put(5) //存
p.Put(6) //存
for i := 0; i < 6; i++ {
time.Sleep(1 * time.Second)
fmt.Println(p.Get()) //取
}
}
//运行结果:每次取出的数随机
//2
//1
//3
//6
//4
//5
|
net包
这些原生API实际工作中用的不多,因为已经有许多框架封装好了
tcp
服务器监听tcp连接,打印客户端IP+PORT+传来的信息:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
func main() {
//创建tcp协议地址
tcpAddr, _ := net.ResolveTCPAddr("tcp", ":8888")
//创建tcp监听
listener, _ := net.ListenTCP("tcp", tcpAddr)
for { //循环监听
//创建tcp连接
conn, err := listener.AcceptTCP()
if err != nil {
fmt.Println(err)
return
// handle error
}
go handleConnection(conn) //启动子协程处理各个tcp连接
}
}
func handleConnection(conn *net.TCPConn) {
buf := make([]byte, 1024)
n, _ := conn.Read(buf)
fmt.Println(conn.RemoteAddr().String() + string(buf[0:n]))
}
|
客户端从命令行接收输入后连接到服务器:
1
2
3
4
5
6
7
|
func main() {
tcpAddr, _ := net.ResolveTCPAddr("tcp", ":8888")
conn, _ := net.DialTCP("tcp", nil, tcpAddr)
reader := bufio.NewReader(os.Stdin) //获取命令行输入
bytes, _, _ := reader.ReadLine()
conn.Write(bytes)
}
|
实现回射:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
//server.go
func main() {
//创建tcp协议地址
tcpAddr, _ := net.ResolveTCPAddr("tcp", ":8888")
//创建tcp监听
listener, _ := net.ListenTCP("tcp", tcpAddr)
for { //循环监听
//创建tcp连接
conn, err := listener.AcceptTCP()
if err != nil {
fmt.Println(err)
return
// handle error
}
go handleConnection(conn) //启动子协程处理各个tcp连接
}
}
func handleConnection(conn *net.TCPConn) {
for {
buf := make([]byte, 1024)
n, err := conn.Read(buf)
if err != nil {
fmt.Println(err)
break
}
fmt.Println(conn.RemoteAddr().String() + " " + string(buf[0:n]))
str := "收到了:" + string(buf[0:n])
conn.Write([]byte(str))
}
}
//client.go
func main() {
tcpAddr, _ := net.ResolveTCPAddr("tcp", ":8888")
conn, _ := net.DialTCP("tcp", nil, tcpAddr)
reader := bufio.NewReader(os.Stdin) //获取命令行输入
for {
bytes, _, _ := reader.ReadLine()
conn.Write(bytes)
rb := make([]byte, 1024)
rn, _ := conn.Read(rb)
fmt.Println(string(rb[0:rn]))
}
}
|
http
GIN框架已经封装好了,这里仅作学习使用
- 访问
127.0.0.1:8080/test(GET请求),看到响应服务器收到:
1
2
3
4
5
6
7
8
9
|
func handler(res http.ResponseWriter, req *http.Request) {
res.Write([]byte("服务器收到"))
}
func main() {
//注册路径'/test',放入写好的handler
http.HandleFunc("/test", handler)
//启动http服务器
http.ListenAndServe(":8080", nil)
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
func handler(res http.ResponseWriter, req *http.Request) {
switch req.Method {
case "GET":
res.Write([]byte("服务器收到了GET请求"))
break
case "POST":
res.Write([]byte("服务器收到了POST请求"))
}
}
func main() {
//注册路径'/test',放入写好的handler
http.HandleFunc("/test", handler)
//启动http服务器
http.ListenAndServe(":8080", nil)
}
|
1
2
3
4
5
6
7
8
9
10
11
12
|
func main() {
//1.创建客户端
client := new(http.Client)
//2.构造请求
//req, _ := http.NewRequest("GET", "http://localhost:8080/test", nil)
req, _ := http.NewRequest("POST", "http://localhost:8080/test", bytes.NewBuffer([]byte("{\"name\":\"wyatt\"}")))
//3.发送请求 得到返回
res, _ := client.Do(req)
body := res.Body
b, _ := io.ReadAll(body)
fmt.Println(string(b))
}
|
rpc
- RPC(Remote Procedure Call):远程过程调用,可以在本地调用远程服务器上的方法
- Go的RPC只支持go写的系统
- Go RPC的函数有特殊要求:
- 函数首字母必须大写
- 必须只有两个参数,第一个是接收的参数,第二个是返回给客户端的参数,第二个参数必须是指针类型的
- 函数还要有一个返回值error
1
|
func (t *T)MethodName(argType T1,replyType *T2) error{}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
|
//server.go
type Server struct {
}
type Req struct {
NumOne int
NumTwo int
}
type Res struct {
Num int
}
func (s *Server) Add(req Req, res *Res) error {
res.Num = req.NumOne + req.NumTwo
return nil
}
func main() {
//1.rpc注册
rpc.Register(new(Server))
//2.借用http协议作为rpc载体
rpc.HandleHTTP()
//3.创建一个listen
listen, err := net.Listen("tcp", ":8888")
if err != nil {
fmt.Println(err)
}
//4.启动服务
http.Serve(listen, nil)
}
//client.go
type Req struct {
NumOne int
NumTwo int
}
type Res struct {
Num int
}
func main() {
req := Req{
NumOne: 1,
NumTwo: 2,
}
var res Res
client, err := rpc.DialHTTP("tcp", "localhost:8888")
if err != nil {
log.Fatal("dialing:", err)
}
client.Call("Server.Add", req, &res)
fmt.Println(res)
}
|
bufio包
原理
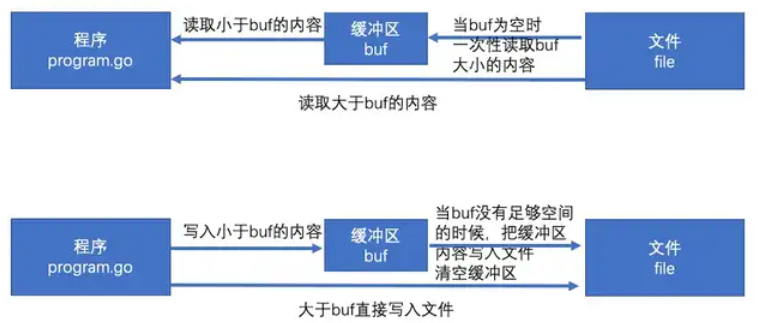
bufio是通过缓冲来提高效率。
io操作本身的效率并不低,低的是频繁的访问本地磁盘的文件。所以bufio就提供了缓冲区(分配一块内存),读和写都先在缓冲区中,最后再读写文件,来降低访问本地磁盘的次数,从而提高效率。
简单的说就是,把文件读取进缓冲(内存)之后再读取的时候就可以避免文件系统的 io 从而提高速度。同理,在进行写操作时,先把文件写入缓冲(内存),然后由缓冲写入文件系统。与 内容->文件 相比 内容->缓冲->文件,缓冲区的设计是为了存储多次的写入,最后一口气把缓冲区内容写入文件。
Reader对象
bufio.Reader 是 bufio 中对 io.Reader 的封装
1
2
3
4
5
6
7
8
9
|
// Reader implements buffering for an io.Reader object.
type Reader struct {
buf []byte
rd io.Reader // reader provided by the client
r, w int // buf read and write positions
err error
lastByte int // last byte read for UnreadByte; -1 means invalid
lastRuneSize int // size of last rune read for UnreadRune; -1 means invalid
}
|
bufio.Reader 实现了如下接口:io.Reader、io.WriterTo、io.ByteScanner、io.RuneScanner`
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
// NewReaderSize 将 rd 封装成一个带缓存的 bufio.Reader 对象,
// 缓存大小由 size 指定(如果小于 16 则会被设置为 16)。
// 如果 rd 的基类型就是有足够缓存的 bufio.Reader 类型,则直接将
// rd 转换为基类型返回。
func NewReaderSize(rd io.Reader, size int) *Reader
// NewReader 相当于 NewReaderSize(rd, 4096)
func NewReader(rd io.Reader) *Reader
// Peek 返回缓存的一个切片,该切片引用缓存中前 n 个字节的数据,
// 该操作不会将数据读出,只是引用,引用的数据在下一次读取操作之
// 前是有效的。如果切片长度小于 n,则返回一个错误信息说明原因。
// 如果 n 大于缓存的总大小,则返回 ErrBufferFull。
func (b *Reader) Peek(n int) ([]byte, error)
// Read 从 b 中读出数据到 p 中,返回读出的字节数和遇到的错误。
// 如果缓存不为空,则只能读出缓存中的数据,不会从底层 io.Reader
// 中提取数据,如果缓存为空,则:
// 1、len(p) >= 缓存大小,则跳过缓存,直接从底层 io.Reader 中读
// 出到 p 中。
// 2、len(p) < 缓存大小,则先将数据从底层 io.Reader 中读取到缓存
// 中,再从缓存读取到 p 中。
func (b *Reader) Read(p []byte) (n int, err error)
// Buffered 返回缓存中未读取的数据的长度。
func (b *Reader) Buffered() int
// f回在第一次出现传入字节前的字节
func (b *Reader) ReadSlice(delim byte) (line []byte, err error)
// ReadBytes 功能同 ReadSlice,只不过返回的是缓存的拷贝。
func (b *Reader) ReadBytes(delim byte) (line []byte, err error)
// ReadString 功能同 ReadBytes,只不过返回的是字符串。
func (b *Reader) ReadString(delim byte) (line string, err error)
...
|
Writer对象
bufio.Writer 是 bufio 中对 io.Writer 的封装
1
2
3
4
5
6
|
type Writer struct {
err error
buf []byte
n int
wr io.Writer
}
|
字段 buf 用来存储数据,当缓存满或者 Flush 被调用时,消费者(wr)可以从缓存中获取到数据。如果写入过程中发生了 I/O error,此 error 将会被赋给 err 字段, error 发生之后,writer 将停止操作(writer is no-op)
bufio.Writer 实现了如下接口:io.Writer、io.ReaderFrom、io.ByteWriter
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
// NewWriterSize 将 wr 封装成一个带缓存的 bufio.Writer 对象,
// 缓存大小由 size 指定(如果小于 4096 则会被设置为 4096)。
// 如果 wr 的基类型就是有足够缓存的 bufio.Writer 类型,则直接将
// wr 转换为基类型返回。
func NewWriterSize(wr io.Writer, size int) *Writer
// NewWriter 相当于 NewWriterSize(wr, 4096)
func NewWriter(wr io.Writer) *Writer
// WriteString 功能同 Write,只不过写入的是字符串
func (b *Writer) WriteString(s string) (int, error)
// WriteRune 向 b 写入 r 的 UTF-8 编码,返回 r 的编码长度。
func (b *Writer) WriteRune(r rune) (size int, err error)
// Flush 将缓存中的数据提交到底层的 io.Writer 中
func (b *Writer) Flush() error
// Available 返回缓存中未使用的空间的长度
func (b *Writer) Available() int
// Buffered 返回缓存中未提交的数据的长度
func (b *Writer) Buffered() int
// Reset 将 b 的底层 Writer 重新指定为 w,同时丢弃缓存中的所有数据,复位
// 所有标记和错误信息。相当于创建了一个新的 bufio.Writer。
func (b *Writer) Reset(w io.Writer)
...
|
文件操作
基础知识
io包的四个接口:
1
|
type Reader interface { Read(p []byte)(n int, err error) }
|
Reader:将len个字节读取到p中ReadFrom():常用方法,实现了Reader接口的都可以用
1
|
type Writer interface { Write(p []byte)(n int, err error) }
|
Write方法用于将p中的数据写入到对象的数据流中
1
|
type Seeker interface { Seek(offset int64, whence int)(ret int64, err error) }
|
Seek设置下一次读写操作的指针位置,每次的读写操作都是从指针位置开始的whence为0:表示从数据的开头开始移动指针whence为1:表示从数据的当前指针位置开始移动指针whence为2:表示从数据的尾部开始移动指针offset:指针移动的偏移量
1
|
type Closer interface { Close() error }
|
Close一般用于关闭文件、关闭连接、关闭数据库等
一些常量
打开文件时赋予文件的权限:
1
2
3
4
5
6
7
8
9
10
|
const(
O.RDONLY int=syscall.O_RDONLY //只读模式打开文件
O.WRONLY int=syscall.O_WRONLY //只写模式打开文件
O_RDWR int=syscall.O_RDWR //读写模式打开文件
O_APPEND int=syscall.O_APPEND //写操作时将数据附加到文件尾部
O_CREATE int=syscall.O_CREAT //如果不存在将创建一个新文件
O_EXCL int=syscall.O_EXCL //和O_CREATE配合使用,文件必须不存在
O_SYNC int=syscall.O_SYNC //打开文件用于同步IO
O_TRUNC int=syscall.O_TRUNC //如果可能,打开时清空文件
)
|
perm:文件权限,一个八进制数。r(读)04,w(写)02,x(执行)01
打开文件若不存在则新建,并读取内容:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
func main() {
f, err := os.OpenFile("./test.txt", os.O_CREATE|os.O_RDWR, 0777)
if err != nil {
fmt.Println(err)
return
}
for {
buf := make([]byte, 12) //缓冲区大小为12字节
n, err := f.Read(buf) //读到缓冲区
if err != nil {
fmt.Println(err)
return
}
//打印每次读到的数据和字节数
fmt.Println(string(buf), n)
}
}
//test.txt内容:家乡的一片片片梯田是我看过最美的绿地
//运行结果:
//家乡的一 12
//片片片梯 12
//田是我看 12
//过最美的 12
//绿地 6
//EOF
|
上面的是原生io操作文件,下面展示部分封装好的读文件的关键方法
-
os.openFile():用于打开文件获取到*fire
-
bufio.newReader(f):将文件变化为reader
reader.ReadString('字符'):调用reader上的方法还 有ReadLine ReadByte ReadSlice 等
-
ioutil.ReadAll(f):直接读取整个文件 os.ReadFile(文件路径)也能达到同样效果
-
os.ReadDir("./"):读取文件夹获取目标文件夹下的文件信息
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
func main() {
f, err := os.OpenFile("./test.txt", os.O_CREATE|os.O_RDWR, 0777)
if err != nil {
fmt.Println(err)
return
}
defer f.Close()
reader := bufio.NewReader(f)
for {
str, isPrefix, err := reader.ReadLine()
if err != nil {
fmt.Println(err)
return
}
//打印每次读到的数据和是否是前缀
fmt.Println(string(str), isPrefix)
}
}
//运行结果:
//家乡的一片片片梯田是我看过最美的绿地 false
//EOF
|
写文件的几个关键方法:
os.openFile():用于打开文件获取到*firef.Seek():挪光标位置f.WriteString():直接写入bufio.NewWriter(f):创建一个缓存的写
writer.VriteString():先写入内存writer.Flush():缓存内容生效,写入文件
复制文件:open两个文件然后io.Copy(dst,src)
实际操作
读取文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
// 读取文件(方法1)
// 1.只读方式打开文件
file, err := os.Open()
// 2.读取文件
file.Read()
// 3.关闭文件流
defer file.Close()
// 读取文件(方法2)`bufio`读取文件
// 1.只读方式打开文件
file,err := os.Open()
// 2.创建reader对象
reader := bufio.NewReader(file)
// 3.ReadString读取文件
line, err := reader.ReadString('\n')
// 4.关闭文件流
defer file.Close()
// 读取文件(方法3)`ioutil`读取文件
// 打开关闭文件的方法它都封装好了只需要一句话就可以读取
ioutil.ReadFile("./main.go")
|
写入文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
// 写入文件(方法1)
// 1.打开文件
file, err := os.OpenFile("C:/test.txt", os.O_CREATE|os.O_RDWR, 0666)
// 2.写入文件
file.Write([]byte(str)) //写入字节切片数据
file.WriteString("直接写入的字符串数据") //直接写入字符串数据
// 3.关闭文件流
file.Close()
// 写入文件(方法2) bufio 写入文件
// 1.打开文件
file, err := os.OpenFile("C:/test.txt", os.O_CREATE|os.O_RDWR, 0666)
// 2.创建writer对象
writer := bufio.NewWriter(file)
// 3.将数据先写入缓存
writer.WriteString("你好golang\r\n")
// 4.将缓存中的内容写入文件
writer.Flush()
// 5.关闭文件流
file.Close()
// 写入文件(方法3) ioutil 写入文件
str := "hello golang"
err := ioutil.WriteFile("C:/test.txt", []byte(str), 0666)
|
文件重命名
1
|
err := os.Rename("C:/test1.txt", "D:/test1.txt") //只能同盘操作
|
复制文件
1
2
3
4
5
6
7
8
9
10
11
12
|
// 方法1
input, err := ioutil.ReadFile(srcFileName)
err = ioutil.WriteFile(dstFileName, input, 0644)
// 方法2
source, _ := os.Open(srcFileName)
destination, _ := os.OpenFile(dstFileName, os.O_CREATE|os.O_WRONLY, 0666)
n, err := source.Read(buf)
destination.Write(buf[:n]);
|
创建目录
1
2
|
err := os.Mkdir("./abc", 0666)
err := os.MkdirAll("dir1/dir2/dir3", 0666) //创建多级目录
|
删除目录和文件
1
2
|
err := os.Remove("t.txt")
err := os.RemoveAll("aaa")
|
socket编程
TCP
TCP服务端程序的处理流程:
- 监听端口
- 接收客户端请求建立链接
- 创建goroutine处理链接。
使用Go语言的net包实现的TCP服务端代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
// tcp/server/main.go
// TCP server端
// 处理函数
func process(conn net.Conn) {
defer conn.Close() // 关闭连接
for {
reader := bufio.NewReader(conn)
var buf [128]byte
n, err := reader.Read(buf[:]) // 读取数据
if err != nil {
fmt.Println("read from client failed, err:", err)
break
}
recvStr := string(buf[:n])
fmt.Println("收到client端发来的数据:", recvStr)
conn.Write([]byte(recvStr)) // 发送数据
}
}
func main() {
listen, err := net.Listen("tcp", "127.0.0.1:20000")
if err != nil {
fmt.Println("listen failed, err:", err)
return
}
for {
conn, err := listen.Accept() // 建立连接
if err != nil {
fmt.Println("accept failed, err:", err)
continue
}
go process(conn) // 启动一个goroutine处理连接
}
}
|
一个TCP客户端进行TCP通信的流程如下:
- 建立与服务端的链接
- 进行数据收发
- 关闭链接
使用Go语言的net包实现的TCP客户端代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
// tcp/client/main.go
// 客户端
func main() {
conn, err := net.Dial("tcp", "127.0.0.1:20000")
if err != nil {
fmt.Println("err :", err)
return
}
defer conn.Close() // 关闭连接
inputReader := bufio.NewReader(os.Stdin)
for {
input, _ := inputReader.ReadString('\n') // 读取用户输入
inputInfo := strings.Trim(input, "\r\n")
if strings.ToUpper(inputInfo) == "Q" { // 如果输入q就退出
return
}
_, err = conn.Write([]byte(inputInfo)) // 发送数据
if err != nil {
return
}
buf := [512]byte{}
n, err := conn.Read(buf[:])
if err != nil {
fmt.Println("recv failed, err:", err)
return
}
fmt.Println(string(buf[:n]))
}
}
|
TCP黏包
服务端代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
// socket_stick/server/main.go
func process(conn net.Conn) {
defer conn.Close()
reader := bufio.NewReader(conn)
var buf [1024]byte
for {
n, err := reader.Read(buf[:])
if err == io.EOF {
break
}
if err != nil {
fmt.Println("read from client failed, err:", err)
break
}
recvStr := string(buf[:n])
fmt.Println("收到client发来的数据:", recvStr)
}
}
func main() {
listen, err := net.Listen("tcp", "127.0.0.1:30000")
if err != nil {
fmt.Println("listen failed, err:", err)
return
}
defer listen.Close()
for {
conn, err := listen.Accept()
if err != nil {
fmt.Println("accept failed, err:", err)
continue
}
go process(conn)
}
}
|
客户端代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
// socket_stick/client/main.go
func main() {
conn, err := net.Dial("tcp", "127.0.0.1:30000")
if err != nil {
fmt.Println("dial failed, err", err)
return
}
defer conn.Close()
for i := 0; i < 20; i++ {
msg := `Hello, Hello. How are you?`
conn.Write([]byte(msg))
}
}
|
将上面的代码保存后,分别编译。先启动服务端再启动客户端,可以看到服务端输出结果如下:
1
2
3
4
5
|
收到client发来的数据: Hello, Hello. How are you?Hello, Hello. How are you?Hello, Hello. How are you?Hello, Hello. How are you?Hello, Hello. How are you?
收到client发来的数据: Hello, Hello. How are you?Hello, Hello. How are you?Hello, Hello. How are you?Hello, Hello. How are you?Hello, Hello. How are you?Hello, Hello. How are you?Hello, Hello. How are you?Hello, Hello. How are you?
收到client发来的数据: Hello, Hello. How are you?Hello, Hello. How are you?
收到client发来的数据: Hello, Hello. How are you?Hello, Hello. How are you?Hello, Hello. How are you?
收到client发来的数据: Hello, Hello. How are you?Hello, Hello. How are you?
|
客户端分10次发送的数据,在服务端并没有成功的输出10次,而是多条数据“粘”到了一起。
为什么会出现粘包
主要原因就是tcp数据传递模式是流模式,在保持长连接的时候可以进行多次的收和发。
“粘包"可发生在发送端也可发生在接收端:
- 由Nagle算法造成的发送端的粘包:Nagle算法是一种改善网络传输效率的算法。简单来说就是当提交一段数据给TCP发送时,TCP并不立刻发送此段数据,而是等待一小段时间看看在等待期间是否还有要发送的数据,若有则会一次把这两段数据发送出去。
- 接收端接收不及时造成的接收端粘包:TCP会把接收到的数据存在自己的缓冲区中,然后通知应用层取数据。当应用层由于某些原因不能及时的把TCP的数据取出来,就会造成TCP缓冲区中存放了几段数据。
解决办法
出现"粘包"的关键在于接收方不确定将要传输的数据包的大小,因此可以对数据包进行封包和拆包的操作。
封包:封包就是给一段数据加上包头,这样一来数据包就分为包头和包体两部分内容了(过滤非法包时封包会加入"包尾"内容)。包头部分的长度是固定的,并且它存储了包体的长度,根据包头长度固定以及包头中含有包体长度的变量就能正确的拆分出一个完整的数据包。
可以自己定义一个协议,比如数据包的前4个字节为包头,里面存储的是发送的数据的长度。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
|
// socket_stick/proto/proto.go
package proto
import (
"bufio"
"bytes"
"encoding/binary"
)
// Encode 将消息编码
func Encode(message string) ([]byte, error) {
// 读取消息的长度,转换成int32类型(占4个字节)
var length = int32(len(message))
var pkg = new(bytes.Buffer)
// 写入消息头
err := binary.Write(pkg, binary.LittleEndian, length)
if err != nil {
return nil, err
}
// 写入消息实体
err = binary.Write(pkg, binary.LittleEndian, []byte(message))
if err != nil {
return nil, err
}
return pkg.Bytes(), nil
}
// Decode 解码消息
func Decode(reader *bufio.Reader) (string, error) {
// 读取消息的长度
lengthByte, _ := reader.Peek(4) // 读取前4个字节的数据
lengthBuff := bytes.NewBuffer(lengthByte)
var length int32
err := binary.Read(lengthBuff, binary.LittleEndian, &length)
if err != nil {
return "", err
}
// Buffered返回缓冲中现有的可读取的字节数。
if int32(reader.Buffered()) < length+4 {
return "", err
}
// 读取真正的消息数据
pack := make([]byte, int(4+length))
_, err = reader.Read(pack)
if err != nil {
return "", err
}
return string(pack[4:]), nil
}
|
接下来在服务端和客户端分别使用上面定义的proto包的Decode和Encode函数处理数据。
服务端代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
// socket_stick/server2/main.go
func process(conn net.Conn) {
defer conn.Close()
reader := bufio.NewReader(conn)
for {
msg, err := proto.Decode(reader)
if err == io.EOF {
return
}
if err != nil {
fmt.Println("decode msg failed, err:", err)
return
}
fmt.Println("收到client发来的数据:", msg)
}
}
func main() {
listen, err := net.Listen("tcp", "127.0.0.1:30000")
if err != nil {
fmt.Println("listen failed, err:", err)
return
}
defer listen.Close()
for {
conn, err := listen.Accept()
if err != nil {
fmt.Println("accept failed, err:", err)
continue
}
go process(conn)
}
}
|
客户端代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
// socket_stick/client2/main.go
func main() {
conn, err := net.Dial("tcp", "127.0.0.1:30000")
if err != nil {
fmt.Println("dial failed, err", err)
return
}
defer conn.Close()
for i := 0; i < 20; i++ {
msg := `Hello, Hello. How are you?`
data, err := proto.Encode(msg)
if err != nil {
fmt.Println("encode msg failed, err:", err)
return
}
conn.Write(data)
}
}
|
UDP
使用Go语言的net包实现的UDP服务端代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
// UDP/server/main.go
// UDP server端
func main() {
listen, err := net.ListenUDP("udp", &net.UDPAddr{
IP: net.IPv4(0, 0, 0, 0),
Port: 30000,
})
if err != nil {
fmt.Println("listen failed, err:", err)
return
}
defer listen.Close()
for {
var data [1024]byte
n, addr, err := listen.ReadFromUDP(data[:]) // 接收数据
if err != nil {
fmt.Println("read udp failed, err:", err)
continue
}
fmt.Printf("data:%v addr:%v count:%v\n", string(data[:n]), addr, n)
_, err = listen.WriteToUDP(data[:n], addr) // 发送数据
if err != nil {
fmt.Println("write to udp failed, err:", err)
continue
}
}
}
|
UDP客户端
使用Go语言的net包实现的UDP客户端代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
// UDP 客户端
func main() {
socket, err := net.DialUDP("udp", nil, &net.UDPAddr{
IP: net.IPv4(0, 0, 0, 0),
Port: 30000,
})
if err != nil {
fmt.Println("连接服务端失败,err:", err)
return
}
defer socket.Close()
sendData := []byte("Hello server")
_, err = socket.Write(sendData) // 发送数据
if err != nil {
fmt.Println("发送数据失败,err:", err)
return
}
data := make([]byte, 4096)
n, remoteAddr, err := socket.ReadFromUDP(data) // 接收数据
if err != nil {
fmt.Println("接收数据失败,err:", err)
return
}
fmt.Printf("recv:%v addr:%v count:%v\n", string(data[:n]), remoteAddr, n)
}
|
泛型
go 1.18新特性
写法:[泛型标识 泛型约束] [T any]
含义:在定义函数(结构等)时候,可能会有多种类型传入,真正使用方法的时候才可以确定用的是什么类型,此时就可以用一个更加宽泛的类型(存在一定约束,只能在哪些类型的范围内使用)暂时占位,这个类型就叫泛型
泛型方法
1
2
3
4
5
6
7
8
9
10
11
12
|
func same[T int | float64 | string](a, b T) bool {
return a == b
}
func main() {
fmt.Println(same(1, 1))
fmt.Println(same("1", "1"))
fmt.Println(same(1.0, 1.0))
}
//运行结果:
//true
//true
//true
|
泛型结构体
1
2
3
4
5
6
7
8
9
10
11
|
type Person[T any] struct {
Name string
Sex T
}
func main() {
//使用时指定T为string类型
p := Person[string]{}
p.Name = "wyatt"
p.Sex = "male"
}
|
泛型Map
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
func same[T int | float64 | string](a, b T) bool {
return a == b
}
type Person[T any] struct {
Name string
Sex T
}
type TMap[K comparable, V string | int] map[K]V
func main() {
m := make(TMap[int, string])
m[1] = "123"
fmt.Println(m)
}
|
泛型切片
1
2
3
4
5
6
7
|
type TSlice[S any] []S
func main() {
s := make(TSlice[string], 6)
s[5] = "456"
fmt.Println(s)
}
|
自定义泛型约束
1
2
3
4
5
6
7
8
9
10
11
12
|
type MyType interface {
int | float64 | string
}
func Test[T MyType](s T) {
fmt.Println(s)
}
func main() {
Test(1)
Test("1")
Test(1.0)
}
|
~的含义
- 模湖匹配,所有底层为这个类型的类型,包括自定义得到数据类型
1
2
3
4
5
6
7
8
9
10
11
|
type MyType interface {
~int | float64 | string
}
type MyInt int
func Test[T MyType](s T) {
fmt.Println(s)
}
func main() {
Test[MyInt](1)
}
|
websocket
- websocket是http的一种升级模式,服务器和客户端不再是一问一答模式,而是一方可以主动向另一方发送消息,建立长连接
github.com/gorilla/websocket
实现回射:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
|
//server.go
// 1.配置socket连接buffer读取和写入和读取大小
var UP = websocket.Upgrader{
ReadBufferSize: 1024,
WriteBufferSize: 1024,
}
// 2.定义方法handler 入参为http请求和写入
func handler(w http.ResponseWriter, r *http.Request) {
//使用Up.Upgrade 创建conn
conn, err := UP.Upgrade(w, r, nil)
if err != nil {
log.Println(err)
return
}
//for循环 读取socket客户端消息
for {
//读取消息
m, p, e := conn.ReadMessage()
if e != nil {
break
}
conn.WriteMessage(websocket.TextMessage, []byte(string(p)))
fmt.Println(m, string(p))
}
defer conn.Close()
log.Println("服务关闭")
}
func main() {
http.HandleFunc("/", handler)
http.ListenAndServe(":8888", nil)
}
//client.go
func main() {
//1.创建一个Dialer
dl := websocket.Dialer{}
//2.用Dialer的Dial方法进行连接,得到conn
conn, _, err := dl.Dial("ws://127.0.0.1:8888", nil)
if err != nil {
log.Println(err)
return
}
go send(conn)
for {
m, p, e := conn.ReadMessage()
if e != nil {
break
}
fmt.Println(m, string(p))
}
}
func send(conn *websocket.Conn) {
for {
reader := bufio.NewReader(os.Stdin)
l, _, _ := reader.ReadLine()
conn.WriteMessage(websocket.TextMessage, l)
}
}
|